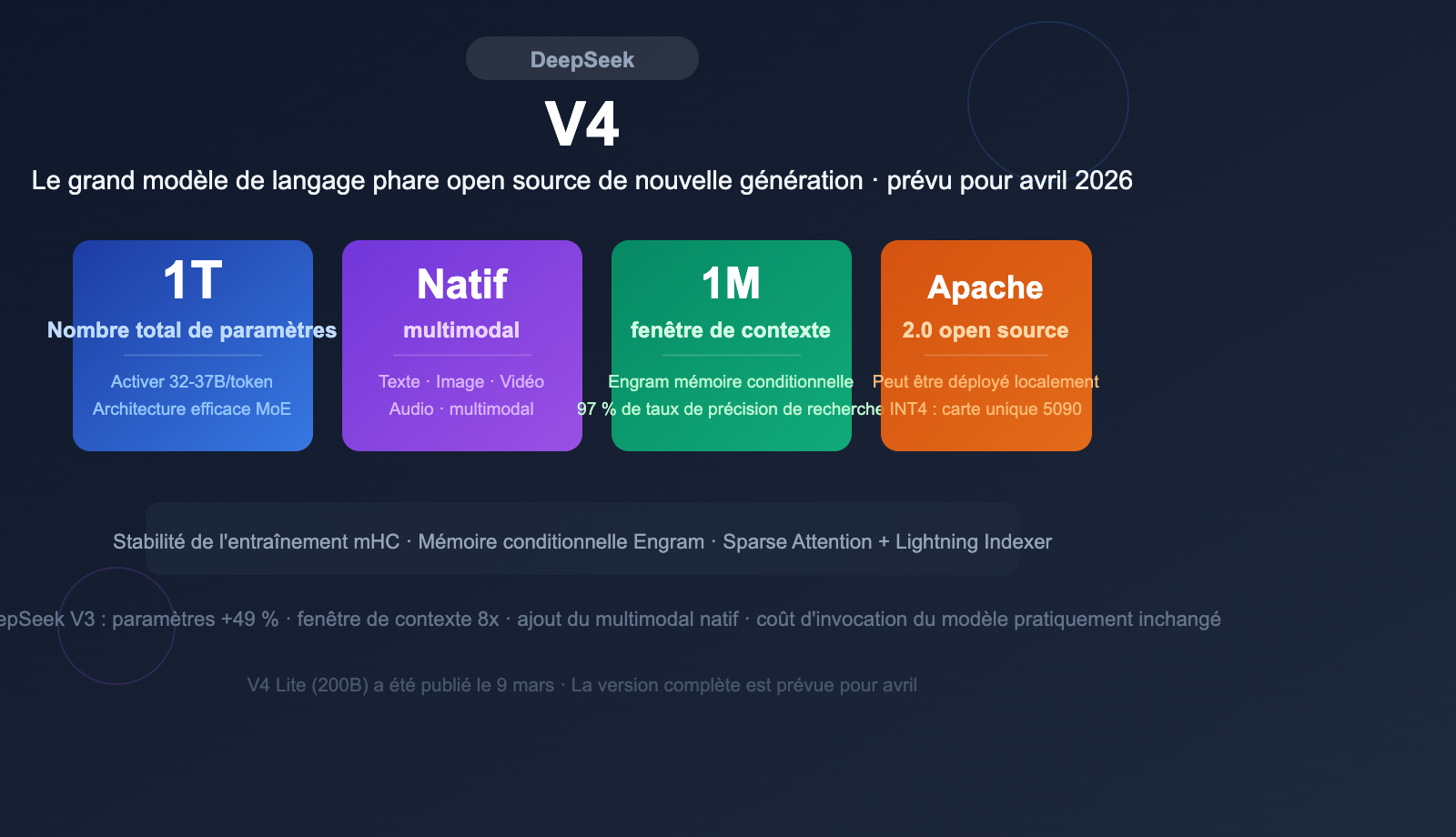
DeepSeek V4 arrive bientôt : il adopte une architecture MoE d'environ 1 000 milliards (1T) de paramètres, prend en charge l'entrée multimodale native et une fenêtre de contexte ultra-longue de 1 million de jetons. Après plusieurs reports, ce grand modèle de langage open source très attendu devrait faire ses débuts officiels en avril 2026, pour rivaliser avec les séries GPT-5.x, Claude 4 et Gemini 3.x.
