إليك ترجمة المحتوى إلى اللغة العربية:
يستعد نموذج DeepSeek V4 للإطلاق قريبًا، حيث يعتمد بنية MoE بمعلمات تصل إلى تريليون (1T) تقريبًا، مع دعم أصلي للمدخلات متعددة الوسائط ونافذة سياق فائقة الطول تصل إلى مليون رمز (tokens). بعد عدة تأجيلات، من المتوقع أن يظهر هذا النموذج اللغوي الكبير مفتوح المصدر -الذي يحظى بترقب واسع- رسميًا في أبريل 2026، لينافس مباشرة سلاسل GPT-5.x وClaude 4 وGemini 3.x.
القيمة الجوهرية: تعرف في 3 دقائق على الابتكارات المعمارية لنموذج DeepSeek V4، ومعلماته الرئيسية، وقدراته متعددة الوسائط، وتأثيره المحتمل على بيئة المطورين.

نظرة سريعة على المعلومات الجوهرية لـ DeepSeek V4
يُعد DeepSeek V4 الجيل القادم من نماذج اللغة الكبيرة الرائدة التي تخطط شركة DeepSeek لإطلاقها. واستنادًا إلى المعلومات المتاحة، حقق الإصدار V4 قفزة نوعية في أبعاد متعددة تشمل حجم المعلمات، وتصميم البنية، والقدرات متعددة الوسائط.
| عنصر المعلومات | DeepSeek V4 |
|---|---|
| تاريخ الإطلاق المتوقع | أبريل 2026 |
| إجمالي عدد المعلمات | حوالي 1 تريليون (1T) |
| المعلمات النشطة لكل رمز | حوالي 32-37 مليار |
| البنية | Transformer MoE + MLA (انتباه كامن متعدد الرؤوس) |
| توجيه الخبراء | 16 خبيرًا نشطًا لكل رمز |
| نافذة السياق | 1 مليون رمز (1M) |
| متعدد الوسائط | دعم أصلي لمدخلات النصوص، الصور، الفيديو، والصوت |
| رخصة المصدر المفتوح | Apache 2.0 (متوقع) |
مقارنة المعلمات الرئيسية بين DeepSeek V4 و V3
تتضح الترقيات الجوهرية في DeepSeek V4 مقارنة بـ V3 كالتالي:
| البعد | DeepSeek V3 | DeepSeek V4 | التغير |
|---|---|---|---|
| إجمالي المعلمات | 671 مليار | ~1 تريليون | +49% |
| المعلمات النشطة | 37 مليار | ~32-37 مليار | ثابتة، الأولوية للكفاءة |
| نافذة السياق | 128 ألف | 1 مليون | توسع 8 أضعاف |
| متعدد الوسائط | نصوص فقط | نصوص + صور + فيديو + صوت | ترقية شاملة للوسائط |
| آلية الانتباه | MLA | MLA + ذاكرة شرطية Engram | تحسين للسياق الطويل |
| استقرار التدريب | قياسي | mHC (اتصال فائق مقيد بالمتشعب) | ابتكار معماري |
اكتشاف رئيسي: بينما زاد إجمالي عدد المعلمات في V4 بنسبة 49%، حافظ النموذج على ثبات عدد المعلمات النشطة لكل رمز (حوالي 32-37 مليار)، مما يعني أن تكلفة الاستدلال لن ترتفع بشكل كبير، بينما ستتحسن سعة معرفة النموذج وقدراته على التعميم بشكل ملحوظ.
🎯 نصيحة تقنية: بمجرد إطلاق DeepSeek V4، يمكن للمطورين اختباره فورًا عبر منصة APIYI (apiyi.com). تدعم المنصة بالفعل سلسلة نماذج DeepSeek V3 وR1 بالكامل، وستقوم بتوفير الدعم لـ V4 بسرعة فور إطلاقه.
الابتكارات الثلاثة الرئيسية في بنية DeepSeek V4
لا يقتصر DeepSeek V4 على زيادة حجم المعلمات فحسب، بل قدم 3 ابتكارات معمارية رئيسية حلت التحديات الجوهرية في تدريب واستنتاج النماذج التي تضم تريليونات المعلمات.

الابتكار 1: التوصيلات الفائقة المقيدة بالمتشعب (mHC)
نشرت DeepSeek في 13 يناير 2026 ورقة بحثية حول تقنية "التوصيلات الفائقة المقيدة بالمتشعب" (mHC). تعالج هذه التقنية بشكل خاص مشكلة استقرار تدريب نماذج MoE ذات التريليونات من المعلمات.
