On June 1, 2026, MiniMax officially launched its new open-weight flagship, MiniMax-M3. This is the industry's first open-weight model to achieve three things simultaneously in a single architecture: frontier-level programming capabilities, a 1 million token context window, and native multimodal input. It scored 59.0 on SWE-Bench Pro, directly surpassing GPT-5.5 and Gemini 3.1 Pro, and closing in on Claude Opus 4.7.
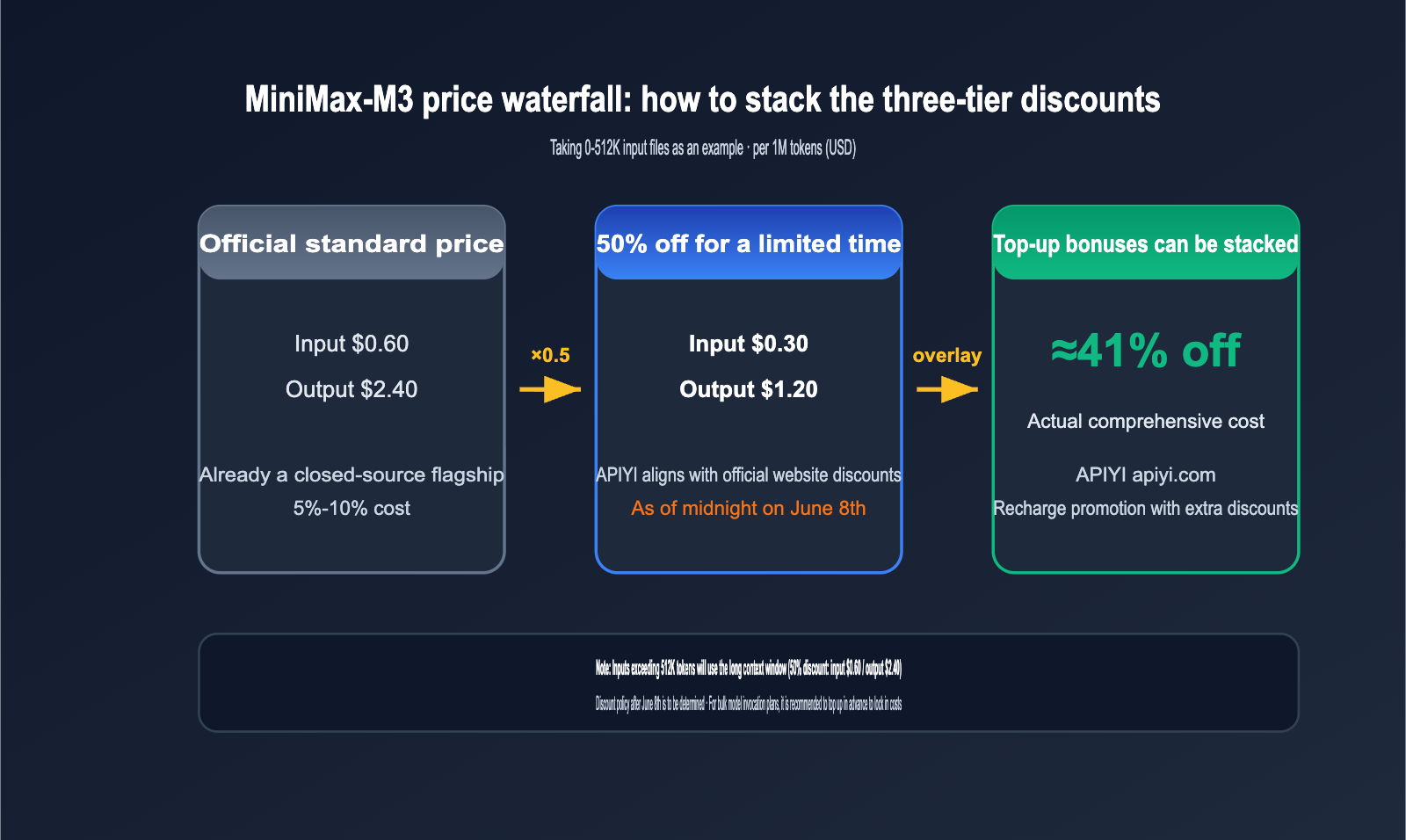
Even more impactful is the pricing. The official standard rate is $0.60 input / $2.40 output per 1M tokens, which is already only 5%-10% of the cost of closed-source models in its class. For the launch period, there's an additional 50% off promotion, bringing the price down to $0.30 input / $1.20 output. Currently, MiniMax-M3 is available on the APIYI (apiyi.com) platform, matching the official 50% off price. With additional recharge bonuses, the actual cost can be as low as ~41% of the standard rate. This promotion ends at midnight on June 8 (UTC+8).
