Gemini 3.1 Pro Preview против Claude Opus 4.6 — что выбрать? Это дилемма, с которой столкнется каждый AI-разработчик в начале 2026 года. В этой статье мы проведем детальное сравнение по 10 ключевым параметрам, опираясь на официальные данные и независимые тесты, чтобы помочь вам сделать осознанный выбор.
Ключевая ценность: После прочтения вы будете четко понимать, какую модель использовать для конкретных задач и как быстро протестировать их в деле.

Обзор базовых данных Gemini 3.1 Pro vs Claude Opus 4.6
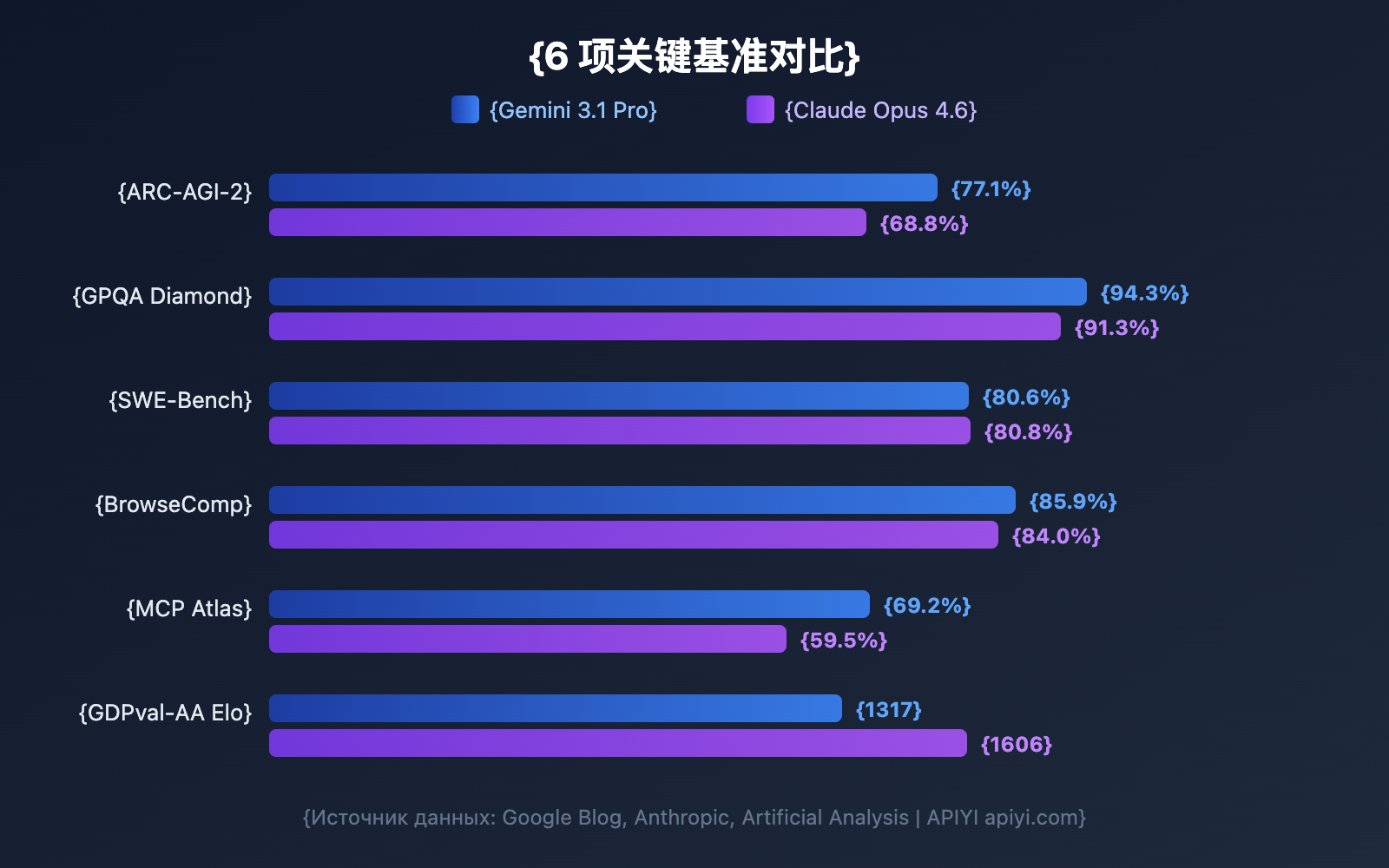
Прежде чем углубляться в детали, давайте взглянем на общую картину. Google официально заявляет, что Gemini 3.1 Pro лидирует в 13 из 16 тестов, однако Claude Opus 4.6 обходит конкурента во многих реальных сценариях.
