DeepSeek V4 steht kurz vor der Veröffentlichung und setzt auf eine MoE-Architektur mit etwa 1 Billion (1T) Parametern, unterstützt native multimodale Eingaben und ein extrem langes Kontextfenster von 1 Million Tokens. Nach mehreren Verzögerungen wird das mit Spannung erwartete Open-Source-Großes Sprachmodell voraussichtlich im April 2026 erscheinen und sich mit der GPT-5.x-, Claude 4- und Gemini 3.x-Serie messen.
Kernnutzen: Erfahren Sie in 3 Minuten alles über die architektonischen Innovationen, Schlüsselparameter und multimodalen Fähigkeiten von DeepSeek V4 sowie dessen Auswirkungen auf das Entwickler-Ökosystem.

DeepSeek V4: Die wichtigsten Informationen auf einen Blick
DeepSeek V4 ist das kommende Flaggschiff-Großes Sprachmodell von DeepSeek. Basierend auf den veröffentlichten Informationen stellt V4 einen generationsübergreifenden Sprung in Bezug auf Parameterumfang, Architekturdesign und multimodale Fähigkeiten dar.
| Information | DeepSeek V4 |
|---|---|
| Voraussichtliche Veröffentlichung | April 2026 |
| Gesamtparameter | ca. 1 Billion (1T) |
| Aktive Parameter pro Token | ca. 32-37 Mrd. |
| Architektur | Transformer MoE + MLA (Multi-Head Latent Attention) |
| Experten-Routing | 16 aktive Experten pro Token |
| Kontextfenster | 1 Million Tokens (1M) |
| Multimodalität | Native Unterstützung für Text-, Bild-, Video- und Audioeingabe |
| Open-Source-Lizenz | Apache 2.0 (geplant) |
DeepSeek V4 vs. V3: Vergleich der Schlüsselparameter
Die wichtigsten Upgrades von DeepSeek V4 gegenüber V3 sind offensichtlich:
| Dimension | DeepSeek V3 | DeepSeek V4 | Änderung |
|---|---|---|---|
| Gesamtparameter | 671 Mrd. | ~1T | +49% |
| Aktive Parameter | 37 Mrd. | ~32-37 Mrd. | Gleichbleibend, Fokus auf Effizienz |
| Kontextfenster | 128K | 1M | 8-fache Erweiterung |
| Multimodalität | Nur Text | Text+Bild+Video+Audio | Vollständiges multimodales Upgrade |
| Aufmerksamkeitsmechanismus | MLA | MLA + Engram konditioniertes Gedächtnis | Optimierung für langen Kontext |
| Trainingsstabilität | Standard | mHC (Manifold-constrained Hyper-connection) | Architektonische Innovation |
Wichtige Erkenntnis: Während die Gesamtparameterzahl um 49 % steigt, bleiben die aktiven Parameter pro Token bei etwa 32-37 Mrd. stabil. Das bedeutet, dass die Inferenzkosten nicht drastisch steigen, während die Wissenskapazität und die Generalisierungsfähigkeit des Modells deutlich zunehmen.
🎯 Technischer Hinweis: Sobald DeepSeek V4 veröffentlicht wird, können Entwickler es direkt über den API-Proxy-Dienst APIYI (apiyi.com) testen. Die Plattform unterstützt bereits die gesamte Modellreihe wie DeepSeek V3 und R1 und wird V4 nach dem Start schnell integrieren.
DeepSeek V4: Drei technologische Durchbrüche in der Architektur
DeepSeek V4 bietet nicht nur eine Skalierung der Parameter, sondern führt drei entscheidende architektonische Innovationen ein, die die Kernprobleme beim Training und bei der Inferenz von Modellen mit Billionen von Parametern lösen.
