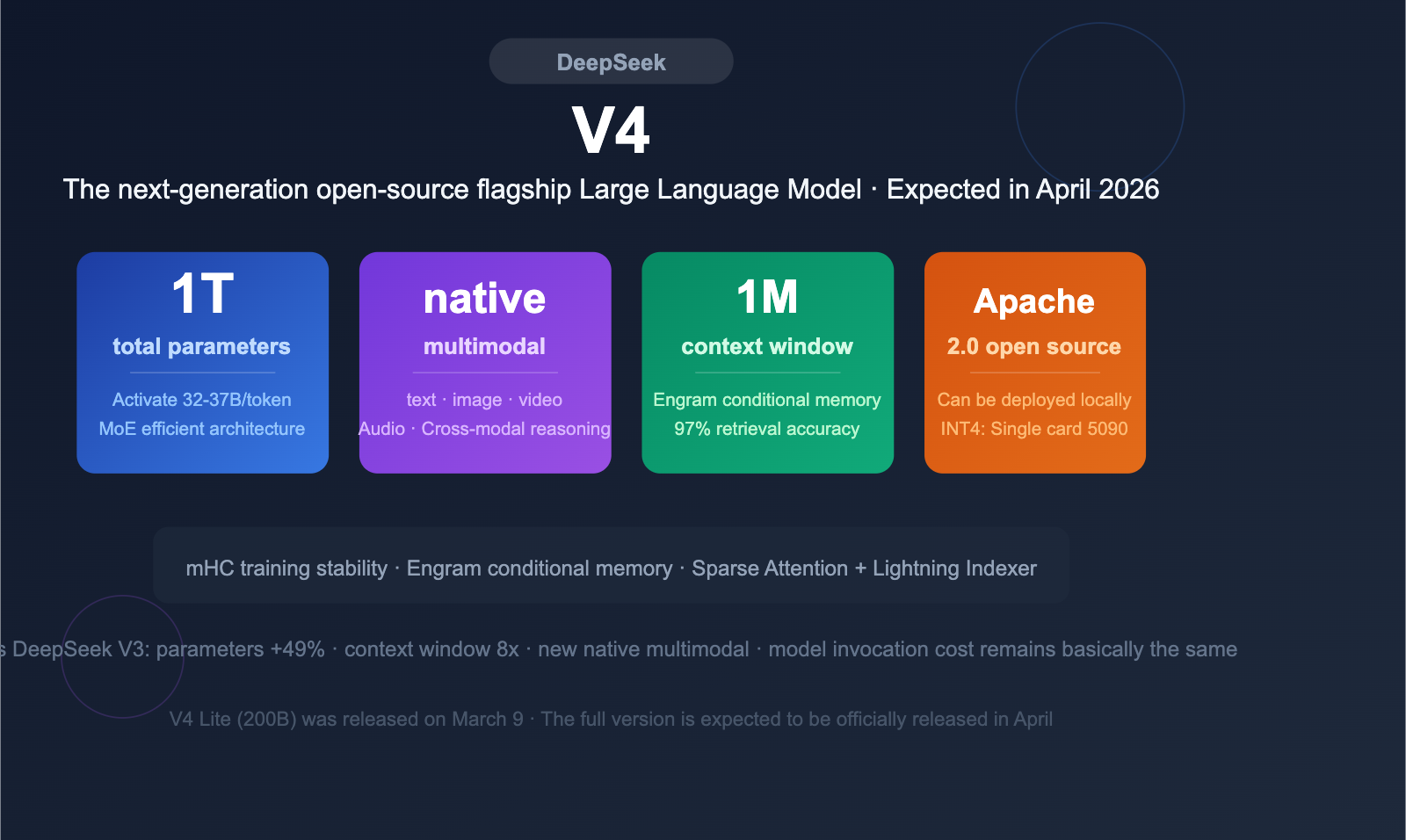
description: DeepSeek V4 is coming! Featuring a 1T parameter MoE architecture, native multimodal support, and a 1M token context window, it's set to challenge the industry's best.
DeepSeek V4 is on the horizon, featuring a massive 1 trillion (1T) parameter MoE architecture with native multimodal input support and a 1-million-token ultra-long context window. After several delays, this highly anticipated open-source Large Language Model is expected to officially debut in April 2026, where it will go head-to-head with the GPT-5.x, Claude 4, and Gemini 3.x series.
