Am 24.04.2026 hat DeepSeek auf Hugging Face gleichzeitig die beiden Vorschaumodelle V4-Pro und V4-Flash veröffentlicht. Ersteres ist ein 1,6T-Parameter-MoE-Gigant für Spitzenleistung, Letzteres ein Preis-Leistungs-Sieger, der „90 % der Pro-Leistung bei nur 1/12 des Preises“ bietet.
Wenn Sie sich nur ein Modell ansehen, dann deepseek-v4-flash. Die Gründe sind einfach:
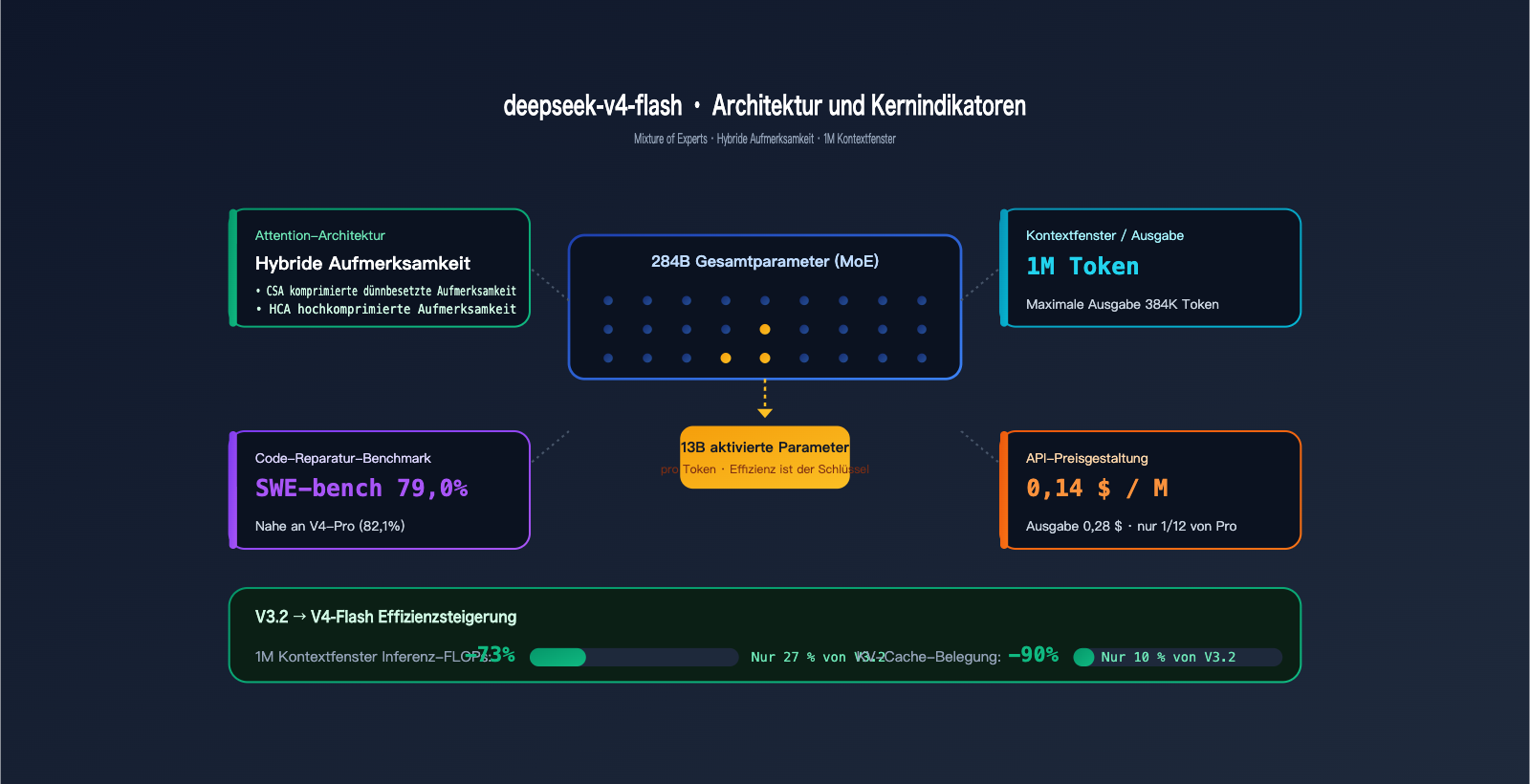
- 284B / 13B MoE-Architektur + Hybrid Attention: Bei 1 Mio. Kontextfenster betragen die Inferenz-FLOPs nur 27 % im Vergleich zu V3.2.