Valeur ajoutée : 3 minutes pour comprendre les innovations architecturales, les paramètres clés et les capacités multimodales de DeepSeek V4, ainsi que son impact potentiel sur l'écosystème des développeurs.
Aperçu des informations clés sur DeepSeek V4
DeepSeek V4 est le grand modèle de langage phare de nouvelle génération que DeepSeek prévoit de lancer. D'après les informations rendues publiques, la version V4 marque un saut générationnel en termes de taille de paramètres, de conception d'architecture et de capacités multimodales.
| Informations | DeepSeek V4 |
|---|---|
| Lancement prévu | Avril 2026 |
| Nombre total de paramètres | ~1 000 milliards (1T) |
| Paramètres activés par jeton | ~32-37B |
| Architecture | Transformer MoE + MLA (Multi-head Latent Attention) |
| Routage des experts | 16 experts activés par jeton |
| Fenêtre de contexte | 1 million de jetons (1M) |
| Multimodal | Support natif des entrées texte, image, vidéo et audio |
| Licence open source | Apache 2.0 (prévu) |
Comparaison des paramètres clés : DeepSeek V4 vs V3
Les améliorations majeures de DeepSeek V4 par rapport à la V3 sont évidentes :
| Dimension | DeepSeek V3 | DeepSeek V4 | Évolution |
|---|---|---|---|
| Paramètres totaux | 671B | ~1T | +49% |
| Paramètres activés | 37B | ~32-37B | Stable, priorité à l'efficacité |
| Fenêtre de contexte | 128K | 1M | Extension x8 |
| Multimodal | Texte uniquement | Texte+Image+Vidéo+Audio | Mise à niveau complète |
| Mécanisme d'attention | MLA | MLA + Mémoire conditionnelle Engram | Optimisation du contexte long |
| Stabilité de l'entraînement | Standard | mHC (Manifold-constrained Hyper-Connection) | Innovation architecturale |
Constat clé : Alors que le nombre total de paramètres augmente de 49 %, DeepSeek V4 maintient un nombre de paramètres activés par jeton quasi identique (environ 32-37B). Cela signifie que les coûts d'inférence ne devraient pas exploser, tout en offrant une capacité de connaissances et une généralisation nettement supérieures.
