O DeepSeek V4 está prestes a ser lançado, adotando uma arquitetura MoE de cerca de 1 trilhão (1T) de parâmetros, com suporte a entrada multimodal nativa e uma janela de contexto ultralonga de 1 milhão de tokens. Após vários adiamentos, este aguardado Modelo de Linguagem Grande de código aberto tem previsão de estreia oficial para abril de 2026, competindo diretamente com as séries GPT-5.x, Claude 4 e Gemini 3.x.
Valor central: Entenda em 3 minutos a inovação arquitetônica, os parâmetros-chave e as capacidades multimodais do DeepSeek V4, além do seu impacto potencial no ecossistema de desenvolvedores.
Visão Geral das Informações Principais do DeepSeek V4
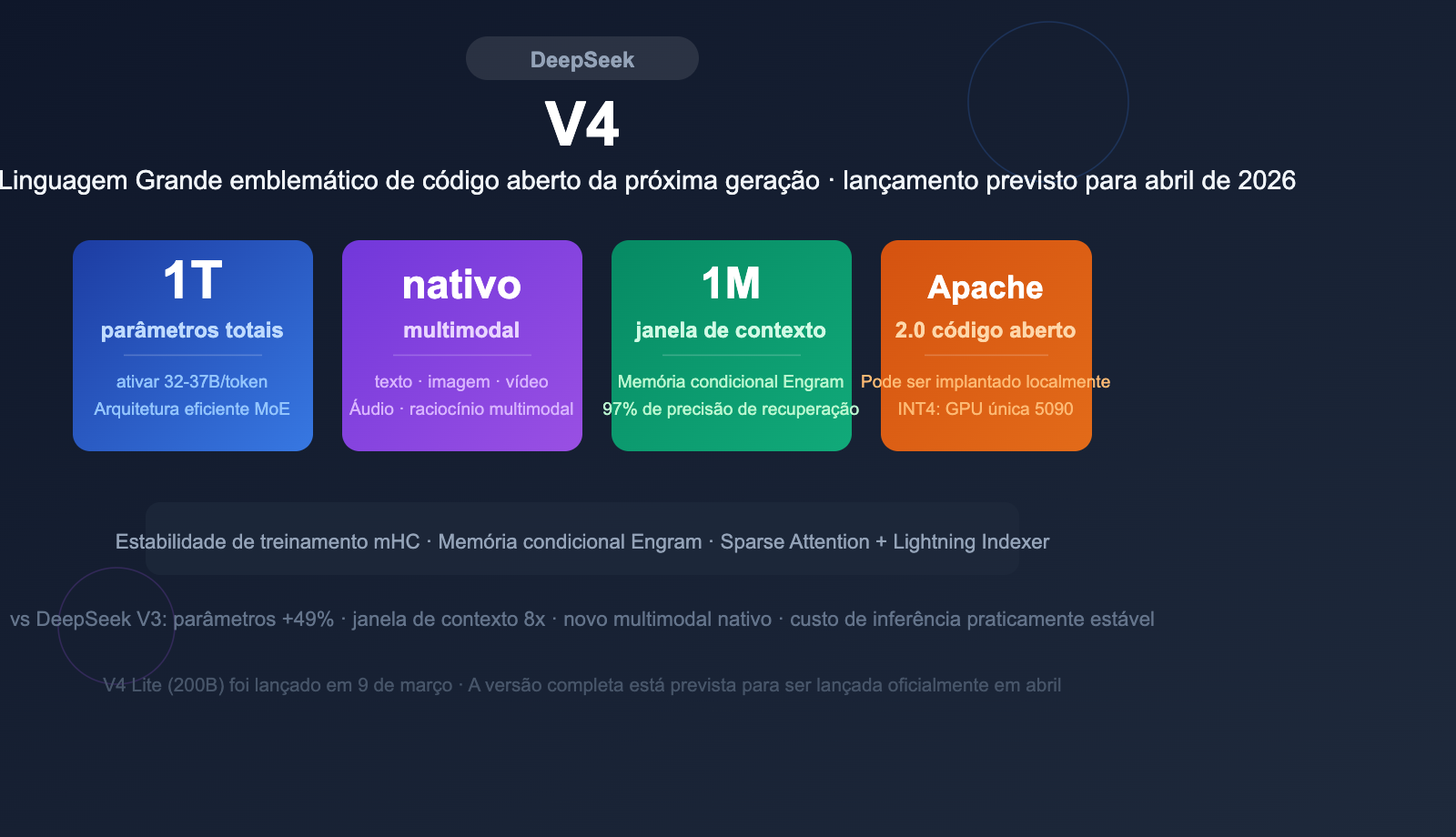
O DeepSeek V4 é o Modelo de Linguagem Grande emblemático de próxima geração que a DeepSeek planeja lançar. Pelas informações já divulgadas, o V4 alcançou um salto geracional em várias dimensões, como escala de parâmetros, design de arquitetura e capacidades multimodais.
