DeepSeek V4 即將發佈,採用約 1 萬億 (1T) 參數 MoE 架構,支持原生多模態輸入和 100 萬 tokens 超長上下文。在經歷多次延期後,這款被廣泛期待的開源大模型預計在 2026 年 4 月正式亮相,將與 GPT-5.x、Claude 4 系列、Gemini 3.x 同臺競技。
核心價值: 3 分鐘瞭解 DeepSeek V4 的架構創新、關鍵參數、多模態能力,以及它對開發者生態的潛在影響。

DeepSeek V4 核心信息速覽
DeepSeek V4 是深度求索 (DeepSeek) 計劃推出的下一代旗艦大模型。從已公開的信息來看,V4 在參數規模、架構設計、多模態能力等多個維度實現了代際躍升。
| 信息項 | DeepSeek V4 |
|---|---|
| 預計發佈 | 2026 年 4 月 |
| 總參數量 | 約 1 萬億 (1T) |
| 每 token 激活參數 | 約 32-37B |
| 架構 | Transformer MoE + MLA (多頭潛注意力) |
| 專家路由 | 每 token 激活 16 個專家 |
| 上下文窗口 | 100 萬 tokens (1M) |
| 多模態 | 原生支持文本、圖像、視頻、音頻輸入 |
| 開源協議 | Apache 2.0 (預計) |
DeepSeek V4 vs V3 關鍵參數對比
DeepSeek V4 相比 V3 的核心升級一目瞭然:
| 維度 | DeepSeek V3 | DeepSeek V4 | 變化 |
|---|---|---|---|
| 總參數 | 671B | ~1T | +49% |
| 激活參數 | 37B | ~32-37B | 持平,效率優先 |
| 上下文窗口 | 128K | 1M | 8 倍擴展 |
| 多模態 | 僅文本 | 文本+圖像+視頻+音頻 | 全模態升級 |
| 注意力機制 | MLA | MLA + Engram 條件記憶 | 長上下文優化 |
| 訓練穩定性 | 標準 | mHC (流形約束超連接) | 架構創新 |
關鍵發現: V4 在總參數量增加 49% 的同時,保持了每 token 激活參數基本不變 (約 32-37B),這意味着推理成本不會大幅上升,但模型知識容量和泛化能力顯著增強。
🎯 技術建議: DeepSeek V4 發佈後,開發者可以第一時間通過 API易 apiyi.com 平臺接入測試。該平臺已支持 DeepSeek V3、R1 等全系列模型,V4 上線後將快速適配。
DeepSeek V4 架構創新 3 大技術突破
DeepSeek V4 不僅僅是參數規模的提升,更引入了 3 項關鍵架構創新,解決了萬億參數模型訓練和推理的核心難題。

創新 1: 流形約束超連接 (mHC)
DeepSeek 於 2026 年 1 月 13 日公開發表了 Manifold-Constrained Hyper-Connections (mHC) 技術論文。這項技術專門解決萬億參數 MoE 模型的訓練穩定性問題。
