DeepSeek V4 即将发布,采用约 1 万亿 (1T) 参数 MoE 架构,支持原生多模态输入和 100 万 tokens 超长上下文。在经历多次延期后,这款被广泛期待的开源大模型预计在 2026 年 4 月正式亮相,将与 GPT-5.x、Claude 4 系列、Gemini 3.x 同台竞技。
核心价值: 3 分钟了解 DeepSeek V4 的架构创新、关键参数、多模态能力,以及它对开发者生态的潜在影响。

DeepSeek V4 核心信息速览
DeepSeek V4 是深度求索 (DeepSeek) 计划推出的下一代旗舰大模型。从已公开的信息来看,V4 在参数规模、架构设计、多模态能力等多个维度实现了代际跃升。
| 信息项 | DeepSeek V4 |
|---|---|
| 预计发布 | 2026 年 4 月 |
| 总参数量 | 约 1 万亿 (1T) |
| 每 token 激活参数 | 约 32-37B |
| 架构 | Transformer MoE + MLA (多头潜注意力) |
| 专家路由 | 每 token 激活 16 个专家 |
| 上下文窗口 | 100 万 tokens (1M) |
| 多模态 | 原生支持文本、图像、视频、音频输入 |
| 开源协议 | Apache 2.0 (预计) |
DeepSeek V4 vs V3 关键参数对比
DeepSeek V4 相比 V3 的核心升级一目了然:
| 维度 | DeepSeek V3 | DeepSeek V4 | 变化 |
|---|---|---|---|
| 总参数 | 671B | ~1T | +49% |
| 激活参数 | 37B | ~32-37B | 持平,效率优先 |
| 上下文窗口 | 128K | 1M | 8 倍扩展 |
| 多模态 | 仅文本 | 文本+图像+视频+音频 | 全模态升级 |
| 注意力机制 | MLA | MLA + Engram 条件记忆 | 长上下文优化 |
| 训练稳定性 | 标准 | mHC (流形约束超连接) | 架构创新 |
关键发现: V4 在总参数量增加 49% 的同时,保持了每 token 激活参数基本不变 (约 32-37B),这意味着推理成本不会大幅上升,但模型知识容量和泛化能力显著增强。
🎯 技术建议: DeepSeek V4 发布后,开发者可以第一时间通过 API易 apiyi.com 平台接入测试。该平台已支持 DeepSeek V3、R1 等全系列模型,V4 上线后将快速适配。
DeepSeek V4 架构创新 3 大技术突破
DeepSeek V4 不仅仅是参数规模的提升,更引入了 3 项关键架构创新,解决了万亿参数模型训练和推理的核心难题。

创新 1: 流形约束超连接 (mHC)
DeepSeek 于 2026 年 1 月 13 日公开发表了 Manifold-Constrained Hyper-Connections (mHC) 技术论文。这项技术专门解决万亿参数 MoE 模型的训练稳定性问题。
