DeepSeek V4 está a punto de lanzarse, con una arquitectura MoE de aproximadamente 1 billón (1T) de parámetros, soporte para entrada multimodal nativa y una ventana de contexto ultralarga de 1 millón de tokens. Tras varios retrasos, este esperado Modelo de Lenguaje Grande de código abierto se estrenará oficialmente en abril de 2026, compitiendo directamente con las series GPT-5.x, Claude 4 y Gemini 3.x.
Valor central: Descubre en 3 minutos la innovación arquitectónica, los parámetros clave y las capacidades multimodales de DeepSeek V4, así como su impacto potencial en el ecosistema de desarrolladores.
Resumen de información clave de DeepSeek V4
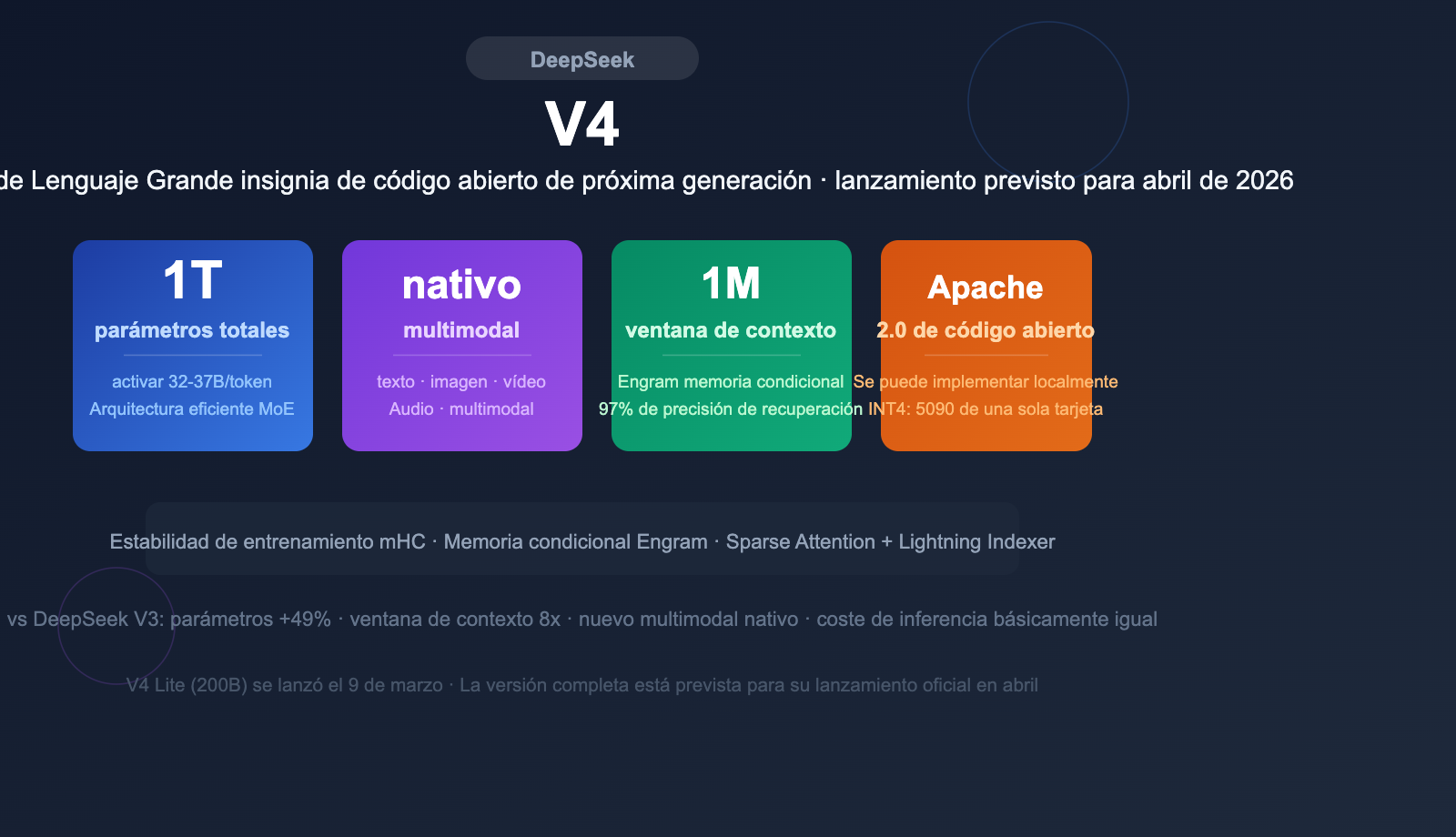
DeepSeek V4 es el Modelo de Lenguaje Grande insignia de próxima generación que planea lanzar DeepSeek. Según la información pública, V4 ha logrado un salto generacional en múltiples dimensiones, como la escala de parámetros, el diseño de arquitectura y las capacidades multimodales.