| Тест (Бенчмарк) | Gemini 3.1 Pro | Claude Opus 4.6 | Победитель | Разрыв |
|---|---|---|---|---|
| ARC-AGI-2 (Абстрактная логика) | 77.1% | 68.8% | Gemini | +8.3pp |
| GPQA Diamond (Наука уровня PhD) | 94.3% | 91.3% | Gemini | +3.0pp |
| SWE-Bench Verified (Разработка ПО) | 80.6% | 80.8% | Claude | +0.2pp |
| Terminal-Bench 2.0 (Кодинг в терминале) | 68.5% | 65.4% | Gemini | +3.1pp |
| BrowseComp (Поиск агентами) | 85.9% | 84.0% | Gemini | +1.9pp |
| MCP Atlas (Многошаговые агенты) | 69.2% | 59.5% | Gemini | +9.7pp |
| HLE без инструментов (Сложный экзамен) | 44.4% | 40.0% | Gemini | +4.4pp |
| HLE с инструментами (Сложный экзамен) | 51.4% | 53.1% | Claude | +1.7pp |
| SciCode (Научное программирование) | 59% | 52% | Gemini | +7pp |
| MMMLU (Многоязычные ответы) | 92.6% | 91.1% | Gemini | +1.5pp |
| tau2-bench Retail (Вызов инструментов) | 90.8% | 91.9% | Claude | +1.1pp |
| GDPval-AA Elo (Экспертные задачи) | 1317 | 1606 | Claude | +289 |
📊 Примечание: Данные взяты из официальных блогов Google, анонсов Anthropic и независимых тестов Artificial Analysis. Через платформу APIYI (apiyi.com) вы можете одновременно протестировать обе модели в своих рабочих сценариях.
Сравнение 1: Gemini 3.1 Pro vs Claude Opus 4.6 — способности к рассуждению
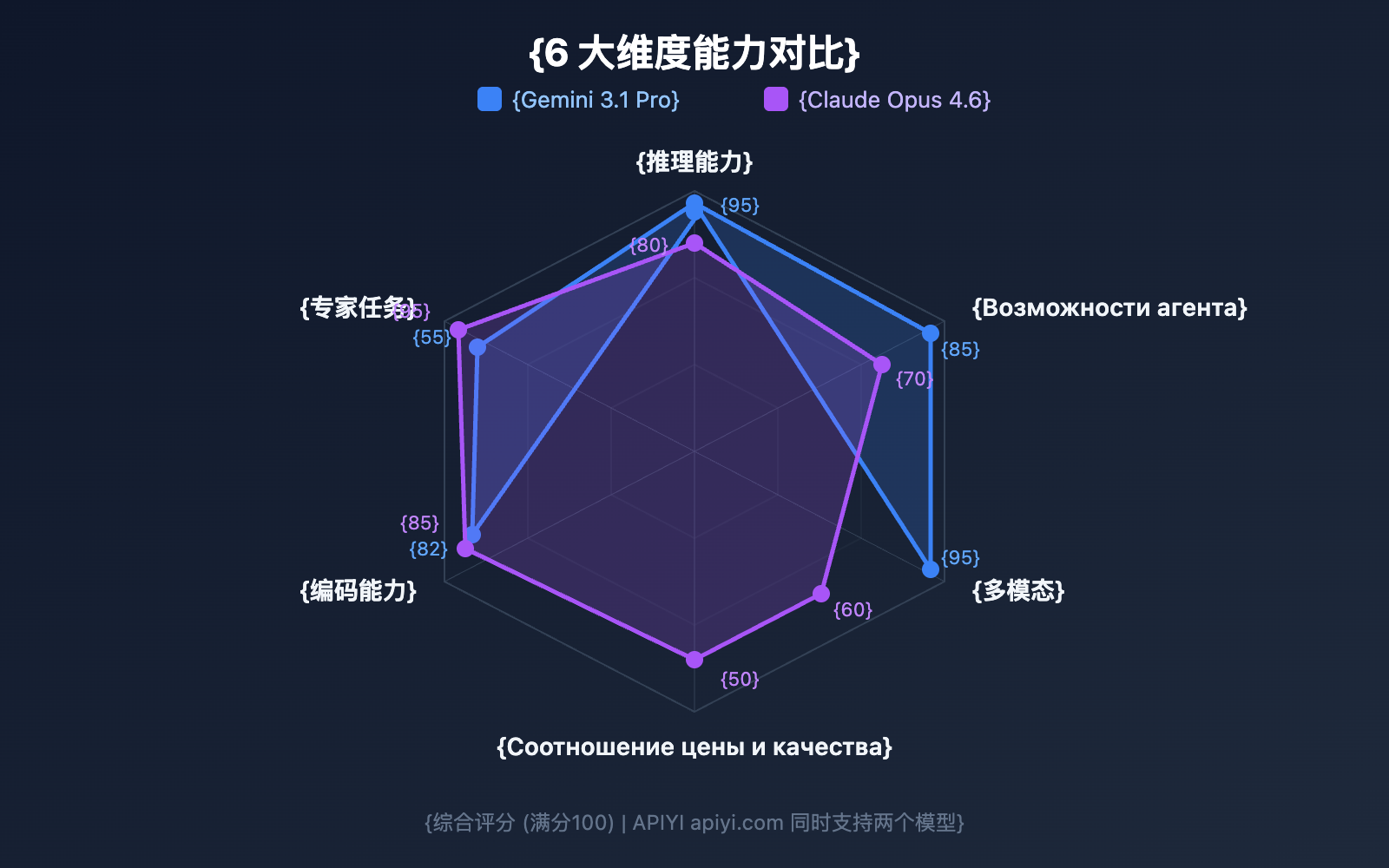
Способность к рассуждению — это главный козырь любой большой языковой модели. Архитектуры этих двух моделей существенно различаются, что напрямую влияет на их «интеллект».
Абстрактное мышление: Gemini 3.1 Pro заметно впереди
ARC-AGI-2 на данный момент считается самым авторитетным бенчмарком для проверки абстрактного мышления. Gemini 3.1 Pro набрала в нем 77.1%, что на 8.3 процентных пункта выше, чем у Claude Opus 4.6 (68.8%). Это означает, что Gemini гораздо лучше справляется с задачами, где нужно выводить правила из небольшого количества примеров.
Научные рассуждения уровня PhD: преимущество Gemini очевидно
Тест GPQA Diamond проверяет знания в области науки на уровне докторской степени (PhD). Gemini 3.1 Pro набрала 94.3%, в то время как Claude Opus 4.6 — 91.3%. Разрыв в 3 процента на таком уровне сложности — это очень серьезный показатель.
