Author's Note: A deep dive into the core content of the Kimi K2.5 technical paper. We'll break down the 1T-parameter MoE architecture, the 384-expert configuration, and the MLA attention mechanism, while comparing local deployment hardware requirements and API integration options.
Curious about the technical details of Kimi K2.5? This article, based on the Kimi K2.5 official technical paper, systematically breaks down its trillion-parameter MoE architecture, training methods, and benchmark results. We'll also dive into the specific hardware requirements for local deployment.
Core Value: By the end of this post, you'll have a solid grasp of Kimi K2.5's core technical parameters and architectural design principles, and you'll know how to choose the best deployment plan for your hardware.
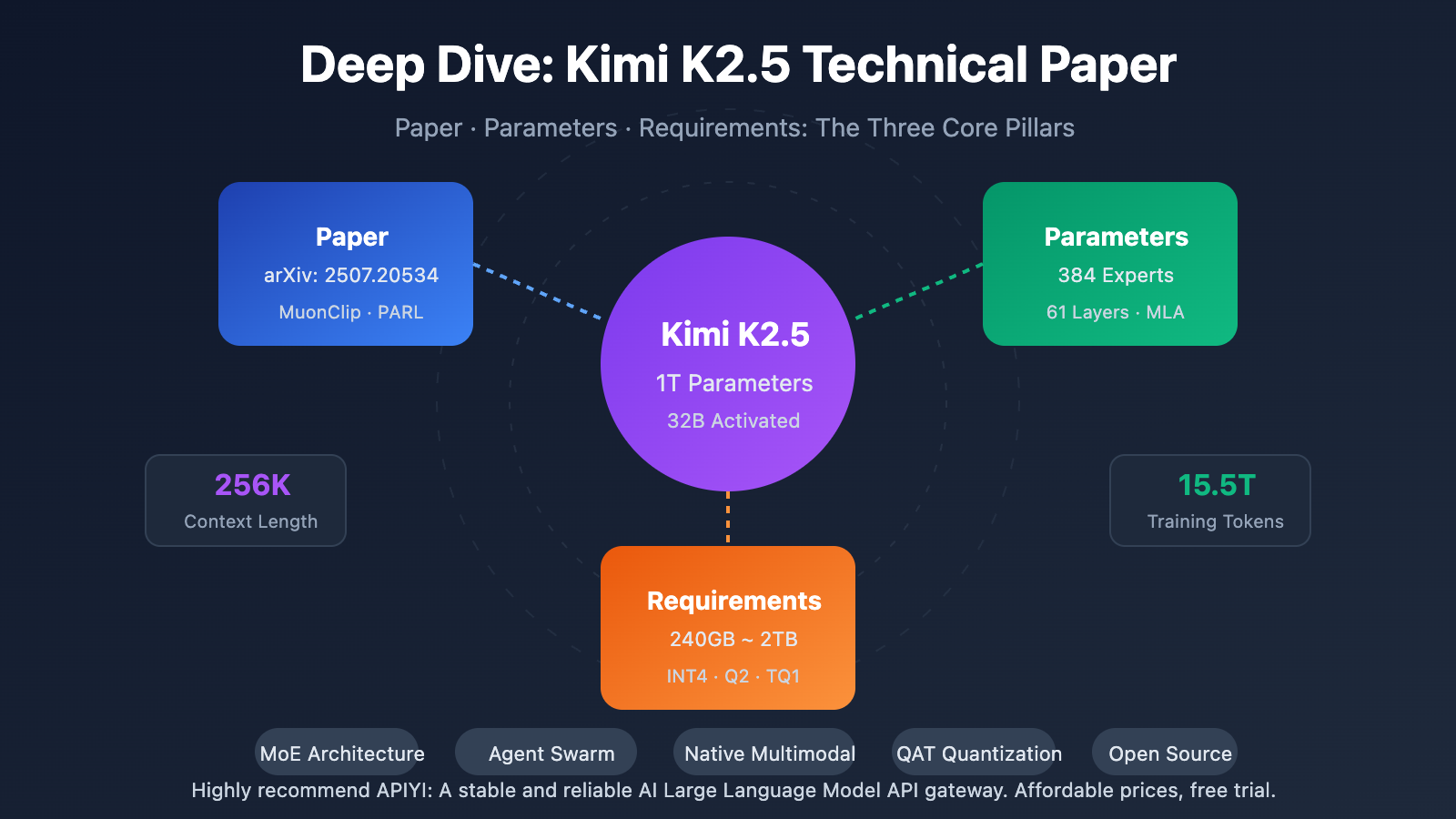
Key Takeaways from the Kimi K2.5 Technical Paper
| Feature | Technical Details | Innovative Value |
|---|---|---|
| Trillion-Parameter MoE | 1T total parameters, 32B activated | Only 3.2% activated during inference; extremely efficient |
| 384 Expert System | 8 experts + 1 shared expert selected per token | 50% more experts than DeepSeek-V3 |
| MLA Attention | Multi-head Latent Attention | Reduces KV Cache, supports 256K context |
| MuonClip Optimizer | Token-efficient training, zero Loss Spike | 15.5T token training without loss spikes |
