DeepSeek V4がまもなくリリースされます。約1兆(1T)パラメータのMoEアーキテクチャを採用し、ネイティブなマルチモーダル入力と100万トークンの超長コンテキストに対応しています。度重なる延期を経て、広く期待を集めるこのオープンソースの大規模言語モデルは2026年4月に正式公開される見込みで、GPT-5.x、Claude 4シリーズ、Gemini 3.xと肩を並べる存在となるでしょう。
コアバリュー: DeepSeek V4のアーキテクチャの革新、主要パラメータ、マルチモーダル能力、そして開発者エコシステムへの潜在的な影響について、3分で解説します。

DeepSeek V4 核心情報まとめ
DeepSeek V4は、DeepSeekがリリースを予定している次世代フラッグシップ大規模言語モデルです。公開されている情報によると、V4はパラメータ規模、アーキテクチャ設計、マルチモーダル能力など、複数の側面で世代を超えた飛躍を遂げています。
| 項目 | DeepSeek V4 |
|---|---|
| リリース予定 | 2026年4月 |
| 総パラメータ数 | 約1兆 (1T) |
| トークンあたりのアクティブパラメータ | 約32-37B |
| アーキテクチャ | Transformer MoE + MLA (Multi-head Latent Attention) |
| エキスパートルーティング | トークンあたり16個のエキスパートをアクティブ化 |
| コンテキストウィンドウ | 100万トークン (1M) |
| マルチモーダル | テキスト、画像、動画、音声の入力をネイティブサポート |
| オープンソースライセンス | Apache 2.0 (予定) |
DeepSeek V4 vs V3 主要パラメータ比較
DeepSeek V4のV3からの主なアップグレードは以下の通りです。
| 項目 | DeepSeek V3 | DeepSeek V4 | 変化 |
|---|---|---|---|
| 総パラメータ | 671B | ~1T | +49% |
| アクティブパラメータ | 37B | ~32-37B | 維持、効率優先 |
| コンテキストウィンドウ | 128K | 1M | 8倍に拡張 |
| マルチモーダル | テキストのみ | テキスト+画像+動画+音声 | 全モーダル対応 |
| アテンション機構 | MLA | MLA + Engram条件付きメモリ | 長コンテキスト最適化 |
| 学習の安定性 | 標準 | mHC (Manifold-constrained Hyper-connection) | アーキテクチャ革新 |
重要な発見: V4は総パラメータ数が49%増加した一方で、トークンあたりのアクティブパラメータ数はほぼ同等(約32-37B)を維持しています。これは、推論コストを大幅に引き上げることなく、モデルの知識容量と汎化能力が大幅に向上していることを意味します。
🎯 技術的アドバイス: DeepSeek V4がリリースされたら、開発者の皆様はAPIYI (apiyi.com) プラットフォームを通じてすぐにテスト接続が可能です。同プラットフォームはすでにDeepSeek V3やR1などの全シリーズモデルに対応しており、V4の公開後も迅速にサポートを開始する予定です。