| Elemento de información | DeepSeek V4 |
|---|---|
| Lanzamiento previsto | Abril de 2026 |
| Parámetros totales | ~1 billón (1T) |
| Parámetros activados por token | ~32-37B |
| Arquitectura | Transformer MoE + MLA (Atención latente multi-cabeza) |
| Enrutamiento de expertos | 16 expertos activados por token |
| Ventana de contexto | 1 millón de tokens (1M) |
| Multimodal | Soporte nativo para entrada de texto, imagen, video y audio |
| Licencia de código abierto | Apache 2.0 (previsto) |
Comparativa de parámetros clave: DeepSeek V4 vs V3
Las actualizaciones principales de DeepSeek V4 en comparación con V3 son evidentes:
| Dimensión | DeepSeek V3 | DeepSeek V4 | Cambio |
|---|---|---|---|
| Parámetros totales | 671B | ~1T | +49% |
| Parámetros activados | 37B | ~32-37B | Estable, eficiencia primero |
| Ventana de contexto | 128K | 1M | Expansión 8x |
| Multimodal | Solo texto | Texto+Imagen+Video+Audio | Actualización multimodal completa |
| Mecanismo de atención | MLA | MLA + Memoria condicional Engram | Optimización de contexto largo |
| Estabilidad de entrenamiento | Estándar | mHC (Hiperconexión con restricción de variedad) | Innovación arquitectónica |
Hallazgo clave: Mientras que el número total de parámetros de V4 aumenta un 49%, los parámetros activados por token se mantienen prácticamente iguales (alrededor de 32-37B). Esto significa que el costo de inferencia no aumentará drásticamente, pero la capacidad de conocimiento y la generalización del modelo se verán significativamente reforzadas.
🎯 Recomendación técnica: Una vez que se lance DeepSeek V4, los desarrolladores podrán acceder y probarlo de inmediato a través de la plataforma APIYI (apiyi.com). Esta plataforma ya admite la serie completa de modelos como DeepSeek V3 y R1, y se adaptará rápidamente tras el lanzamiento de V4.
Innovaciones en la arquitectura de DeepSeek V4: 3 avances técnicos clave
DeepSeek V4 no es solo un aumento en la escala de parámetros; introduce 3 innovaciones arquitectónicas fundamentales que resuelven los desafíos críticos del entrenamiento e inferencia de modelos de billones de parámetros.