🎯 Conseil technique : Dès la sortie de DeepSeek V4, les développeurs pourront le tester immédiatement via la plateforme APIYI (apiyi.com). Cette plateforme prend déjà en charge la gamme complète des modèles DeepSeek V3 et R1, et sera rapidement adaptée pour intégrer la V4.
3 percées technologiques majeures dans l'architecture de DeepSeek V4
DeepSeek V4 ne se limite pas à une simple augmentation du nombre de paramètres ; il introduit trois innovations architecturales clés qui résolvent les défis fondamentaux de l'entraînement et de l'inférence des modèles à mille milliards de paramètres.
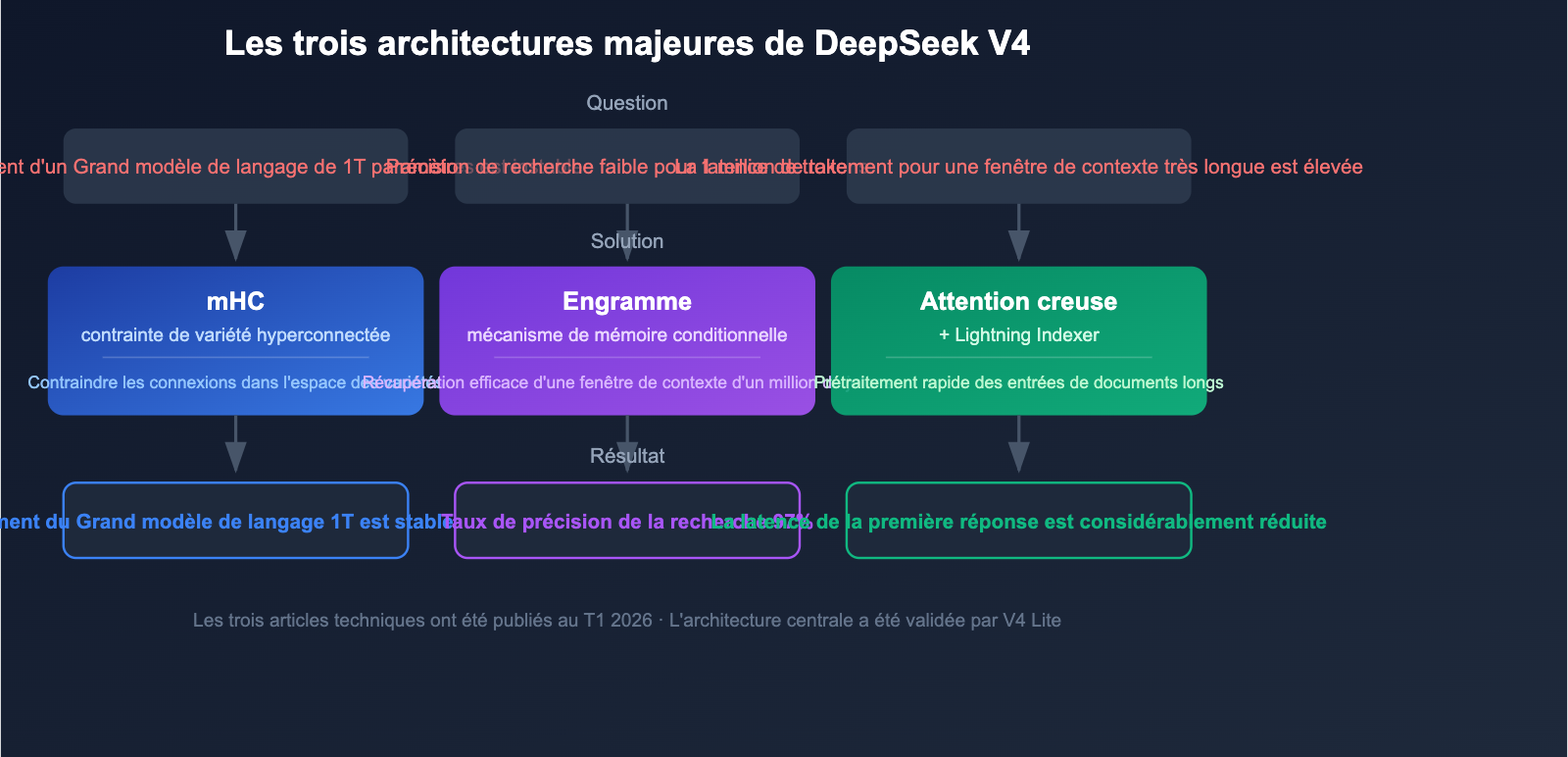
Innovation 1 : Connexions hyper-spatiales contraintes par variété (mHC)
DeepSeek a publié le 13 janvier 2026 le document technique sur la technologie Manifold-Constrained Hyper-Connections (mHC). Cette technologie résout spécifiquement les problèmes de stabilité d'entraînement des modèles MoE à mille milliards de paramètres.
Les modèles MoE à grande échelle traditionnels sont sujets à l'explosion des gradients et au déséquilibre de charge des experts pendant l'entraînement. Le mHC, en contraignant les hyper-connexions dans l'espace des variétés, améliore considérablement la stabilité du processus, rendant possible l'entraînement de modèles au niveau du téra-paramètre.
Innovation 2 : Mémoire conditionnelle Engram
La mémoire conditionnelle Engram est la technologie centrale permettant à DeepSeek V4 d'atteindre une fenêtre de contexte d'un million de jetons. Les mécanismes d'attention traditionnels font face à un double défi d'efficacité et de précision sur des contextes ultra-longs.
| Indicateur | Attention standard | Mémoire conditionnelle Engram |
|---|---|---|
| Précision "Needle-in-a-Haystack" | 84,2 % | 97 % |
| Récupération long contexte | Dégradation nette | Cohérence totale |
| Coût de calcul | O(n²) | Significativement réduit |
Un taux de précision de 97 % sur le test "Needle-in-a-Haystack" signifie que, même dans un texte ultra-long d'un million de jetons, le modèle peut localiser et extraire avec précision les informations clés.
