On April 24, 2026, DeepSeek simultaneously open-sourced two preview models on Hugging Face: V4-Pro and V4-Flash. The former is a 1.6T parameter MoE beast designed for cutting-edge performance, while the latter is a cost-effective "sweet spot" that offers 90% of the Pro's capability at just 1/12th the price.
If you only pay attention to one model, make it deepseek-v4-flash. Here’s why:
- 284B / 13B MoE architecture + Hybrid Attention: Inference FLOPs at a 1M context window are only 27% of V3.2.
- 1M tokens context / 384K tokens max output: Native support for long documents—no more chunking.
- $0.14 input / $0.28 output per million tokens: An order of magnitude cheaper than the Pro version.
- 79.0% on SWE-bench Verified and 45–47 on the Artificial Analysis Intelligence Index: More than enough for the vast majority of use cases.
- Dual-protocol compatibility: Supports both OpenAI ChatCompletions and Anthropic API, making it a drop-in replacement for Claude Code, OpenClaw, and OpenCode with zero modifications.
One critical note: The legacy models deepseek-chat and deepseek-reasoner will be officially retired on July 24, 2026. All production services must be migrated before this date. That’s a hard 90-day countdown.
The good news is: deepseek-v4-flash is now available on APIYI (apiyi.com). You don't need to set up a DeepSeek account, modify your SDK, or handle international payments—just update your model field and point your base_url to api.apiyi.com to get started.
This article is a 3+5 guide: 3 minutes to understand the core V4-Flash upgrades + 5 minutes to complete your migration from the legacy models.
1. The 5 Core Upgrades of deepseek-v4-flash
1.1 Core Specifications Overview
Let’s look at the big picture before diving into the details:
| Dimension | deepseek-v4-flash |
|---|---|
| Release Date | 2026-04-24 (Preview) |
| Open Source Repo | huggingface.co/deepseek-ai/DeepSeek-V4-Flash |
| Total Parameters | 284B (Mixture of Experts) |
| Active Parameters | 13B |
| Context Window | 1M tokens |
| Max Output | 384K tokens |
| Attention Architecture | Hybrid Attention (CSA + HCA) |
| Inference Mode | Thinking / Non-Thinking dual modes |
| Function Calling | ✅ Supported |
| JSON Mode | ✅ Supported |
| Chat Prefix Completion | Beta supported |
| API Protocol | OpenAI ChatCompletions + Anthropic dual compatibility |
| Input Price | $0.14 / M tokens |
| Output Price | $0.28 / M tokens |
Here is a breakdown of these 5 upgrades.
1.2 Upgrade 1: 1M Context + 384K Output (Native Long-Context)
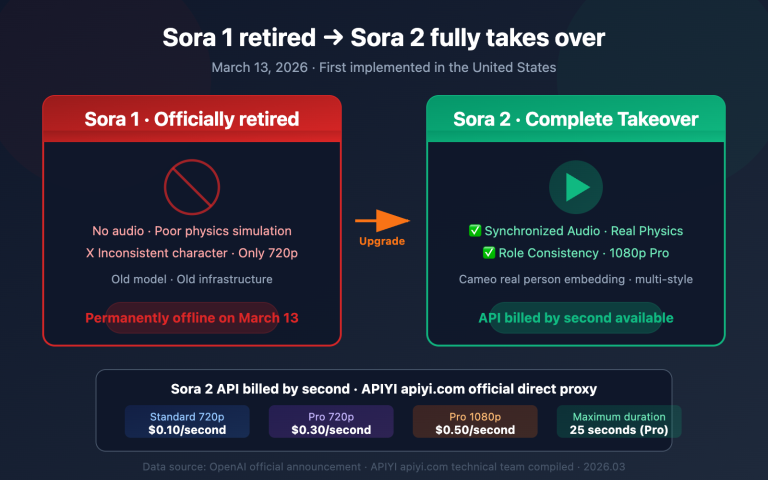
deepseek-v4-flash natively supports 1M tokens of input and 384K tokens of output. This is the standard specification for the entire V4 series; Flash hasn't sacrificed context length for affordability.
