On April 24, 2026, DeepSeek simultaneously open-sourced the V4-Pro and V4-Flash models. If Flash is the "good enough for a bargain" sweet spot, then V4-Pro is an entirely different beast:
It is currently the most powerful open-source model for coding.
This isn't just a polite way of saying it's "the best among open-source models"—it's a champion that crushes GPT-5.4, Claude Opus 4.6, and Gemini 3.1-Pro in raw data:
- LiveCodeBench 93.5 — Ranked #1 overall, beating Gemini 3.1-Pro (91.7) and Claude Opus 4.6 (88.8).
- Codeforces Rating 3206 — Surpassing GPT-5.4 (3168) and Gemini 3.1-Pro (3052).
- Apex Shortlist Pass@1 90.2 — A significant lead over GPT-5.4 (78.1) and Claude (85.9).
- IMOAnswerBench 89.8 — Outperforming Claude Opus 4.6 (75.3) by a full 14 points on math competition problems.
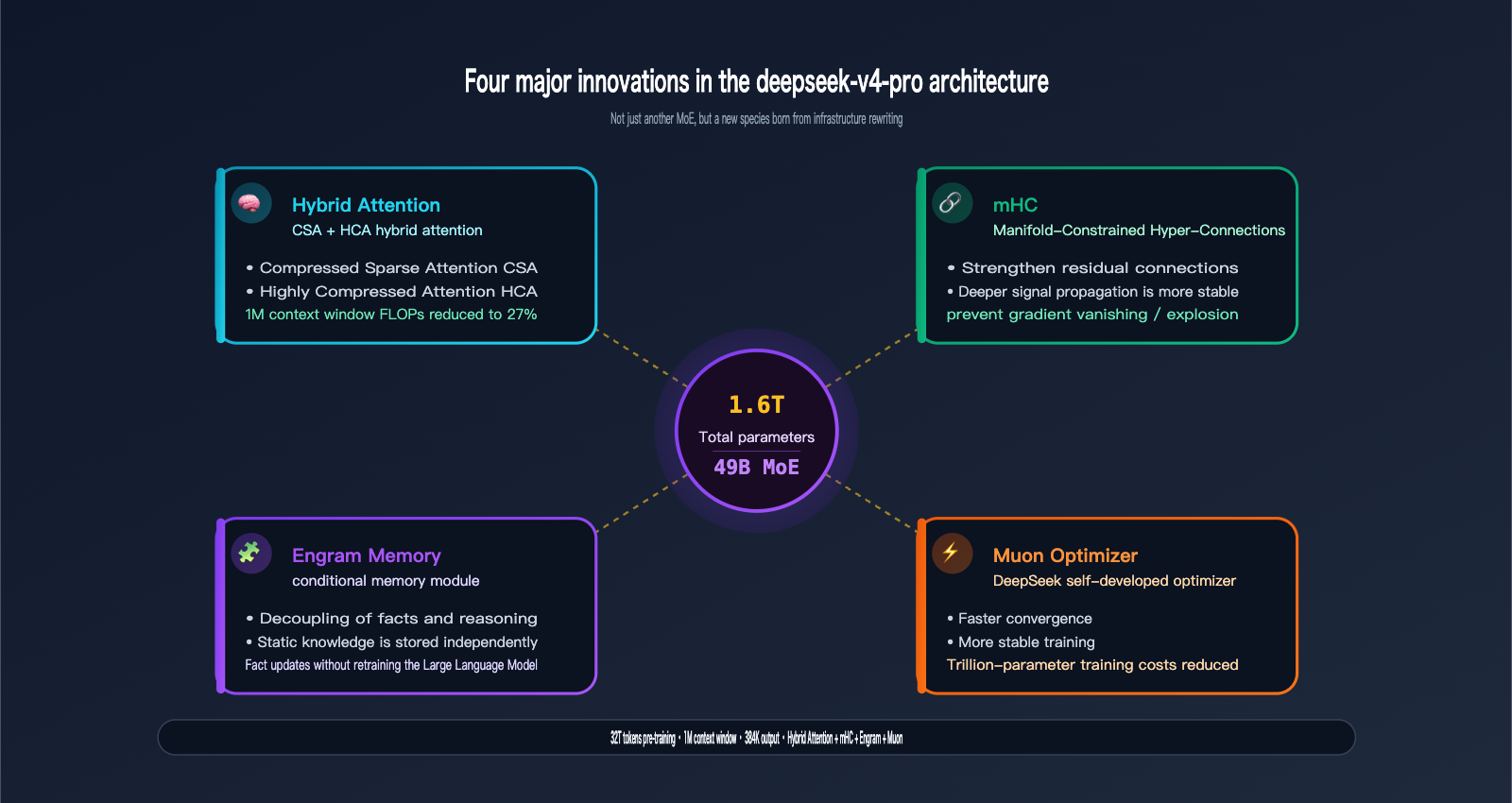
The specs are impressive: 1.6T total parameters / 49B active / 32T tokens pre-trained / 1M context window / 384K output, combined with four major architectural innovations specifically designed for the V4 series: Hybrid Attention, Manifold-Constrained Hyper-Connections (mHC), Engram Conditional Memory, and the Muon Optimizer.