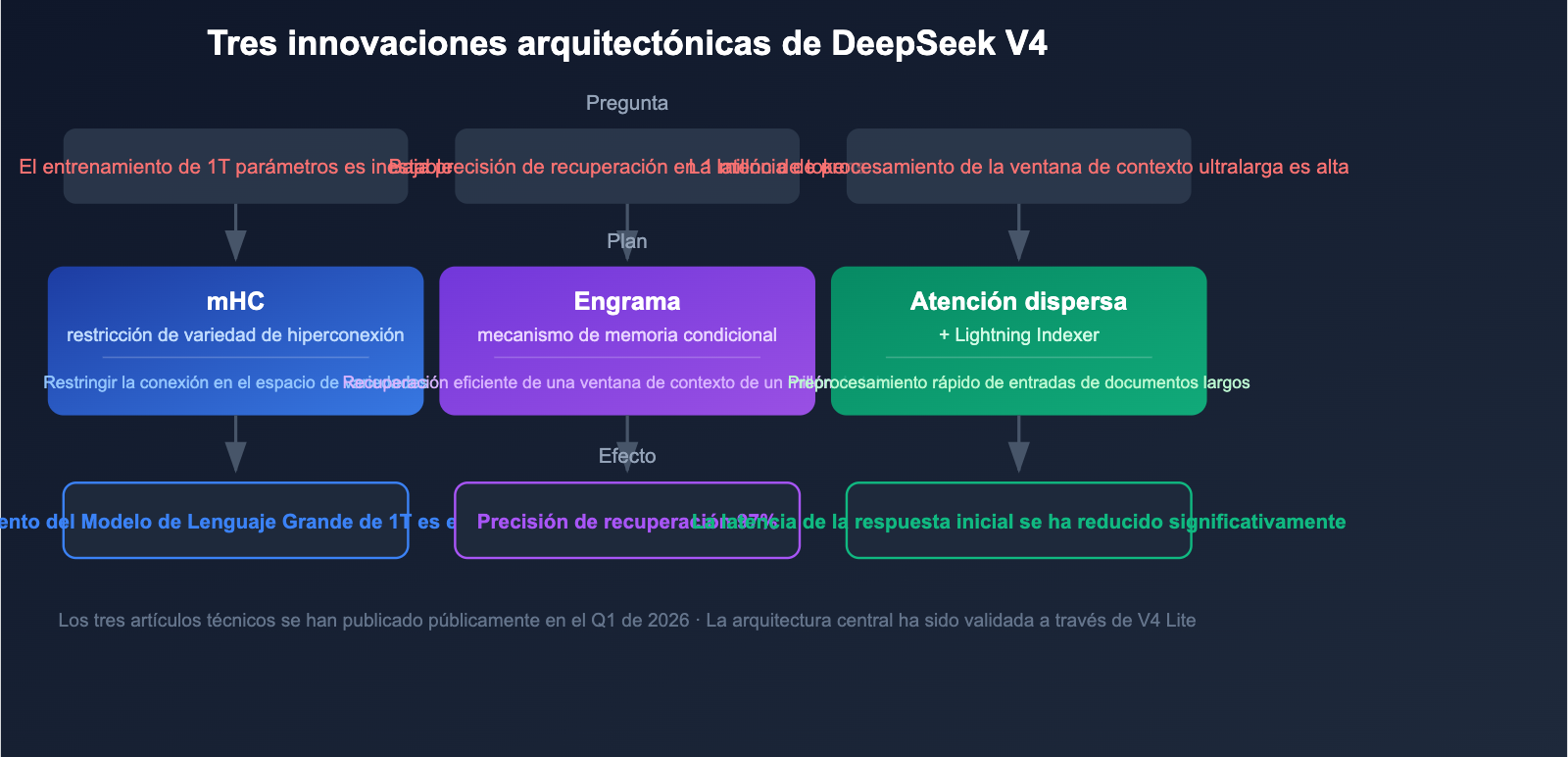
Innovación 1: Hiperconexiones restringidas por variedades (mHC)
DeepSeek publicó el artículo técnico sobre la tecnología de Hiperconexiones restringidas por variedades (mHC, por sus siglas en inglés) el 13 de enero de 2026. Esta tecnología resuelve específicamente los problemas de estabilidad en el entrenamiento de modelos MoE de billones de parámetros.