Core Value: Spend 3 minutes getting up to speed on DeepSeek V4’s architectural innovations, key parameters, multimodal capabilities, and its potential impact on the developer ecosystem.
DeepSeek V4 Quick Overview
DeepSeek V4 is the next-generation flagship Large Language Model from DeepSeek. Based on publicly available information, V4 represents a generational leap in parameter scale, architectural design, and multimodal capabilities.
| Feature | DeepSeek V4 |
|---|---|
| Expected Release | April 2026 |
| Total Parameters | ~1 Trillion (1T) |
| Active Parameters per Token | ~32-37B |
| Architecture | Transformer MoE + MLA (Multi-head Latent Attention) |
| Expert Routing | 16 experts activated per token |
| Context Window | 1 Million (1M) tokens |
| Multimodal | Native support for text, image, video, and audio input |
| Open Source License | Apache 2.0 (expected) |
DeepSeek V4 vs. V3: Key Parameter Comparison
The core upgrades in DeepSeek V4 compared to V3 are clear:
| Dimension | DeepSeek V3 | DeepSeek V4 | Change |
|---|---|---|---|
| Total Parameters | 671B | ~1T | +49% |
| Active Parameters | 37B | ~32-37B | Stable (Efficiency-focused) |
| Context Window | 128K | 1M | 8x Expansion |
| Multimodal | Text only | Text+Image+Video+Audio | Full-modal upgrade |
| Attention Mechanism | MLA | MLA + Engram conditional memory | Long-context optimization |
| Training Stability | Standard | mHC (Manifold-constrained Hyper-connection) | Architectural innovation |
Key Takeaway: While increasing the total parameter count by 49%, V4 maintains roughly the same number of active parameters per token (~32-37B). This means that while inference costs shouldn't skyrocket, the model's knowledge capacity and generalization capabilities will be significantly enhanced.
🎯 Technical Tip: Once DeepSeek V4 is released, developers can immediately access and test it via the APIYI (apiyi.com) platform. The platform already supports the full range of models including DeepSeek V3 and R1, and will quickly adapt to support V4 upon launch.
DeepSeek V4 Architectural Innovations: 3 Key Technical Breakthroughs
DeepSeek V4 isn't just about scaling up parameters; it introduces three critical architectural innovations that solve the core challenges of training and inferencing trillion-parameter models.
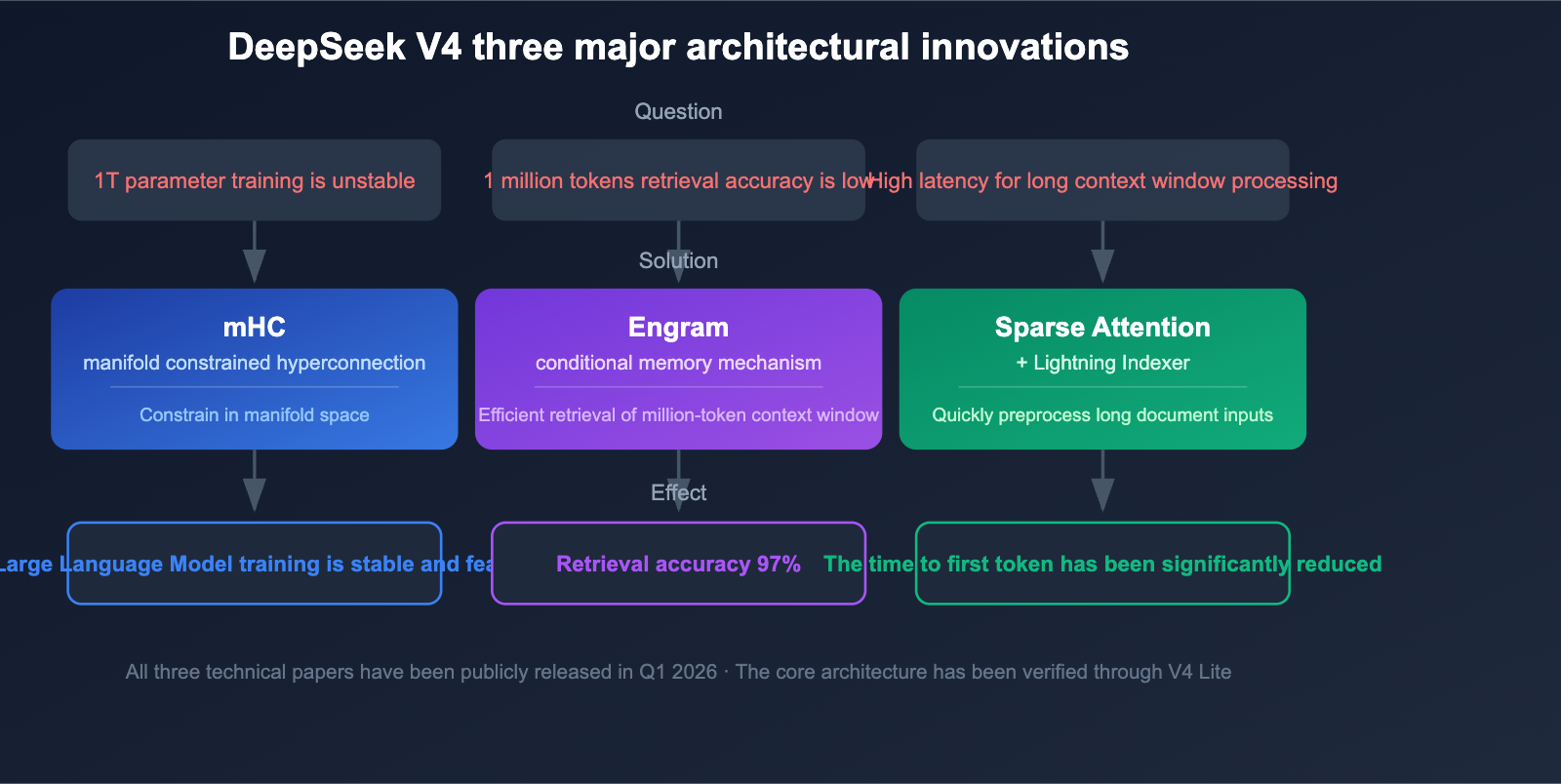
Innovation 1: Manifold-Constrained Hyper-Connections (mHC)
DeepSeek published the technical paper on Manifold-Constrained Hyper-Connections (mHC) on January 13, 2026. This technology is specifically designed to address training stability issues in trillion-parameter MoE models.
