
Le 24 avril 2026, DeepSeek a publié en open source les versions préliminaires V4-Pro et V4-Flash sur Hugging Face. Le premier est un monstre MoE de 1,6 T de paramètres axé sur des performances de pointe, tandis que le second est une option au rapport qualité-prix imbattable, offrant "90 % des capacités du Pro pour seulement 1/12 du prix".
Si vous ne devez retenir qu'un seul modèle, choisissez deepseek-v4-flash. La raison est simple :
- Architecture MoE 284B / 13B + Hybrid Attention : les FLOPs d'inférence pour 1 M de contexte ne représentent que 27 % de ceux du V3.2.
- Contexte de 1 M de jetons / Sortie maximale de 384 K jetons : gérez nativement de longs textes sans avoir à les découper.
- 0,14 $ en entrée / 0,28 $ en sortie par million de jetons : un ordre de grandeur moins cher que la version Pro.
- 79,0 % sur SWE-bench Verified et 45–47 sur l'Artificial Analysis Intelligence Index : suffisant pour la grande majorité des cas d'usage.
- Double compatibilité avec les protocoles OpenAI ChatCompletions et Anthropic API : utilisable sans modification avec Claude Code, OpenClaw ou OpenCode.
Point crucial : les anciens modèles deepseek-chat et deepseek-reasoner seront officiellement mis hors service le 24 juillet 2026. Toutes les activités en ligne doivent être migrées avant cette date. Il s'agit d'un compte à rebours ferme de 90 jours.
La bonne nouvelle : deepseek-v4-flash est déjà disponible sur APIYI (apiyi.com). Pas besoin de créer un compte DeepSeek, de modifier votre SDK ou de gérer des paiements internationaux : il suffit de changer le champ model et de pointer base_url vers api.apiyi.com pour commencer à l'utiliser.
Cet article est structuré en deux parties : 3 minutes pour comprendre les améliorations clés de V4-Flash + 5 minutes pour effectuer une migration complète depuis les anciens modèles.
I. Les 5 améliorations majeures de deepseek-v4-flash
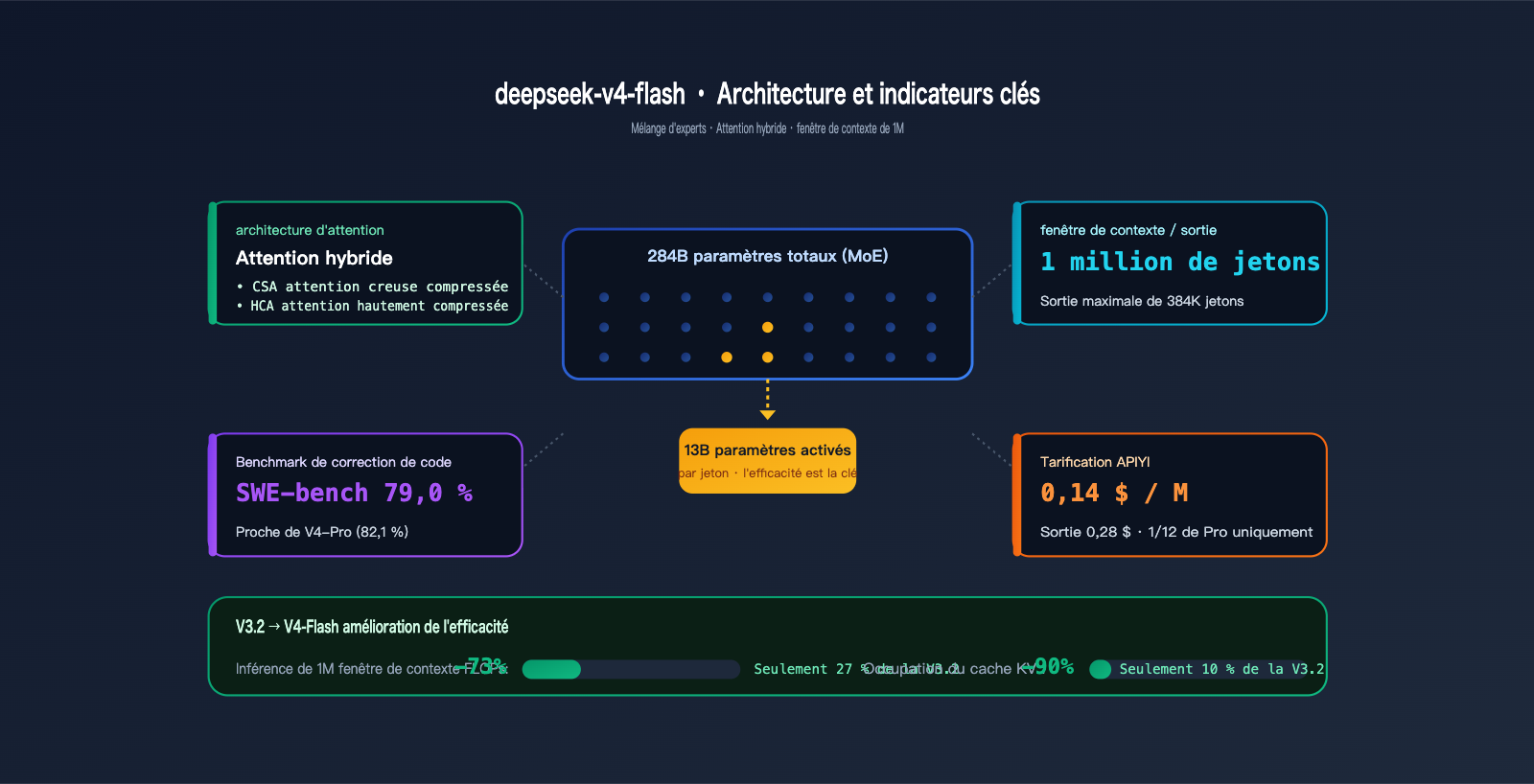
1.1 Tableau récapitulatif des spécifications
Voici une vue d'ensemble :
| Dimension | deepseek-v4-flash |