Рассуждения с использованием инструментов: Claude берет реванш
В тесте HLE (Humanity's Last Exam) без использования инструментов лидирует Gemini (44.4% против 40.0%), но как только подключаются внешние инструменты, Claude вырывается вперед (53.1% против 51.4%). Это говорит о том, что Claude Opus 4.6 эффективнее использует сторонние сервисы и API для решения сложных логических задач.
| Аспект рассуждений | Gemini 3.1 Pro | Claude Opus 4.6 | Кому подходит |
|---|---|---|---|
| Абстрактное мышление | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Распознавание паттернов, вывод правил |
| Научные рассуждения | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Академические исследования, помощь с научными работами |
| Инструментальные рассуждения | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Сложные рабочие процессы, координация нескольких инструментов |
| Математические рассуждения | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Специализация Deep Think Mini |
Сравнение 2: Gemini 3.1 Pro vs Claude Opus 4.6 — навыки программирования
Навыки написания кода — это то, что больше всего интересует разработчиков. Здесь показатели моделей очень близки, но у каждой есть свои нюансы.
SWE-Bench: практически наравне
SWE-Bench Verified — это бенчмарк, основанный на реальных задачах по исправлению багов в GitHub:
- Claude Opus 4.6: 80.8% (незначительное лидерство)
- Gemini 3.1 Pro: 80.6%
Разница всего в 0.2% позволяет сказать, что в реальных задачах программной инженерии обе модели справляются одинаково хорошо.
Terminal-Bench: Gemini лидирует
Terminal-Bench 2.0 проверяет способности ИИ-агентов работать в среде терминала:
- Gemini 3.1 Pro: 68.5%
- Claude Opus 4.6: 65.4%
Разрыв в 3.1% показывает, что Gemini лучше проявляет себя в сценариях, где агенту нужно выполнять команды в консоли.
Спортивное программирование: Gemini впереди
Данные LiveCodeBench Pro показывают, что рейтинг Gemini 3.1 Pro достиг 2887 Elo, что говорит о выдающихся способностях в олимпиадном программировании. Точные данные для Claude Opus 4.6 пока не опубликованы, но, судя по результатам в USACO, Claude также находится на топовом уровне.