| Item de Informação | DeepSeek V4 |
|---|---|
| Previsão de lançamento | Abril de 2026 |
| Total de parâmetros | Cerca de 1 trilhão (1T) |
| Parâmetros ativos por token | Cerca de 32-37B |
| Arquitetura | Transformer MoE + MLA (Multi-head Latent Attention) |
| Roteamento de especialistas | 16 especialistas ativados por token |
| Janela de contexto | 1 milhão de tokens (1M) |
| Multimodal | Suporte nativo para entrada de texto, imagem, vídeo e áudio |
| Licença de código aberto | Apache 2.0 (previsto) |
Comparação de Parâmetros-Chave: DeepSeek V4 vs V3
As atualizações principais do DeepSeek V4 em relação ao V3 são claras:
| Dimensão | DeepSeek V3 | DeepSeek V4 | Mudança |
|---|---|---|---|
| Total de parâmetros | 671B | ~1T | +49% |
| Parâmetros ativos | 37B | ~32-37B | Estável, foco em eficiência |
| Janela de contexto | 128K | 1M | Expansão de 8x |
| Multimodal | Apenas texto | Texto+Imagem+Vídeo+Áudio | Atualização multimodal completa |
| Mecanismo de atenção | MLA | MLA + Memória condicional Engram | Otimização para contexto longo |
| Estabilidade de treino | Padrão | mHC (Manifold-constrained Hyper-Connection) | Inovação arquitetônica |
Descoberta principal: Enquanto o número total de parâmetros do V4 aumentou 49%, o número de parâmetros ativos por token permaneceu praticamente inalterado (cerca de 32-37B). Isso significa que o custo de inferência não aumentará drasticamente, mas a capacidade de conhecimento e a generalização do modelo serão significativamente aprimoradas.
🎯 Sugestão técnica: Após o lançamento do DeepSeek V4, os desenvolvedores poderão acessar e testar o modelo imediatamente através da plataforma APIYI (apiyi.com). A plataforma já suporta a série completa de modelos, incluindo DeepSeek V3 e R1, e será rapidamente adaptada para o V4 assim que ele for lançado.
3 Inovações Arquiteturais do DeepSeek V4
O DeepSeek V4 não se trata apenas de um aumento na escala de parâmetros; ele introduz 3 inovações arquiteturais fundamentais que resolvem os principais desafios no treinamento e na inferência de modelos com trilhões de parâmetros.
