2026-04-24,DeepSeek 在 Hugging Face 同時開源了 V4-Pro 和 V4-Flash 兩個預覽版模型。前者是面向最前沿性能的 1.6T 參數 MoE 巨獸,後者是"接近 Pro 90% 能力、價格只有 1/12"的性價比甜點。
如果你只看一個模型,就看 deepseek-v4-flash。原因也簡單:
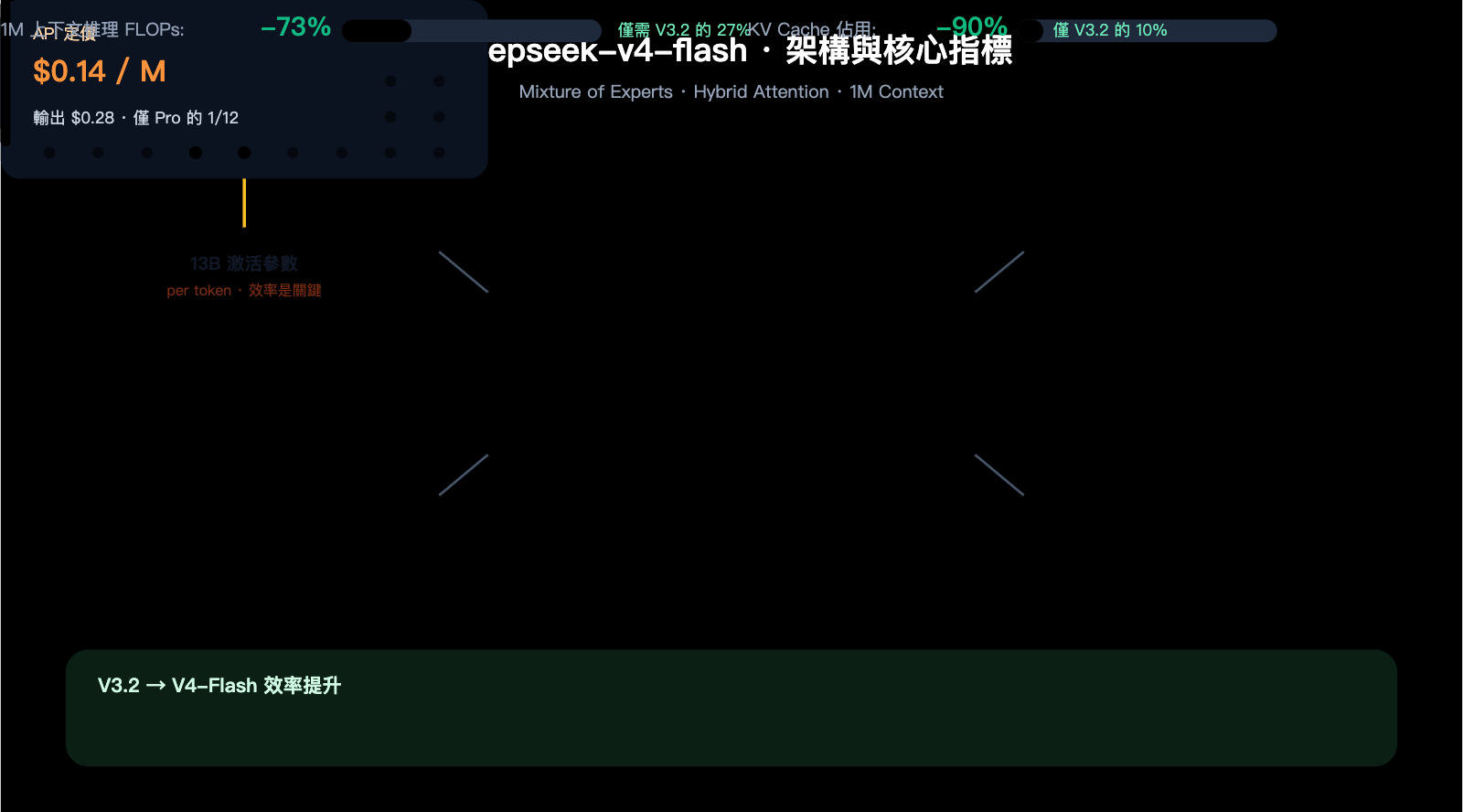
- 284B / 13B MoE 架構 + Hybrid Attention,1M 上下文下推理 FLOPs 僅 V3.2 的 27%
- 1M tokens 上下文 / 384K tokens 最大輸出,原生跑長文不用再切 chunk
- 輸入 $0.14、輸出 $0.28 每百萬 tokens,比 Pro 便宜一個數量級
- SWE-bench Verified 79.0%、Artificial Analysis Intelligence Index 45–47,夠用絕大多數場景
- 同時兼容 OpenAI ChatCompletions 和 Anthropic API 雙協議,Claude Code / OpenClaw / OpenCode 零改造可用
更重要的一條:舊模型 deepseek-chat 和 deepseek-reasoner 將於 2026-07-24 正式停服,所有線上業務必須在此之前完成遷移。這是 90 天倒計時的硬截止。
好消息是:deepseek-v4-flash 已在 API易 apiyi.com 上架。你不需要自建 DeepSeek 賬號、不需要改 SDK、不需要處理海外支付——把 model 字段改一下、base_url 指到 api.apiyi.com 就能用上。
本文是一份 3+5 的組合:3 分鐘讀懂 V4-Flash 核心升級 + 5 分鐘完成從舊模型的完整遷移。
一、deepseek-v4-flash 的 5 大核心升級
1.1 核心規格一覽表
先看全貌,再展開細節:
| 維度 | deepseek-v4-flash |
|---|---|
| 發佈日期 | 2026-04-24(預覽版) |
| 開源倉庫 | huggingface.co/deepseek-ai/DeepSeek-V4-Flash |
| 總參數 | 284B(Mixture of Experts) |
| 激活參數 | 13B |
| 上下文窗口 | 1M tokens |
| 最大輸出 | 384K tokens |
| 注意力架構 | Hybrid Attention(CSA + HCA) |
| 推理模式 | Thinking / Non-Thinking 雙模式 |
| Function Calling | ✅ 支持 |
| JSON 模式 | ✅ 支持 |
| Chat Prefix Completion | Beta 支持 |
| API 協議 | OpenAI ChatCompletions + Anthropic 雙兼容 |
| 輸入價格 | $0.14 / M tokens |
| 輸出價格 | $0.28 / M tokens |
下面把這 5 項升級逐一拆開講。
1.2 升級 1:1M 上下文 + 384K 輸出(原生超長)
deepseek-v4-flash 原生支持 1M tokens 輸入、384K tokens 輸出。這是整個 V4 系列的統一規格,Flash 並沒有爲了便宜而縮水上下文。
什麼場景能喫下 1M?
| 內容類型 | 大致 token 數 |
|---|---|
| 10 萬字中文書稿 | ≈ 150K tokens |
| 200 頁 PDF 技術文檔 | ≈ 300K tokens |
| 一箇中型代碼倉庫(~50 個文件) | ≈ 500K–800K tokens |
| 整本《紅樓夢》 | ≈ 1M tokens |
對比 GPT-5.4(400K)、Claude Opus 4.6(1M + 1M 上下文包)、Gemini 3.1-Pro(2M),V4-Flash 的 1M 已經是行業主流配置,而它的價格比前三者便宜 5–20 倍。
1.3 升級 2:284B/13B MoE + Hybrid Attention
V4-Flash 用了 DeepSeek 2026 引入的兩個關鍵架構創新:
- MoE:總參數 284B,每 token 只激活 13B。效果接近一個 13B 密集模型但知識面接近 200B+ 密集模型
