Want to use AI to batch-generate 2K HD videos with native audio, but found out the Seedance 2.0 API hasn't officially launched yet? That's the dilemma many developers and content creators are facing right now. In this post, we'll give you a comprehensive breakdown of the 5 core capabilities of Seedance 2.0, helping you get a head start on the technical architecture and API integration methods for ByteDance's latest video generation model.
Core Value: By the end of this article, you'll have a full understanding of Seedance 2.0's technical capabilities, API integration methods, and best practices, so you can hit the ground running as soon as the API officially opens.
Seedance 2.0 API: Quick Look
Before we dive into the technical details, let's take a quick look at the key specs for Seedance 2.0.
| Feature | Details |
|---|---|
| Model Name | Seedance 2.0 (ByteDance Seed Series) |
| Publisher | ByteDance |
| Expected API Launch | February 24, 2025 (Volcengine/BytePlus) |
| Current Channels | Jimeng (Dreamina) website, Volcengine/BytePlus console debugging |
| Output Resolution | Up to 2K (supports 1080p production-grade output) |
| Video Duration | 4-15 seconds |
| Supported Aspect Ratios | 16:9, 9:16, 4:3, 3:4, 21:9, 1:1 |
| Input Modalities | Text + Images (0-5) + Video + Audio |
| Native Audio | Supports synchronized generation of dialogue, ambient sound, and SFX |
| Available Platforms | Jimeng, Volcengine, APIYI (apiyi.com) (supported simultaneously once API is live) |
🎯 Important Note: The Seedance 2.0 API is expected to launch on February 24th. At that time, developers can quickly integrate via the APIYI (apiyi.com) platform using a unified interface, without needing to interface with Volcengine separately.
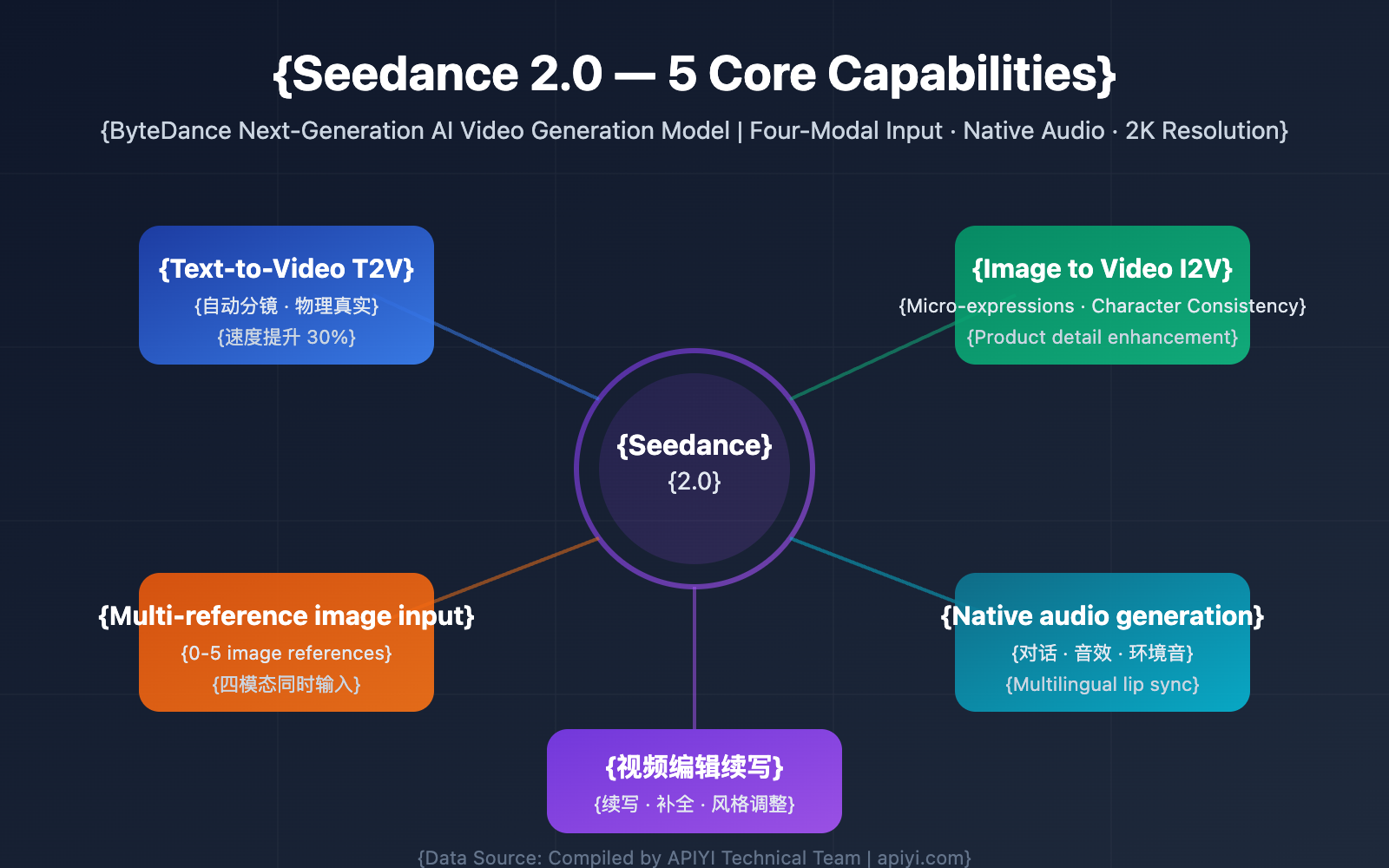
5 Core Capabilities of the Seedance 2.0 API
Seedance 2.0 is a massive upgrade over the previous Seedance 1.5 Pro. Here are the 5 core capabilities that developers care about most.
Seedance 2.0 Core Capability 1: Text-to-Video
Seedance 2.0's Text-to-Video capability is its most fundamental yet powerful feature. All you need to do is enter a text description, and the model generates high-quality video content.
Key improvements over version 1.5:
| Improvement Dimension | Seedance 1.5 Pro | Seedance 2.0 | Improvement Level |
|---|---|---|---|
| Physical Realism | Basic physics simulation | Precise gravity, momentum, and causality | Significant boost |