傳統的大規模 MoE 模型在訓練過程中容易出現梯度爆炸和專家負載不均衡等問題。mHC 通過在流形空間中約束超連接,顯著提高了訓練過程的穩定性,使 1T 參數級別的模型訓練變得可行。
創新 2: Engram 條件記憶
Engram 條件記憶是 DeepSeek V4 實現 100 萬 tokens 上下文的核心技術。傳統注意力機制在超長上下文中面臨效率和準確性的雙重挑戰。
| 指標 | 標準注意力 | Engram 條件記憶 |
|---|---|---|
| Needle-in-a-Haystack 準確率 | 84.2% | 97% |
| 長上下文檢索 | 性能衰減明顯 | 全程一致 |
| 計算開銷 | O(n²) | 優化後顯著降低 |
97% 的 Needle-in-a-Haystack 準確率意味着,即使在 100 萬 tokens 的超長文本中,模型也能精準定位和提取關鍵信息。
創新 3: 稀疏注意力 + Lightning Indexer
DeepSeek Sparse Attention 配合 Lightning Indexer 預處理引擎,實現了對超長上下文的高速處理。這項技術使得 100 萬 tokens 的輸入不再需要漫長的預處理時間,大幅降低了長文檔分析的首次響應延遲。
DeepSeek V4 原生多模態能力解析
DeepSeek V4 最大的變化之一是從純文本模型升級爲原生多模態模型。與後期拼接的多模態方案不同,V4 在預訓練階段就集成了多模態能力。
多模態輸入支持
| 模態 | 支持情況 | 說明 |
|---|---|---|
| 文本 | ✅ 原生支持 | 延續 V3 的強大文本能力 |
| 圖像 | ✅ 原生支持 | 預訓練集成,非後期拼接 |
| 視頻 | ✅ 原生支持 | 跨幀理解和分析 |
| 音頻 | ✅ 原生支持 | 語音和聲音理解 |
| 跨模態推理 | ✅ 原生支持 | 多模態信息綜合分析 |
原生多模態 vs 後期拼接
原生多模態 (在預訓練階段集成) 相比後期拼接方案有顯著優勢:
- 跨模態理解更深: 模型在訓練時就學會了不同模態間的關聯
- 推理一致性更強: 文本、圖像、視頻信息可以無縫參與同一推理鏈
- 幻覺率更低: 多模態信息相互驗證,減少單一模態的幻覺
- 延遲更低: 無需額外的模態轉換步驟
💡 選擇建議: DeepSeek V4 的原生多模態能力使其適合需要綜合分析多種信息源的場景。建議通過 API易 apiyi.com 平臺統一接入,在同一接口下對比 DeepSeek V4 和其他多模態模型的實際表現。
DeepSeek V4 發佈時間線與延期背景
DeepSeek V4 的發佈經歷了多次延期。瞭解這段歷史有助於理解 V4 面臨的技術挑戰和最終產品的成熟度。
發佈時間線
| 時間 | 事件 |
|---|---|
| 2026 年 1 月初 | Reddit 社區出現 V4 相關討論 |
| 2026 年 1 月 13 日 | mHC 技術論文發表,架構創新曝光 |
| 2026 年 1 月 20 日 | GitHub 代碼泄露,出現 28 處 "MODEL1" 內部代號引用 |
