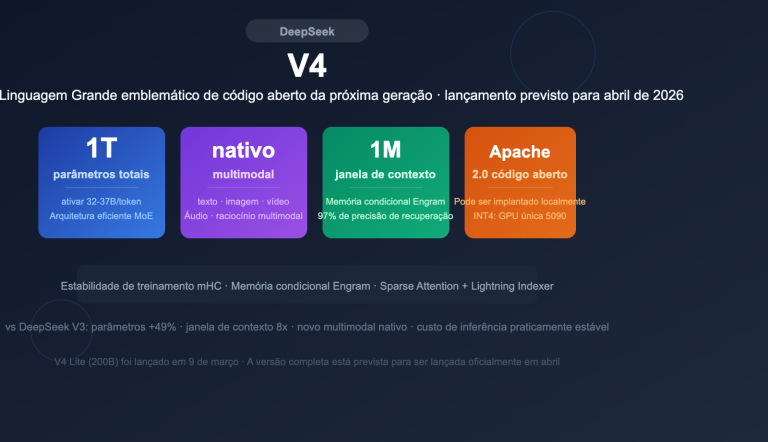
24/04/2026, a DeepSeek lançou no Hugging Face os modelos de pré-visualização V4-Pro e V4-Flash. O primeiro é um monstro MoE de 1,6T de parâmetros focado em desempenho de ponta, enquanto o segundo é uma opção com excelente custo-benefício, oferecendo "cerca de 90% da capacidade do Pro por apenas 1/12 do preço".
Se você precisa escolher apenas um modelo, escolha o deepseek-v4-flash. O motivo é simples:
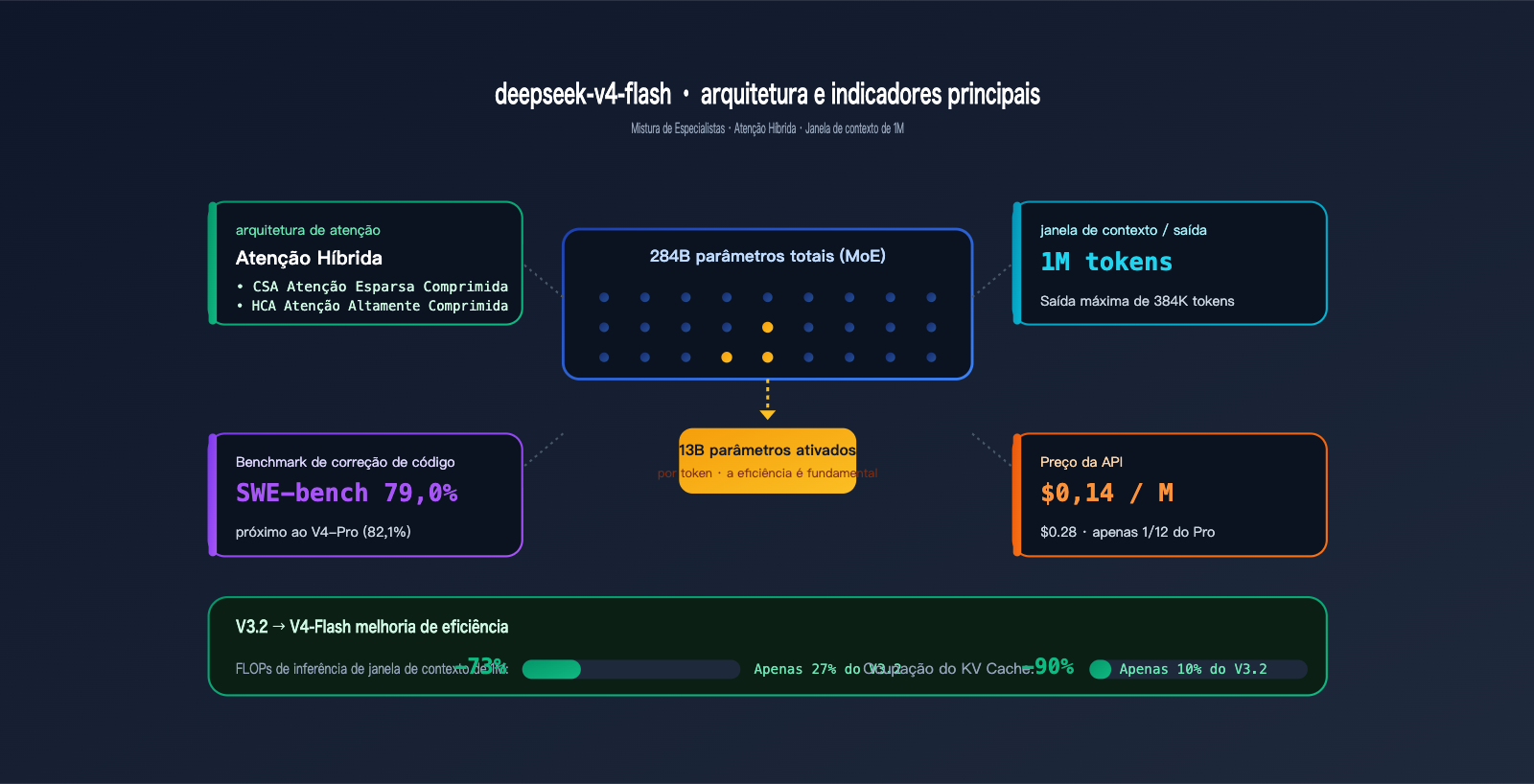
- Arquitetura MoE de 284B / 13B + Hybrid Attention, com FLOPs de inferência em 1M de contexto representando apenas 27% do V3.2.