- 1 Mio. Tokens Kontext / 384K Tokens maximale Ausgabe: Natives Arbeiten mit langen Texten ohne Chunking.
- $0,14 für Eingabe / $0,28 für Ausgabe pro Million Tokens: Eine Größenordnung günstiger als die Pro-Version.
- SWE-bench Verified 79,0 %, Artificial Analysis Intelligence Index 45–47: Ausreichend für die meisten Anwendungsszenarien.
- Kompatibel mit OpenAI ChatCompletions und Anthropic API: Claude Code / OpenClaw / OpenCode sind ohne Anpassungen nutzbar.
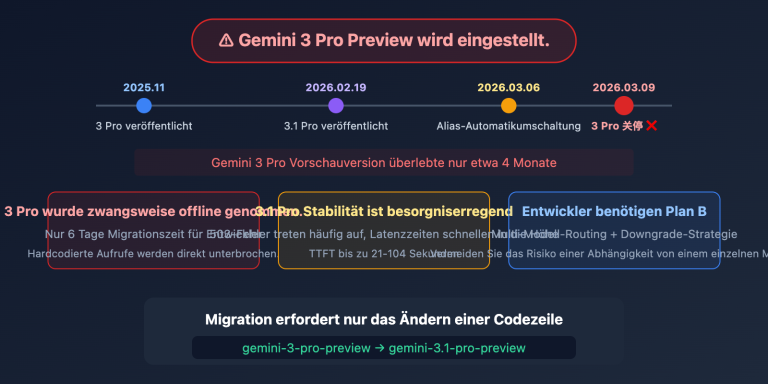
Ein wichtiger Hinweis: Die alten Modelle deepseek-chat und deepseek-reasoner werden am 24.07.2026 offiziell eingestellt. Alle Online-Dienste müssen bis dahin migriert sein. Das ist eine harte Frist mit einem 90-Tage-Countdown.
Die gute Nachricht: deepseek-v4-flash ist bereits auf APIYI (apiyi.com) verfügbar. Sie benötigen kein eigenes DeepSeek-Konto, müssen kein SDK ändern und sich nicht um Auslandszahlungen kümmern – ändern Sie einfach das Feld model und setzen Sie die base_url auf api.apiyi.com.
Dieser Artikel ist eine 3+5-Kombination: 3 Minuten, um die wichtigsten Upgrades von V4-Flash zu verstehen + 5 Minuten für die vollständige Migration von alten Modellen.
I. Die 5 wichtigsten Upgrades von deepseek-v4-flash
1.1 Spezifikationen im Überblick
Hier der Überblick, bevor wir ins Detail gehen:
| Dimension | deepseek-v4-flash |
|---|---|
| Veröffentlichungsdatum | 24.04.2026 (Vorschau) |
| Open-Source-Repository | huggingface.co/deepseek-ai/DeepSeek-V4-Flash |
| Gesamtparameter | 284B (Mixture of Experts) |
| Aktive Parameter | 13B |
| Kontextfenster | 1 Mio. Tokens |
| Maximale Ausgabe | 384K Tokens |
| Attention-Architektur | Hybrid Attention (CSA + HCA) |
| Inferenz-Modus | Thinking / Non-Thinking Dual-Modus |
| Function Calling | ✅ Unterstützt |
| JSON-Modus | ✅ Unterstützt |
| Chat Prefix Completion | Beta-Unterstützung |
| API-Protokoll | OpenAI ChatCompletions + Anthropic Dual-Kompatibilität |
| Eingabepreis | $0,14 / M Tokens |
| Ausgabepreis | $0,28 / M Tokens |
1.2 Upgrade 1: 1 Mio. Kontext + 384K Ausgabe (Nativ ultra-lang)
deepseek-v4-flash unterstützt nativ 1 Mio. Tokens Eingabe und 384K Tokens Ausgabe. Dies ist der Standard für die gesamte V4-Serie; Flash hat beim Kontext keine Abstriche gemacht.