| Native Multimodal | MoonViT 400M vision encoder | 15T vision-text hybrid training |
Kimi K2.5 Paper Background
The Kimi K2.5 technical paper was released by the Moonshot AI team, listed under arXiv as 2507.20534. The paper details the technical evolution from Kimi K2 to K2.5, with core contributions including:
- Ultra-sparse MoE Architecture: A 384-expert configuration, which is 50% more than DeepSeek-V3's 256 experts.
- MuonClip Training Optimization: Effectively addresses the Loss Spike issue in large-scale training.
- Agent Swarm Paradigm: Uses the PARL (Parallel-Agent Reinforcement Learning) training method.
- Native Multimodal Fusion: Integrates vision-language capabilities right from the pre-training stage.
The paper points out that as high-quality human data becomes increasingly scarce, token efficiency is becoming a critical coefficient for scaling Large Language Models. This shift has driven the adoption of the Muon optimizer and synthetic data generation.
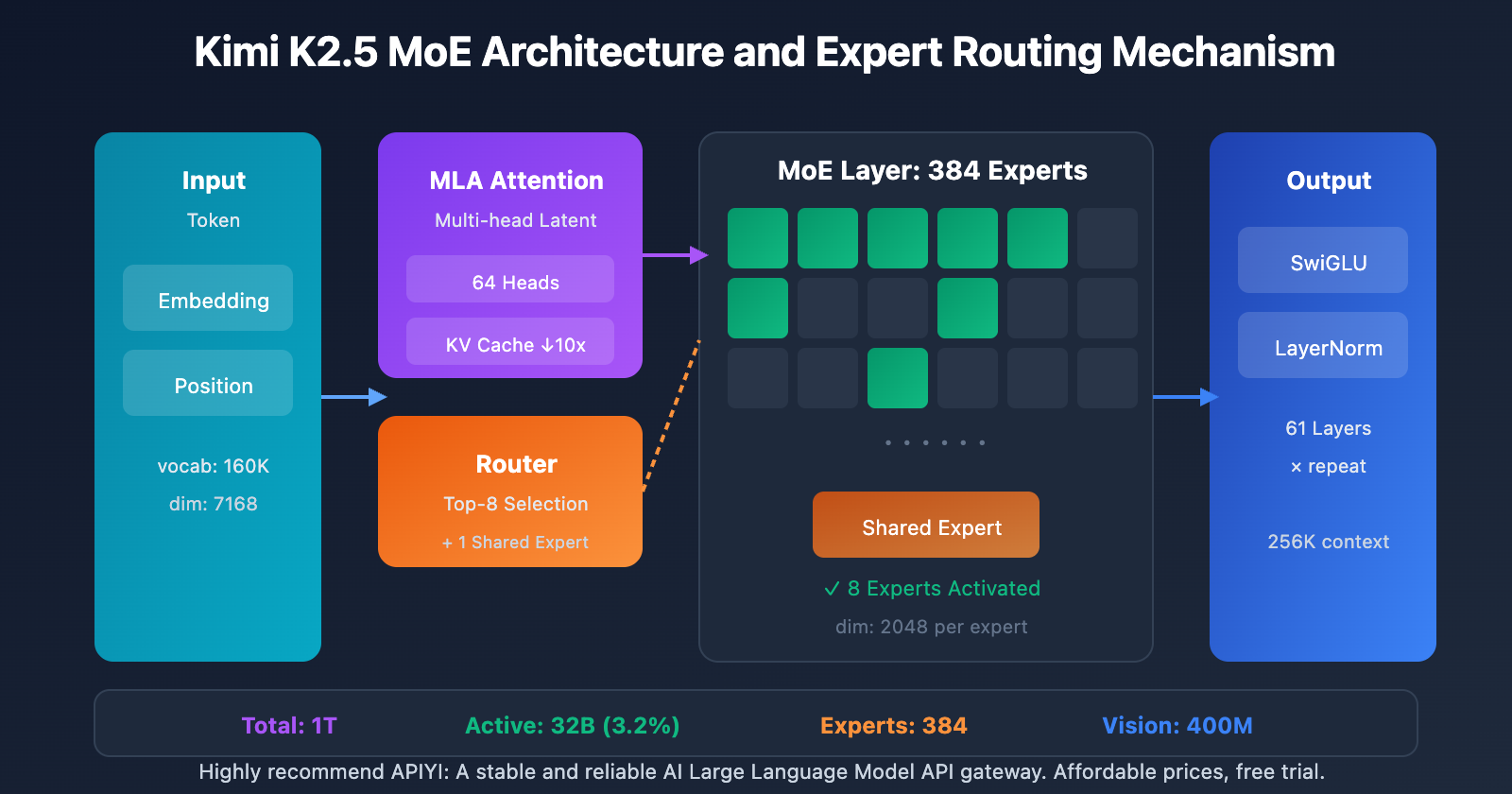
Kimi K2.5 Parameters: Full Specifications
Core Architecture Parameters
| Category | Parameter | Value | Description |
|---|---|---|---|
| Scale | Total Parameters | 1T (1.04 Trillion) | Full model size |
| Scale | Active Parameters | 32B | Actually used during a single inference |
| Architecture | Layers | 61 Layers | Includes 1 Dense layer |
| Architecture | Hidden Dimension | 7168 | Model backbone dimension |