| 2026 年 1 月底 | 第一個預期發佈窗口,未能如期 |
| 2026 年 2 月 11 日 | 100 萬 tokens 上下文能力被確認 |
| 2026 年 2 月中旬 | 基準測試數據泄露 |
| 2026 年 2 月底 | 春節後發佈窗口,再次延期 |
| 2026 年 3 月 9 日 | V4 Lite 發佈 (~200B 參數,驗證核心架構) |
| 2026 年 4 月 | V4 完整版預計發佈 |
延期核心原因
V4 多次延期的主要原因是訓練基礎設施的挑戰:
- 硬件適配問題: 在國產芯片上進行萬億參數訓練面臨穩定性挑戰
- 芯片互聯帶寬: 大規模分佈式訓練對芯片間通信帶寬要求極高
- 軟件生態成熟度: 訓練框架和優化工具鏈仍在迭代中
值得注意的是,V4 Lite (約 200B 參數) 已於 3 月 9 日提前發佈,作爲完整 V4 的架構驗證版本。這一舉措表明核心架構已經過驗證,完整版的延期主要是規模化訓練的工程問題。
DeepSeek V4 API 定價預測
基於 DeepSeek 一貫的定價策略和 V4 的架構特點,我們可以對 V4 的 API 定價進行合理預測。
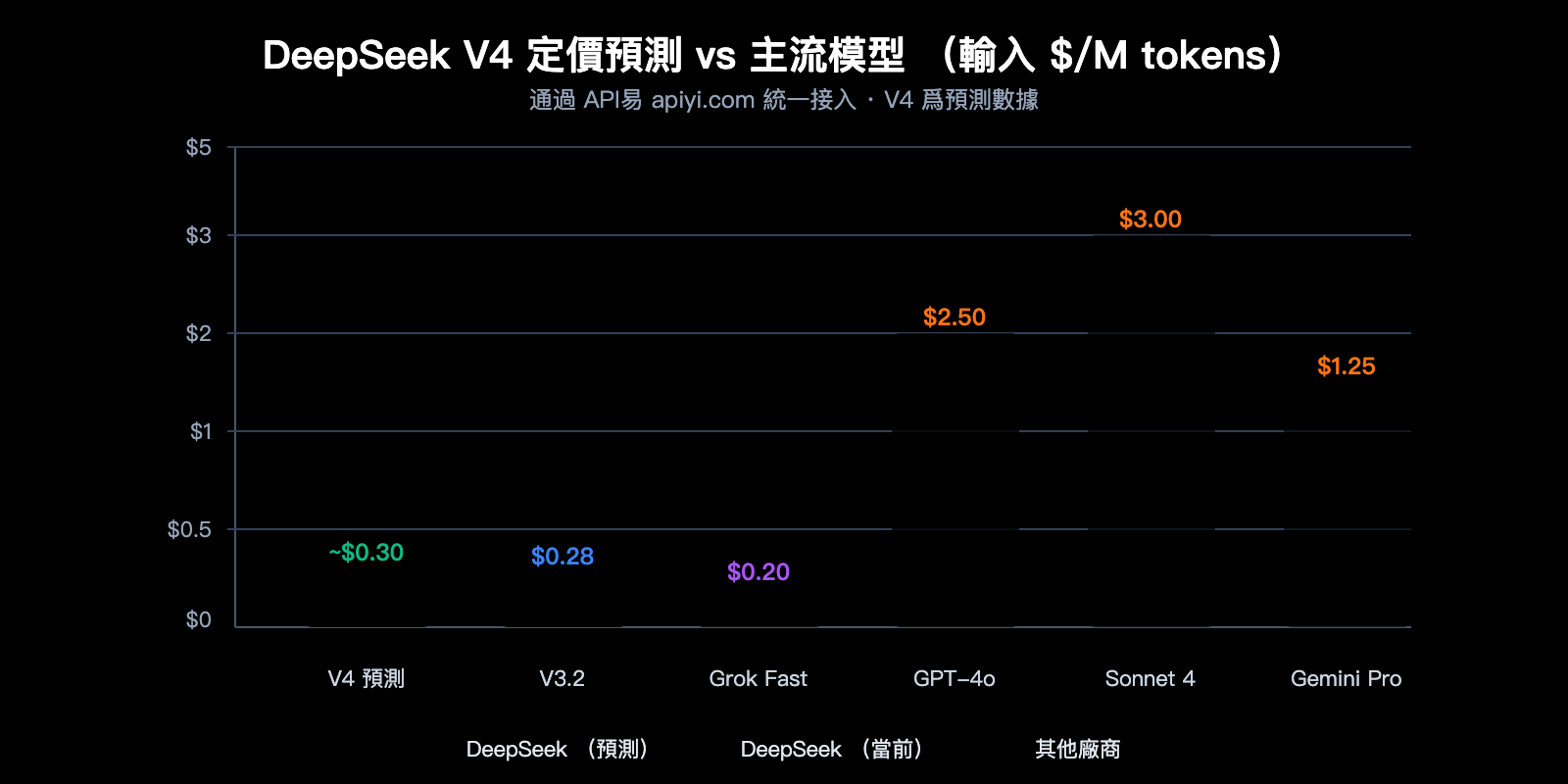
當前 DeepSeek API 定價
| 模型 | 輸入 (緩存未命中) | 輸入 (緩存命中) | 輸出 | 上下文 |
|---|---|---|---|---|
| deepseek-chat (V3.2) | $0.28/M | $0.028/M | $0.42/M | 128K |
| deepseek-reasoner (V3.2) | $0.28/M | $0.028/M | $0.42/M | 128K |
DeepSeek V4 定價預測
綜合多個來源的分析,V4 的定價預計在以下區間:
| 預測場景 | 輸入價格 | 輸出價格 | 依據 |
|---|---|---|---|
| 樂觀預測 | ~$0.14/M | ~$0.28/M | 激活參數不變,效率提升 |
| 中性預測 | ~$0.30/M | ~$0.50/M | 1M 上下文帶來額外計算成本 |
| 保守預測 | ~$0.50/M | ~$0.80/M | 多模態處理增加開銷 |
即使按保守預測,$0.50/M 的輸入價格在萬億參數多模態模型中也極具競爭力。作爲對比,GPT-4o 的輸入價格爲 $2.50/M,Claude Opus 4 爲 $15.00/M。
💰 成本優化: DeepSeek 系列一直以極致性價比著稱。通過 API易 apiyi.com 平臺,開發者可以用統一接口同時調用 DeepSeek 和其他主流模型,在成本和效果之間找到最佳平衡。
DeepSeek V4 競爭格局分析
2026 年 4 月是 AI 大模型的密集發佈期。DeepSeek V4 將面對來自多個方向的競爭。
同期競品對比
| 模型 | 廠商 | 參數規模 | 上下文 | 多模態 | 開源 |
|---|---|---|---|---|---|
