2026年4月24日,DeepSeek 在 Hugging Face 上同时开源了 V4-Pro 和 V4-Flash 两个预览版模型。前者是面向最前沿性能的 1.6T 参数 MoE 巨兽,而后者则是“性能接近 Pro 的 90%,价格却仅为 1/12”的高性价比甜点。
如果你只需关注一个模型,那么 deepseek-v4-flash 绝对是首选。原因非常简单:
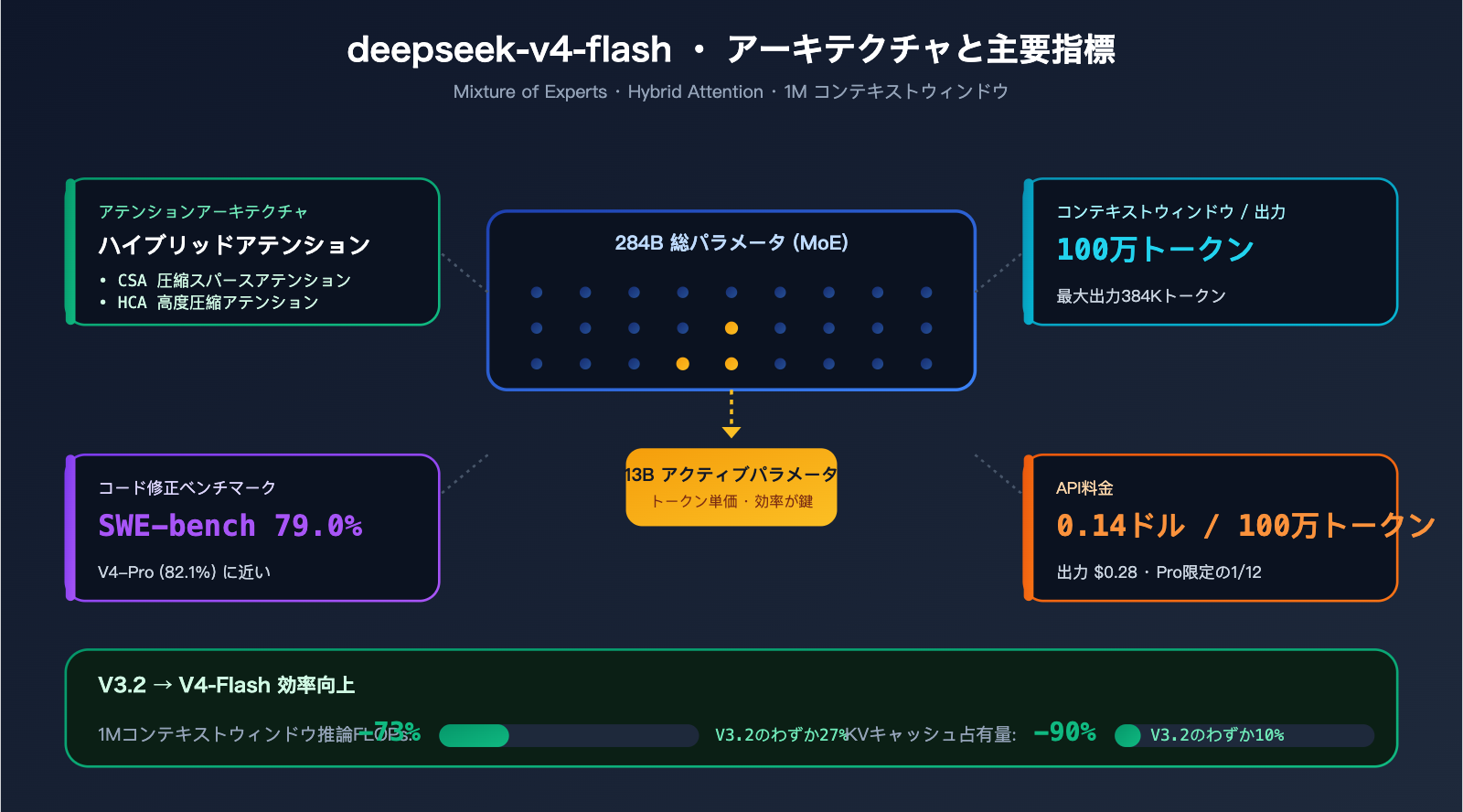
- 284B / 13B MoE 架构 + Hybrid Attention,在 1M 上下文推理时的 FLOPs 仅为 V3.2 的 27%。
- 1M tokens 上下文 / 384K tokens 最大输出,原生支持长文本,无需再进行切片(chunk)处理。
- 输入 $0.14 / 输出 $0.28(每百万 tokens),价格比 Pro 版本便宜一个数量级。
- SWE-bench Verified 79.0%、Artificial Analysis Intelligence Index 45–47,足以胜任绝大多数应用场景。
- 同时兼容 OpenAI ChatCompletions 和 Anthropic API 双协议,Claude Code / OpenClaw / OpenCode 等工具无需改造即可直接使用。
更重要的一点:旧模型 deepseek-chat 和 deepseek-reasoner 将于 2026年7月24日 正式停服,所有线上业务必须在此之前完成迁移。这是 90 天倒计时的硬截止日期。
好消息是:deepseek-v4-flash 已在 APIYI (apiyi.com) 上架。你无需自建 DeepSeek 账号、无需修改 SDK、无需处理复杂的海外支付——只需将 model 字段替换,并将 base_url 指向 api.apiyi.com 即可立即使用。