# 通过 APIYI 同时测试两个模型的编码能力
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 统一接口
)
# 同一编码任务分别测试
coding_prompt = "实现一个 LRU Cache,支持 get 和 put 操作,时间复杂度 O(1)"
for model in ["gemini-3.1-pro-preview", "claude-opus-4-6"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": coding_prompt}]
)
print(f"\n{'='*50}")
print(f"模型: {model}")
print(f"Token 用量: {resp.usage.total_tokens}")
print(f"回答:\n{resp.choices[0].message.content[:500]}")
Сравнение 3: Возможности агентов Gemini 3.1 Pro и Claude Opus 4.6
Агенты и автономные рабочие процессы — это ключевой сценарий 2026 года. И это одна из областей, где различия между двумя моделями проявляются ярче всего.
Поиск через агентов: Оба сильны
Тест BrowseComp оценивает способности модели к автономному поиску в вебе и извлечению информации:
- Gemini 3.1 Pro: 85,9%
- Claude Opus 4.6: 84,0%
Разрыв составляет всего 1,9 процентных пункта — обе модели демонстрируют топовый уровень.
Многошаговые агенты: Gemini заметно впереди
Бенчмарк MCP Atlas проверяет сложные многошаговые рабочие процессы. Gemini 3.1 Pro набрала 69,2%, что почти на 10 процентных пунктов выше, чем у Claude Opus 4.6 (59,5%). Это один из тестов с самой большой разницей между моделями.
Управление компьютером: Эксклюзивное преимущество Claude
Бенчмарк OSWorld тестирует способность модели управлять реальным графическим интерфейсом (GUI). Claude Opus 4.6 набрала 72,7%. Gemini пока не опубликовала результаты в этой категории. Это значит, что если вам нужно, чтобы ИИ автоматически управлял десктопными приложениями, Claude на данный момент — единственный выбор.
Задачи экспертного уровня: Claude лидирует с отрывом
GDPval-AA тестирует задачи экспертного уровня в реальной офисной среде (анализ данных, написание отчетов и т.д.). Рейтинг Эло у Claude Opus 4.6 составил 1606, что значительно выше, чем 1317 у Gemini. Это говорит о том, что в интеллектуальной работе, требующей глубокого понимания и точного исполнения, Claude надежнее.
| Подкатегории агентов | Gemini 3.1 Pro | Claude Opus 4.6 | Разница |
|---|---|---|---|
| BrowseComp (Поиск) | 85,9% | 84,0% | +1,9 п.п. |
| MCP Atlas (Многошаговость) | 69,2% | 59,5% | +9,7 п.п. |
| APEX-Agents (Длинные циклы) | 33,5% | 29,8% | +3,7 п.п. |
| OSWorld (Управление ПК) | — | 72,7% | Только у Claude |
| GDPval-AA (Экспертные задачи) | 1317 Elo | 1606 Elo | +289 |
Сравнение 4: Архитектура систем мышления Gemini 3.1 Pro и Claude Opus 4.6
У обеих моделей есть механизмы «глубокого мышления», но подходы к их проектированию различаются.
Gemini 3.1 Pro: Трехуровневая система мышления
| Уровень | Название | Особенности | Сценарии использования |
|---|---|---|---|
| Low | Быстрый отклик | Почти без задержек | Простые вопросы, перевод |
| Medium | Сбалансированное рассуждение | Средняя задержка (новинка) | Повседневный кодинг, анализ |
| High | Deep Think Mini | Глубокое рассуждение, решение задач IMO за 8 мин | Математика, сложная отладка |
Режим High в Gemini 3.1 Pro — это фактически мини-версия Deep Think (специализированной модели рассуждений от Google). По сути, это выделенный движок рассуждений, встроенный в модель.
Claude Opus 4.6: Адаптивная система мышления
| Уровень | Название | Особенности | Сценарии использования |
|---|---|---|---|
| Low | Быстрый режим | Минимальные затраты на рассуждение | Простые задачи |
| Medium | Сбалансированный режим | Умеренное рассуждение | Обычная разработка |
| High | Глубокий режим (по умолчанию) | Автоматическое определение глубины | Большинство задач |
| Max | Максимальное рассуждение | Рассуждение на полную мощность | Экстремально сложные проблемы |
Фишка Claude — адаптивное мышление. Модель сама решает, сколько ресурсов на рассуждение потратить в зависимости от сложности вопроса, разработчику не нужно выбирать вручную. Режим High по умолчанию уже очень умен.