- Contexto de 1M de tokens / 384K de saída máxima, permitindo processar textos longos nativamente sem precisar dividir em partes.
- US$ 0,14 para entrada / US$ 0,28 para saída por milhão de tokens, uma ordem de grandeza mais barato que o Pro.
- 79,0% no SWE-bench Verified e 45–47 no Artificial Analysis Intelligence Index, o suficiente para a grande maioria dos cenários.
- Compatibilidade dupla com os protocolos OpenAI ChatCompletions e Anthropic API, funcionando sem modificações no Claude Code, OpenClaw ou OpenCode.
Um ponto importante: os modelos antigos deepseek-chat e deepseek-reasoner serão descontinuados em 24/07/2026. Todos os serviços online devem ser migrados antes dessa data. É um prazo rígido de 90 dias.
A boa notícia é: o deepseek-v4-flash já está disponível no APIYI apiyi.com. Você não precisa criar uma conta na DeepSeek, não precisa alterar seu SDK e não precisa lidar com pagamentos internacionais — basta alterar o campo model e apontar a base_url para api.apiyi.com para começar a usar.
Este artigo é um guia 3+5: 3 minutos para entender as atualizações principais do V4-Flash + 5 minutos para concluir a migração completa dos modelos antigos.
I. As 5 principais atualizações do deepseek-v4-flash
1.1 Tabela de especificações principais
Veja o panorama geral antes de entrarmos nos detalhes:
| Dimensão | deepseek-v4-flash |
|---|---|
| Data de lançamento | 24/04/2026 (Versão de pré-visualização) |
| Repositório open source | huggingface.co/deepseek-ai/DeepSeek-V4-Flash |
| Parâmetros totais | 284B (Mixture of Experts) |
| Parâmetros ativos | 13B |
| Janela de contexto | 1M tokens |
| Saída máxima | 384K tokens |
| Arquitetura de atenção | Hybrid Attention (CSA + HCA) |
| Modo de inferência | Modo duplo Thinking / Non-Thinking |
| Function Calling | ✅ Suportado |
| Modo JSON | ✅ Suportado |
| Chat Prefix Completion | Suporte Beta |
| Protocolo API | Compatibilidade dupla OpenAI ChatCompletions + Anthropic |
| Preço de entrada | US$ 0,14 / M tokens |
| Preço de saída | US$ 0,28 / M tokens |
Abaixo, detalhamos cada uma dessas 5 atualizações.
1.2 Atualização 1: 1M de contexto + 384K de saída (Nativamente longo)
O deepseek-v4-flash suporta nativamente 1M de tokens de entrada e 384K de tokens de saída. Esta é a especificação padrão de toda a série V4; o Flash não reduziu o contexto para baratear o custo.