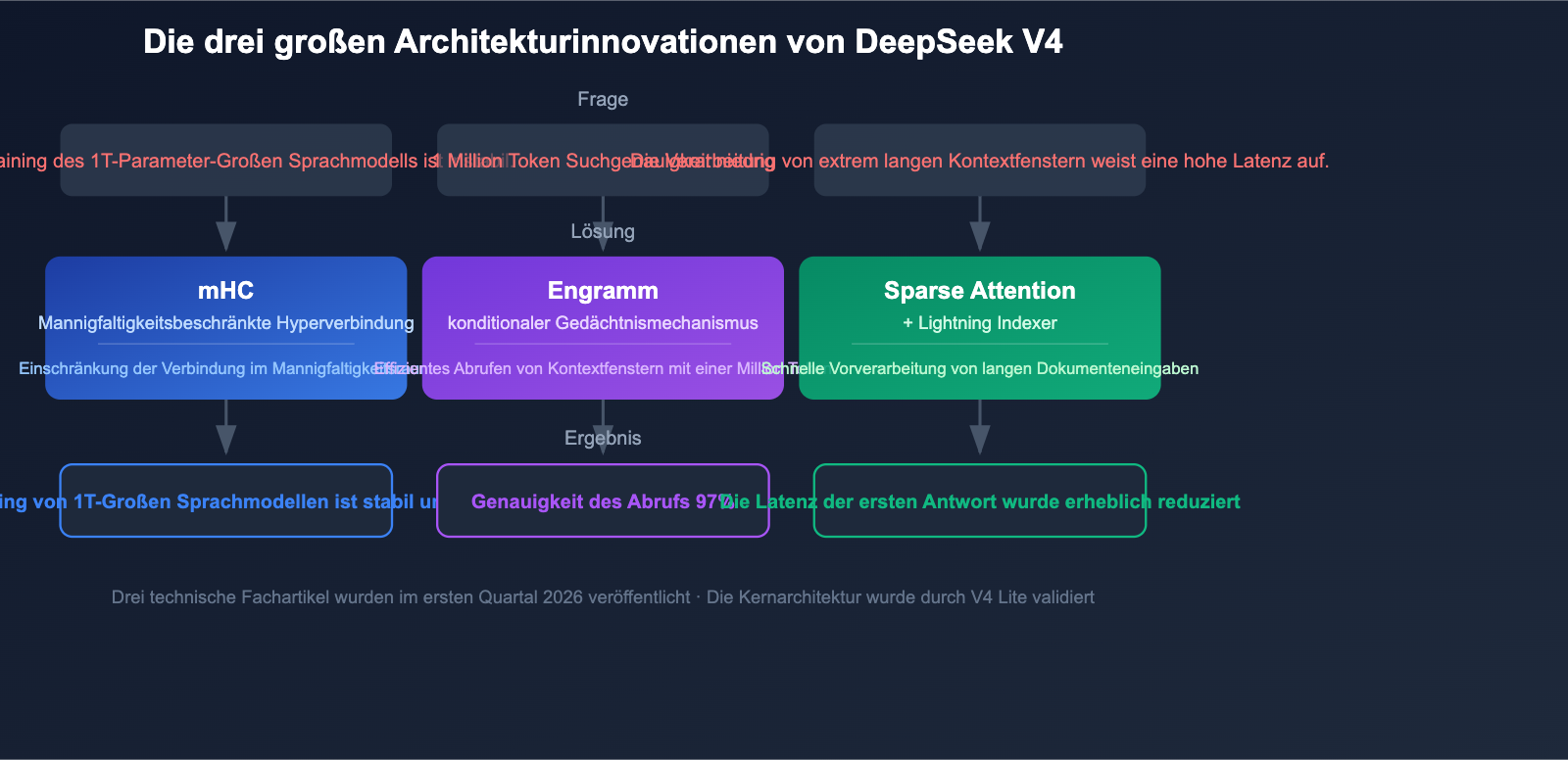
Innovation 1: Manifold-Constrained Hyper-Connections (mHC)
DeepSeek veröffentlichte am 13. Januar 2026 das Fachpapier zur mHC-Technologie. Diese Technik wurde speziell entwickelt, um die Stabilität beim Training von MoE-Modellen mit Billionen von Parametern zu gewährleisten.
Herkömmliche, groß angelegte MoE-Modelle neigen während des Trainings zu Problemen wie explodierenden Gradienten und unausgewogener Expertenlast. Durch die Einschränkung der Hyper-Connections im Mannigfaltigkeitsraum (Manifold Space) verbessert mHC die Stabilität des Trainingsprozesses erheblich und macht das Training von Modellen im 1T-Parameter-Bereich erst möglich.