Los modelos MoE tradicionales a gran escala suelen sufrir de explosión de gradientes y desequilibrio en la carga de expertos durante el entrenamiento. Al restringir las hiperconexiones en el espacio de variedades, mHC mejora significativamente la estabilidad, haciendo viable el entrenamiento de modelos de 1 billón de parámetros.
Innovación 2: Memoria condicional Engram
La memoria condicional Engram es la tecnología central que permite a DeepSeek V4 alcanzar una ventana de contexto de 1 millón de tokens. Los mecanismos de atención tradicionales enfrentan desafíos de eficiencia y precisión en contextos extremadamente largos.
| Indicador | Atención estándar | Memoria condicional Engram |
|---|---|---|
| Precisión "Needle-in-a-Haystack" | 84.2% | 97% |
| Recuperación de contexto largo | Degradación notable | Consistente en todo el proceso |
| Costo computacional | O(n²) | Reducción significativa tras optimización |
Una precisión del 97% en la prueba "Needle-in-a-Haystack" significa que, incluso en textos de 1 millón de tokens, el modelo puede localizar y extraer información clave con total precisión.
Innovación 3: Atención dispersa + Lightning Indexer
La combinación de la atención dispersa (Sparse Attention) de DeepSeek con el motor de preprocesamiento Lightning Indexer permite un procesamiento de alta velocidad para contextos ultra largos. Esta tecnología elimina la necesidad de largos tiempos de preprocesamiento para entradas de 1 millón de tokens, reduciendo drásticamente la latencia de respuesta inicial en el análisis de documentos extensos.
Análisis de las capacidades multimodales nativas de DeepSeek V4
Uno de los cambios más importantes en DeepSeek V4 es su evolución de un modelo de solo texto a uno multimodal nativo. A diferencia de las soluciones multimodales que se añaden posteriormente, V4 integra capacidades multimodales desde la fase de preentrenamiento.
Soporte de entrada multimodal
| Modalidad | Estado | Notas |
|---|---|---|
| Texto | ✅ Soporte nativo | Continúa la potente capacidad de texto de V3 |
| Imagen | ✅ Soporte nativo | Integrado en preentrenamiento, no añadido después |
| Video | ✅ Soporte nativo | Comprensión y análisis entre fotogramas |
| Audio | ✅ Soporte nativo | Comprensión de voz y sonido |
| Razonamiento multimodal | ✅ Soporte nativo | Análisis integral de información multimodal |
Multimodalidad nativa vs. Integración posterior
La multimodalidad nativa (integrada en la fase de preentrenamiento) ofrece ventajas significativas frente a las soluciones de integración posterior:
- Comprensión intermodal más profunda: El modelo aprende la relación entre diferentes modalidades durante el entrenamiento.
- Mayor consistencia en la inferencia: La información de texto, imagen y video puede participar sin problemas en la misma cadena de razonamiento.
- Menor tasa de alucinaciones: La información de múltiples modalidades se verifica entre sí, reduciendo las alucinaciones de una sola modalidad.
- Menor latencia: No requiere pasos adicionales de conversión de modalidad.
💡 Sugerencia: Las capacidades multimodales nativas de DeepSeek V4 lo hacen ideal para escenarios que requieren un análisis integral de diversas fuentes de información. Te recomendamos acceder a través de la plataforma APIYI (apiyi.com) para integrar y comparar el rendimiento real de DeepSeek V4 con otros modelos multimodales bajo una misma interfaz.
Cronología de lanzamiento y contexto de los retrasos de DeepSeek V4
El lanzamiento de DeepSeek V4 ha experimentado múltiples retrasos. Conocer esta historia ayuda a comprender los desafíos técnicos a los que se enfrentó la versión V4 y el nivel de madurez del producto final.