| MoE | Number of Experts | 384 | 128 more than DeepSeek-V3 |
| MoE | Active Experts | 8 + 1 Shared | Top-8 routing selection |
| MoE | Expert Hidden Dim | 2048 | FFN dimension for each expert |
| Attention | Attention Heads | 64 | Half as many as DeepSeek-V3 |
| Attention | Mechanism Type | MLA | Multi-head Latent Attention |
| Other | Vocabulary Size | 160K | Multilingual support |
| Other | Context Length | 256K | Ultra-long document processing |
| Other | Activation Function | SwiGLU | Efficient non-linear transformation |
Kimi K2.5 Design Deep Dive
Why choose 384 experts?
Scaling Law analysis in the paper shows that continuously increasing sparsity brings significant performance gains. The team increased the number of experts from 256 in DeepSeek-V3 to 384, boosting the model's representation capabilities.
Why reduce the number of attention heads?
To lower computational overhead during inference, the number of attention heads was reduced from 128 to 64. Combined with the MLA mechanism, this design significantly cuts down on KV Cache memory usage while maintaining top-tier performance.
Advantages of the MLA Attention Mechanism:
Traditional MHA: KV Cache = 2 × L × H × D × B
MLA: KV Cache = 2 × L × C × B (C << H × D)
L = Layers, H = Heads, D = Dimension, B = Batch, C = Compression Dim
MLA uses latent space compression to reduce the KV Cache by about 10x, making a 256K context window actually feasible.