Innovation 3 : Attention creuse + Lightning Indexer
L'attention creuse (Sparse Attention) de DeepSeek, associée au moteur de prétraitement Lightning Indexer, permet un traitement ultra-rapide des contextes longs. Cette technologie évite les temps de prétraitement interminables pour les entrées d'un million de jetons, réduisant considérablement la latence de première réponse pour l'analyse de documents volumineux.
Analyse des capacités multimodales natives de DeepSeek V4
L'un des changements les plus importants de DeepSeek V4 est sa transition d'un modèle purement textuel vers un modèle multimodal natif. Contrairement aux solutions multimodales assemblées a posteriori, le V4 intègre les capacités multimodales dès la phase de pré-entraînement.
Prise en charge des entrées multimodales
| Modalité | État | Remarques |
|---|---|---|
| Texte | ✅ Natif | Poursuit les capacités textuelles puissantes du V3 |
| Image | ✅ Natif | Intégration au pré-entraînement, pas d'assemblage tardif |
| Vidéo | ✅ Natif | Compréhension et analyse inter-images |
| Audio | ✅ Natif | Compréhension de la parole et des sons |
| Raisonnement inter-modal | ✅ Natif | Analyse intégrée des informations multimodales |
Multimodalité native vs Assemblage a posteriori
La multimodalité native (intégrée lors du pré-entraînement) présente des avantages significatifs par rapport aux solutions assemblées :
- Compréhension inter-modale plus profonde : Le modèle apprend les corrélations entre les différentes modalités dès l'entraînement.
- Cohérence d'inférence renforcée : Les informations textuelles, visuelles et vidéo participent de manière transparente à la même chaîne de raisonnement.
- Taux d'hallucination réduit : Les informations multimodales se vérifient mutuellement, limitant les hallucinations liées à une modalité unique.
- Latence réduite : Aucune étape de conversion de modalité supplémentaire n'est nécessaire.
💡 Conseil d'utilisation : Les capacités multimodales natives de DeepSeek V4 le rendent idéal pour les scénarios nécessitant une analyse complète de sources d'informations variées. Nous vous recommandons d'y accéder via la plateforme APIYI (apiyi.com) pour comparer facilement les performances réelles de DeepSeek V4 avec d'autres modèles multimodaux au sein d'une interface unifiée.
Chronologie de la sortie de DeepSeek V4 et contexte des reports
La sortie de DeepSeek V4 a connu plusieurs reports. Comprendre cet historique permet de mieux cerner les défis techniques rencontrés par la V4 et le niveau de maturité du produit final.
Chronologie de la sortie
| Date | Événement |
|---|---|
| Début janvier 2026 | Premières discussions sur la V4 dans la communauté Reddit |
| 13 janvier 2026 | Publication de l'article technique mHC, révélant des innovations architecturales |
| 20 janvier 2026 | Fuite de code sur GitHub, mentionnant 28 fois le nom de code interne "MODEL1" |
| Fin janvier 2026 | Première fenêtre de lancement prévue, non respectée |
| 11 février 2026 | Confirmation d'une capacité de contexte de 1 million de jetons |
| Mi-février 2026 | Fuite des données de benchmark |
| Fin février 2026 | Fenêtre de lancement après le Nouvel An chinois, reportée à nouveau |
| 9 mars 2026 | Sortie de V4 Lite (~200B de paramètres, validation de l'architecture centrale) |
| Avril 2026 | Sortie prévue de la version complète de V4 |
Raisons principales des reports
Les reports successifs de la V4 sont principalement dus aux défis liés à l'infrastructure d'entraînement :
- Problèmes d'adaptation matérielle : L'entraînement de modèles à mille milliards de paramètres sur des puces locales pose des défis de stabilité.
- Bande passante d'interconnexion des puces : L'entraînement distribué à grande échelle exige une bande passante de communication extrêmement élevée entre les puces.
- Maturité de l'écosystème logiciel : Les frameworks d'entraînement et les outils d'optimisation sont encore en phase d'itération.
Il est intéressant de noter que la version V4 Lite (environ 200B de paramètres) a été publiée en avance le 9 mars, servant de version de validation architecturale pour la V4 complète. Cette initiative montre que l'architecture centrale est déjà validée, et que le report de la version complète est principalement lié à des problèmes d'ingénierie liés à l'entraînement à grande échelle.