What can you fit into 1M tokens?
| Content Type | Approximate Token Count |
|---|---|
| 100,000-character Chinese manuscript | ≈ 150K tokens |
| 200-page PDF technical document | ≈ 300K tokens |
| Mid-sized code repository (~50 files) | ≈ 500K–800K tokens |
| The entire "Dream of the Red Chamber" | ≈ 1M tokens |
Compared to GPT-5.4 (400K), Claude Opus 4.6 (1M + 1M context window package), and Gemini 3.1-Pro (2M), V4-Flash's 1M is already an industry-standard configuration, yet it costs 5–20 times less than the others.
1.3 Upgrade 2: 284B/13B MoE + Hybrid Attention
V4-Flash utilizes two key architectural innovations introduced by DeepSeek in 2026:
- MoE: 284B total parameters, with only 13B activated per token. This delivers performance close to a 13B dense model but with the knowledge breadth of a 200B+ dense model.
- Hybrid Attention (Compressed Sparse Attention + Highly Compressed Attention): Specifically designed for long contexts.
Efficiency Benchmarks (via official DeepSeek data):
| Metric | V3.2 | V4-Flash | Improvement |
|---|---|---|---|
| 1M context single-token inference FLOPs | 100% | 27% | -73% |
| 1M context KV cache usage | 100% | 10% | -90% |
These two figures explain why Flash can keep prices at $0.14: the underlying compute costs have genuinely decreased, rather than being heavily subsidized.
1.4 Upgrade 3: Thinking / Non-Thinking Dual Modes
V4-Flash allows you to switch between two modes using the same model ID:
- Non-Thinking (Default): Fast, ideal for casual chat, Q&A, classification, and summarization.
- Thinking: The model outputs internal reasoning first (similar to OpenAI's o-series) before providing the final answer. Ideal for complex reasoning, multi-step tool invocation, and code debugging.
You toggle this via request parameters (no need for separate model IDs), requiring minimal developer effort. When calling via APIYI (api.apiyi.com), the parameter names are identical to the official DeepSeek API.
1.5 Upgrade 4: $0.14 / $0.28 per M tokens
This is the most impressive set of numbers from this release:
| Model | Input ($/M) | Output ($/M) | Relative to V4-Flash |
|---|---|---|---|
| deepseek-v4-flash | 0.14 | 0.28 | 1× (Baseline) |
| deepseek-v4-pro | 1.74 | 3.48 | 12× |
| GPT-5.4 (Ref) | 2.50 | 10.00 | 17×–35× |
| Claude Sonnet 4.6 (Ref) | 3.00 | 15.00 | 21×–53× |
For a typical request of "500 tokens input + 500 tokens output":
- V4-Flash: $0.000 21 ≈ ¥0.0015
- GPT-5.4: $0.006 25 ≈ ¥0.045
- Claude Sonnet 4.6: $0.009 ≈ ¥0.065
Flash is 30–40 times cheaper. For products with monthly volumes in the hundreds of millions of tokens, this directly impacts your gross margin.
1.6 Upgrade 5: OpenAI + Anthropic Dual Protocol Compatibility
V4-Flash implements two protocols at the API layer:
POST /v1/chat/completions→ OpenAI formatPOST /v1/messages→ Anthropic format
This means:
| Client | Migration Cost |
|---|---|
| OpenAI Python/Node SDK | Zero changes, just update base_url and model |
| Anthropic Python/Node SDK | Zero changes, just update base_url and model |
| Claude Code | Just switch the Anthropic endpoint |
| OpenClaw / OpenCode | Natively supported |
| LangChain / LlamaIndex | Just update the base_url |
This was a very smart decision by DeepSeek for this release: they aren't forcing you to learn a new protocol, allowing existing ecosystems to integrate at zero cost.
