DeepSeek V4 akan segera dirilis, menggunakan arsitektur MoE dengan sekitar 1 triliun (1T) parameter, mendukung input multimodal asli, dan jendela konteks super panjang hingga 1 juta token. Setelah mengalami beberapa kali penundaan, model bahasa besar sumber terbuka yang sangat dinantikan ini dijadwalkan untuk debut resmi pada April 2026, siap bersaing dengan seri GPT-5.x, Claude 4, dan Gemini 3.x.
Nilai Inti: Pahami inovasi arsitektur, parameter kunci, kemampuan multimodal, dan potensi dampaknya terhadap ekosistem pengembang dalam 3 menit.

Sekilas Informasi Inti DeepSeek V4
DeepSeek V4 adalah Model Bahasa Besar unggulan generasi berikutnya yang direncanakan oleh DeepSeek. Berdasarkan informasi yang telah dipublikasikan, V4 telah mencapai lompatan antargenerasi dalam beberapa dimensi seperti skala parameter, desain arsitektur, dan kemampuan multimodal.
| Item Informasi | DeepSeek V4 |
|---|---|
| Estimasi Rilis | April 2026 |
| Total Parameter | Sekitar 1 Triliun (1T) |
| Parameter Aktif per token | Sekitar 32-37B |
| Arsitektur | Transformer MoE + MLA (Multi-head Latent Attention) |
| Perutean Pakar | 16 pakar aktif per token |
| Jendela Konteks | 1 juta token (1M) |
| Multimodal | Mendukung input teks, gambar, video, dan audio secara asli |
| Lisensi Sumber Terbuka | Apache 2.0 (diperkirakan) |
Perbandingan Parameter Kunci DeepSeek V4 vs V3
Peningkatan inti DeepSeek V4 dibandingkan V3 terlihat jelas:
| Dimensi | DeepSeek V3 | DeepSeek V4 | Perubahan |
|---|---|---|---|
| Total Parameter | 671B | ~1T | +49% |
| Parameter Aktif | 37B | ~32-37B | Stabil, efisiensi diutamakan |
| Jendela Konteks | 128K | 1M | Ekspansi 8x |
| Multimodal | Hanya teks | Teks+Gambar+Video+Audio | Peningkatan penuh |
| Mekanisme Perhatian | MLA | MLA + Memori Kondisional Engram | Optimasi konteks panjang |
| Stabilitas Pelatihan | Standar | mHC (Manifold-constrained Hyper-connection) | Inovasi arsitektur |
Temuan Kunci: Dengan peningkatan total parameter sebesar 49%, V4 tetap mempertahankan parameter aktif per token yang hampir sama (sekitar 32-37B). Ini berarti biaya inferensi tidak akan melonjak drastis, namun kapasitas pengetahuan dan kemampuan generalisasi model meningkat secara signifikan.
🎯 Saran Teknis: Setelah DeepSeek V4 dirilis, pengembang dapat segera melakukan pengujian melalui platform APIYI (apiyi.com). Platform ini telah mendukung rangkaian lengkap model seperti DeepSeek V3 dan R1, dan akan segera mengadaptasi V4 setelah diluncurkan.
Inovasi Arsitektur DeepSeek V4: 3 Terobosan Teknologi Utama
DeepSeek V4 bukan sekadar peningkatan jumlah parameter, melainkan menghadirkan 3 inovasi arsitektur kunci yang menjawab tantangan utama dalam pelatihan dan inferensi model dengan parameter triliunan.