في نماذج MoE واسعة النطاق التقليدية، تظهر بسهولة مشاكل مثل انفجار التدرج وعدم توازن حمل الخبراء أثناء التدريب. ومن خلال تقييد التوصيلات الفائقة في فضاء المتشعب، تعمل تقنية mHC على تحسين استقرار عملية التدريب بشكل ملحوظ، مما يجعل تدريب النماذج بمستوى 1 تريليون معلمة أمراً ممكناً.
الابتكار 2: ذاكرة Engram الشرطية
تعد ذاكرة Engram الشرطية التقنية الأساسية التي مكنت DeepSeek V4 من الوصول إلى نافذة سياق بحجم مليون رمز (token). تواجه آليات الانتباه التقليدية تحديات مزدوجة تتعلق بالكفاءة والدقة عند التعامل مع سياقات طويلة جداً.
| المؤشر | الانتباه القياسي | ذاكرة Engram الشرطية |
|---|---|---|
| دقة "إبرة في كومة قش" | 84.2% | 97% |
| استرجاع السياق الطويل | تدهور ملحوظ في الأداء | اتساق كامل |
| التكلفة الحسابية | O(n²) | انخفاض ملحوظ بعد التحسين |
تعني دقة 97% في اختبار "إبرة في كومة قش" أن النموذج قادر على تحديد واستخراج المعلومات الأساسية بدقة، حتى ضمن نصوص طويلة جداً تصل إلى مليون رمز.
الابتكار 3: الانتباه المتناثر + Lightning Indexer
من خلال الجمع بين "الانتباه المتناثر" (Sparse Attention) ومحرك المعالجة المسبقة Lightning Indexer، حقق DeepSeek معالجة فائقة السرعة للسياقات الطويلة جداً. هذه التقنية تجعل المدخلات التي تصل إلى مليون رمز لا تتطلب أوقات معالجة مسبقة طويلة، مما يقلل بشكل كبير من زمن الاستجابة الأول لتحليل المستندات الطويلة.
تحليل قدرات الوسائط المتعددة الأصلية في DeepSeek V4
يعد التحول من نموذج نصي بحت إلى نموذج متعدد الوسائط أصلي أحد أكبر التغييرات في DeepSeek V4. وعلى عكس حلول الوسائط المتعددة التي يتم دمجها في مراحل لاحقة، تم دمج قدرات الوسائط المتعددة في V4 مباشرة خلال مرحلة التدريب المسبق.
دعم إدخال الوسائط المتعددة
| النمط | حالة الدعم | ملاحظات |
|---|---|---|
| النص | ✅ دعم أصلي | استمرار للقدرات النصية القوية في V3 |
| الصور | ✅ دعم أصلي | مدمجة في التدريب المسبق، وليست إضافة لاحقة |
| الفيديو | ✅ دعم أصلي | فهم وتحليل عبر الإطارات |
| الصوت | ✅ دعم أصلي | فهم الكلام والأصوات |
| الاستدلال متعدد الوسائط | ✅ دعم أصلي | تحليل شامل لمعلومات الوسائط المتعددة |
الوسائط المتعددة الأصلية مقابل الحلول المدمجة لاحقاً
تتمتع الوسائط المتعددة الأصلية (المدمجة في مرحلة التدريب المسبق) بمزايا كبيرة مقارنة بحلول الدمج اللاحق:
- فهم أعمق عبر الوسائط: تعلم النموذج الارتباطات بين الأنماط المختلفة أثناء التدريب.
- اتساق أقوى في الاستدلال: يمكن للمعلومات النصية والصورية والمرئية المشاركة بسلاسة في نفس سلسلة الاستدلال.
- معدل هلوسة أقل: تعمل معلومات الوسائط المتعددة على التحقق المتبادل، مما يقلل من هلوسة النمط الواحد.
- زمن انتقال أقل: لا حاجة لخطوات إضافية لتحويل الأنماط.
💡 نصيحة للاختيار: تجعل قدرات الوسائط المتعددة الأصلية في DeepSeek V4 مناسبة للسيناريوهات التي تتطلب تحليلاً شاملاً لمصادر معلومات متنوعة. نوصي بالوصول الموحد عبر منصة APIYI (apiyi.com)، حيث يمكنك مقارنة الأداء الفعلي لنموذج DeepSeek V4 مع نماذج الوسائط المتعددة الأخرى تحت واجهة برمجة تطبيقات واحدة.