本文是一份 3+5 的指南:3 分钟读懂 V4-Flash 核心升级 + 5 分钟完成从旧模型的完整迁移。
一、deepseek-v4-flash 的 5 大核心升级
1.1 核心规格一览表
先看全貌,再展开细节:
| 维度 | deepseek-v4-flash |
|---|---|
| 发布日期 | 2026-04-24(预览版) |
| 开源仓库 | huggingface.co/deepseek-ai/DeepSeek-V4-Flash |
| 总参数 | 284B(Mixture of Experts) |
| 激活参数 | 13B |
| 上下文窗口 | 1M tokens |
| 最大输出 | 384K tokens |
| 注意力架构 | Hybrid Attention(CSA + HCA) |
| 推理模式 | Thinking / Non-Thinking 双模式 |
| Function Calling | ✅ 支持 |
| JSON 模式 | ✅ 支持 |
| Chat Prefix Completion | Beta 支持 |
| API 协议 | OpenAI ChatCompletions + Anthropic 双兼容 |
| 输入价格 | $0.14 / M tokens |
| 输出价格 | $0.28 / M tokens |
下面逐一解析这 5 项核心升级。
1.2 升级 1:1M 上下文 + 384K 输出(原生超长)
deepseek-v4-flash 原生支持 1M tokens 输入和 384K tokens 输出。这是整个 V4 系列的统一规格,Flash 版本并未因追求性价比而缩减上下文能力。
1M 的容量意味着什么?
