DeepSeek V4 уже на подходе: модель использует архитектуру MoE с примерно 1 триллионом (1T) параметров, поддерживает нативный мультимодальный ввод и сверхдлинное контекстное окно в 1 миллион токенов. После нескольких переносов релиза, эта долгожданная большая языковая модель с открытым исходным кодом должна официально дебютировать в апреле 2026 года, чтобы составить конкуренцию сериям GPT-5.x, Claude 4 и Gemini 3.x.
Ключевая ценность: за 3 минуты вы узнаете об архитектурных инновациях, ключевых параметрах и мультимодальных возможностях DeepSeek V4, а также о том, как она повлияет на экосистему разработчиков.

Краткий обзор ключевой информации о DeepSeek V4
DeepSeek V4 — это флагманская большая языковая модель следующего поколения от компании DeepSeek. Судя по уже опубликованным данным, V4 совершила качественный скачок в параметрах, архитектурном дизайне и мультимодальных возможностях.
| Параметр | DeepSeek V4 |
|---|---|
| Ожидаемый релиз | Апрель 2026 г. |
| Общее количество параметров | ~1 триллион (1T) |
| Активных параметров на токен | ~32-37 млрд |
| Архитектура | Transformer MoE + MLA (Multi-head Latent Attention) |
| Маршрутизация экспертов | 16 активных экспертов на токен |
| Контекстное окно | 1 миллион токенов (1M) |
| Мультимодальность | Нативная поддержка текста, изображений, видео и аудио |
| Лицензия | Apache 2.0 (ожидается) |
Сравнение ключевых параметров DeepSeek V4 и V3
Основные улучшения DeepSeek V4 по сравнению с V3 очевидны:
| Измерение | DeepSeek V3 | DeepSeek V4 | Изменение |
|---|---|---|---|
| Общие параметры | 671 млрд | ~1 трлн | +49% |
| Активные параметры | 37 млрд | ~32-37 млрд | Без изменений, фокус на эффективности |
| Контекстное окно | 128 тыс. | 1 млн | В 8 раз больше |
| Мультимодальность | Только текст | Текст + изображения + видео + аудио | Полная поддержка |
| Механизм внимания | MLA | MLA + Engram (условная память) | Оптимизация для длинного контекста |
| Стабильность обучения | Стандарт | mHC (Manifold-constrained Hyper-connection) | Архитектурная инновация |
Ключевой вывод: При увеличении общего количества параметров на 49%, DeepSeek V4 сохраняет количество активных параметров на токен практически неизменным (около 32-37 млрд). Это означает, что стоимость вывода не вырастет значительно, при этом емкость знаний и возможности обобщения модели существенно возрастут.
🎯 Технический совет: После выхода DeepSeek V4 разработчики смогут протестировать её в числе первых через платформу APIYI (apiyi.com). Платформа уже поддерживает всю линейку моделей, включая DeepSeek V3 и R1, и будет оперативно адаптирована под V4 сразу после её релиза.
3 ключевых архитектурных прорыва в DeepSeek V4
DeepSeek V4 — это не просто увеличение количества параметров. Модель привнесла 3 фундаментальных архитектурных новшества, которые решили главные проблемы обучения и инференса моделей с триллионами параметров.