deepseek-v4-pro is now available on APIYI (apiyi.com). You can integrate it with zero code changes using OpenAI or Anthropic SDKs, at just 1/7th the price of GPT-5.4.
This article won't repeat the basics of "how to migrate" or "how to choose a budget model"—we covered that in the Flash guide. This is a deep dive for the technical believers of deepseek-v4-pro:
- 3 minutes to understand why Pro earns the "flagship" title (Architecture + Data + Scale).
- 4 Benchmark comparison tables to see exactly where Pro wins and where it loses.
- 5 minutes to integrate + 2 real-world coding/math scenario walkthroughs.
I. The Four Flagship Capabilities of deepseek-v4-pro
1.1 Core Specifications at a Glance
| Dimension | deepseek-v4-pro |
|---|---|
| Release Date | 2026-04-24 (Preview) |
| Open Source Repo | huggingface.co/deepseek-ai/DeepSeek-V4-Pro |
| Total Parameters | 1.6T (Mixture of Experts) |
| Active Parameters | 49B |
| Pre-training Data | > 32T tokens |
| Context Window | 1M tokens |
| Max Output | 384K tokens |
| Architectural Innovation | Hybrid Attention + mHC + Engram Memory + Muon |
| Inference Mode | Thinking / Non-Thinking dual modes |
| Function Calling | ✅ Supported |
| JSON Mode | ✅ Supported |
| API Protocol | Dual-compatible (OpenAI + Anthropic) |
| Input Price | $1.74 / M tokens |
| Output Price | $3.48 / M tokens |
Remember these four core numbers: 1.6T / 49B / 32T / 1M—this is the foundation of its flagship status.
1.2 1.6T / 49B MoE: The "Open Source Ceiling" in Scale
DeepSeek-V4-Pro features 1.6 trillion total parameters using a Mixture of Experts architecture, activating only 49B parameters per token. Here’s what these numbers mean:
| Model | Total Params | Active Params | Type |
|---|---|---|---|
| Llama 3 70B | 70B | 70B | Dense |
| Mistral Large 2 | 123B | 123B | Dense |
| DeepSeek-V3.2 | 671B | 37B | MoE |
| DeepSeek-V4-Pro | 1.6T | 49B | MoE ⭐ |
| Claude Opus 4.6 | Undisclosed | Undisclosed | Closed Source |
The 1.6T total parameters give the model a knowledge base approaching GPT-5.4 / Claude Opus levels, while the 49B active parameters keep the per-token inference cost manageable—this is the secret sauce behind why the MoE architecture achieves such cutting-edge performance.
1.3 32T Tokens Pre-training: Maximizing Data Volume
Pre-training data > 32T tokens
This is a staggering number:
- GPT-4 pre-training data is estimated at ~13T tokens
- Llama 3: 15T tokens
- DeepSeek-V3: 14.8T tokens
- DeepSeek-V4-Pro: >32T tokens ⭐
The direct benefit of doubling the data volume is: more comprehensive long-tail knowledge, more up-to-date code corpora, and deeper mathematical problem sets—which is why V4-Pro is dominating the leaderboards on LiveCodeBench and IMOAnswerBench.