- Hybrid Attention(CSA 壓縮稀疏注意力 + HCA 高度壓縮注意力):專門爲長上下文設計
效率實測數據(來自 DeepSeek 官方):
| 指標 | V3.2 | V4-Flash | 提升 |
|---|---|---|---|
| 1M 上下文單 token 推理 FLOPs | 100% | 27% | -73% |
| 1M 上下文 KV 緩存佔用 | 100% | 10% | -90% |
這兩組數字解釋了爲什麼 Flash 能把價格壓到 $0.14:底層算力成本真的降下來了,不是硬補貼。
1.4 升級 3:Thinking / Non-Thinking 雙模式
V4-Flash 一個模型 ID 就能切兩種模式:
- Non-Thinking(默認):快,適合閒聊、問答、分類、摘要
- Thinking:模型會先輸出一段內部推理(類似 OpenAI o 系列),然後再給出最終答案。適合複雜推理、多步工具調用、代碼調試
調用時通過請求參數切換(不是兩個 model id),開發者側改動極小。在 API易 api.apiyi.com 上調用時,這個參數名和 DeepSeek 官方完全一致。
1.5 升級 4:$0.14 / $0.28 每 M tokens
這是本次發佈最驚人的一組數字:
| 模型 | 輸入 ($/M) | 輸出 ($/M) | 相對 V4-Flash |
|---|---|---|---|
| deepseek-v4-flash | 0.14 | 0.28 | 1×(基準) |
| deepseek-v4-pro | 1.74 | 3.48 | 12× |
| GPT-5.4(參考) | 2.50 | 10.00 | 17×–35× |
| Claude Sonnet 4.6(參考) | 3.00 | 15.00 | 21×–53× |
一個典型的 "500 tokens 輸入 + 500 tokens 輸出" 請求:
- V4-Flash:$0.000 21 ≈ ¥0.0015
- GPT-5.4:$0.006 25 ≈ ¥0.045
- Claude Sonnet 4.6:$0.009 ≈ ¥0.065
Flash 便宜了 30–40 倍。對月調用量上億 tokens 的產品來說,這直接決定毛利率。
1.6 升級 5:OpenAI + Anthropic 雙協議兼容
V4-Flash 在 API 層同時實現了兩套協議:
POST /v1/chat/completions→ OpenAI 格式POST /v1/messages→ Anthropic 格式
這意味着:
| 客戶端 | 遷移成本 |
|---|---|
| OpenAI Python/Node SDK | 零修改,只改 base_url 和 model |
| Anthropic Python/Node SDK | 零修改,只改 base_url 和 model |
| Claude Code | 換個 Anthropic endpoint 即可 |
| OpenClaw / OpenCode | 原生支持 |
| LangChain / LlamaIndex | 換 base_url 即可 |
這是 DeepSeek 本次版本一個非常聰明的決策:不逼你學新協議,讓存量生態零成本接入。
1.7 Benchmark 實測對比表
| Benchmark | V4-Flash | V4-Pro | 差距 |
|---|---|---|---|
| SWE-bench Verified(代碼修復) | 79.0% | 82.1% | -3.1 |
| Terminal-Bench 2.0(多步工具用) | 56.9% | 67.9% | -11.0 |
| SimpleQA-Verified(事實召回) | 34.1% | 57.9% | -23.8 |
| Artificial Analysis Intelligence Index | 45 / 47 | 58 | -11 ~ -13 |
解讀:Flash 在單步代碼任務(SWE-bench)上幾乎追平 Pro,但在需要多步工具鏈(Terminal-Bench)和事實記憶(SimpleQA)上差距明顯。這兩個差距正是判斷"選 Flash 還是 Pro"的決策依據。
二、deepseek-v4-flash vs V4-Pro 場景決策
2.1 一張決策矩陣:先看這裏
| 場景 | 推薦 | 理由 |