| 内容类型 | 大致 token 数 |
|---|---|
| 10 万字中文书稿 | ≈ 150K tokens |
| 200 页 PDF 技术文档 | ≈ 300K tokens |
| 中型代码仓库(约 50 个文件) | ≈ 500K–800K tokens |
| 整本《红楼梦》 | ≈ 1M tokens |
对比 GPT-5.4(400K)、Claude Opus 4.6(1M + 1M 上下文包)、Gemini 3.1-Pro(2M),V4-Flash 的 1M 已是行业主流配置,且价格比前三者便宜 5–20 倍。
1.3 升级 2:284B/13B MoE + Hybrid Attention
V4-Flash 采用了 DeepSeek 2026 年引入的两项关键架构创新:
- MoE:总参数 284B,每 token 仅激活 13B。效果接近 13B 密集模型,但知识覆盖面接近 200B+ 密集模型。
- Hybrid Attention(CSA 压缩稀疏注意力 + HCA 高度压缩注意力):专为长上下文设计。
效率实测数据(来自 DeepSeek 官方):
| 指标 | V3.2 | V4-Flash | 提升 |
|---|---|---|---|
| 1M 上下文单 token 推理 FLOPs | 100% | 27% | -73% |
| 1M 上下文 KV 缓存占用 | 100% | 10% | -90% |
这两组数据解释了为何 Flash 能将价格压至 $0.14:底层算力成本确实大幅降低了,而非单纯的硬补贴。
1.4 升级 3:Thinking / Non-Thinking 双模式
V4-Flash 通过同一个模型 ID 即可切换两种模式:
- Non-Thinking(默认):速度快,适合闲聊、问答、分类、摘要。
- Thinking:模型会先输出一段内部推理过程(类似 OpenAI o 系列),然后再给出最终答案。适合复杂推理、多步工具调用、代码调试。
调用时通过请求参数进行切换(无需更换模型 ID),开发者侧改动极小。在 APIYI api.apiyi.com 上调用时,参数名与 DeepSeek 官方完全一致。
1.5 升级 4:$0.14 / $0.28 每 M tokens
这是本次发布最惊人的数字:
| 模型 | 输入 ($/M) | 输出 ($/M) | 相对 V4-Flash |
|---|---|---|---|
| deepseek-v4-flash | 0.14 | 0.28 | 1×(基准) |
| deepseek-v4-pro | 1.74 | 3.48 | 12× |
| GPT-5.4(参考) | 2.50 | 10.00 | 17×–35× |
| Claude Sonnet 4.6(参考) | 3.00 | 15.00 | 21×–53× |
以典型的“500 tokens 输入 + 500 tokens 输出”请求为例:
- V4-Flash:$0.000 21 ≈ ¥0.0015
- GPT-5.4:$0.006 25 ≈ ¥0.045
- Claude Sonnet 4.6:$0.009 ≈ ¥0.065
Flash 便宜了 30–40 倍。对于月调用量达亿级 tokens 的产品而言,这直接决定了毛利率。
1.6 升级 5:OpenAI + Anthropic 双协议兼容
V4-Flash 在 API 层同时实现了两套协议:
POST /v1/chat/completions→ OpenAI 格式POST /v1/messages→ Anthropic 格式
这意味着:
| 客户端 | 迁移成本 |
|---|---|
| OpenAI Python/Node SDK | 零修改,仅需更改 base_url 和 model |
| Anthropic Python/Node SDK | 零修改,仅需更改 base_url 和 model |
| Claude Code | 切换至 Anthropic endpoint 即可 |
| OpenClaw / OpenCode | 原生支持 |
| LangChain / LlamaIndex | 更改 base_url 即可 |
这是 DeepSeek 本次版本的一个明智决策:不强制学习新协议,让存量生态实现零成本接入。
1.7 Benchmark 实测对比表
| Benchmark | V4-Flash | V4-Pro | 差距 |
|---|---|---|---|
| SWE-bench Verified(代码修复) | 79.0% | 82.1% | -3.1 |
| Terminal-Bench 2.0(多步工具用) | 56.9% | 67.9% | -11.0 |
| SimpleQA-Verified(事实召回) | 34.1% | 57.9% | -23.8 |
| Artificial Analysis Intelligence Index | 45 / 47 | 58 | -11 ~ -13 |
解读:Flash 在单步代码任务(SWE-bench)上几乎追平 Pro,但在需要多步工具链(Terminal-Bench)和事实记忆(SimpleQA)上差距明显。这两个指标正是判断“选 Flash 还是 Pro”的核心决策依据。
2. deepseek-v4-flash と V4-Pro のシナリオ別選定
2.1 意思決定マトリックス:まずはここを確認
| シナリオ | 推奨モデル | 理由 |
|---|---|---|
| 日常会話、雑談、Q&A | Flash | 能力は十分、価格は1/12 |
