24 апреля 2026 года компания DeepSeek одновременно выпустила в открытый доступ на Hugging Face две предварительные версии моделей: V4-Pro и V4-Flash. Первая — это 1,6-триллионный гигант на архитектуре MoE, ориентированный на максимальную производительность, а вторая — «золотая середина» с 90% возможностей Pro-версии при цене в 12 раз ниже.
Если вам нужно выбрать только одну модель, выбирайте deepseek-v4-flash. Вот почему:
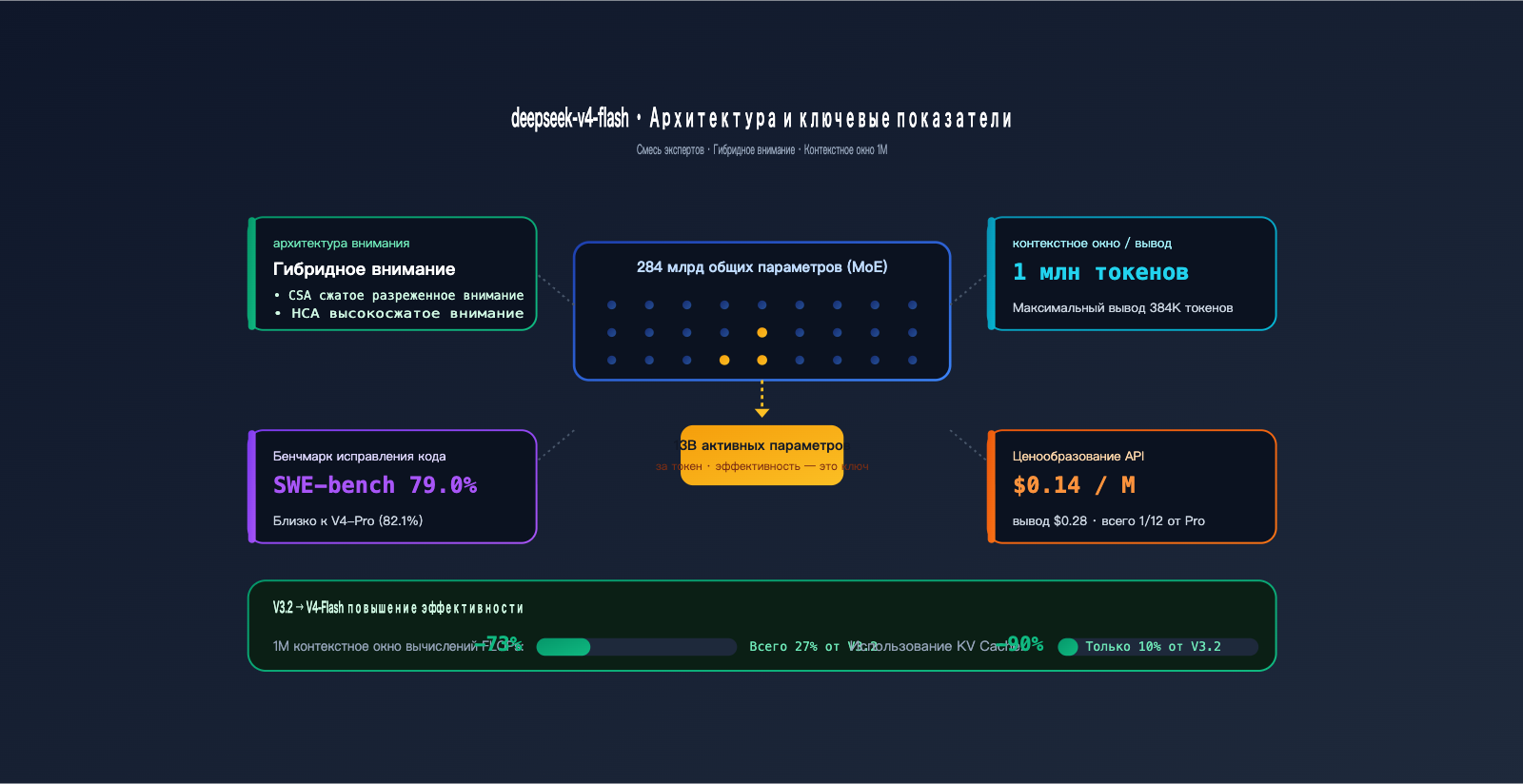
- Архитектура 284B / 13B MoE + Hybrid Attention: при контексте 1M токенов количество операций (FLOPs) составляет всего 27% от уровня V3.2.