Traditional large-scale MoE models often suffer from gradient explosion and expert load imbalance during training. By constraining hyper-connections within the manifold space, mHC significantly improves training stability, making the training of 1T-parameter models feasible.
Innovation 2: Engram Conditional Memory
Engram Conditional Memory is the core technology that enables DeepSeek V4 to achieve a 1-million-token context window. Traditional attention mechanisms face dual challenges of efficiency and accuracy when dealing with ultra-long contexts.
| Metric | Standard Attention | Engram Conditional Memory |
|---|---|---|
| Needle-in-a-Haystack Accuracy | 84.2% | 97% |
| Long Context Retrieval | Significant performance drop | Consistent throughout |
| Computational Overhead | O(n²) | Significantly reduced |
A 97% Needle-in-a-Haystack accuracy means the model can precisely locate and extract key information even within a 1-million-token text.
Innovation 3: Sparse Attention + Lightning Indexer
DeepSeek's Sparse Attention, combined with the Lightning Indexer preprocessing engine, enables high-speed processing of ultra-long contexts. This technology eliminates the need for lengthy preprocessing times for 1-million-token inputs, drastically reducing the initial response latency for long-document analysis.
DeepSeek V4 Native Multimodal Capabilities Explained
One of the biggest changes in DeepSeek V4 is its transition from a text-only model to a native multimodal model. Unlike "late-fusion" multimodal approaches, V4 integrates multimodal capabilities directly into the pre-training phase.
Multimodal Input Support
| Modality | Support Status | Notes |
|---|---|---|
| Text | ✅ Native | Continues the powerful text capabilities of V3 |
| Image | ✅ Native | Integrated during pre-training, not a late-fusion add-on |
| Video | ✅ Native | Cross-frame understanding and analysis |
| Audio | ✅ Native | Speech and sound understanding |
| Cross-modal Reasoning | ✅ Native | Comprehensive analysis of multimodal information |
Native Multimodal vs. Late-Fusion
Native multimodal (integrated during pre-training) offers significant advantages over late-fusion schemes:
- Deeper Cross-modal Understanding: The model learns the correlations between different modalities during training.
- Stronger Reasoning Consistency: Text, image, and video information can seamlessly participate in the same reasoning chain.
- Lower Hallucination Rate: Multimodal information cross-validates, reducing hallucinations from a single modality.
- Lower Latency: No extra modality conversion steps required.