|---|---|
| Date de sortie | 24/04/2026 (version préliminaire) |
| Dépôt open source | huggingface.co/deepseek-ai/DeepSeek-V4-Flash |
| Paramètres totaux | 284B (Mixture of Experts) |
| Paramètres activés | 13B |
| Fenêtre de contexte | 1 M de jetons |
| Sortie maximale | 384 K jetons |
| Architecture d'attention | Hybrid Attention (CSA + HCA) |
| Mode d'inférence | Double mode Thinking / Non-Thinking |
| Appel de fonction | ✅ Supporté |
| Mode JSON | ✅ Supporté |
| Chat Prefix Completion | Supporté (Beta) |
| Protocole API | Double compatibilité OpenAI + Anthropic |
| Prix d'entrée | 0,14 $ / M jetons |
| Prix de sortie | 0,28 $ / M jetons |
Passons en revue ces 5 points.
1.2 Amélioration 1 : 1 M de contexte + 384 K de sortie (Ultra-long natif)
deepseek-v4-flash prend nativement en charge 1 M de jetons en entrée et 384 K en sortie. Il s'agit de la spécification standard de la gamme V4 ; la version Flash ne sacrifie pas le contexte pour le prix.
Que peut-on traiter avec 1 M de jetons ?
| Type de contenu | Nombre approximatif de jetons |
|---|---|
| Manuscrit de 100 000 caractères chinois | ≈ 150 K jetons |
| Document technique PDF de 200 pages | ≈ 300 K jetons |
| Dépôt de code de taille moyenne (~50 fichiers) | ≈ 500 K–800 K jetons |
| Le roman complet "Le Rêve dans le pavillon rouge" | ≈ 1 M jetons |
Comparé au GPT-5.4 (400 K), au Claude Opus 4.6 (1 M + 1 M de pack de contexte) et au Gemini 3.1-Pro (2 M), le 1 M de V4-Flash est déjà la configuration standard de l'industrie, pour un prix 5 à 20 fois inférieur.
1.3 Amélioration 2 : MoE 284B/13B + Hybrid Attention
V4-Flash utilise deux innovations architecturales introduites par DeepSeek en 2026 :
- MoE : 284 B de paramètres totaux, avec seulement 13 B activés par jeton. Les performances sont proches d'un modèle dense de 13 B, mais avec une base de connaissances équivalente à un modèle dense de plus de 200 B.
- Hybrid Attention (CSA : Compressed Sparse Attention + HCA : Highly Compressed Attention) : conçu spécifiquement pour les longs contextes.