Innovation 2: Engram-Konditionierter Speicher
Der Engram-konditionierte Speicher ist die Kerntechnologie, die es DeepSeek V4 ermöglicht, ein Kontextfenster von 1 Million Tokens zu realisieren. Herkömmliche Aufmerksamkeitsmechanismen (Attention Mechanisms) stehen bei extrem langen Kontexten vor der doppelten Herausforderung von Effizienz und Genauigkeit.
| Metrik | Standard-Attention | Engram-konditionierter Speicher |
|---|---|---|
| Needle-in-a-Haystack-Genauigkeit | 84,2 % | 97 % |
| Langkontext-Abruf | Deutlicher Leistungsabfall | Durchgehend konsistent |
| Rechenaufwand | O(n²) | Nach Optimierung deutlich reduziert |
Eine Needle-in-a-Haystack-Genauigkeit von 97 % bedeutet, dass das Modell selbst in extrem langen Texten von 1 Million Tokens in der Lage ist, wichtige Informationen präzise zu lokalisieren und zu extrahieren.
Innovation 3: Sparse Attention + Lightning Indexer
Die Kombination aus DeepSeek Sparse Attention und der Vorverarbeitungs-Engine Lightning Indexer ermöglicht die Hochgeschwindigkeitsverarbeitung extrem langer Kontexte. Diese Technologie sorgt dafür, dass die Eingabe von 1 Million Tokens keine langwierigen Vorverarbeitungszeiten mehr erfordert, was die Latenz bei der ersten Antwort für die Analyse langer Dokumente drastisch senkt.
Analyse der nativen multimodalen Fähigkeiten von DeepSeek V4
Eine der größten Neuerungen bei DeepSeek V4 ist der Übergang von einem reinen Textmodell zu einem nativen multimodalen Modell. Im Gegensatz zu nachträglich zusammengesetzten Lösungen wurde die multimodale Funktionalität bei V4 bereits in der Phase des Vortrainings integriert.
Unterstützung für multimodale Eingaben
| Modalität | Unterstützung | Anmerkung |
|---|---|---|
| Text | ✅ Nativ unterstützt | Setzt die starke Textleistung von V3 fort |
| Bild | ✅ Nativ unterstützt | Im Vortraining integriert, kein nachträgliches Patchwork |
| Video | ✅ Nativ unterstützt | Verständnis und Analyse über Bildfolgen hinweg |
| Audio | ✅ Nativ unterstützt | Verständnis von Sprache und Geräuschen |
| Cross-modale Schlussfolgerung | ✅ Nativ unterstützt | Umfassende Analyse multimodaler Informationen |
Natives multimodales Modell vs. nachträgliche Zusammenstellung
Natives multimodales Design (Integration während des Vortrainings) bietet gegenüber nachträglichen Lösungen deutliche Vorteile:
- Tieferes cross-modales Verständnis: Das Modell lernt die Zusammenhänge zwischen verschiedenen Modalitäten bereits während des Trainings.
- Stärkere Konsistenz bei Schlussfolgerungen: Text-, Bild- und Videoinformationen können nahtlos in dieselbe logische Kette einfließen.
- Geringere Halluzinationsrate: Multimodale Informationen validieren sich gegenseitig, was Halluzinationen bei einzelnen Modalitäten reduziert.
- Geringere Latenz: Es sind keine zusätzlichen Schritte zur Modalumwandlung erforderlich.
💡 Empfehlung: Die nativen multimodalen Fähigkeiten von DeepSeek V4 machen es ideal für Szenarien, die eine umfassende Analyse verschiedener Informationsquellen erfordern. Wir empfehlen die einheitliche Anbindung über die APIYI-Plattform (apiyi.com), um die tatsächliche Leistung von DeepSeek V4 und anderen multimodalen Modellen über dieselbe Schnittstelle zu vergleichen.
Zeitplan der DeepSeek V4-Veröffentlichung und Hintergrund der Verzögerungen
Die Veröffentlichung von DeepSeek V4 wurde mehrfach verschoben. Die Kenntnis dieser Hintergründe hilft dabei, die technischen Herausforderungen und die Reife des Endprodukts besser einzuschätzen.