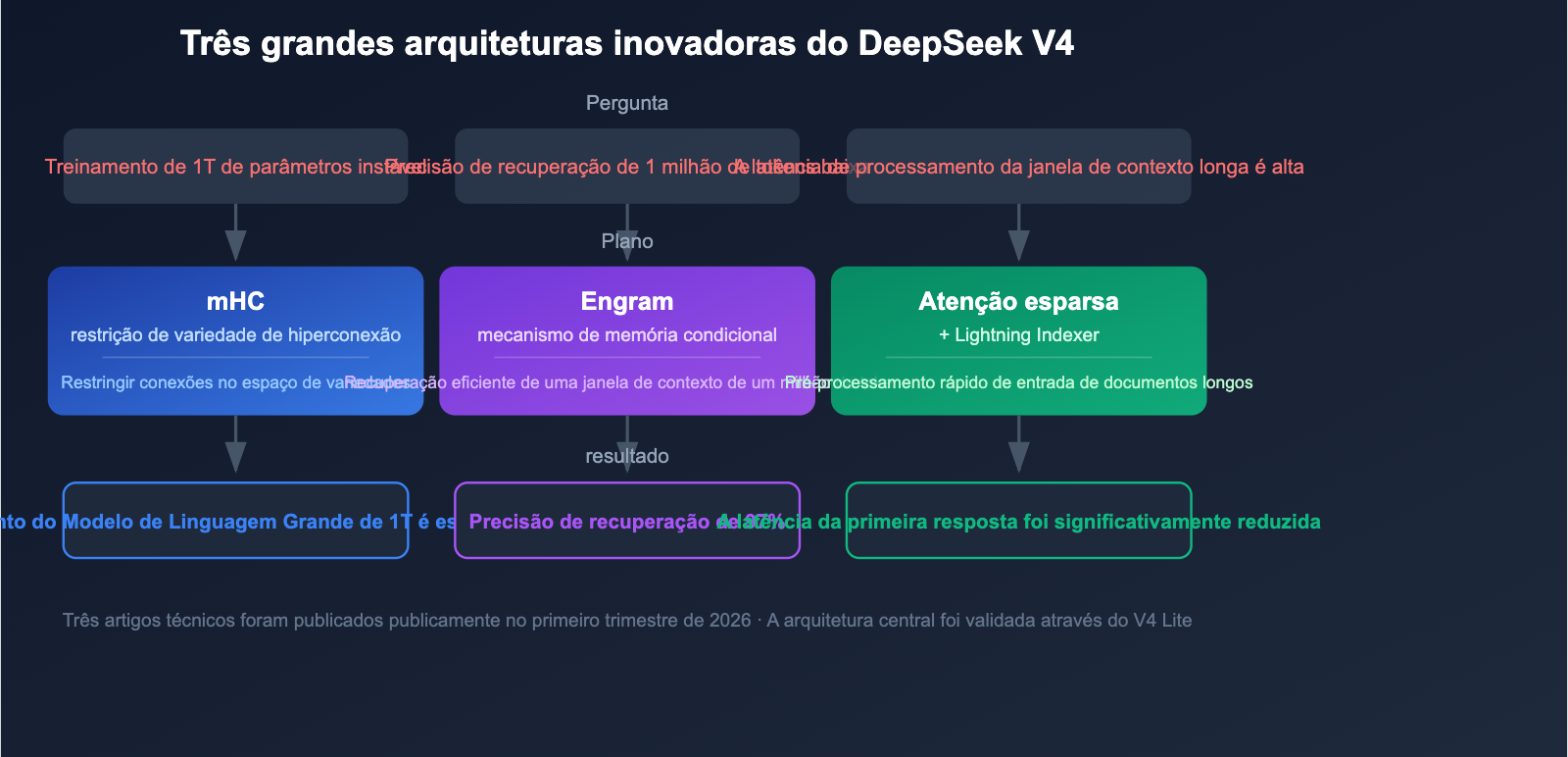
Inovação 1: Hiperconexões com Restrição de Variedade (mHC)
O DeepSeek publicou em 13 de janeiro de 2026 o artigo técnico sobre a tecnologia Manifold-Constrained Hyper-Connections (mHC). Esta tecnologia resolve especificamente o problema da estabilidade de treinamento de modelos MoE com trilhões de parâmetros.
Modelos MoE tradicionais de larga escala são propensos a problemas como explosão de gradiente e desequilíbrio de carga entre especialistas durante o treinamento. O mHC, ao restringir as hiperconexões no espaço de variedade, melhora significativamente a estabilidade do processo, tornando viável o treinamento de modelos na escala de 1 trilhão de parâmetros.
Inovação 2: Memória Condicional Engram
A memória condicional Engram é a tecnologia central que permite ao DeepSeek V4 atingir uma janela de contexto de 1 milhão de tokens. Os mecanismos de atenção tradicionais enfrentam desafios duplos de eficiência e precisão em contextos extremamente longos.
| Indicador | Atenção Padrão | Memória Condicional Engram |
|---|---|---|
| Precisão "Needle-in-a-Haystack" | 84,2% | 97% |
| Recuperação de contexto longo | Queda de desempenho notável | Consistente do início ao fim |
| Custo computacional | O(n²) | Redução significativa após otimização |
Uma precisão de 97% no teste "Needle-in-a-Haystack" significa que, mesmo em textos super longos de 1 milhão de tokens, o modelo consegue localizar e extrair informações cruciais com precisão.
Inovação 3: Atenção Esparsa + Lightning Indexer
A combinação da Atenção Esparsa do DeepSeek com o motor de pré-processamento Lightning Indexer permite um processamento de alta velocidade para contextos super longos. Essa tecnologia faz com que a entrada de 1 milhão de tokens não exija tempos de pré-processamento longos, reduzindo drasticamente a latência de resposta inicial para a análise de documentos extensos.