💡 Recommendation: DeepSeek V4's native multimodal capabilities make it ideal for scenarios requiring comprehensive analysis of diverse information sources. We recommend accessing it via the APIYI (apiyi.com) platform to unify your integrations and compare the real-world performance of DeepSeek V4 against other multimodal models under the same interface.
DeepSeek V4 Release Timeline and Background on Delays
The release of DeepSeek V4 has faced several delays. Understanding this history helps clarify the technical challenges V4 encountered and the maturity of the final product.
Release Timeline
| Date | Event |
|---|---|
| Early Jan 2026 | V4-related discussions appear in the Reddit community |
| Jan 13, 2026 | mHC technical paper published, architectural innovations revealed |
| Jan 20, 2026 | GitHub code leak, 28 references to internal codename "MODEL1" found |
| Late Jan 2026 | First expected release window, missed |
| Feb 11, 2026 | 1 million tokens context window capability confirmed |
| Mid-Feb 2026 | Benchmark data leaked |
| Late Feb 2026 | Post-Spring Festival release window, delayed again |
| Mar 9, 2026 | V4 Lite released (~200B parameters, core architecture verified) |
| Apr 2026 | Full version of V4 expected release |
Core Reasons for Delays
The primary reasons for the multiple V4 delays stem from challenges in training infrastructure:
- Hardware Adaptation Issues: Training a trillion-parameter model on domestic chips faces significant stability challenges.
- Chip Interconnect Bandwidth: Large-scale distributed training places extreme demands on inter-chip communication bandwidth.
- Software Ecosystem Maturity: Training frameworks and optimization toolchains are still in the iteration phase.
It’s worth noting that V4 Lite (approx. 200B parameters) was released early on March 9th as an architectural validation version for the full V4. This move indicates that the core architecture has been verified, and the delay of the full version is primarily due to engineering challenges related to large-scale training.
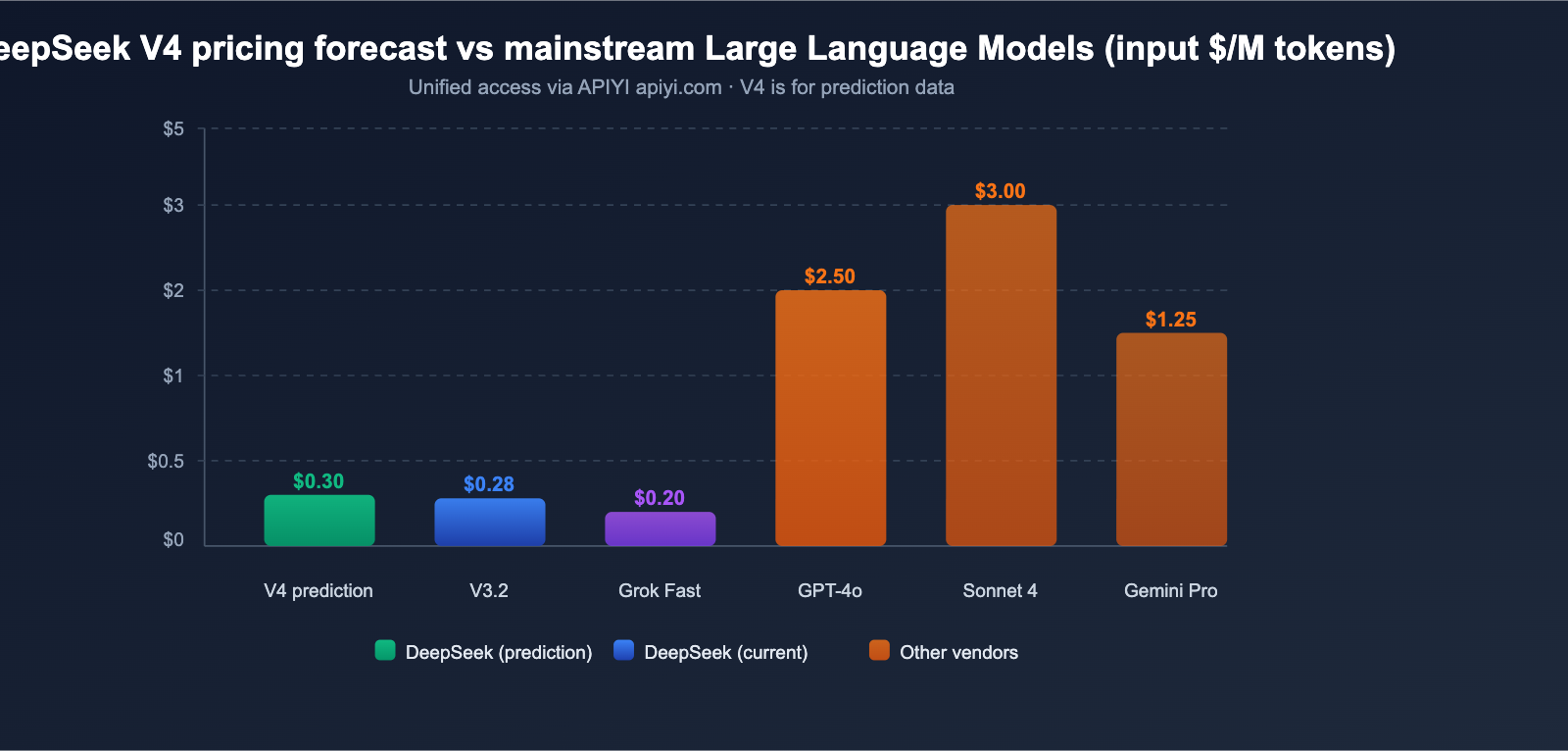
DeepSeek V4 API Pricing Forecast
Based on DeepSeek's consistent pricing strategy and the architectural characteristics of V4, we can make reasonable predictions about its API pricing.
Current DeepSeek API Pricing
| Model | Input (Cache Miss) | Input (Cache Hit) | Output | Context Window |
|---|---|---|---|---|
| deepseek-chat (V3.2) | $0.28/M | $0.028/M | $0.42/M | 128K |
| deepseek-reasoner (V3.2) | $0.28/M | $0.028/M | $0.42/M | 128K |