1.4 Four Architectural Innovations: The True Moat of Pro
This is what separates V4-Pro from "just another MoE model." The four core innovations disclosed by the team:
| Innovation | Full Name | Problem Solved |
|---|---|---|
| Hybrid Attention | CSA + HCA Mixed Attention | FLOPs and VRAM issues in long context (1M) inference |
| mHC | Manifold-Constrained Hyper-Connections | Stability of deep residual connections, preventing gradient vanishing/explosion |
| Engram | Engram Conditional Memory | Decoupling "static facts" from "reasoning ability" for cheaper fact updates |
| Muon | Muon Optimizer | Training convergence speed and stability, reducing training costs |
Each one is worth a closer look:
-
Hybrid Attention (CSA + HCA): Traditional Transformer attention has O(n²) complexity, which explodes at 1M context. V4 uses Compressed Sparse Attention (CSA) for coarse-grained filtering and Highly Compressed Attention (HCA) for fine-grained focus. Combined, they slash FLOPs to 27% of V3.2 and KV cache to just 10%. This is how deepseek-v4-pro makes a 1M context window "actually usable."
-
mHC (Manifold-Constrained Hyper-Connections): In deep MoE model training, signals in residual connections often distort after dozens of layers. mHC adds constraints in the manifold space to keep signal propagation stable. In practical terms: the model can be trained deeper and longer without collapsing.
-
Engram Conditional Memory: A highly engineering-focused innovation. It decouples "facts in memory" from "reasoning ability"—facts are stored in a dedicated memory module, while reasoning chains follow a different path. The result is that when world knowledge needs updating, you don't need to retrain the entire model, which will significantly lower the cost of future Pro version releases.
-
Muon Optimizer: A proprietary optimizer developed by DeepSeek. Compared to AdamW, it converges faster and is more stable. At a trillion-parameter scale, this means more thorough training for the same amount of compute.