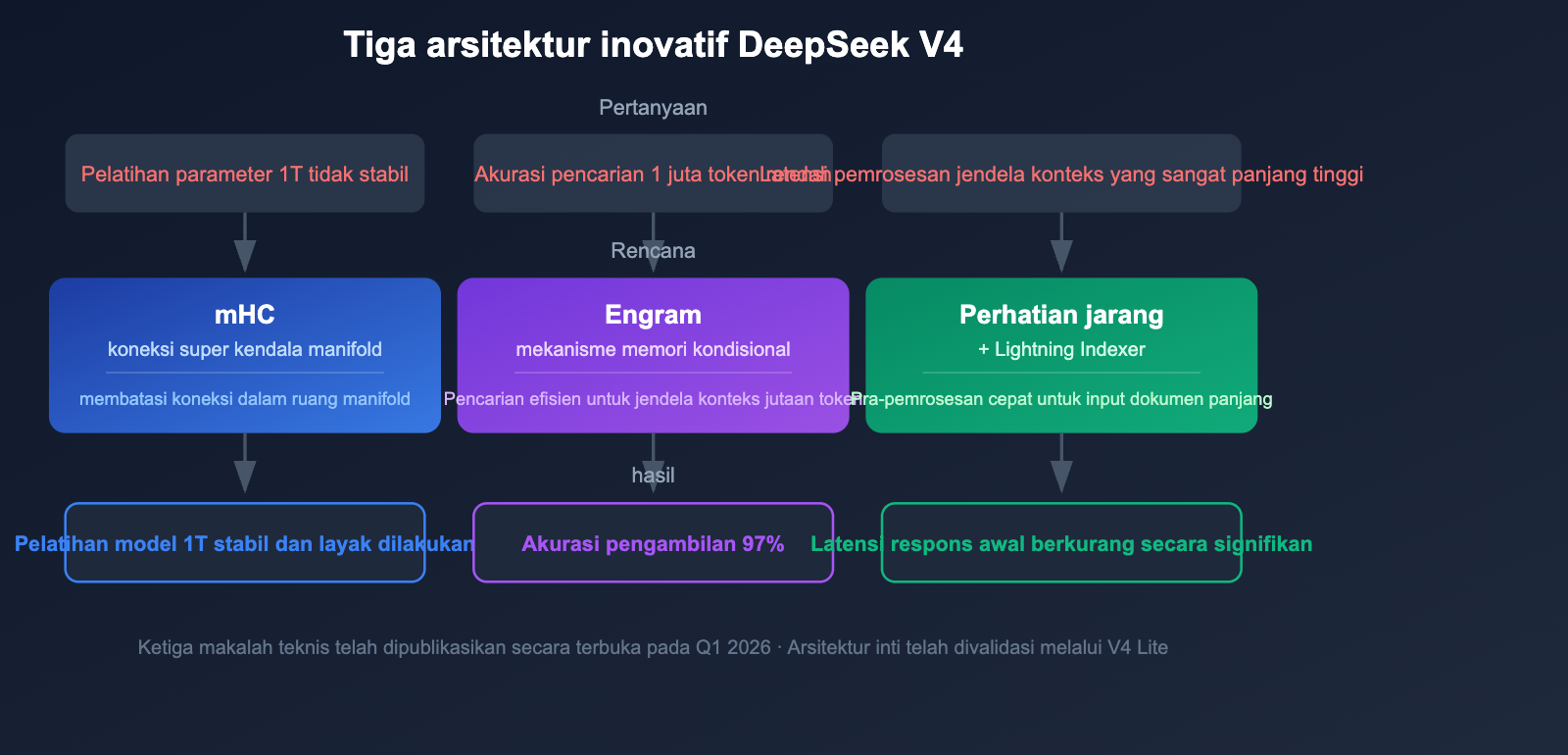
Inovasi 1: Manifold-Constrained Hyper-Connections (mHC)
DeepSeek merilis makalah teknis tentang Manifold-Constrained Hyper-Connections (mHC) pada 13 Januari 2026. Teknologi ini secara khusus dirancang untuk mengatasi masalah stabilitas pelatihan pada model MoE dengan parameter triliunan.
Model MoE skala besar tradisional sering mengalami masalah ledakan gradien (gradient explosion) dan ketidakseimbangan beban pakar selama pelatihan. mHC meningkatkan stabilitas proses pelatihan secara signifikan dengan membatasi hyper-connection di ruang manifold, sehingga pelatihan model tingkat 1T parameter menjadi layak dilakukan.