Que tipo de conteúdo cabe em 1M?
| Tipo de conteúdo | Número aproximado de tokens |
|---|---|
| Manuscrito chinês de 100 mil caracteres | ≈ 150K tokens |
| Documento técnico em PDF de 200 páginas | ≈ 300K tokens |
| Repositório de código de médio porte (~50 arquivos) | ≈ 500K–800K tokens |
| O livro clássico "O Sonho da Câmara Vermelha" | ≈ 1M tokens |
Comparado ao GPT-5.4 (400K), Claude Opus 4.6 (pacote de 1M + 1M de contexto) e Gemini 3.1-Pro (2M), o 1M do V4-Flash já é a configuração padrão da indústria, custando de 5 a 20 vezes menos que os citados.
1.3 Atualização 2: 284B/13B MoE + Hybrid Attention
O V4-Flash utiliza duas inovações arquiteturais introduzidas pela DeepSeek em 2026:
- MoE: 284B de parâmetros totais, com apenas 13B ativados por token. O resultado é um desempenho próximo a um modelo denso de 13B, mas com um conhecimento vasto próximo a modelos densos de 200B+.
- Hybrid Attention (CSA – Compressed Sparse Attention + HCA – Highly Compressed Attention): projetado especificamente para contextos longos.
Dados de eficiência (da DeepSeek):
| Indicador | V3.2 | V4-Flash | Melhoria |
|---|---|---|---|
| FLOPs de inferência por token em 1M de contexto | 100% | 27% | -73% |
| Ocupação de cache KV em 1M de contexto | 100% | 10% | -90% |
Esses números explicam por que o Flash consegue manter o preço em US$ 0,14: o custo computacional real foi reduzido, não se trata apenas de subsídio.
1.4 Atualização 3: Modo duplo Thinking / Non-Thinking
O V4-Flash permite alternar entre dois modos usando o mesmo ID de modelo:
- Non-Thinking (padrão): Rápido, ideal para conversas casuais, perguntas e respostas, classificação e resumos.
- Thinking: O modelo gera primeiro um raciocínio interno (similar à série o da OpenAI) antes de fornecer a resposta final. Ideal para raciocínios complexos, chamadas de ferramentas em várias etapas e depuração de código.
A alternância é feita via parâmetros de requisição (não são IDs de modelo diferentes), tornando a mudança mínima para o desenvolvedor. Ao usar o APIYI api.apiyi.com, o nome desse parâmetro é idêntico ao oficial da DeepSeek.
1.5 Atualização 4: US$ 0,14 / US$ 0,28 por milhão de tokens
Este é o dado mais impressionante deste lançamento:
| Modelo | Entrada ($/M) | Saída ($/M) | Relativo ao V4-Flash |
|---|---|---|---|
| deepseek-v4-flash | 0,14 | 0,28 | 1× (Base) |
| deepseek-v4-pro | 1,74 | 3,48 | 12× |
| GPT-5.4 (Ref.) | 2,50 | 10,00 | 17×–35× |
| Claude Sonnet 4.6 (Ref.) | 3,00 | 15,00 | 21×–53× |
Para uma requisição típica de "500 tokens de entrada + 500 tokens de saída":
- V4-Flash: US$ 0,000 21
- GPT-5.4: US$ 0,006 25
- Claude Sonnet 4.6: US$ 0,009
O Flash é de 30 a 40 vezes mais barato. Para produtos com volume mensal de centenas de milhões de tokens, isso impacta diretamente a margem de lucro.
1.6 Atualização 5: Compatibilidade dupla com protocolos OpenAI + Anthropic
O V4-Flash implementa duas camadas de protocolo na API:
POST /v1/chat/completions→ Formato OpenAIPOST /v1/messages→ Formato Anthropic
Isso significa que:
| Cliente | Custo de migração |
|---|---|
| SDK Python/Node da OpenAI | Zero modificação, apenas altere base_url e model |
| SDK Python/Node da Anthropic | Zero modificação, apenas altere base_url e model |
| Claude Code | Basta trocar o endpoint da Anthropic |
| OpenClaw / OpenCode | Suporte nativo |
| LangChain / LlamaIndex | Basta trocar a base_url |
Essa foi uma decisão inteligente da DeepSeek: não forçar o aprendizado de novos protocolos, permitindo que o ecossistema existente se conecte sem custos.
