أيهما تختار: Gemini 3.1 Pro Preview أم Claude Opus 4.6؟ هذا هو القرار الذي لا مفر منه لمطوري الذكاء الاصطناعي في أوائل عام 2026. يتناول هذا المقال مقارنة شاملة من 10 أبعاد أساسية، مع الاستشهاد ببيانات القياس الرسمية وتقييمات الطرف الثالث، لمساعدتك في اتخاذ قرار واضح بناءً على البيانات.
القيمة الجوهرية: بعد قراءة هذا المقال، ستعرف بوضوح أي نموذج تختار في السيناريوهات المختلفة، وكيفية التحقق من ذلك بسرعة في مشاريعك الفعلية.

نظرة عامة على بيانات قياس Gemini 3.1 Pro مقابل Claude Opus 4.6
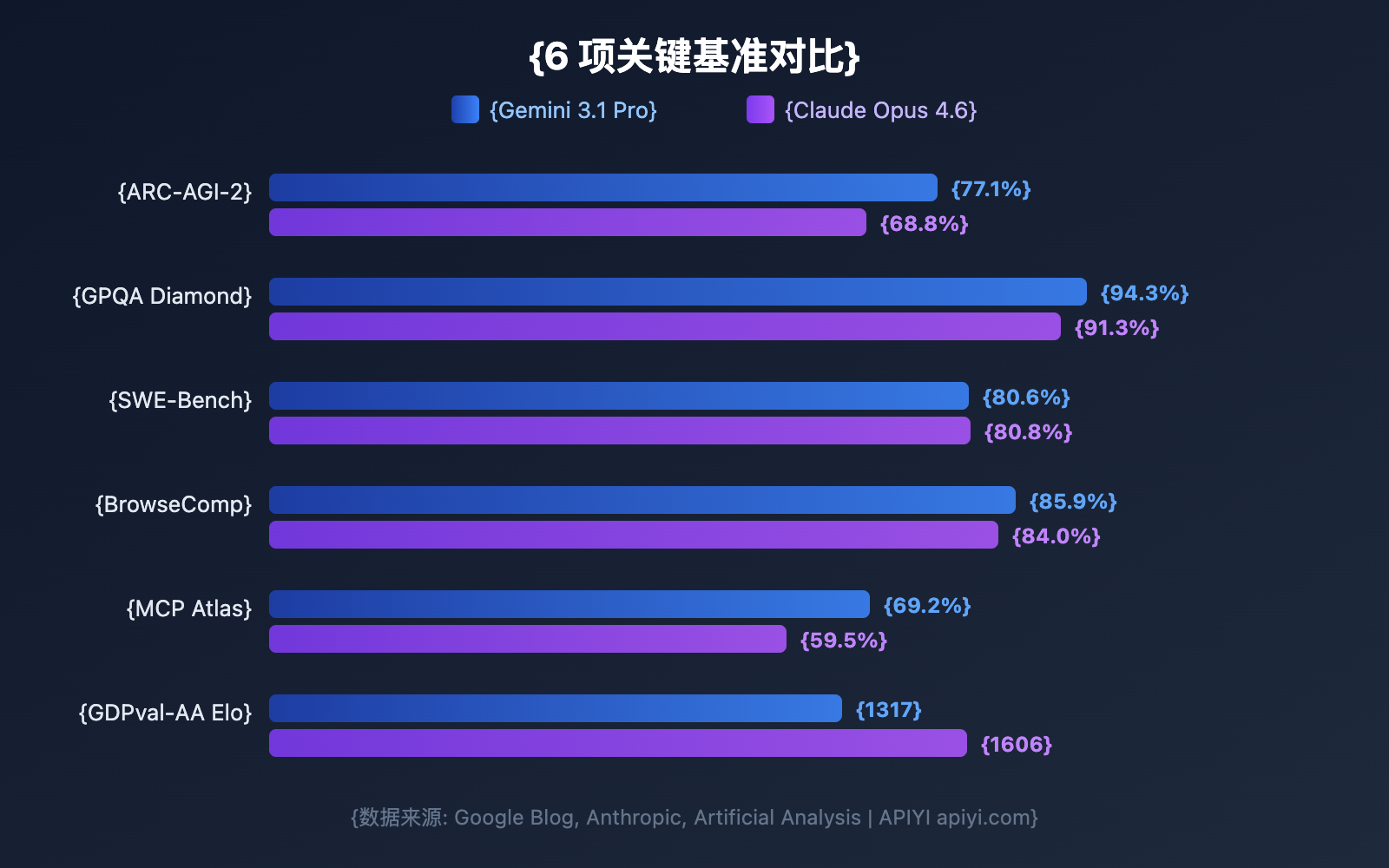
قبل التعمق في الأبعاد المختلفة، لنلقِ نظرة على مقارنة المعايير العالمية. تدعي جوجل رسمياً أن Gemini 3.1 Pro يتصدر في 13 من أصل 16 معياراً، ولكن Claude Opus 4.6 يتفوق في العديد من السيناريوهات العملية.