| カスタマーサポート、FAQ | Flash | スループットが高く、低遅延 |
| コード補完、単一ファイル修正 | Flash | SWE-bench 79%でProに肉薄 |
| 長文要約、書籍の読解 | Flash | 1Mのコンテキストウィンドウをフル活用 |
| 多段階ツールチェーン Agent | Pro | Terminal-Benchで11ポイントの差 |
| 詳細な調査、多段階検証 | Pro | SimpleQAで24ポイントの差 |
| 高価値なビジネスレポート生成 | Pro | Intelligence Indexが11以上高い |
| 開発・探索的実験 | Flash | 12倍安価で、反復が早い |
基本ルール:デフォルトはFlashを使用し、ボトルネックが発生した場合にProへアップグレードする。これは技術選定における「まずはシンプルな構成から始め、必要に応じて拡張する」という原則と同じです。
2.2 コストパフォーマンス試算:どの規模でFlashがより節約になるか
1日あたり1億トークン(入力6,000万 + 出力4,000万)を消費する製品を想定します。
| モデル | 1日のコスト | 月間コスト | 年間コスト |
|---|---|---|---|
| V4-Flash | $19.6 | $588 | $7,056 |
| V4-Pro | $243.6 | $7,308 | $87,696 |
| GPT-5.4(参考) | $550 | $16,500 | $198,000 |
Flashを使うことで、Proと比較して年間$80,000以上の節約になります。これは開発者をもう一人雇えるほどの金額です。
2.3 ハイブリッドルーティング:本番環境でのベストプラクティス
多くの製品にとっての最適解はどちらか一方を選ぶことではなく、リクエストタイプに応じて動的にルーティングすることです。
def route_model(request_type: str) -> str:
# チャットやFAQ、要約などの軽量タスクはFlashへ
if request_type in ("chat", "faq", "summarize", "classify"):
return "deepseek-v4-flash"
# 複雑な調査やマルチステップAgentはProへ
if request_type in ("deep_research", "multi_step_agent"):
return "deepseek-v4-pro"
return "deepseek-v4-flash" # デフォルトはFlash
🎯 導入のアドバイス:APIYI (apiyi.com) プラットフォームでは、V4-FlashとV4-Proの両方のモデル呼び出し権限を保持しておくことを推奨します。どちらも同じAPIキーで利用でき、
modelフィールドを書き換えるだけで切り替え可能です。バッチ処理にはvip.apiyi.comの高並列ルート、複雑なタスクにはメインのapi.apiyi.comを利用するなど、ビジネス要件に合わせて同一設定内でABトラフィックの振り分けを行うことができます。
三、5分で完了!APIYI (apiyi.com) で deepseek-v4-flash を呼び出す方法
3.1 ステップ1:環境準備とAPIキーの取得
| 項目 | 要件 |
|---|---|
| Python または Node.js | Python 3.8+ / Node.js 18+ |
| クライアントSDK | OpenAI Python openai >= 1.0 または公式 Node SDK |
| ネットワーク | api.apiyi.com へのアクセスが可能であること |
| APIキー | APIYI apiyi.com コンソールで生成(sk- で始まるもの) |
APIキーの取得手順:
apiyi.comにアクセスし、登録またはログインしてコンソールへ移動します。- 左側のメニューから「API Keys」→「新規キー作成」を選択します。
- 初期検証用に「使用上限額」を ¥50–100 程度に設定することをお勧めします。
sk-で始まるキー文字列をコピーします。
3.2 ステップ2:接続先(base_url)の選択
APIYIでは3つの接続先を提供しており、すべて同じAPIキーで利用可能です。
| base_url | 用途 | 推奨シーン |
|---|---|---|
https://api.apiyi.com/v1 |
メイン | デフォルトの推奨設定、日常的な呼び出し |
https://vip.apiyi.com/v1 |
高負荷 | バッチ処理、夜間の大量リクエスト |
https://b.apiyi.com/v1 |
バックアップ | メインが不安定な際の自動フォールバック用 |
日常的な開発にはメインサイトを使用し、本番環境で 429 エラー(レート制限)や 5xx エラーが発生した場合に VIP/バックアップへ切り替えてください。
3.3 ステップ3:Pythonによる最小呼び出し例(非思考モード)
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "system", "content": "あなたは簡潔なアシスタントです"},
{"role": "user", "content": "DeepSeek V4-Flash の主要なアップグレード点を3つでまとめて"},
],
max_tokens=512,
)
print(resp.choices[0].message.content)