| Motion Dynamics | Smooth but occasionally unnatural | Highly natural motion continuity | Significant boost |
| Visual Aesthetics | HD quality | Cinematic aesthetic quality | Noticeable improvement |
| Resolution | 1080p | Up to 2K | Doubled resolution |
| Scene Generation | Primarily single scenes | Automatic scene/storyboard generation | New capability |
| Generation Speed | Standard speed | ~30% faster | Efficiency boost |
Seedance 2.0's understanding of physical laws has reached a whole new level—gravity, momentum, and causality remain accurate even in complex action sequences. This means the motion trajectories, collision effects, and environmental interactions in your generated videos are much more realistic and believable.
The Automatic Storyboarding feature is a major highlight of Seedance 2.0's Text-to-Video. The model can automatically break down a narrative text into multiple coherent shots, ensuring character appearance, environmental details, and narrative consistency are maintained across different scenes.
Seedance 2.0 Core Capability 2: Image-to-Video
Image-to-Video is the ability to transform static reference images into dynamic videos. Seedance 2.0 has made a qualitative leap in this area.
Core upgrade points:
- Micro-expression Optimization: Subtle facial expressions are more delicate and natural, with smooth transitions for blinking, smiling, and frowning.
- Motion Continuity: Transitions from static images to dynamic video are more natural, without frame skipping or jitter.
- Character Consistency: Facial features, clothing, and body type remain consistent across different angles and multi-shot sequences.
- Object Consistency: The shape, position, and lighting of objects in the scene stay stable.
- Scene Coherence: Background environments don't change abruptly during video playback.
- Product Detail Performance: Significantly enhanced ability to restore textures, logos, packaging, and other fine details.

🎯 Business Tip: Seedance 2.0's enhanced product detail performance makes it perfect for e-commerce product videos. By calling the Seedance 2.0 API via APIYI (apiyi.com), you can generate showcase videos for your products in bulk.
Seedance 2.0 Core Capability 3: Multi-Reference and Multi-Modal Input
This is one of Seedance 2.0's most differentiating capabilities. The model supports simultaneous input from multiple modalities, allowing for precise creative control.