Cronología de lanzamiento
| Fecha | Evento |
|---|---|
| Principios de enero de 2026 | Aparecen las primeras discusiones sobre V4 en la comunidad de Reddit |
| 13 de enero de 2026 | Publicación del artículo técnico sobre mHC, revelando innovaciones en la arquitectura |
| 20 de enero de 2026 | Filtración de código en GitHub, con 28 referencias al nombre en clave interno "MODEL1" |
| Finales de enero de 2026 | Primera ventana de lanzamiento prevista, no se cumplió |
| 11 de febrero de 2026 | Se confirma la capacidad de 1 millón de tokens en la ventana de contexto |
| Mediados de febrero de 2026 | Filtración de datos de pruebas comparativas (benchmarks) |
| Finales de febrero de 2026 | Ventana de lanzamiento tras el Año Nuevo chino, nuevo retraso |
| 9 de marzo de 2026 | Lanzamiento de V4 Lite (~200B de parámetros, validación de la arquitectura central) |
| Abril de 2026 | Lanzamiento previsto de la versión completa de V4 |
Razones principales de los retrasos
Los motivos fundamentales de los múltiples retrasos de V4 se deben a desafíos en la infraestructura de entrenamiento:
- Problemas de adaptación de hardware: Desafíos de estabilidad al entrenar modelos de billones de parámetros en chips de fabricación nacional.
- Ancho de banda de interconexión de chips: El entrenamiento distribuido a gran escala exige un ancho de banda de comunicación extremadamente alto entre chips.
- Madurez del ecosistema de software: El marco de entrenamiento y las herramientas de optimización aún están en fase de iteración.
Cabe destacar que la versión V4 Lite (aprox. 200B de parámetros) se lanzó anticipadamente el 9 de marzo como una versión de validación de arquitectura para la V4 completa. Esta medida demuestra que la arquitectura central ya ha sido validada, y que el retraso de la versión completa se debe principalmente a problemas de ingeniería relacionados con el entrenamiento a gran escala.