传统的大规模 MoE 模型在训练过程中容易出现梯度爆炸和专家负载不均衡等问题。mHC 通过在流形空间中约束超连接,显著提高了训练过程的稳定性,使 1T 参数级别的模型训练变得可行。
创新 2: Engram 条件记忆
Engram 条件记忆是 DeepSeek V4 实现 100 万 tokens 上下文的核心技术。传统注意力机制在超长上下文中面临效率和准确性的双重挑战。
| 指标 | 标准注意力 | Engram 条件记忆 |
|---|---|---|
| Needle-in-a-Haystack 准确率 | 84.2% | 97% |
| 长上下文检索 | 性能衰减明显 | 全程一致 |
| 计算开销 | O(n²) | 优化后显著降低 |
97% 的 Needle-in-a-Haystack 准确率意味着,即使在 100 万 tokens 的超长文本中,模型也能精准定位和提取关键信息。
创新 3: 稀疏注意力 + Lightning Indexer
DeepSeek Sparse Attention 配合 Lightning Indexer 预处理引擎,实现了对超长上下文的高速处理。这项技术使得 100 万 tokens 的输入不再需要漫长的预处理时间,大幅降低了长文档分析的首次响应延迟。
DeepSeek V4 原生多模态能力解析
DeepSeek V4 最大的变化之一是从纯文本模型升级为原生多模态模型。与后期拼接的多模态方案不同,V4 在预训练阶段就集成了多模态能力。
多模态输入支持
| 模态 | 支持情况 | 说明 |
|---|---|---|
| 文本 | ✅ 原生支持 | 延续 V3 的强大文本能力 |
| 图像 | ✅ 原生支持 | 预训练集成,非后期拼接 |
| 视频 | ✅ 原生支持 | 跨帧理解和分析 |
| 音频 | ✅ 原生支持 | 语音和声音理解 |
| 跨模态推理 | ✅ 原生支持 | 多模态信息综合分析 |
原生多模态 vs 后期拼接
原生多模态 (在预训练阶段集成) 相比后期拼接方案有显著优势:
- 跨模态理解更深: 模型在训练时就学会了不同模态间的关联
- 推理一致性更强: 文本、图像、视频信息可以无缝参与同一推理链
- 幻觉率更低: 多模态信息相互验证,减少单一模态的幻觉
- 延迟更低: 无需额外的模态转换步骤
💡 选择建议: DeepSeek V4 的原生多模态能力使其适合需要综合分析多种信息源的场景。建议通过 API易 apiyi.com 平台统一接入,在同一接口下对比 DeepSeek V4 和其他多模态模型的实际表现。
DeepSeek V4 发布时间线与延期背景
DeepSeek V4 的发布经历了多次延期。了解这段历史有助于理解 V4 面临的技术挑战和最终产品的成熟度。
发布时间线
| 时间 | 事件 |
|---|---|
| 2026 年 1 月初 | Reddit 社区出现 V4 相关讨论 |
| 2026 年 1 月 13 日 | mHC 技术论文发表,架构创新曝光 |
| 2026 年 1 月 20 日 | GitHub 代码泄露,出现 28 处 "MODEL1" 内部代号引用 |