| الاختبار القياسي | Gemini 3.1 Pro | Claude Opus 4.6 | الفائز | الفارق |
|---|---|---|---|---|
| ARC-AGI-2 (الاستدلال التجريدي) | 77.1% | 68.8% | Gemini | +8.3pp |
| GPQA Diamond (العلوم – مستوى الدكتوراه) | 94.3% | 91.3% | Gemini | +3.0pp |
| SWE-Bench Verified (هندسة البرمجيات) | 80.6% | 80.8% | Claude | +0.2pp |
| Terminal-Bench 2.0 (برمجة الطرفية) | 68.5% | 65.4% | Gemini | +3.1pp |
| BrowseComp (بحث الوكيل) | 85.9% | 84.0% | Gemini | +1.9pp |
| MCP Atlas (وكيل متعدد الخطوات) | 69.2% | 59.5% | Gemini | +9.7pp |
| HLE بدون أدوات (الاختبار النهائي) | 44.4% | 40.0% | Gemini | +4.4pp |
| HLE مع أدوات (الاختبار النهائي) | 51.4% | 53.1% | Claude | +1.7pp |
| SciCode (البرمجة العلمية) | 59% | 52% | Gemini | +7pp |
| MMMLU (الأسئلة والأجوبة متعددة اللغات) | 92.6% | 91.1% | Gemini | +1.5pp |
| tau2-bench Retail (استدعاء الأدوات) | 90.8% | 91.9% | Claude | +1.1pp |
| GDPval-AA Elo (مهام الخبراء) | 1317 | 1606 | Claude | +289 |
📊 توضيح البيانات: المصادر هي مدونة جوجل الرسمية، وإعلانات Anthropic الرسمية، وتقييمات الطرف الثالث من Artificial Analysis. يمكنك استخدام APIYI (apiyi.com) لاستدعاء النموذجين معاً للتحقق في السيناريوهات الفعلية.
المقارنة 1: Gemini 3.1 Pro مقابل Claude Opus 4.6 في قدرات التفكير المنطقي
تُعد قدرة التفكير المنطقي (Reasoning) هي الميزة التنافسية الأساسية لأي نموذج لغة كبير. وتظهر اختلافات جوهرية في بنية التفكير بين هذين النموذجين.
التفكير التجريدي: تفوق واضح لـ Gemini 3.1 Pro
يُعتبر ARC-AGI-2 حالياً المعيار الأكثر موثوقية لقياس التفكير التجريدي، حيث سجل Gemini 3.1 Pro نتيجة 77.1%، متفوقاً على Claude Opus 4.6 الذي سجل 68.8% بفارق 8.3 نقطة مئوية. وهذا يعني أن Gemini أقوى في المهام التي تتطلب استنباط القواعد من أمثلة قليلة.
التفكير العلمي بمستوى الدكتوراه: ميزة بارزة لـ Gemini
في اختبار GPQA Diamond، الذي يفحص الأسئلة العلمية بمستوى الدكتوراه، سجل Gemini 3.1 Pro نتيجة 94.3%، بينما سجل Claude Opus 4.6 نتيجة 91.3%. إن فجوة الـ 3 نقاط مئوية في هذا المستوى من الصعوبة تُعد كبيرة جداً.
التفكير المعزز بالأدوات: Claude يستعيد الصدارة
في اختبار HLE (Humanity's Last Exam)، يتفوق Gemini في الظروف التي لا تتوفر فيها أدوات (44.4% مقابل 40.0%)، ولكن بمجرد إدخال الأدوات المساعدة، يتفوق Claude (53.1% مقابل 51.4%). يشير هذا إلى أن Claude Opus 4.6 يتفوق في استخدام الأدوات الخارجية لتعزيز عملية التفكير والاستنتاج.
| أبعاد التفكير الفرعية | Gemini 3.1 Pro | Claude Opus 4.6 | لمن يصلح |
|---|---|---|---|
| التفكير التجريدي | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | التعرف على الأنماط، استنباط القواعد |
| التفكير العلمي | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | البحث الأكاديمي، المساعدة في الأوراق البحثية |
| التفكير بالأدوات | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | سير العمل المعقد، تنسيق الأدوات المتعددة |
| التفكير الرياضي | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | تخصص Deep Think Mini |
المقارنة 2: Gemini 3.1 Pro مقابل Claude Opus 4.6 في قدرات البرمجة
تُعد قدرات البرمجة هي البعد الأكثر أهمية للمطورين. أداء النموذجين متقارب للغاية، ولكن لكل منهما نقاط قوة مختلفة.