1.7 Benchmark Comparison Table
| Benchmark | V4-Flash | V4-Pro | Gap |
|---|---|---|---|
| SWE-bench Verified (Code Repair) | 79.0% | 82.1% | -3.1 |
| Terminal-Bench 2.0 (Multi-step Tools) | 56.9% | 67.9% | -11.0 |
| SimpleQA-Verified (Fact Retrieval) | 34.1% | 57.9% | -23.8 |
| Artificial Analysis Intelligence Index | 45 / 47 | 58 | -11 ~ -13 |
Takeaway: Flash nearly matches the Pro version on single-step coding tasks (SWE-bench), but there is a noticeable gap in multi-step toolchain requirements (Terminal-Bench) and factual memory (SimpleQA). These gaps are exactly what you should use to decide whether to choose Flash or Pro.
2. DeepSeek-V4-Flash vs. V4-Pro Scenario Decision
{deepseek-v4-flash · Architecture and Core Metrics}
{Mixture of Experts · Hybrid Attention · 1M context window}
{284B total parameters (MoE)}
{13B activated parameters}
{per token · efficiency is key}
{attention architecture}
{Hybrid Attention}
{• CSA Compressed Sparse Attention}
{• HCA Highly Compressed Attention}
{context / output}
{1M tokens}
{Maximum output 384K tokens}
{Code repair Benchmark}
{SWE-bench 79.0%}
{Close to V4-Pro (82.1%)}
{API pricing}
{$0.14 / M}
{Output $0.28 · only 1/12 of Pro}
{V3.2 to V4-Flash efficiency improvement}
{1M context window inference FLOPs:}
{-73%}
{Only 27% of V3.2}
{KV Cache usage:}
{-90%}
{Only 10% of V3.2}
2.1 A Decision Matrix: Start Here
| Scenario | Recommendation | Reason |
|---|---|---|
| Daily chat, casual talk, Q&A | Flash | More than capable, 1/12th the price |
| Customer service bots, FAQ systems | Flash | High throughput, low latency |
| Code completion, single-file edits | Flash | 79% on SWE-bench, close to Pro |
| Long document summary, reading books | Flash | Full 1M context window included |
| Multi-step tool-use Agents | Pro | 11-point lead on Terminal-Bench |
| Deep research, multi-round verification | Pro | 24-point lead on SimpleQA |
| High-value business report generation | Pro | 11+ points higher on Intelligence Index |
| R&D / Exploratory experiments | Flash | 12x cheaper, faster iteration |
The Golden Rule: Default to Flash, upgrade to Pro only when you hit a bottleneck. This aligns with the standard technical selection principle: "Start with the simplest solution, upgrade only when necessary."
2.2 Cost-Effectiveness Analysis: Where Flash Saves You the Most
Assuming your product handles 100 million tokens daily (60M input + 40M output):
| Model | Daily Cost | Monthly Cost | Annual Cost |
|---|---|---|---|
| V4-Flash | $19.6 | $588 | $7,056 |
| V4-Pro | $243.6 | $7,308 | $87,696 |
| GPT-5.4 (Ref) | $550 | $16,500 | $198,000 |
Flash saves you over $80K annually compared to Pro. That's enough to cover half a developer's salary.
2.3 Hybrid Routing: Best Practices for Production
For most products, the optimal solution isn't picking one or the other, but dynamically routing based on request type:
def route_model(request_type: str) -> str:
# Route based on the complexity of the request
if request_type in ("chat", "faq", "summarize", "classify"):
return "deepseek-v4-flash"
if request_type in ("deep_research", "multi_step_agent"):
return "deepseek-v4-pro"
return "deepseek-v4-flash" # Default to Flash
🎯 Implementation Tip: We recommend keeping both V4-Flash and V4-Pro model invocation permissions active on the APIYI (apiyi.com) platform. Both use the same API key; you only need to update the
modelfield to switch. For batch tasks, we recommend using the high-concurrency route atvip.apiyi.com, while complex Pro tasks can go through the mainapi.apiyi.comendpoint. You can even perform A/B traffic distribution for different business modules within the same configuration.