Predicción de precios de la API de DeepSeek V4
Basándonos en la estrategia de precios constante de DeepSeek y las características de la arquitectura de V4, podemos realizar una predicción razonable sobre los precios de su API.
Precios actuales de la API de DeepSeek
| Modelo | Entrada (caché fallida) | Entrada (caché acertada) | Salida | Ventana de contexto |
|---|---|---|---|---|
| deepseek-chat (V3.2) | $0.28/M | $0.028/M | $0.42/M | 128K |
| deepseek-reasoner (V3.2) | $0.28/M | $0.028/M | $0.42/M | 128K |
Predicción de precios de DeepSeek V4
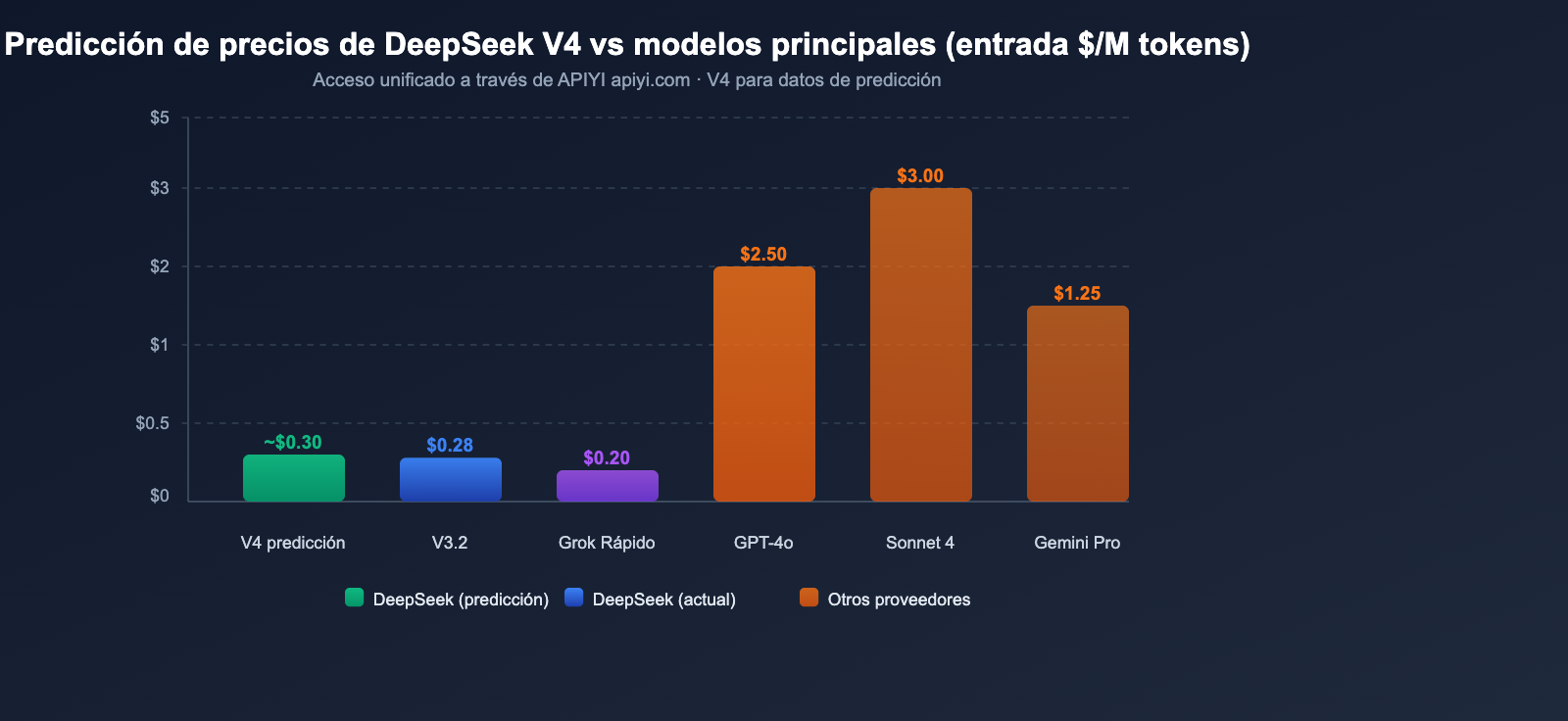
Combinando el análisis de diversas fuentes, se espera que los precios de V4 se sitúen en el siguiente rango:
| Escenario de predicción | Precio de entrada | Precio de salida | Fundamento |
|---|---|---|---|
| Predicción optimista | ~$0.14/M | ~$0.28/M | Parámetros activos constantes, mejora de eficiencia |
| Predicción neutral | ~$0.30/M | ~$0.50/M | 1M de contexto conlleva costes de cómputo adicionales |
| Predicción conservadora | ~$0.50/M | ~$0.80/M | El procesamiento multimodal aumenta los gastos |
Incluso bajo una predicción conservadora, el precio de entrada de $0.50/M es extremadamente competitivo para un modelo multimodal de billones de parámetros. Como comparación, el precio de entrada de GPT-4o es de $2.50/M y el de Claude Opus 4 es de $15.00/M.
💰 Optimización de costes: La serie DeepSeek siempre se ha caracterizado por su excelente relación calidad-precio. A través de la plataforma APIYI (apiyi.com), los desarrolladores pueden utilizar una interfaz unificada para invocar tanto a DeepSeek como a otros modelos líderes, logrando el equilibrio perfecto entre coste y rendimiento.
Análisis del panorama competitivo de DeepSeek V4
Abril de 2026 marca un periodo de lanzamientos intensos para los Modelos de Lenguaje Grande. DeepSeek V4 se enfrentará a la competencia desde múltiples frentes.