|---|---|---|
| 日常對話、閒聊、問答 | Flash | 能力完全夠用,價格 1/12 |
| 客服機器人、FAQ 系統 | Flash | 吞吐高、延遲低 |
| 代碼補全、單文件修改 | Flash | SWE-bench 79%,接近 Pro |
| 長文檔摘要、讀一本書 | Flash | 1M 上下文全給到 |
| 多步工具鏈 Agent | Pro | Terminal-Bench 差 11 分 |
| 深度研究、多輪查證 | Pro | SimpleQA 差 24 分 |
| 高價值商業報告生成 | Pro | Intelligence Index 高 11+ |
| 研發 / 探索型實驗 | Flash | 便宜 12 倍,迭代快 |
通用法則:默認用 Flash,遇到瓶頸再升 Pro。這和做技術選型時"先用簡單方案、有瓶頸再升級"的原則一致。
2.2 性價比測算:什麼規模下 Flash 省錢更狠
假設你的產品每日調用 1 億 tokens(輸入 6 千萬 + 輸出 4 千萬):
| 模型 | 日成本 | 月成本 | 年成本 |
|---|---|---|---|
| V4-Flash | $19.6 | $588 | $7 056 |
| V4-Pro | $243.6 | $7 308 | $87 696 |
| GPT-5.4(參考) | $550 | $16 500 | $198 000 |
Flash 一年省 $80K+ vs Pro。這筆錢夠再養半個開發了。
2.3 混合路由:生產環境的最佳實踐
大多數產品的最優解不是二選一,而是按請求類型動態路由:
def route_model(request_type: str) -> str:
if request_type in ("chat", "faq", "summarize", "classify"):
return "deepseek-v4-flash"
if request_type in ("deep_research", "multi_step_agent"):
return "deepseek-v4-pro"
return "deepseek-v4-flash" # 默認走 Flash
🎯 落地建議:我們建議你在 API易 apiyi.com 平臺同時保留 V4-Flash 和 V4-Pro 兩個模型調用權限。兩者共用一把 Key,只要改
model字段就能切換。批量任務推薦走vip.apiyi.com高併發線路,Pro 的複雜任務走主站api.apiyi.com,不同業務可以在同一個配置裏做 AB 流量分配。
三、5 分鐘在 API易 apiyi.com 調用 deepseek-v4-flash
3.1 Step 1:前置環境與拿 Key
| 項 | 要求 |
|---|---|
| Python 或 Node.js | Python 3.8+ / Node.js 18+ |
| 客戶端 SDK | OpenAI Python openai >= 1.0 或 官方 Node SDK |
| 網絡 | 可訪問 api.apiyi.com |
| Key | 在 API易 apiyi.com 控制檯生成,以 sk- 開頭 |
拿 Key:
- 訪問
apiyi.com,註冊/登錄後進入控制檯 - 左側菜單 → API Keys → 新建密鑰
- 建議設置「使用額度上限」爲 ¥50–100 做初期驗證
- 複製以
sk-開頭的密鑰字符串
3.2 Step 2:選擇線路(base_url)
API易提供三條線路,共用同一把 Key:
| base_url | 定位 | 推薦場景 |
|---|---|---|
https://api.apiyi.com/v1 |
主站 | 默認首選,日常調用 |
https://vip.apiyi.com/v1 |
高併發 | 批量跑圖/推理、夜間隊列 |
https://b.apiyi.com/v1 |
備用 | 主站波動時自動 fallback |
日常開發用主站即可,生產環境遇到 429 限流或 5xx 抖動再切 VIP/備用。
3.3 Step 3:Python 最小調用示例(Non-Thinking)
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "system", "content": "你是一個簡潔的助手"},