In this article, we'll break down the architectural highlights, benchmark scores, pricing tiers, and integration code for MiniMax-M3 to help you decide if it's worth switching during the promotional window.

What is MiniMax-M3: The "Three-in-One" Flagship of the Open-Source Camp
MiniMax-M3 is the new generation flagship from MiniMax, following the M2 series, positioned as a general-purpose model for programming and agent scenarios. It uses a fine-grained MoE (Mixture of Experts) architecture with approximately 229.9B total parameters, activating only about 9.8B parameters per token across 256 experts. This means its inference cost is closer to a 10B-class small model, while its capabilities compete with top-tier flagships.
The training data scale is approximately 100 trillion tokens, and it includes interleaved image-text data from the pre-training stage. Therefore, MiniMax-M3's multimodal capability is "native"—its image and video understanding abilities are baked directly into the semantic space, rather than being appended via an external visual encoder. In addition to image and video input, it also supports Computer Use, leaving plenty of interfaces for agent scenarios.
The company has promised that the model weights and technical report will be fully open-sourced within 10 days of release, at which point they will be available on HuggingFace and GitHub, supporting private deployment and fine-tuning. Based on the modified MIT license used for the previous M2 series, the barrier for commercial use is expected to be very low, though the final terms will be subject to the official license release.
MiniMax-M3 Core Specifications at a Glance
| Dimension | MiniMax-M3 Specification |
|---|---|
| Release Date | June 1, 2026 |
| Architecture | Fine-grained MoE, 229.9B total / 9.8B active params, 256 experts |
| Attention Mechanism | MSA (MiniMax Sparse Attention) |
| Context Window | 1,000,000 tokens (approx. 5x the M2 series) |
| Modality Support | Text + Image + Video input, Text output, supports Computer Use |
| Training Data | ~100T tokens, interleaved image-text multimodal corpus |
| Thinking Mode | Toggleable Thinking mode, same pricing |
| Open Source Plan | Weights and technical report to be released within 10 days |
🎯 Quick Experience Suggestion: If you want to verify the true performance of MiniMax-M3 immediately, there's no need to wait for the weights to be released to build your own cluster. We recommend calling it directly via the OpenAI-compatible API on APIYI (apiyi.com) by setting the model name to