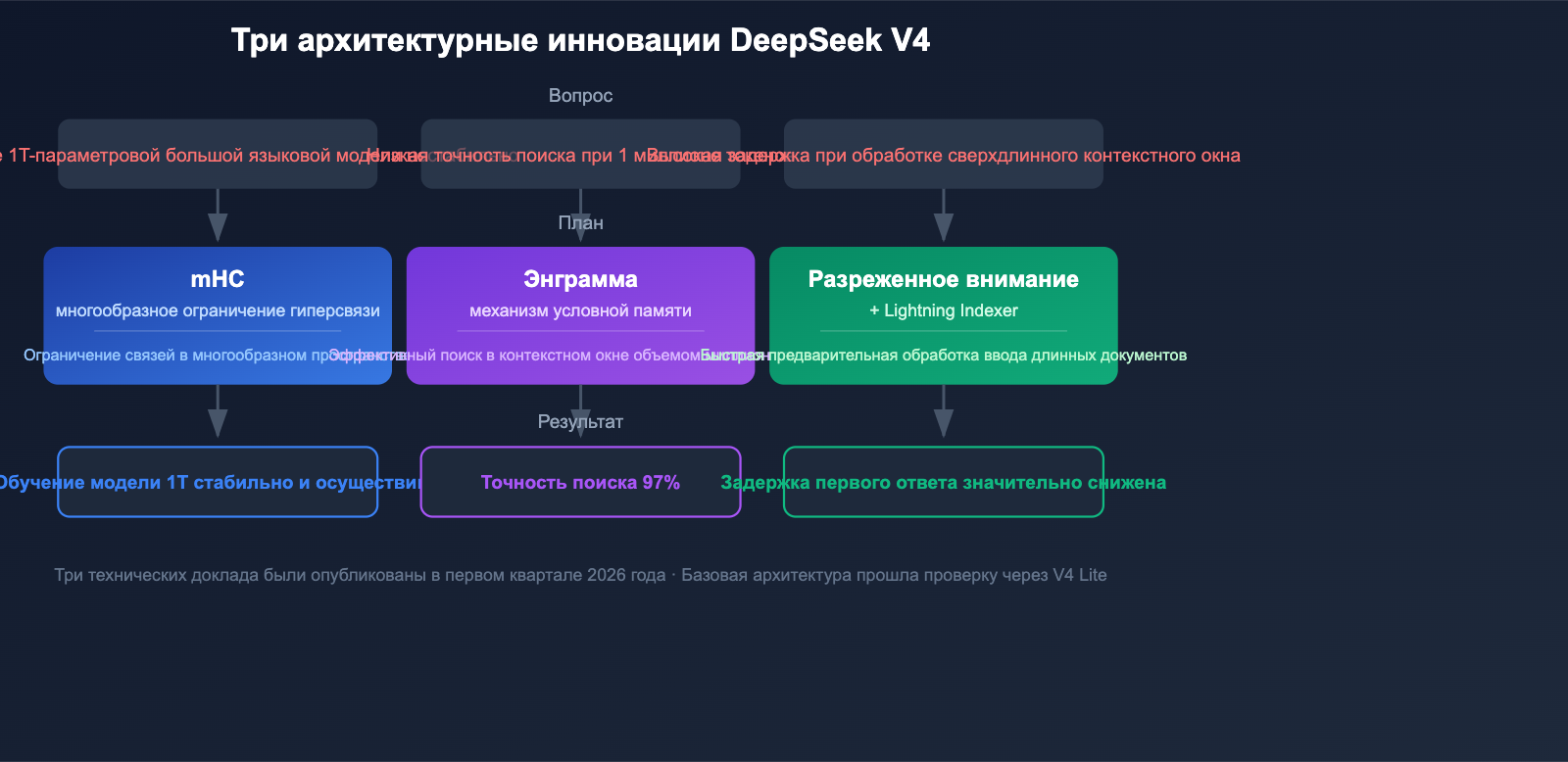
Инновация 1: Гиперсвязи с ограничением многообразия (mHC)
13 января 2026 года DeepSeek опубликовал техническую статью о технологии Manifold-Constrained Hyper-Connections (mHC). Она решает проблему стабильности обучения MoE-моделей с триллионами параметров.
Традиционные масштабные MoE-модели во время обучения часто страдают от взрыва градиентов и дисбаланса нагрузки между экспертами. mHC ограничивает гиперсвязи в пространстве многообразий, что значительно повышает стабильность и делает обучение моделей уровня 1T параметров реальной задачей.
Инновация 2: Условная память Engram
Условная память Engram — это ключевая технология, благодаря которой DeepSeek V4 поддерживает контекстное окно в 1 миллион токенов. Традиционные механизмы внимания в условиях сверхдлинного контекста сталкиваются с проблемами эффективности и точности.
| Показатель | Стандартное внимание | Условная память Engram |
|---|---|---|
| Точность Needle-in-a-Haystack | 84.2% | 97% |
| Поиск по длинному контексту | Заметное снижение производительности | Стабильно высокая |
| Вычислительные затраты | O(n²) | Значительно оптимизированы |
Точность 97% в тесте Needle-in-a-Haystack означает, что даже в тексте объемом 1 млн токенов модель способна точно находить и извлекать ключевую информацию.