🎯 Technical Insight: deepseek-v4-pro isn't just a scaled-up version of an old architecture; it's a complete rewrite of the infrastructure. This is why it can reach the level of closed-source giants while remaining open source. If you plan to use it extensively, we recommend running a set of typical business prompts via APIYI (apiyi.com) to experience the difference brought by this architectural upgrade—especially in long-context and multi-step reasoning scenarios.
1.5 1M Context + 384K Output: A Watershed for Long-Form Generation
Pro and Flash share the same context specs: 1M tokens input and 384K tokens output. However, Pro's advantage isn't just "how much it can read," but "how deeply it can think within that 1M."
Practical implications for long-form scenarios:
| Task | V3.2 Era | V4-Pro Era |
|---|---|---|
| Editing a 500k-word manuscript | Required 10+ chunks | 1M window handles it all at once |
| 200-page technical doc Q&A | Required RAG construction | Feed it directly |
| Mid-sized code repo audit | Summary-based analysis | Cross-file consistency checking |
| Novel writing coherence | Manual memory management | 384K output in one go |
II. The Benchmark Throne of deepseek-v4-pro
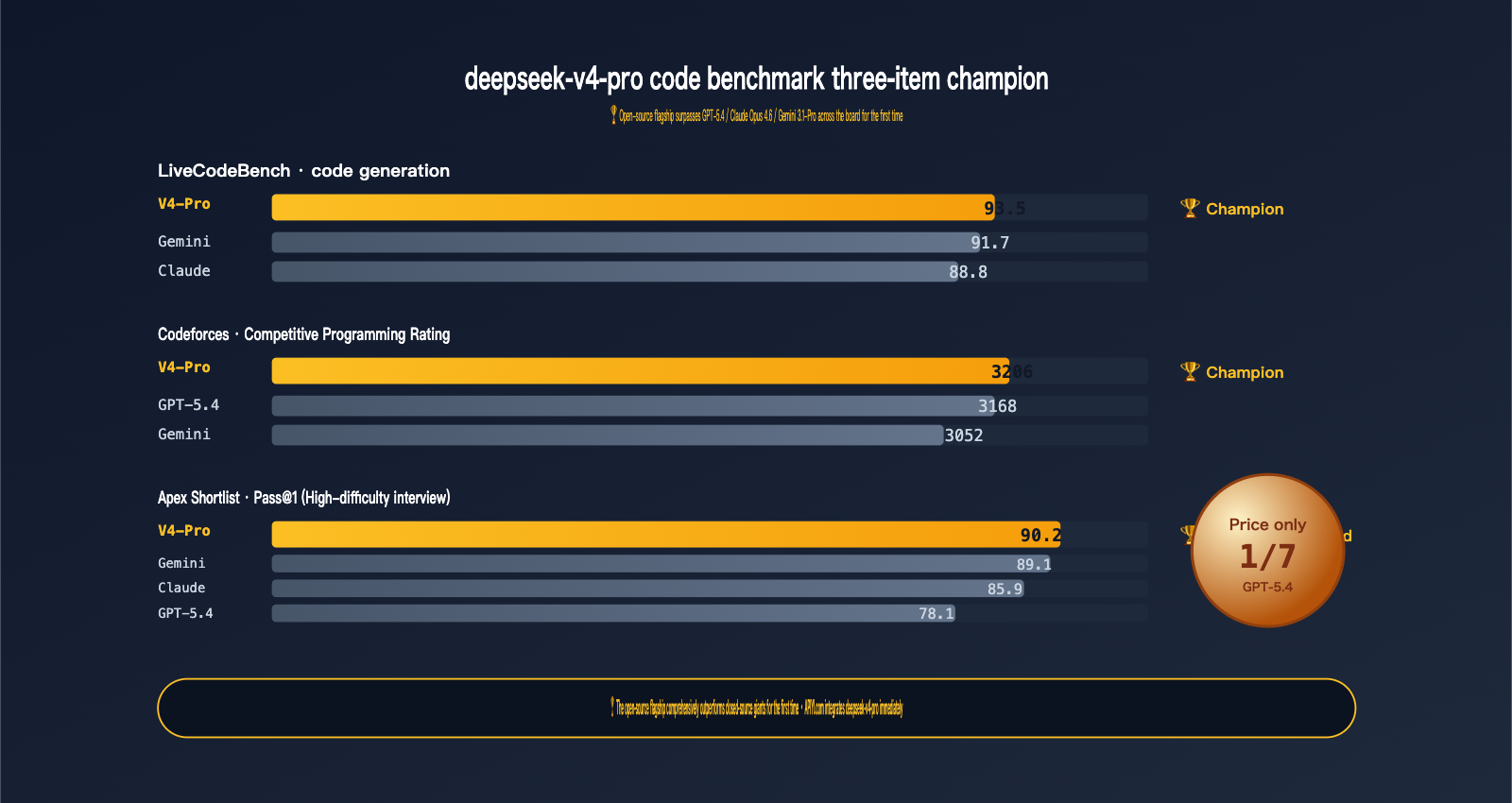
2.1 Coding Ability: deepseek-v4-pro Sweeps the Leaderboards
Let's look at the hard data—coding ability:
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro | Winner |
|---|---|---|---|---|---|
| LiveCodeBench | 93.5 | — | 88.8 | 91.7 | V4-Pro 🏆 |
| Codeforces Rating | 3206 | 3168 | — | 3052 | V4-Pro 🏆 |
| Apex Shortlist Pass@1 | 90.2 | 78.1 | 85.9 | 89.1 | V4-Pro 🏆 |
| SWE-bench Verified | 80.6–82.1 | — | 80.8 | 80.6 | Tied |
| Terminal-Bench 2.0 | 67.9 | 75.1 | 65.4 | 68.5 | GPT-5.4 |
Leading in three, tied or slightly behind in two. This is the first time an open-source model has comprehensively suppressed closed-source flagships in coding ability—a landmark event for 2026.