🎯 Практический итог: Gemini дает вам более тонкий ручной контроль (3 уровня), что удобно для точного управления затратами и задержками. Claude предлагает более умную автоподстройку (4 уровня + адаптивность), что идеально для рабочих сред в духе «настроил и забыл». Обе модели можно напрямую вызвать и сравнить на APIYI apiyi.com.
Сравнение 5: Цены и стоимость Gemini 3.1 Pro vs Claude Opus 4.6
Стоимость — это критический фактор при развертывании в продакшене. Разница в цене между этими двумя моделями весьма ощутима.
| Параметр | Gemini 3.1 Pro | Claude Opus 4.6 | Выгода Gemini |
|---|---|---|---|
| Вход (стандарт) | $2.00 / 1M токенов | $5.00 / 1M токенов | в 2.5x дешевле |
| Вывод (стандарт) | $12.00 / 1M токенов | $25.00 / 1M токенов | в 2.1x дешевле |
| Вход (длинный контекст >200K) | $4.00 / 1M токенов | $10.00 / 1M токенов | в 2.5x дешевле |
| Вывод (длинный контекст >200K) | $18.00 / 1M токенов | $37.50 / 1M токенов | в 2.1x дешевле |
Оценка затрат в реальных сценариях
Расчет исходя из ежедневной нагрузки в 1 млн входных токенов + 200 тыс. выходных токенов:
| Сценарий | Gemini 3.1 Pro | Claude Opus 4.6 | Экономия в месяц |
|---|---|---|---|
| Обычное использование | $4.40/день | $10.00/день | $168/мес |
| Интенсивное использование (3x) | $13.20/день | $30.00/день | $504/мес |
Gemini 3.1 Pro примерно в два раза дешевле Claude Opus 4.6 по всем ценовым позициям. Для проектов, где бюджет имеет значение, это очень весомое преимущество.
💰 Совет по оптимизации затрат: Используя платформу APIYI (apiyi.com) для работы с обеими моделями, вы получаете гибкую тарификацию и единое управление. Рекомендуем сначала провести тесты на небольших объемах, чтобы оценить результат, и только потом выбирать основную модель.
Сравнение 6: Контекстное окно и лимиты вывода Gemini 3.1 Pro vs Claude Opus 4.6
| Характеристика | Gemini 3.1 Pro | Claude Opus 4.6 | Лидер |
|---|---|---|---|
| Контекстное окно | 1,000,000 токенов | 200,000 токенов (1M в бете) | Gemini |
| Макс. объем вывода | 64,000 токенов | 128,000 токенов | Claude |
| Размер загружаемого файла | 100MB | — | Gemini |
Контекстное окно: Gemini впереди в 5 раз
Gemini 3.1 Pro стандартно поддерживает контекст в 1 миллион токенов, тогда как у Claude Opus 4.6 стандартный лимит — 200 тысяч (1 млн доступен только в бета-режиме). В сценариях, где нужно анализировать огромные репозитории кода, длинные документы или видеофайлы, преимущество Gemini неоспоримо.
Максимальный вывод: Claude лидирует с двойным отрывом
Claude Opus 4.6 поддерживает вывод до 128 тыс. токенов, что в два раза больше, чем у Gemini. Это критически важно для генерации лонгридов, детального написания кода и построения глубоких цепочек рассуждений — большой объем «выхлопа» позволяет модели более тщательно «продумывать» свои ответы.
Сравнение 7: Gemini 3.1 Pro vs Claude Opus 4.6 — мультимодальные возможности
Мультимодальность — это традиционно сильная сторона моделей Gemini.
| Модальность | Gemini 3.1 Pro | Claude Opus 4.6 |
|---|---|---|
| Текстовый ввод | ✅ | ✅ |
| Ввод изображений | ✅ (нативно) | ✅ |
| Ввод видео | ✅ (нативно) | ❌ |
| Ввод аудио | ✅ (нативно) | ❌ |
| Обработка PDF | ✅ | ✅ |
| YouTube URL | ✅ | ❌ |
| Генерация SVG | ✅ (нативно) | ✅ |
Gemini 3.1 Pro — это полноценная омнимодальная модель. Она еще на уровне архитектуры обучения была спроектирована для нативного понимания текста, изображений, аудио и видео в едином пространстве. Мультимодальность Claude Opus 4.6 пока ограничена только текстом и изображениями.