Zeitplan der Veröffentlichung
| Datum | Ereignis |
|---|---|
| Anfang Januar 2026 | Erste Diskussionen zu V4 in der Reddit-Community |
| 13. Januar 2026 | Veröffentlichung des mHC-Whitepapers, Enthüllung architektonischer Innovationen |
| 20. Januar 2026 | GitHub-Code-Leak, 28 Referenzen auf den internen Codenamen "MODEL1" entdeckt |
| Ende Januar 2026 | Erstes geplantes Veröffentlichungsfenster, nicht eingehalten |
| 11. Februar 2026 | Bestätigung der Kontextfenster-Kapazität von 1 Million Token |
| Mitte Februar 2026 | Leck von Benchmark-Daten |
| Ende Februar 2026 | Veröffentlichungsfenster nach dem Frühlingsfest, erneut verschoben |
| 9. März 2026 | V4 Lite veröffentlicht (~200B Parameter, Validierung der Kernarchitektur) |
| April 2026 | Voraussichtliche Veröffentlichung der vollständigen V4-Version |
Hauptgründe für die Verzögerungen
Die mehrfachen Verschiebungen von V4 sind primär auf Herausforderungen bei der Trainingsinfrastruktur zurückzuführen:
- Hardware-Anpassung: Stabilitätsprobleme beim Training von Modellen mit Billionen von Parametern auf heimischen Chips.
- Interconnect-Bandbreite der Chips: Groß angelegtes verteiltes Training stellt extrem hohe Anforderungen an die Kommunikationsbandbreite zwischen den Chips.
- Reife des Software-Ökosystems: Trainings-Frameworks und Optimierungs-Toolchains befinden sich noch in der Iterationsphase.
Es ist erwähnenswert, dass die V4 Lite-Version (ca. 200B Parameter) bereits am 9. März als Architektur-Validierung für die vollständige V4-Version veröffentlicht wurde. Dieser Schritt zeigt, dass die Kernarchitektur bereits erfolgreich validiert wurde und die Verzögerung der Vollversion hauptsächlich auf technische Probleme bei der Skalierung des Trainings zurückzuführen ist.