Welche Szenarien passen in 1 Mio. Tokens?
| Inhaltstyp | Ungefähre Token-Anzahl |
|---|---|
| 100.000 chinesische Schriftzeichen | ≈ 150K Tokens |
| 200 Seiten technisches PDF | ≈ 300K Tokens |
| Ein mittelgroßes Code-Repository (~50 Dateien) | ≈ 500K–800K Tokens |
| Der gesamte Roman „Der Traum der Roten Kammer“ | ≈ 1 Mio. Tokens |
Im Vergleich zu GPT-5.4 (400K), Claude Opus 4.6 (1M + 1M Kontextpaket) und Gemini 3.1-Pro (2M) ist das 1-Mio.-Kontextfenster von V4-Flash bereits Branchenstandard, wobei es 5–20 Mal günstiger ist als die genannten Konkurrenten.
1.3 Upgrade 2: 284B/13B MoE + Hybrid Attention
V4-Flash nutzt zwei wichtige Architektur-Innovationen, die DeepSeek 2026 eingeführt hat:
- MoE: 284B Gesamtparameter, nur 13B pro Token aktiv. Die Leistung entspricht einem 13B-Modell, aber das Wissen ist vergleichbar mit einem 200B+-Modell.
- Hybrid Attention (CSA Compressed Sparse Attention + HCA Highly Compressed Attention): Speziell für lange Kontexte entwickelt.
Effizienz-Messdaten (von DeepSeek offiziell):
| Metrik | V3.2 | V4-Flash | Verbesserung |
|---|---|---|---|
| Inferenz-FLOPs pro Token bei 1M Kontext | 100 % | 27 % | -73 % |
| KV-Cache-Auslastung bei 1M Kontext | 100 % | 10 % | -90 % |
Diese Zahlen erklären, warum Flash den Preis auf $0,14 drücken konnte: Die zugrunde liegenden Rechenkosten sind tatsächlich gesunken, es handelt sich nicht um eine reine Subvention.
1.4 Upgrade 3: Thinking / Non-Thinking Dual-Modus
V4-Flash bietet zwei Modi über eine einzige Modell-ID:
- Non-Thinking (Standard): Schnell, geeignet für Chats, Fragen, Klassifizierungen und Zusammenfassungen.
- Thinking: Das Modell gibt zuerst eine interne Schlussfolgerung aus (ähnlich der OpenAI o-Serie) und liefert dann die endgültige Antwort. Ideal für komplexe Schlussfolgerungen, mehrstufige Tool-Aufrufe und Code-Debugging.
Der Wechsel erfolgt über Anfrageparameter (keine zwei Modell-IDs), was den Aufwand für Entwickler minimal hält. Bei einem Modellaufruf über APIYI api.apiyi.com sind diese Parameternamen identisch mit denen von DeepSeek.
1.5 Upgrade 4: $0,14 / $0,28 pro M Tokens
Dies ist die beeindruckendste Zahl dieser Veröffentlichung:
| Modell | Eingabe ($/M) | Ausgabe ($/M) | Relativ zu V4-Flash |
|---|---|---|---|
| deepseek-v4-flash | 0,14 | 0,28 | 1× (Basis) |
| deepseek-v4-pro | 1,74 | 3,48 | 12× |
| GPT-5.4 (Ref.) | 2,50 | 10,00 | 17×–35× |
| Claude Sonnet 4.6 (Ref.) | 3,00 | 15,00 | 21×–53× |
Eine typische Anfrage mit "500 Tokens Eingabe + 500 Tokens Ausgabe":
- V4-Flash: $0,000 21
- GPT-5.4: $0,006 25
- Claude Sonnet 4.6: $0,009
Flash ist 30–40 Mal günstiger. Für Produkte mit monatlich hunderten Millionen Tokens ist dies direkt entscheidend für die Bruttomarge.