الجدول الزمني لإصدار DeepSeek V4 وخلفية التأجيل
شهد إصدار DeepSeek V4 تأجيلات متعددة. يساعد فهم هذا التاريخ في إدراك التحديات التقنية التي واجهها V4 ومدى نضج المنتج النهائي.
الجدول الزمني للإصدار
| التاريخ | الحدث |
|---|---|
| أوائل يناير 2026 | ظهور نقاشات حول V4 في مجتمع Reddit |
| 13 يناير 2026 | نشر ورقة بحثية حول تقنية mHC والكشف عن ابتكارات البنية |
| 20 يناير 2026 | تسريب كود GitHub، وظهور 28 إشارة للرمز الداخلي "MODEL1" |
| أواخر يناير 2026 | نافذة الإصدار المتوقعة الأولى، لم يتم الإطلاق |
| 11 فبراير 2026 | تأكيد قدرة نافذة السياق التي تصل إلى مليون رمز (tokens) |
| منتصف فبراير 2026 | تسريب بيانات اختبارات الأداء (Benchmarks) |
| أواخر فبراير 2026 | نافذة الإصدار بعد عطلة الربيع، تأجيل إضافي |
| 9 مارس 2026 | إصدار V4 Lite (حوالي 200 مليار معامل، للتحقق من البنية الأساسية) |
| أبريل 2026 | من المتوقع إصدار النسخة الكاملة من V4 |
الأسباب الرئيسية للتأجيل
تعود الأسباب الرئيسية لتأجيل V4 عدة مرات إلى تحديات البنية التحتية للتدريب:
- مشكلات توافق الأجهزة: مواجهة تحديات الاستقرار عند تدريب نموذج بمليارات المعاملات على رقائق محلية الصنع.
- عرض نطاق الربط بين الرقائق: يتطلب التدريب الموزع واسع النطاق عرض نطاق ترددي عالٍ جداً للاتصال بين الرقائق.
- نضج النظام البيئي للبرمجيات: لا تزال أطر التدريب وسلاسل أدوات التحسين في مرحلة التطور.
تجدر الإشارة إلى أن إصدار V4 Lite (حوالي 200 مليار معامل) قد تم إطلاقه مبكراً في 9 مارس كنسخة للتحقق من بنية V4 الكاملة. تشير هذه الخطوة إلى أن البنية الأساسية قد تم التحقق منها بالفعل، وأن تأجيل النسخة الكاملة يعود بشكل أساسي إلى مشكلات هندسية تتعلق بالتدريب على نطاق واسع.