Breakdown:
- LiveCodeBench 93.5: LiveCodeBench updates problems monthly to avoid training set contamination. V4-Pro's 93.5 score indicates its coding ability is generalized and capable of solving new problems, not just memorizing a database.
- Codeforces 3206: Competitive programming rating; 3206 is near IGM (International Grandmaster) level. This score makes it overkill for daily business coding tasks.
- Apex Shortlist Pass@1 90.2 vs GPT-5.4 78.1: This gap is systemic. Apex Shortlist is a collection of high-difficulty interview questions, and V4-Pro leads by a full 12 percentage points.
- Terminal-Bench 2.0 (Slightly weaker): This measures multi-step command-line tool usage. GPT-5.4 still leads here, suggesting GPT-5.4 has a moat in "complex multi-step Agent" scenarios.
2.2 Math and Reasoning: deepseek-v4-pro Approaches the Frontier
In mathematics, Pro and the closed-source giants are "neck and neck," rather than a total blowout:
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro |
|---|---|---|---|---|
| MMLU-Pro | 87.5 | 87.5 | 89.1 | 91.0 |
| IMOAnswerBench | 89.8 | 91.4 | 75.3 | 81.0 |
| HMMT 2026 | 95.2 | 97.7 | 96.2 | — |
| MATH | 92% | — | — | — |
| HumanEval | 90% | — | — | — |
| MMLU | 89% | — | — | — |
The highlight is IMOAnswerBench: The International Mathematical Olympiad problem set. V4-Pro's 89.8 score leads Claude Opus 4.6 by a full 14.5 points and Gemini 3.1-Pro by 8.8 points. For high-level tasks like mathematical reasoning and formal proofs, Pro is currently the ceiling for open-source models.
The weakness is MMLU-Pro general knowledge: Pro's 87.5 is on par with GPT-5.4, but trails Gemini 3.1-Pro's 91.0 by 3.5 points. Gemini still holds an advantage in general knowledge Q&A.
2.3 Battlefield Distribution: Where deepseek-v4-pro Wins and Loses
| Battlefield | Champion | V4-Pro Position |
|---|---|---|
| Code Generation (LiveCodeBench) | V4-Pro 🏆 | Champion |
| Competitive Programming (Codeforces) | V4-Pro 🏆 | Champion |
| High-Difficulty Interviews (Apex) | V4-Pro 🏆 | Champion (Significant lead) |
| Software Engineering (SWE-bench) | Tied | Tied for 1st |
| Math Olympiad (IMO) | GPT-5.4 | 2nd (Far ahead of Claude/Gemini) |
| General Knowledge (MMLU-Pro) | Gemini 3.1-Pro | 3rd |
| Multi-step Toolchain (Terminal-Bench) | GPT-5.4 | 2nd |
| Consistency Reasoning (HMMT) | GPT-5.4 | 3rd |
Conclusion: If your workload is primarily code-based, deepseek-v4-pro is currently one of the most powerful choices on Earth (including both open and closed source). If you focus on multi-step Agent toolchains, GPT-5.4 still holds a slight edge; if you focus on general knowledge Q&A, Gemini 3.1-Pro is stronger.
🎯 Selection Advice: We recommend running a set of V4-Pro vs. existing model AB tests (20–50 samples is enough) on APIYI (apiyi.com) using your own business-typical prompts. Don't rely solely on public benchmarks to make your selection—your own prompt distribution is the only real benchmark. For batch AB testing, we suggest using the
vip.apiyi.comhigh-concurrency line.
3. Calling deepseek-v4-pro on APIYI (apiyi.com) in 5 Minutes
3.1 Step 1: Get Your Key and Choose a Route
Prerequisites: Python 3.8+ or Node.js 18+, and either the official OpenAI SDK or Anthropic SDK.
Get your Key:
- Visit APIYI at
apiyi.com, go to Console → API Keys → Create New Key. - It's recommended to set a daily limit for your Pro key (¥200–500, depending on your business scale).
- Copy the key starting with
sk-.