1.7 Tabela de comparação de benchmarks
| Benchmark | V4-Flash | V4-Pro | Diferença |
|---|---|---|---|
| SWE-bench Verified (Correção de código) | 79,0% | 82,1% | -3,1 |
| Terminal-Bench 2.0 (Uso de ferramentas) | 56,9% | 67,9% | -11,0 |
| SimpleQA-Verified (Recuperação de fatos) | 34,1% | 57,9% | -23,8 |
| Artificial Analysis Intelligence Index | 45 / 47 | 58 | -11 ~ -13 |
Análise: O Flash quase empata com o Pro em tarefas de código de etapa única (SWE-bench), mas a diferença é clara em tarefas que exigem cadeias de ferramentas de várias etapas (Terminal-Bench) e memória factual (SimpleQA). Essas diferenças são o critério para decidir entre o Flash e o Pro.
2. Decisão de cenário: deepseek-v4-flash vs V4-Pro
2.1 Matriz de decisão: comece por aqui
| Cenário | Recomendação | Motivo |
|---|---|---|
| Conversas diárias, chat, perguntas e respostas | Flash | Capacidade suficiente, preço 1/12 |
| Chatbots de atendimento, sistemas de FAQ | Flash | Alta taxa de transferência, baixa latência |
| Autocompletar código, modificação de arquivo único | Flash | 79% no SWE-bench, próximo ao Pro |
| Resumo de documentos longos, ler um livro | Flash | Janela de contexto de 1M completa |
| Agentes de cadeia de ferramentas de várias etapas | Pro | Diferença de 11 pontos no Terminal-Bench |
| Pesquisa profunda, verificação de várias rodadas | Pro | Diferença de 24 pontos no SimpleQA |
| Geração de relatórios comerciais de alto valor | Pro | Índice de inteligência 11+ pontos superior |
| P&D / Experimentos exploratórios | Flash | 12 vezes mais barato, iteração rápida |
Regra geral: Use Flash por padrão e suba para o Pro apenas se encontrar gargalos. Isso segue o princípio de seleção técnica de "usar a solução simples primeiro e atualizar se houver gargalos".
2.2 Cálculo de custo-benefício: onde o Flash economiza mais
Supondo que seu produto consuma 100 milhões de tokens por dia (60 milhões de entrada + 40 milhões de saída):
| Modelo | Custo diário | Custo mensal | Custo anual |
|---|---|---|---|
| V4-Flash | $19,6 | $588 | $7 056 |
| V4-Pro | $243,6 | $7 308 | $87 696 |
| GPT-5.4 (ref.) | $550 | $16 500 | $198 000 |
O Flash economiza mais de $80 mil por ano em comparação ao Pro. Esse valor é suficiente para contratar meio desenvolvedor adicional.
2.3 Roteamento híbrido: melhores práticas para produção
Para a maioria dos produtos, a solução ideal não é escolher um ou outro, mas sim rotear dinamicamente de acordo com o tipo de solicitação:
def route_model(request_type: str) -> str:
# Roteia para o Flash para tarefas simples
if request_type in ("chat", "faq", "summarize", "classify"):
return "deepseek-v4-flash"
# Roteia para o Pro para tarefas complexas
if request_type in ("deep_research", "multi_step_agent"):
return "deepseek-v4-pro"
return "deepseek-v4-flash" # Padrão para o Flash
🎯 Dica de implementação: Recomendamos que você mantenha as permissões de invocação do modelo para o V4-Flash e o V4-Pro na plataforma APIYI (apiyi.com). Ambos compartilham a mesma chave API; basta alterar o campo
modelpara alternar. Para tarefas em lote, recomendamos a linha de alta concorrênciavip.apiyi.com, enquanto tarefas complexas do Pro devem seguir pelo site principalapi.apiyi.com. Diferentes fluxos de trabalho podem realizar a distribuição de tráfego AB na mesma configuração.
三、5 minutos para invocar o deepseek-v4-flash na APIYI apiyi.com
3.1 Passo 1: Ambiente prévio e obtenção da chave
| Item | Requisito |
|---|---|
| Python ou Node.js | Python 3.8+ / Node.js 18+ |
| SDK do cliente | OpenAI Python openai >= 1.0 ou SDK oficial para Node |
| Rede | Acesso a api.apiyi.com |
| Chave | Gerada no painel da APIYI apiyi.com, começando com sk- |
Obtendo a chave:
- Acesse
apiyi.com, registre-se/faça login e entre no painel de controle. - Menu lateral → API Keys → Criar nova chave.
- Recomendamos definir um "limite de uso" de ¥50–100 para a verificação inicial.
- Copie a string da chave que começa com
sk-.