変更点は以下の2箇所のみです:
base_urlをapi.apiyi.comに指定modelをdeepseek-v4-flashに変更
その他の OpenAI SDK コードはそのまま利用可能です。
3.4 ステップ4:Thinking(推論)モードの有効化
高度な推論が必要な場合は、リクエストに reasoning パラメータを追加します:
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "user", "content": "証明:n個の点があるとき、すべての点のペアをカバーするために必要な直線の最小数は?"},
],
extra_body={
"reasoning": {"enabled": True, "effort": "high"},
},
max_tokens=8192,
)
# レスポンスには reasoning_content フィールドが含まれます
print("思考プロセス:", resp.choices[0].message.reasoning_content)
print("最終回答:", resp.choices[0].message.content)
Thinking モードでは処理時間が2〜5倍(問題の複雑さに依存)かかりますが、コードや数学問題の正答率が大幅に向上します。
3.5 ステップ5:Node.jsによる最小呼び出し例
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_API_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const resp = await client.chat.completions.create({
model: "deepseek-v4-flash",
messages: [
{ role: "user", content: "2026年のAIについて俳句を書いて" },
],
max_tokens: 256,
});
console.log(resp.choices[0].message.content);
3.6 ステップ6:Function Calling(関数呼び出し)の例
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "指定した都市の現在の天気を取得する",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
},
},
}]
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[{"role": "user", "content": "今日の上海の天気はどう?"}],
tools=tools,
)
print(resp.choices[0].message.tool_calls)
V4-Flash は単一のツール呼び出しにおいて非常に安定しています。多段階の複雑なツールチェーン(5ステップ以上)が必要な場合は、V4-Pro へのアップグレードを推奨します。
3.7 ステップ7:Anthropic プロトコルでの呼び出し
Anthropic SDK をベースにしたプロジェクト(Claude Code など)でも利用可能です:
from anthropic import Anthropic
client = Anthropic(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com",
)
resp = client.messages.create(
model="deepseek-v4-flash",
max_tokens=1024,
messages=[{"role": "user", "content": "Hi"}],
)
print(resp.content[0].text)
🎯 デュアルプロトコルのヒント:同じ deepseek-v4-flash モデルでも、OpenAI プロトコルは
api.apiyi.com/v1、Anthropic プロトコルはapi.apiyi.com(/v1なし)を使用します。切り替え時は base_url を変更するだけです。詳細は APIYI 公式ドキュメントdocs.apiyi.comの DeepSeek セクションを参照してください。
四、旧モデルから deepseek-v4-flash への完全移行ガイド

4.1 なぜ移行が必須なのか:90日間のカウントダウン
DeepSeek 公式発表により、以下の通りアナウンスされています:
旧モデル
deepseek-chatおよびdeepseek-reasonerは 2026年7月24日 に廃止されます。
deepseek-v4-proまたはdeepseek-v4-flashへの更新をお願いします。
2026年7月24日以降、旧モデルIDを使用したリクエストはエラーとなります。リリース日の2026年4月24日から数えて、合計 90日間 の猶予期間が設けられています。
4.2 移行決定表
現在使用しているモデルに応じた移行先は以下の通りです:
| 旧 model id | 新 model id | 移行難易度 |
|---|---|---|
deepseek-chat |
deepseek-v4-flash(非思考モード) |
⭐ 1フィールドの変更のみ |
deepseek-reasoner |
deepseek-v4-flash + Thinkingモード |
⭐⭐ モデル変更 + reasoningパラメータ追加 |