1.6 Upgrade 5: OpenAI + Anthropic Dual-Protokoll-Kompatibilität
V4-Flash implementiert auf API-Ebene zwei Protokolle gleichzeitig:
POST /v1/chat/completions→ OpenAI-FormatPOST /v1/messages→ Anthropic-Format
Das bedeutet:
| Client | Migrationsaufwand |
|---|---|
| OpenAI Python/Node SDK | Keine Änderung, nur base_url und model anpassen |
| Anthropic Python/Node SDK | Keine Änderung, nur base_url und model anpassen |
| Claude Code | Einfach den Anthropic-Endpunkt tauschen |
| OpenClaw / OpenCode | Nativ unterstützt |
| LangChain / LlamaIndex | Einfach base_url tauschen |
Dies ist eine sehr kluge Entscheidung von DeepSeek: Sie zwingen niemanden, neue Protokolle zu lernen, und ermöglichen eine Migration des bestehenden Ökosystems ohne Kosten.
1.7 Benchmark-Vergleichstabelle
| Benchmark | V4-Flash | V4-Pro | Differenz |
|---|---|---|---|
| SWE-bench Verified (Code-Reparatur) | 79,0 % | 82,1 % | -3,1 |
| Terminal-Bench 2.0 (Mehrstufige Tools) | 56,9 % | 67,9 % | -11,0 |
| SimpleQA-Verified (Faktenabruf) | 34,1 % | 57,9 % | -23,8 |
| Artificial Analysis Intelligence Index | 45 / 47 | 58 | -11 ~ -13 |
Interpretation: Flash zieht bei einstufigen Code-Aufgaben (SWE-bench) fast mit Pro gleich, zeigt aber bei mehrstufigen Tool-Ketten (Terminal-Bench) und Faktengedächtnis (SimpleQA) deutliche Unterschiede. Genau diese Unterschiede sind die Entscheidungsgrundlage für die Wahl zwischen Flash und Pro.
2. DeepSeek-V4-Flash vs. V4-Pro: Entscheidungshilfe für Anwendungsfälle
2.1 Entscheidungsmatrix: Der schnelle Überblick
| Szenario | Empfehlung | Grund |
|---|---|---|
| Alltagsgespräche, Chat, Q&A | Flash | Leistung absolut ausreichend, 1/12 der Kosten |
| Chatbots, FAQ-Systeme | Flash | Hoher Durchsatz, niedrige Latenz |
| Code-Vervollständigung, Datei-Änderungen | Flash | SWE-bench 79 %, nahe am Pro-Modell |
| Zusammenfassung langer Dokumente | Flash | Volles 1M-Kontextfenster verfügbar |
| Multi-Step-Agenten | Pro | Terminal-Bench liegt 11 Punkte zurück |
| Tiefgehende Recherche, mehrstufige Prüfung | Pro | SimpleQA liegt 24 Punkte zurück |
| Erstellung hochwertiger Geschäftsberichte | Pro | Intelligence Index um 11+ höher |
| F&E / Explorative Experimente | Flash | 12x günstiger, schnellere Iteration |
Allgemeine Regel: Standardmäßig Flash verwenden, erst bei Engpässen auf Pro upgraden. Dies entspricht dem bewährten Prinzip bei der Technologieauswahl: "Erst einfache Lösungen nutzen, bei Bedarf skalieren."
2.2 Wirtschaftlichkeitsrechnung: Wann lohnt sich Flash besonders?
Angenommen, Ihr Produkt verbraucht täglich 100 Millionen Tokens (60 Mio. Input + 40 Mio. Output):
| Modell | Tageskosten | Monatskosten | Jahreskosten |
|---|---|---|---|
| V4-Flash | 19,6 $ | 588 $ | 7.056 $ |
| V4-Pro | 243,6 $ | 7.308 $ | 87.696 $ |
| GPT-5.4 (Ref.) | 550 $ | 16.500 $ | 198.000 $ |
Flash spart jährlich über 80.000 $ gegenüber Pro. Das ist genug Budget, um einen halben Entwickler zusätzlich zu finanzieren.