Если ваш проект связан с анализом видео, транскрибацией аудио или глубоким пониманием мультимедийного контента, Gemini 3.1 Pro на данный момент — единственный подходящий выбор.
Сравнение 8: Gemini 3.1 Pro vs Claude Opus 4.6 — уникальные фишки
Уникально для Gemini 3.1 Pro
| Особенность | Описание | Преимущество |
|---|---|---|
| Deep Think Mini | Встроенный движок сложных рассуждений в режиме High | Рассуждения уровня математических олимпиад |
| Поиск (Grounding) | 5000 бесплатных поисковых запросов в месяц | Актуализация информации в реальном времени |
| Загрузка файлов до 100 МБ | Возможность разовой загрузки огромных файлов | Анализ крупных кодовых баз и массивов данных |
| Анализ YouTube URL | Понимание контента напрямую через ссылку на видео | Быстрый разбор видеоконтента |
| Нативное понимание аудио/видео | Сквозная мультимодальная обработка | Продвинутые мультимедийные AI-приложения |
Уникально для Claude Opus 4.6
| Особенность | Описание | Преимущество |
|---|---|---|
| Computer Use (OSWorld 72.7%) | Автоматическое управление графическим интерфейсом | RPA / Автоматизированное тестирование |
| Адаптивное мышление | Автоматический выбор глубины рассуждений | Умные рассуждения без лишних настроек |
| 128K на выходе | Поддержка очень длинных ответов | Генерация лонгридов / Глубокая проработка тем |
| Batch API (скидка 50%) | Асинхронная пакетная обработка | Масштабная и дешевая обработка данных |
| Быстрый режим (Fast Mode) | Ускоренный вывод при 6-кратном тарифе | Сценарии, где критически важна низкая задержка |
Руководство по выбору сценариев: Gemini 3.1 Pro vs Claude Opus 4.6
Основываясь на сравнении по 8 параметрам, вот четкие рекомендации по выбору модели для конкретных задач:
Когда выбирать Gemini 3.1 Pro
| Сценарий | Ключевое преимущество | Почему рекомендуем |
|---|---|---|
| Абстрактное рассуждение / Математика | ARC-AGI-2 +8.3 п.п. | Режим Deep Think Mini невероятно силен |
| Многошаговые агенты (Agents) | MCP Atlas +9.7 п.п. | Лучшая исполнительность в рабочих процессах |
| Анализ видео и аудио | Нативная мультимодальность | Единственный полноценный мультимодальный выбор |
| Проекты с ограниченным бюджетом | Дешевле в 2–2.5 раза | То же качество при меньших затратах |
| Анализ огромных документов | Контекст 1M токенов | Стандартная поддержка сверхбольшого контекста |
| Научные исследования | GPQA +3.0 п.п. | Самые сильные способности к научным рассуждениям |
Когда выбирать Claude Opus 4.6
| Сценарий | Ключевое преимущество | Почему рекомендуем |
|---|---|---|
| Реальная программная инженерия | SWE-Bench 80.8% | Самый точный в исправлении реальных багов |
| Экспертная интеллектуальная работа | GDPval-AA +289 Elo | Лучший для отчетов, анализа и принятия решений |
| Компьютерная автоматизация | OSWorld 72.7% | Единственный с поддержкой управления GUI |
| Рассуждения с инструментами | HLE+tools +1.7 п.п. | Оптимальная синергия нескольких инструментов |
| Потребность в длинных ответах | Вывод 128K | Длинные тексты и глубокие цепочки рассуждений |
| Продакшн с низкой задержкой | Быстрый режим | Скорость в обмен на оплату |
Используем оба: Архитектура интеллектуальной маршрутизации
Во многих продакшн-системах оптимальное решение — использовать обе модели одновременно, распределяя задачи по типам с помощью интеллектуальной маршрутизации:
| Тип задачи | Маршрут на | Причина | Примерная доля |
|---|---|---|---|
| Обычные вопросы-ответы / Перевод | Gemini 3.1 Pro | Низкая стоимость, достаточное качество | 40% |
| Генерация кода / Отладка | Claude Opus 4.6 | Чуть лучше в SWE-Bench | 20% |
| Рассуждения / Математика / Наука | Gemini 3.1 Pro | Значительный отрыв в ARC-AGI-2 | 15% |
| Ворклоу агентов (Agent workflows) | Gemini 3.1 Pro | MCP Atlas +9.7 п.п. | 10% |
| Экспертный анализ / Отчеты | Claude Opus 4.6 | Явное лидерство в GDPval-AA | 10% |
| Обработка видео и аудио | Gemini 3.1 Pro | Единственный полноценный мультимодальный выбор | 5% |
При такой маршрутизации общие затраты сокращаются примерно на 55% по сравнению с использованием только Claude, при этом вы получаете максимальное качество в каждом конкретном сценарии.