Análise das Capacidades Multimodais Nativas do DeepSeek V4
Uma das maiores mudanças no DeepSeek V4 é a transição de um modelo puramente de texto para um modelo multimodal nativo. Diferente de soluções multimodais montadas posteriormente, o V4 integra capacidades multimodais desde a fase de pré-treinamento.
Suporte a entradas multimodais
| Modalidade | Suporte | Observação |
|---|---|---|
| Texto | ✅ Nativo | Continua a poderosa capacidade de texto do V3 |
| Imagem | ✅ Nativo | Integrado no pré-treinamento, não é uma montagem posterior |
| Vídeo | ✅ Nativo | Compreensão e análise entre quadros |
| Áudio | ✅ Nativo | Compreensão de voz e sons |
| Raciocínio cross-modal | ✅ Nativo | Análise abrangente de informações multimodais |
Multimodalidade Nativa vs. Montagem Posterior
A multimodalidade nativa (integrada na fase de pré-treinamento) tem vantagens significativas sobre as soluções de montagem posterior:
- Compreensão cross-modal mais profunda: O modelo aprende a correlação entre diferentes modalidades durante o treinamento.
- Maior consistência de inferência: Informações de texto, imagem e vídeo podem participar perfeitamente da mesma cadeia de raciocínio.
- Menor taxa de alucinação: As informações multimodais se validam mutuamente, reduzindo alucinações de uma única modalidade.
- Menor latência: Não há necessidade de etapas extras de conversão de modalidade.
💡 Sugestão de uso: As capacidades multimodais nativas do DeepSeek V4 o tornam ideal para cenários que exigem a análise abrangente de múltiplas fontes de informação. Recomendamos o acesso unificado através da plataforma APIYI (apiyi.com), onde você pode comparar o desempenho real do DeepSeek V4 com outros modelos multimodais sob a mesma interface.
Cronograma de lançamento e contexto de adiamento do DeepSeek V4
O lançamento do DeepSeek V4 passou por vários adiamentos. Conhecer esse histórico ajuda a entender os desafios técnicos enfrentados pelo V4 e a maturidade do produto final.
Cronograma de lançamento
| Data | Evento |
|---|---|
| Início de janeiro de 2026 | Discussões sobre o V4 surgem na comunidade Reddit |
| 13 de janeiro de 2026 | Publicação do artigo técnico mHC, revelando inovações de arquitetura |
| 20 de janeiro de 2026 | Vazamento de código no GitHub, revelando 28 referências ao codinome interno "MODEL1" |
| Final de janeiro de 2026 | Primeira janela de lançamento prevista, não concretizada |
| 11 de fevereiro de 2026 | Capacidade de contexto de 1 milhão de tokens confirmada |
| Meados de fevereiro de 2026 | Vazamento de dados de benchmark |
| Final de fevereiro de 2026 | Janela de lançamento pós-Ano Novo Chinês, novo adiamento |
| 9 de março de 2026 | Lançamento do V4 Lite (~200B de parâmetros, validação da arquitetura central) |
| Abril de 2026 | Previsão de lançamento da versão completa do V4 |
Principais motivos do adiamento
Os principais motivos para os sucessivos adiamentos do V4 estão relacionados aos desafios da infraestrutura de treinamento:
- Problemas de adaptação de hardware: Treinar modelos com trilhões de parâmetros em chips nacionais enfrenta desafios de estabilidade.
- Largura de banda de interconexão de chips: O treinamento distribuído em larga escala exige uma largura de banda de comunicação extremamente alta entre os chips.
- Maturidade do ecossistema de software: As ferramentas de otimização e os frameworks de treinamento ainda estão em fase de iteração.
Vale notar que o V4 Lite (aprox. 200B de parâmetros) foi lançado antecipadamente em 9 de março como uma versão de validação de arquitetura para o V4 completo. Essa medida indica que a arquitetura central já foi validada, e o adiamento da versão completa deve-se principalmente a questões de engenharia de treinamento em larga escala.
Previsão de preços da API do DeepSeek V4
Com base na estratégia de preços consistente do DeepSeek e nas características da arquitetura do V4, podemos fazer uma previsão razoável para os preços da API do V4.