deepseek-reasoner(高価値シーン) |
deepseek-v4-pro + Thinkingモード |
⭐⭐ モデル変更 + reasoningパラメータ追加 |
deepseek-v3.x |
deepseek-v4-flash |
⭐ モデル変更のみ |
deepseek-coder 等 |
deepseek-v4-flash |
⭐ モデル変更のみ(汎用能力がカバー) |
4.3 コードの差分:ほぼ変更なし
移行前:
resp = client.chat.completions.create(
model="deepseek-chat", # ← 旧モデル
messages=[...],
)
移行後:
resp = client.chat.completions.create(
model="deepseek-v4-flash", # ← ここを変更
messages=[...],
)
deepseek-reasoner から移行する場合:
resp = client.chat.completions.create(
- model="deepseek-reasoner",
+ model="deepseek-v4-flash",
messages=[...],
+ extra_body={"reasoning": {"enabled": True}},
)
4.4 移行チェックリスト
移行前に以下のリストを確認することをお勧めします:
- コード内の
model=がハードコードされている箇所をすべて洗い出す -
deepseek-reasonerの呼び出しを V4-Pro にアップグレードすべきか評価する - 回帰テスト用プロンプト(20〜50件、コア業務を網羅)を準備する
- APIYI
apiyi.comコンソールで旧モデルの1日あたりの上限を一時的に絞り、移行を強制的にトリガーする - 新旧モデルで ABテストを1週間実施し、出力品質を比較する
- トークン消費量を監視し、コストが予期せず上昇していないか確認する
- 社内ドキュメントと運用手順書(Runbook)を更新する
4.5 カナリアリリース(段階的移行)の推奨
3フェーズで実施:
| フェーズ | トラフィック | 期間 | 目標 |
|---|---|---|---|
| 第1期 | 5% | 第1週 | プロトコルと基本出力の検証 |
| 第2期 | 30% | 第2-3週 | 主要指標(品質 + コスト)の比較 |
| 第3期 | 100% | 第4週 | 全量移行、旧キーは緊急ロールバック用に保持 |
💡 緊急ロールバック:APIYI
apiyi.comでは、2026年7月24日まで旧モデルのルーティング互換性を維持します。移行中に重大な問題が発生した場合は、modelをdeepseek-chat/deepseek-reasonerに戻すだけで即座に復旧可能です。ただし、7月末まで先延ばしにしないよう注意してください。
五、deepseek-v4-flash よくある質問 (FAQ)
Q1:Flash と Pro は具体的にどう選べばいいですか?
一言で言うと:デフォルトは Flash、ボトルネックを感じたら Pro にアップグレード。具体的なシーンは以下の通りです:
- 単発の対話、FAQ、分類、要約、コード補完 → Flash
- マルチステップの Agent ワークフロー(5ステップ以上のツール呼び出し) → Pro
- 深いリサーチが必要なタスク → Pro
- 判断に迷う場合は、まず Flash で試して、結果が不十分なら Pro に切り替える
Q2:1M のコンテキストウィンドウは本当に使い切れますか?
可能です。ただし、以下の点に注意してください:
- 前半 100K–300K:モデルの注意力が最も高く、精度が最も良い
- 300K–800K:精度は依然として安定している
- 800K–1M:周辺情報の想起率が低下するため、重要な情報は最初か最後に配置することを推奨
- コストの注意点:1M トークンの入力 ≈ $0.14。高額ではありませんが、無料でもありません
長文を扱う場合は、「冒頭に質問を配置 + 中間に資料を配置 + 最後に再度質問を強調する」という構成をお勧めします。
Q3:Thinking モードはどうやってトリガーしますか?
OpenAI プロトコルでは extra_body.reasoning.enabled=true でトリガーします。effort パラメータは low / medium / high から選択可能で、デフォルトは medium です。APIYI api.apiyi.com でも公式と同様のパラメータが利用可能です。
Q4:Flash での Function Calling は安定していますか?
単発の呼び出しは非常に安定しています(成功率 95% 以上)。マルチステップのツールチェーン(5ステップ以上)の場合は Pro の使用を推奨します。Terminal-Bench 2.0 での 11 ポイントの差は、主にこの部分に現れます。
Q5:適切な同時実行数はどれくらいですか?
個人開発者であれば 10–20 同時実行で問題ありません。本番環境では以下を推奨します:
- デフォルト:
api.apiyi.comを経由して 50 同時実行 - バッチ/夜間タスク:
vip.apiyi.comに切り替え、200 以上の同時実行が可能 - 緊急時の負荷分散:一時的に
b.apiyi.comへフォールバック
具体的な上限については、docs.apiyi.com で最新のクォータ説明を確認してください。
Q6:移行リスクをどう評価すればいいですか?