Инновация 3: Разреженное внимание + Lightning Indexer
Разреженное внимание (Sparse Attention) в сочетании с движком предварительной обработки Lightning Indexer обеспечивает высокоскоростную работу с огромным контекстом. Благодаря этому для обработки 1 млн токенов больше не требуется длительная предварительная подготовка, что существенно снижает задержку первого ответа при анализе длинных документов.
Анализ нативных мультимодальных возможностей DeepSeek V4
Одним из главных изменений в DeepSeek V4 стал переход от чисто текстовой модели к нативной мультимодальной. В отличие от решений, где мультимодальность «приклеивается» на поздних этапах, V4 интегрирует эти возможности еще на стадии предварительного обучения.
Поддержка мультимодального ввода
| Модальность | Поддержка | Описание |
|---|---|---|
| Текст | ✅ Нативная | Сохраняет мощные текстовые возможности V3 |
| Изображения | ✅ Нативная | Интеграция при обучении, а не пост-обработка |
| Видео | ✅ Нативная | Понимание и анализ с учетом межкадровых связей |
| Аудио | ✅ Нативная | Распознавание речи и понимание звуков |
| Кросс-модальный вывод | ✅ Нативная | Комплексный анализ мультимодальной информации |
Нативная мультимодальность vs «приклеенные» решения
Нативная мультимодальность (интегрированная на этапе обучения) имеет ряд существенных преимуществ перед сторонними надстройками:
- Более глубокое понимание: модель учится связывать разные модальности еще в процессе обучения.
- Высокая согласованность рассуждений: текстовая, визуальная и видеоинформация бесшовно участвуют в одной цепочке логических выводов.
- Снижение галлюцинаций: информация из разных модальностей перекрестно проверяется, что уменьшает ошибки, характерные для работы с одним типом данных.
- Минимальная задержка: не требуется дополнительных этапов преобразования данных между модальностями.
💡 Совет: Нативные мультимодальные возможности DeepSeek V4 делают её идеальной для задач, требующих комплексного анализа различных источников информации. Рекомендуем подключаться через платформу APIYI (apiyi.com), чтобы удобно сравнивать работу DeepSeek V4 и других мультимодальных моделей в рамках одного интерфейса.
Хронология выпуска DeepSeek V4 и причины задержек
Выпуск DeepSeek V4 неоднократно откладывался. Понимание этой истории помогает осознать технические вызовы, с которыми столкнулась команда, и оценить зрелость финального продукта.
Хронология выпуска
| Дата | Событие |
|---|---|
| Начало января 2026 | Первые обсуждения V4 в сообществе Reddit |
| 13 января 2026 | Публикация научной статьи по технологии mHC, раскрытие архитектурных инноваций |
| 20 января 2026 | Утечка кода на GitHub, обнаружено 28 ссылок на внутренний код "MODEL1" |
| Конец января 2026 | Первое ожидаемое окно релиза, перенос |
| 11 февраля 2026 | Подтверждена поддержка контекстного окна в 1 млн токенов |
| Середина февраля 2026 | Утечка данных бенчмарков |
| Конец февраля 2026 | Окно релиза после китайского Нового года, повторный перенос |
| 9 марта 2026 | Выпуск V4 Lite (~200 млрд параметров, проверка архитектуры) |
| Апрель 2026 | Ожидаемый выпуск полной версии V4 |
Основные причины задержек
Главными факторами, тормозившими релиз V4, стали проблемы с инфраструктурой обучения:
- Адаптация оборудования: обеспечение стабильности при обучении модели с триллионами параметров на отечественных чипах.
- Пропускная способность интерконнекта: масштабное распределенное обучение требует экстремально высокой скорости обмена данными между чипами.
- Зрелость программной экосистемы: фреймворки для обучения и цепочки инструментов оптимизации все еще находятся в стадии активной доработки.
Важно отметить, что версия V4 Lite (около 200 млрд параметров) была выпущена 9 марта в качестве архитектурного прототипа полной версии. Это подтверждает, что базовая архитектура уже прошла проверку, а задержка полноценного релиза связана исключительно с инженерными задачами масштабирования обучения.
Прогноз стоимости API DeepSeek V4
Опираясь на устоявшуюся ценовую стратегию DeepSeek и архитектурные особенности версии V4, мы можем сделать обоснованный прогноз стоимости её API.