3. 5 Minutes to Call deepseek-v4-flash on APIYI (apiyi.com)
3.1 Step 1: Prerequisites and Getting Your Key
| Item | Requirement |
|---|---|
| Python or Node.js | Python 3.8+ / Node.js 18+ |
| Client SDK | OpenAI Python openai >= 1.0 or official Node SDK |
| Network | Access to api.apiyi.com |
| Key | Generate in the APIYI apiyi.com console; starts with sk- |
Getting Your Key:
- Visit
apiyi.com, register/log in, and enter the console. - Left menu → API Keys → Create New Key.
- We recommend setting a "Usage Limit" of ¥50–100 for initial verification.
- Copy the key string starting with
sk-.
3.2 Step 2: Choosing a Route (base_url)
APIYI provides three routes, all sharing the same Key:
| base_url | Positioning | Recommended Scenario |
|---|---|---|
https://api.apiyi.com/v1 |
Main Site | Default choice, daily usage |
https://vip.apiyi.com/v1 |
High Concurrency | Batch image generation/inference, night queues |
https://b.apiyi.com/v1 |
Backup | Automatic fallback if the main site fluctuates |
Use the main site for daily development. Switch to VIP/Backup only if you encounter 429 rate limits or 5xx jitters in production.
3.3 Step 3: Minimal Python Invocation Example (Non-Thinking)
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "system", "content": "You are a concise assistant"},
{"role": "user", "content": "Summarize the core upgrades of DeepSeek V4-Flash in three points"},
],
max_tokens=512,
)
print(resp.choices[0].message.content)
There are only two changes required:
base_urlpoints tohttps://api.apiyi.com/v1modelis changed todeepseek-v4-flash
All other OpenAI SDK code remains unchanged.
3.4 Step 4: Enabling Thinking Inference Mode
When deep reasoning is required, add the reasoning parameter to your request:
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "user", "content": "Proof: Given n points, what is the minimum number of lines needed to cover all point pairs?"},
],
extra_body={
"reasoning": {"enabled": True, "effort": "high"},
},
max_tokens=8192,
)
# The response will contain a reasoning_content field
print("Thinking process:", resp.choices[0].message.reasoning_content)
print("Final answer:", resp.choices[0].message.content)
In Thinking mode, latency increases by 2–5 times (depending on problem complexity), but accuracy for coding and math problems improves significantly.
3.5 Step 5: Minimal Node.js Invocation Example
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_API_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const resp = await client.chat.completions.create({
model: "deepseek-v4-flash",
messages: [
{ role: "user", content: "Write a haiku about 2026 AI" },
],
max_tokens: 256,
});
console.log(resp.choices[0].message.content);
3.6 Step 6: Function Calling Example
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
},
},
}]
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[{"role": "user", "content": "How is the weather in Shanghai today?"}],
tools=tools,
)
print(resp.choices[0].message.tool_calls)
V4-Flash is very stable in single-tool calling scenarios. For complex multi-step tool chains (5+ steps), we recommend upgrading to V4-Pro.
3.7 Step 7: Anthropic Protocol Invocation
If your project is built on the Anthropic SDK (e.g., integrated with Claude Code), you can still use it:
from anthropic import Anthropic
client = Anthropic(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com",
)
resp = client.messages.create(
model="deepseek-v4-flash",
max_tokens=1024,
messages=[{"role": "user", "content": "Hi"}],
)
print(resp.content[0].text)
🎯 Dual-Protocol Tip: For the same deepseek-v4-flash model, the OpenAI protocol uses
api.apiyi.com/v1, while the Anthropic protocol usesapi.apiyi.com(without/v1). Only the base_url field needs to change. For more protocol details, refer to the DeepSeek section in the official APIYI documentation atdocs.apiyi.com.