SWE-Bench: تعادل تقريباً
يُعد SWE-Bench Verified معياراً لإصلاح مشكلات GitHub الحقيقية:
- Claude Opus 4.6: 80.8% (تفوق طفيف)
- Gemini 3.1 Pro: 80.6%
بفارق 0.2 نقطة مئوية فقط، يمكن اعتبار أن كلا النموذجين يمتلكان قدرات متساوية تقريباً في مهام هندسة البرمجيات الواقعية.
Terminal-Bench: تفوق Gemini
يختبر Terminal-Bench 2.0 قدرات الوكيل البرمجي (Agent) في بيئة الطرفية (Terminal):
- Gemini 3.1 Pro: 68.5%
- Claude Opus 4.6: 65.4%
فارق 3.1 نقطة مئوية يوضح أن Gemini يمتلك قدرة تنفيذية أقوى في سيناريوهات وكلاء الطرفية.
البرمجة التنافسية: Gemini في المقدمة
تظهر بيانات LiveCodeBench Pro أن Gemini 3.1 Pro حقق 2887 نقطة في تصنيف Elo، مما يظهر أداءً ممتازاً في البرمجة التنافسية. لم يتم الكشف عن البيانات المقابلة لـ Claude Opus 4.6 بعد، ولكن بناءً على الأداء في مسابقات مثل USACO، فإن Claude يظل أيضاً في المستوى الأعلى.
# 通过 APIYI 同时测试两个模型的编码能力
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 统一接口
)
# 同一编码任务分别测试
coding_prompt = "实现一个 LRU Cache,支持 get 和 put 操作,时间复杂度 O(1)"
for model in ["gemini-3.1-pro-preview", "claude-opus-4-6"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": coding_prompt}]
)
print(f"\n{'='*50}")
print(f"模型: {model}")
print(f"Token 用量: {resp.usage.total_tokens}")
print(f"回答:\n{resp.choices[0].message.content[:500]}")
المقارنة 3: Gemini 3.1 Pro مقابل Claude Opus 4.6 في قدرات الوكيل (Agent)
تُعد الوكلاء (Agents) وسير العمل المستقل هي المشهد الأساسي لعام 2026. وهذا أحد المجالات التي يظهر فيها أكبر تباين بين النموذجين.
بحث الوكيل: تقارب بين العملاقين
يختبر معيار BrowseComp قدرة النموذج على البحث الذاتي في الويب واستخراج المعلومات:
- Gemini 3.1 Pro: 85.9%
- Claude Opus 4.6: 84.0%
الفجوة هي 1.9 نقطة مئوية فقط، وكلاهما في المستوى الأعلى عالمياً.
الوكلاء متعددو الخطوات: تفوق كبير لـ Gemini
يختبر معيار MCP Atlas سير العمل المعقد متعدد الخطوات، حيث سجل Gemini 3.1 Pro نسبة 69.2%، وهو ما يزيد بنحو 10 نقاط مئوية عن درجة Claude Opus 4.6 البالغة 59.5%. هذا أحد المعايير التي يظهر فيها أكبر اختلاف بين النموذجين.
تشغيل الكمبيوتر: ميزة حصرية لـ Claude
يقيس معيار OSWorld قدرة النموذج على تشغيل واجهة المستخدم الرسومية (GUI) الحقيقية، وقد سجل Claude Opus 4.6 درجة 72.7%. لم يعلن Gemini عن نتائج لهذه الفئة بعد. هذا يعني أنه إذا كنت بحاجة إلى ذكاء اصطناعي يقوم بتشغيل تطبيقات سطح المكتب تلقائياً، فإن Claude هو خيارك الوحيد حالياً.
المهام بمستوى الخبراء: تفوق واضح لـ Claude
يختبر GDPval-AA مهام مستوى الخبراء في بيئة مكتبية حقيقية (تحليل البيانات، كتابة التقارير، إلخ)، حيث بلغ تقييم Elo لنموذج Claude Opus 4.6 حوالي 1606، وهو ما يتجاوز بكثير تقييم Gemini البالغ 1317. وهذا يشير إلى أن Claude أكثر موثوقية في العمل المعرفي الذي يتطلب فهماً عميقاً وتنفيذاً دقيقاً.
| أبعاد الوكيل (Agent) | Gemini 3.1 Pro | Claude Opus 4.6 | الفجوة |
|---|---|---|---|
| BrowseComp (البحث) | 85.9% | 84.0% | +1.9pp |
| MCP Atlas (متعدد الخطوات) | 69.2% | 59.5% | +9.7pp |
| APEX-Agents (الدورات الطويلة) | 33.5% | 29.8% | +3.7pp |
| OSWorld (تشغيل الكمبيوتر) | — | 72.7% | حصري لـ Claude |
| GDPval-AA (مهام الخبراء) | 1317 Elo | 1606 Elo | +289 |
المقارنة 4: Gemini 3.1 Pro مقابل Claude Opus 4.6 في بنية نظام التفكير
يمتلك كلا النموذجين آلية "تفكير عميق"، لكن بفلسفات تصميم مختلفة.