{"role": "user", "content": "用三點總結 DeepSeek V4-Flash 的核心升級"},
],
max_tokens=512,
)
print(resp.choices[0].message.content)
改動點只有兩處:
base_url指向api.apiyi.commodel改成deepseek-v4-flash
其他 OpenAI SDK 代碼原樣保留。
3.4 Step 4:啓用 Thinking 推理模式
需要深度推理時,在請求里加 reasoning 參數:
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "user", "content": "證明:給定 n 個點,最少需要多少條直線覆蓋所有點對?"},
],
extra_body={
"reasoning": {"enabled": True, "effort": "high"},
},
max_tokens=8192,
)
# 返回裏會帶 reasoning_content 字段
print("思考過程:", resp.choices[0].message.reasoning_content)
print("最終答案:", resp.choices[0].message.content)
Thinking 模式下耗時會增加 2–5 倍(取決於問題複雜度),但代碼/數學題的準確率顯著上升。
3.5 Step 5:Node.js 最小調用示例
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_API_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const resp = await client.chat.completions.create({
model: "deepseek-v4-flash",
messages: [
{ role: "user", content: "Write a haiku about 2026 AI" },
],
max_tokens: 256,
});
console.log(resp.choices[0].message.content);
3.6 Step 6:Function Calling 示例
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
},
},
}]
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[{"role": "user", "content": "今天上海天氣怎麼樣?"}],
tools=tools,
)
print(resp.choices[0].message.tool_calls)
V4-Flash 在單次工具調用場景裏穩定性非常好。多步複雜工具鏈(5+ 步)時建議升級到 V4-Pro。
3.7 Step 7:Anthropic 協議調用
如果你的項目是基於 Anthropic SDK 開發的(比如集成了 Claude Code),照樣能用:
from anthropic import Anthropic
client = Anthropic(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com",
)
resp = client.messages.create(
model="deepseek-v4-flash",
max_tokens=1024,
messages=[{"role": "user", "content": "Hi"}],
)
print(resp.content[0].text)
🎯 雙協議建議:同一個 deepseek-v4-flash 模型,OpenAI 協議走
api.apiyi.com/v1,Anthropic 協議走api.apiyi.com(無/v1)。切換時只動 base_url 一個字段。更多協議細節可參考 API易官方文檔docs.apiyi.com的 DeepSeek 專欄。
四、從舊模型遷移到 deepseek-v4-flash 的完整路徑

4.1 爲什麼必須遷移:90 天倒計時
DeepSeek 官方公告明確:
Legacy models
deepseek-chatanddeepseek-reasonerretire July 24, 2026.