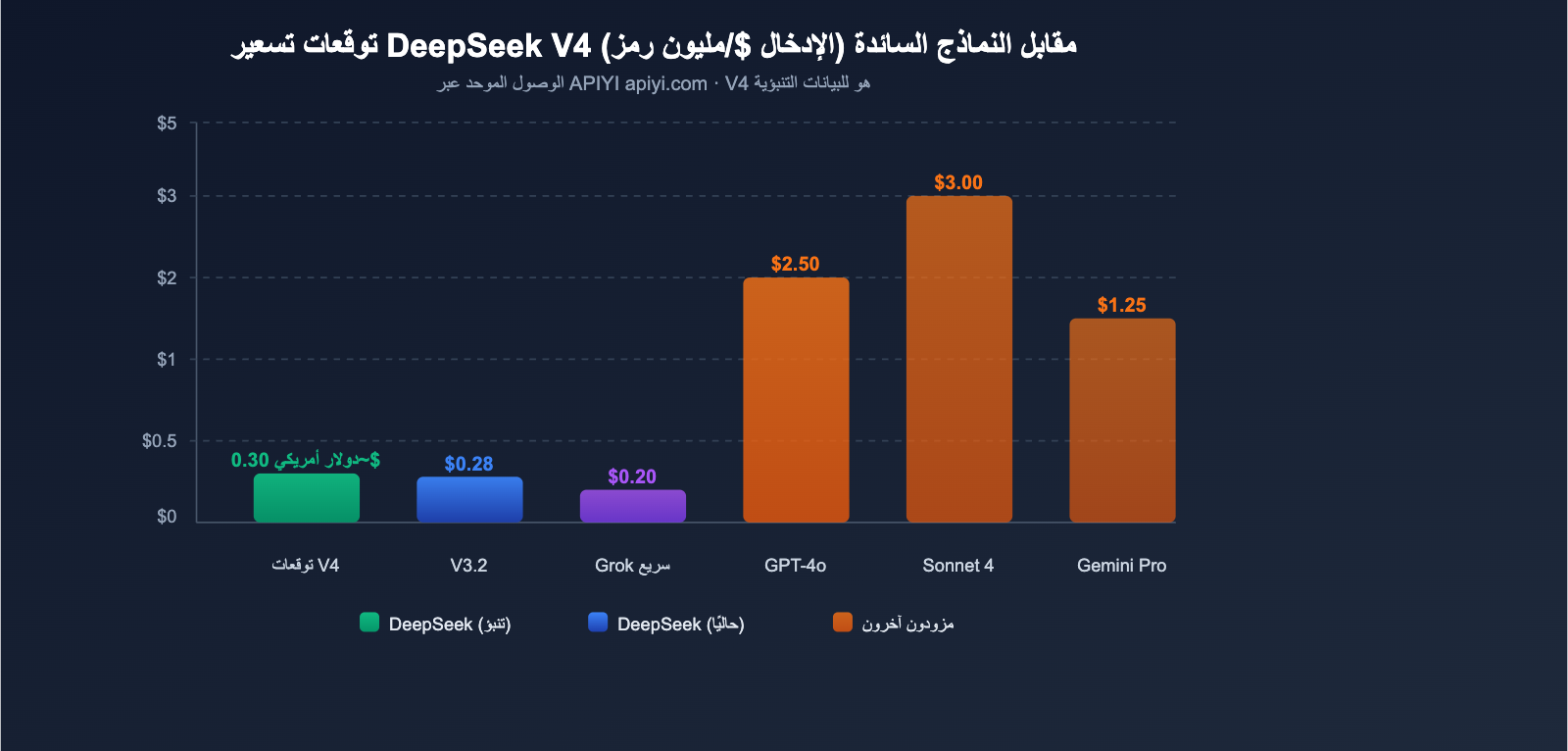
توقعات تسعير واجهة برمجة التطبيقات (API) لنموذج DeepSeek V4
بناءً على استراتيجية التسعير المتبعة من DeepSeek وخصائص بنية V4، يمكننا تقديم توقعات منطقية لتسعير واجهة برمجة التطبيقات (API) الخاصة بـ V4.
تسعير DeepSeek API الحالي
| النموذج | الإدخال (بدون تخزين مؤقت) | الإدخال (مع تخزين مؤقت) | الإخراج | نافذة السياق |
|---|---|---|---|---|
| deepseek-chat (V3.2) | $0.28/M | $0.028/M | $0.42/M | 128K |
| deepseek-reasoner (V3.2) | $0.28/M | $0.028/M | $0.42/M | 128K |
توقعات تسعير DeepSeek V4
بناءً على تحليل مصادر متعددة، من المتوقع أن يقع تسعير V4 ضمن النطاقات التالية:
| سيناريو التوقع | سعر الإدخال | سعر الإخراج | الأساس |
|---|---|---|---|
| توقع متفائل | ~$0.14/M | ~$0.28/M | ثبات المعلمات النشطة، تحسن الكفاءة |
| توقع محايد | ~$0.30/M | ~$0.50/M | تكاليف حسابية إضافية بسبب سياق 1M |
| توقع متحفظ | ~$0.50/M | ~$0.80/M | زيادة التكاليف بسبب المعالجة متعددة الوسائط |
حتى وفقاً للتوقعات المتحفظة، يظل سعر الإدخال البالغ $0.50/M تنافسياً للغاية بين النماذج متعددة الوسائط ذات التريليونات من المعلمات. للمقارنة، يبلغ سعر إدخال GPT-4o حوالي $2.50/M، بينما يصل سعر Claude Opus 4 إلى $15.00/M.
💰 تحسين التكلفة: تشتهر سلسلة DeepSeek دائماً بتقديم أفضل قيمة مقابل السعر. من خلال منصة APIYI (apiyi.com)، يمكن للمطورين استخدام واجهة موحدة لاستدعاء نماذج DeepSeek والنماذج الرئيسية الأخرى في وقت واحد، مما يساعد في تحقيق التوازن الأمثل بين التكلفة والأداء.
تحليل المشهد التنافسي لـ DeepSeek V4
يُعد شهر أبريل 2026 فترة حافلة بإصدارات نماذج اللغة الكبيرة. وسيواجه DeepSeek V4 منافسة شرسة من عدة جهات.