Four-Modal Input System:
| Input Modality | Quantity Supported | Purpose |
|---|---|---|
| Image | 0-5 (up to 9) | Character, scene, and style reference |
| Video | Up to 3 (total duration ≤15s) | Motion and camera movement reference |
| Audio | Up to 3 (MP3, total duration ≤15s) | Rhythm, dialogue, and ambient sound reference |
| Text | Natural language description | Scene description, action commands, style specification |
The Multi-reference Search Capability is a unique advantage of Seedance 2.0. You can provide 0-5 reference images, and the model extracts key features to fuse them into the generated video. For example:
- Provide 1 face image + 1 motion video + 1 audio rhythm → Generate a video of a specific character dancing to the beat.
- Provide 3 product images from different angles → Generate a 360-degree rotating product showcase video.
- Provide 1 scene image + text description → Generate a video with specific actions in a designated scene.
Seedance 2.0 Core Capability 4: Native Audio Generation
Seedance 2.0 features an industry-first: native Audio-Visual Co-generation, synchronizing video frames and audio content in a single inference process.
Audio Capability Highlights:
- Dialogue Generation: Supports multi-language speech generation (Chinese, English, Spanish, etc.) with precise lip-sync.
- Ambient Sound Effects: Automatically generates ambient sounds that match the visuals (wind, water, city noise, etc.).
- Sound Effect Sync: Action sounds (footsteps, collisions, etc.) are precisely synchronized with the visual movement.
- Reference Real Voice: Supports reference real voice input for more than 2 subjects.
- Voice Accuracy: Significant improvements in speech generation accuracy for languages like Chinese, English, and Spanish.
- No Post-Production: Traditional workflows require adding sound effects and dubbing separately; Seedance 2.0 does it all in one go.
This means developers can get a complete video file with full audio through a single API call, greatly simplifying the content production workflow.
Seedance 2.0 Core Capability 5: Video Editing and Extension
Beyond generating videos from scratch, Seedance 2.0 also supports editing and extending existing videos.
| Editing Capability | Description | Constraints |
|---|---|---|
| Video Extension | Naturally extends visuals and plot based on existing video | Input video ≤15s |
| Video Completion | Intelligently fills in missing parts of a video | Input video ≤15s |
| Limited Editing | Adjusts style, tone, etc., for short videos | Input video <15s |
| Simultaneous Input | Supports inputting both images and videos as references | Limits on total number of images + videos |
Seedance 2.0 API Integration Tutorial
Seedance 2.0 API Current Status
As of the time of publication (February 2025), the status of the Seedance 2.0 API is as follows:
- Volcengine: Not yet officially launched; online debugging is available in the console.
- BytePlus (International Version): Not yet officially launched; online debugging is available in the console.
- Dreamina: Available for experience on the web version.
- Official API Launch: Expected February 24, 2025.
If you're already using the Seedance 1.5 Pro or Seedream 4.5 API, the good news is that the Seedance 2.0 API interface remains highly compatible, so migration costs are minimal.
Seedance 2.0 API Quick Start Code
Here’s a basic code example for calling the Seedance 2.0 API (based on the Volcengine API style, ready for use once the API officially launches):
Text-to-Video (T2V) Minimalist Example
import requests
import json
# Calling Seedance 2.0 API via APIYI
API_BASE = "https://api.apiyi.com/v1"
API_KEY = "your-api-key"
def text_to_video(prompt, aspect_ratio="16:9", duration=5):
"""Seedance 2.0 Text-to-Video Call"""
response = requests.post(
f"{API_BASE}/video/generations",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={
"model": "seedance-2.0",
"prompt": prompt,
"aspect_ratio": aspect_ratio,
"duration": duration,
"audio": True # Enable native audio generation
}
)
return response.json()
# Generate a video with audio
result = text_to_video(
prompt="A Golden Retriever running on a sandy beach, sunlight sparkling on the sea, waves crashing against the shore",
aspect_ratio="16:9",
duration=8
)