| DeepSeek V4 | DeepSeek | ~1T (MoE) | 1M | ✅ 原生 | ✅ Apache 2.0 |
| GPT-5.x | OpenAI | 未公開 | 未公開 | ✅ | ❌ |
| Claude 4 系列 | Anthropic | 未公開 | 1M | ✅ | ❌ |
| Gemini 3.x | 未公開 | 2M | ✅ | ❌ | |
| Grok 4.x | xAI | 未公開 | 2M | ✅ | ❌ |
DeepSeek V4 的差異化優勢
- 開源: 預計採用 Apache 2.0 協議,這在萬億參數級別的模型中幾乎是獨一無二的
- 極致性價比: DeepSeek 的定價策略一直是同級別模型中最低的
- 本地部署可能: 開源意味着企業可以在自有基礎設施上部署
- MoE 效率: 激活參數僅 32-37B,推理效率遠高於同參數量的稠密模型
DeepSeek V4 本地部署硬件需求
對於希望本地部署的團隊,V4 的硬件需求如下:
| 量化方式 | 所需 VRAM | 推薦硬件 |
|---|---|---|
| FP16/BF16 (全精度) | 極大 | 多節點 GPU 集羣 |
| INT8 (8位量化) | ~48GB | 雙 RTX 4090 |
| INT4 (4位量化) | ~32GB | 單 RTX 5090 |
INT4 量化後僅需單張 RTX 5090 即可運行,這使得中小團隊和研究人員的本地部署成爲可能。
DeepSeek 模型版本演進
瞭解 DeepSeek 的完整產品演進有助於理解 V4 的定位和技術路線。
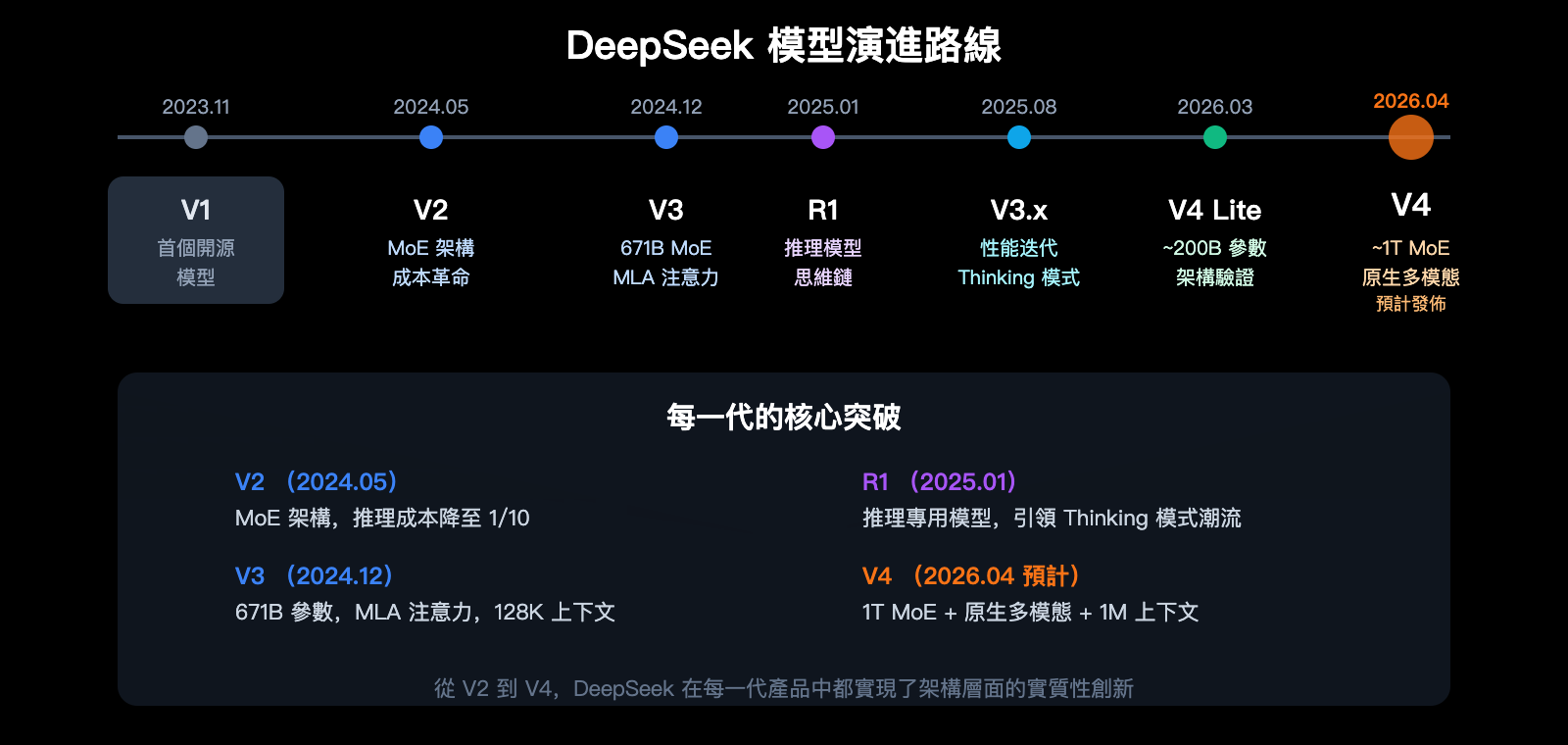
| 版本 | 發佈時間 | 核心特點 |
|---|---|---|
| V1 | 2023 年 11 月 | 首個開源模型 |
| V2 | 2024 年 5 月 | MoE 架構引入,成本大幅降低 |
| V2.5 | 2024 年 9 月 | 對話和代碼能力增強 |
| V3 | 2024 年 12 月 | 671B 參數,MLA 注意力,128K 上下文 |
| R1 | 2025 年 1 月 | 推理專用模型,思維鏈技術 |
| V3.1 | 2025 年 8 月 | 性能優化,推理增強 |
| V3.2 | 2025 年底 | 當前主力模型,支持 Thinking 模式 |
| V4 Lite | 2026 年 3 月 | ~200B 參數,架構驗證版 |
| V4 | 2026 年 4 月 (預計) | ~1T MoE,原生多模態,1M 上下文 |
從 V2 引入 MoE 架構,到 V3 的 MLA 注意力,再到 V4 的 mHC 和 Engram 技術,DeepSeek 的每一代產品都在架構層面有實質性創新。
🎯 技術建議: 在等待 V4 正式發佈期間,開發者可以先通過 API易 apiyi.com 平臺使用 DeepSeek V3.2 和 R1 進行開發。V4 發佈後平臺將第一時間接入。
常見問題
Q1: DeepSeek V4 什麼時候正式發佈?