- Контекстное окно 1M токенов / 384K токенов на вывод: нативная поддержка длинных текстов без необходимости разбивки на части (chunking).
- Цена $0.14 за вход и $0.28 за выход на миллион токенов: на порядок дешевле Pro-версии.
- Результаты: 79.0% в SWE-bench Verified и 45–47 баллов в Artificial Analysis Intelligence Index — этого достаточно для большинства сценариев.
- Двойная совместимость: поддержка протоколов OpenAI ChatCompletions и Anthropic API. Работает с Claude Code, OpenClaw и OpenCode без доработок.
Важное напоминание: старые модели deepseek-chat и deepseek-reasoner будут официально отключены 24 июля 2026 года. Все рабочие проекты должны быть перенесены до этой даты. У вас есть 90 дней.
Хорошая новость: deepseek-v4-flash уже доступна на APIYI (apiyi.com). Вам не нужно создавать аккаунт DeepSeek, менять SDK или решать проблемы с зарубежными платежами — просто укажите нужную модель в поле model и направьте base_url на api.apiyi.com.
Эта статья — комбинация «3+5»: 3 минуты на понимание ключевых обновлений V4-Flash + 5 минут на полный перенос со старых моделей.
1. Пять главных обновлений deepseek-v4-flash
1.1 Краткая таблица характеристик
Взглянем на общую картину:
| Параметр | deepseek-v4-flash |
|---|---|
| Дата выпуска | 24.04.2026 (предварительная версия) |
| Репозиторий | huggingface.co/deepseek-ai/DeepSeek-V4-Flash |
| Общее число параметров | 284B (Mixture of Experts) |
| Активных параметров | 13B |
| Контекстное окно | 1M токенов |
| Максимальный вывод | 384K токенов |
| Архитектура внимания | Hybrid Attention (CSA + HCA) |
| Режимы вывода | Thinking / Non-Thinking |
| Function Calling | ✅ Поддерживается |
| JSON-режим | ✅ Поддерживается |
| Chat Prefix Completion | Beta-поддержка |
| API-протоколы | OpenAI ChatCompletions + Anthropic |
| Цена (вход) | $0.14 / M токенов |
| Цена (выход) | $0.28 / M токенов |
Разберем эти 5 пунктов подробнее.
1.2 Обновление 1: Контекст 1M + вывод 384K (нативная работа с длинными данными)
deepseek-v4-flash нативно поддерживает 1M токенов на вход и 384K на выход. Это стандарт для всей серии V4, и Flash не урезали в угоду дешевизне.
Что можно уместить в 1M токенов?
| Тип контента | Примерный объем токенов |
|---|---|
| Рукопись на 100 тыс. иероглифов | ≈ 150K токенов |
| Техническая документация на 200 стр. | ≈ 300K токенов |
| Средний репозиторий кода (~50 файлов) | ≈ 500K–800K токенов |
| Полный текст «Сна в красном тереме» | ≈ 1M токенов |
По сравнению с GPT-5.4 (400K), Claude Opus 4.6 (1M) и Gemini 3.1-Pro (2M), 1M у V4-Flash — это актуальный отраслевой стандарт, при этом модель в 5–20 раз дешевле конкурентов.
1.3 Обновление 2: 284B/13B MoE + Hybrid Attention
В V4-Flash реализованы две ключевые инновации DeepSeek 2026 года:
- MoE: 284B общих параметров, при этом на каждый токен активируется только 13B. Эффективность сопоставима с плотной моделью 13B, а база знаний — с моделями 200B+.