DeepSeek V4 アーキテクチャの3つの技術的ブレイクスルー
DeepSeek V4 は単なるパラメータ規模の拡大にとどまらず、3つの重要なアーキテクチャ革新を導入し、兆単位のパラメータを持つモデルの学習と推論における核心的な課題を解決しました。

イノベーション 1: 多様体制約付きハイパーコネクション (mHC)
DeepSeek は2026年1月13日、Manifold-Constrained Hyper-Connections (mHC) に関する技術論文を公開しました。この技術は、兆単位のパラメータを持つMoEモデルの学習における安定性の問題を解決するために開発されました。
従来の大規模MoEモデルは、学習中に勾配爆発や専門家(エキスパート)の負荷不均衡といった問題が発生しやすい傾向がありました。mHCは多様体空間においてハイパーコネクションを制約することで、学習プロセスの安定性を大幅に向上させ、1Tパラメータ規模のモデル学習を可能にしました。
イノベーション 2: Engram 条件付き記憶
Engram 条件付き記憶は、DeepSeek V4 が100万トークンのコンテキストウィンドウを実現するための核心技術です。従来の注意(アテンション)機構は、超長文のコンテキストにおいて効率と精度の両面で課題を抱えていました。
| 指標 | 標準アテンション | Engram 条件付き記憶 |
|---|---|---|
| Needle-in-a-Haystack 精度 | 84.2% | 97% |
| 長文コンテキスト検索 | 性能低下が顕著 | 全体を通して一貫 |
| 計算コスト | O(n²) | 最適化により大幅低減 |
97% という Needle-in-a-Haystack(干し草の中の針)の精度は、100万トークンという超長文においても、モデルが重要な情報を正確に特定・抽出できることを意味します。
イノベーション 3: スパースアテンション + Lightning Indexer
DeepSeek のスパースアテンションと前処理エンジンである Lightning Indexer を組み合わせることで、超長文コンテキストの高速処理を実現しました。これにより、100万トークンの入力であっても長い前処理時間を必要とせず、長文ドキュメント分析における初回応答の遅延を大幅に削減しています。
DeepSeek V4 のネイティブマルチモーダル能力の解説
DeepSeek V4 の最大の変更点の一つは、純粋なテキストモデルからネイティブなマルチモーダルモデルへと進化したことです。後付けでマルチモーダル化した手法とは異なり、V4 は事前学習段階からマルチモーダル能力が統合されています。
マルチモーダル入力のサポート
| モダリティ | サポート状況 | 説明 |
|---|---|---|
| テキスト | ✅ ネイティブ対応 | V3 の強力なテキスト能力を継承 |
| 画像 | ✅ ネイティブ対応 | 事前学習で統合、後付けではない |