Comparativa con competidores del mismo periodo
| Modelo | Fabricante | Escala de parámetros | Contexto | Multimodal | Código abierto |
|---|---|---|---|---|---|
| DeepSeek V4 | DeepSeek | ~1T (MoE) | 1M | ✅ Nativo | ✅ Apache 2.0 |
| GPT-5.x | OpenAI | No público | No público | ✅ | ❌ |
| Serie Claude 4 | Anthropic | No público | 1M | ✅ | ❌ |
| Gemini 3.x | No público | 2M | ✅ | ❌ | |
| Grok 4.x | xAI | No público | 2M | ✅ | ❌ |
Ventajas diferenciales de DeepSeek V4
- Código abierto: Se espera que adopte la licencia Apache 2.0, algo casi único en modelos de escala de billones de parámetros.
- Relación calidad-precio extrema: La estrategia de precios de DeepSeek siempre ha sido la más baja entre los modelos de su categoría.
- Posibilidad de despliegue local: El código abierto permite a las empresas desplegar el modelo en su propia infraestructura.
- Eficiencia MoE: Con parámetros de activación de solo 32-37B, la eficiencia de inferencia es muy superior a la de los modelos densos con la misma cantidad de parámetros.
Requisitos de hardware para el despliegue local de DeepSeek V4
Para los equipos que deseen realizar un despliegue local, los requisitos de hardware para V4 son los siguientes:
| Método de cuantización | VRAM necesaria | Hardware recomendado |
|---|---|---|
| FP16/BF16 (Precisión completa) | Extremadamente alta | Clúster de GPU multinodo |
| INT8 (Cuantización de 8 bits) | ~48GB | Dual RTX 4090 |
| INT4 (Cuantización de 4 bits) | ~32GB | RTX 5090 individual |
Tras la cuantización INT4, es posible ejecutarlo con una sola RTX 5090, lo que hace viable el despliegue local para equipos pequeños y investigadores.
Evolución de las versiones del modelo DeepSeek
Comprender la evolución completa del producto DeepSeek ayuda a entender el posicionamiento y la ruta técnica de la V4.

| Versión | Fecha de lanzamiento | Características principales |
|---|---|---|
| V1 | Noviembre de 2023 | Primer modelo de código abierto |
| V2 | Mayo de 2024 | Introducción de la arquitectura MoE, reducción drástica de costes |
| V2.5 | Septiembre de 2024 | Mejora en capacidades de diálogo y código |
| V3 | Diciembre de 2024 | 671B de parámetros, atención MLA, 128K de ventana de contexto |
| R1 | Enero de 2025 | Modelo especializado en razonamiento, tecnología de cadena de pensamiento |
| V3.1 | Agosto de 2025 | Optimización de rendimiento, mejora en razonamiento |
| V3.2 | Finales de 2025 | Modelo principal actual, compatible con modo Thinking |
| V4 Lite | Marzo de 2026 | ~200B de parámetros, versión de validación de arquitectura |
| V4 | Abril de 2026 (previsto) | ~1T MoE, multimodal nativo, 1M de ventana de contexto |
Desde la introducción de la arquitectura MoE en la V2, pasando por la atención MLA de la V3, hasta las tecnologías mHC y Engram de la V4, cada generación de productos de DeepSeek ha contado con innovaciones sustanciales a nivel de arquitectura.
🎯 Consejo técnico: Mientras esperas el lanzamiento oficial de la V4, los desarrolladores pueden comenzar a trabajar utilizando DeepSeek V3.2 y R1 a través de la plataforma APIYI (apiyi.com). La plataforma integrará la V4 tan pronto como sea lanzada.
Preguntas frecuentes
Q1: ¿Cuándo se lanzará oficialmente DeepSeek V4?