2.3 Hybrides Routing: Best Practices für die Produktion
Für die meisten Produkte ist nicht die Wahl zwischen den beiden Modellen entscheidend, sondern das dynamische Routing nach Anfragetyp:
def route_model(request_type: str) -> str:
# Routing-Logik basierend auf dem Anfragetyp
if request_type in ("chat", "faq", "summarize", "classify"):
return "deepseek-v4-flash"
if request_type in ("deep_research", "multi_step_agent"):
return "deepseek-v4-pro"
return "deepseek-v4-flash" # Standardmäßig Flash
🎯 Implementierungsempfehlung: Wir empfehlen, auf der APIYI-Plattform (apiyi.com) sowohl für V4-Flash als auch für V4-Pro Zugriffsberechtigungen zu hinterlegen. Beide nutzen denselben API-Schlüssel; Sie müssen lediglich das Feld
modelanpassen. Für Batch-Aufgaben empfehlen wir die Hochleistungs-Routevip.apiyi.com, während komplexe Pro-Aufgaben überapi.apiyi.comlaufen sollten. So können Sie verschiedene Geschäftsbereiche innerhalb einer Konfiguration per A/B-Traffic-Verteilung steuern.
III. In 5 Minuten deepseek-v4-flash bei APIYI (apiyi.com) aufrufen
3.1 Schritt 1: Voraussetzungen und API-Schlüssel abrufen
| Punkt | Anforderung |
|---|---|
| Python oder Node.js | Python 3.8+ / Node.js 18+ |
| Client-SDK | OpenAI Python openai >= 1.0 oder offizielles Node SDK |
| Netzwerk | Zugriff auf api.apiyi.com erforderlich |
| Schlüssel | Im APIYI apiyi.com Dashboard generieren, beginnt mit sk- |
Schlüssel abrufen:
- Besuchen Sie
apiyi.com, registrieren/anmelden und zum Dashboard navigieren. - Linkes Menü → API Keys → Neuen Schlüssel erstellen.
- Es wird empfohlen, für erste Tests ein „Nutzungslimit“ von 50–100 ¥ festzulegen.
- Kopieren Sie den mit
sk-beginnenden Schlüssel.
3.2 Schritt 2: Route (base_url) wählen
APIYI bietet drei Routen an, die denselben Schlüssel nutzen:
| base_url | Positionierung | Empfohlener Einsatz |
|---|---|---|
https://api.apiyi.com/v1 |
Hauptseite | Standardwahl für tägliche Aufrufe |
https://vip.apiyi.com/v1 |
Hohe Last | Batch-Verarbeitung/Inferenz, nächtliche Queues |
https://b.apiyi.com/v1 |
Backup | Automatisches Fallback bei Störungen der Hauptseite |
Für die tägliche Entwicklung reicht die Hauptseite. Wechseln Sie bei 429-Rate-Limits oder 5xx-Fehlern in der Produktion auf VIP/Backup.
3.3 Schritt 3: Minimales Python-Beispiel (Non-Thinking)
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "system", "content": "Du bist ein präziser Assistent."},
{"role": "user", "content": "Fasse die Kern-Upgrades von DeepSeek V4-Flash in drei Punkten zusammen."},
],
max_tokens=512,
)
print(resp.choices[0].message.content)
Es gibt nur zwei Änderungen:
base_urlzeigt aufapi.apiyi.com/v1modelwird aufdeepseek-v4-flashgesetzt
Der restliche OpenAI-SDK-Code bleibt unverändert.
3.4 Schritt 4: Thinking-Inferenzmodus aktivieren
Für tiefgreifende Schlussfolgerungen fügen Sie den Parameter reasoning hinzu:
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "user", "content": "Beweis: Gegeben n Punkte, wie viele Linien werden mindestens benötigt, um alle Punktpaare abzudecken?"},
],
extra_body={
"reasoning": {"enabled": True, "effort": "high"},
},
max_tokens=8192,
)
# Die Antwort enthält das Feld reasoning_content
print("Denkprozess:", resp.choices[0].message.reasoning_content)
print("Endergebnis:", resp.choices[0].message.content)
Im Thinking-Modus dauert die Verarbeitung 2–5 Mal länger (abhängig von der Komplexität), aber die Genauigkeit bei Code- und Matheaufgaben steigt deutlich.