Please update your model todeepseek-v4-proordeepseek-v4-flash.
2026-07-24 之後,繼續使用舊 model id 的請求將直接返回錯誤。從發佈日 2026-04-24 算起,總共 90 天緩衝期。
4.2 遷移決策表
按你當前使用的模型,對應新模型:
| 舊 model id | 新 model id | 遷移難度 |
|---|---|---|
deepseek-chat |
deepseek-v4-flash(Non-Thinking 模式) |
⭐ 只改 1 個字段 |
deepseek-reasoner |
deepseek-v4-flash + Thinking 模式 |
⭐⭐ 改 model + 加 reasoning 參數 |
deepseek-reasoner(高價值場景) |
deepseek-v4-pro + Thinking 模式 |
⭐⭐ 改 model + 加 reasoning 參數 |
deepseek-v3.x |
deepseek-v4-flash |
⭐ 只改 model |
deepseek-coder 等專用 |
deepseek-v4-flash |
⭐ 只改 model(通用能力已覆蓋) |
4.3 代碼 Diff:幾乎零改動
遷移前:
resp = client.chat.completions.create(
model="deepseek-chat", # ← 舊模型
messages=[...],
)
遷移後:
resp = client.chat.completions.create(
model="deepseek-v4-flash", # ← 改這一行
messages=[...],
)
如果同時要從 deepseek-reasoner 遷移:
resp = client.chat.completions.create(
- model="deepseek-reasoner",
+ model="deepseek-v4-flash",
messages=[...],
+ extra_body={"reasoning": {"enabled": True}},
)
4.4 遷移 Checklist
建議在遷移前跑一遍這份清單:
- 梳理所有代碼裏的
model=硬編碼位置 - 評估
deepseek-reasoner的調用是否需要升級到 V4-Pro - 準備一組迴歸測試 prompt(20–50 條,覆蓋核心業務)
- 在 API易
apiyi.com控制檯把舊請求的每日上限臨時收緊,強制觸發遷移 - 新老模型 AB 跑 1 周,對比輸出質量
- 監控 token 消耗曲線,確認成本沒有意外上漲
- 更新內部文檔和 Runbook
4.5 灰度發佈建議
分 3 期:
| 期次 | 流量 | 週期 | 目標 |
|---|---|---|---|
| 第 1 期 | 5% | 第 1 周 | 驗證協議和基本輸出 |
| 第 2 期 | 30% | 第 2-3 周 | 對比關鍵指標(質量 + 成本) |
| 第 3 期 | 100% | 第 4 周 | 全量遷移,保留舊 Key 做緊急回滾 |
💡 緊急回滾:API易 apiyi.com 的舊模型路由在 2026-07-24 之前保留兼容。遷移期間如果發現嚴重問題,把
model改回deepseek-chat/deepseek-reasoner即可立即恢復。但千萬別拖到 7 月底才動工。
五、deepseek-v4-flash 常見問題 FAQ
Q1:Flash 和 Pro 具體怎麼選?
一句話法則:默認 Flash,遇到瓶頸再升 Pro。具體到場景:
- 單次對話、FAQ、分類、摘要、代碼補全 → Flash
- 多步 Agent 工作流(5+ 步工具調用)→ Pro
- 深度研究型任務 → Pro
- 不確定時,先跑 Flash 看效果,差再升
Q2:1M 上下文是不是真的能跑滿?