Preços atuais da API do DeepSeek
| Modelo | Entrada (Cache Miss) | Entrada (Cache Hit) | Saída | Janela de contexto |
|---|---|---|---|---|
| deepseek-chat (V3.2) | $0.28/M | $0.028/M | $0.42/M | 128K |
| deepseek-reasoner (V3.2) | $0.28/M | $0.028/M | $0.42/M | 128K |
Previsão de preços do DeepSeek V4
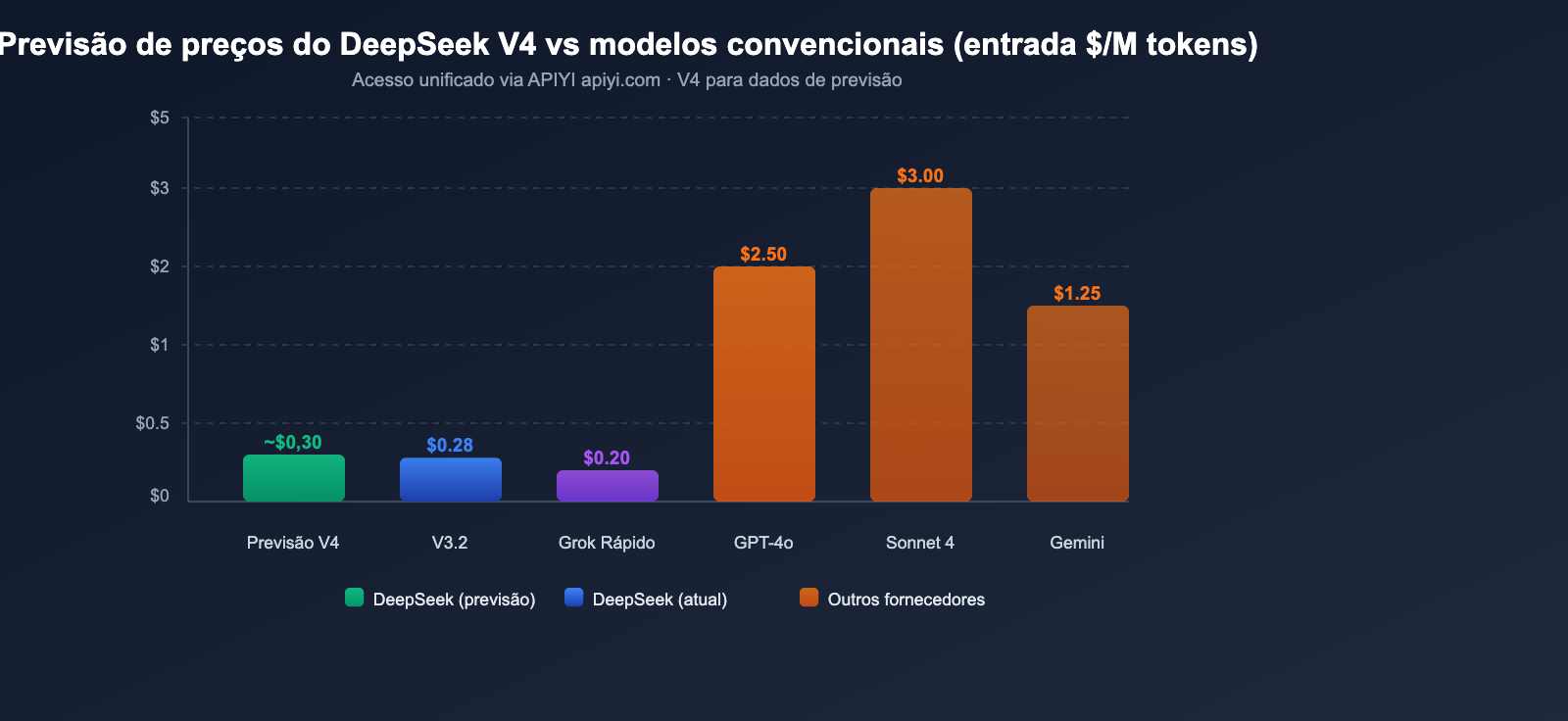
Com base na análise de várias fontes, espera-se que o preço do V4 fique na seguinte faixa:
| Cenário de previsão | Preço de entrada | Preço de saída | Base |
|---|---|---|---|
| Previsão otimista | ~$0.14/M | ~$0.28/M | Parâmetros ativos inalterados, maior eficiência |
| Previsão neutra | ~$0.30/M | ~$0.50/M | 1M de contexto traz custo computacional extra |
| Previsão conservadora | ~$0.50/M | ~$0.80/M | Processamento multimodal aumenta os custos |
Mesmo na previsão conservadora, o preço de entrada de $0,50/M é extremamente competitivo para um Modelo de Linguagem Grande multimodal com trilhões de parâmetros. Para comparação, o preço de entrada do GPT-4o é de $2,50/M e o do Claude Opus 4 é de $15,00/M.