3.5 Schritt 5: Minimales Node.js-Beispiel
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_API_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const resp = await client.chat.completions.create({
model: "deepseek-v4-flash",
messages: [
{ role: "user", content: "Schreibe ein Haiku über KI im Jahr 2026" },
],
max_tokens: 256,
});
console.log(resp.choices[0].message.content);
3.6 Schritt 6: Function Calling-Beispiel
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Aktuelles Wetter für eine Stadt abrufen",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
},
},
}]
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[{"role": "user", "content": "Wie ist das Wetter heute in Shanghai?"}],
tools=tools,
)
print(resp.choices[0].message.tool_calls)
V4-Flash ist bei einfachen Tool-Aufrufen sehr stabil. Für komplexe, mehrstufige Tool-Ketten (5+ Schritte) wird ein Upgrade auf V4-Pro empfohlen.
3.7 Schritt 7: Aufruf über das Anthropic-Protokoll
Falls Ihr Projekt auf dem Anthropic-SDK basiert (z. B. Integration in Claude Code), können Sie es ebenfalls nutzen:
from anthropic import Anthropic
client = Anthropic(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com",
)
resp = client.messages.create(
model="deepseek-v4-flash",
max_tokens=1024,
messages=[{"role": "user", "content": "Hi"}],
)
print(resp.content[0].text)
🎯 Empfehlung für beide Protokolle: Für dasselbe Modell
deepseek-v4-flashnutzt das OpenAI-Protokollapi.apiyi.com/v1, das Anthropic-Protokoll hingegenapi.apiyi.com(ohne/v1). Beim Wechsel muss nur diebase_urlangepasst werden. Weitere Details finden Sie in der APIYI-Dokumentation unterdocs.apiyi.comim DeepSeek-Bereich.
IV. Der vollständige Migrationspfad zu deepseek-v4-flash

4.1 Warum die Migration zwingend ist: 90-Tage-Countdown
DeepSeek hat offiziell angekündigt:
Legacy-Modelle
deepseek-chatunddeepseek-reasonerwerden am 24. Juli 2026 eingestellt.
Bitte aktualisieren Sie Ihr Modell aufdeepseek-v4-prooderdeepseek-v4-flash.
Nach dem 24.07.2026 führen Anfragen mit alten Modell-IDs zu Fehlern. Ab dem Veröffentlichungsdatum (24.04.2026) gibt es eine Pufferzeit von insgesamt 90 Tagen.
4.2 Migrations-Entscheidungstabelle
Ordnen Sie Ihr aktuelles Modell dem neuen Modell zu:
| Altes Modell-ID | Neues Modell-ID | Migrationsaufwand |
|---|---|---|
deepseek-chat |
deepseek-v4-flash (Non-Thinking-Modus) |
⭐ Nur 1 Feld ändern |
deepseek-reasoner |
deepseek-v4-flash + Thinking-Modus |
⭐⭐ Modell ändern + reasoning-Parameter |
deepseek-reasoner (High-Value) |
deepseek-v4-pro + Thinking-Modus |
⭐⭐ Modell ändern + reasoning-Parameter |
deepseek-v3.x |
deepseek-v4-flash |
⭐ Nur Modell ändern |
deepseek-coder etc. |
deepseek-v4-flash |
⭐ Nur Modell ändern (Fähigkeiten abgedeckt) |
4.3 Code-Diff: Nahezu keine Änderungen
Vor der Migration:
resp = client.chat.completions.create(
model="deepseek-chat", # ← Altes Modell
messages=[...],
)
Nach der Migration:
resp = client.chat.completions.create(
model="deepseek-v4-flash", # ← Diese Zeile ändern
messages=[...],
)
Falls Sie von deepseek-reasoner migrieren:
resp = client.chat.completions.create(
- model="deepseek-reasoner",
+ model="deepseek-v4-flash",
messages=[...],
+ extra_body={"reasoning": {"enabled": True}},
)
4.4 Migrations-Checkliste
Wir empfehlen, diese Liste vor der Migration abzuarbeiten:
- Alle hartcodierten
model=-Stellen im Code identifizieren. - Prüfen, ob
deepseek-reasoner-Aufrufe ein Upgrade auf V4-Pro benötigen. - Einen Satz Regressionstest-Prompts (20–50 Stück, deckt Kerngeschäft ab) vorbereiten.
- Im APIYI
apiyi.comDashboard das tägliche Limit für alte Anfragen temporär senken, um die Migration zu erzwingen. - Altes und neues Modell 1 Woche im A/B-Test laufen lassen und die Ausgabequalität vergleichen.