Vision Encoder Parameters
| Component | Parameter | Value |
|---|---|---|
| Name | MoonViT | In-house vision encoder |
| Parameters | – | 400M |
| Features | Spatio-temporal pooling | Video understanding support |
| Integration | Native fusion | Integrated during the pre-training stage |
Kimi K2.5 Requirements: Deployment Hardware Requirements
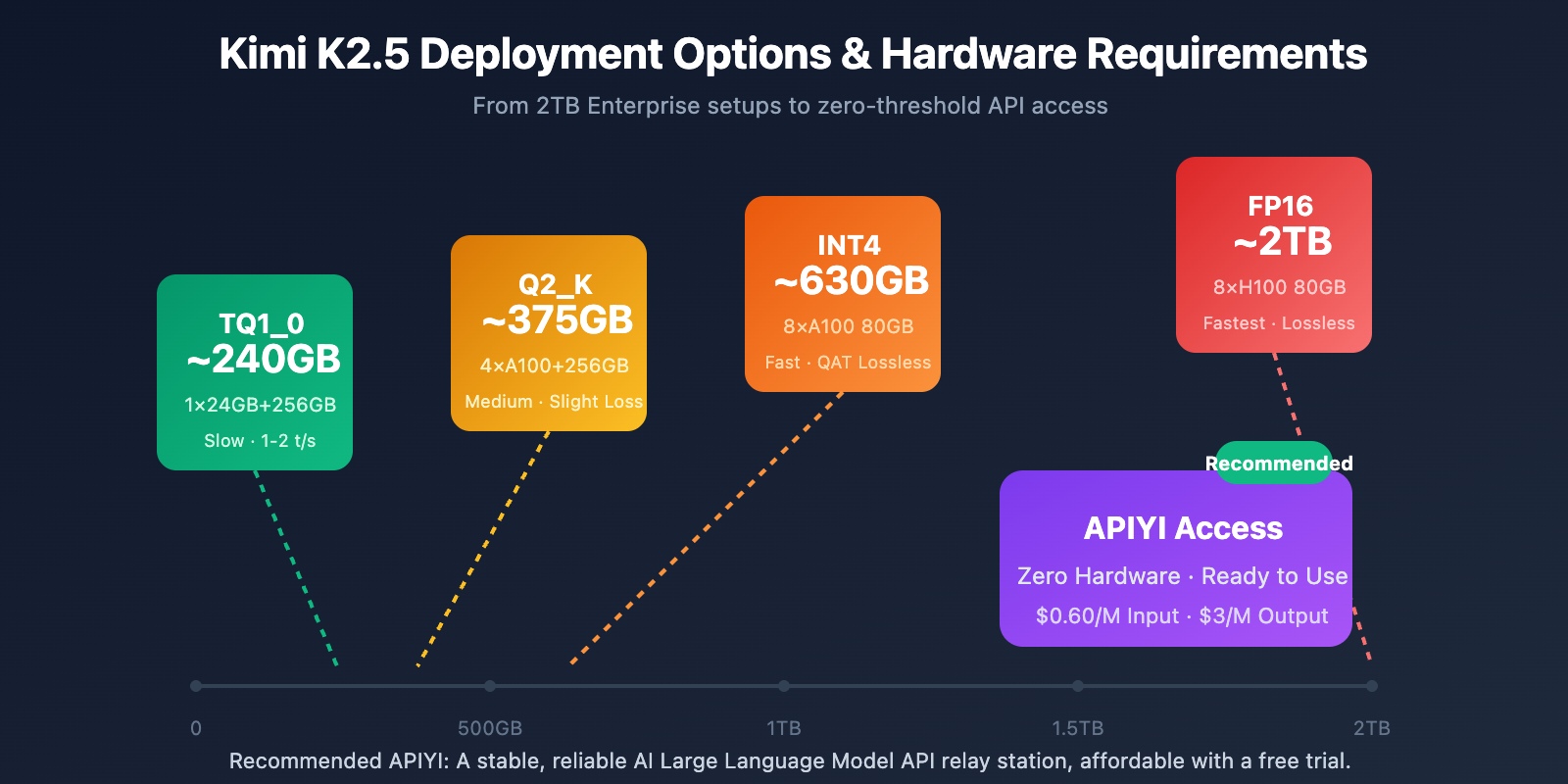
Local Deployment Hardware Requirements
| Quantization | Storage Required | Minimum Hardware | Inference Speed | Accuracy Loss |
|---|---|---|---|---|
| FP16 | ~2TB | 8×H100 80GB | Fastest | None |
| INT4 (QAT) | ~630GB | 8×A100 80GB | Fast | Near-lossless |
| Q2_K_XL | ~375GB | 4×A100 + 256GB RAM | Medium | Slight |
| TQ1_0 (1.58-bit) | ~240GB | 1×24GB GPU + 256GB RAM | Slow (1-2 t/s) | Noticeable |
Kimi K2.5 Requirements: Detailed Breakdown
Enterprise-Grade Deployment (Recommended)
Hardware: 2× NVIDIA H100 80GB or 8× A100 80GB
Storage: 630GB+ (INT4 Quantization)
Performance: 50-100 tokens/s
Use Case: Production environments, high-concurrency services
Extreme Compression Deployment
Hardware: 1× RTX 4090 24GB + 256GB System RAM
Storage: 240GB (1.58-bit Quantization)
Performance: 1-2 tokens/s
Use Case: Research testing, feature verification
Note: MoE layers are completely offloaded to RAM, so it's slow.
Why the high memory requirement?
Even though the MoE architecture only activates 32B parameters per inference, the model needs to keep the full 1T parameters in memory to dynamically route inputs to the correct experts. This is an inherent trait of MoE models.
A More Practical Solution: API Access
For most developers, the hardware barrier for local Kimi K2.5 deployment is quite high. Accessing it via API is a much more practical choice:
| Option | Cost | Advantages |
|---|---|---|
| APIYI (Recommended) | $0.60/M input, $3/M output | Unified interface, multi-model switching, free credits |
| Official API | Same as above | Full feature set, earliest updates |
| Local 1-bit | Hardware cost + Electricity | Localized data |
Deployment Advice: Unless you have strict data localization requirements, we recommend using APIYI (apiyi.com) to access Kimi K2.5. It saves you from massive hardware investments.
Kimi K2.5 Paper Benchmark Results
Core Capability Evaluation
| Benchmark | Kimi K2.5 | GPT-5.2 | Claude Opus 4.5 | Description |
|---|---|---|---|---|
| AIME 2025 | 96.1% | – | – | Math Competition (avg@32) |
| HMMT 2025 | 95.4% | 93.3% | – | Math Competition (avg@32) |
| GPQA-Diamond | 87.6% | – | – | Scientific Reasoning (avg@8) |
| SWE-Bench Verified | 76.8% | – | 80.9% | Code Repair |
| SWE-Bench Multi | 73.0% | – | – | Multilingual Code |
| HLE-Full | 50.2% | – | – | Comprehensive Reasoning (with tools) |
| BrowseComp | 60.2% | 54.9% | 24.1% | Web Interaction |
| MMMU-Pro | 78.5% | – | – | Multimodal Understanding |
| MathVision | 84.2% | – | – | Visual Math |
Training Data and Methods
| Stage | Data Volume | Method |
|---|---|---|
| K2 Base Pre-training | 15.5T tokens | MuonClip Optimizer, Zero Loss Spikes |
| K2.5 Continued Pre-training | 15T Vision-Text Mix | Native Multimodal Fusion |
| Agent Training | – | PARL (Parallel Agent Reinforcement Learning) |
| Quantization Training | – | QAT (Quantization-Aware Training) |
The paper specifically highlights that the MuonClip optimizer allowed the entire 15.5T token pre-training process to run without a single loss spike. This is a significant breakthrough in the world of trillion-parameter scale training.