| 2026 年 1 月底 | 第一个预期发布窗口,未能如期 |
| 2026 年 2 月 11 日 | 100 万 tokens 上下文能力被确认 |
| 2026 年 2 月中旬 | 基准测试数据泄露 |
| 2026 年 2 月底 | 春节后发布窗口,再次延期 |
| 2026 年 3 月 9 日 | V4 Lite 发布 (~200B 参数,验证核心架构) |
| 2026 年 4 月 | V4 完整版预计发布 |
延期核心原因
V4 多次延期的主要原因是训练基础设施的挑战:
- 硬件适配问题: 在国产芯片上进行万亿参数训练面临稳定性挑战
- 芯片互联带宽: 大规模分布式训练对芯片间通信带宽要求极高
- 软件生态成熟度: 训练框架和优化工具链仍在迭代中
值得注意的是,V4 Lite (约 200B 参数) 已于 3 月 9 日提前发布,作为完整 V4 的架构验证版本。这一举措表明核心架构已经过验证,完整版的延期主要是规模化训练的工程问题。
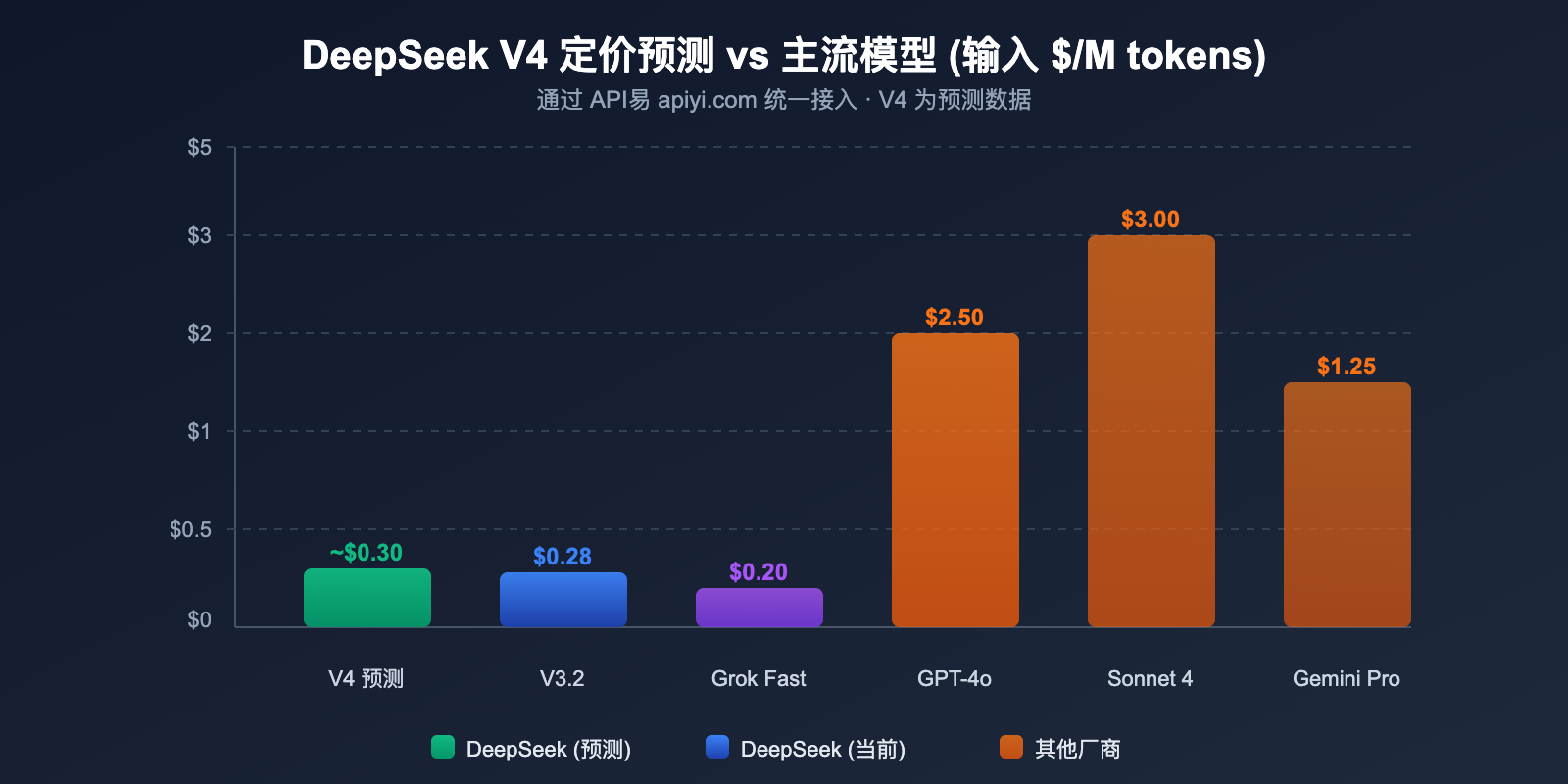
DeepSeek V4 API 定价预测
基于 DeepSeek 一贯的定价策略和 V4 的架构特点,我们可以对 V4 的 API 定价进行合理预测。
当前 DeepSeek API 定价
| 模型 | 输入 (缓存未命中) | 输入 (缓存命中) | 输出 | 上下文 |
|---|---|---|---|---|
| deepseek-chat (V3.2) | $0.28/M | $0.028/M | $0.42/M | 128K |
| deepseek-reasoner (V3.2) | $0.28/M | $0.028/M | $0.42/M | 128K |
DeepSeek V4 定价预测
综合多个来源的分析,V4 的定价预计在以下区间:
| 预测场景 | 输入价格 | 输出价格 | 依据 |
|---|---|---|---|
| 乐观预测 | ~$0.14/M | ~$0.28/M | 激活参数不变,效率提升 |
| 中性预测 | ~$0.30/M | ~$0.50/M | 1M 上下文带来额外计算成本 |
| 保守预测 | ~$0.50/M | ~$0.80/M | 多模态处理增加开销 |
即使按保守预测,$0.50/M 的输入价格在万亿参数多模态模型中也极具竞争力。作为对比,GPT-4o 的输入价格为 $2.50/M,Claude Opus 4 为 $15.00/M。
💰 成本优化: DeepSeek 系列一直以极致性价比著称。通过 API易 apiyi.com 平台,开发者可以用统一接口同时调用 DeepSeek 和其他主流模型,在成本和效果之间找到最佳平衡。
DeepSeek V4 竞争格局分析
2026 年 4 月是 AI 大模型的密集发布期。DeepSeek V4 将面对来自多个方向的竞争。
同期竞品对比
| 模型 | 厂商 | 参数规模 | 上下文 | 多模态 | 开源 |
|---|---|---|---|---|---|