Стратегии оптимизации затрат: Gemini 3.1 Pro vs Claude Opus 4.6
Стратегия 1: Уровневая обработка
Для простых задач используйте режим Gemini Low (самый быстрый и дешевый), для средних — Gemini Medium, и только для действительно сложных задач подключайте Claude High или Gemini High (Deep Think Mini).
Стратегия 2: Разделение пакетной и real-time обработки
Для запросов в реальном времени используйте Gemini 3.1 Pro (низкая задержка, низкая стоимость), а для офлайн-обработки можно использовать Batch API от Claude (скидка 50%), что делает итоговую стоимость сопоставимой.
Стратегия 3: Кэширование контекста
Gemini предлагает кэширование контекста (ввод $0.20–$0.40 за млн токенов). В сценариях с многократным использованием одного и того же длинного документа кэширование позволяет снизить затраты более чем на 80%.
🚀 Быстрая проверка: Через платформу APIYI (apiyi.com) вы можете вызывать Gemini 3.1 Pro и Claude Opus 4.6, используя один и тот же API-ключ. Рекомендуем провести A/B тест на ваших реальных промптах — это займет всего 10 минут.
Быстрый старт: Gemini 3.1 Pro vs Claude Opus 4.6
Ниже приведен код, демонстрирующий, как через единый интерфейс APIYI вызвать обе модели для сравнительного теста:
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Единый интерфейс APIYI
)
def compare_models(prompt, models=None):
"""Сравнение качества и скорости вывода двух моделей"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-opus-4-6"]
results = {}
for model in models:
start = time.time()
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
elapsed = time.time() - start
results[model] = {
"time": f"{elapsed:.2f}s",
"tokens": resp.usage.total_tokens,
"answer": resp.choices[0].message.content[:300]
}
for model, data in results.items():
print(f"\n{'='*50}")
print(f"Модель: {model}")
print(f"Затрачено времени: {data['time']} | Токенов: {data['tokens']}")
print(f"Ответ: {data['answer']}...")
# Тест способностей к рассуждению
compare_models("Пожалуйста, объясни с помощью цепочки рассуждений, почему 0.1 + 0.2 не равно 0.3")
Посмотреть полный код с управлением уровнем размышлений (thinking level)
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def compare_with_thinking(prompt, thinking_config=None):
"""Сравнение работы моделей при разных уровнях размышления"""
configs = [
{"model": "gemini-3.1-pro-preview", "label": "Gemini Medium",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 8000}}},
{"model": "gemini-3.1-pro-preview", "label": "Gemini High (Deep Think Mini)",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 32000}}},
{"model": "claude-opus-4-6", "label": "Claude High (адаптивный по умолчанию)",
"extra": {}},
]
for cfg in configs:
start = time.time()
params = {
"model": cfg["model"],
"messages": [{"role": "user", "content": prompt}],
**cfg["extra"]
}
resp = client.chat.completions.create(**params)
elapsed = time.time() - start
print(f"\n[{cfg['label']}] {elapsed:.2f}s | {resp.usage.total_tokens} токенов")
print(f" → {resp.choices[0].message.content[:200]}...")
# Тест сложного рассуждения
compare_with_thinking("Докажите: для любого целого положительного n, n^3 - n делится на 6")
Часто задаваемые вопросы
Q1: Что лучше: Gemini 3.1 Pro или Claude Opus 4.6?
Нет однозначного ответа, какая модель «лучше». Gemini 3.1 Pro лидирует в абстрактном мышлении (ARC-AGI-2 +8.3 п.п.), многошаговых агентах (MCP Atlas +9.7 п.п.), мультимодальности и стоимости. Claude Opus 4.6 превосходит в реальной программной инженерии (SWE-Bench), экспертных задачах (GDPval-AA +289 Elo), управлении компьютером и работе с инструментами. Рекомендуем провести A/B-тестирование в ваших реальных сценариях через APIYI (apiyi.com).
Q2: Совместимы ли API-интерфейсы этих двух моделей? Легко ли между ними переключаться?
Через платформу APIYI (apiyi.com) обе модели используют единый OpenAI-совместимый интерфейс. Для переключения достаточно просто изменить параметр model (gemini-3.1-pro-preview → claude-opus-4-6), остальной код менять не нужно.