- Token-Verbrauchskurve überwachen, um unerwartete Kostensteigerungen auszuschließen.
- Interne Dokumentation und Runbooks aktualisieren.
4.5 Empfehlung für das Canary-Release
In 3 Phasen:
| Phase | Traffic | Zeitraum | Ziel |
|---|---|---|---|
| Phase 1 | 5% | Woche 1 | Protokoll und grundlegende Ausgabe validieren |
| Phase 2 | 30% | Woche 2-3 | Vergleich der Schlüsselmetriken (Qualität + Kosten) |
| Phase 3 | 100% | Woche 4 | Vollständige Migration, alten Schlüssel für Notfall-Rollback behalten |
💡 Notfall-Rollback: Das Routing für alte Modelle bei APIYI (apiyi.com) bleibt bis zum 24.07.2026 kompatibel. Sollten während der Migration schwerwiegende Probleme auftreten, ändern Sie das
modeleinfach zurück aufdeepseek-chat/deepseek-reasoner, um den Betrieb sofort wiederherzustellen. Warten Sie jedoch nicht bis Ende Juli mit der Umstellung.
V. FAQ zu deepseek-v4-flash
Q1: Wie entscheide ich mich zwischen Flash und Pro?
Die Faustregel lautet: Standardmäßig Flash, bei Engpässen auf Pro upgraden. Im Detail:
- Einzelne Dialoge, FAQ, Klassifizierung, Zusammenfassungen, Code-Vervollständigung → Flash
- Mehrstufige Agenten-Workflows (5+ Tool-Aufrufe) → Pro
- Tiefgehende Forschungsaufgaben → Pro
- Im Zweifelsfall: Erst mit Flash testen, bei unzureichenden Ergebnissen auf Pro wechseln.
Q2: Ist das 1M-Kontextfenster wirklich voll nutzbar?
Ja, aber beachten Sie Folgendes:
- Erste 100K–300K: Hier ist die Aufmerksamkeit des Modells am höchsten, beste Ergebnisse.
- 300K–800K: Ergebnisse bleiben stabil.
- 800K–1M: Die Rand-Recall-Rate sinkt; wichtige Informationen sollten idealerweise am Anfang oder Ende platziert werden.
- Kostenhinweis: 1M Token Input ≈ $0,14 – nicht teuer, aber auch nicht kostenlos.
Für lange Texte empfiehlt sich die Struktur: "Frage am Anfang + Material in der Mitte + Frage am Ende wiederholen".
Q3: Wie aktiviere ich den Thinking-Modus?
Unter dem OpenAI-Protokoll erfolgt die Aktivierung über extra_body.reasoning.enabled=true. Der Parameter effort kann auf low, medium oder high gesetzt werden (Standard ist medium). Bei APIYI api.apiyi.com sind die Parameter identisch mit den offiziellen Vorgaben.
Q4: Ist Function Calling bei Flash stabil?
Einzelaufrufe sind sehr stabil (über 95 % Erfolgsquote). Für mehrstufige Tool-Ketten (5+ Schritte) wird Pro empfohlen – der 11-Punkte-Unterschied im Terminal-Bench 2.0 zeigt sich vor allem hier.
Q5: Was ist eine angemessene Parallelität?
Für einzelne Entwickler sind 10–20 parallele Anfragen kein Problem. Für Produktionsumgebungen gilt:
- Standard: Über
api.apiyi.comsind 50 parallele Anfragen möglich. - Batch-/Nacht-Aufgaben: Wechseln Sie zu
vip.apiyi.com, hier sind 200+ Anfragen möglich. - Notfall-Ausweichlösung: Temporär auf
b.apiyi.comausweichen.
Die aktuellen Limits finden Sie unter docs.apiyi.com.
Q6: Wie bewerte ich das Migrationsrisiko?
Drei-Schritte-Methode:
- Ausgabequalität: Führen Sie einen A/B-Test mit 20–50 typischen Business-Prompts durch und bewerten Sie diese manuell oder durch ein Scoring-Modell.
- Kostenkurve: Beobachten Sie den täglichen Token-Verbrauch; Flash-Output-Token sind oft etwas höher (besonders im Thinking-Modus).