| DeepSeek V4 | DeepSeek | ~1T (MoE) | 1M | ✅ 原生 | ✅ Apache 2.0 |
| GPT-5.x | OpenAI | 未公开 | 未公开 | ✅ | ❌ |
| Claude 4 系列 | Anthropic | 未公开 | 1M | ✅ | ❌ |
| Gemini 3.x | 未公开 | 2M | ✅ | ❌ | |
| Grok 4.x | xAI | 未公开 | 2M | ✅ | ❌ |
DeepSeek V4 的差异化优势
- 开源: 预计采用 Apache 2.0 协议,这在万亿参数级别的模型中几乎是独一无二的
- 极致性价比: DeepSeek 的定价策略一直是同级别模型中最低的
- 本地部署可能: 开源意味着企业可以在自有基础设施上部署
- MoE 效率: 激活参数仅 32-37B,推理效率远高于同参数量的稠密模型
DeepSeek V4 本地部署硬件需求
对于希望本地部署的团队,V4 的硬件需求如下:
| 量化方式 | 所需 VRAM | 推荐硬件 |
|---|---|---|
| FP16/BF16 (全精度) | 极大 | 多节点 GPU 集群 |
| INT8 (8位量化) | ~48GB | 双 RTX 4090 |
| INT4 (4位量化) | ~32GB | 单 RTX 5090 |
INT4 量化后仅需单张 RTX 5090 即可运行,这使得中小团队和研究人员的本地部署成为可能。
DeepSeek 模型版本演进
了解 DeepSeek 的完整产品演进有助于理解 V4 的定位和技术路线。
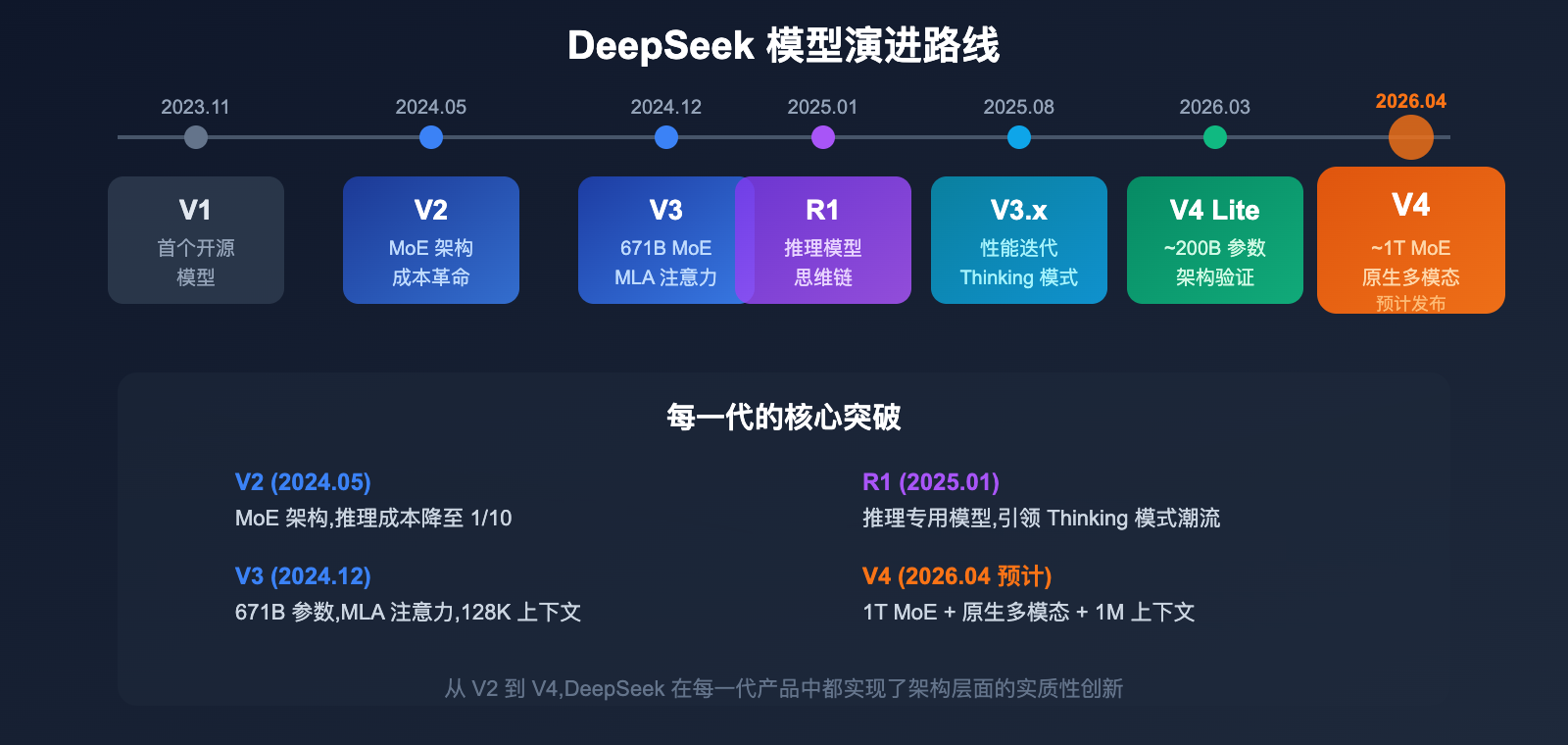
| 版本 | 发布时间 | 核心特点 |
|---|---|---|
| V1 | 2023 年 11 月 | 首个开源模型 |
| V2 | 2024 年 5 月 | MoE 架构引入,成本大幅降低 |
| V2.5 | 2024 年 9 月 | 对话和代码能力增强 |
| V3 | 2024 年 12 月 | 671B 参数,MLA 注意力,128K 上下文 |
| R1 | 2025 年 1 月 | 推理专用模型,思维链技术 |
| V3.1 | 2025 年 8 月 | 性能优化,推理增强 |
| V3.2 | 2025 年底 | 当前主力模型,支持 Thinking 模式 |
| V4 Lite | 2026 年 3 月 | ~200B 参数,架构验证版 |
| V4 | 2026 年 4 月 (预计) | ~1T MoE,原生多模态,1M 上下文 |
从 V2 引入 MoE 架构,到 V3 的 MLA 注意力,再到 V4 的 mHC 和 Engram 技术,DeepSeek 的每一代产品都在架构层面有实质性创新。
🎯 技术建议: 在等待 V4 正式发布期间,开发者可以先通过 API易 apiyi.com 平台使用 DeepSeek V3.2 和 R1 进行开发。V4 发布后平台将第一时间接入。
常见问题
Q1: DeepSeek V4 什么时候正式发布?