Q3: Какую модель выбрать при ограниченном бюджете?
В первую очередь выбирайте Gemini 3.1 Pro. Цена за входящие токены у неё составляет 40% от стоимости Claude Opus 4.6 ($2 против $5), а цена за исходящие — меньше половины ($12 против $25). В большинстве бенчмарков Gemini не уступает или даже превосходит конкурента, предлагая отличное соотношение цены и качества. Используйте Claude только в тех сценариях, где он явно доминирует, например, в SWE-Bench или узкоспециализированных экспертных задачах.
Q4: Можно ли использовать обе модели одновременно для интеллектуальной маршрутизации?
Да. Рекомендуемая архитектура: используйте Gemini 3.1 Pro для обработки 80% обычных запросов (низкая стоимость, сильное логическое мышление) и Claude Opus 4.6 для 20% задач экспертного уровня и сценариев с расширенным использованием инструментов. Благодаря единому интерфейсу APIYI (apiyi.com) вы можете реализовать интеллектуальную маршрутизацию, просто определяя тип задачи в коде и переключая параметр model.
Итог: Как выбрать между Gemini 3.1 Pro и Claude Opus 4.6
| # | Критерий сравнения | Gemini 3.1 Pro | Claude Opus 4.6 | Победитель |
|---|---|---|---|---|
| 1 | Абстрактное мышление | ARC-AGI-2 77.1% | 68.8% | Gemini |
| 2 | Навыки программирования | SWE-Bench 80.6% | 80.8% | Claude (незначительно) |
| 3 | Агентные воркфлоу | MCP Atlas 69.2% | 59.5% | Gemini |
| 4 | Экспертные задачи | GDPval 1317 | 1606 | Claude |
| 5 | Мультимодальность | Все модальности (текст/фото/аудио/видео) | Текст/фото | Gemini |
| 6 | Цена | $2/$12 за млн токенов | $5/$25 за млн токенов | Gemini (в 2 раза дешевле) |
| 7 | Контекстное окно | 1M (стандарт) | 200K (1M в бете) | Gemini |
| 8 | Максимальный вывод | 64K токенов | 128K токенов | Claude |
| 9 | Система рассуждений | Уровень 3 + Deep Think Mini | Уровень 4 + адаптивная | У каждой свои плюсы |
| 10 | Управление компьютером | Пока не поддерживается | OSWorld 72.7% | Эксклюзивно у Claude |
Финальные рекомендации:
- Приоритет на цену и качество → Gemini 3.1 Pro (в 2 раза дешевле, сильнее в логике).
- Приоритет на разработку ПО → Claude Opus 4.6 (лидер в SWE-Bench и GDPval).
- Приоритет на мультимодальность → Gemini 3.1 Pro (единственный выбор для работы со всеми типами данных).
- Лучшая практика → Используйте обе модели через интеллектуальную маршрутизацию.
Рекомендуем подключить обе модели через платформу APIYI (apiyi.com), чтобы использовать единый интерфейс для гибкого управления и A/B-тестирования.
Справочные материалы
-
Официальный блог Google: Анонс релиза Gemini 3.1 Pro
- Ссылка:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - Описание: Официальные бенчмарки и обзор функций.
- Ссылка:
-
Официальный анонс Anthropic: Подробности выпуска Claude Opus 4.6
- Ссылка:
anthropic.com/news/claude-opus-4-6 - Описание: Технические характеристики и данные бенчмарков Claude Opus 4.6.
- Ссылка:
-
Artificial Analysis: Стороннее сравнительное тестирование
- Ссылка:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - Описание: Независимое сравнение и анализ производительности.
- Ссылка:
-
Google DeepMind: Карточка модели и оценка безопасности
- Ссылка:
deepmind.google/models/model-cards/gemini-3-1-pro - Описание: Подробные технические параметры и данные по безопасности.
- Ссылка:
-
VentureBeat: Глубокое погружение в Deep Think Mini
- Ссылка:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - Описание: Практический тест трехуровневой системы мышления.
- Ссылка:
📝 Автор: Команда APIYI | По вопросам технического сотрудничества заходите на APIYI apiyi.com
📅 Дата обновления: 20 февраля 2026 г.
🏷️ Ключевые слова: Gemini 3.1 Pro vs Claude Opus 4.6, сравнение моделей, ARC-AGI-2, SWE-Bench, MCP Atlas, мультимодальность, вызов API