Inovasi 2: Memori Kondisional Engram
Memori kondisional Engram adalah teknologi inti yang memungkinkan DeepSeek V4 mencapai jendela konteks hingga 1 juta token. Mekanisme atensi tradisional menghadapi tantangan ganda dalam hal efisiensi dan akurasi pada konteks yang sangat panjang.
| Indikator | Atensi Standar | Memori Kondisional Engram |
|---|---|---|
| Akurasi Needle-in-a-Haystack | 84,2% | 97% |
| Pengambilan Konteks Panjang | Performa menurun drastis | Konsisten sepanjang proses |
| Biaya Komputasi | O(n²) | Berkurang drastis setelah optimasi |
Akurasi 97% pada Needle-in-a-Haystack berarti model mampu menemukan dan mengekstrak informasi penting secara presisi, bahkan di dalam teks super panjang berukuran 1 juta token.
Inovasi 3: Atensi Jarang (Sparse Attention) + Lightning Indexer
Sparse Attention DeepSeek yang dipadukan dengan mesin pra-pemrosesan Lightning Indexer memungkinkan pemrosesan konteks super panjang dengan kecepatan tinggi. Teknologi ini membuat input 1 juta token tidak lagi memerlukan waktu pra-pemrosesan yang lama, sehingga secara signifikan mengurangi latensi respons awal untuk analisis dokumen panjang.
Analisis Kemampuan Multimodal Asli DeepSeek V4
Salah satu perubahan terbesar pada DeepSeek V4 adalah peningkatan dari model teks murni menjadi model multimodal asli (native multimodal). Berbeda dengan solusi multimodal yang digabungkan di tahap akhir, V4 mengintegrasikan kemampuan multimodal sejak tahap pra-pelatihan.
Dukungan Input Multimodal
| Modalitas | Status Dukungan | Penjelasan |
|---|---|---|
| Teks | ✅ Dukungan Asli | Melanjutkan kemampuan teks V3 yang kuat |
| Gambar | ✅ Dukungan Asli | Terintegrasi sejak pra-pelatihan, bukan tempelan |
| Video | ✅ Dukungan Asli | Pemahaman dan analisis lintas bingkai |
| Audio | ✅ Dukungan Asli | Pemahaman suara dan ucapan |
| Penalaran Lintas Modal | ✅ Dukungan Asli | Analisis komprehensif informasi multimodal |
Multimodal Asli vs. Penggabungan Tahap Akhir
Multimodal asli (terintegrasi saat pra-pelatihan) memiliki keunggulan signifikan dibandingkan solusi penggabungan tahap akhir:
- Pemahaman lintas modal lebih dalam: Model mempelajari korelasi antar modalitas sejak masa pelatihan.
- Konsistensi inferensi lebih kuat: Informasi teks, gambar, dan video dapat berpartisipasi dalam rantai penalaran yang sama dengan mulus.
- Tingkat halusinasi lebih rendah: Informasi multimodal saling memverifikasi, mengurangi halusinasi dari modalitas tunggal.
- Latensi lebih rendah: Tidak memerlukan langkah konversi modalitas tambahan.
💡 Saran Penggunaan: Kemampuan multimodal asli DeepSeek V4 membuatnya sangat cocok untuk skenario yang memerlukan analisis komprehensif dari berbagai sumber informasi. Disarankan untuk mengaksesnya secara terpadu melalui platform APIYI (apiyi.com) untuk membandingkan performa aktual DeepSeek V4 dengan model multimodal lainnya dalam satu antarmuka.
Linimasa Perilisan DeepSeek V4 dan Latar Belakang Penundaan
Perilisan DeepSeek V4 telah mengalami beberapa kali penundaan. Memahami sejarah ini membantu kita melihat tantangan teknis yang dihadapi V4 serta tingkat kematangan produk akhirnya.