Kimi K2.5 Quick Integration
Simple Implementation
With the APIYI platform, you can call Kimi K2.5 in just 10 lines of code:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY", # 在 apiyi.com 获取
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "解释 MoE 架构的工作原理"}]
)
print(response.choices[0].message.content)
View Thinking Mode Code
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Thinking 模式 - 深度推理
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "system", "content": "你是 Kimi,请详细分析问题"},
{"role": "user", "content": "证明根号2是无理数"}
],
temperature=1.0, # Thinking 模式推荐
top_p=0.95,
max_tokens=8192
)
# 获取推理过程和最终答案
reasoning = getattr(response.choices[0].message, "reasoning_content", None)
answer = response.choices[0].message.content
if reasoning:
print(f"推理过程:\n{reasoning}\n")
print(f"最终答案:\n{answer}")
Tip: Head over to APIYI (apiyi.com) to grab some free test credits and experience Kimi K2.5's deep reasoning capabilities in Thinking Mode for yourself.
FAQ
Q1: Where can I get the Kimi K2.5 technical paper?
The official technical paper for the Kimi K2 series is published on arXiv under the identifier 2507.20534 and can be accessed at arxiv.org/abs/2507.20534. The specific technical report for Kimi K2.5 is available on the official blog at kimi.com/blog/kimi-k2-5.html.
Q2: What are the minimum requirements for Kimi K2.5 local deployment?
An extreme compression setup requires: 1 GPU with 24GB VRAM + 256GB system RAM + 240GB storage space. However, inference speed in this configuration is only about 1-2 tokens/s. The recommended setup is 2×H100 or 8×A100; using INT4 quantization can achieve production-grade performance.
Q3: How can I quickly verify Kimi K2.5’s capabilities?
There's no need for local deployment—you can test it quickly via API:
- Visit APIYI (apiyi.com) to register an account.
- Get your API Key and free credits.
- Use the code examples provided in this article and set the model name to
kimi-k2.5. - Experience the deep reasoning power of "Thinking" mode.
Summary
Key takeaways from the Kimi K2.5 technical paper:
- Kimi K2.5 Paper Core Innovations: Features a 384-expert MoE architecture + MLA attention + MuonClip optimizer, achieving loss-free peak training for trillion-parameter models.
- Kimi K2.5 Key Parameters: 1T total parameters, 32B active parameters, 61 layers, and a 256K context window, with only 3.2% of parameters activated during each inference.
- Kimi K2.5 Deployment Requirements: The barrier for local deployment is high (minimum 240GB+), making API access a much more practical choice.
Kimi K2.5 is now live on APIYI (apiyi.com). We recommend quickly verifying the model's capabilities through the API to evaluate how it fits your specific business needs.
References
⚠️ Link Format Note: All external links use the format
Resource Name: domain.com. This makes them easy to copy while preventing accidental clicks and SEO link equity loss.
-
Kimi K2 arXiv Paper: Official technical report detailing the architecture and training methods.
- Link:
arxiv.org/abs/2507.20534 - Description: Get full technical details and experimental data.
- Link:
-
Kimi K2.5 Technical Blog: Official K2.5 technical report release.
- Link:
kimi.com/blog/kimi-k2-5.html - Description: Learn about Agent Swarm and multimodal capabilities.
- Link:
-
HuggingFace Model Card: Model weights and usage instructions.
- Link:
huggingface.co/moonshotai/Kimi-K2.5 - Description: Download model weights and view deployment guides.
- Link:
-
Unsloth Local Deployment Guide: Detailed tutorial for quantized deployment.
- Link:
unsloth.ai/docs/models/kimi-k2.5 - Description: Understand hardware requirements for various quantization precisions.
- Link:
Author: Technical Team
Technical Discussion: Feel free to discuss Kimi K2.5's technical details in the comments. For more Large Language Model deep dives, visit the APIYI apiyi.com tech community.