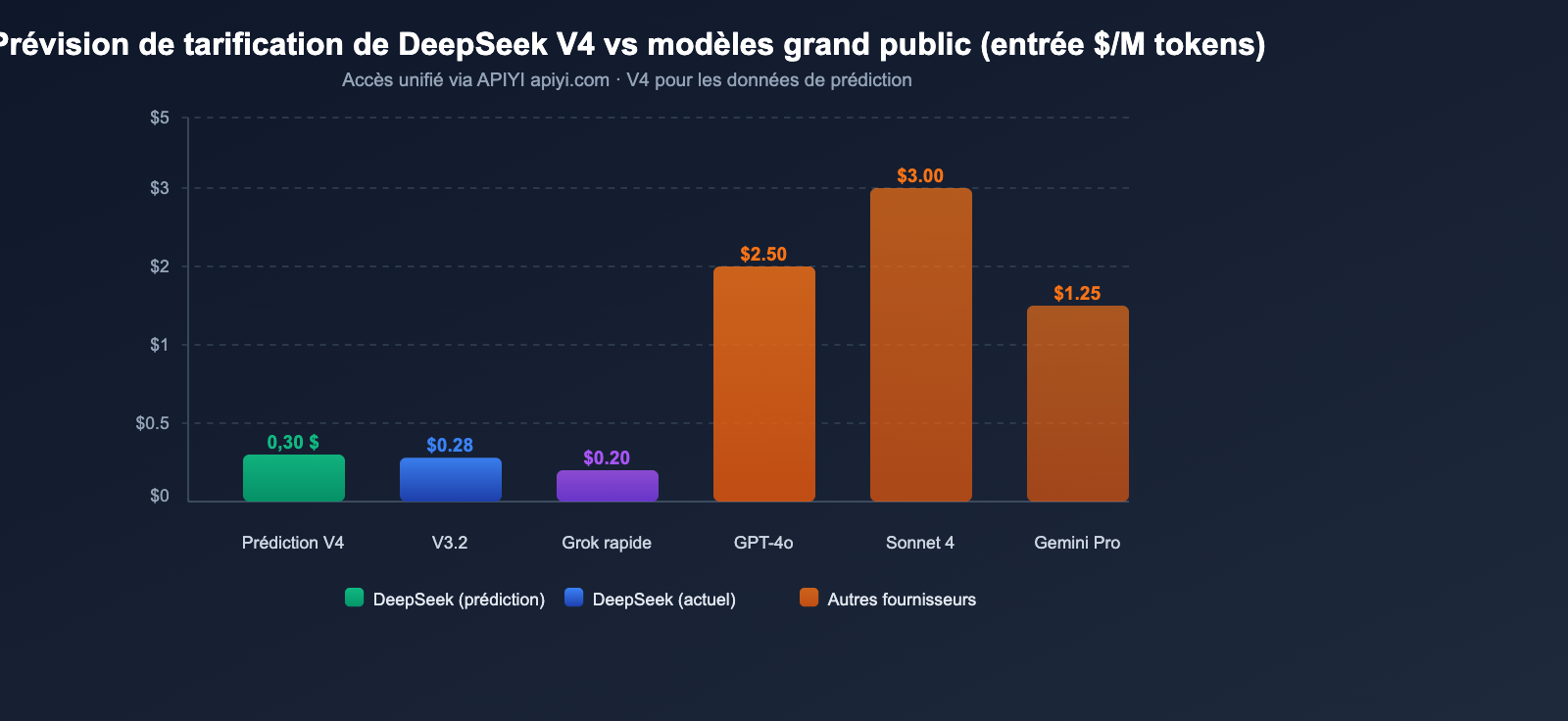
Prévisions de tarification de l'API DeepSeek V4
En nous basant sur la stratégie tarifaire habituelle de DeepSeek et sur les caractéristiques architecturales de la V4, nous pouvons établir des prévisions raisonnables pour la tarification de son API.