مقارنة مع المنافسين في نفس الفترة
| النموذج | الشركة المصنعة | حجم المعلمات | نافذة السياق | متعدد الوسائط | مفتوح المصدر |
|---|---|---|---|---|---|
| DeepSeek V4 | DeepSeek | ~1T (MoE) | 1M | ✅ أصلي | ✅ Apache 2.0 |
| GPT-5.x | OpenAI | غير معلن | غير معلن | ✅ | ❌ |
| سلسلة Claude 4 | Anthropic | غير معلن | 1M | ✅ | ❌ |
| Gemini 3.x | غير معلن | 2M | ✅ | ❌ | |
| Grok 4.x | xAI | غير معلن | 2M | ✅ | ❌ |
المزايا التنافسية لـ DeepSeek V4
- مفتوح المصدر: من المتوقع أن يعتمد ترخيص Apache 2.0، وهو أمر شبه فريد للنماذج التي تصل إلى تريليون معلمة.
- فعالية فائقة من حيث التكلفة: لطالما كانت استراتيجية التسعير الخاصة بـ DeepSeek هي الأقل بين النماذج من نفس الفئة.
- إمكانية النشر المحلي: كونه مفتوح المصدر يعني أن الشركات يمكنها نشره على بنيتها التحتية الخاصة.
- كفاءة MoE: تبلغ المعلمات النشطة 32-37 مليار فقط، مما يجعل كفاءة الاستدلال أعلى بكثير من النماذج الكثيفة ذات الحجم المماثل.
متطلبات الأجهزة للنشر المحلي لـ DeepSeek V4
بالنسبة للفرق التي تتطلع إلى النشر المحلي، فإن متطلبات الأجهزة لـ V4 هي كما يلي:
| طريقة التكميم (Quantization) | ذاكرة الفيديو (VRAM) المطلوبة | الأجهزة الموصى بها |
|---|---|---|
| FP16/BF16 (دقة كاملة) | ضخمة جداً | مجموعة GPU متعددة العقد |
| INT8 (تكميم 8 بت) | ~48 جيجابايت | بطاقتا RTX 4090 |
| INT4 (تكميم 4 بت) | ~32 جيجابايت | بطاقة RTX 5090 واحدة |
بعد التكميم إلى INT4، يمكن تشغيل النموذج باستخدام بطاقة RTX 5090 واحدة فقط، مما يجعل النشر المحلي متاحاً للفرق الصغيرة والمتوسطة والباحثين.
تطور إصدارات نموذج DeepSeek
يساعد فهم التطور الكامل لمنتجات DeepSeek في استيعاب موقع V4 وخارطة الطريق التقنية الخاصة به.

| الإصدار | تاريخ الإصدار | الخصائص الجوهرية |
|---|---|---|
| V1 | نوفمبر 2023 | أول نموذج مفتوح المصدر |
| V2 | مايو 2024 | إدخال بنية MoE، انخفاض كبير في التكلفة |
| V2.5 | سبتمبر 2024 | تعزيز قدرات الحوار والبرمجة |
| V3 | ديسمبر 2024 | 671B معلمة، انتباه MLA، نافذة سياق 128K |
| R1 | يناير 2025 | نموذج مخصص للاستدلال، تقنية سلسلة الأفكار |
| V3.1 | أغسطس 2025 | تحسين الأداء، تعزيز الاستدلال |
| V3.2 | نهاية 2025 | النموذج الرئيسي الحالي، يدعم وضع التفكير (Thinking) |
| V4 Lite | مارس 2026 | ~200B معلمة، نسخة للتحقق من البنية |
| V4 | أبريل 2026 (متوقع) | ~1T MoE، متعدد الوسائط أصلي، نافذة سياق 1M |
بدءاً من إدخال بنية MoE في V2، وصولاً إلى انتباه MLA في V3، وتقنيات mHC و Engram في V4، يقدم كل جيل من منتجات DeepSeek ابتكارات جوهرية على مستوى البنية.
🎯 نصيحة تقنية: في انتظار الإصدار الرسمي لـ V4، يمكن للمطورين البدء في التطوير باستخدام DeepSeek V3.2 و R1 عبر منصة APIYI (apiyi.com). ستدعم المنصة V4 فور إطلاقه.
الأسئلة الشائعة
س1: متى سيتم الإطلاق الرسمي لنموذج DeepSeek V4؟
وفقاً للمعلومات المجمعة من مصادر متعددة، من المتوقع إطلاق DeepSeek V4 في أبريل 2026. وقد شهد النموذج تأجيلين سابقين في نهاية يناير ونهاية فبراير. ومع إطلاق نسخة V4 Lite (بحجم ~200 مليار معامل) في 9 مارس، تم التحقق من جدوى البنية الأساسية، مما يرفع احتمالية إطلاق النسخة الكاملة قريباً. يمكنك الحصول على وصول فوري إلى API الخاص بـ V4 عبر منصة APIYI apiyi.com.