Données d'efficacité (source officielle DeepSeek) :
| Indicateur | V3.2 | V4-Flash | Amélioration |
|---|---|---|---|
| FLOPs d'inférence par jeton (1 M contexte) | 100 % | 27 % | -73 % |
| Occupation du cache KV (1 M contexte) | 100 % | 10 % | -90 % |
Ces chiffres expliquent pourquoi Flash peut maintenir un prix de 0,14 $ : les coûts de calcul sous-jacents ont réellement diminué, ce n'est pas une simple subvention.
1.4 Amélioration 3 : Double mode Thinking / Non-Thinking
Un seul identifiant de modèle V4-Flash permet de basculer entre deux modes :
- Non-Thinking (par défaut) : rapide, idéal pour la conversation, les questions-réponses, la classification et le résumé.
- Thinking : le modèle génère d'abord une réflexion interne (similaire à la série o d'OpenAI) avant de donner la réponse finale. Idéal pour le raisonnement complexe, les appels d'outils en plusieurs étapes et le débogage de code.
Le changement s'effectue via les paramètres de la requête (pas besoin de deux identifiants de modèle différents). Sur APIYI api.apiyi.com, le nom de ce paramètre est identique à celui de DeepSeek.
1.5 Amélioration 4 : 0,14 $ / 0,28 $ par million de jetons
Voici les chiffres les plus impressionnants de cette sortie :
| Modèle | Entrée ($/M) | Sortie ($/M) | Relatif à V4-Flash |
|---|---|---|---|
| deepseek-v4-flash | 0,14 | 0,28 | 1× (base) |
| deepseek-v4-pro | 1,74 | 3,48 | 12× |
| GPT-5.4 (référence) | 2,50 | 10,00 | 17×–35× |
| Claude Sonnet 4.6 (référence) | 3,00 | 15,00 | 21×–53× |
Pour une requête typique de "500 jetons en entrée + 500 jetons en sortie" :
- V4-Flash : 0,000 21 $ ≈ 0,0015 ¥
- GPT-5.4 : 0,006 25 $ ≈ 0,045 ¥
- Claude Sonnet 4.6 : 0,009 $ ≈ 0,065 ¥
Flash est 30 à 40 fois moins cher. Pour les produits traitant des centaines de millions de jetons par mois, cela impacte directement la marge brute.
1.6 Amélioration 5 : Double compatibilité de protocole OpenAI + Anthropic
V4-Flash implémente deux protocoles au niveau de l'API :
POST /v1/chat/completions→ format OpenAIPOST /v1/messages→ format Anthropic
Cela signifie que :
| Client | Coût de migration |
|---|---|
| SDK Python/Node OpenAI | Zéro modification, il suffit de changer base_url et model |
| SDK Python/Node Anthropic | Zéro modification, il suffit de changer base_url et model |
| Claude Code | Il suffit de changer le point de terminaison Anthropic |
| OpenClaw / OpenCode | Support natif |
| LangChain / LlamaIndex | Il suffit de changer base_url |
C'est une décision très intelligente de la part de DeepSeek : ne pas forcer l'apprentissage d'un nouveau protocole, permettant une intégration sans coût pour l'écosystème existant.
1.7 Comparaison des benchmarks
| Benchmark | V4-Flash | V4-Pro | Écart |
|---|---|---|---|
| SWE-bench Verified (réparation de code) | 79,0 % | 82,1 % | -3,1 |
| Terminal-Bench 2.0 (outils multi-étapes) | 56,9 % | 67,9 % | -11,0 |
| SimpleQA-Verified (rappel de faits) | 34,1 % | 57,9 % | -23,8 |
| Artificial Analysis Intelligence Index | 45 / 47 | 58 | -11 ~ -13 |
Analyse : Flash égale presque le Pro sur les tâches de code en une étape (SWE-bench), mais l'écart est significatif sur les chaînes d'outils multi-étapes (Terminal-Bench) et la mémoire factuelle (SimpleQA). Ces deux points constituent la base de votre décision pour choisir entre Flash et Pro.