Choose a route (all three routes share the same key):
| base_url | Best for |
|---|---|
https://api.apiyi.com/v1 |
Daily calls, interactive scenarios |
https://vip.apiyi.com/v1 |
Batch tasks, high concurrency |
https://b.apiyi.com/v1 |
Backup if the main site is unstable |
3.2 Step 2: Minimal Python Invocation (Non-Thinking)
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "You are a senior Python engineer."},
{"role": "user", "content": "Write a production-ready LRU cache in 30 lines."},
],
max_tokens=2048,
)
print(resp.choices[0].message.content)
Change only two things: base_url and model — the rest of your OpenAI SDK code remains untouched.
3.3 Step 3: Enable Thinking Mode (The Pro Advantage)
The true value of deepseek-v4-pro is fully unlocked in Thinking mode. Benchmarks like IMOAnswerBench (89.8) and LiveCodeBench (93.5) were all measured using this mode.
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": """
Please implement a concurrency-safe token bucket rate limiter, requiring:
1. Support for dynamic rate adjustment
2. Support for burst traffic reservation
3. Lock-free implementation (CAS or atomic operations)
4. Include complete unit tests
"""},
],
extra_body={
"reasoning": {"enabled": True, "effort": "high"},
},
max_tokens=16384,
)
print("--- Reasoning Process ---")
print(resp.choices[0].message.reasoning_content)
print("\n--- Final Answer ---")
print(resp.choices[0].message.content)
With effort=high, the Pro model performs deep planning—you'll see it analyze requirements, design the API, discuss various implementation strategies, and finally provide the code. This is why deepseek-v4-pro is worth the price difference over the Flash version.
3.4 Step 4: Real-world Code Debugging
A common business scenario: having Pro fix a bug.
buggy_code = """
def find_kth_largest(nums, k):
nums.sort()
return nums[k] # BUG here
"""
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "You are a senior code reviewer. Identify bugs, explain root cause, and give fixed code."},
{"role": "user", "content": f"Review this code:\n```python\n{buggy_code}\n```"},
],
extra_body={"reasoning": {"enabled": True}},
max_tokens=4096,
)
print(resp.choices[0].message.content)
Pro will point out that the index should be -k (after sorting, the k-th largest is at the k-th position from the end) and provide the fix along with edge case handling (k <= 0, k > len(nums)) and test cases.
The 80%+ SWE-bench score really shows in this kind of scenario.
3.5 Step 5: Function Calling / Tool Use
Pro is highly stable for single-step tool calls. While its multi-step tool chaining is slightly behind GPT-5.4, it leads over Claude:
tools = [
{
"type": "function",
"function": {
"name": "run_sql",
"description": "Execute a read-only SQL query on the analytics DB.",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "SELECT-only SQL"},
},
"required": ["query"],
},
},
},
]
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": "What are the top 5 cities by DAU in the last 30 days?"},
],
tools=tools,
tool_choice="auto",
)
print(resp.choices[0].message.tool_calls)
3.6 Step 6: Anthropic Protocol (Connecting Claude Code to Pro)
This is the most underrated value of deepseek-v4-pro: you can swap the underlying model of any existing Claude SDK or Claude Code project to V4-Pro without changing any business logic.
from anthropic import Anthropic
client = Anthropic(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com", # Note: no /v1 here
)
resp = client.messages.create(
model="deepseek-v4-pro",
max_tokens=4096,
messages=[
{"role": "user", "content": "Refactor this Python code to async/await style..."},
],
)
print(resp.content[0].text)
Claude Code Terminal: In your configuration, set ANTHROPIC_BASE_URL=https://api.apiyi.com, ANTHROPIC_API_KEY=sk-..., and change the model to deepseek-v4-pro. You'll instantly have a terminal Agent with superior coding capabilities.
3.7 Step 7: Connecting deepseek-v4-pro in Cursor
In Cursor, go to Settings → Models → Custom OpenAI-Compatible:
- Base URL:
https://api.apiyi.com/v1 - API Key:
sk-... - Model Name:
deepseek-v4-pro
Once done, Cursor's Chat, Cmd+K, and Composer will all use V4-Pro, significantly improving the quality of code completion and refactoring.