- Hybrid Attention (сжатое разреженное внимание CSA + высокосжатое внимание HCA): разработано специально для длинного контекста.
Данные по эффективности (официальные данные DeepSeek):
| Показатель | V3.2 | V4-Flash | Улучшение |
|---|---|---|---|
| FLOPs на токен при 1M контексте | 100% | 27% | -73% |
| Занятость KV-кэша при 1M контексте | 100% | 10% | -90% |
Эти цифры объясняют, почему Flash стоит всего $0.14: реально снизились затраты на вычислительные мощности, это не просто демпинг.
1.4 Обновление 3: Двойной режим Thinking / Non-Thinking
В V4-Flash можно переключаться между двумя режимами через один ID модели:
- Non-Thinking (по умолчанию): высокая скорость, идеально для чатов, ответов на вопросы, классификации и суммаризации.
- Thinking: модель сначала выводит внутренние рассуждения (как в серии OpenAI o), а затем итоговый ответ. Подходит для сложных логических задач, многошагового вызова инструментов и отладки кода.
Переключение происходит через параметры запроса, что требует минимальных правок со стороны разработчика. При вызове через APIYI api.apiyi.com названия параметров полностью соответствуют официальным.
1.5 Обновление 4: $0.14 / $0.28 за миллион токенов
Это самые впечатляющие цифры релиза:
| Модель | Вход ($/M) | Выход ($/M) | Относительно V4-Flash |
|---|---|---|---|
| deepseek-v4-flash | 0.14 | 0.28 | 1× (база) |
| deepseek-v4-pro | 1.74 | 3.48 | 12× |
| GPT-5.4 (справ.) | 2.50 | 10.00 | 17×–35× |
| Claude Sonnet 4.6 (справ.) | 3.00 | 15.00 | 21×–53× |
Типичный запрос «500 токенов вход + 500 токенов выход»:
- V4-Flash: $0.000 21
- GPT-5.4: $0.006 25
- Claude Sonnet 4.6: $0.009
Flash дешевле в 30–40 раз. Для продуктов с ежемесячным потреблением в сотни миллионов токенов это напрямую влияет на маржинальность.
1.6 Обновление 5: Совместимость с протоколами OpenAI и Anthropic
V4-Flash на уровне API поддерживает два стандарта:
POST /v1/chat/completions→ формат OpenAIPOST /v1/messages→ формат Anthropic
Это значит:
| Клиент | Стоимость миграции |
|---|---|
| OpenAI Python/Node SDK | Нулевая, меняете только base_url и model |
| Anthropic Python/Node SDK | Нулевая, меняете только base_url и model |
| Claude Code | Просто смените endpoint на Anthropic |
| OpenClaw / OpenCode | Нативная поддержка |
| LangChain / LlamaIndex | Достаточно сменить base_url |
Это очень мудрое решение DeepSeek: не заставлять учить новые протоколы, позволяя экосистеме подключиться без затрат.
1.7 Сравнительная таблица бенчмарков
| Бенчмарк | V4-Flash | V4-Pro | Разница |
|---|---|---|---|
| SWE-bench Verified (исправление кода) | 79.0% | 82.1% | -3.1 |
| Terminal-Bench 2.0 (инструменты) | 56.9% | 67.9% | -11.0 |
| SimpleQA-Verified (факты) | 34.1% | 57.9% | -23.8 |
| Artificial Analysis Intelligence Index | 45 / 47 | 58 | -11 ~ -13 |
Вывод: Flash почти догнал Pro в задачах по написанию кода (SWE-bench), но заметно отстает там, где нужны многошаговые цепочки инструментов (Terminal-Bench) и память на факты (SimpleQA). Именно на эти показатели стоит ориентироваться при выборе между Flash и Pro.