Según la información recopilada de diversas fuentes, se espera que DeepSeek V4 se lance en abril de 2026. Anteriormente, el lanzamiento se había pospuesto dos veces, a finales de enero y finales de febrero. El lanzamiento de la versión V4 Lite (~200B de parámetros) el 9 de marzo validó la viabilidad de la arquitectura central, por lo que la probabilidad de un lanzamiento completo es alta. A través de la plataforma APIYI (apiyi.com) podrás obtener acceso a la API de V4 tan pronto como esté disponible.
Q2: ¿El billón (1T) de parámetros de DeepSeek V4 implica un costo de inferencia muy elevado?
No necesariamente. V4 utiliza una arquitectura MoE, donde cada token activa solo unos 32-37B de parámetros, lo cual está básicamente al mismo nivel que la versión V3. Esto significa que la carga de cálculo real durante la inferencia no aumentará drásticamente y se espera que los costos se mantengan en un rango razonable. La estrategia de precios de DeepSeek siempre ha sido agresiva, por lo que se espera que el precio de la API de V4 siga siendo extremadamente competitivo.
Q3: ¿Se lanzará el modelo de razonamiento DeepSeek R2?
La fecha de lanzamiento de DeepSeek R2 aún no está clara. Algunos análisis sugieren que las capacidades de razonamiento de R2 podrían integrarse directamente en V4 (la versión V3.2 ya admite el modo "Thinking"). Otros puntos de vista sostienen que R2 sigue en desarrollo independiente, pero enfrenta desafíos de entrenamiento. Se recomienda seguir los canales oficiales de DeepSeek para obtener la información más reciente.
Q4: ¿Qué preparativos deben hacer los desarrolladores antes del lanzamiento de V4?
Se recomienda familiarizarse con el método de invocación del modelo de la API de DeepSeek con antelación. Es muy probable que V4 sea compatible con la interfaz estándar de OpenAI, por lo que el costo de migración será muy bajo. Puedes utilizar DeepSeek V3.2 a través de la plataforma APIYI (apiyi.com) para realizar el desarrollo y las pruebas; una vez que V4 esté en línea, solo tendrás que cambiar el nombre del modelo.
Resumen
Se espera que DeepSeek V4 se convierta en uno de los lanzamientos de Modelo de Lenguaje Grande de código abierto más importantes de 2026. Con una arquitectura MoE de aproximadamente 1T de parámetros, una ventana de contexto ultralarga de 1 millón de tokens, soporte multimodal nativo, además de la licencia de código abierto Apache 2.0 y una relación costo-beneficio inigualable, V4 es una propuesta prometedora tanto en indicadores técnicos como en valor comercial.
Resumen de puntos clave:
- Arquitectura: MoE de ~1T de parámetros, con 32-37B activados por token, priorizando la eficiencia.
- Contexto: 1 millón de tokens, con memoria condicional Engram que logra una precisión de recuperación del 97%.
- Multimodal: Soporte nativo para entradas de texto, imagen, video y audio.
- Innovación: Estabilidad de entrenamiento mHC + memoria condicional Engram + atención dispersa.
- Código abierto: Se espera bajo licencia Apache 2.0; la cuantización INT4 permitirá su ejecución en una sola RTX 5090.
- Precios: Se espera que mantenga la excelente relación costo-beneficio característica de DeepSeek.
Te recomendamos acceder a toda la serie de modelos de DeepSeek de forma unificada a través de APIYI (apiyi.com) para obtener acceso a la API tan pronto como se lance V4.
Referencias
- Dataconomy – Informe sobre el lanzamiento de DeepSeek V4:
dataconomy.com/2026/03/16/deepseek-v4-and-tencents-new-hunyuan-model-to-launch-in-april/ - NxCode – Especificaciones técnicas de DeepSeek V4:
nxcode.io/resources/news/deepseek-v4-release-specs-benchmarks-2026 - Documentación oficial de DeepSeek:
platform.deepseek.com/docs
Este artículo fue redactado por el equipo técnico de APIYI. Para más tutoriales sobre el uso de Modelos de Lenguaje Grande, visita APIYI en apiyi.com.