🎯 IDE Integration Tip: Mainstream AI programming tools like Cursor, Windsurf, Cline, and Continue are all compatible with the OpenAI protocol. Simply point the
base_urlto APIYI'sapi.apiyi.com/v1and change the model todeepseek-v4-profor a seamless migration. Detailed IDE configuration examples can be found in the DeepSeek V4 section of the official APIYI documentation atdocs.apiyi.com.
4. When to Choose deepseek-v4-pro (and When Not To)
4.1 Decision Criteria for Choosing Pro
✅ Choose deepseek-v4-pro for these scenarios:
| Scenario | Why |
|---|---|
| Code generation, refactoring, review | LiveCodeBench 93.5 (overall champion) |
| Competitive programming, algorithm training | Codeforces 3206 (equivalent to IGM level) |
| Batch interview question answering | Apex Shortlist 90.2 (significant lead) |
| Mathematical reasoning, formal proofs | IMOAnswerBench 89.8 (leads Claude by 14 points) |
| Large codebase understanding | 1M context window + 49B active parameters |
| Long-form writing and editing | 384K output in one go |
| Local deployment / fine-tuning | Open weights + Engram module for easy fine-tuning |
| Replacing underlying model for Cursor / Claude Code | Zero-modification access via Anthropic protocol |
4.2 When Not to Choose Pro
❌ Don't waste Pro's compute on these scenarios:
| Scenario | Recommendation |
|---|---|
| Daily chat, FAQ | Use Flash (12x cheaper) |
| Short text classification, extraction | Use Flash or a smaller model |
| Multi-step complex Agent tool chains | Prioritize GPT-5.4 (leads in Terminal-Bench) |
| General knowledge Q&A | Gemini 3.1-Pro is stronger |
| Latency-sensitive online interaction | Use Flash (Non-Thinking mode) or add caching |
4.3 Hybrid Routing Suggestion
The optimal solution for production environments is usually layered routing:
def pick_model(request_type: str, complexity: str) -> str:
# Heavy coding tasks → Pro
if request_type in ("code_gen", "code_review", "refactor") and complexity == "hard":
return "deepseek-v4-pro"
# Mathematical reasoning → Pro
if request_type in ("math_proof", "competitive_programming"):
return "deepseek-v4-pro"
# Deep long-document understanding → Pro
if request_type == "long_doc_analysis":
return "deepseek-v4-pro"
# Other daily tasks → Flash
return "deepseek-v4-flash"
On APIYI (apiyi.com), these two models share the same key; switching only requires changing the model field, with no other configuration changes needed.
V. deepseek-v4-pro FAQ
Q1: Why is the Pro's coding capability so strong?
It's a combination of three factors:
- 32T tokens of pre-training data, which includes a vast amount of high-quality code.
- 1.6T MoE / 49B active parameters, allowing the model to store and retrieve deep coding knowledge effectively.
- Thinking mode + Engram Memory, which decouples "memorizing coding paradigms" from "reasoning through new code."
None of these alone could achieve these results; it's the combination that led to a 93.5 score on LiveCodeBench.
Q2: Won't 1.6T parameters make it slow to respond?
The response speed for a single request is determined by the active parameters, not the total count. Pro only activates 49B parameters per token. Combined with Hybrid Attention's FLOPs optimization, the time-to-first-token latency is close to Flash. Thinking mode is slower (because it outputs the reasoning process), but that's a design trade-off—you're trading time for reasoning quality.
Q3: Is Thinking mode mandatory?
Not at all. You can turn it off for casual chats, simple code, or daily Q&A. However, most of the value you're paying for with Pro lies in Thinking mode—so for complex code, math problems, and multi-step logical reasoning, be sure to enable reasoning.enabled=true + effort=high.
Q4: How do I use it in Cursor / Claude Code?
- Cursor: Settings → Models → Custom OpenAI-Compatible. Set Base URL to
https://api.apiyi.com/v1and Model todeepseek-v4-pro. - Claude Code: Set environment variables
ANTHROPIC_BASE_URL=https://api.apiyi.comandANTHROPIC_API_KEY=sk-..., then specifydeepseek-v4-proas the model when starting.