Tarification actuelle de l'API DeepSeek
| Modèle | Entrée (cache manqué) | Entrée (cache atteint) | Sortie | Fenêtre de contexte |
|---|---|---|---|---|
| deepseek-chat (V3.2) | 0,28 $/M | 0,028 $/M | 0,42 $/M | 128K |
| deepseek-reasoner (V3.2) | 0,28 $/M | 0,028 $/M | 0,42 $/M | 128K |
Prévisions de tarification pour DeepSeek V4
En synthétisant les analyses de plusieurs sources, la tarification de la V4 devrait se situer dans les fourchettes suivantes :
| Scénario de prévision | Prix d'entrée | Prix de sortie | Justification |
|---|---|---|---|
| Prévision optimiste | ~0,14 $/M | ~0,28 $/M | Paramètres activés constants, efficacité accrue |
| Prévision neutre | ~0,30 $/M | ~0,50 $/M | Le contexte de 1M entraîne des coûts de calcul supplémentaires |
| Prévision prudente | ~0,50 $/M | ~0,80 $/M | Frais supplémentaires liés au traitement multimodal |
Même selon la prévision prudente, un prix d'entrée de 0,50 $/M reste extrêmement compétitif pour un modèle multimodal à mille milliards de paramètres. À titre de comparaison, le prix d'entrée de GPT-4o est de 2,50 $/M, et celui de Claude Opus 4 est de 15,00 $/M.
💰 Optimisation des coûts : La série DeepSeek est reconnue pour son rapport qualité-prix exceptionnel. Grâce à la plateforme APIYI apiyi.com, les développeurs peuvent utiliser une interface unifiée pour invoquer simultanément DeepSeek et d'autres modèles majeurs, trouvant ainsi le meilleur équilibre entre coût et performance.
Analyse du paysage concurrentiel de DeepSeek V4
Avril 2026 marque une période de sorties intenses pour les grands modèles de langage. DeepSeek V4 devra faire face à une concurrence venant de plusieurs fronts.
Comparaison avec les produits concurrents de la même période
| Modèle | Fabricant | Taille des paramètres | Contexte | Multimodal | Open Source |
|---|---|---|---|---|---|
| DeepSeek V4 | DeepSeek | ~1T (MoE) | 1M | ✅ Natif | ✅ Apache 2.0 |
| GPT-5.x | OpenAI | Non divulgué | Non divulgué | ✅ | ❌ |
| Série Claude 4 | Anthropic | Non divulgué | 1M | ✅ | ❌ |
| Gemini 3.x | Non divulgué | 2M | ✅ | ❌ | |
| Grok 4.x | xAI | Non divulgué | 2M | ✅ | ❌ |
Avantages différenciateurs de DeepSeek V4
- Open Source : Prévu sous licence Apache 2.0, ce qui est presque unique pour un modèle de l'ordre du billion de paramètres.
- Rapport coût-efficacité extrême : La stratégie tarifaire de DeepSeek a toujours été la plus basse parmi les modèles de même catégorie.
- Possibilité de déploiement local : L'aspect open source permet aux entreprises de déployer le modèle sur leur propre infrastructure.
- Efficacité MoE : Avec seulement 32 à 37 milliards de paramètres activés, l'efficacité d'inférence est bien supérieure à celle des modèles denses de taille équivalente.
Besoins matériels pour le déploiement local de DeepSeek V4
Pour les équipes souhaitant un déploiement local, voici les besoins matériels pour la version V4 :
| Méthode de quantification | VRAM nécessaire | Matériel recommandé |
|---|---|---|
| FP16/BF16 (Précision totale) | Très élevé | Cluster GPU multi-nœuds |
| INT8 (Quantification 8 bits) | ~48 Go | Double RTX 4090 |
| INT4 (Quantification 4 bits) | ~32 Go | Simple RTX 5090 |
Après une quantification INT4, une seule RTX 5090 suffit pour faire tourner le modèle, rendant le déploiement local accessible aux petites équipes et aux chercheurs.
Évolution des versions du modèle DeepSeek
Comprendre l'évolution complète des produits DeepSeek aide à saisir le positionnement et la trajectoire technologique de la V4.