3.2 Passo 2: Seleção de rota (base_url)
A APIYI oferece três rotas, todas utilizando a mesma chave:
| base_url | Posicionamento | Cenário recomendado |
|---|---|---|
https://api.apiyi.com/v1 |
Principal | Primeira escolha, uso diário |
https://vip.apiyi.com/v1 |
Alta concorrência | Processamento em lote/inferência, filas noturnas |
https://b.apiyi.com/v1 |
Backup | Fallback automático em caso de instabilidade na rota principal |
Para o desenvolvimento diário, a rota principal é suficiente. Se encontrar limites de taxa (429) ou instabilidades (5xx) em produção, mude para a rota VIP ou de backup.
3.3 Passo 3: Exemplo mínimo de invocação em Python (Sem Thinking)
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "system", "content": "Você é um assistente conciso"},
{"role": "user", "content": "Resuma em três pontos as principais atualizações do DeepSeek V4-Flash"},
],
max_tokens=512,
)
print(resp.choices[0].message.content)
Existem apenas duas alterações:
base_urlaponta paraapi.apiyi.commodelalterado paradeepseek-v4-flash
O restante do código do SDK da OpenAI permanece inalterado.
3.4 Passo 4: Habilitar o modo de inferência Thinking
Quando precisar de raciocínio profundo, adicione o parâmetro reasoning na requisição:
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "user", "content": "Prove: dados n pontos, qual o número mínimo de linhas retas necessárias para cobrir todos os pares de pontos?"},
],
extra_body={
"reasoning": {"enabled": True, "effort": "high"},
},
max_tokens=8192,
)
# O retorno conterá o campo reasoning_content
print("Processo de pensamento:", resp.choices[0].message.reasoning_content)
print("Resposta final:", resp.choices[0].message.content)
No modo Thinking, o tempo de processamento aumenta de 2 a 5 vezes (dependendo da complexidade do problema), mas a precisão em questões de código/matemática aumenta significativamente.
3.5 Passo 5: Exemplo mínimo de invocação em Node.js
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_API_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const resp = await client.chat.completions.create({
model: "deepseek-v4-flash",
messages: [
{ role: "user", content: "Escreva um haikai sobre IA em 2026" },
],
max_tokens: 256,
});
console.log(resp.choices[0].message.content);
3.6 Passo 6: Exemplo de Function Calling
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Obter o clima atual de uma cidade",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
},
},
}]
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[{"role": "user", "content": "Como está o tempo em Xangai hoje?"}],
tools=tools,
)
print(resp.choices[0].message.tool_calls)
O V4-Flash é muito estável em cenários de chamada de ferramenta única. Para cadeias de ferramentas complexas de várias etapas (mais de 5 passos), recomendamos atualizar para o V4-Pro.
3.7 Passo 7: Invocação via protocolo Anthropic
Se o seu projeto for baseado no SDK da Anthropic (como integrações com Claude Code), você ainda pode utilizá-lo:
from anthropic import Anthropic
client = Anthropic(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com",
)
resp = client.messages.create(
model="deepseek-v4-flash",
max_tokens=1024,
messages=[{"role": "user", "content": "Oi"}],
)
print(resp.content[0].text)
🎯 Sugestão de protocolo duplo: Para o mesmo modelo deepseek-v4-flash, o protocolo OpenAI utiliza
api.apiyi.com/v1, enquanto o protocolo Anthropic utilizaapi.apiyi.com(sem/v1). Ao alternar, altere apenas o campo base_url. Para mais detalhes sobre protocolos, consulte a coluna DeepSeek na documentação oficial da APIYI emdocs.apiyi.com.
Quatro: Caminho completo para migrar de modelos antigos para o deepseek-v4-flash

4.1 Por que você deve migrar: contagem regressiva de 90 dias
O anúncio oficial do DeepSeek é claro:
Os modelos legados
deepseek-chatedeepseek-reasonerserão desativados em 24 de julho de 2026.
Por favor, atualize seu modelo paradeepseek-v4-prooudeepseek-v4-flash.
Após 24/07/2026, as solicitações que continuarem usando os IDs de modelo antigos retornarão um erro. A partir da data de lançamento, 24/04/2026, há um período de carência total de 90 dias.