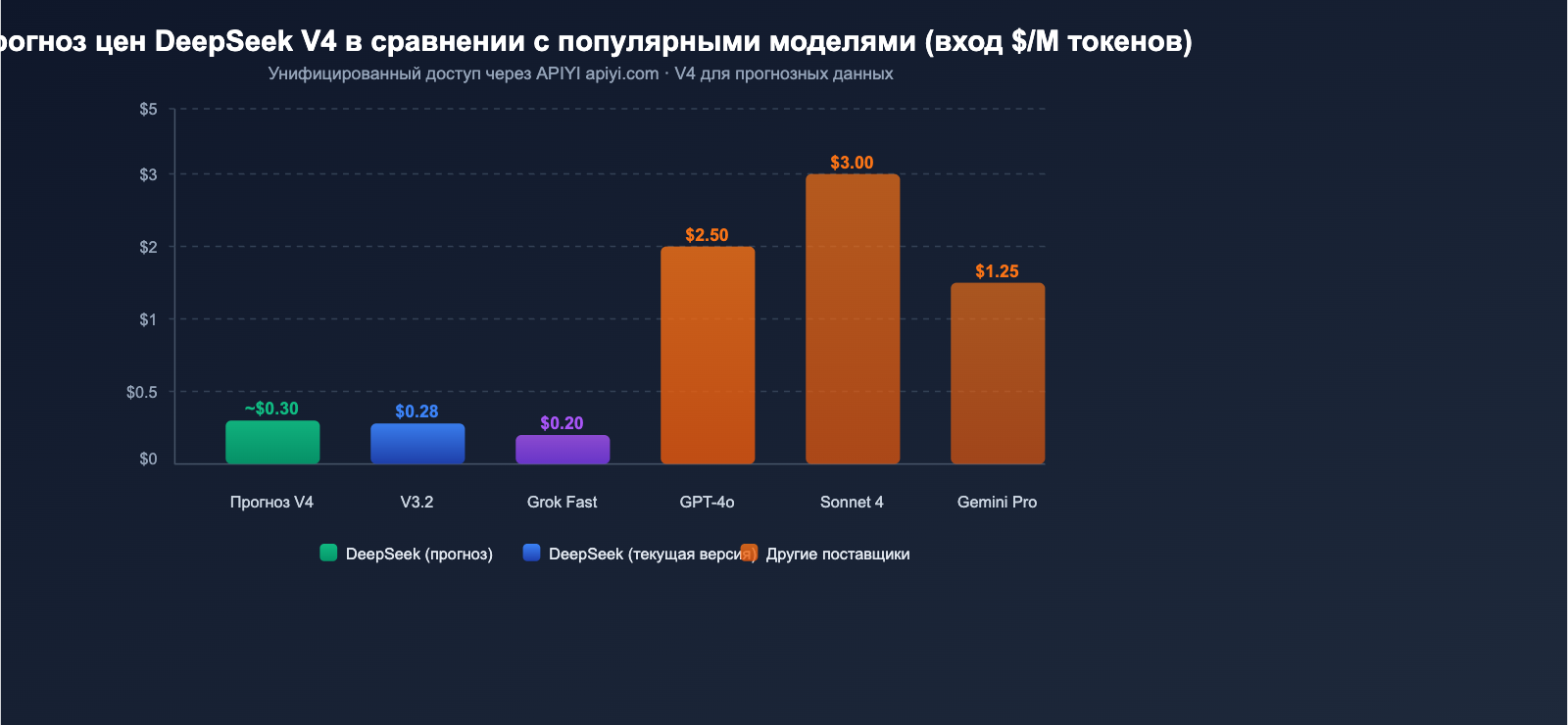
Текущие цены на API DeepSeek
| Модель | Вход (без кэша) | Вход (с кэшем) | Выход | Контекстное окно |
|---|---|---|---|---|
| deepseek-chat (V3.2) | $0.28/млн | $0.028/млн | $0.42/млн | 128K |
| deepseek-reasoner (V3.2) | $0.28/млн | $0.028/млн | $0.42/млн | 128K |
Прогноз цен на DeepSeek V4
Основываясь на анализе различных источников, ожидается, что цены на V4 будут находиться в следующем диапазоне:
| Сценарий прогноза | Цена на вход | Цена на выход | Обоснование |
|---|---|---|---|
| Оптимистичный | ~$0.14/млн | ~$0.28/млн | Параметры активации прежние, эффективность выше |
| Нейтральный | ~$0.30/млн | ~$0.50/млн | Дополнительные затраты на контекст 1M |
| Консервативный | ~$0.50/млн | ~$0.80/млн | Увеличение затрат на мультимодальную обработку |
Даже при консервативном прогнозе цена в $0.50/млн токенов на входе выглядит крайне конкурентоспособной для мультимодальной модели с триллионными параметрами. Для сравнения: вход GPT-4o стоит $2.50/млн, а Claude Opus 4 — $15.00/млн.