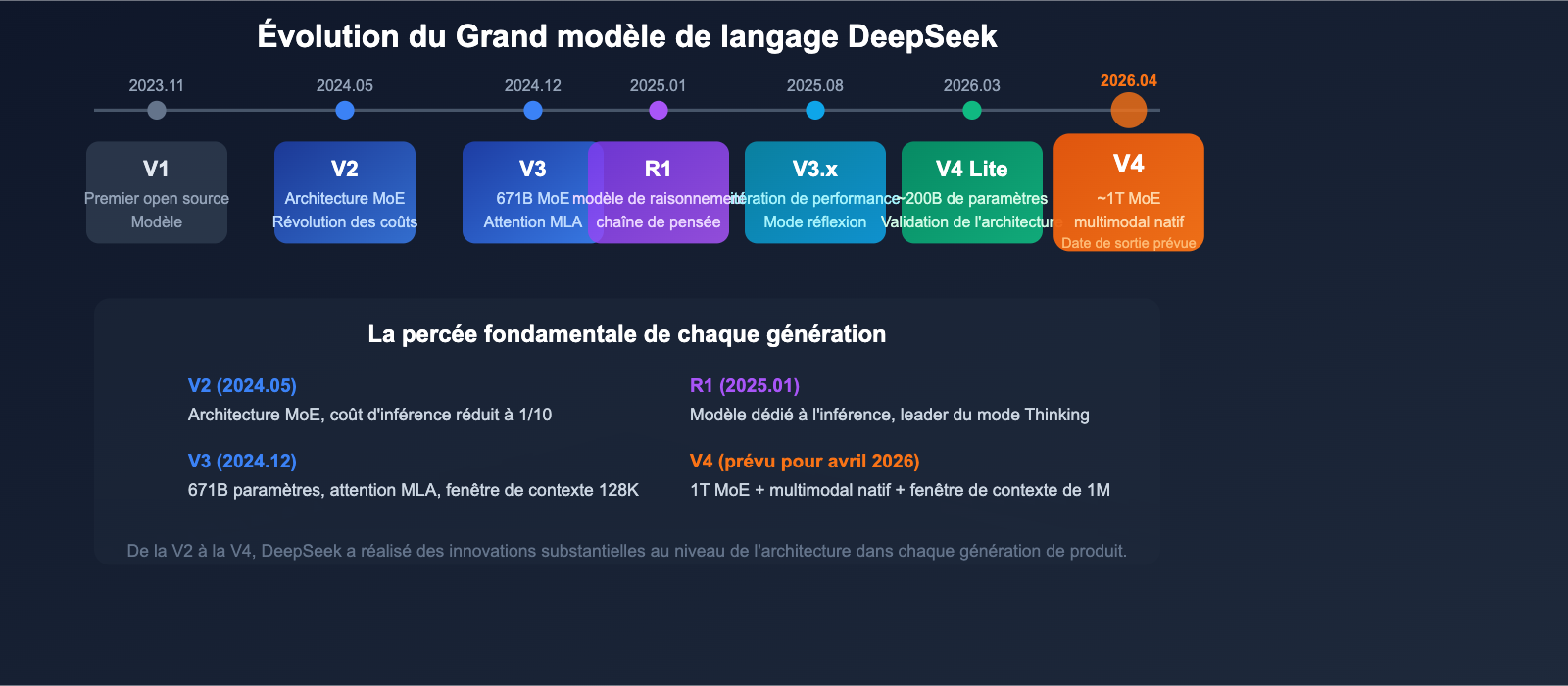
| Version | Date de sortie | Caractéristiques clés |
|---|---|---|
| V1 | Novembre 2023 | Premier modèle open source |
| V2 | Mai 2024 | Introduction de l'architecture MoE, réduction drastique des coûts |
| V2.5 | Septembre 2024 | Amélioration des capacités de dialogue et de code |
| V3 | Décembre 2024 | 671B de paramètres, attention MLA, contexte 128K |
| R1 | Janvier 2025 | Modèle dédié à l'inférence, technologie de chaîne de pensée |
| V3.1 | Août 2025 | Optimisation des performances, inférence renforcée |
| V3.2 | Fin 2025 | Modèle principal actuel, support du mode Thinking |
| V4 Lite | Mars 2026 | ~200B de paramètres, version de validation d'architecture |
| V4 | Avril 2026 (prévu) | ~1T MoE, multimodal natif, contexte 1M |
De l'introduction de l'architecture MoE avec la V2, à l'attention MLA de la V3, jusqu'aux technologies mHC et Engram de la V4, chaque génération de produits DeepSeek apporte des innovations substantielles au niveau de l'architecture.