DeepSeek V4 Pricing Forecast
Synthesizing analysis from multiple sources, V4 pricing is expected to fall within these ranges:
| Forecast Scenario | Input Price | Output Price | Basis |
|---|---|---|---|
| Optimistic | ~$0.14/M | ~$0.28/M | Active parameters unchanged, efficiency gains |
| Neutral | ~$0.30/M | ~$0.50/M | 1M context window adds extra compute costs |
| Conservative | ~$0.50/M | ~$0.80/M | Multimodal processing increases overhead |
Even with the conservative forecast, an input price of $0.50/M is highly competitive for a trillion-parameter multimodal model. For comparison, GPT-4o's input price is $2.50/M, and Claude Opus 4 is $15.00/M.
💰 Cost Optimization: The DeepSeek series has always been known for its extreme cost-effectiveness. Through the APIYI (apiyi.com) platform, developers can use a unified interface to call DeepSeek and other mainstream models simultaneously, finding the perfect balance between cost and performance.
DeepSeek V4 Competitive Landscape Analysis
April 2026 is shaping up to be a busy month for Large Language Model releases. DeepSeek V4 is set to face competition from several directions.
Competitor Comparison
| Model | Vendor | Parameter Scale | Context Window | Multimodal | Open Source |
|---|---|---|---|---|---|
| DeepSeek V4 | DeepSeek | ~1T (MoE) | 1M | ✅ Native | ✅ Apache 2.0 |
| GPT-5.x | OpenAI | Undisclosed | Undisclosed | ✅ | ❌ |
| Claude 4 Series | Anthropic | Undisclosed | 1M | ✅ | ❌ |
| Gemini 3.x | Undisclosed | 2M | ✅ | ❌ | |
| Grok 4.x | xAI | Undisclosed | 2M | ✅ | ❌ |
DeepSeek V4's Differentiating Advantages
- Open Source: Expected to use the Apache 2.0 license, which is nearly unique for a model at the trillion-parameter scale.
- Extreme Cost-Effectiveness: DeepSeek’s pricing strategy has consistently been the lowest among models in its class.
- Local Deployment Potential: Being open source means enterprises can deploy it on their own infrastructure.
- MoE Efficiency: With only 32-37B active parameters, its inference efficiency is far superior to dense models of the same size.
DeepSeek V4 Local Deployment Hardware Requirements
For teams looking to deploy locally, here are the hardware requirements for V4:
| Quantization | Required VRAM | Recommended Hardware |
|---|---|---|
| FP16/BF16 (Full Precision) | Massive | Multi-node GPU cluster |
| INT8 (8-bit) | ~48GB | Dual RTX 4090 |
| INT4 (4-bit) | ~32GB | Single RTX 5090 |
After INT4 quantization, it can run on a single RTX 5090, making local deployment accessible for small teams and researchers.