💰 Оптимизация затрат: Семейство DeepSeek всегда славилось своей исключительной эффективностью. С помощью платформы APIYI (apiyi.com) разработчики могут использовать единый интерфейс для вызова как DeepSeek, так и других популярных моделей, находя идеальный баланс между стоимостью и качеством работы.
Анализ конкурентной среды DeepSeek V4
Апрель 2026 года стал периодом активных релизов больших языковых моделей. DeepSeek V4 предстоит столкнуться с серьезной конкуренцией на нескольких фронтах.
Сравнение с конкурентами того же периода
| Модель | Разработчик | Параметры | Контекстное окно | Мультимодальность | Open Source |
|---|---|---|---|---|---|
| DeepSeek V4 | DeepSeek | ~1T (MoE) | 1M | ✅ Нативная | ✅ Apache 2.0 |
| GPT-5.x | OpenAI | Не раскрыто | Не раскрыто | ✅ | ❌ |
| Серия Claude 4 | Anthropic | Не раскрыто | 1M | ✅ | ❌ |
| Gemini 3.x | Не раскрыто | 2M | ✅ | ❌ | |
| Grok 4.x | xAI | Не раскрыто | 2M | ✅ | ❌ |
Дифференцированные преимущества DeepSeek V4
- Open Source: Ожидается использование лицензии Apache 2.0, что практически уникально для моделей с триллионом параметров.
- Максимальная экономичность: Стратегия ценообразования DeepSeek остается одной из самых доступных среди моделей аналогичного уровня.
- Возможность локального развертывания: Открытый исходный код позволяет компаниям разворачивать модель на собственной инфраструктуре.
- Эффективность MoE: Активные параметры составляют всего 32-37B, что обеспечивает гораздо более высокую эффективность вывода по сравнению с плотными моделями аналогичного размера.
Требования к оборудованию для локального развертывания DeepSeek V4
Для команд, планирующих локальный запуск, требования к железу выглядят следующим образом:
| Метод квантования | Требуемая VRAM | Рекомендуемое оборудование |
|---|---|---|
| FP16/BF16 (полная точность) | Огромная | Кластер GPU из нескольких узлов |
| INT8 (8-битное квантование) | ~48 ГБ | Две RTX 4090 |
| INT4 (4-битное квантование) | ~32 ГБ | Одна RTX 5090 |
После квантования в INT4 модель можно запустить на одной видеокарте RTX 5090, что делает локальное развертывание доступным для небольших команд и исследователей.
Эволюция версий моделей DeepSeek
Понимание истории развития продуктов DeepSeek помогает лучше осознать позиционирование и технический путь версии V4.

| Версия | Дата выпуска | Основные характеристики |
|---|---|---|
| V1 | Ноябрь 2023 | Первая открытая модель |
| V2 | Май 2024 | Внедрение архитектуры MoE, значительное снижение затрат |
| V2.5 | Сентябрь 2024 | Улучшенные навыки диалога и написания кода |
| V3 | Декабрь 2024 | 671B параметров, внимание MLA, контекстное окно 128K |
| R1 | Январь 2025 | Специализированная модель для рассуждений, технология цепочки мыслей |
| V3.1 | Август 2025 | Оптимизация производительности, усиление логического вывода |
| V3.2 | Конец 2025 | Текущая основная модель, поддержка режима Thinking |
| V4 Lite | Март 2026 | ~200B параметров, архитектурная проверочная версия |
| V4 | Апрель 2026 (ожидается) | ~1T MoE, нативная мультимодальность, контекстное окно 1M |
От внедрения архитектуры MoE в V2 и внимания MLA в V3 до технологий mHC и Engram в V4 — каждое поколение продуктов DeepSeek привносит существенные инновации на уровне архитектуры.