II. Выбор сценария: deepseek-v4-flash против V4-Pro
2.1 Матрица принятия решений: с чего начать
| Сценарий | Рекомендация | Причина |
|---|---|---|
| Повседневные чаты, вопросы | Flash | Возможностей достаточно, цена в 12 раз ниже |
| Чат-боты поддержки, FAQ | Flash | Высокая пропускная способность, низкая задержка |
| Автодополнение кода, правка файлов | Flash | SWE-bench 79%, близко к Pro |
| Резюме длинных текстов, книг | Flash | Полная поддержка контекстного окна 1M |
| Агенты с многошаговыми цепочками | Pro | Разница в 11 баллов в Terminal-Bench |
| Глубокие исследования, проверка фактов | Pro | Разница в 24 балла в SimpleQA |
| Генерация бизнес-отчетов | Pro | Индекс интеллекта выше на 11+ |
| R&D / Эксперименты | Flash | В 12 раз дешевле, быстрая итерация |
Золотое правило: по умолчанию используйте Flash, переходите на Pro только при возникновении «бутылочного горлышка». Это соответствует принципу технического проектирования: «сначала простое решение, усложнение — только при необходимости».
2.2 Расчет окупаемости: где Flash экономит больше всего
Допустим, ваш продукт потребляет 100 млн токенов в день (60 млн входных + 40 млн выходных):
| Модель | Дневные затраты | Месячные затраты | Годовые затраты |
|---|---|---|---|
| V4-Flash | $19.6 | $588 | $7 056 |
| V4-Pro | $243.6 | $7 308 | $87 696 |
| GPT-5.4 (справ.) | $550 | $16 500 | $198 000 |
Flash экономит более $80 000 в год по сравнению с Pro. Этих денег хватит, чтобы нанять еще пол-разработчика.
2.3 Гибридная маршрутизация: лучшие практики для продакшена
Для большинства продуктов оптимальным решением является не выбор «одного из двух», а динамическая маршрутизация в зависимости от типа запроса:
def route_model(request_type: str) -> str:
# Для простых задач используем Flash
if request_type in ("chat", "faq", "summarize", "classify"):
return "deepseek-v4-flash"
# Для сложных задач используем Pro
if request_type in ("deep_research", "multi_step_agent"):
return "deepseek-v4-pro"
return "deepseek-v4-flash" # По умолчанию Flash
🎯 Совет по внедрению: Мы рекомендуем сохранить доступ к обеим моделям (V4-Flash и V4-Pro) на платформе APIYI (apiyi.com). Они используют один и тот же API-ключ, поэтому для переключения достаточно изменить поле
model. Для пакетных задач рекомендуем использовать высокопроизводительный каналvip.apiyi.com, а для сложных запросов Pro — основнойapi.apiyi.com. Вы можете легко настроить A/B-распределение трафика для разных бизнес-задач в рамках одной конфигурации.
III. 5 минут на вызов deepseek-v4-flash через APIYI (apiyi.com)
3.1 Шаг 1: Подготовка среды и получение ключа
| Параметр | Требование |
|---|---|
| Python или Node.js | Python 3.8+ / Node.js 18+ |
| Клиентский SDK | OpenAI Python openai >= 1.0 или официальный Node SDK |
| Сеть | Доступ к api.apiyi.com |
| Ключ | Генерируется в консоли APIYI apiyi.com, начинается с sk- |
Как получить ключ:
- Перейдите на
apiyi.com, зарегистрируйтесь или войдите в систему. - В меню слева выберите «API Keys» → «Создать ключ».
- Для первичной проверки рекомендуем установить лимит использования на уровне ¥50–100.
- Скопируйте строку ключа, начинающуюся с
sk-.
3.2 Шаг 2: Выбор маршрута (base_url)
APIYI предоставляет три маршрута, которые используют один и тот же ключ:
| base_url | Назначение | Рекомендуемый сценарий |
|---|---|---|
https://api.apiyi.com/v1 |
Основной | Выбор по умолчанию для повседневных задач |
https://vip.apiyi.com/v1 |
Высокая нагрузка | Пакетная генерация/инференс, ночные очереди |
https://b.apiyi.com/v1 |
Резервный | Автоматический fallback при сбоях основного сервера |
Для обычной разработки используйте основной сервер. Переключайтесь на VIP или резервный только в случае возникновения ошибок 429 (лимиты) или 5xx в продакшене.