MiniMax-M3. You can get a comparative test running in minutes, and costs are cut in half during the promotional period.
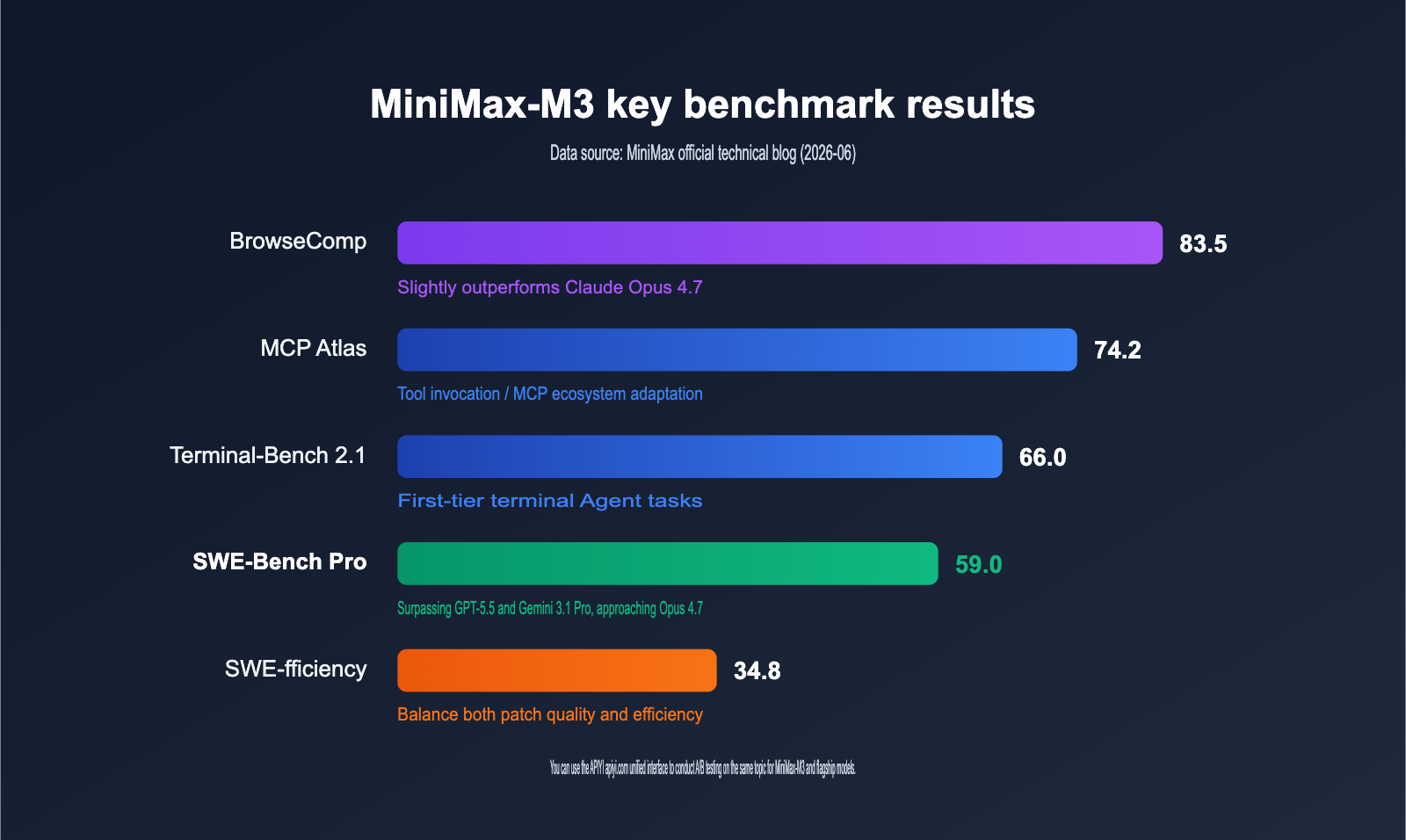
What MiniMax-M3's 59.0 Score on SWE-Bench Pro Really Means
SWE-Bench Pro is widely recognized as one of the toughest real-world software engineering benchmarks, testing a model's end-to-end ability to fix bugs and write patches within actual code repositories. MiniMax-M3 achieved a score of 59.0. Official comparison data shows this score surpasses both GPT-5.5 and Gemini 3.1 Pro, sitting just a step behind Claude Opus 4.7. For an upcoming open-source model with fewer than 10B active parameters, this marks the first time an open-source contender has outperformed closed-source flagships on this benchmark.
Beyond programming, its Agent-related metrics are equally impressive. It scored 66.0 on Terminal-Bench 2.1, 74.2 on MCP Atlas, and 83.5 on the autonomous browsing task BrowseComp—the latter even slightly edging out Claude Opus 4.7. On the multimodal front, it outperformed Opus 4.7 on SVG-Bench and scored higher than Gemini 3.1 Pro on the document understanding benchmark, OmniDocBench.
Of course, it doesn't dominate across the board. On PostTrainBench, which evaluates post-training capabilities for scientific research, MiniMax-M3 scored 0.37, trailing Claude Opus 4.7's 0.42 and roughly matching GPT-5.5's 0.39. A quick reminder: these figures currently come from official technical blogs, and independent third-party testing is still underway. For mission-critical business applications, we recommend running your own evaluations to confirm performance.
MiniMax-M3 vs. Leading Flagship Models
| Benchmark | MiniMax-M3 | Conclusion |
|---|---|---|
| SWE-Bench Pro | 59.0 | Surpasses GPT-5.5 & Gemini 3.1 Pro, nears Opus 4.7 |
| Terminal-Bench 2.1 | 66.0 | Top-tier for terminal Agent tasks |
| BrowseComp | 83.5 | Slightly exceeds Claude Opus 4.7 |
| MCP Atlas | 74.2 | Strong tool calling and MCP ecosystem adaptation |
| SWE-fficiency | 34.8 | Balances patch quality with efficiency |
| PostTrainBench | 0.37 | Below Opus 4.7 (0.42), matches GPT-5.5 (0.39) |
If you want to verify these numbers yourself, you can use the APIYI platform to call MiniMax-M3, GPT-5.5, and Claude Opus 4.7 simultaneously using the same prompt. The platform standardizes the interface format, so switching models only requires changing the model parameter—perfect for A/B testing.