Gemini 3.1 Pro: نظام تفكير ثلاثي المستويات
| المستوى | الاسم | الميزات | سيناريوهات الاستخدام |
|---|---|---|---|
| Low | استجابة سريعة | بدون تأخير تقريباً | الأسئلة والأجوبة البسيطة، الترجمة |
| Medium | استدلال متوازن | تأخير متوسط (جديد) | البرمجة اليومية، التحليل |
| High | Deep Think Mini | استدلال عميق، يحل مسائل IMO في 8 دقائق | الرياضيات، تصحيح الأخطاء المعقد |
وضع High في Gemini 3.1 Pro هو في الواقع نسخة مصغرة من Deep Think (نموذج الاستدلال المخصص من جوجل)، وهو ما يعادل دمج محرك استدلال مخصص داخل النموذج.
Claude Opus 4.6: نظام تفكير تكيفي
| المستوى | الاسم | الميزات | سيناريوهات الاستخدام |
|---|---|---|---|
| Low | الوضع السريع | أدنى تكلفة استدلال | المهام البسيطة |
| Medium | الوضع المتوازن | استدلال معتدل | التطوير الروتيني |
| High | الوضع العميق (افتراضي) | يحدد عمق الاستدلال تلقائياً | معظم المهام |
| Max | أقصى استدلال | استدلال بكامل القوة | المسائل الصعبة للغاية |
تتميز Claude بـ التفكير التكيفي — حيث يقرر النموذج تلقائياً مقدار موارد الاستدلال التي سيخصصها بناءً على تعقيد السؤال، دون حاجة المطور للاختيار يدوياً. الوضع الافتراضي High ذكي للغاية بالفعل.
🎯 مقارنة عملية: يوفر لك Gemini تحكماً يدوياً أكثر دقة (3 مستويات)، وهو مناسب للسيناريوهات التي تتطلب تحكماً دقيقاً في التكلفة والتأخير؛ بينما يوفر لك Claude تكيفاً تلقائياً أذكى (4 مستويات + تكيفي)، وهو مناسب لبيئات الإنتاج التي تعتمد مبدأ "اضبطه وانسه". يمكن استدعاء كلا النموذجين والمقارنة بينهما مباشرة على APIYI (apiyi.com).
المقارنة 5: Gemini 3.1 Pro مقابل Claude Opus 4.6 – التسعير والتكلفة
تعد التكلفة عاملاً حاسماً في بيئات الإنتاج. هناك فرق ملحوظ في السعر بين النموذجين.
| بُعد السعر | Gemini 3.1 Pro | Claude Opus 4.6 | نسبة السعر مقابل الأداء في Gemini |
|---|---|---|---|
| الإدخال (القياسي) | $2.00 / مليون توكن | $5.00 / مليون توكن | أرخص بـ 2.5 مرة |
| الإخراج (القياسي) | $12.00 / مليون توكن | $25.00 / مليون توكن | أرخص بـ 2.1 مرة |
| الإدخال (سياق طويل >200 ألف) | $4.00 / مليون توكن | $10.00 / مليون توكن | أرخص بـ 2.5 مرة |
| الإخراج (سياق طويل >200 ألف) | $18.00 / مليون توكن | $37.50 / مليون توكن | أرخص بـ 2.1 مرة |
تقدير التكلفة في السيناريوهات الواقعية
بناءً على معالجة مليون توكن إدخال + 200 ألف توكن إخراج يومياً:
| السيناريو | Gemini 3.1 Pro | Claude Opus 4.6 | التوفير الشهري |
|---|---|---|---|
| الاستخدام اليومي | $4.40 / يوم | $10.00 / يوم | 168 دولار / شهر |
| الاستخدام المكثف (3 أضعاف) | $13.20 / يوم | $30.00 / يوم | 504 دولار / شهر |
يأتي Gemini 3.1 Pro بنصف تكلفة Claude Opus 4.6 تقريباً في جميع أبعاد التسعير. بالنسبة للمشاريع الحساسة للتكلفة، تعد هذه ميزة كبيرة جداً.