3.3 Шаг 3: Минимальный пример вызова на Python (без режима рассуждения)
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "system", "content": "Ты лаконичный помощник"},
{"role": "user", "content": "Назови три ключевых улучшения DeepSeek V4-Flash"},
],
max_tokens=512,
)
print(resp.choices[0].message.content)
Нужно изменить всего два параметра:
base_urlдолжен указывать наapi.apiyi.com/v1.modelменяется наdeepseek-v4-flash.
Остальной код OpenAI SDK остается без изменений.
3.4 Шаг 4: Активация режима рассуждения (Thinking)
Если требуется глубокий анализ, добавьте параметр reasoning в запрос:
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "user", "content": "Докажи: дано n точек, какое минимальное количество прямых нужно, чтобы покрыть все пары точек?"},
],
extra_body={
"reasoning": {"enabled": True, "effort": "high"},
},
max_tokens=8192,
)
# В ответе будет поле reasoning_content
print("Процесс мышления:", resp.choices[0].message.reasoning_content)
print("Итоговый ответ:", resp.choices[0].message.content)
В режиме Thinking время ответа увеличивается в 2–5 раз (в зависимости от сложности задачи), но точность в решении математических и программных задач значительно возрастает.
3.5 Шаг 5: Минимальный пример вызова на Node.js
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_API_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const resp = await client.chat.completions.create({
model: "deepseek-v4-flash",
messages: [
{ role: "user", content: "Напиши хайку об ИИ в 2026 году" },
],
max_tokens: 256,
});
console.log(resp.choices[0].message.content);
3.6 Шаг 6: Пример вызова функций (Function Calling)
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Получить текущую погоду в городе",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
},
},
}]
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[{"role": "user", "content": "Какая сегодня погода в Шанхае?"}],
tools=tools,
)
print(resp.choices[0].message.tool_calls)
V4-Flash отлично справляется с одиночными вызовами инструментов. Для сложных многошаговых цепочек (более 5 шагов) рекомендуем использовать V4-Pro.
3.7 Шаг 7: Вызов через протокол Anthropic
Если ваш проект использует SDK Anthropic (например, при интеграции с Claude Code), это тоже будет работать:
from anthropic import Anthropic
client = Anthropic(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com",
)
resp = client.messages.create(
model="deepseek-v4-flash",
max_tokens=1024,
messages=[{"role": "user", "content": "Привет"}],
)
print(resp.content[0].text)
🎯 Совет по протоколам: Для одной и той же модели deepseek-v4-flash протокол OpenAI использует
api.apiyi.com/v1, а протокол Anthropic —api.apiyi.com(без/v1). При переключении меняйте только полеbase_url. Дополнительные детали по протоколам можно найти в разделе DeepSeek официальной документации APIYI наdocs.apiyi.com.
IV. Полный путь миграции на deepseek-v4-flash

4.1 Почему миграция обязательна: обратный отсчет 90 дней
Официальное объявление DeepSeek гласит:
Устаревшие модели
deepseek-chatиdeepseek-reasonerбудут выведены из эксплуатации 24 июля 2026 года.
Пожалуйста, обновите используемую модель доdeepseek-v4-proилиdeepseek-v4-flash.
После 24 июля 2026 года запросы с использованием старых идентификаторов моделей будут возвращать ошибку. С момента выпуска (24 апреля 2026 года) у вас есть 90 дней на переход.