4. The Complete Migration Path to deepseek-v4-flash

4.1 Why You Must Migrate: The 90-Day Countdown
DeepSeek's official announcement states:
Legacy models
deepseek-chatanddeepseek-reasonerretire July 24, 2026.
Please update your model todeepseek-v4-proordeepseek-v4-flash.
After July 24, 2026, requests using the old model IDs will return an error. From the release date of April 24, 2026, there is a 90-day buffer period.
4.2 Migration Decision Table
Match your current model to the new one:
| Old model ID | New model ID | Migration Difficulty |
|---|---|---|
deepseek-chat |
deepseek-v4-flash (Non-Thinking mode) |
⭐ Change 1 field |
deepseek-reasoner |
deepseek-v4-flash + Thinking mode |
⭐⭐ Change model + add reasoning param |
deepseek-reasoner (High-value) |
deepseek-v4-pro + Thinking mode |
⭐⭐ Change model + add reasoning param |
deepseek-v3.x |
deepseek-v4-flash |
⭐ Change model |
deepseek-coder etc. |
deepseek-v4-flash |
⭐ Change model (general capabilities covered) |
4.3 Code Diff: Almost Zero Effort
Before migration:
resp = client.chat.completions.create(
model="deepseek-chat", # ← Old model
messages=[...],
)
After migration:
resp = client.chat.completions.create(
model="deepseek-v4-flash", # ← Change this line
messages=[...],
)
If migrating from deepseek-reasoner:
resp = client.chat.completions.create(
- model="deepseek-reasoner",
+ model="deepseek-v4-flash",
messages=[...],
+ extra_body={"reasoning": {"enabled": True}},
)
4.4 Migration Checklist
We recommend running through this list before migrating:
- Audit all hardcoded
model=strings in your codebase. - Evaluate if
deepseek-reasonercalls need to upgrade to V4-Pro. - Prepare a set of regression test prompts (20–50 items covering core business).
- Temporarily tighten the daily limit for old requests in the APIYI
apiyi.comconsole to force migration triggers. - Run old and new models in AB testing for 1 week to compare output quality.
- Monitor token consumption curves to ensure no unexpected cost spikes.
- Update internal documentation and runbooks.
4.5 Canary Release Suggestion
3-Phase Rollout:
| Phase | Traffic | Duration | Goal |
|---|---|---|---|
| Phase 1 | 5% | Week 1 | Verify protocol and basic output |
| Phase 2 | 30% | Weeks 2-3 | Compare key metrics (quality + cost) |
| Phase 3 | 100% | Week 4 | Full migration, keep old Key for emergency rollback |
💡 Emergency Rollback: The old model routes on APIYI
apiyi.comwill remain compatible until July 24, 2026. If you encounter critical issues during migration, simply change themodelback todeepseek-chat/deepseek-reasonerto restore service immediately. Just don't wait until the end of July to start.
V. FAQ: Common Questions About deepseek-v4-flash
Q1: How should I choose between Flash and Pro?
The rule of thumb: Default to Flash, and upgrade to Pro only if you hit a bottleneck. Here’s the breakdown by scenario:
- Single-turn conversations, FAQs, classification, summarization, and code completion → Flash
- Multi-step Agent workflows (5+ tool calls) → Pro
- Deep research tasks → Pro
- When in doubt, run it on Flash first to check the results; upgrade if the quality isn't up to par.
Q2: Can I really use the full 1M context window?
Yes, but keep these nuances in mind:
- First 100K–300K: The model's attention is sharpest here; performance is best.
- 300K–800K: Performance remains stable.
- 800K–1M: Marginal recall may decrease. It's best to place key information at the very beginning or the very end.
- Cost reminder: 1M input tokens ≈ $0.14. It’s not expensive, but it isn't free.
For long-form content, we recommend a structure of "Question at the start + Materials in the middle + Reiterate the question at the end."
Q3: How do I trigger Thinking mode?
Under the OpenAI protocol, you can trigger it by setting extra_body.reasoning.enabled=true. The effort parameter can be set to low, medium, or high (default is medium). On APIYI (api.apiyi.com), these parameters work exactly as they do in the official documentation.