能,但要注意:
- 前 100K–300K:模型注意力最集中,效果最好
- 300K–800K:效果仍然穩定
- 800K–1M:邊際召回會下降,關鍵信息建議放在前或後
- 成本提醒:1M token 輸入 ≈ $0.14,不算貴但也不免費
建議長文場景用"開頭放問題 + 中間放材料 + 結尾再重申問題"的結構。
Q3:Thinking 模式怎麼觸發?
OpenAI 協議下通過 extra_body.reasoning.enabled=true 觸發。effort 參數可選 low / medium / high,默認 medium。在 API易 api.apiyi.com 上參數和官方一致。
Q4:Function Calling 在 Flash 上穩不穩?
單次調用非常穩(95%+ 成功率)。多步工具鏈(5+ 步)建議用 Pro——Terminal-Bench 2.0 的 11 分差距主要體現在這裏。
Q5:合理併發是多少?
個人開發者 10–20 併發沒問題。生產環境建議:
- 默認:通過
api.apiyi.com走 50 併發 - 批量/夜間任務:切到
vip.apiyi.com,可到 200+ 併發 - 緊急抖動:臨時 fallback 到
b.apiyi.com
具體上限建議在 docs.apiyi.com 查看最新配額說明。
Q6:怎麼評估遷移風險?
三步法:
- 輸出質量:用 20–50 條業務典型 prompt 做 AB,人工或打分模型評估
- 成本曲線:觀察每日 token 消耗,Flash 輸出 token 通常會略多一點(Thinking 模式下更明顯)
- 延遲:Flash 的 TTFT 和 V3.5 接近,Thinking 模式會慢 2–5 倍
超過 10% 質量回退就考慮升級到 Pro,否則放心遷。
Q7:Anthropic 協議兼容具體怎麼用?
base_url 不帶 /v1,直接調 POST /v1/messages。Anthropic SDK 的 model 字段填 deepseek-v4-flash 即可。這對已經在用 Claude SDK 的項目是零改造遷移的捷徑。
Q8:有沒有上下文緩存優惠?
V4-Flash 已啓用自動上下文緩存(context caching),重複前綴的請求實際計費會更低。長系統提示詞場景下能再省 30–50%。這個優惠在 API易 apiyi.com 平臺是默認開啓的,不需要額外參數。
六、deepseek-v4-flash 上架總結
這次 DeepSeek V4 的發佈,對開發者來說有兩個關鍵事實:
- 便宜了:V4-Flash 用 1/12 的價格做到接近 Pro 的能力,$0.14/M 輸入創了行業新低
- 逼遷了:2026-07-24 舊模型正式下線,90 天緩衝期從發佈日開始倒計時
好消息是 deepseek-v4-flash 已在 API易 apiyi.com 上架,你不用自建海外賬號、不用改 SDK、不用擔心支付通道。三步搞定:
- ✅ 在
apiyi.com控制檯拿一把 Key - ✅
base_url指向api.apiyi.com/v1(備用vip.apiyi.com/b.apiyi.com) - ✅
model設爲deepseek-v4-flash,其餘代碼原樣保留
🎯 行動建議:強烈建議今天就啓動 deepseek-v4-flash 的 AB 測試。在 API易 apiyi.com 開一把專用 Key,跑 20–50 條業務典型 prompt,對比原有模型的輸出質量和成本。如果沒有明顯回退,本週就可以把 5% 流量切過去,4 周內完成全量遷移——比拖到 7 月再趕工從容得多。更詳細的遷移案例和 benchmark 腳本可參考
docs.apiyi.com的 DeepSeek V4 專欄。
deepseek-v4-flash 的價值不是"又一個便宜模型",而是"把原本只有前沿巨頭才能服務的場景推到了人人能用的價位"——1M 上下文讀整本書、Thinking 模式做複雜推理、Function Calling 接全套工具,這些能力的單次成本壓到了幾毫錢。這會直接打開一批新的產品機會,誰先遷完誰先跑在前面。
作者: API易技術團隊
相關資源:
- DeepSeek 官方公告: api-docs.deepseek.com/news/news260424
- Hugging Face 開源倉庫: huggingface.co/deepseek-ai/DeepSeek-V4-Flash
- API易官網: apiyi.com
- API易文檔: docs.apiyi.com
- API易主站: api.apiyi.com(備用 vip.apiyi.com / b.apiyi.com)