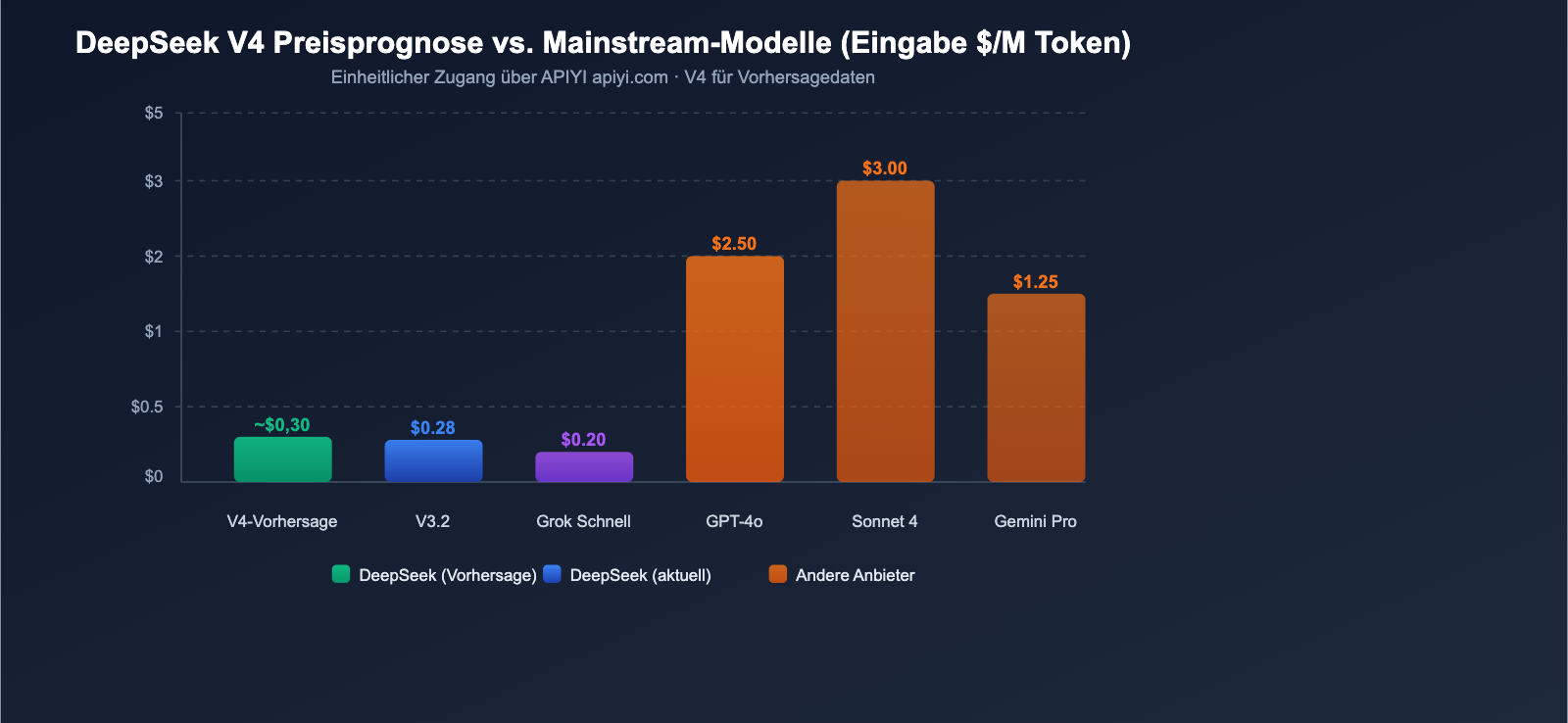
Prognose zur Preisgestaltung der DeepSeek V4 API
Basierend auf der bewährten Preisstrategie von DeepSeek und den architektonischen Merkmalen von V4 können wir eine fundierte Prognose für die API-Preise von V4 erstellen.
Aktuelle DeepSeek API-Preisgestaltung
| Modell | Eingabe (Cache-Miss) | Eingabe (Cache-Hit) | Ausgabe | Kontextfenster |
|---|---|---|---|---|
| deepseek-chat (V3.2) | $0,28/M | $0,028/M | $0,42/M | 128K |
| deepseek-reasoner (V3.2) | $0,28/M | $0,028/M | $0,42/M | 128K |
Prognose zur DeepSeek V4 Preisgestaltung
Basierend auf Analysen aus verschiedenen Quellen wird für V4 die folgende Preisspanne erwartet:
| Prognoseszenario | Eingabepreis | Ausgabepreis | Grundlage |
|---|---|---|---|
| Optimistisch | ~$0,14/M | ~$0,28/M | Gleichbleibende aktivierte Parameter, Effizienzsteigerung |
| Neutral | ~$0,30/M | ~$0,50/M | 1M Kontextfenster verursacht zusätzliche Rechenkosten |
| Konservativ | ~$0,50/M | ~$0,80/M | Mehraufwand durch multimodale Verarbeitung |
Selbst bei einer konservativen Schätzung ist der Eingabepreis von $0,50/M für ein multimodales Modell mit Billionen von Parametern äußerst wettbewerbsfähig. Zum Vergleich: GPT-4o kostet $2,50/M und Claude Opus 4 $15,00/M.
💰 Kostenoptimierung: Die DeepSeek-Serie ist für ihr exzellentes Preis-Leistungs-Verhältnis bekannt. Über die APIYI-Plattform (apiyi.com) können Entwickler DeepSeek und andere führende Modelle über eine einheitliche Schnittstelle aufrufen, um die optimale Balance zwischen Kosten und Leistung zu finden.
Analyse der Wettbewerbslandschaft für DeepSeek V4
Der April 2026 ist ein Monat mit zahlreichen Veröffentlichungen großer Sprachmodelle. DeepSeek V4 wird sich einem intensiven Wettbewerb stellen müssen.