根据多方信息汇总,DeepSeek V4 预计在 2026 年 4 月发布。此前已经历了 1 月底和 2 月底两次延期。3 月 9 日发布的 V4 Lite (~200B 参数) 验证了核心架构可行性,完整版发布的可能性较高。通过 API易 apiyi.com 平台可以第一时间获取 V4 API 接入。
Q2: DeepSeek V4 的 1T 参数是否意味着推理成本很高?
不一定。V4 采用 MoE 架构,每个 token 仅激活约 32-37B 参数,与 V3 基本持平。这意味着推理时的实际计算量不会大幅增加,成本也有望保持在合理范围。DeepSeek 的定价策略一贯激进,V4 的 API 价格预计仍将极具竞争力。
Q3: DeepSeek R2 推理模型还会发布吗?
DeepSeek R2 的发布时间目前仍不明确。部分分析认为 R2 的推理能力可能被直接整合进 V4 (V3.2 已支持 Thinking 模式)。也有观点认为 R2 仍在独立开发中,但面临训练挑战。建议关注 DeepSeek 官方动态获取最新信息。
Q4: V4 发布前,开发者应该做什么准备?
建议提前熟悉 DeepSeek API 的调用方式。V4 大概率兼容现有的 OpenAI 兼容接口,迁移成本很低。通过 API易 apiyi.com 平台使用 DeepSeek V3.2 进行开发和测试,V4 上线后只需切换模型名称即可。
总结
DeepSeek V4 有望成为 2026 年最重要的开源大模型发布之一。约 1T 参数的 MoE 架构、100 万 tokens 超长上下文、原生多模态支持,加上 Apache 2.0 开源协议和极致的性价比,V4 在技术指标和商业价值上都值得期待。
核心要点回顾:
- 架构: ~1T 参数 MoE,每 token 激活 32-37B,效率优先
- 上下文: 100 万 tokens,Engram 条件记忆实现 97% 检索准确率
- 多模态: 原生支持文本、图像、视频、音频输入
- 创新: mHC 训练稳定性 + Engram 条件记忆 + 稀疏注意力
- 开源: 预计 Apache 2.0,INT4 量化可在单张 RTX 5090 运行
- 定价: 预计保持 DeepSeek 一贯的极致性价比
推荐通过 API易 apiyi.com 统一接入 DeepSeek 全系列模型,V4 发布后第一时间获取 API 访问。
参考资料
- Dataconomy – DeepSeek V4 发布报道:
dataconomy.com/2026/03/16/deepseek-v4-and-tencents-new-hunyuan-model-to-launch-in-april/ - NxCode – DeepSeek V4 技术规格:
nxcode.io/resources/news/deepseek-v4-release-specs-benchmarks-2026 - DeepSeek 官方文档:
platform.deepseek.com/docs
本文由 APIYI Team 技术团队撰写,更多 AI 模型使用教程请关注 API易 apiyi.com