| 動画 | ✅ ネイティブ対応 | フレーム間理解と分析 |
| 音声 | ✅ ネイティブ対応 | 音声および音響の理解 |
| クロスモーダル推論 | ✅ ネイティブ対応 | マルチモーダル情報の統合分析 |
ネイティブマルチモーダル vs 後付け統合
ネイティブマルチモーダル(事前学習段階で統合)は、後付けの統合手法と比較して以下のような顕著な利点があります。
- より深いクロスモーダル理解: 学習段階で異なるモダリティ間の関連性を習得
- 推論の一貫性が向上: テキスト、画像、動画情報を同一の推論チェーンでシームレスに処理可能
- ハルシネーション(幻覚)の低減: モダリティ間で情報を相互検証し、単一モダリティによる誤りを削減
- 低遅延: モダリティ変換のための追加ステップが不要
💡 利用のヒント: DeepSeek V4 のネイティブマルチモーダル能力は、多様な情報源を総合的に分析する必要があるシナリオに最適です。APIYI (apiyi.com) プラットフォームを通じて統一的に接続し、同一インターフェース上で DeepSeek V4 と他のマルチモーダルモデルの実際のパフォーマンスを比較検討することをお勧めします。
DeepSeek V4 リリースまでのタイムラインと延期の背景
DeepSeek V4のリリースは、これまでに何度か延期されてきました。この経緯を理解することは、V4が直面した技術的な課題と、最終的な製品の成熟度を把握する上で非常に重要です。
リリースまでのタイムライン
| 日付 | 出来事 |
|---|---|
| 2026年1月初旬 | RedditコミュニティでV4に関する議論が始まる |
| 2026年1月13日 | mHCに関する技術論文が発表され、アーキテクチャの革新が明らかに |
| 2026年1月20日 | GitHubでコードがリークし、内部コードネーム「MODEL1」への言及が28箇所発見される |
| 2026年1月末 | 当初のリリース予定時期だったが、実現せず |
| 2026年2月11日 | 100万トークンのコンテキストウィンドウ能力が確認される |
| 2026年2月中旬 | ベンチマークデータが流出 |
| 2026年2月末 | 春節後のリリースウィンドウだったが、再び延期 |
| 2026年3月9日 | V4 Lite リリース(約200Bパラメータ、コアアーキテクチャを検証) |
| 2026年4月 | V4 完全版のリリース予定 |
延期の主な原因
V4が何度も延期された主な理由は、トレーニングインフラにおける課題にあります。
- ハードウェアの適合性: 国産チップ上での兆単位パラメータのトレーニングにおいて、安定性の確保が課題となりました。
- チップ間接続帯域: 大規模な分散トレーニングでは、チップ間の通信帯域に対して極めて高い要求が求められます。
- ソフトウェアエコシステムの成熟度: トレーニングフレームワークや最適化ツールチェーンが、現在もなお進化の途上にあります。
注目すべきは、V4のアーキテクチャ検証版として、約200Bパラメータの「V4 Lite」が3月9日に先行リリースされたことです。これはコアとなるアーキテクチャ自体は既に検証済みであり、完全版の延期は主に大規模トレーニングにおけるエンジニアリング上の問題であることを示しています。