Linimasa Perilisan
| Waktu | Peristiwa |
|---|---|
| Awal Januari 2026 | Diskusi terkait V4 muncul di komunitas Reddit |
| 13 Januari 2026 | Makalah teknis mHC diterbitkan, inovasi arsitektur terungkap |
| 20 Januari 2026 | Kebocoran kode GitHub, ditemukan 28 referensi kode internal "MODEL1" |
| Akhir Januari 2026 | Jendela perilisan pertama yang diharapkan, namun tidak tercapai |
| 11 Februari 2026 | Kemampuan konteks 1 juta token dikonfirmasi |
| Pertengahan Februari 2026 | Data tolok ukur (benchmark) bocor |
| Akhir Februari 2026 | Jendela perilisan setelah Tahun Baru Imlek, kembali ditunda |
| 9 Maret 2026 | V4 Lite dirilis (~200B parameter, memvalidasi arsitektur inti) |
| April 2026 | Perilisan lengkap V4 diperkirakan |
Alasan Utama Penundaan
Penyebab utama penundaan V4 berulang kali adalah tantangan pada infrastruktur pelatihan:
- Masalah adaptasi perangkat keras: Melatih model dengan parameter triliunan pada chip domestik menghadapi tantangan stabilitas.
- Bandwidth interkoneksi chip: Pelatihan terdistribusi skala besar menuntut bandwidth komunikasi antar-chip yang sangat tinggi.
- Kematangan ekosistem perangkat lunak: Kerangka kerja pelatihan dan rantai alat optimasi masih dalam tahap iterasi.
Perlu dicatat bahwa V4 Lite (sekitar 200B parameter) telah dirilis lebih awal pada 9 Maret sebagai versi validasi arsitektur untuk V4 lengkap. Langkah ini menunjukkan bahwa arsitektur inti telah teruji, dan penundaan versi lengkap lebih disebabkan oleh masalah teknis pada pelatihan skala besar.
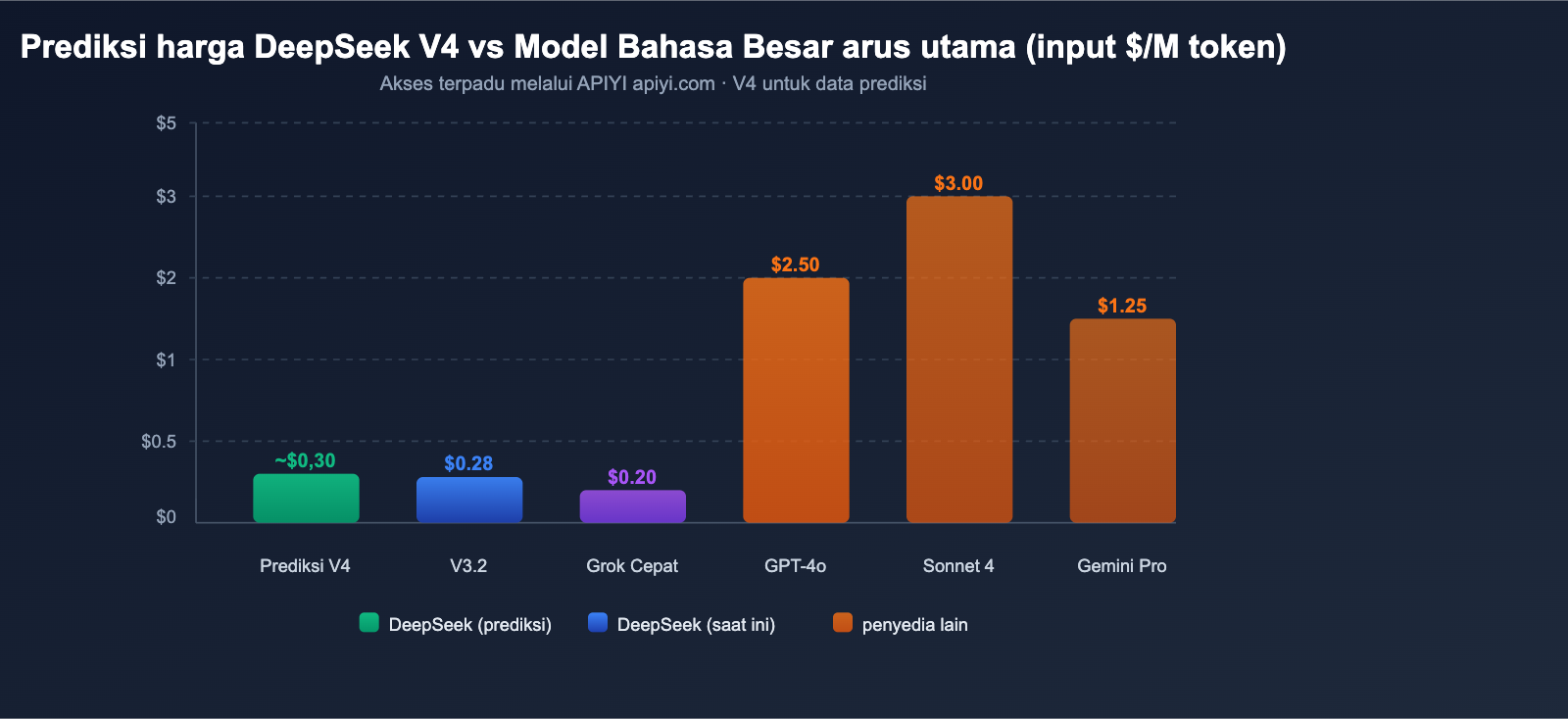