DeepSeek Model Evolution
Understanding the complete product evolution of DeepSeek helps clarify the positioning and technical roadmap of V4.

| Version | Release Date | Key Features |
|---|---|---|
| V1 | Nov 2023 | First open-source model |
| V2 | May 2024 | MoE architecture introduced, significant cost reduction |
| V2.5 | Sep 2024 | Enhanced chat and coding capabilities |
| V3 | Dec 2024 | 671B parameters, MLA attention, 128K context window |
| R1 | Jan 2025 | Reasoning-focused model, chain-of-thought technology |
| V3.1 | Aug 2025 | Performance optimization, enhanced reasoning |
| V3.2 | Late 2025 | Current flagship model, supports Thinking mode |
| V4 Lite | Mar 2026 | ~200B parameters, architecture validation version |
| V4 | Apr 2026 (Est.) | ~1T MoE, native multimodal, 1M context window |
From the MoE architecture introduced in V2 to the MLA attention in V3, and the mHC and Engram technologies in V4, every generation of DeepSeek products has featured substantial architectural innovations.
🎯 Technical Advice: While waiting for the official V4 release, developers can start building with DeepSeek V3.2 and R1 via the APIYI (apiyi.com) platform. The platform will integrate V4 as soon as it launches.
FAQ
Q1: When will DeepSeek V4 be officially released?
According to various sources, DeepSeek V4 is expected to be released in April 2026. It has previously faced two delays, one at the end of January and another at the end of February. The V4 Lite (~200B parameters) released on March 9th has already validated the core architecture, making a full version release highly likely. You can get immediate access to the V4 API via the APIYI (apiyi.com) platform.
Q2: Does the 1T parameter count of DeepSeek V4 mean high inference costs?
Not necessarily. V4 utilizes a MoE architecture where only about 32-37B parameters are activated per token, which is roughly on par with V3. This means the actual computational load during inference won't increase significantly, and costs are expected to remain within a reasonable range. DeepSeek's pricing strategy has always been aggressive, so the API pricing for V4 is expected to remain highly competitive.
Q3: Will the DeepSeek R2 reasoning model still be released?
The release date for DeepSeek R2 remains unclear. Some analysts believe that R2's reasoning capabilities might be integrated directly into V4 (as V3.2 already supports Thinking mode). Others suggest that R2 is still in independent development but is facing training challenges. We recommend keeping an eye on official DeepSeek updates for the latest information.
Q4: What should developers do to prepare before the V4 release?
We recommend getting familiar with the DeepSeek API invocation methods in advance. V4 will likely be compatible with existing OpenAI-compatible interfaces, making migration very easy. You can use DeepSeek V3.2 via the APIYI (apiyi.com) platform for development and testing; once V4 goes live, you'll only need to switch the model name.
Summary
DeepSeek V4 is poised to be one of the most significant open-source Large Language Model releases of 2026. With its ~1T parameter MoE architecture, 1 million token context window, native multimodal support, Apache 2.0 open-source license, and extreme cost-effectiveness, V4 is highly anticipated for both its technical benchmarks and commercial value.
Key Takeaways:
- Architecture: ~1T parameter MoE, 32-37B active parameters per token, efficiency-first design.
- Context: 1 million tokens, achieving 97% retrieval accuracy via Engram conditional memory.
- Multimodal: Native support for text, image, video, and audio inputs.
- Innovation: mHC training stability + Engram conditional memory + sparse attention.
- Open Source: Expected Apache 2.0, with INT4 quantization capable of running on a single RTX 5090.
- Pricing: Expected to maintain DeepSeek's signature extreme cost-effectiveness.
We recommend using APIYI (apiyi.com) for unified access to the entire DeepSeek model series and to get immediate API access as soon as V4 is released.
References
- Dataconomy – DeepSeek V4 Launch Report:
dataconomy.com/2026/03/16/deepseek-v4-and-tencents-new-hunyuan-model-to-launch-in-april/ - NxCode – DeepSeek V4 Technical Specifications:
nxcode.io/resources/news/deepseek-v4-release-specs-benchmarks-2026 - DeepSeek Official Documentation:
platform.deepseek.com/docs
This article was written by the APIYI technical team. For more tutorials on using Large Language Models, please follow APIYI at apiyi.com.