DeepSeek V4 APIの価格予測
DeepSeekの一貫した価格戦略とV4のアーキテクチャ特性に基づき、V4のAPI価格を予測します。
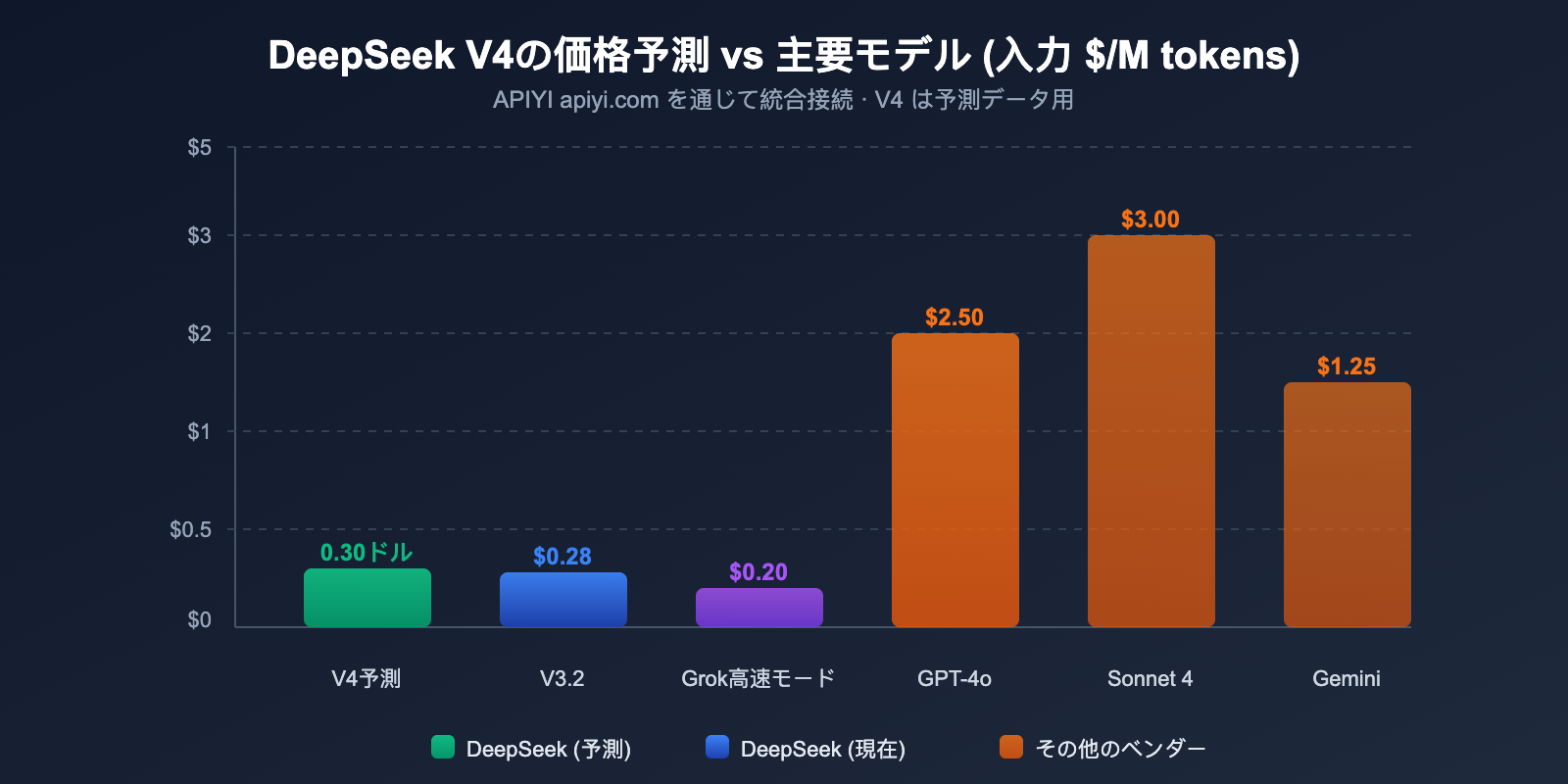
現在のDeepSeek API価格
| モデル | 入力 (キャッシュミス) | 入力 (キャッシュヒット) | 出力 | コンテキスト |
|---|---|---|---|---|
| deepseek-chat (V3.2) | $0.28/M | $0.028/M | $0.42/M | 128K |
| deepseek-reasoner (V3.2) | $0.28/M | $0.028/M | $0.42/M | 128K |
DeepSeek V4 価格予測
複数の情報源による分析を総合すると、V4の価格は以下の範囲になると予測されます。
| 予測シナリオ | 入力価格 | 出力価格 | 根拠 |
|---|---|---|---|
| 楽観的予測 | ~$0.14/M | ~$0.28/M | アクティブパラメータ維持、効率向上 |
| 中立的予測 | ~$0.30/M | ~$0.50/M | 1Mコンテキストによる計算コスト増 |
| 保守的予測 | ~$0.50/M | ~$0.80/M | マルチモーダル処理によるオーバーヘッド増 |
保守的な予測であっても、入力価格$0.50/Mは、兆単位パラメータのマルチモーダルモデルとしては極めて高い競争力を持っています。比較対象として、GPT-4oの入力価格は$2.50/M、Claude Opus 4は$15.00/Mとなっています。
💰 コスト最適化: DeepSeekシリーズは一貫して圧倒的なコストパフォーマンスを誇ります。APIYI (apiyi.com) プラットフォームを活用すれば、開発者は統一されたインターフェースを通じてDeepSeekや他の主要モデルを呼び出し、コストとパフォーマンスの最適なバランスを見つけることができます。
DeepSeek V4 競争環境分析
2026年4月は、AI大規模言語モデルが集中してリリースされる時期です。DeepSeek V4は、多方面からの競争に直面することになります。
同時期の競合モデル比較
| モデル | ベンダー | パラメータ規模 | コンテキスト | マルチモーダル | オープンソース |
|---|---|---|---|---|---|
| DeepSeek V4 | DeepSeek | ~1T (MoE) | 1M | ✅ ネイティブ | ✅ Apache 2.0 |
| GPT-5.x | OpenAI | 非公開 | 非公開 | ✅ | ❌ |
| Claude 4 シリーズ | Anthropic | 非公開 | 1M | ✅ | ❌ |
| Gemini 3.x | 非公開 | 2M | ✅ | ❌ | |
| Grok 4.x | xAI | 非公開 | 2M | ✅ | ❌ |
DeepSeek V4 の差別化優位性