4.2 Таблица решений по миграции
Выберите новую модель в зависимости от того, что вы используете сейчас:
| Старый model id | Новый model id | Сложность миграции |
|---|---|---|
deepseek-chat |
deepseek-v4-flash (режим Non-Thinking) |
⭐ Изменить 1 поле |
deepseek-reasoner |
deepseek-v4-flash + режим Thinking |
⭐⭐ Изменить модель + добавить параметр reasoning |
deepseek-reasoner (критичные задачи) |
deepseek-v4-pro + режим Thinking |
⭐⭐ Изменить модель + добавить параметр reasoning |
deepseek-v3.x |
deepseek-v4-flash |
⭐ Изменить модель |
deepseek-coder и др. |
deepseek-v4-flash |
⭐ Изменить модель (общие возможности уже покрыты) |
4.3 Diff кода: практически нулевые изменения
До миграции:
resp = client.chat.completions.create(
model="deepseek-chat", # ← старая модель
messages=[...],
)
После миграции:
resp = client.chat.completions.create(
model="deepseek-v4-flash", # ← измените эту строку
messages=[...],
)
Если вы также мигрируете с deepseek-reasoner:
resp = client.chat.completions.create(
- model="deepseek-reasoner",
+ model="deepseek-v4-flash",
messages=[...],
+ extra_body={"reasoning": {"enabled": True}},
)
4.4 Чек-лист миграции
Рекомендуем выполнить этот список перед переходом:
- Проверьте все места в коде, где жестко прописан
model=. - Оцените, требует ли ваш сценарий использования
deepseek-reasonerперехода на V4-Pro. - Подготовьте набор регрессионных промптов (20–50 штук, охватывающих основные бизнес-задачи).
- В консоли APIYI
apiyi.comвременно ограничьте дневной лимит для старых запросов, чтобы принудительно выявить места, требующие обновления. - Запустите AB-тестирование старой и новой модели в течение 1 недели для сравнения качества вывода.
- Отслеживайте график потребления токенов, чтобы убедиться в отсутствии непредвиденного роста затрат.
- Обновите внутреннюю документацию и Runbook.
4.5 Рекомендации по поэтапному внедрению
3 этапа:
| Этап | Трафик | Период | Цель |
|---|---|---|---|
| 1-й этап | 5% | 1-я неделя | Проверка протокола и базового вывода |
| 2-й этап | 30% | 2–3-я недели | Сравнение ключевых метрик (качество + стоимость) |
| 3-й этап | 100% | 4-я неделя | Полная миграция, сохранение старого ключа для экстренного отката |
💡 Экстренный откат: Маршрутизация старых моделей в APIYI (apiyi.com) сохраняет совместимость до 24 июля 2026 года. Если во время миграции возникнут серьезные проблемы, просто верните
modelкdeepseek-chat/deepseek-reasonerдля немедленного восстановления работы. Но не откладывайте это до конца июля.
V. Часто задаваемые вопросы по deepseek-v4-flash
Q1: Что выбрать: Flash или Pro?
Коротко: по умолчанию используйте Flash, переходите на Pro, если уперлись в потолок возможностей. Если подробнее:
- Одиночные диалоги, FAQ, классификация, суммаризация, автодополнение кода → Flash.
- Многошаговые рабочие процессы Agent (более 5 вызовов инструментов) → Pro.
- Задачи, требующие глубокого анализа → Pro.
- Если сомневаетесь: сначала протестируйте на Flash, если результат не устраивает — повышайте до Pro.
Q2: Можно ли реально использовать контекстное окно в 1 млн токенов?
Да, но учитывайте следующее:
- Первые 100К–300К: внимание модели максимально, качество лучшее.
- 300К–800К: качество остается стабильным.
- 800К–1М: полнота извлечения информации может снижаться, поэтому важные данные лучше размещать в начале или конце.
- Напоминание о стоимости: 1 млн входных токенов ≈ $0.14, это недорого, но не бесплатно.
Для длинных текстов рекомендуем структуру: "вопрос в начале + материалы в середине + повторение вопроса в конце".
Q3: Как активировать режим Thinking?
В протоколе OpenAI это делается через extra_body.reasoning.enabled=true. Параметр effort может принимать значения low / medium / high (по умолчанию medium). На платформе APIYI api.apiyi.com параметры полностью соответствуют официальным.
Q4: Насколько стабилен Function Calling в Flash?
Для одиночных вызовов — очень стабильно (успешность 95%+). Для многошаговых цепочек инструментов (более 5 шагов) рекомендуем использовать Pro — разрыв в 11 баллов в Terminal-Bench 2.0 проявляется именно здесь.
Q5: Какая допустимая нагрузка (конкурентность)?