4.2 Tabela de decisão de migração
De acordo com o modelo que você usa atualmente, aqui está o novo modelo correspondente:
| ID do modelo antigo | ID do novo modelo | Dificuldade de migração |
|---|---|---|
deepseek-chat |
deepseek-v4-flash (modo Non-Thinking) |
⭐ Altere apenas 1 campo |
deepseek-reasoner |
deepseek-v4-flash + modo Thinking |
⭐⭐ Altere o modelo + adicione parâmetro reasoning |
deepseek-reasoner (cenários de alto valor) |
deepseek-v4-pro + modo Thinking |
⭐⭐ Altere o modelo + adicione parâmetro reasoning |
deepseek-v3.x |
deepseek-v4-flash |
⭐ Altere apenas o modelo |
deepseek-coder etc. (especializados) |
deepseek-v4-flash |
⭐ Altere apenas o modelo (capacidades gerais já cobertas) |
4.3 Diff de código: quase zero de alteração
Antes da migração:
resp = client.chat.completions.create(
model="deepseek-chat", # ← Modelo antigo
messages=[...],
)
Após a migração:
resp = client.chat.completions.create(
model="deepseek-v4-flash", # ← Altere esta linha
messages=[...],
)
Se você também estiver migrando do deepseek-reasoner:
resp = client.chat.completions.create(
- model="deepseek-reasoner",
+ model="deepseek-v4-flash",
messages=[...],
+ extra_body={"reasoning": {"enabled": True}},
)
4.4 Checklist de migração
Recomendamos executar esta lista antes da migração:
- Mapear todos os locais onde
model=está codificado (hardcoded) no código. - Avaliar se as chamadas do
deepseek-reasonerprecisam ser atualizadas para o V4-Pro. - Preparar um conjunto de prompts de teste de regressão (20–50 prompts, cobrindo o negócio principal).
- No painel da APIYI
apiyi.com, reduzir temporariamente o limite diário das solicitações antigas para forçar a migração. - Executar modelos novos e antigos em AB Test por 1 semana para comparar a qualidade da saída.
- Monitorar a curva de consumo de tokens para confirmar que não houve aumento inesperado de custos.
- Atualizar a documentação interna e o Runbook.
4.5 Sugestão de lançamento gradual (Canary)
Em 3 fases:
| Fase | Tráfego | Período | Objetivo |
|---|---|---|---|
| Fase 1 | 5% | 1ª semana | Validar protocolo e saída básica |
| Fase 2 | 30% | 2ª-3ª semana | Comparar métricas-chave (qualidade + custo) |
| Fase 3 | 100% | 4ª semana | Migração total, manter chave antiga para rollback de emergência |
💡 Rollback de emergência: O roteamento de modelos antigos na APIYI apiyi.com permanecerá compatível até 24/07/2026. Se encontrar problemas graves durante a migração, basta alterar o
modelde volta paradeepseek-chat/deepseek-reasonerpara restaurar o serviço imediatamente. Mas não deixe para a última hora no final de julho.
V. FAQ sobre o deepseek-v4-flash
Q1: Como escolher entre o Flash e o Pro?
A regra de ouro é: use o Flash por padrão e suba para o Pro se encontrar gargalos. Veja os cenários:
- Conversas simples, FAQ, classificação, resumos, preenchimento de código → Flash
- Fluxos de trabalho de agentes com várias etapas (mais de 5 chamadas de ferramentas) → Pro
- Tarefas de pesquisa profunda → Pro
- Se estiver em dúvida, teste primeiro com o Flash; se o resultado não for satisfatório, mude para o Pro.
Q2: A janela de contexto de 1M é realmente utilizável?
Sim, mas fique atento a estes pontos:
- Primeiros 100K–300K: onde o modelo tem maior atenção e melhor desempenho.
- 300K–800K: o desempenho permanece estável.
- 800K–1M: a recuperação marginal pode cair; recomenda-se colocar informações críticas no início ou no fim.
- Lembrete de custo: 1M de tokens de entrada custa aproximadamente US$ 0,14; não é caro, mas não é gratuito.
Para textos longos, a estrutura recomendada é: "pergunta no início + material no meio + reafirmação da pergunta no final".
Q3: Como ativar o modo Thinking?
No protocolo OpenAI, ative via extra_body.reasoning.enabled=true. O parâmetro effort pode ser low, medium ou high (o padrão é medium). Na APIYI api.apiyi.com, os parâmetros são idênticos aos oficiais.
Q4: O Function Calling é estável no Flash?