2. Analyse comparative : deepseek-v4-flash vs V4-Pro
2.1 Matrice de décision : par où commencer
| Scénario | Recommandation | Raison |
|---|---|---|
| Conversations quotidiennes, chat, Q&A | Flash | Capacités suffisantes, prix divisé par 12 |
| Chatbots de support, systèmes FAQ | Flash | Débit élevé, faible latence |
| Complétion de code, modification de fichier unique | Flash | 79 % sur SWE-bench, proche du Pro |
| Résumé de longs documents, lecture de livre | Flash | Fenêtre de contexte de 1M complète |
| Agents à outils multi-étapes | Pro | 11 points d'écart sur Terminal-Bench |
| Recherche approfondie, vérification multi-tours | Pro | 24 points d'écart sur SimpleQA |
| Génération de rapports commerciaux à haute valeur | Pro | Indice d'intelligence supérieur de 11+ |
| R&D / Expérimentations exploratoires | Flash | 12 fois moins cher, itération rapide |
Règle générale : Utilisez Flash par défaut, passez au Pro uniquement en cas de blocage. Cela suit le principe de conception technique : "commencer simple, monter en gamme si nécessaire".
2.2 Calcul de rentabilité : quand Flash devient-il vraiment avantageux ?
Supposons que votre produit consomme 100 millions de tokens par jour (60 millions en entrée + 40 millions en sortie) :
| Modèle | Coût quotidien | Coût mensuel | Coût annuel |
|---|---|---|---|
| V4-Flash | 19,6 $ | 588 $ | 7 056 $ |
| V4-Pro | 243,6 $ | 7 308 $ | 87 696 $ |
| GPT-5.4 (réf.) | 550 $ | 16 500 $ | 198 000 $ |
Flash permet d'économiser plus de 80 000 $ par an par rapport au Pro. C'est un budget suffisant pour financer un demi-développeur supplémentaire.
2.3 Routage hybride : les meilleures pratiques en production
Pour la plupart des produits, la solution optimale n'est pas de choisir l'un ou l'autre, mais d'effectuer un routage dynamique selon le type de requête :
def route_model(request_type: str) -> str:
# Pour les tâches simples, on utilise Flash
if request_type in ("chat", "faq", "summarize", "classify"):
return "deepseek-v4-flash"
# Pour les tâches complexes, on passe au Pro
if request_type in ("deep_research", "multi_step_agent"):
return "deepseek-v4-pro"
return "deepseek-v4-flash" # Flash par défaut
🎯 Conseil de mise en œuvre : Nous vous recommandons de conserver les droits d'invocation du modèle pour V4-Flash et V4-Pro sur la plateforme APIYI (apiyi.com). Les deux partagent la même clé API ; il suffit de modifier le champ
modelpour basculer. Pour les tâches par lots, privilégiez la ligne à haute concurrencevip.apiyi.com, et pour les tâches complexes du Pro, utilisez le site principalapi.apiyi.com. Vous pouvez ainsi gérer la répartition du trafic AB dans une seule configuration.
三、5 分钟在 APIYI apiyi.com 调用 deepseek-v4-flash
3.1 Step 1:Configuration et obtention de la clé
| Élément | Exigence |
|---|---|
| Python ou Node.js | Python 3.8+ / Node.js 18+ |
| SDK client | OpenAI Python openai >= 1.0 ou SDK Node officiel |
| Réseau | Accès à api.apiyi.com |
| Clé | Générée dans la console APIYI apiyi.com, commence par sk- |
Obtenir la clé :
- Visitez
apiyi.com, inscrivez-vous/connectez-vous et accédez à la console. - Menu de gauche → API Keys → Créer une nouvelle clé.
- Il est conseillé de définir une « limite de crédit » de 50 à 100 ¥ pour la vérification initiale.
- Copiez la chaîne de caractères commençant par
sk-.
3.2 Step 2:Choisir la route (base_url)
APIYI propose trois routes, partageant la même clé :
| base_url | Positionnement | Scénario recommandé |
|---|---|---|
https://api.apiyi.com/v1 |
Serveur principal | Choix par défaut, usage quotidien |
https://vip.apiyi.com/v1 |
Haute concurrence | Traitement par lots/inférence, files d'attente nocturnes |
https://b.apiyi.com/v1 |
Secours | Basculement automatique en cas d'instabilité du serveur principal |
Pour le développement quotidien, utilisez le serveur principal. En production, passez au VIP ou au secours en cas de limitation 429 ou d'erreurs 5xx.