💰 نصيحة لتحسين التكلفة: يمكنك استدعاء هذين النموذجين عبر منصة APIYI (apiyi.com) للاستمتاع بنظام فوترة مرن وإدارة موحدة. نوصي بإجراء اختبارات على دفعات صغيرة للتأكد من النتائج قبل اختيار النموذج الأساسي.
المقارنة 6: Gemini 3.1 Pro مقابل Claude Opus 4.6 – نافذة السياق والمخرجات
| المواصفات | Gemini 3.1 Pro | Claude Opus 4.6 | الطرف المتفوق |
|---|---|---|---|
| نافذة السياق | 1,000,000 توكن | 200,000 توكن (1 مليون في النسخة التجريبية) | Gemini |
| أقصى مخرجات | 64,000 توكن | 128,000 توكن | Claude |
| حجم الملف المرفوع | 100 ميجابايت | — | Gemini |
نافذة السياق: تفوق Gemini بـ 5 أضعاف
يدعم Gemini 3.1 Pro بشكل قياسي سياقاً يصل إلى مليون توكن، بينما يدعم Claude Opus 4.6 سياقاً قدره 200 ألف توكن (المليون توكن لا تزال في المرحلة التجريبية). تظهر ميزة Gemini بوضوح في السيناريوهات التي تتطلب تحليل مستودعات الأكواد الضخمة، أو المستندات الطويلة، أو مقاطع الفيديو.
أقصى مخرجات: تفوق Claude بالضعف
يدعم Claude Opus 4.6 مخرجات تصل إلى 128 ألف توكن، وهو ضعف ما يقدمه Gemini. هذا الأمر حيوي جداً لإنشاء النصوص الطويلة، وتوليد الأكواد البرمجية المفصلة، وسلاسل التفكير العميق؛ فمساحة المخرجات الأكبر تعني أن النموذج يمكنه "التفكير" بشكل أكثر استفاضة.
المقارنة 7: القدرات متعددة الوسائط بين Gemini 3.1 Pro و Claude Opus 4.6
تُعد القدرات متعددة الوسائط نقطة قوة تقليدية لنموذج Gemini.
| الوسيط | Gemini 3.1 Pro | Claude Opus 4.6 |
|---|---|---|
| إدخال النصوص | ✅ | ✅ |
| إدخال الصور | ✅ (أصيل) | ✅ |
| إدخال الفيديو | ✅ (أصيل) | ❌ |
| إدخال الصوت | ✅ (أصيل) | ❌ |
| معالجة ملفات PDF | ✅ | ✅ |
| رابط YouTube | ✅ | ❌ |
| توليد رسوم SVG | ✅ (أصيل) | ✅ |
يعتبر Gemini 3.1 Pro نموذجاً حقيقياً "شامل الوسائط" (Omni-modal)، حيث يدعم معمارياً وبشكل أصيل الفهم الموحد للنصوص والصور والصوت والفيديو. أما Claude Opus 4.6، فتقتصر قدراته متعددة الوسائط حالياً على النصوص والصور فقط.
إذا كان تطبيقك يتضمن تحليل الفيديو، أو تحويل الصوت إلى نصوص، أو فهم محتوى الوسائط المتعددة، فإن Gemini 3.1 Pro هو الخيار الوحيد المتاح حالياً.
المقارنة 8: الميزات الحصرية لكل من Gemini 3.1 Pro و Claude Opus 4.6
ميزات حصرية لـ Gemini 3.1 Pro
| الميزة | الوصف | القيمة |
|---|---|---|
| Deep Think Mini | محرك استنتاج مخصص مدمج في وضع High | استنتاج بمستوى الرياضيات/المسابقات |
| البحث المدعم (Grounding) | 5000 عملية بحث مجانية شهرياً | تعزيز المعلومات في الوقت الفعلي |
| رفع ملفات بحجم 100MB | رفع ملفات ضخمة في المرة الواحدة | قواعد كود ضخمة/تحليل بيانات |
| تحليل روابط YouTube | إدخال رابط الفيديو مباشرة لفهمه | تحليل محتوى الفيديو |
| فهم أصيل للصوت والفيديو | معالجة متعددة الوسائط من البداية للنهاية | تطبيقات الذكاء الاصطناعي للوسائط المتعددة |
ميزات حصرية لـ Claude Opus 4.6
| الميزة | الوصف | القيمة |
|---|---|---|
| تشغيل الكمبيوتر (OSWorld 72.7%) | التحكم التلقائي في واجهات المستخدم (GUI) | أتمتة العمليات (RPA)/الاختبار الآلي |
| التفكير التكيفي | تحديد عمق الاستنتاج تلقائياً | استنتاج ذكي بدون إعدادات مسبقة |
| مخرجات تصل لـ 128K | دعم مخرجات نصية طويلة جداً | توليد نصوص طويلة/استنتاج عميق |