Q4: Is Function Calling stable on Flash?
Single-turn calls are very stable (95%+ success rate). For multi-step tool chains (5+ steps), we recommend using Pro—the 11-point gap in Terminal-Bench 2.0 is primarily reflected in these complex scenarios.
Q5: What is a reasonable concurrency limit?
For individual developers, 10–20 concurrent requests are perfectly fine. For production environments, we suggest:
- Default: Use 50 concurrent requests via
api.apiyi.com. - Batch/Nightly Tasks: Switch to
vip.apiyi.comfor up to 200+ concurrent requests. - Emergency Spikes: Temporarily fallback to
b.apiyi.com.
Check docs.apiyi.com for the latest quota details.
Q6: How do I assess migration risks?
Follow this three-step process:
- Output Quality: Run an A/B test using 20–50 typical business prompts and evaluate the results manually or via a scoring model.
- Cost Curve: Monitor daily token consumption. Flash output tokens are usually slightly higher (more noticeable in Thinking mode).
- Latency: Flash's TTFT (Time to First Token) is close to V3.5, but Thinking mode will be 2–5 times slower.
If you see a quality drop of more than 10%, consider upgrading to Pro; otherwise, feel free to migrate.
Q7: How do I use Anthropic protocol compatibility?
Do not include /v1 in the base_url; call POST /v1/messages directly. Simply set the model field in the Anthropic SDK to deepseek-v4-flash. This is a shortcut for zero-code migration for projects already using the Claude SDK.
Q8: Are there any discounts for context caching?
V4-Flash has enabled automatic context caching. Requests with repeated prefixes will be billed at a lower rate. You can save an additional 30–50% on scenarios with long system prompts. This discount is enabled by default on the APIYI (apiyi.com) platform—no extra parameters required.
VI. Summary: Launching deepseek-v4-flash
The release of DeepSeek V4 brings two key takeaways for developers:
- It’s cheaper: V4-Flash delivers near-Pro performance at 1/12th the price, setting a new industry low of $0.14/M for input.
- The clock is ticking: Older models will be officially retired on 2026-07-24, with a 90-day grace period starting from the release date.
The good news is that deepseek-v4-flash is now live on APIYI (apiyi.com). You don't need to set up an overseas account, modify your SDK, or worry about payment gateways. Just follow these three steps:
- ✅ Grab a Key from the
apiyi.comconsole. - ✅ Point your
base_urltoapi.apiyi.com/v1(or usevip.apiyi.com/b.apiyi.comas backups). - ✅ Set
modeltodeepseek-v4-flashand keep the rest of your code as-is.
🎯 Action Plan: We strongly recommend starting your deepseek-v4-flash A/B tests today. Create a dedicated Key on APIYI, run 20–50 typical business prompts, and compare the output quality and cost against your current model. If there’s no significant regression, you can shift 5% of your traffic this week and complete the full migration within 4 weeks—much more comfortable than rushing before the July deadline. For detailed migration cases and benchmark scripts, refer to the DeepSeek V4 section on
docs.apiyi.com.
The value of deepseek-v4-flash isn't just that it's "another cheap model," but that it "brings capabilities previously reserved for tech giants down to an accessible price point for everyone." Reading entire books with a 1M context window, performing complex reasoning with Thinking mode, and connecting full tool suites via Function Calling—all at a fraction of the cost. This will unlock a new wave of product opportunities. The sooner you migrate, the further ahead you'll be.
Author: APIYI Technical Team
Resources:
- DeepSeek Official Announcement: api-docs.deepseek.com/news/news260424
- Hugging Face Repository: huggingface.co/deepseek-ai/DeepSeek-V4-Flash
- APIYI Official Website: apiyi.com
- APIYI Documentation: docs.apiyi.com
- APIYI Main Site: api.apiyi.com (Backups: vip.apiyi.com / b.apiyi.com)