MiniMax-M3 Architecture: How MSA Sparse Attention Powers a 1M Context Window
A 1M token context window isn't unheard of, but making it economically viable is the real breakthrough. MiniMax-M3's answer is its proprietary MSA (MiniMax Sparse Attention). Traditional full attention's computational cost grows quadratically with context length, whereas MSA partitions the KV cache into blocks. Each query precisely retrieves only the most relevant KV blocks, achieving much higher effective context coverage.
The official engineering data is quite aggressive: with a 1M token context, MiniMax-M3's per-token computational cost is only 1/20th of the previous M2 generation; prefill speed is boosted by over 9x, and decode speed by over 15x; at the operator level, it's 4x faster than the open-source Flash-Sparse-Attention. In other words, you can dump an entire code repository, hundreds of pages of PDFs, or an hour-long meeting video into the context without latency or costs becoming a dealbreaker.
For developers, this means many long-document tasks that previously required RAG chunking, vector retrieval, or multi-round summarization can now be handled in a single "all-in" prompt. Long-range Agent tasks no longer require frequent history compression, significantly improving task coherence.

💡 Long Context Testing Tip: 1M context billing is split into two tiers, with the unit price doubling after 512K input. We recommend testing with real documents in the 200K-400K range via the APIYI (apiyi.com) console first. Once you've confirmed the quality meets your needs, you can scale up to longer inputs. The platform's usage statistics will help you precisely calculate the token costs for each invocation.
MiniMax-M3 API Pricing: 50% Off Limited Time + Extra Savings for ~41% Off
MiniMax-M3 uses a tiered pricing model based on input length. Inputs up to 512K tokens follow the standard tier, while anything beyond 512K falls under the long-context tier. During the launch period, all prices are 50% off. APIYI (apiyi.com) has synchronized these official discounts, with the promotion running until midnight (UTC+8) on June 8, 2026. Future discount policies are yet to be determined.
MiniMax-M3 API Pricing Tiers (per 1M tokens)
| Billing Tier | Input (50% Off Price) | Output (50% Off Price) | Standard Price (Input/Output) |
|---|---|---|---|
| 0-512K Input | $0.30 | $1.20 | $0.60 / $2.40 |
| >512K Input | $0.60 | $2.40 | $1.20 / $4.80 |
To put this pricing into perspective: running a million-token code review task might cost over ten dollars with flagship closed-source models, whereas the MiniMax-M3 promotional price is just a few cents—a 10x to 20x cost difference. For high-frequency Agent pipelines, bulk code migration, and long-document processing, these savings can pay for a new development machine in just one month.
You can save even more on the APIYI platform. The platform's top-up bonus credits can be stacked with the 50% off model pricing, bringing your actual cost down to as low as ~41% of the standard rate. If your team already has a stable volume of model invocations, topping up before June 8 is the most cost-effective move.
Getting Started with MiniMax-M3 API: Access in 5 Minutes
MiniMax-M3 uses the standard OpenAI-compatible protocol on the APIYI platform, so any SDK, framework, or client that supports a custom base_url will work seamlessly. One important detail: the model name MiniMax-M3 is case-sensitive. The M must be capitalized; using minimax-m3 will result in a "model not found" error.
Accessing it takes just three steps: register and create an API key at APIYI (apiyi.com); set your base_url to https://api.apiyi.com/v1; and set the model parameter to MiniMax-M3. Here is a simple Python example:
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1" # APIYI unified interface
)
response = client.chat.completions.create(
model="MiniMax-M3", # Note: Case-sensitive, M must be uppercase
messages=[
{"role": "user", "content": "Implement a Fibonacci function with LRU cache in Python"}
]
)
print(response.choices[0].message.content)
When you need to pass images or video, simply use the standard OpenAI multimodal message format by changing content to an array containing image_url. MiniMax-M3 will handle visual understanding and code generation within the same session. For Agent tools like Cline, Cursor, or OpenClaw, you can simply update the base_url and model name in the settings to switch the underlying engine to MiniMax-M3.