Vergleich mit zeitgleichen Konkurrenzprodukten
| Modell | Anbieter | Parameterumfang | Kontextfenster | multimodal | Open Source |
|---|---|---|---|---|---|
| DeepSeek V4 | DeepSeek | ~1T (MoE) | 1M | ✅ nativ | ✅ Apache 2.0 |
| GPT-5.x | OpenAI | nicht öffentlich | nicht öffentlich | ✅ | ❌ |
| Claude 4 Serie | Anthropic | nicht öffentlich | 1M | ✅ | ❌ |
| Gemini 3.x | nicht öffentlich | 2M | ✅ | ❌ | |
| Grok 4.x | xAI | nicht öffentlich | 2M | ✅ | ❌ |
Differenzierte Vorteile von DeepSeek V4
- Open Source: Es wird erwartet, dass die Apache 2.0-Lizenz verwendet wird, was bei Modellen in der Größenordnung von einer Billion Parametern nahezu einzigartig ist.
- Hervorragendes Preis-Leistungs-Verhältnis: Die Preisstrategie von DeepSeek ist durchgehend die niedrigste in dieser Modellklasse.
- Möglichkeit zur lokalen Bereitstellung: Open Source bedeutet, dass Unternehmen das Modell auf ihrer eigenen Infrastruktur betreiben können.
- MoE-Effizienz: Mit nur 32-37B aktivierten Parametern ist die Inferenz-Effizienz deutlich höher als bei dichten Modellen mit vergleichbarer Parameterzahl.
Hardwareanforderungen für die lokale Bereitstellung von DeepSeek V4
Für Teams, die eine lokale Bereitstellung planen, ergeben sich folgende Hardwareanforderungen:
| Quantisierung | Benötigter VRAM | Empfohlene Hardware |
|---|---|---|
| FP16/BF16 (Volle Präzision) | Extrem hoch | Multi-Node GPU-Cluster |
| INT8 (8-Bit-Quantisierung) | ~48GB | Dual RTX 4090 |
| INT4 (4-Bit-Quantisierung) | ~32GB | Einzelne RTX 5090 |
Dank der INT4-Quantisierung ist der Betrieb auf einer einzelnen RTX 5090 möglich, was die lokale Bereitstellung auch für kleinere Teams und Forscher realisierbar macht.
Entwicklung der DeepSeek-Modellversionen
Ein Verständnis der vollständigen Produktentwicklung von DeepSeek hilft dabei, die Positionierung und den technischen Pfad von V4 besser einzuordnen.

| Version | Veröffentlichungsdatum | Kernmerkmale |
|---|---|---|
| V1 | Nov. 2023 | Erstes Open-Source-Modell |
| V2 | Mai 2024 | Einführung der MoE-Architektur, deutliche Kostensenkung |
| V2.5 | Sept. 2024 | Verbesserte Dialog- und Programmierfähigkeiten |
| V3 | Dez. 2024 | 671B Parameter, MLA-Aufmerksamkeit, 128K Kontextfenster |
| R1 | Jan. 2025 | Spezialisiertes Modell für Schlussfolgerungen, Chain-of-Thought-Technik |
| V3.1 | Aug. 2025 | Leistungsoptimierung, verbesserte Schlussfolgerung |
| V3.2 | Ende 2025 | Aktuelles Hauptmodell, unterstützt Thinking-Modus |
| V4 Lite | März 2026 | ~200B Parameter, Architektur-Validierungsversion |
| V4 | April 2026 (geplant) | ~1T MoE, natives multimodal, 1M Kontextfenster |
Von der Einführung der MoE-Architektur in V2 über die MLA-Aufmerksamkeit in V3 bis hin zu mHC- und Engram-Technologien in V4 weist jede Generation von DeepSeek substanzielle Innovationen auf Architekturebene auf.
🎯 Technischer Hinweis: Während Sie auf die offizielle Veröffentlichung von V4 warten, können Entwickler bereits über die APIYI-Plattform (apiyi.com) mit DeepSeek V3.2 und R1 arbeiten. Sobald V4 veröffentlicht wird, wird die Plattform es umgehend integrieren.
Häufig gestellte Fragen
Q1: Wann wird DeepSeek V4 offiziell veröffentlicht?
Basierend auf verschiedenen Informationsquellen wird DeepSeek V4 voraussichtlich im April 2026 veröffentlicht. Zuvor gab es bereits zwei Verzögerungen Ende Januar und Ende Februar. Die am 9. März veröffentlichte V4 Lite-Version (~200B Parameter) hat die Machbarkeit der Kernarchitektur bestätigt, was die Wahrscheinlichkeit einer Veröffentlichung der Vollversion erhöht. Über die Plattform APIYI (apiyi.com) erhalten Sie als Erste Zugriff auf die V4-API.