🎯 Conseil technique : En attendant la sortie officielle de la V4, les développeurs peuvent commencer à travailler avec DeepSeek V3.2 et R1 via la plateforme APIYI (apiyi.com). La plateforme intégrera la V4 dès sa sortie.
FAQ
Q1 : Quand DeepSeek V4 sera-t-il officiellement lancé ?
Selon les informations recueillies auprès de diverses sources, DeepSeek V4 devrait être lancé en avril 2026. Le lancement a déjà été reporté deux fois, fin janvier et fin février. La version V4 Lite (~200B de paramètres), publiée le 9 mars, a validé la faisabilité de l'architecture centrale, ce qui rend le lancement de la version complète très probable. Vous pourrez accéder à l'API V4 dès sa sortie via la plateforme APIYI apiyi.com.
Q2 : Le 1T de paramètres de DeepSeek V4 signifie-t-il que le coût d’inférence sera très élevé ?
Pas nécessairement. V4 utilise une architecture MoE, où chaque jeton n'active qu'environ 32 à 37B de paramètres, ce qui est comparable à la V3. Cela signifie que la charge de calcul réelle lors de l'inférence n'augmentera pas de manière significative et que les coûts devraient rester dans une fourchette raisonnable. La stratégie de tarification de DeepSeek a toujours été agressive, et le prix de l'API V4 devrait rester extrêmement compétitif.
Q3 : Le modèle de raisonnement DeepSeek R2 sera-t-il publié ?
La date de sortie de DeepSeek R2 reste incertaine. Certaines analyses suggèrent que les capacités de raisonnement de R2 pourraient être directement intégrées dans la V4 (le mode Thinking est déjà pris en charge dans la V3.2). D'autres estiment que R2 est toujours en cours de développement indépendant, mais qu'il fait face à des défis d'entraînement. Nous vous conseillons de suivre les annonces officielles de DeepSeek pour obtenir les dernières informations.
Q4 : Comment les développeurs doivent-ils se préparer avant la sortie de la V4 ?
Il est conseillé de se familiariser dès maintenant avec l'invocation du modèle via l'API DeepSeek. La V4 sera très probablement compatible avec les interfaces OpenAI existantes, ce qui rendra la migration très simple. Utilisez la plateforme APIYI apiyi.com pour développer et tester avec DeepSeek V3.2 ; une fois la V4 disponible, il vous suffira de changer le nom du modèle.
Résumé
DeepSeek V4 promet d'être l'un des lancements de grands modèles de langage open source les plus importants de 2026. Avec son architecture MoE d'environ 1T de paramètres, sa fenêtre de contexte ultra-longue d'un million de jetons, son support multimodal natif, ainsi que sa licence open source Apache 2.0 et son rapport coût-efficacité exceptionnel, la V4 est très attendue, tant pour ses performances techniques que pour sa valeur commerciale.
Points clés à retenir :
- Architecture : MoE d'environ 1T de paramètres, 32-37B activés par jeton, priorité à l'efficacité.
- Contexte : 1 million de jetons, mémoire conditionnelle Engram atteignant 97 % de précision de récupération.
- Multimodal : Support natif des entrées texte, image, vidéo et audio.
- Innovation : Stabilité d'entraînement mHC + mémoire conditionnelle Engram + attention creuse.
- Open Source : Licence Apache 2.0 prévue, quantification INT4 exécutable sur une seule RTX 5090.
- Tarification : Maintien prévu du rapport coût-efficacité extrême propre à DeepSeek.
Nous vous recommandons d'utiliser APIYI apiyi.com pour accéder de manière centralisée à toute la gamme de modèles DeepSeek et bénéficier d'un accès API dès la sortie de la V4.
Références
- Dataconomy – Rapport sur la sortie de DeepSeek V4 :
dataconomy.com/2026/03/16/deepseek-v4-and-tencents-new-hunyuan-model-to-launch-in-april/ - NxCode – Spécifications techniques de DeepSeek V4 :
nxcode.io/resources/news/deepseek-v4-release-specs-benchmarks-2026 - Documentation officielle de DeepSeek :
platform.deepseek.com/docs
Cet article a été rédigé par l'équipe technique d'APIYI. Pour plus de tutoriels sur l'utilisation des modèles d'IA, veuillez consulter APIYI sur apiyi.com.