print(f"Video URL: {result['data']['url']}")
print(f"Audio generated synchronously: {result['data']['has_audio']}")
View Full Image-to-Video (I2V) Code
import requests
import json
import base64
from pathlib import Path
API_BASE = "https://api.apiyi.com/v1"
API_KEY = "your-api-key"
def image_to_video(image_paths, prompt, aspect_ratio="16:9", duration=5):
"""
Seedance 2.0 Image-to-Video Call
Supports 0-5 reference image inputs
"""
# Encode reference images
images = []
for path in image_paths:
with open(path, "rb") as f:
img_data = base64.b64encode(f.read()).decode()
images.append({
"type": "image",
"data": img_data
})
response = requests.post(
f"{API_BASE}/video/generations",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={
"model": "seedance-2.0",
"prompt": prompt,
"references": images,
"aspect_ratio": aspect_ratio,
"duration": duration,
"audio": True,
"resolution": "2k" # Use 2K resolution
}
)
result = response.json()
if result.get("status") == "processing":
task_id = result["data"]["task_id"]
print(f"Task submitted, ID: {task_id}")
# Asynchronous tasks require polling for results
return poll_result(task_id)
return result
def poll_result(task_id, max_wait=300):
"""Poll to get video generation results"""
import time
for _ in range(max_wait // 5):
time.sleep(5)
resp = requests.get(
f"{API_BASE}/video/generations/{task_id}",
headers={"Authorization": f"Bearer {API_KEY}"}
)
data = resp.json()
if data["data"]["status"] == "completed":
return data
elif data["data"]["status"] == "failed":
raise Exception(f"Generation failed: {data['data']['error']}")
raise TimeoutError("Wait timeout")
# Example usage: Generate a showcase video from product photos
result = image_to_video(
image_paths=["product_front.jpg", "product_side.jpg"],
prompt="360-degree rotating product display, soft lighting, white background",
aspect_ratio="1:1",
duration=6
)
print(f"Video generated: {result['data']['url']}")
🚀 Quick Start: We recommend using the APIYI (apiyi.com) platform to access the Seedance 2.0 API. It provides a unified interface compatible with Volcengine, allowing you to complete integration in 5 minutes without needing a separate Volcengine account.
Seedance 2.0 vs. Mainstream AI Video Models
Understanding Seedance 2.0's position in the current AI video generation landscape will help you make better technical choices.
| Comparison Dimension | Seedance 2.0 | Sora 2 | Kling 3.0 | Veo 3.1 |
|---|---|---|---|---|
| Max Resolution | 2K | 1080p | 1080p | 1080p |
| Video Duration | 4-15s | 5-20s | 5-10s | 5-8s |
| Native Audio | ✅ Fully Supported | ✅ Supported | ❌ Not Supported | ✅ Supported |
| Multi-Reference Input | ✅ 0-5 images | ❌ Not Supported | ✅ 1-2 images | ❌ Not Supported |
| Multimodal Input | Quad-modal (Text/Img/Vid/Aud) | Text/Img | Text/Img | Text/Img |
| Physical Realism | Excellent | Top-tier | Excellent | Excellent |
| Motion Naturalness | Excellent | Excellent | Top-tier | Excellent |
| Multi-Shot Narrative | ✅ Auto-storyboarding | ✅ Supported | ❌ Not Supported | ✅ Supported |
| Video Editing | ✅ Limited Support | ✅ Supported | ❌ Not Supported | ❌ Not Supported |
| Generation Speed | Fast (5s video < 60s) | Slower | Fast | Medium |
| API Availability | Launching Feb 24 | Live | Live | Live |
| Available Platforms | Volcengine, APIYI apiyi.com | OpenAI | Kuaishou |
Unique Advantages of Seedance 2.0
Seedance 2.0 offers distinct advantages in three key areas:
- Quad-Modal Input System: Currently the only video generation model supporting simultaneous input of text, images, video, and audio, providing creative control precision far beyond its peers.
- Multi-Reference Image Support: Supports feature extraction and fusion from 0-5 reference images, making it ideal for commercial applications requiring precise character and scene control.
- Native 2K Resolution: Offers the highest output resolution among similar models, meeting the needs of professional-grade content production.
💡 Selection Advice: The best video model depends on your specific use case. If you need precise multimodal control and 2K resolution, Seedance 2.0 is your best bet. We recommend testing multiple models via the APIYI (apiyi.com) platform, which supports unified API calls for Seedance 2.0, Sora 2, and other mainstream models, making it easy to compare results quickly.