Q2: Bedeuten die 1T Parameter von DeepSeek V4 hohe Inferenzkosten?
Nicht unbedingt. V4 verwendet eine MoE-Architektur, bei der pro Token nur etwa 32-37B Parameter aktiviert werden, was in etwa dem Niveau von V3 entspricht. Dies bedeutet, dass der tatsächliche Rechenaufwand bei der Inferenz nicht drastisch ansteigt und die Kosten voraussichtlich in einem vernünftigen Rahmen bleiben. Die Preisstrategie von DeepSeek ist traditionell aggressiv, daher wird erwartet, dass die API-Preise für V4 weiterhin äußerst wettbewerbsfähig sein werden.
Q3: Wird das DeepSeek R2 Inferenzmodell noch veröffentlicht?
Der Veröffentlichungszeitpunkt für DeepSeek R2 ist derzeit noch unklar. Einige Analysen deuten darauf hin, dass die Inferenzfähigkeiten von R2 möglicherweise direkt in V4 integriert wurden (V3.2 unterstützt bereits den Thinking-Modus). Andere Ansichten besagen, dass R2 noch in der unabhängigen Entwicklung ist, jedoch mit Trainingsherausforderungen konfrontiert ist. Es wird empfohlen, die offiziellen Ankündigungen von DeepSeek für aktuelle Informationen zu verfolgen.
Q4: Wie sollten sich Entwickler vor der V4-Veröffentlichung vorbereiten?
Es wird empfohlen, sich frühzeitig mit der Art und Weise des DeepSeek-Modellaufrufs vertraut zu machen. V4 wird höchstwahrscheinlich mit den bestehenden OpenAI-kompatiblen Schnittstellen kompatibel sein, was die Migrationskosten sehr niedrig hält. Nutzen Sie die Plattform APIYI (apiyi.com), um mit DeepSeek V3.2 zu entwickeln und zu testen; nach dem Start von V4 müssen Sie lediglich den Modellnamen umstellen.
Zusammenfassung
DeepSeek V4 verspricht, eine der wichtigsten Veröffentlichungen eines Open-Source-Großen Sprachmodells im Jahr 2026 zu werden. Mit einer MoE-Architektur von ca. 1T Parametern, einem Kontextfenster von 1 Million Token, nativer multimodaler Unterstützung sowie der Apache 2.0-Lizenz und einem extremen Preis-Leistungs-Verhältnis ist V4 sowohl technisch als auch kommerziell vielversprechend.
Die wichtigsten Punkte im Überblick:
- Architektur: ~1T Parameter MoE, 32-37B aktivierte Parameter pro Token, Fokus auf Effizienz
- Kontext: 1 Million Token, Engram-konditioniertes Gedächtnis erreicht 97 % Abrufgenauigkeit
- Multimodal: Native Unterstützung für Texteingabe, Bilderzeugung, Video und Audio
- Innovation: mHC-Trainingsstabilität + Engram-konditioniertes Gedächtnis + Sparse Attention
- Open Source: Voraussichtlich Apache 2.0, INT4-Quantisierung auf einer einzelnen RTX 5090 ausführbar
- Preisgestaltung: Voraussichtlich weiterhin das für DeepSeek typische, exzellente Preis-Leistungs-Verhältnis
Wir empfehlen die einheitliche Anbindung der gesamten DeepSeek-Modellreihe über APIYI (apiyi.com), um nach der Veröffentlichung von V4 sofortigen API-Zugriff zu erhalten.
Referenzmaterialien
- Dataconomy – Bericht zur Veröffentlichung von DeepSeek V4:
dataconomy.com/2026/03/16/deepseek-v4-and-tencents-new-hunyuan-model-to-launch-in-april/ - NxCode – Technische Spezifikationen zu DeepSeek V4:
nxcode.io/resources/news/deepseek-v4-release-specs-benchmarks-2026 - Offizielle DeepSeek-Dokumentation:
platform.deepseek.com/docs
Dieser Artikel wurde vom technischen Team von APIYI verfasst. Weitere Tutorials zur Nutzung von KI-Modellen finden Sie bei APIYI unter apiyi.com.