💰 Otimização de custos: A série DeepSeek é conhecida por sua excelente relação custo-benefício. Através da plataforma APIYI (apiyi.com), os desenvolvedores podem usar uma interface unificada para invocar o DeepSeek e outros modelos principais simultaneamente, encontrando o melhor equilíbrio entre custo e desempenho.
Análise do cenário competitivo do DeepSeek V4
Abril de 2026 é um período de lançamentos intensos de grandes modelos de linguagem. O DeepSeek V4 enfrentará concorrência de várias frentes.
Comparação com concorrentes do mesmo período
| Modelo | Fabricante | Escala de parâmetros | Contexto | Multimodal | Código aberto |
|---|---|---|---|---|---|
| DeepSeek V4 | DeepSeek | ~1T (MoE) | 1M | ✅ Nativo | ✅ Apache 2.0 |
| GPT-5.x | OpenAI | Não divulgado | Não divulgado | ✅ | ❌ |
| Série Claude 4 | Anthropic | Não divulgado | 1M | ✅ | ❌ |
| Gemini 3.x | Não divulgado | 2M | ✅ | ❌ | |
| Grok 4.x | xAI | Não divulgado | 2M | ✅ | ❌ |
Vantagens diferenciais do DeepSeek V4
- Código aberto: Espera-se que adote a licença Apache 2.0, o que é quase único para modelos na escala de trilhões de parâmetros.
- Custo-benefício extremo: A estratégia de preços da DeepSeek sempre foi a mais baixa entre modelos do mesmo nível.
- Possibilidade de implantação local: Ser código aberto significa que as empresas podem implantar o modelo em sua própria infraestrutura.
- Eficiência MoE: Com parâmetros ativos de apenas 32-37B, a eficiência de inferência é muito superior à de modelos densos com a mesma quantidade de parâmetros.
Requisitos de hardware para implantação local do DeepSeek V4
Para equipes que desejam realizar a implantação local, os requisitos de hardware para o V4 são os seguintes:
| Método de quantização | VRAM necessária | Hardware recomendado |
|---|---|---|
| FP16/BF16 (Precisão total) | Extremamente alta | Cluster de GPU com múltiplos nós |
| INT8 (Quantização de 8 bits) | ~48GB | Duas RTX 4090 |
| INT4 (Quantização de 4 bits) | ~32GB | Uma RTX 5090 |
Após a quantização INT4, é possível rodar o modelo em uma única RTX 5090, tornando a implantação local viável para pequenas e médias equipes e pesquisadores.
Evolução das versões do modelo DeepSeek
Entender a evolução completa dos produtos da DeepSeek ajuda a compreender o posicionamento e a rota tecnológica do V4.

| Versão | Data de lançamento | Principais características |
|---|---|---|
| V1 | Novembro de 2023 | Primeiro modelo de código aberto |
| V2 | Maio de 2024 | Introdução da arquitetura MoE, redução drástica de custos |
| V2.5 | Setembro de 2024 | Melhoria nas capacidades de diálogo e código |
| V3 | Dezembro de 2024 | 671B de parâmetros, atenção MLA, 128K de contexto |
| R1 | Janeiro de 2025 | Modelo especializado em raciocínio, tecnologia de cadeia de pensamento |
| V3.1 | Agosto de 2025 | Otimização de desempenho, reforço de raciocínio |
| V3.2 | Final de 2025 | Modelo principal atual, suporte ao modo Thinking |
| V4 Lite | Março de 2026 | ~200B de parâmetros, versão de validação de arquitetura |
| V4 | Abril de 2026 (previsto) | ~1T MoE, multimodal nativo, 1M de contexto |
Desde a introdução da arquitetura MoE no V2, passando pela atenção MLA no V3, até às tecnologias mHC e Engram no V4, cada geração de produtos da DeepSeek trouxe inovações substanciais ao nível da arquitetura.