🎯 Технический совет: В ожидании официального релиза V4 разработчики могут использовать DeepSeek V3.2 и R1 для своих задач через платформу APIYI (apiyi.com). После выхода V4 платформа обеспечит доступ к ней в кратчайшие сроки.
Часто задаваемые вопросы
Q1: Когда состоится официальный релиз DeepSeek V4?
Согласно сводным данным из различных источников, релиз DeepSeek V4 ожидается в апреле 2026 года. Ранее запуск уже дважды откладывался — в конце января и конце февраля. Выпуск версии V4 Lite (~200 млрд параметров) 9 марта подтвердил работоспособность базовой архитектуры, поэтому вероятность выхода полной версии крайне высока. Через платформу APIYI apiyi.com вы сможете получить доступ к API V4 сразу после его появления.
Q2: Означает ли наличие 1 трлн параметров у DeepSeek V4 высокую стоимость инференса?
Не обязательно. В V4 используется архитектура MoE (смесь экспертов), где на каждый токен активируется лишь около 32–37 млрд параметров, что сопоставимо с V3. Это означает, что фактический объем вычислений при инференсе не вырастет значительно, а значит, и стоимость останется в разумных пределах. Ценовая политика DeepSeek всегда была агрессивной, поэтому ожидается, что цены на API V4 останутся весьма конкурентоспособными.
Q3: Будет ли выпущена модель для рассуждений DeepSeek R2?
Дата релиза DeepSeek R2 пока остается неясной. Некоторые аналитики полагают, что возможности рассуждений R2 могут быть напрямую интегрированы в V4 (в V3.2 уже поддерживается режим Thinking). Существует и мнение, что R2 все еще находится в разработке, но сталкивается с трудностями при обучении. Рекомендуем следить за официальными новостями DeepSeek для получения актуальной информации.
Q4: К чему стоит подготовиться разработчикам до выхода V4?
Рекомендуем заранее ознакомиться с методами вызова API DeepSeek. Скорее всего, V4 будет совместима с текущим интерфейсом OpenAI, поэтому переход будет практически бесшовным. Используйте платформу APIYI apiyi.com для разработки и тестирования на базе DeepSeek V3.2 — после выхода V4 вам останется лишь сменить название модели в настройках.
Резюме
DeepSeek V4 обещает стать одним из самых значимых релизов среди открытых больших языковых моделей в 2026 году. Архитектура MoE с объемом около 1 трлн параметров, контекстное окно в 1 млн токенов, нативная поддержка мультимодальности, а также лицензия Apache 2.0 и исключительная экономическая эффективность делают V4 крайне перспективной как с технической, так и с коммерческой точки зрения.
Краткий обзор ключевых моментов:
- Архитектура: MoE с ~1 трлн параметров, активация 32–37 млрд на токен, приоритет эффективности.
- Контекст: 1 млн токенов, использование условной памяти Engram обеспечивает 97% точности поиска.
- Мультимодальность: нативная поддержка ввода текста, изображений, видео и аудио.
- Инновации: стабильность обучения mHC + условная память Engram + разреженное внимание (sparse attention).
- Открытый исходный код: ожидается лицензия Apache 2.0, квантование INT4 позволит запускать модель на одной RTX 5090.
- Ценообразование: ожидается сохранение фирменной ценовой политики DeepSeek с максимальной выгодой.
Рекомендуем использовать APIYI apiyi.com для унифицированного доступа ко всей линейке моделей DeepSeek и получения доступа к API V4 сразу после релиза.
Справочные материалы
- Dataconomy — отчет о выпуске DeepSeek V4:
dataconomy.com/2026/03/16/deepseek-v4-and-tencents-new-hunyuan-model-to-launch-in-april/ - NxCode — технические характеристики DeepSeek V4:
nxcode.io/resources/news/deepseek-v4-release-specs-benchmarks-2026 - Официальная документация DeepSeek:
platform.deepseek.com/docs
Эта статья подготовлена технической командой APIYI. Больше руководств по использованию моделей ИИ вы найдете на сайте APIYI apiyi.com.