| واجهة برمجة التطبيقات للدفعات (خصم 50%) | معالجة الدفعات بشكل غير متزامن | معالجة البيانات على نطاق واسع |
| الوضع السريع | معدل رسوم 6x مقابل مخرجات أسرع | سيناريوهات الإنتاج ذات التأخير المنخفض |
دليل اختيار السيناريو: Gemini 3.1 Pro مقابل Claude Opus 4.6
بناءً على مقارنة الأبعاد الثمانية المذكورة أعلاه، إليك توصيات محددة لاختيار النموذج حسب السيناريو:
سيناريوهات اختيار Gemini 3.1 Pro
| السيناريو | الميزة الأساسية | سبب التوصية |
|---|---|---|
| الاستدلال المجرد / الرياضيات | ARC-AGI-2 +8.3pp | وضع Deep Think Mini قوي جداً |
| الوكلاء (Agents) متعددو الخطوات | MCP Atlas +9.7pp | أقوى قدرة على تنفيذ سير العمل |
| تحليل الفيديو / الصوت | وسائط متعددة أصلية | الخيار الوحيد الذي يدعم جميع الوسائط بشكل أصلي |
| المشاريع الحساسة للتكلفة | أرخص بـ 2-2.5 مرة | جودة مماثلة بتكلفة أقل |
| تحليل المستندات الضخمة | سياق 1 مليون توكن | دعم قياسي لسياق ضخم جداً |
| البحث العلمي | GPQA +3.0pp | أقوى قدرة على الاستدلال العلمي |
سيناريوهات اختيار Claude Opus 4.6
| السيناريو | الميزة الأساسية | سبب التوصية |
|---|---|---|
| هندسة البرمجيات الواقعية | SWE-Bench 80.8% | الأكثر دقة في إصلاح الأخطاء البرمجية الحقيقية |
| العمل المعرفي بمستوى الخبراء | GDPval-AA +289 Elo | الأفضل في التقارير، التحليل، واتخاذ القرار |
| أتمتة الكمبيوتر | OSWorld 72.7% | الوحيد الذي يدعم عمليات واجهة المستخدم الرسومية (GUI) |
| الاستدلال المعزز بالأدوات | HLE+tools +1.7pp | التنسيق الأمثل بين أدوات متعددة |
| متطلبات المخرجات الطويلة جداً | مخرجات 128 ألف توكن | مناسب للمقالات الطويلة وسلاسل الاستدلال العميق |
| بيئات إنتاج ذات زمن انتقال منخفض | الوضع السريع | دفع مبالغ إضافية مقابل السرعة |
استخدام النموذجين معاً: بنية التوجيه الذكي
في العديد من بيئات الإنتاج، الحل الأمثل هو استخدام النموذجين في آن واحد، مع توجيه المهام ذكياً حسب نوعها:
| نوع المهمة | التوجيه إلى | السبب | النسبة التقديرية |
|---|---|---|---|
| الأسئلة والأجوبة العامة / الترجمة | Gemini 3.1 Pro | تكلفة منخفضة وجودة كافية | 40% |
| توليد الكود / تصحيح الأخطاء | Claude Opus 4.6 | تفوق طفيف في SWE-Bench | 20% |
| الاستدلال / الرياضيات / العلوم | Gemini 3.1 Pro | تفوق كبير في ARC-AGI-2 | 15% |
| سير عمل الوكلاء (Agents) | Gemini 3.1 Pro | تفوق في MCP Atlas بمقدار +9.7pp | 10% |
| التحليل والتقارير بمستوى الخبراء | Claude Opus 4.6 | تفوق واضح في GDPval-AA | 10% |
| معالجة الفيديو / الصوت | Gemini 3.1 Pro | الخيار الوحيد الذي يدعم جميع الوسائط | 5% |
باتباع هذه النسب في التوجيه، يمكن توفير حوالي 55% من التكلفة الإجمالية مقارنة باستخدام Claude وحده، مع الحصول على أفضل جودة في كل سيناريو فرعي.
استراتيجيات تحسين التكلفة بين Gemini 3.1 Pro و Claude Opus 4.6
الاستراتيجية 1: المعالجة المتدرجة
استخدم وضع Gemini Low للمهام البسيطة (الأسرع والأرخص)، وGemini Medium للمهام المتوسطة، وفقط للمهام المعقدة حقاً استخدم Claude High أو Gemini High (Deep Think Mini).
الاستراتيجية 2: الفصل بين المعالجة الدفعية والفورية
استخدم Gemini 3.1 Pro للطلبات الفورية (زمن انتقال منخفض وتكلفة منخفضة)، بينما يمكن استخدام Batch API الخاص بـ Claude للمعالجة الدفعية غير المتصلة بالإنترنت (خصم 50%)، مما يجعل التكلفة الإجمالية متقاربة.