🎯 Sugestão técnica: Enquanto aguarda o lançamento oficial do V4, os desenvolvedores podem começar a desenvolver usando o DeepSeek V3.2 e o R1 através da plataforma APIYI (apiyi.com). Assim que o V4 for lançado, a plataforma o integrará imediatamente.
Perguntas Frequentes
Q1: Quando o DeepSeek V4 será lançado oficialmente?
De acordo com informações compiladas de várias fontes, o DeepSeek V4 está previsto para ser lançado em abril de 2026. Anteriormente, o lançamento sofreu dois adiamentos, no final de janeiro e no final de fevereiro. A versão V4 Lite (~200B de parâmetros), lançada em 9 de março, validou a viabilidade da arquitetura principal, tornando a probabilidade de lançamento da versão completa bastante alta. Você pode obter acesso à API do V4 em primeira mão através da plataforma APIYI apiyi.com.
Q2: O 1T de parâmetros do DeepSeek V4 significa que o custo de inferência será muito alto?
Não necessariamente. O V4 adota uma arquitetura MoE, onde cada token ativa apenas cerca de 32-37B de parâmetros, mantendo-se basicamente no mesmo nível do V3. Isso significa que o volume de cálculo real durante a inferência não aumentará drasticamente, e espera-se que o custo permaneça dentro de uma faixa razoável. A estratégia de preços da DeepSeek é consistentemente agressiva, e espera-se que o preço da API do V4 continue extremamente competitivo.
Q3: O modelo de raciocínio DeepSeek R2 ainda será lançado?
A data de lançamento do DeepSeek R2 ainda não está clara. Algumas análises sugerem que a capacidade de raciocínio do R2 pode ter sido integrada diretamente ao V4 (o V3.2 já suporta o modo Thinking). Outras opiniões indicam que o R2 ainda está em desenvolvimento independente, mas enfrentando desafios de treinamento. Recomendamos acompanhar os canais oficiais da DeepSeek para obter as informações mais recentes.
Q4: O que os desenvolvedores devem preparar antes do lançamento do V4?
Recomendamos familiarizar-se com o método de invocação da API da DeepSeek com antecedência. É muito provável que o V4 seja compatível com a interface padrão da OpenAI, tornando o custo de migração muito baixo. Utilize o DeepSeek V3.2 através da plataforma APIYI apiyi.com para desenvolvimento e testes; assim que o V4 for lançado, bastará alternar o nome do modelo.
Resumo
O DeepSeek V4 promete ser um dos lançamentos de Modelo de Linguagem Grande de código aberto mais importantes de 2026. Com uma arquitetura MoE de cerca de 1T de parâmetros, uma janela de contexto ultralonga de 1 milhão de tokens, suporte multimodal nativo, além da licença de código aberto Apache 2.0 e uma relação custo-benefício extrema, o V4 é altamente aguardado tanto em indicadores técnicos quanto em valor comercial.
Revisão dos pontos principais:
- Arquitetura: ~1T de parâmetros MoE, ativando 32-37B por token, priorizando a eficiência
- Contexto: 1 milhão de tokens, com memória condicional Engram alcançando 97% de precisão na recuperação
- Multimodal: Suporte nativo para entrada de texto, imagem, vídeo e áudio
- Inovação: Estabilidade de treinamento mHC + memória condicional Engram + atenção esparsa
- Código aberto: Esperado sob licença Apache 2.0, com quantização INT4 capaz de rodar em uma única RTX 5090
- Preço: Espera-se que mantenha a relação custo-benefício extrema característica da DeepSeek
Recomendamos acessar toda a série de modelos DeepSeek através da APIYI apiyi.com para garantir o acesso à API assim que o V4 for lançado.
Referências
- Dataconomy – Relatório de lançamento do DeepSeek V4:
dataconomy.com/2026/03/16/deepseek-v4-and-tencents-new-hunyuan-model-to-launch-in-april/ - NxCode – Especificações técnicas do DeepSeek V4:
nxcode.io/resources/news/deepseek-v4-release-specs-benchmarks-2026 - Documentação oficial do DeepSeek:
platform.deepseek.com/docs
Este artigo foi escrito pela equipe técnica da APIYI. Para mais tutoriais sobre o uso de Modelos de Linguagem Grande, acompanhe a APIYI em apiyi.com.