You can find specific screenshots and steps in the IDE integration section at docs.apiyi.com.
Q5: Which is more worth it, this or GPT-5.4?
If you have to choose one:
- Daily coding / Competitions / Math / Cost-sensitive tasks → deepseek-v4-pro (Coding champion, 1/7th the price).
- Multi-step toolchain Agents / General knowledge Q&A → GPT-5.4.
- Mixing both is the optimal solution (use one API key from APIYI apiyi.com to switch between models).
Q6: Can I deploy it locally?
Yes, the full weights for V4-Pro are open-sourced on Hugging Face (deepseek-ai/DeepSeek-V4-Pro). However, self-deployment requires:
- A single machine with ≥ 8×H200 or equivalent GPUs.
- Extra KV cache for 1M context (though Pro has already compressed the cache to 10% of V3.2).
- Engineering costs to maintain the inference service.
Cost analysis: Unless your monthly usage exceeds 50 billion tokens, managed calls via APIYI apiyi.com are more economical than self-deployment.
Q7: What is the concurrent request limit?
For production environments, we recommend:
- Main site
api.apiyi.com: 50 concurrent requests safe. - High-concurrency route
vip.apiyi.com: 200+ concurrent requests. - Backup
b.apiyi.com: Automatic fallback if the main route jitters.
Pro has higher latency for complex Thinking tasks, so higher concurrency isn't always better—it's better to estimate your required concurrency window based on QPS × average response time.
Q8: Will a stable version be released soon?
The version released on 2026-04-24 is a Preview. Following DeepSeek's historical cadence, the stable version usually arrives 1–2 months after the preview, potentially with minor benchmark improvements. It's perfectly fine to use the preview version on APIYI apiyi.com now—the model ID will likely remain deepseek-v4-pro for backward compatibility.
VI. deepseek-v4-pro Launch Summary
If you skipped to the end, here's the bottom line:
- ✅ deepseek-v4-pro is currently the most powerful open-source model for coding—it beats GPT-5.4 / Claude Opus 4.6 / Gemini 3.1-Pro across three hard-core benchmarks: LiveCodeBench, Codeforces, and Apex.
- ✅ Four major architectural innovations (Hybrid Attention / mHC / Engram Memory / Muon) make it not just "another large language model," but a new species built on rewritten infrastructure.
- ✅ 1.6T / 49B MoE + 32T tokens of pre-training + 1M context reaches the ceiling of open-source scale.
- ✅ Now available on APIYI apiyi.com, compatible with both OpenAI and Anthropic protocols, allowing zero-modification integration for Cursor, Claude Code, Cline, and other mainstream tools.
- ✅ Priced at only 1/7th of GPT-5.4, with Thinking mode being its true highlight.
For development teams focused on coding, deepseek-v4-pro is worth testing immediately—it's not just a "slightly cheaper alternative," but a flagship model that might become the new default.
🎯 Action Plan: We recommend applying for an API key from APIYI
apiyi.comtoday (dedicated to Pro, with a daily limit of ¥200–500). Run 20 prompts that best represent your business—code, math, or long-form text—and perform an AB test between V4-Pro (Thinking mode) and your current primary model. If the quality of your coding tasks improves significantly, switch your default model in Cursor / Claude Code. If you need a cheaper model for daily tasks, add V4-Flash (see our previous migration guide). Usevip.apiyi.comfor batch testing andb.apiyi.comas an automatic fallback if the main site jitters. Full integration examples, IDE configurations, and benchmark reproduction scripts can be found atdocs.apiyi.com.
The significance of deepseek-v4-pro goes beyond being "another cheap SOTA model." It marks the first time an open-source model has fully suppressed closed-source flagships in core coding capabilities—a milestone that every team serious about AI engineering should test for themselves.
Author: APIYI Technical Team
Resources:
- DeepSeek Official Announcement: api-docs.deepseek.com/news/news260424
- Hugging Face Repository: huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- APIYI Official Website: apiyi.com
- APIYI Documentation: docs.apiyi.com
- APIYI Main Site: api.apiyi.com (Backup: vip.apiyi.com / b.apiyi.com)