س2: هل يعني حجم 1 تريليون معامل في DeepSeek V4 أن تكلفة الاستدلال ستكون مرتفعة جداً؟
ليس بالضرورة. يعتمد V4 على بنية MoE، حيث يتم تفعيل حوالي 32-37 مليار معامل فقط لكل رمز (token)، وهو ما يعادل تقريباً ما كان عليه في V3. هذا يعني أن حجم الحوسبة الفعلي أثناء الاستدلال لن يزداد بشكل كبير، ومن المتوقع أن تظل التكلفة ضمن نطاق معقول. تتبع DeepSeek دائماً استراتيجية تسعير جريئة، ومن المتوقع أن تظل أسعار API لنموذج V4 تنافسية للغاية.
س3: هل سيتم إطلاق نموذج الاستدلال DeepSeek R2؟
لا يزال موعد إطلاق DeepSeek R2 غير واضح حالياً. يرى بعض المحللين أن قدرات الاستدلال الخاصة بـ R2 قد يتم دمجها مباشرة في V4 (حيث يدعم V3.2 بالفعل وضع التفكير Thinking). وهناك وجهة نظر أخرى تشير إلى أن R2 لا يزال قيد التطوير المستقل، لكنه يواجه تحديات في التدريب. ننصح بمتابعة التحديثات الرسمية من DeepSeek للحصول على أحدث المعلومات.
س4: ما الذي يجب على المطورين القيام به استعداداً لإطلاق V4؟
ننصح بالتعرف مسبقاً على كيفية استدعاء API الخاص بـ DeepSeek. من المرجح جداً أن يكون V4 متوافقاً مع واجهات OpenAI الحالية، مما يجعل تكلفة الانتقال منخفضة للغاية. يمكنك استخدام DeepSeek V3.2 عبر منصة APIYI apiyi.com للتطوير والاختبار، وبمجرد إطلاق V4، ستحتاج فقط إلى تبديل اسم النموذج.
ملخص
من المتوقع أن يصبح DeepSeek V4 واحداً من أهم إصدارات نماذج اللغة الكبيرة مفتوحة المصدر في عام 2026. بفضل بنية MoE التي تبلغ حوالي 1 تريليون معامل، ونافذة سياق فائقة الطول تصل إلى مليون رمز، ودعم أصلي للوسائط المتعددة، بالإضافة إلى ترخيص Apache 2.0 مفتوح المصدر والقيمة الفائقة مقابل السعر، فإن V4 يستحق الترقب سواء من الناحية التقنية أو التجارية.
مراجعة النقاط الجوهرية:
- البنية: ~1 تريليون معامل بنظام MoE، مع تفعيل 32-37 مليار معامل لكل رمز، مع التركيز على الكفاءة.
- نافذة السياق: مليون رمز، مع تحقيق دقة استرجاع تصل إلى 97% بفضل ذاكرة Engram الشرطية.
- متعدد الوسائط: دعم أصلي لمدخلات النصوص، الصور، الفيديو، والصوت.
- الابتكار: استقرار التدريب mHC + ذاكرة Engram الشرطية + الانتباه المتناثر (Sparse Attention).
- مفتوح المصدر: من المتوقع أن يكون بترخيص Apache 2.0، مع إمكانية تشغيل كمية INT4 على بطاقة RTX 5090 واحدة.
- التسعير: من المتوقع أن يحافظ على التوازن الفائق بين الأداء والتكلفة الذي تشتهر به DeepSeek.
نوصي بالوصول الموحد إلى جميع نماذج DeepSeek عبر منصة APIYI apiyi.com، والحصول على وصول API فور إطلاق V4.
المراجع
- Dataconomy – تقرير إطلاق DeepSeek V4:
dataconomy.com/2026/03/16/deepseek-v4-and-tencents-new-hunyuan-model-to-launch-in-april/ - NxCode – المواصفات التقنية لـ DeepSeek V4:
nxcode.io/resources/news/deepseek-v4-release-specs-benchmarks-2026 - وثائق DeepSeek الرسمية:
platform.deepseek.com/docs
تم كتابة هذا المقال بواسطة الفريق التقني في APIYI، للمزيد من الدروس التعليمية حول استخدام نماذج الذكاء الاصطناعي، يرجى متابعة APIYI عبر apiyi.com