Prediksi Harga API DeepSeek V4
Berdasarkan strategi penetapan harga DeepSeek yang konsisten dan karakteristik arsitektur V4, kita dapat membuat prediksi harga API untuk V4.
Harga API DeepSeek Saat Ini
| Model | Input (Cache Miss) | Input (Cache Hit) | Output | Jendela Konteks |
|---|---|---|---|---|
| deepseek-chat (V3.2) | $0.28/M | $0.028/M | $0.42/M | 128K |
| deepseek-reasoner (V3.2) | $0.28/M | $0.028/M | $0.42/M | 128K |
Prediksi Harga DeepSeek V4
Berdasarkan analisis dari berbagai sumber, harga V4 diperkirakan berada pada kisaran berikut:
| Skenario Prediksi | Harga Input | Harga Output | Dasar |
|---|---|---|---|
| Prediksi Optimis | ~$0.14/M | ~$0.28/M | Parameter aktif tetap, efisiensi meningkat |
| Prediksi Netral | ~$0.30/M | ~$0.50/M | Konteks 1M membawa biaya komputasi tambahan |
| Prediksi Konservatif | ~$0.50/M | ~$0.80/M | Pemrosesan multimodal menambah biaya |
Bahkan dengan prediksi konservatif, harga input $0,50/M sangat kompetitif untuk model multimodal dengan parameter triliunan. Sebagai perbandingan, harga input GPT-4o adalah $2,50/M, dan Claude Opus 4 adalah $15,00/M.
💰 Optimasi Biaya: Seri DeepSeek selalu dikenal dengan efisiensi biaya yang luar biasa. Melalui platform APIYI (apiyi.com), pengembang dapat menggunakan antarmuka terpadu untuk memanggil DeepSeek dan model utama lainnya secara bersamaan, guna menemukan keseimbangan terbaik antara biaya dan performa.
Analisis Lanskap Kompetitif DeepSeek V4
April 2026 menjadi periode padat peluncuran Model Bahasa Besar AI. DeepSeek V4 akan menghadapi persaingan dari berbagai arah.