- Latenz: Die TTFT von Flash ist vergleichbar mit V3.5, der Thinking-Modus ist jedoch 2–5 Mal langsamer.
Bei einem Qualitätsverlust von über 10 % sollten Sie ein Upgrade auf Pro in Betracht ziehen, ansonsten können Sie bedenkenlos migrieren.
Q7: Wie nutze ich die Kompatibilität mit dem Anthropic-Protokoll?
Die base_url wird ohne /v1 angegeben, rufen Sie direkt POST /v1/messages auf. Im model-Feld des Anthropic SDK tragen Sie einfach deepseek-v4-flash ein. Dies ist der schnellste Weg für eine Migration ohne Code-Anpassungen, falls Sie bereits das Claude SDK nutzen.
Q8: Gibt es Rabatte für das Kontext-Caching?
V4-Flash unterstützt jetzt automatisches Kontext-Caching (context caching). Anfragen mit wiederkehrenden Präfixen werden günstiger abgerechnet. Bei langen System-Eingabeaufforderungen lassen sich so 30–50 % einsparen. Dieser Vorteil ist auf der APIYI-Plattform apiyi.com standardmäßig aktiviert und erfordert keine zusätzlichen Parameter.
VI. Zusammenfassung zum Start von deepseek-v4-flash
Die Veröffentlichung von DeepSeek V4 bringt zwei entscheidende Fakten für Entwickler:
- Günstiger: V4-Flash bietet nahezu Pro-Leistung zu 1/12 des Preises; $0,14/M Input setzt einen neuen Branchen-Tiefstwert.
- Migrationsdruck: Am 24.07.2026 werden alte Modelle offiziell abgeschaltet; die 90-tägige Übergangsfrist läuft ab Veröffentlichungsdatum.
Die gute Nachricht: deepseek-v4-flash ist ab sofort bei APIYI apiyi.com verfügbar. Sie benötigen kein eigenes Konto im Ausland, müssen das SDK nicht ändern und brauchen sich keine Sorgen um Zahlungswege zu machen. Drei Schritte genügen:
- ✅ Holen Sie sich einen Schlüssel im
apiyi.com-Dashboard. - ✅ Setzen Sie die
base_urlaufapi.apiyi.com/v1(alternativvip.apiyi.com/b.apiyi.com). - ✅ Setzen Sie das
modelaufdeepseek-v4-flash, der restliche Code bleibt unverändert.
🎯 Handlungsempfehlung: Starten Sie noch heute mit dem A/B-Test für deepseek-v4-flash. Erstellen Sie einen dedizierten Schlüssel bei APIYI apiyi.com, führen Sie 20–50 typische Business-Prompts aus und vergleichen Sie die Ausgabequalität sowie die Kosten mit Ihrem bisherigen Modell. Wenn kein signifikanter Qualitätsverlust auftritt, können Sie diese Woche 5 % des Traffics umstellen und die vollständige Migration innerhalb von 4 Wochen abschließen – das ist deutlich entspannter, als bis Juli unter Zeitdruck zu arbeiten. Detailliertere Migrationsbeispiele und Benchmark-Skripte finden Sie in der DeepSeek V4-Rubrik unter
docs.apiyi.com.
Der Wert von deepseek-v4-flash liegt nicht darin, "nur ein weiteres günstiges Modell" zu sein, sondern darin, Szenarien, die bisher nur großen Tech-Giganten vorbehalten waren, zu einem Preis anzubieten, den sich jeder leisten kann – 1M Kontext für ganze Bücher, Thinking-Modus für komplexe Schlussfolgerungen und Function Calling für komplette Tool-Suiten, alles zu minimalen Kosten pro Aufruf. Dies eröffnet völlig neue Produktmöglichkeiten; wer zuerst migriert, hat den Vorsprung.
Autor: APIYI Technik-Team
Ressourcen:
- Offizielle DeepSeek-Ankündigung: api-docs.deepseek.com/news/news260424
- Hugging Face Open-Source-Repository: huggingface.co/deepseek-ai/DeepSeek-V4-Flash
- APIYI Website: apiyi.com
- APIYI Dokumentation: docs.apiyi.com
- APIYI Hauptseite: api.apiyi.com (alternativ vip.apiyi.com / b.apiyi.com)