- オープンソース: Apache 2.0ライセンスの採用が予想されており、1兆パラメータ級のモデルとしては極めて異例です。
- 圧倒的なコストパフォーマンス: DeepSeekの価格戦略は、常に同クラスのモデルの中で最も安価です。
- ローカルデプロイの可能性: オープンソースであるため、企業は自社のインフラ上で運用可能です。
- MoEの効率性: アクティブパラメータはわずか32〜37Bであり、同規模の密なモデル(デンスモデル)よりも推論効率が大幅に優れています。
DeepSeek V4 のローカルデプロイに必要なハードウェア要件
ローカル環境へのデプロイを検討しているチーム向けに、V4のハードウェア要件をまとめました。
| 量子化方式 | 必要なVRAM | 推奨ハードウェア |
|---|---|---|
| FP16/BF16 (フル精度) | 極めて大 | マルチノードGPUクラスター |
| INT8 (8bit量子化) | ~48GB | RTX 4090 × 2 |
| INT4 (4bit量子化) | ~32GB | RTX 5090 × 1 |
INT4量子化を行えば、RTX 5090単体で動作可能なため、中小規模のチームや研究者でもローカル環境での運用が現実的になります。
DeepSeek モデルバージョンの進化
DeepSeekの製品進化の歴史を理解することは、V4の立ち位置と技術的なロードマップを把握する上で重要です。
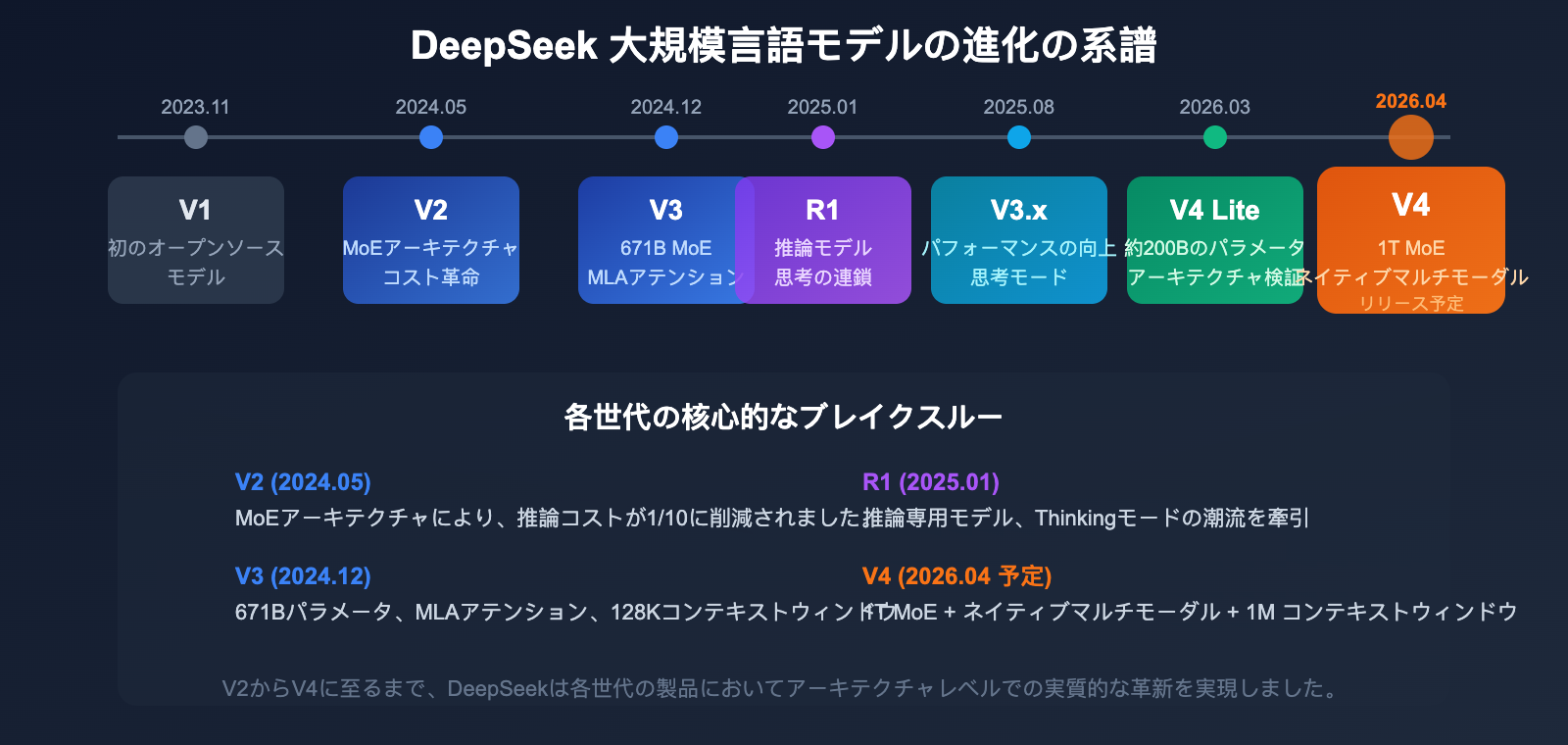
| バージョン | リリース時期 | 主な特徴 |
|---|---|---|
| V1 | 2023年11月 | 初のオープンソースモデル |
| V2 | 2024年5月 | MoEアーキテクチャ導入、コストを大幅削減 |
| V2.5 | 2024年9月 | 対話およびコード生成能力の強化 |
| V3 | 2024年12月 | 671Bパラメータ、MLAアテンション、128Kコンテキスト |
| R1 | 2025年1月 | 推論特化モデル、思考の連鎖(CoT)技術 |
| V3.1 | 2025年8月 | パフォーマンス最適化、推論能力の強化 |
| V3.2 | 2025年末 | 現行の主力モデル、Thinkingモード対応 |
| V4 Lite | 2026年3月 | ~200Bパラメータ、アーキテクチャ検証版 |
| V4 | 2026年4月 (予定) | ~1T MoE、ネイティブマルチモーダル、1Mコンテキスト |
V2でのMoEアーキテクチャ導入から、V3のMLAアテンション、そしてV4のmHCおよびEngram技術に至るまで、DeepSeekは世代を追うごとにアーキテクチャレベルでの革新を続けています。
🎯 技術的なアドバイス: V4の正式リリースを待つ間、開発者の皆様はAPIYI(apiyi.com)プラットフォームを通じて、DeepSeek V3.2やR1を活用した開発を先行して進めることができます。V4リリース後、当プラットフォームでは即座に対応予定です。
よくある質問
Q1: DeepSeek V4 はいつ正式リリースされますか?