Perbandingan Kompetitor di Periode yang Sama
| Model | Vendor | Skala Parameter | Jendela Konteks | Multimodal | Open Source |
|---|---|---|---|---|---|
| DeepSeek V4 | DeepSeek | ~1T (MoE) | 1M | ✅ Native | ✅ Apache 2.0 |
| GPT-5.x | OpenAI | Tidak diungkap | Tidak diungkap | ✅ | ❌ |
| Seri Claude 4 | Anthropic | Tidak diungkap | 1M | ✅ | ❌ |
| Gemini 3.x | Tidak diungkap | 2M | ✅ | ❌ | |
| Grok 4.x | xAI | Tidak diungkap | 2M | ✅ | ❌ |
Keunggulan Diferensiasi DeepSeek V4
- Open Source: Diperkirakan menggunakan lisensi Apache 2.0, yang hampir unik untuk model dengan skala triliunan parameter.
- Efektivitas Biaya Ekstrem: Strategi penetapan harga DeepSeek selalu menjadi yang terendah di antara model sekelasnya.
- Potensi Deployment Lokal: Bersifat open source berarti perusahaan dapat melakukan deployment pada infrastruktur milik sendiri.
- Efisiensi MoE: Parameter aktif hanya 32-37B, efisiensi inferensi jauh lebih tinggi dibandingkan model padat (dense) dengan jumlah parameter yang sama.
Kebutuhan Perangkat Keras untuk Deployment Lokal DeepSeek V4
Bagi tim yang ingin melakukan deployment lokal, berikut adalah kebutuhan perangkat keras untuk V4:
| Metode Kuantisasi | VRAM yang Dibutuhkan | Perangkat Keras yang Disarankan |
|---|---|---|
| FP16/BF16 (Presisi Penuh) | Sangat Besar | Klaster GPU multi-node |
| INT8 (Kuantisasi 8-bit) | ~48GB | Dual RTX 4090 |
| INT4 (Kuantisasi 4-bit) | ~32GB | Single RTX 5090 |
Setelah kuantisasi INT4, model ini hanya memerlukan satu kartu RTX 5090 untuk dijalankan, yang memungkinkan tim kecil dan peneliti untuk melakukan deployment lokal.
Evolusi Versi Model DeepSeek
Memahami evolusi produk lengkap DeepSeek membantu memahami posisi dan jalur teknis V4.

| Versi | Waktu Rilis | Fitur Utama |
|---|---|---|
| V1 | November 2023 | Model open source pertama |
| V2 | Mei 2024 | Pengenalan arsitektur MoE, biaya berkurang drastis |
| V2.5 | September 2024 | Peningkatan kemampuan percakapan dan kode |
| V3 | Desember 2024 | 671B parameter, atensi MLA, konteks 128K |
| R1 | Januari 2025 | Model khusus inferensi, teknologi rantai pemikiran (CoT) |
| V3.1 | Agustus 2025 | Optimalisasi performa, peningkatan inferensi |
| V3.2 | Akhir 2025 | Model utama saat ini, mendukung mode Thinking |
| V4 Lite | Maret 2026 | ~200B parameter, versi validasi arsitektur |
| V4 | April 2026 (Estimasi) | ~1T MoE, multimodal native, konteks 1M |
Mulai dari V2 yang memperkenalkan arsitektur MoE, hingga atensi MLA pada V3, dan teknologi mHC serta Engram pada V4, setiap generasi produk DeepSeek memiliki inovasi substansial di tingkat arsitektur.
🎯 Saran Teknis: Sembari menunggu rilis resmi V4, pengembang dapat mencoba DeepSeek V3.2 dan R1 terlebih dahulu melalui platform APIYI (apiyi.com). Setelah V4 dirilis, platform akan segera mendukungnya.
Pertanyaan Umum
Q1: Kapan DeepSeek V4 resmi dirilis?
Berdasarkan rangkuman berbagai informasi, DeepSeek V4 diperkirakan akan dirilis pada April 2026. Sebelumnya, peluncuran ini telah mengalami dua kali penundaan, yakni pada akhir Januari dan akhir Februari. V4 Lite (~200B parameter) yang dirilis pada 9 Maret telah memvalidasi kelayakan arsitektur intinya, sehingga kemungkinan besar versi lengkapnya akan segera hadir. Anda bisa mendapatkan akses API V4 lebih awal melalui platform APIYI apiyi.com.