3.3 Step 3:Exemple minimal d'invocation en Python (Non-Thinking)
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "system", "content": "Tu es un assistant concis"},
{"role": "user", "content": "Résume en trois points les améliorations majeures de DeepSeek V4-Flash"},
],
max_tokens=512,
)
print(resp.choices[0].message.content)
Il n'y a que deux changements à effectuer :
base_urlpointe versapi.apiyi.commodelest défini surdeepseek-v4-flash
Le reste du code utilisant le SDK OpenAI est conservé tel quel.
3.4 Step 4:Activer le mode de raisonnement (Thinking)
Pour une réflexion approfondie, ajoutez le paramètre reasoning à votre requête :
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "user", "content": "Démontrer : Étant donné n points, combien de lignes droites sont nécessaires au minimum pour couvrir toutes les paires de points ?"},
],
extra_body={
"reasoning": {"enabled": True, "effort": "high"},
},
max_tokens=8192,
)
# La réponse contiendra le champ reasoning_content
print("Processus de réflexion:", resp.choices[0].message.reasoning_content)
print("Réponse finale:", resp.choices[0].message.content)
En mode Thinking, le temps de réponse est multiplié par 2 à 5 (selon la complexité), mais la précision sur les problèmes de code ou de mathématiques augmente significativement.
3.5 Step 5:Exemple minimal d'invocation en Node.js
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_API_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const resp = await client.chat.completions.create({
model: "deepseek-v4-flash",
messages: [
{ role: "user", content: "Écris un haïku sur l'IA en 2026" },
],
max_tokens: 256,
});
console.log(resp.choices[0].message.content);
3.6 Step 6:Exemple de Function Calling
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Obtenir la météo actuelle d'une ville",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
},
},
}]
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[{"role": "user", "content": "Quel temps fait-il à Shanghai aujourd'hui ?"}],
tools=tools,
)
print(resp.choices[0].message.tool_calls)
V4-Flash offre une excellente stabilité pour les appels d'outils simples. Pour des chaînes d'outils complexes (plus de 5 étapes), nous recommandons de passer à V4-Pro.
3.7 Step 7:Invocation via le protocole Anthropic
Si votre projet est basé sur le SDK Anthropic (par exemple, si vous avez intégré Claude Code), vous pouvez toujours l'utiliser :
from anthropic import Anthropic
client = Anthropic(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com",
)
resp = client.messages.create(
model="deepseek-v4-flash",
max_tokens=1024,
messages=[{"role": "user", "content": "Salut"}],
)
print(resp.content[0].text)
🎯 Conseil sur le double protocole : Pour le même modèle deepseek-v4-flash, le protocole OpenAI utilise
api.apiyi.com/v1, tandis que le protocole Anthropic utiliseapi.apiyi.com(sans/v1). Lors du basculement, modifiez uniquement le champ base_url. Pour plus de détails sur les protocoles, consultez la section DeepSeek dans la documentation officielle d'APIYI surdocs.apiyi.com.
IV. Parcours complet de migration vers deepseek-v4-flash

4.1 Pourquoi migrer : compte à rebours de 90 jours
L'annonce officielle de DeepSeek est claire :
Les anciens modèles
deepseek-chatetdeepseek-reasonerseront retirés le 24 juillet 2026.
Veuillez mettre à jour votre modèle versdeepseek-v4-prooudeepseek-v4-flash.
Après le 24/07/2026, les requêtes utilisant les anciens identifiants de modèle renverront une erreur. À partir de la date de lancement du 24/04/2026, vous disposez d'une période de transition de 90 jours.
