Gemini 3.1 Pro Preview vs Claude Opus 4.6 该选谁? 这是 2026 年初 AI 开发者绕不开的抉择。本文从 10 个核心维度 进行全面对比,引用官方基准数据和第三方评测,帮你用数据做出明确选择。
核心价值: 看完本文,你将清楚知道在不同场景下应该选择哪个模型,以及如何在实际项目中快速验证。

Gemini 3.1 Pro vs Claude Opus 4.6 基准数据总览
在深入各维度之前,先看全局基准对比。谷歌官方宣称 Gemini 3.1 Pro 在 16 项基准中的 13 项领先,但 Claude Opus 4.6 在多个实战场景中胜出。
| 基准测试 | Gemini 3.1 Pro | Claude Opus 4.6 | 胜出 | 差距 |
|---|---|---|---|---|
| ARC-AGI-2 (抽象推理) | 77.1% | 68.8% | Gemini | +8.3pp |
| GPQA Diamond (PhD科学) | 94.3% | 91.3% | Gemini | +3.0pp |
| SWE-Bench Verified (软件工程) | 80.6% | 80.8% | Claude | +0.2pp |
| Terminal-Bench 2.0 (终端编码) | 68.5% | 65.4% | Gemini | +3.1pp |
| BrowseComp (Agent 搜索) | 85.9% | 84.0% | Gemini | +1.9pp |
| MCP Atlas (多步骤 Agent) | 69.2% | 59.5% | Gemini | +9.7pp |
| HLE 无工具 (终极考试) | 44.4% | 40.0% | Gemini | +4.4pp |
| HLE 有工具 (终极考试) | 51.4% | 53.1% | Claude | +1.7pp |
| SciCode (科研编码) | 59% | 52% | Gemini | +7pp |
| MMMLU (多语言QA) | 92.6% | 91.1% | Gemini | +1.5pp |
| tau2-bench Retail (工具调用) | 90.8% | 91.9% | Claude | +1.1pp |
| GDPval-AA Elo (专家任务) | 1317 | 1606 | Claude | +289 |
📊 数据说明: 以上数据来源于谷歌官方博客、Anthropic 官方公告及 Artificial Analysis 第三方评测。通过 API易 apiyi.com 可以同时调用两个模型进行实际场景验证。
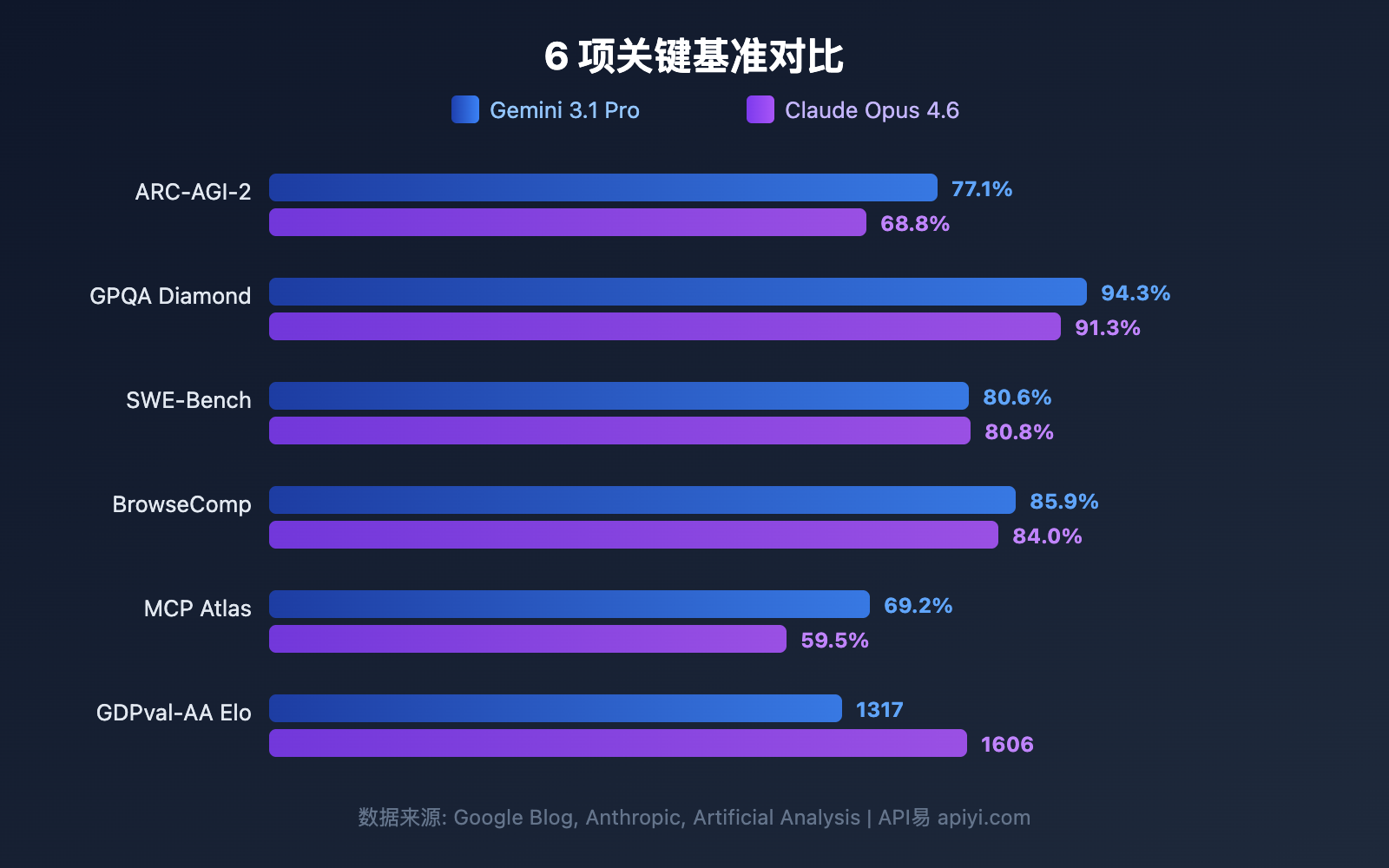
对比 1: Gemini 3.1 Pro vs Claude Opus 4.6 推理能力
推理能力是大模型的核心竞争力。两个模型的推理架构差异显著。
抽象推理: Gemini 3.1 Pro 领先明显
ARC-AGI-2 是目前最权威的抽象推理基准,Gemini 3.1 Pro 得分 77.1%,比 Claude Opus 4.6 的 68.8% 高出 8.3 个百分点。这意味着在需要从少量示例中归纳规则的任务中,Gemini 更强。
PhD 级科学推理: Gemini 优势突出
GPQA Diamond 测试 PhD 级别的科学问题,Gemini 3.1 Pro 得分 94.3%,Claude Opus 4.6 得分 91.3%。3 个百分点的差距在这个难度级别上非常显著。
工具增强推理: Claude 反超
HLE (Humanity's Last Exam) 在无工具条件下 Gemini 领先 (44.4% vs 40.0%),但引入工具后 Claude 反超 (53.1% vs 51.4%)。这表明 Claude Opus 4.6 在利用外部工具辅助推理方面更出色。
| 推理子维度 | Gemini 3.1 Pro | Claude Opus 4.6 | 适合谁 |
|---|---|---|---|
| 抽象推理 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 模式识别、规则归纳 |
| 科学推理 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 学术研究、论文辅助 |
| 工具推理 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 复杂工作流、多工具协同 |
| 数学推理 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Deep Think Mini 专长 |
对比 2: Gemini 3.1 Pro vs Claude Opus 4.6 编码能力
编码能力是开发者最关心的维度。两个模型的表现非常接近,但各有侧重。
SWE-Bench: 几乎持平
SWE-Bench Verified 是真实 GitHub 问题修复基准:
- Claude Opus 4.6: 80.8% (微弱领先)
- Gemini 3.1 Pro: 80.6%
仅 0.2 个百分点的差距,基本可以认为两者在真实软件工程任务上能力相当。
Terminal-Bench: Gemini 占优
Terminal-Bench 2.0 测试终端环境下的 Agent 编码能力:
- Gemini 3.1 Pro: 68.5%
- Claude Opus 4.6: 65.4%
3.1 个百分点的差距说明 Gemini 在终端 Agent 场景下执行力更强。
竞赛编程: Gemini 领先
LiveCodeBench Pro 数据显示 Gemini 3.1 Pro 达到 2887 Elo,在竞赛编程上表现出色。Claude Opus 4.6 的对应数据暂未公开,但从 USACO 等竞赛表现来看,Claude 也是顶级水平。
# 通过 API易 同时测试两个模型的编码能力
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易 统一接口
)
# 同一编码任务分别测试
coding_prompt = "实现一个 LRU Cache,支持 get 和 put 操作,时间复杂度 O(1)"
for model in ["gemini-3.1-pro-preview", "claude-opus-4-6"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": coding_prompt}]
)
print(f"\n{'='*50}")
print(f"模型: {model}")
print(f"Token 用量: {resp.usage.total_tokens}")
print(f"回答:\n{resp.choices[0].message.content[:500]}")
对比 3: Gemini 3.1 Pro vs Claude Opus 4.6 Agent 能力
Agent 和自主工作流是 2026 年的核心场景。这是两个模型差异最大的领域之一。
Agent 搜索: 两强接近
BrowseComp 测试模型的自主网页搜索和信息提取能力:
- Gemini 3.1 Pro: 85.9%
- Claude Opus 4.6: 84.0%
差距仅 1.9 个百分点,两者都是顶级水平。
多步骤 Agent: Gemini 大幅领先
MCP Atlas 测试复杂多步骤工作流,Gemini 3.1 Pro 得分 69.2%,比 Claude Opus 4.6 的 59.5% 高出近 10 个百分点。这是两个模型差异最大的基准之一。
计算机操作: Claude 独占优势
OSWorld 基准测试模型操作真实 GUI 的能力,Claude Opus 4.6 得分 72.7%。Gemini 暂未公布该项成绩。这意味着如果你需要 AI 自动操作桌面应用,Claude 是当前唯一选择。
专家级任务: Claude 明显领先
GDPval-AA 测试真实办公环境中的专家级任务 (数据分析、报告撰写等),Claude Opus 4.6 的 Elo 评分 1606,远超 Gemini 的 1317。这说明在需要深度理解和精细执行的知识工作中,Claude 更可靠。
| Agent 子维度 | Gemini 3.1 Pro | Claude Opus 4.6 | 差距 |
|---|---|---|---|
| BrowseComp (搜索) | 85.9% | 84.0% | +1.9pp |
| MCP Atlas (多步骤) | 69.2% | 59.5% | +9.7pp |
| APEX-Agents (长周期) | 33.5% | 29.8% | +3.7pp |
| OSWorld (计算机操作) | — | 72.7% | Claude 独占 |
| GDPval-AA (专家任务) | 1317 Elo | 1606 Elo | +289 |
对比 4: Gemini 3.1 Pro vs Claude Opus 4.6 思考系统架构
两个模型都有「深度思考」机制,但设计理念不同。
Gemini 3.1 Pro: 三级思考系统
| 级别 | 名称 | 特点 | 适用场景 |
|---|---|---|---|
| Low | 快速响应 | 几乎无延迟 | 简单问答、翻译 |
| Medium | 平衡推理 | 中等延迟 (新增) | 日常编码、分析 |
| High | Deep Think Mini | 深度推理,8 分钟解 IMO 题 | 数学、复杂调试 |
Gemini 3.1 Pro 的 High 模式实际上是 Deep Think (谷歌专用推理模型) 的迷你版,相当于在一个模型内嵌入了专用推理引擎。
Claude Opus 4.6: 自适应思考系统
| 级别 | 名称 | 特点 | 适用场景 |
|---|---|---|---|
| Low | 快速模式 | 最小推理开销 | 简单任务 |
| Medium | 平衡模式 | 适度推理 | 常规开发 |
| High | 深度模式 (默认) | 自动判断推理深度 | 大多数任务 |
| Max | 最大推理 | 全力推理 | 极难问题 |
Claude 的特色是自适应思考 — 模型会根据问题复杂度自动决定投入多少推理资源,开发者无需手动选择。默认 High 模式已经非常智能。
🎯 实用对比: Gemini 给你更精细的手动控制 (3 级),适合需要精确控制成本和延迟的场景; Claude 给你更智能的自动适配 (4 级 + 自适应),适合「设好就不管」的生产环境。两个模型都可以在 API易 apiyi.com 上直接调用和对比。
对比 5: Gemini 3.1 Pro vs Claude Opus 4.6 定价和成本
成本是生产环境中的关键考量。两个模型的价格差异显著。
| 价格维度 | Gemini 3.1 Pro | Claude Opus 4.6 | Gemini 性价比 |
|---|---|---|---|
| 输入 (标准) | $2.00 / 1M tokens | $5.00 / 1M tokens | 2.5x 更便宜 |
| 输出 (标准) | $12.00 / 1M tokens | $25.00 / 1M tokens | 2.1x 更便宜 |
| 输入 (长上下文 >200K) | $4.00 / 1M tokens | $10.00 / 1M tokens | 2.5x 更便宜 |
| 输出 (长上下文 >200K) | $18.00 / 1M tokens | $37.50 / 1M tokens | 2.1x 更便宜 |
实际场景成本估算
以每天处理 100 万输入 token + 20 万输出 token 计算:
| 场景 | Gemini 3.1 Pro | Claude Opus 4.6 | 月节省 |
|---|---|---|---|
| 日常调用 | $4.40/天 | $10.00/天 | $168/月 |
| 重度使用 (3x) | $13.20/天 | $30.00/天 | $504/月 |
Gemini 3.1 Pro 在所有价格维度上都是 Claude Opus 4.6 的一半左右。对于成本敏感的项目,这是一个非常显著的优势。
💰 成本优化建议: 通过 API易 apiyi.com 平台调用这两个模型,可以享受灵活计费和统一管理。建议先用小批量测试确认效果,再决定主力模型。
对比 6: Gemini 3.1 Pro vs Claude Opus 4.6 上下文窗口和输出
| 规格 | Gemini 3.1 Pro | Claude Opus 4.6 | 优势方 |
|---|---|---|---|
| 上下文窗口 | 1,000,000 tokens | 200,000 tokens (1M beta) | Gemini |
| 最大输出 | 64,000 tokens | 128,000 tokens | Claude |
| 上传文件大小 | 100MB | — | Gemini |
上下文窗口: Gemini 5 倍领先
Gemini 3.1 Pro 标准支持 100 万 token 上下文,Claude Opus 4.6 标准是 20 万 (1M 在 beta 中)。对于需要分析大型代码仓库、长文档或视频的场景,Gemini 的优势非常明显。
最大输出: Claude 翻倍领先
Claude Opus 4.6 支持 128K token 输出,是 Gemini 的 2 倍。这对于长文生成、详细代码生成和深度推理链条至关重要——更长的输出空间意味着模型可以进行更充分的「思考」。
对比 7: Gemini 3.1 Pro vs Claude Opus 4.6 多模态能力
多模态能力是 Gemini 的传统强项。
| 模态 | Gemini 3.1 Pro | Claude Opus 4.6 |
|---|---|---|
| 文本输入 | ✅ | ✅ |
| 图像输入 | ✅ (原生) | ✅ |
| 视频输入 | ✅ (原生) | ❌ |
| 音频输入 | ✅ (原生) | ❌ |
| PDF 处理 | ✅ | ✅ |
| YouTube URL | ✅ | ❌ |
| SVG 生成 | ✅ (原生) | ✅ |
Gemini 3.1 Pro 是真正的全模态模型,从训练架构上就原生支持文本、图像、音频、视频的统一理解。Claude Opus 4.6 的多模态限于文本和图像。
如果你的应用涉及视频分析、音频转写或多媒体内容理解,Gemini 3.1 Pro 是目前唯一支持的选择。
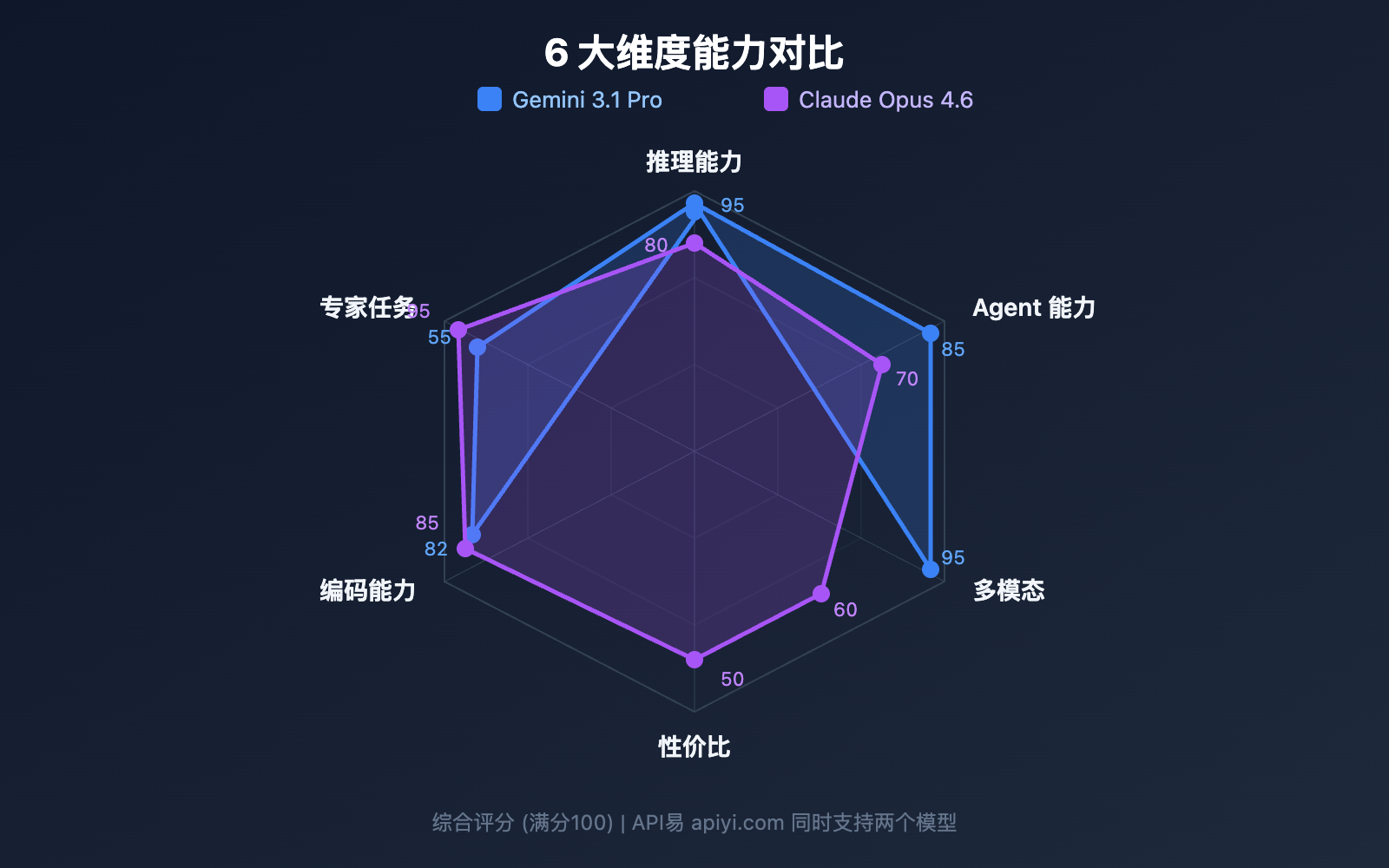
对比 8: Gemini 3.1 Pro vs Claude Opus 4.6 独有特性
Gemini 3.1 Pro 独有
| 特性 | 说明 | 价值 |
|---|---|---|
| Deep Think Mini | High 模式内嵌专用推理引擎 | 数学/竞赛级推理 |
| 搜索落地 (Grounding) | 每月 5000 次免费搜索 | 实时信息增强 |
| 100MB 文件上传 | 单次上传大型文件 | 大型代码库/数据分析 |
| YouTube URL 分析 | 直接输入视频 URL 进行理解 | 视频内容分析 |
| 音视频原生理解 | 端到端多模态处理 | 多媒体 AI 应用 |
Claude Opus 4.6 独有
| 特性 | 说明 | 价值 |
|---|---|---|
| 计算机操作 (OSWorld 72.7%) | 自动操作 GUI 界面 | RPA/自动化测试 |
| 自适应思考 | 自动判断推理深度 | 零配置智能推理 |
| 128K 输出 | 超长输出支持 | 长文生成/深度推理 |
| 批量 API (50% 折扣) | 异步批量处理 | 大规模数据处理 |
| 快速模式 | 6x 费率换取更快输出 | 低延迟生产场景 |
Gemini 3.1 Pro vs Claude Opus 4.6 场景选择指南
根据以上 8 个维度的对比,以下是明确的场景推荐:
选择 Gemini 3.1 Pro 的场景
| 场景 | 关键优势 | 推荐理由 |
|---|---|---|
| 抽象推理/数学 | ARC-AGI-2 +8.3pp | Deep Think Mini 极强 |
| 多步骤 Agent | MCP Atlas +9.7pp | 工作流执行力最强 |
| 视频/音频分析 | 原生多模态 | 唯一全模态选择 |
| 成本敏感项目 | 价格便宜 2-2.5x | 同等质量更低成本 |
| 大型文档分析 | 1M 上下文 | 超大上下文标准支持 |
| 科学研究 | GPQA +3.0pp | 科学推理能力最强 |
选择 Claude Opus 4.6 的场景
| 场景 | 关键优势 | 推荐理由 |
|---|---|---|
| 真实软件工程 | SWE-Bench 80.8% | 修复实际 Bug 最准 |
| 专家级知识工作 | GDPval-AA +289 Elo | 报告/分析/决策最强 |
| 计算机自动化 | OSWorld 72.7% | 唯一支持 GUI 操作 |
| 工具增强推理 | HLE+tools +1.7pp | 多工具协同最优 |
| 超长输出需求 | 128K 输出 | 长文/深度推理链 |
| 低延迟生产环境 | 快速模式 | 付费换速度 |
两个都用: 智能路由架构
很多生产环境中,最优解是同时使用两个模型,按任务类型智能路由:
| 任务类型 | 路由到 | 原因 | 预估占比 |
|---|---|---|---|
| 常规问答/翻译 | Gemini 3.1 Pro | 成本低,质量足够 | 40% |
| 代码生成/调试 | Claude Opus 4.6 | SWE-Bench 略优 | 20% |
| 推理/数学/科学 | Gemini 3.1 Pro | ARC-AGI-2 大幅领先 | 15% |
| Agent 工作流 | Gemini 3.1 Pro | MCP Atlas +9.7pp | 10% |
| 专家级分析/报告 | Claude Opus 4.6 | GDPval-AA 明显领先 | 10% |
| 视频/音频处理 | Gemini 3.1 Pro | 唯一全模态选择 | 5% |
按上述比例路由,整体成本相比全用 Claude 可节省约 55%,同时在各细分场景都获得最优质量。
Gemini 3.1 Pro vs Claude Opus 4.6 成本优化策略
策略 1: 分级处理
简单任务用 Gemini Low 模式 (最快最便宜),中等任务用 Gemini Medium,只有真正复杂的任务才用 Claude High 或 Gemini High (Deep Think Mini)。
策略 2: 批量与实时分离
实时请求用 Gemini 3.1 Pro (低延迟、低成本),离线批量处理可以用 Claude 的 Batch API (50% 折扣),综合成本接近。
策略 3: 上下文缓存
Gemini 提供上下文缓存 (输入 $0.20-$0.40/MTok),对于重复使用同一长文档的场景,缓存后成本可降低 80% 以上。
🚀 快速验证: 通过 API易 apiyi.com 平台,你可以用同一个 API Key 同时调用 Gemini 3.1 Pro 和 Claude Opus 4.6。建议先用实际业务 prompt 做 A/B 测试,10 分钟即可得出结论。
Gemini 3.1 Pro vs Claude Opus 4.6 快速上手
以下代码演示如何通过 API易 统一接口同时调用两个模型进行对比测试:
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易 统一接口
)
def compare_models(prompt, models=None):
"""对比两个模型的输出质量和速度"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-opus-4-6"]
results = {}
for model in models:
start = time.time()
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
elapsed = time.time() - start
results[model] = {
"time": f"{elapsed:.2f}s",
"tokens": resp.usage.total_tokens,
"answer": resp.choices[0].message.content[:300]
}
for model, data in results.items():
print(f"\n{'='*50}")
print(f"模型: {model}")
print(f"耗时: {data['time']} | Token: {data['tokens']}")
print(f"回答: {data['answer']}...")
# 测试推理能力
compare_models("请用链式推理解释为什么 0.1 + 0.2 不等于 0.3")
查看带思考级别控制的完整代码
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def compare_with_thinking(prompt, thinking_config=None):
"""对比不同思考级别下的模型表现"""
configs = [
{"model": "gemini-3.1-pro-preview", "label": "Gemini Medium",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 8000}}},
{"model": "gemini-3.1-pro-preview", "label": "Gemini High (Deep Think Mini)",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 32000}}},
{"model": "claude-opus-4-6", "label": "Claude High (默认自适应)",
"extra": {}},
]
for cfg in configs:
start = time.time()
params = {
"model": cfg["model"],
"messages": [{"role": "user", "content": prompt}],
**cfg["extra"]
}
resp = client.chat.completions.create(**params)
elapsed = time.time() - start
print(f"\n[{cfg['label']}] {elapsed:.2f}s | {resp.usage.total_tokens} tokens")
print(f" → {resp.choices[0].message.content[:200]}...")
# 测试复杂推理
compare_with_thinking("证明: 对于所有正整数 n, n^3 - n 能被 6 整除")
常见问题
Q1: Gemini 3.1 Pro 和 Claude Opus 4.6 哪个更好?
没有绝对的「更好」。Gemini 3.1 Pro 在抽象推理 (ARC-AGI-2 +8.3pp)、多步骤 Agent (MCP Atlas +9.7pp)、多模态和成本上领先; Claude Opus 4.6 在真实软件工程 (SWE-Bench)、专家知识工作 (GDPval-AA +289 Elo)、计算机操作和工具推理上占优。建议通过 API易 apiyi.com 在你的实际场景中做 A/B 测试。
Q2: 两个模型的 API 接口兼容吗? 能方便切换吗?
通过 API易 apiyi.com 平台,两个模型使用统一的 OpenAI 兼容接口。切换只需修改 model 参数 (gemini-3.1-pro-preview → claude-opus-4-6),其他代码完全不用改。
Q3: 预算有限应该选哪个?
优先选择 Gemini 3.1 Pro。它的输入价格是 Claude Opus 4.6 的 40% ($2 vs $5),输出价格不到一半 ($12 vs $25)。在大多数基准上 Gemini 表现不输甚至更强,性价比极高。只在 SWE-Bench、专家任务等 Claude 明显占优的场景用 Claude。
Q4: 能同时用两个模型做智能路由吗?
可以。推荐的架构是: 用 Gemini 3.1 Pro 处理 80% 的常规请求 (成本低、推理强),Claude Opus 4.6 处理 20% 的专家级任务和工具增强场景。通过 API易 apiyi.com 的统一接口,只需在代码中判断任务类型并切换 model 参数即可实现智能路由。
总结: Gemini 3.1 Pro vs Claude Opus 4.6 选择决策
| # | 对比维度 | Gemini 3.1 Pro | Claude Opus 4.6 | 胜出 |
|---|---|---|---|---|
| 1 | 抽象推理 | ARC-AGI-2 77.1% | 68.8% | Gemini |
| 2 | 编码能力 | SWE-Bench 80.6% | 80.8% | Claude (微弱) |
| 3 | Agent 工作流 | MCP Atlas 69.2% | 59.5% | Gemini |
| 4 | 专家任务 | GDPval 1317 | 1606 | Claude |
| 5 | 多模态 | 全模态 (文/图/音/视频) | 文/图 | Gemini |
| 6 | 价格 | $2/$12 per MTok | $5/$25 per MTok | Gemini (2x便宜) |
| 7 | 上下文窗口 | 1M (标准) | 200K (1M beta) | Gemini |
| 8 | 最大输出 | 64K tokens | 128K tokens | Claude |
| 9 | 思考系统 | 3级 + Deep Think Mini | 4级 + 自适应 | 各有千秋 |
| 10 | 计算机操作 | 暂不支持 | OSWorld 72.7% | Claude 独占 |
最终建议:
- 性价比优先 → Gemini 3.1 Pro (便宜 2 倍,推理更强)
- 软件工程优先 → Claude Opus 4.6 (SWE-Bench、GDPval 领先)
- 多模态优先 → Gemini 3.1 Pro (全模态唯一选择)
- 最佳实践 → 两个都用,智能路由
推荐通过 API易 apiyi.com 平台同时接入两个模型,用统一接口实现灵活调度和 A/B 测试。
参考资料
-
Google 官方博客: Gemini 3.1 Pro 发布公告
- 链接:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - 说明: 官方基准数据和功能介绍
- 链接:
-
Anthropic 官方公告: Claude Opus 4.6 发布详情
- 链接:
anthropic.com/news/claude-opus-4-6 - 说明: Claude Opus 4.6 技术规格和基准数据
- 链接:
-
Artificial Analysis: 第三方对比评测
- 链接:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - 说明: 独立基准对比和性能分析
- 链接:
-
Google DeepMind: 模型卡和安全评估
- 链接:
deepmind.google/models/model-cards/gemini-3-1-pro - 说明: 详细技术参数和安全性数据
- 链接:
-
VentureBeat: Deep Think Mini 深度体验
- 链接:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - 说明: 三级思考系统实际测评
- 链接:
📝 作者: APIYI Team | 技术交流请访问 API易 apiyi.com
📅 更新时间: 2026 年 2 月 20 日
🏷️ 关键词: Gemini 3.1 Pro vs Claude Opus 4.6, 模型对比, ARC-AGI-2, SWE-Bench, MCP Atlas, 多模态, API 调用