3ステップ法で評価しましょう:
- 出力品質:業務で典型的なプロンプトを 20–50 件用意して AB テストを行い、人間または評価用モデルでスコアリングする
- コスト曲線:日次のトークン消費量を観察する。Flash は出力トークンが若干多くなる傾向があります(Thinking モードでは特に顕著)
- 遅延:Flash の TTFT(最初のトークンが出るまでの時間)は V3.5 に近く、Thinking モードでは 2–5 倍の時間がかかります
10% 以上の品質低下が見られない限り、安心して移行して問題ありません。
Q7:Anthropic プロトコルとの互換性はどのように使いますか?
base_url に /v1 を含めず、直接 POST /v1/messages を呼び出します。Anthropic SDK の model フィールドに deepseek-v4-flash を入力するだけです。すでに Claude SDK を使用しているプロジェクトにとっては、コード修正なしで移行できる近道です。
Q8:コンテキストキャッシュの割引はありますか?
V4-Flash は自動コンテキストキャッシュ(context caching)を有効にしています。重複するプレフィックスを持つリクエストは、実際の課金が低くなります。長いシステムプロンプトを使用するシーンでは、30–50% のコスト削減が可能です。この割引は APIYI apiyi.com プラットフォームでデフォルトで有効になっており、追加のパラメータ設定は不要です。
六、deepseek-v4-flash 導入まとめ
今回の DeepSeek V4 のリリースにおいて、開発者が知っておくべき重要な事実は 2 つあります:
- 安価になった:V4-Flash は Pro に近い性能を 1/12 の価格で提供し、入力コスト $0.14/M という業界最安値を実現しました。
- 移行の期限:2026年7月24日に旧モデルが正式に廃止されます。リリース日から 90 日間の猶予期間がカウントダウンされています。
幸いなことに、deepseek-v4-flash はすでに APIYI apiyi.com で利用可能です。海外アカウントの作成や SDK の大幅な修正、決済手段の心配は不要です。以下の 3 ステップで完了します:
- ✅
apiyi.comのコンソールで APIキーを取得 - ✅
base_urlをapi.apiyi.com/v1に設定(予備としてvip.apiyi.com/b.apiyi.comも利用可能) - ✅
modelをdeepseek-v4-flashに設定し、残りのコードはそのまま維持
🎯 アクションプラン:今日から deepseek-v4-flash の AB テストを開始することを強くお勧めします。APIYI apiyi.com で専用キーを発行し、20–50 件の典型的なプロンプトを実行して、既存モデルの出力品質とコストを比較してください。明らかな品質低下がなければ、今週中にトラフィックの 5% を切り替え、4 週間以内に完全移行を完了させましょう。7 月の期限ギリギリに慌てるよりも余裕を持って進められます。詳細な移行事例やベンチマークスクリプトについては、
docs.apiyi.comの DeepSeek V4 特設ページを参照してください。
deepseek-v4-flash の価値は単なる「安いモデル」であることではなく、「これまで最先端の巨大企業しか提供できなかったサービスを、誰もが使える価格帯に引き下げたこと」にあります。1M のコンテキストで本一冊を読み込み、Thinking モードで複雑な推論を行い、Function Calling であらゆるツールを連携させる。これらの能力をわずかなコストで実現できるようになったのです。これは新たな製品チャンスを切り開くものであり、早く移行した者が先行者利益を得ることになるでしょう。
著者: APIYI 技術チーム
関連リソース:
- DeepSeek 公式アナウンス: api-docs.deepseek.com/news/news260424
- Hugging Face オープンソースリポジトリ: huggingface.co/deepseek-ai/DeepSeek-V4-Flash
- APIYI 公式サイト: apiyi.com
- APIYI ドキュメント: docs.apiyi.com
- APIYI メインサイト: api.apiyi.com(予備: vip.apiyi.com / b.apiyi.com)