Для индивидуальных разработчиков 10–20 одновременных запросов — без проблем. Для продакшена рекомендуем:
- По умолчанию: через
api.apiyi.comдо 50 запросов. - Пакетные/ночные задачи: переключайтесь на
vip.apiyi.com, там доступно 200+ запросов. - Экстренные ситуации: временный откат на
b.apiyi.com.
Актуальные лимиты смотрите в разделе квот на docs.apiyi.com.
Q6: Как оценить риски при миграции?
Метод трех шагов:
- Качество вывода: проведите A/B-тестирование на 20–50 типичных промптах, оцените результат вручную или с помощью другой модели.
- Кривая затрат: следите за ежедневным потреблением токенов (у Flash выходных токенов обычно чуть больше, особенно в режиме Thinking).
- Задержка: TTFT (время до первого токена) у Flash близко к V3.5, а в режиме Thinking задержка увеличивается в 2–5 раз.
Если качество падает более чем на 10%, переходите на Pro, в остальных случаях миграция безопасна.
Q7: Как использовать совместимость с протоколом Anthropic?
base_url указывается без /v1, вызывайте напрямую POST /v1/messages. В поле model SDK Anthropic просто укажите deepseek-v4-flash. Это кратчайший путь для миграции проектов, уже использующих Claude SDK, без изменения кода.
Q8: Есть ли скидки на кэширование контекста?
В V4-Flash автоматически включено кэширование контекста (context caching), поэтому запросы с повторяющимися префиксами стоят дешевле. В сценариях с длинными системными промптами можно сэкономить еще 30–50%. На платформе APIYI apiyi.com эта функция включена по умолчанию, дополнительные параметры не нужны.
VI. Итоги запуска deepseek-v4-flash
Релиз DeepSeek V4 несет для разработчиков два важных факта:
- Стало дешевле: V4-Flash предлагает возможности, близкие к Pro, за 1/12 цены. Стоимость $0.14/млн входных токенов — новый отраслевой минимум.
- Сроки поджимают: 24 июля 2026 года старые модели будут официально отключены, 90-дневный льготный период уже начался.
Хорошая новость: deepseek-v4-flash уже доступен на APIYI apiyi.com. Вам не нужно создавать зарубежные аккаунты, менять SDK или беспокоиться об оплате. Три шага:
- ✅ Получите ключ в панели управления
apiyi.com. - ✅ Укажите
base_urlнаapi.apiyi.com/v1(резервные:vip.apiyi.com/b.apiyi.com). - ✅ Установите
modelкакdeepseek-v4-flash, остальной код оставьте без изменений.
🎯 Рекомендация: настоятельно советуем запустить A/B-тестирование deepseek-v4-flash уже сегодня. Создайте выделенный ключ на APIYI apiyi.com, прогоните 20–50 типичных промптов и сравните качество и стоимость с текущей моделью. Если нет значительного проседания, на этой неделе можно переключить 5% трафика, а в течение 4 недель завершить полную миграцию — это гораздо спокойнее, чем спешить в июле. Подробные кейсы миграции и скрипты бенчмарков можно найти в разделе DeepSeek V4 на
docs.apiyi.com.
Ценность deepseek-v4-flash не в том, что это «просто еще одна дешевая модель», а в том, что она делает доступными для всех сценарии, которые раньше были под силу только технологическим гигантам: чтение целых книг в контекстном окне 1М, сложные рассуждения в режиме Thinking, использование Function Calling для полноценной автоматизации — все это теперь стоит копейки. Это открывает новые возможности для продуктов, и те, кто перейдет первым, получат преимущество.
Автор: Техническая команда APIYI
Ресурсы:
- Официальный анонс DeepSeek: api-docs.deepseek.com/news/news260424
- Репозиторий на Hugging Face: huggingface.co/deepseek-ai/DeepSeek-V4-Flash
- Официальный сайт APIYI: apiyi.com
- Документация APIYI: docs.apiyi.com
- Основной шлюз APIYI: api.apiyi.com (резервные: vip.apiyi.com / b.apiyi.com)