Chamadas únicas são muito estáveis (taxa de sucesso superior a 95%). Para cadeias de ferramentas complexas (mais de 5 etapas), recomendamos o Pro — a diferença de 11 pontos no Terminal-Bench 2.0 reflete exatamente esse cenário.
Q5: Qual é a concorrência (concurrency) razoável?
Para desenvolvedores individuais, 10–20 conexões simultâneas funcionam bem. Para ambientes de produção, sugerimos:
- Padrão: use 50 conexões simultâneas via
api.apiyi.com. - Tarefas em lote/noturnas: mude para
vip.apiyi.com, que suporta mais de 200 conexões. - Picos de emergência: faça um fallback temporário para
b.apiyi.com.
Consulte os limites mais recentes em docs.apiyi.com.
Q6: Como avaliar o risco de migração?
Use o método de três etapas:
- Qualidade da saída: faça um teste AB com 20–50 prompts típicos do seu negócio, avaliando manualmente ou via modelo de pontuação.
- Curva de custo: observe o consumo diário de tokens; a saída do Flash costuma ser um pouco maior (especialmente no modo Thinking).
- Latência: o TTFT do Flash é próximo ao do V3.5, mas o modo Thinking é de 2 a 5 vezes mais lento.
Se a perda de qualidade for superior a 10%, considere o Pro; caso contrário, pode migrar sem medo.
Q7: Como usar a compatibilidade com o protocolo Anthropic?
Não inclua /v1 na base_url, chame diretamente POST /v1/messages. Basta definir o campo model do SDK da Anthropic como deepseek-v4-flash. É um atalho para migração com custo zero para projetos que já utilizam o SDK da Claude.
Q8: Existe desconto para cache de contexto?
O V4-Flash já possui cache de contexto automático (context caching); solicitações com prefixos repetidos terão cobranças menores. Em cenários com comandos de sistema longos, é possível economizar de 30% a 50%. Esse benefício é ativado por padrão na plataforma APIYI apiyi.com, sem necessidade de parâmetros extras.
VI. Resumo do lançamento do deepseek-v4-flash
O lançamento do DeepSeek V4 traz dois fatos cruciais para os desenvolvedores:
- Mais barato: o V4-Flash oferece um desempenho próximo ao Pro por 1/12 do preço, estabelecendo um novo recorde de mercado com US$ 0,14/M de entrada.
- Migração obrigatória: os modelos antigos serão desativados em 24/07/2026, com uma contagem regressiva de 90 dias iniciada na data do lançamento.
A boa notícia é que o deepseek-v4-flash já está disponível na APIYI apiyi.com. Você não precisa configurar contas internacionais, alterar SDKs ou se preocupar com pagamentos. Basta seguir três passos:
- ✅ Obtenha uma chave no painel da
apiyi.com. - ✅ Aponte a
base_urlparaapi.apiyi.com/v1(ou use os backupsvip.apiyi.com/b.apiyi.com). - ✅ Defina o
modelcomodeepseek-v4-flashe mantenha o restante do código como está.
🎯 Dica de ação: recomendamos fortemente iniciar hoje mesmo um teste AB com o deepseek-v4-flash. Crie uma chave dedicada na APIYI apiyi.com, rode 20–50 prompts típicos e compare a qualidade e o custo com o seu modelo atual. Se não houver perda significativa, você pode migrar 5% do tráfego ainda esta semana e concluir a migração total em 4 semanas — é muito mais tranquilo do que deixar para a última hora em julho. Para casos de migração detalhados e scripts de benchmark, consulte a seção DeepSeek V4 em
docs.apiyi.com.
O valor do deepseek-v4-flash não é ser "apenas mais um modelo barato", mas sim levar a um preço acessível capacidades que antes eram exclusivas de gigantes do setor: ler livros inteiros com 1M de contexto, realizar raciocínios complexos com o modo Thinking e conectar ferramentas completas via Function Calling. Isso abrirá novas oportunidades de produtos; quem migrar primeiro, sairá na frente.
Autor: Equipe Técnica APIYI
Recursos relacionados:
- Comunicado oficial DeepSeek: api-docs.deepseek.com/news/news260424
- Repositório open source Hugging Face: huggingface.co/deepseek-ai/DeepSeek-V4-Flash
- Site oficial APIYI: apiyi.com
- Documentação APIYI: docs.apiyi.com
- Site principal APIYI: api.apiyi.com (backups: vip.apiyi.com / b.apiyi.com)