Seedance 2.0 API Typical Application Scenarios
Seedance 2.0's multimodal capabilities make it a perfect fit for a wide range of commercial and creative scenarios.
E-commerce Product Videos
With image-to-video and multi-reference image capabilities, merchants can quickly turn a few product photos into high-quality showcase videos. Seedance 2.0’s enhanced detail rendering is especially impressive, as it can accurately reproduce product textures, logos, and packaging.
Short Video Content Creation
The text-to-video automatic storyboarding and native audio generation allow creators to generate short videos—complete with full voiceovers and sound effects—from just a single text description. This significantly lowers the barrier to entry for content production.
Digital Humans and Virtual Streamers
Seedance 2.0 features micro-expression optimization and multi-language voice generation (supporting Chinese, English, Spanish, and more). When combined with reference voice input, you can generate digital human videos with rich expressions and precise lip-syncing.
Batch Generation of Ad Creatives
By combining multi-reference image inputs with video editing capabilities, advertising teams can quickly generate multiple versions of an ad video based on the same set of assets, making A/B testing much more efficient.
Seedance 2.0 API FAQ
Q1: When will the Seedance 2.0 API be officially available?
According to internal sources, the Seedance 2.0 API is expected to officially launch on February 24, 2025. At that time, API services will be provided through Volcano Engine (Volcano Ark) and BytePlus. If you want to use it as soon as possible, we recommend following the APIYI (apiyi.com) platform. They'll provide a unified interface for Seedance 2.0 as soon as the API goes live.
Q2: Is the cost of migrating from Seedance 1.5 Pro to 2.0 high?
Migration costs are actually very low. The Seedance 2.0 API is designed to be highly compatible with 1.5 Pro. The main changes involve new parameters for things like multi-reference images and audio input. Your existing text-to-video and image-to-video calling code should run on 2.0 with almost no modifications.
Q3: What is the pricing for the Seedance 2.0 API?
Official pricing for Seedance 2.0 hasn't been released yet. Based on the Seedance 1.5 Pro pricing structure, it's expected to be billed based on video duration and resolution. You should keep an eye on the APIYI (apiyi.com) platform for the latest pricing updates, as they often offer more flexible billing options.
Q4: Is there any way to try Seedance 2.0 early?
You can experience it through the following channels:
- Jimeng (Dreamina) Website: Visit the official Jimeng site at
jimeng.jianying.comto use Seedance 2.0 directly online. - Volcano Engine Backend: Log in to the Volcano Engine console and perform online tests in the model debugging area.
- BytePlus Backend: International users can debug and experience it via the BytePlus console.
Q5: Which languages does Seedance 2.0 support for audio generation?
Seedance 2.0's native audio generation supports multiple languages, including Chinese, English, and Spanish. There's been a significant improvement in accuracy across these languages, particularly in lip-sync precision and natural intonation.
Seedance 2.0 API Integration Summary
Seedance 2.0, ByteDance's latest generation video model, has made significant breakthroughs in multi-modal input, native audio, and 2K resolution. In particular, its four-modal input system and multi-reference image search capabilities provide developers with unprecedented precision in creative control.
Key Highlights:
- Supports four-modal input: Text + Images (0-5) + Video + Audio.
- Native 2K resolution output with a 30% boost in generation speed.
- Industry-first synchronous audio-video co-generation—get a complete video with a single API call.
- Multi-shot automatic storyboard narrative, maintaining high consistency across characters and scenes.
- API is expected to launch on February 24th and is highly compatible with 1.5 Pro interfaces.
We recommend using APIYI (apiyi.com) for quick access to the Seedance 2.0 API. The platform supports calling multiple mainstream video generation models through a unified interface, making it easy to compare results and choose the best solution for your project.
This article was written by the APIYI technical team, focusing on the latest trends in the AI video generation field. For more AI model tutorials, please visit the APIYI (apiyi.com) Help Center.
References
-
Official Seedance Introduction: ByteDance Seed Series Model Documentation
- Link:
byteplus.com/en/product/seedance
- Link:
-
Dreamina Platform: Online experience portal for Seedance 2.0
- Link:
jimeng.jianying.com
- Link:
-
Volcengine ModelArk: Model release notes
- Link:
docs.byteplus.com/en/docs/ModelArk/1159178
- Link: