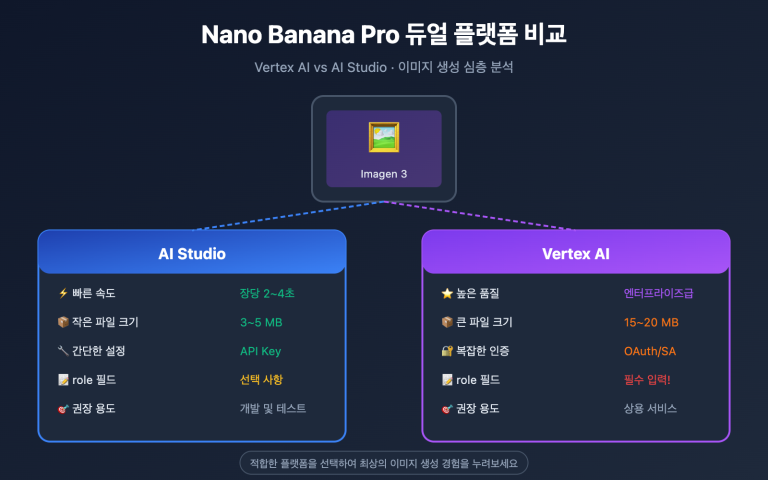
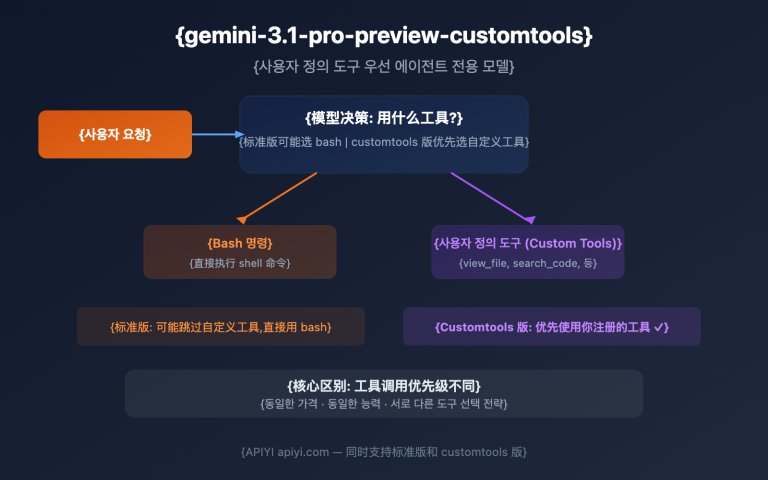
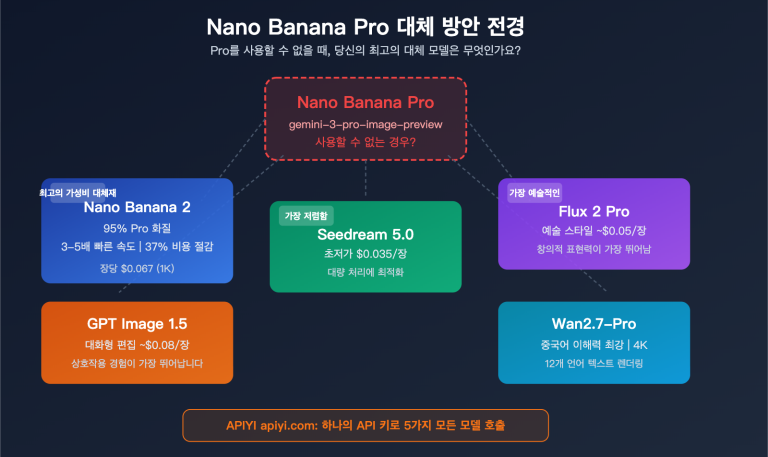
Gemini 3.1 Pro Preview vs Claude Opus 4.6, 누구를 선택해야 할까요? 이는 2026년 초 AI 개발자라면 피할 수 없는 선택입니다. 이 글에서는 10가지 핵심 차원에서 두 모델을 전격 비교하고, 공식 벤치마크 데이터와 제3자 평가를 인용하여 여러분이 데이터를 바탕으로 명확한 결정을 내릴 수 있도록 도와드릴게요.
핵심 가치: 이 글을 읽고 나면 다양한 시나리오에서 어떤 모델을 선택해야 하는지, 그리고 실제 프로젝트에서 어떻게 성능을 빠르게 검증할 수 있는지 명확하게 알게 되실 거예요.

对比 8: Gemini 3.1 Pro vs Claude Opus 4.6 独有特性
Gemini 3.1 Pro 独有
| 特性 | 说明 | 价值 |
|---|---|---|
| Deep Think Mini | High 模式内嵌专用推理引擎 | 数学/竞赛级推理 |
| 搜索落地 (Grounding) | 每月 5000 次免费搜索 | 实时信息增强 |
| 100MB 文件上传 | 单次上传大型文件 | 大型代码库/数据分析 |
| YouTube URL 分析 | 直接输入视频 URL 进行理解 | 视频内容分析 |
| 音视频原生理解 | 端到端多模态处理 | 多媒体 AI 应用 |
Claude Opus 4.6 独有
| 特性 | 说明 | 价值 |
|---|---|---|
| 计算机操作 (OSWorld 72.7%) | 自动操作 GUI 界面 | RPA/自动化测试 |
| 自适应思考 | 自动判断推理深度 | 零配置智能推理 |
| 128K 输出 | 超长输出支持 | 长文生成/深度推理 |
| 批量 API (50% 折扣) | 异步批量处理 | 大规模数据处理 |
| 快速模式 | 6x 费率换取更快输出 | 低延迟生产场景 |
Gemini 3.1 Pro vs Claude Opus 4.6 시나리오별 선택 가이드
앞서 살펴본 8가지 차원의 비교를 바탕으로, 상황에 맞는 명확한 모델 선택 가이드를 정리해 드립니다.
Gemini 3.1 Pro를 선택해야 하는 경우
| 시나리오 | 핵심 장점 | 추천 이유 |
|---|---|---|
| 추상적 추론/수학 | ARC-AGI-2 +8.3pp | Deep Think Mini의 강력한 성능 |
| 다단계 에이전트 | MCP Atlas +9.7pp | 워크플로우 실행력이 가장 뛰어남 |
| 비디오/오디오 분석 | 네이티브 멀티모달 | 유일한 풀 멀티모달(Full-modal) 선택지 |
| 비용 민감 프로젝트 | 2~2.5배 저렴한 가격 | 동일한 품질을 더 낮은 비용으로 구현 |
| 대규모 문서 분석 | 1M 컨텍스트 | 초거대 컨텍스트 표준 지원 |
| 과학 연구 | GPQA +3.0pp | 과학적 추론 능력이 가장 강력함 |
Claude Opus 4.6을 선택해야 하는 경우
| 시나리오 | 핵심 장점 | 추천 이유 |
|---|---|---|
| 실제 소프트웨어 공학 | SWE-Bench 80.8% | 실제 버그 수정 정확도가 가장 높음 |
| 전문가급 지식 작업 | GDPval-AA +289 Elo | 보고서/분석/의사결정에 최적화 |
| 컴퓨터 자동화 | OSWorld 72.7% | GUI 조작을 지원하는 유일한 모델 |
| 도구 강화 추론 | HLE+tools +1.7pp | 여러 도구 간의 협업 능력이 뛰어남 |
| 초장문 출력 요구 | 128K 출력 | 긴 글 작성 및 깊이 있는 추론 체인에 유리 |
| 저지연 생산 환경 | 빠른 모드(Fast Mode) | 비용을 투자해 속도를 확보해야 할 때 |
둘 다 사용하기: 스마트 라우팅 아키텍처
많은 실제 운영 환경에서 가장 좋은 해결책은 두 모델을 동시에 사용하면서 작업 유형에 따라 스마트하게 라우팅하는 것입니다.
| 작업 유형 | 라우팅 대상 | 이유 | 예상 비중 |
|---|---|---|---|
| 일반 질의응답/번역 | Gemini 3.1 Pro | 낮은 비용으로 충분한 품질 확보 | 40% |
| 코드 생성/디버깅 | Claude Opus 4.6 | SWE-Bench 성능 우위 | 20% |
| 추론/수학/과학 | Gemini 3.1 Pro | ARC-AGI-2에서 큰 폭으로 앞섬 | 15% |
| 에이전트 워크플로우 | Gemini 3.1 Pro | MCP Atlas +9.7pp | 10% |
| 전문가급 분석/보고서 | Claude Opus 4.6 | GDPval-AA 성능 우위 | 10% |
| 비디오/오디오 처리 | Gemini 3.1 Pro | 유일한 풀 멀티모달 선택지 | 5% |
위 비율대로 라우팅을 구성하면, Claude만 사용할 때보다 전체 비용을 약 55% 절감하면서도 각 세부 시나리오에서 최상의 품질을 얻을 수 있습니다.
Gemini 3.1 Pro vs Claude Opus 4.6 비용 최적화 전략
전략 1: 계층별 처리
단순한 작업은 Gemini Low 모드(가장 빠르고 저렴함)를 사용하고, 중간 난이도는 Gemini Medium, 정말 복잡한 작업에만 Claude High 또는 Gemini High(Deep Think Mini)를 할당하세요.
전략 2: 배치와 실시간 분리
실시간 요청에는 Gemini 3.1 Pro(저지연, 저비용)를 사용하고, 오프라인 배치 작업에는 Claude의 Batch API(50% 할인)를 활용하면 종합적인 비용을 비슷하게 맞출 수 있습니다.
전략 3: 컨텍스트 캐싱
Gemini는 컨텍스트 캐싱(입력 $0.20-$0.40/MTok)을 제공합니다. 동일한 긴 문서를 반복해서 사용하는 시나리오에서는 캐싱을 통해 비용을 80% 이상 줄일 수 있습니다.
🚀 빠른 검증: APIYI(apiyi.com) 플랫폼을 이용하면 하나의 API Key로 Gemini 3.1 Pro와 Claude Opus 4.6을 동시에 호출할 수 있습니다. 실제 비즈니스 프롬프트로 A/B 테스트를 진행해 보세요. 10분이면 결론을 내릴 수 있습니다.
Gemini 3.1 Pro vs Claude Opus 4.6 빠른 시작 가이드
다음은 APIYI 통합 인터페이스를 통해 두 모델을 동시에 호출하여 비교 테스트하는 Python 코드 예시입니다.
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 통합 인터페이스
)
def compare_models(prompt, models=None):
"""두 모델의 출력 품질과 속도를 비교합니다."""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-opus-4-6"]
results = {}
for model in models:
start = time.time()
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
elapsed = time.time() - start
results[model] = {
"time": f"{elapsed:.2f}s",
"tokens": resp.usage.total_tokens,
"answer": resp.choices[0].message.content[:300]
}
for model, data in results.items():
print(f"\n{'='*50}")
print(f"모델: {model}")
print(f"소요 시간: {data['time']} | 토큰 수: {data['tokens']}")
print(f"답변: {data['answer']}...")
# 추론 능력 테스트
compare_models("0.1 + 0.2가 왜 0.3과 같지 않은지 단계별 추론(Chain of Thought)으로 설명해 주세요.")
사고 수준(Thinking Level) 제어가 포함된 전체 코드 보기
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def compare_with_thinking(prompt, thinking_config=None):
"""다양한 사고 수준에 따른 모델 성능을 비교합니다."""
configs = [
{"model": "gemini-3.1-pro-preview", "label": "Gemini Medium",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 8000}}},
{"model": "gemini-3.1-pro-preview", "label": "Gemini High (Deep Think Mini)",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 32000}}},
{"model": "claude-opus-4-6", "label": "Claude High (기본 적응형)",
"extra": {}},
]
for cfg in configs:
start = time.time()
params = {
"model": cfg["model"],
"messages": [{"role": "user", "content": prompt}],
**cfg["extra"]
}
resp = client.chat.completions.create(**params)
elapsed = time.time() - start
print(f"\n[{cfg['label']}] {elapsed:.2f}s | {resp.usage.total_tokens} tokens")
print(f" → {resp.choices[0].message.content[:200]}...")
# 복잡한 추론 테스트
compare_with_thinking("증명: 모든 양의 정수 n에 대하여, n^3 - n은 6으로 나누어떨어진다.")
자주 묻는 질문 (FAQ)
Q1: Gemini 3.1 Pro와 Claude Opus 4.6 중 어떤 것이 더 좋은가요?
절대적으로 '더 나은' 모델은 없습니다. Gemini 3.1 Pro는 추상적 추론(ARC-AGI-2 +8.3pp), 다단계 에이전트(MCP Atlas +9.7pp), 멀티모달 기능 및 비용 측면에서 앞서 있습니다. 반면 Claude Opus 4.6은 실제 소프트웨어 엔지니어링(SWE-Bench), 전문가 지식 작업(GDPval-AA +289 Elo), 컴퓨터 조작 및 도구 추론에서 우위를 점합니다. APIYI(apiyi.com)를 통해 실제 사용 환경에서 A/B 테스트를 해보시는 것을 추천드려요.
Q2: 두 모델의 API 인터페이스가 호환되나요? 쉽게 교체할 수 있을까요?
APIYI(apiyi.com) 플랫폼을 이용하면 두 모델 모두 통일된 OpenAI 호환 인터페이스를 사용합니다. model 파라미터만 수정하면(gemini-3.1-pro-preview → claude-opus-4-6) 다른 코드는 전혀 고칠 필요 없이 바로 교체할 수 있어 매우 편리합니다.
Q3: 예산이 한정적이라면 어떤 모델을 선택해야 할까요?
Gemini 3.1 Pro를 우선적으로 고려해 보세요. 입력 비용은 Claude Opus 4.6의 40%($2 vs $5), 출력 비용은 절반 미만($12 vs $25) 수준입니다. 대부분의 벤치마크에서 Gemini의 성능이 뒤처지지 않거나 오히려 더 강력하기 때문에 가성비가 매우 뛰어납니다. SWE-Bench나 전문가용 작업 등 Claude가 명확하게 우세한 상황에서만 Claude를 사용하는 것이 경제적입니다.
Q4: 두 모델을 동시에 사용하여 스마트 라우팅을 구현할 수 있나요?
네, 가능합니다. 추천하는 아키텍처는 다음과 같습니다. 일반적인 요청의 80%(저비용, 강력한 추론)는 Gemini 3.1 Pro로 처리하고, 전문가 수준의 작업이나 도구 강화가 필요한 20%의 시나리오는 Claude Opus 4.6으로 처리하는 방식입니다. APIYI(apiyi.com)의 통합 인터페이스를 활용하면 코드 내에서 작업 유형에 따라 model 파라미터만 전환해주는 것으로 간단히 스마트 라우팅을 구현할 수 있습니다.
요약: Gemini 3.1 Pro vs Claude Opus 4.6 선택 가이드
| # | 비교 차원 | Gemini 3.1 Pro | Claude Opus 4.6 | 승자 |
|---|---|---|---|---|
| 1 | 추상적 추론 | ARC-AGI-2 77.1% | 68.8% | Gemini |
| 2 | 코딩 능력 | SWE-Bench 80.6% | 80.8% | Claude (미세 우위) |
| 3 | 에이전트 워크플로우 | MCP Atlas 69.2% | 59.5% | Gemini |
| 4 | 전문가 작업 | GDPval 1317 | 1606 | Claude |
| 5 | 멀티모달 | 풀 모달 (텍스트/이미지/오디오/비디오) | 텍스트/이미지 | Gemini |
| 6 | 가격 | $2/$12 (1M 토큰당) | $5/$25 (1M 토큰당) | Gemini (2배 저렴) |
| 7 | 컨텍스트 윈도우 | 1M (표준) | 200K (1M 베타) | Gemini |
| 8 | 최대 출력 | 64K 토큰 | 128K 토큰 | Claude |
| 9 | 사고 시스템 | 3단계 + Deep Think Mini | 4단계 + 적응형 | 막상막하 |
| 10 | 컴퓨터 조작 | 미지원 | OSWorld 72.7% | Claude 독점 |
최종 제안:
- 가성비 우선 → Gemini 3.1 Pro (2배 저렴, 더 강력한 추론)
- 소프트웨어 엔지니어링 우선 → Claude Opus 4.6 (SWE-Bench, GDPval 우세)
- 멀티모달 우선 → Gemini 3.1 Pro (풀 모달 지원 유일 선택지)
- 베스트 프랙티스 → 두 모델 모두 도입 후 스마트 라우팅 활용
APIYI(apiyi.com) 플랫폼을 통해 두 모델을 동시에 연동하고, 단일 인터페이스로 유연한 스케줄링과 A/B 테스트를 시작해 보세요.
참고 자료
-
Google 공식 블로그: Gemini 3.1 Pro 출시 공지
- 링크:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - 설명: 공식 벤치마크 데이터 및 기능 소개
- 링크:
-
Anthropic 공식 공지: Claude Opus 4.6 출시 상세 정보
- 링크:
anthropic.com/news/claude-opus-4-6 - 설명: Claude Opus 4.6 기술 사양 및 벤치마크 데이터
- 링크:
-
Artificial Analysis: 제3자 비교 평가
- 링크:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - 설명: 독립적 벤치마크 비교 및 성능 분석
- 링크:
-
Google DeepMind: 모델 카드 및 안전성 평가
- 링크:
deepmind.google/models/model-cards/gemini-3-1-pro - 설명: 상세 기술 파라미터 및 안전성 데이터
- 링크:
-
VentureBeat: Deep Think Mini 심층 체험
- 링크:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - 설명: 3단계 사고 시스템 실제 테스트
- 링크:
📝 작성자: APIYI 팀 | 기술 교류는 APIYI(apiyi.com)를 방문해 주세요.
📅 업데이트 날짜: 2026년 2월 20일
🏷️ 키워드: Gemini 3.1 Pro vs Claude Opus 4.6, 모델 비교, ARC-AGI-2, SWE-Bench, MCP Atlas, 멀티모달, API 호출