الاستراتيجية 3: التخزين المؤقت للسياق (Context Caching)
يوفر Gemini ميزة التخزين المؤقت للسياق (الإدخال $0.20-$0.40 لكل مليون توكن). بالنسبة للسيناريوهات التي تعيد استخدام نفس المستند الطويل، يمكن أن تنخفض التكلفة بنسبة تزيد عن 80% بعد التخزين المؤقت.
🚀 تحقق سريع: من خلال منصة APIYI (apiyi.com)، يمكنك استدعاء كل من Gemini 3.1 Pro و Claude Opus 4.6 في وقت واحد باستخدام مفتاح API واحد. نوصي بإجراء اختبار A/B باستخدام موجه (prompt) عملك الفعلي، ويمكنك الحصول على النتائج في غضون 10 دقائق.
البدء السريع مع Gemini 3.1 Pro و Claude Opus 4.6
يوضح الكود التالي كيفية استخدام واجهة APIYI الموحدة لاستدعاء النموذجين معاً لإجراء اختبار مقارنة:
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # واجهة APIYI الموحدة
)
def compare_models(prompt, models=None):
"""مقارنة جودة وسرعة مخرجات النموذجين"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-opus-4-6"]
results = {}
for model in models:
start = time.time()
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
elapsed = time.time() - start
results[model] = {
"time": f"{elapsed:.2f}s",
"tokens": resp.usage.total_tokens,
"answer": resp.choices[0].message.content[:300]
}
for model, data in results.items():
print(f"\n{'='*50}")
print(f"النموذج: {model}")
print(f"الوقت المستغرق: {data['time']} | التوكنز: {data['tokens']}")
print(f"الإجابة: {data['answer']}...")
# اختبار قدرة الاستدلال
compare_models("يرجى شرح سبب عدم تساوي 0.1 + 0.2 لـ 0.3 باستخدام الاستدلال المتسلسل")
عرض الكود الكامل مع التحكم في مستوى التفكير (Thinking Level)
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def compare_with_thinking(prompt, thinking_config=None):
"""مقارنة أداء النماذج تحت مستويات تفكير مختلفة"""
configs = [
{"model": "gemini-3.1-pro-preview", "label": "Gemini Medium",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 8000}}},
{"model": "gemini-3.1-pro-preview", "label": "Gemini High (Deep Think Mini)",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 32000}}},
{"model": "claude-opus-4-6", "label": "Claude High (تلقائي افتراضي)",
"extra": {}},
]
for cfg in configs:
start = time.time()
params = {
"model": cfg["model"],
"messages": [{"role": "user", "content": prompt}],
**cfg["extra"]
}
resp = client.chat.completions.create(**params)
elapsed = time.time() - start
print(f"\n[{cfg['label']}] {elapsed:.2f}s | {resp.usage.total_tokens} tokens")
print(f" → {resp.choices[0].message.content[:200]}...")
# اختبار الاستدلال المعقد
compare_with_thinking("أثبت أنه: لكل عدد صحيح موجب n، فإن n^3 - n يقبل القسمة على 6")
الأسئلة الشائعة
س1: أيهما أفضل، Gemini 3.1 Pro أم Claude Opus 4.6؟
لا يوجد "أفضل" مطلق. يتفوق Gemini 3.1 Pro في الاستدلال المجرد (ARC-AGI-2 +8.3pp)، والوكلاء (Agents) متعددي الخطوات (MCP Atlas +9.7pp)، وتعدد الوسائط، والتكلفة؛ بينما يتميز Claude Opus 4.6 في هندسة البرمجيات الحقيقية (SWE-Bench)، ومهام المعرفة التخصصية (GDPval-AA +289 Elo)، وتشغيل الكمبيوتر، والاستدلال بالأدوات. نوصي بإجراء اختبار A/B في سيناريوهاتك الفعلية عبر APIYI apiyi.com.
س2: هل واجهات API للنموذجين متوافقة؟ وهل يسهل التبديل بينهما؟
من خلال منصة APIYI apiyi.com، يستخدم كلا النموذجين واجهة موحدة متوافقة مع OpenAI. للتبديل، ما عليك سوى تعديل معامل model (من gemini-3.1-pro-preview إلى claude-opus-4-6) دون الحاجة لتغيير أي كود آخر.
س3: أيهما أختار إذا كانت ميزانيتي محدودة؟
الأولوية لـ Gemini 3.1 Pro. سعر الإدخال فيه يمثل 40% فقط من سعر Claude Opus 4.6 (2 دولار مقابل 5 دولارات)، وسعر المخرجات أقل من النصف (12 دولاراً مقابل 25 دولاراً). في معظم المقاييس، أداء Gemini لا يقل عن منافسه بل وقد يتفوق عليه، مما يجعله ذا قيمة ممتازة مقابل السعر. استخدم Claude فقط في السيناريوهات التي يتفوق فيها بوضوح مثل SWE-Bench والمهام التخصصية.