4.2 Tableau de décision de migration
Selon le modèle que vous utilisez actuellement, voici le modèle cible :
| Ancien ID de modèle | Nouvel ID de modèle | Difficulté de migration |
|---|---|---|
deepseek-chat |
deepseek-v4-flash (mode Non-Thinking) |
⭐ Modifier 1 champ |
deepseek-reasoner |
deepseek-v4-flash + mode Thinking |
⭐⭐ Modifier le modèle + ajouter le paramètre reasoning |
deepseek-reasoner (scénarios à haute valeur) |
deepseek-v4-pro + mode Thinking |
⭐⭐ Modifier le modèle + ajouter le paramètre reasoning |
deepseek-v3.x |
deepseek-v4-flash |
⭐ Modifier le modèle |
deepseek-coder etc. |
deepseek-v4-flash |
⭐ Modifier le modèle (capacités générales couvertes) |
4.3 Diff de code : presque aucun changement
Avant migration :
resp = client.chat.completions.create(
model="deepseek-chat", # ← Ancien modèle
messages=[...],
)
Après migration :
resp = client.chat.completions.create(
model="deepseek-v4-flash", # ← Modifier cette ligne
messages=[...],
)
Si vous migrez également depuis deepseek-reasoner :
resp = client.chat.completions.create(
- model="deepseek-reasoner",
+ model="deepseek-v4-flash",
messages=[...],
+ extra_body={"reasoning": {"enabled": True}},
)
4.4 Checklist de migration
Il est recommandé de suivre cette liste avant de migrer :
- Recenser tous les emplacements où
model=est codé en dur dans votre code. - Évaluer si les appels à
deepseek-reasonernécessitent une mise à niveau vers V4-Pro. - Préparer un ensemble de prompts de test de régression (20 à 50 prompts couvrant vos activités principales).
- Réduire temporairement la limite quotidienne des anciennes requêtes dans la console APIYI
apiyi.compour forcer le déclenchement de la migration. - Effectuer un test A/B pendant 1 semaine entre l'ancien et le nouveau modèle pour comparer la qualité des sorties.
- Surveiller la courbe de consommation des jetons pour confirmer l'absence d'augmentation inattendue des coûts.
- Mettre à jour la documentation interne et les procédures d'exploitation (Runbook).
4.5 Suggestions pour un déploiement progressif
En 3 phases :
| Phase | Trafic | Période | Objectif |
|---|---|---|---|
| Phase 1 | 5% | Semaine 1 | Vérifier le protocole et les sorties de base |
| Phase 2 | 30% | Semaines 2-3 | Comparer les indicateurs clés (qualité + coût) |
| Phase 3 | 100% | Semaine 4 | Migration complète, conserver l'ancienne clé pour un retour arrière d'urgence |
💡 Retour arrière d'urgence : Le routage des anciens modèles sur APIYI apiyi.com restera compatible jusqu'au 24/07/2026. Si un problème grave survient pendant la migration, remettez simplement
modelàdeepseek-chat/deepseek-reasonerpour rétablir le service immédiatement. Mais ne tardez pas jusqu'à fin juillet pour commencer.
V. FAQ sur deepseek-v4-flash
Q1 : Comment choisir entre Flash et Pro ?
La règle d'or : par défaut, utilisez Flash, et passez à Pro si vous atteignez une limite. Plus précisément :
- Conversations simples, FAQ, classification, résumé, complétion de code → Flash
- Flux de travail d'agent multi-étapes (plus de 5 appels d'outils) → Pro
- Tâches de recherche approfondie → Pro
- En cas de doute, testez d'abord avec Flash, et montez en gamme si les résultats sont insuffisants.
Q2 : La fenêtre de contexte de 1M est-elle réellement exploitable ?
Oui, mais gardez ces points en tête :
- 100K–300K premiers tokens : l'attention du modèle est maximale, les performances sont optimales.
- 300K–800K : les résultats restent stables.
- 800K–1M : le rappel marginal diminue ; placez les informations critiques au début ou à la fin.
- Rappel tarifaire : 1M de tokens en entrée ≈ 0,14 $, ce n'est pas cher, mais ce n'est pas gratuit.
Pour les textes longs, nous recommandons une structure : "Question au début + Matériel au milieu + Rappel de la question à la fin".
Q3 : Comment déclencher le mode Thinking ?
Avec le protocole OpenAI, utilisez extra_body.reasoning.enabled=true. Le paramètre effort peut être réglé sur low, medium ou high (par défaut sur medium). Sur APIYI api.apiyi.com, les paramètres sont identiques à ceux de l'API officielle.
Q4 : Le Function Calling est-il stable sur Flash ?
Très stable pour un appel unique (plus de 95 % de taux de réussite). Pour des chaînes d'outils complexes (plus de 5 étapes), nous recommandons la version Pro — l'écart de 11 points dans le Terminal-Bench 2.0 se ressent principalement ici.
Q5 : Quel est le niveau de concurrence raisonnable ?
Pour un développeur individuel, 10 à 20 requêtes simultanées ne posent aucun problème. Pour un environnement de production :
- Par défaut : passez par
api.apiyi.compour 50 requêtes simultanées. - Tâches par lots/nuit : basculez sur
vip.apiyi.compour atteindre plus de 200 requêtes simultanées. - Urgence/Pics de charge : utilisez
b.apiyi.comcomme solution de repli temporaire.