Q2: Apakah 1T parameter pada DeepSeek V4 berarti biaya inferensinya sangat mahal?
Belum tentu. V4 menggunakan arsitektur MoE, di mana setiap token hanya mengaktifkan sekitar 32-37B parameter, setara dengan V3. Ini berarti beban komputasi aktual saat inferensi tidak akan meningkat secara drastis, dan biayanya diharapkan tetap berada dalam kisaran yang wajar. Strategi penetapan harga DeepSeek selalu agresif, sehingga harga API V4 diperkirakan akan tetap sangat kompetitif.
Q3: Apakah model penalaran DeepSeek R2 akan tetap dirilis?
Waktu perilisan DeepSeek R2 saat ini masih belum jelas. Beberapa analisis berpendapat bahwa kemampuan penalaran R2 mungkin telah diintegrasikan langsung ke dalam V4 (V3.2 sudah mendukung mode Thinking). Ada juga pandangan yang menyebutkan bahwa R2 masih dalam pengembangan independen, namun menghadapi tantangan dalam pelatihan. Disarankan untuk memantau pembaruan resmi dari DeepSeek untuk mendapatkan informasi terkini.
Q4: Apa yang harus dipersiapkan pengembang sebelum V4 dirilis?
Disarankan untuk membiasakan diri dengan cara pemanggilan API DeepSeek. V4 kemungkinan besar akan kompatibel dengan antarmuka OpenAI yang sudah ada, sehingga biaya migrasinya sangat rendah. Gunakan DeepSeek V3.2 melalui platform APIYI apiyi.com untuk pengembangan dan pengujian; setelah V4 diluncurkan, Anda hanya perlu mengganti nama modelnya saja.
Kesimpulan
DeepSeek V4 digadang-gadang akan menjadi salah satu rilis Model Bahasa Besar sumber terbuka paling penting di tahun 2026. Dengan arsitektur MoE berkapasitas ~1T parameter, jendela konteks super panjang hingga 1 juta token, dukungan multimodal asli, ditambah lisensi sumber terbuka Apache 2.0 dan efisiensi biaya yang luar biasa, V4 sangat dinantikan baik dari sisi metrik teknis maupun nilai komersialnya.
Ringkasan Poin Utama:
- Arsitektur: ~1T parameter MoE, mengaktifkan 32-37B per token, mengutamakan efisiensi
- Konteks: 1 juta token, memori kondisional Engram mencapai akurasi pengambilan 97%
- Multimodal: Mendukung input teks, gambar, video, dan audio secara asli
- Inovasi: Stabilitas pelatihan mHC + memori kondisional Engram + atensi jarang (sparse attention)
- Sumber Terbuka: Diperkirakan menggunakan Apache 2.0, kuantisasi INT4 dapat berjalan pada satu kartu RTX 5090
- Harga: Diperkirakan tetap mempertahankan efisiensi biaya yang menjadi ciri khas DeepSeek
Direkomendasikan untuk mengakses seluruh seri model DeepSeek secara terpadu melalui APIYI apiyi.com agar Anda bisa mendapatkan akses API segera setelah V4 dirilis.
Referensi
- Dataconomy – Laporan Rilis DeepSeek V4:
dataconomy.com/2026/03/16/deepseek-v4-and-tencents-new-hunyuan-model-to-launch-in-april/ - NxCode – Spesifikasi Teknis DeepSeek V4:
nxcode.io/resources/news/deepseek-v4-release-specs-benchmarks-2026 - Dokumentasi Resmi DeepSeek:
platform.deepseek.com/docs
Artikel ini ditulis oleh tim teknis APIYI. Untuk tutorial penggunaan Model Bahasa Besar lainnya, silakan kunjungi APIYI di apiyi.com