MiniMax-M3 Use Case Quick Reference
| Scenario | Suitability | Notes |
|---|---|---|
| Agent Programming / Auto-Bug Fixing | ⭐⭐⭐⭐⭐ | SWE-Bench Pro 59.0, maintains context for long tasks |
| Full Repository Analysis & Migration | ⭐⭐⭐⭐⭐ | 1M context window fits mid-sized repositories |
| Long Document / Multimodal Parsing | ⭐⭐⭐⭐⭐ | OmniDocBench exceeds Gemini 3.1 Pro |
| Autonomous Browsing & Tool Use Agent | ⭐⭐⭐⭐ | BrowseComp 83.5, MCP Atlas 74.2 |
| Research Post-training / Frontier Reasoning | ⭐⭐⭐ | PostTrainBench slightly behind Opus 4.7, use hybrid routing |
Hybrid routing is a more practical approach: use MiniMax-M3 for 80% of your daily high-frequency coding and document tasks, and reserve the most complex reasoning tasks for Claude Opus 4.7 or GPT-5.5. By using APIYI's unified interface for model routing, you can implement this "cost-performance layering" strategy with a single codebase, without needing to manage multiple vendor keys and SDKs.
MiniMax-M3 FAQ
Q1: When does the 50% off promotion for MiniMax-M3 end?
The promotion ends at midnight (UTC+8) on June 8, 2026, synchronized between the APIYI platform and the official MiniMax website. The official policy after this date hasn't been announced yet, but it's likely to revert to standard pricing. If you have high-volume model invocation plans, we recommend topping up before the deadline; when combined with our top-up bonuses, your effective cost could be as low as 41% of the original price.
Q2: Is MiniMax-M3 actually open-source? Can I download the weights now?
The team has committed to releasing the model weights and technical report within 10 days of launch, which will be available on the MiniMaxAI HuggingFace page. As of this writing, the weights haven't been uploaded yet. Teams that can't wait to self-host can start by testing performance via API, then evaluate the hardware requirements for private deployment once the weights are released—given it's a 230B parameter MoE model, the VRAM requirements for local deployment are quite significant.
Q3: Is the 1M context window just marketing hype, or is it actually usable?
The MSA architecture makes the 1M context window genuinely usable in production: it speeds up prefill by over 9x and decode by 15x, while reducing the compute cost per token to 1/20th of the previous generation. However, keep an eye on the billing tiers; the unit price doubles once your input exceeds 512K. We recommend managing your context length based on the actual needs of your task rather than just filling it up blindly.
Q4: How should I choose between MiniMax-M3, GPT-5.5, and Claude Opus 4.7?
It depends on your task type and budget. For programming agents, long context, and multimodal document scenarios, MiniMax-M3 currently has no rival in terms of cost-effectiveness. For top-tier complex reasoning and scientific research tasks, Opus 4.7 still holds an advantage. We recommend running small-scale comparison tests using your actual business prompts on the APIYI platform; the data will be more convincing than any leaderboard.
Summary: MiniMax-M3 Brings Flagship Performance to "Budget" Prices
The release of MiniMax-M3 has dropped a bombshell on the 2026 model market: open-source weights, a SWE-Bench Pro score of 59.0 (surpassing GPT-5.5), a 1M context window, and native multimodal capabilities—all at an official price point that's only 5%-10% of other closed-source flagships. Even if third-party re-testing causes some scores to dip, its dominance in the "cost-effectiveness" category will be hard to shake.
The most important short-term move is to take advantage of the pricing window: the limited-time 50% off offer ($0.30 input / $1.20 output per 1M tokens) ends at midnight on June 8. By combining this with the top-up promotions at APIYI (apiyi.com), you can get the price down to as low as 41% of the original. Running your evaluations at the lowest possible cost before deciding to switch your production traffic over is the safest strategy right now.
For more details on the promotion and the latest model updates, check out the official APIYI announcement: docs.apiyi.com/news/minimax-m3-launch
Author: APIYI Team
Focused on Large Language Model API aggregation and best practices. For more model evaluations and integration guides, visit APIYI at apiyi.com.