根據多方信息彙總,DeepSeek V4 預計在 2026 年 4 月發佈。此前已經歷了 1 月底和 2 月底兩次延期。3 月 9 日發佈的 V4 Lite (~200B 參數) 驗證了核心架構可行性,完整版發佈的可能性較高。通過 API易 apiyi.com 平臺可以第一時間獲取 V4 API 接入。
Q2: DeepSeek V4 的 1T 參數是否意味着推理成本很高?
不一定。V4 採用 MoE 架構,每個 token 僅激活約 32-37B 參數,與 V3 基本持平。這意味着推理時的實際計算量不會大幅增加,成本也有望保持在合理範圍。DeepSeek 的定價策略一貫激進,V4 的 API 價格預計仍將極具競爭力。
Q3: DeepSeek R2 推理模型還會發布嗎?
DeepSeek R2 的發佈時間目前仍不明確。部分分析認爲 R2 的推理能力可能被直接整合進 V4 (V3.2 已支持 Thinking 模式)。也有觀點認爲 R2 仍在獨立開發中,但面臨訓練挑戰。建議關注 DeepSeek 官方動態獲取最新信息。
Q4: V4 發佈前,開發者應該做什麼準備?
建議提前熟悉 DeepSeek API 的調用方式。V4 大概率兼容現有的 OpenAI 兼容接口,遷移成本很低。通過 API易 apiyi.com 平臺使用 DeepSeek V3.2 進行開發和測試,V4 上線後只需切換模型名稱即可。
總結
DeepSeek V4 有望成爲 2026 年最重要的開源大模型發佈之一。約 1T 參數的 MoE 架構、100 萬 tokens 超長上下文、原生多模態支持,加上 Apache 2.0 開源協議和極致的性價比,V4 在技術指標和商業價值上都值得期待。
核心要點回顧:
- 架構: ~1T 參數 MoE,每 token 激活 32-37B,效率優先
- 上下文: 100 萬 tokens,Engram 條件記憶實現 97% 檢索準確率
- 多模態: 原生支持文本、圖像、視頻、音頻輸入
- 創新: mHC 訓練穩定性 + Engram 條件記憶 + 稀疏注意力
- 開源: 預計 Apache 2.0,INT4 量化可在單張 RTX 5090 運行
- 定價: 預計保持 DeepSeek 一貫的極致性價比
推薦通過 API易 apiyi.com 統一接入 DeepSeek 全系列模型,V4 發佈後第一時間獲取 API 訪問。
參考資料
- Dataconomy – DeepSeek V4 發佈報道:
dataconomy.com/2026/03/16/deepseek-v4-and-tencents-new-hunyuan-model-to-launch-in-april/ - NxCode – DeepSeek V4 技術規格:
nxcode.io/resources/news/deepseek-v4-release-specs-benchmarks-2026 - DeepSeek 官方文檔:
platform.deepseek.com/docs
本文由 APIYI Team 技術團隊撰寫,更多 AI 模型使用教程請關注 API易 apiyi.com