س4: هل يمكن استخدام النموذجين معاً لعمل توجيه ذكي (Smart Routing)؟
نعم، يمكنك ذلك. البنية الموصى بها هي: استخدام Gemini 3.1 Pro لمعالجة 80% من الطلبات العادية (تكلفة منخفضة واستدلال قوي)، واستخدام Claude Opus 4.6 لمعالجة 20% من المهام التخصصية وسيناريوهات تعزيز الأدوات. عبر الواجهة الموحدة لـ APIYI apiyi.com، يمكنك تحقيق التوجيه الذكي ببساطة عن طريق تحديد نوع المهمة وتبديل معامل model في الكود.
ملخص: قرار الاختيار بين Gemini 3.1 Pro و Claude Opus 4.6
| # | بُعد المقارنة | Gemini 3.1 Pro | Claude Opus 4.6 | الفائز |
|---|---|---|---|---|
| 1 | الاستدلال المجرد | ARC-AGI-2 77.1% | 68.8% | Gemini |
| 2 | قدرات البرمجة | SWE-Bench 80.6% | 80.8% | Claude (بفارق ضئيل) |
| 3 | سير عمل الوكيل (Agent) | MCP Atlas 69.2% | 59.5% | Gemini |
| 4 | المهام التخصصية | GDPval 1317 | 1606 | Claude |
| 5 | تعدد الوسائط | شامل (نص/صورة/صوت/فيديو) | نص/صورة | Gemini |
| 6 | السعر | 2$/12$ لكل مليون توكن | 5$/25$ لكل مليون توكن | Gemini (أرخص بمرتين) |
| 7 | نافذة السياق | 1 مليون (قياسي) | 200 ألف (1 مليون تجريبي) | Gemini |
| 8 | أقصى مخرجات | 64 ألف توكن | 128 ألف توكن | Claude |
| 9 | نظام التفكير | المستوى 3 + Deep Think Mini | المستوى 4 + تكيفي | لكل منهما مميزاته |
| 10 | تشغيل الكمبيوتر | لا يدعم حالياً | OSWorld 72.7% | حصري لـ Claude |
التوصية النهائية:
- الأولوية للقيمة مقابل السعر ← Gemini 3.1 Pro (أرخص بمرتين واستدلال أقوى).
- الأولوية لهندسة البرمجيات ← Claude Opus 4.6 (متصدر في SWE-Bench و GDPval).
- الأولوية لتعدد الوسائط ← Gemini 3.1 Pro (الخيار الوحيد للوسائط المتعددة الشاملة).
- أفضل الممارسات ← استخدم كليهما مع التوجيه الذكي.
نوصي بالوصول إلى كلا النموذجين عبر منصة APIYI apiyi.com لتحقيق مرونة الجدولة واختبارات A/B باستخدام واجهة موحدة.
المصادر والمراجع
-
مدونة جوجل الرسمية: إعلان إطلاق Gemini 3.1 Pro
- الرابط:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - التوضيح: بيانات القياس الرسمية ومقدمة عن الميزات.
- الرابط:
-
إعلان Anthropic الرسمي: تفاصيل إطلاق Claude Opus 4.6
- الرابط:
anthropic.com/news/claude-opus-4-6 - التوضيح: المواصفات التقنية وبيانات القياس لنموذج Claude Opus 4.6.
- الرابط:
-
Artificial Analysis: تقييم مقارن من جهة خارجية
- الرابط:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - التوضيح: مقارنة معيارية مستقلة وتحليل للأداء.
- الرابط:
-
Google DeepMind: بطاقة النموذج وتقييم الأمان
- الرابط:
deepmind.google/models/model-cards/gemini-3-1-pro - التوضيح: المعايير التقنية التفصيلية وبيانات الأمان.
- الرابط:
-
VentureBeat: تجربة متعمقة لـ Deep Think Mini
- الرابط:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - التوضيح: التقييم الفعلي لنظام التفكير ثلاثي المستويات.
- الرابط:
📝 المؤلف: فريق APIYI | للتواصل التقني يرجى زيارة APIYI عبر apiyi.com
📅 تاريخ التحديث: 20 فبراير 2026
🏷️ الكلمات المفتاحية: Gemini 3.1 Pro vs Claude Opus 4.6، مقارنة النماذج، ARC-AGI-2، SWE-Bench، MCP Atlas، متعدد الوسائط، استدعاء واجهة برمجة التطبيقات (API)