Consultez docs.apiyi.com pour connaître les derniers quotas mis à jour.
Q6 : Comment évaluer les risques de migration ?
Une méthode en trois étapes :
- Qualité de sortie : réalisez un test A/B sur 20 à 50 invites représentatives de votre activité, évaluées manuellement ou par un modèle de notation.
- Courbe des coûts : observez la consommation quotidienne de tokens ; les tokens de sortie de Flash sont généralement légèrement plus élevés (surtout en mode Thinking).
- Latence : le TTFT de Flash est proche de celui de la V3.5, mais le mode Thinking est 2 à 5 fois plus lent.
Si vous constatez une baisse de qualité supérieure à 10 %, envisagez de passer à la version Pro, sinon, migrez en toute confiance.
Q7 : Comment utiliser la compatibilité avec le protocole Anthropic ?
N'incluez pas /v1 dans la base_url, appelez directement POST /v1/messages. Remplissez simplement le champ model du SDK Anthropic avec deepseek-v4-flash. C'est le raccourci idéal pour migrer sans modification les projets utilisant déjà le SDK Claude.
Q8 : Existe-t-il des remises sur la mise en cache du contexte ?
V4-Flash intègre automatiquement la mise en cache du contexte (context caching) ; les requêtes avec des préfixes répétés sont facturées moins cher. Pour les invites système longues, cela permet d'économiser 30 à 50 %. Cette remise est activée par défaut sur la plateforme APIYI apiyi.com, sans paramètre supplémentaire.
VI. Résumé du lancement de deepseek-v4-flash
Le lancement de DeepSeek V4 apporte deux faits majeurs pour les développeurs :
- Plus économique : V4-Flash offre des capacités proches de la version Pro pour 1/12ème du prix, avec un coût d'entrée de 0,14 $/M, un nouveau record dans l'industrie.
- Migration forcée : les anciens modèles seront officiellement retirés le 24 juillet 2026, avec un compte à rebours de 90 jours lancé dès aujourd'hui.
La bonne nouvelle est que deepseek-v4-flash est déjà disponible sur APIYI apiyi.com. Pas besoin de créer un compte à l'étranger, de modifier votre SDK ou de vous soucier des méthodes de paiement. Trois étapes suffisent :
- ✅ Obtenez une clé sur le tableau de bord
apiyi.com. - ✅ Pointez la
base_urlversapi.apiyi.com/v1(ou utilisez les alternativesvip.apiyi.com/b.apiyi.com). - ✅ Définissez
modelsurdeepseek-v4-flash, et gardez le reste de votre code intact.
🎯 Conseil d'action : nous vous recommandons vivement de lancer dès aujourd'hui vos tests A/B pour deepseek-v4-flash. Créez une clé dédiée sur APIYI apiyi.com, testez 20 à 50 invites représentatives et comparez la qualité et les coûts avec votre modèle actuel. Sans baisse de performance notable, vous pourrez basculer 5 % de votre trafic cette semaine et finaliser la migration totale sous 4 semaines — bien plus sereinement que dans l'urgence de juillet. Pour des cas de migration détaillés et des scripts de benchmark, consultez la rubrique DeepSeek V4 sur
docs.apiyi.com.
La valeur de deepseek-v4-flash n'est pas d'être "juste un modèle bon marché", mais de rendre accessibles à tous des scénarios autrefois réservés aux géants de la tech : lire un livre entier avec 1M de contexte, effectuer des raisonnements complexes avec le mode Thinking, ou connecter des outils complets via le Function Calling, le tout pour un coût dérisoire. Cela ouvre de nouvelles opportunités de produits ; les premiers à migrer seront les premiers à en récolter les fruits.
Auteur : Équipe technique APIYI
Ressources associées :
- Annonce officielle DeepSeek : api-docs.deepseek.com/news/news260424
- Dépôt open source Hugging Face : huggingface.co/deepseek-ai/DeepSeek-V4-Flash
- Site officiel APIYI : apiyi.com
- Documentation APIYI : docs.apiyi.com
- Site principal APIYI : api.apiyi.com (alternatives : vip.apiyi.com / b.apiyi.com)