複数の情報を総合すると、DeepSeek V4 は 2026 年 4 月にリリースされる見込みです。これまで 1 月末と 2 月末の 2 回、延期が続いていました。3 月 9 日にリリースされた V4 Lite(約 200B パラメータ)によってコアアーキテクチャの実現可能性が検証されており、完全版がリリースされる可能性は高いでしょう。APIYI (apiyi.com) プラットフォームを通じて、V4 の API アクセスをいち早く取得可能です。
Q2: DeepSeek V4 の 1T パラメータは、推論コストが高いことを意味しますか?
必ずしもそうではありません。V4 は MoE アーキテクチャを採用しており、各トークンでアクティブ化されるパラメータは約 32〜37B に抑えられており、V3 とほぼ同水準です。つまり、推論時の実際の計算量は大幅には増加せず、コストも妥当な範囲に維持される見込みです。DeepSeek の価格戦略は一貫して積極的であり、V4 の API 価格も非常に競争力のあるものになると予想されます。
Q3: DeepSeek R2 推論モデルは今後リリースされますか?
DeepSeek R2 のリリース時期は現時点では不明です。一部の分析では、R2 の推論能力は V4 に直接統合される可能性があるとされています(V3.2 ですでに Thinking モードをサポート済み)。一方で、R2 は依然として独立して開発中であるものの、学習上の課題に直面しているという見方もあります。最新情報については、DeepSeek 公式の動向を注視することをお勧めします。
Q4: V4 リリース前に、開発者はどのような準備をすべきですか?
DeepSeek API の呼び出し方法に事前に慣れておくことをお勧めします。V4 は既存の OpenAI 互換インターフェースと高い確率で互換性があるため、移行コストは非常に低いです。APIYI (apiyi.com) プラットフォームを利用して DeepSeek V3.2 で開発やテストを行い、V4 がリリースされたらモデル名を切り替えるだけで対応可能です。
まとめ
DeepSeek V4 は、2026 年に最も重要なオープンソース大規模言語モデルのリリースの一つとなることが期待されています。約 1T パラメータの MoE アーキテクチャ、100 万トークンの超長文コンテキスト、ネイティブなマルチモーダル対応に加え、Apache 2.0 オープンソースライセンスと圧倒的なコストパフォーマンスにより、技術指標とビジネス価値の両面で期待が高まっています。
核心となるポイントの振り返り:
- アーキテクチャ: 約 1T パラメータの MoE、トークンあたり 32〜37B をアクティブ化し、効率を優先
- コンテキスト: 100 万トークン、Engram 条件付きメモリにより 97% の検索精度を実現
- マルチモーダル: テキスト、画像、動画、音声入力をネイティブサポート
- イノベーション: mHC 学習の安定性 + Engram 条件付きメモリ + スパースアテンション
- オープンソース: Apache 2.0 を予定、INT4 量化により RTX 5090 単体で動作可能
- 価格設定: DeepSeek 一貫の圧倒的なコストパフォーマンスを維持する見込み
DeepSeek の全モデルを統一して利用できる APIYI (apiyi.com) を通じて、V4 リリース後すぐに API アクセスを取得することをお勧めします。
参考資料
- Dataconomy – DeepSeek V4 リリース報道:
dataconomy.com/2026/03/16/deepseek-v4-and-tencents-new-hunyuan-model-to-launch-in-april/ - NxCode – DeepSeek V4 技術仕様:
nxcode.io/resources/news/deepseek-v4-release-specs-benchmarks-2026 - DeepSeek 公式ドキュメント:
platform.deepseek.com/docs
本記事は APIYI チームの技術担当者が執筆しました。AI モデルの活用チュートリアルについては、APIYI (apiyi.com) をぜひフォローしてください。