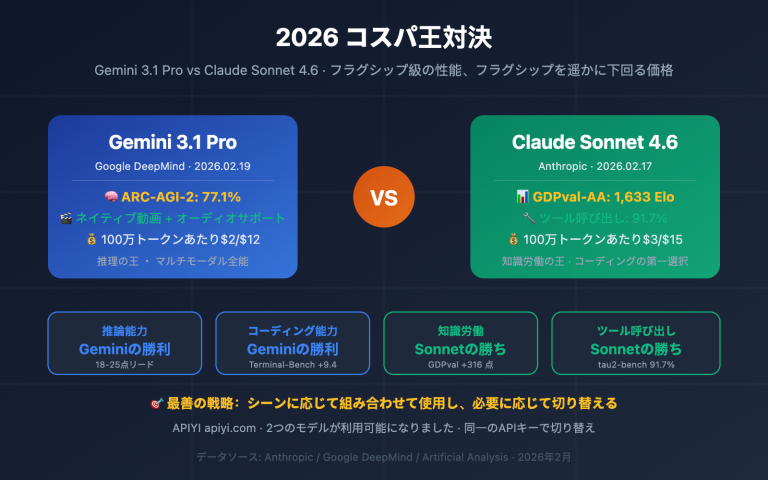
Gemini 3.1 Pro Preview vs Claude Opus 4.6、どちらを選ぶべきか?これは2026年初頭、AI開発者にとって避けては通れない選択です。本記事では、10の核心的な次元から徹底比較を行い、公式ベンチマークデータや第三者による評価を引用しながら、データに基づいた明確な選択をサポートします。
コアバリュー: この記事を読み終える頃には、異なるシナリオでどちらのモデルを選択すべきか、そして実際のプロジェクトでどのように素早く検証すべきかが明確になります。

Gemini 3.1 Pro vs Claude Opus 4.6 ベンチマークデータ概要
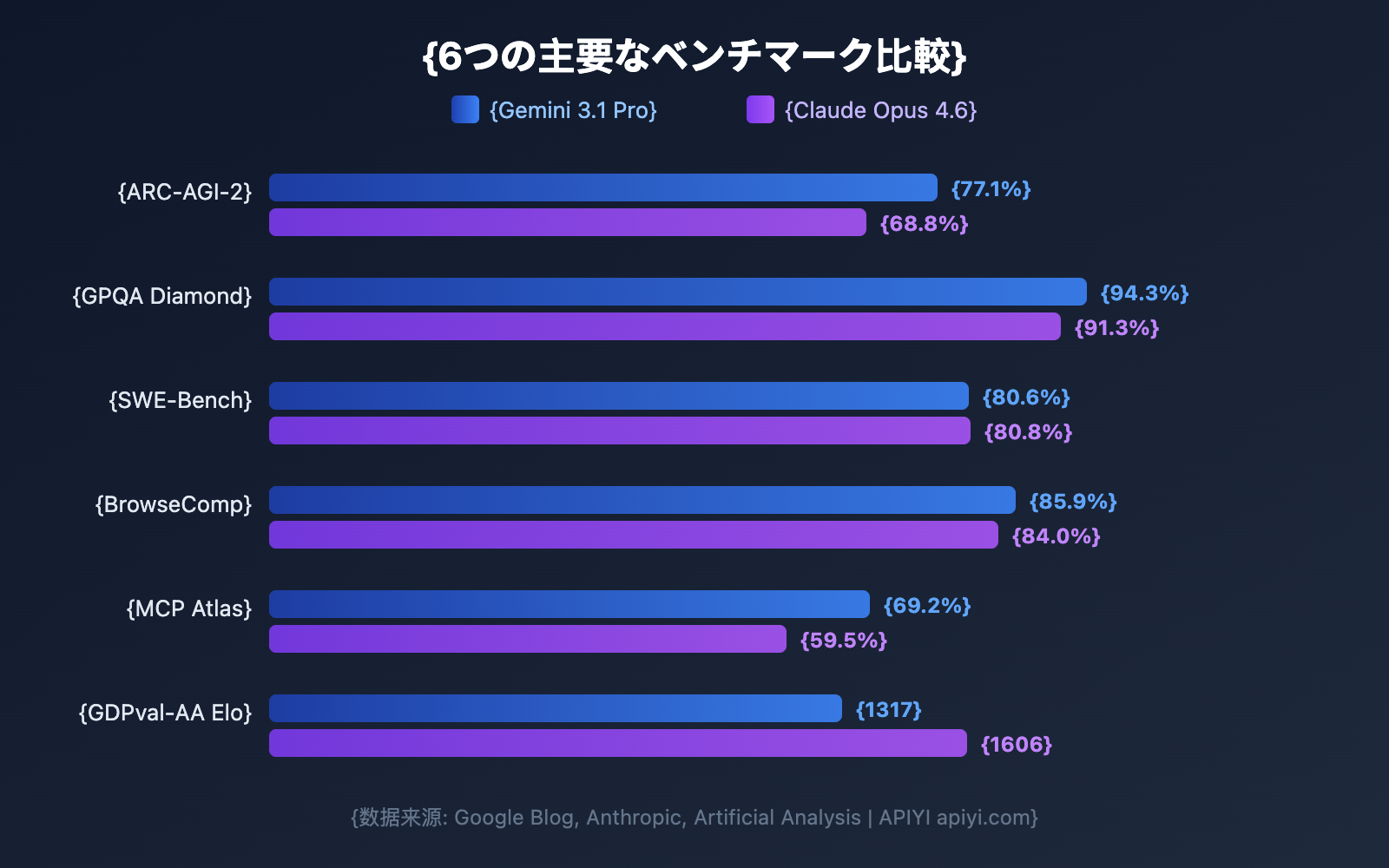
各次元を深掘りする前に、まずは全体的なベンチマーク比較を見てみましょう。Google公式は Gemini 3.1 Pro が16項目のベンチマークのうち13項目でリードしていると主張していますが、Claude Opus 4.6 も多くの実戦シナリオで勝利を収めています。
| ベンチマーク | Gemini 3.1 Pro | Claude Opus 4.6 | 勝者 | 差 |
|---|---|---|---|---|
| ARC-AGI-2 (抽象的推論) | 77.1% | 68.8% | Gemini | +8.3pp |
| GPQA Diamond (博士レベルの科学) | 94.3% | 91.3% | Gemini | +3.0pp |
| SWE-Bench Verified (ソフトウェアエンジニアリング) | 80.6% | 80.8% | Claude | +0.2pp |
| Terminal-Bench 2.0 (ターミナルコーディング) | 68.5% | 65.4% | Gemini | +3.1pp |
| BrowseComp (エージェント検索) | 85.9% | 84.0% | Gemini | +1.9pp |
| MCP Atlas (多段階エージェント) | 69.2% | 59.5% | Gemini | +9.7pp |
| HLE 無ツール (究極の試験) | 44.4% | 40.0% | Gemini | +4.4pp |
| HLE 有ツール (究極の試験) | 51.4% | 53.1% | Claude | +1.7pp |
| SciCode (科学研究コーディング) | 59% | 52% | Gemini | +7pp |
| MMMLU (多言語QA) | 92.6% | 91.1% | Gemini | +1.5pp |
| tau2-bench Retail (ツール呼び出し) | 90.8% | 91.9% | Claude | +1.1pp |
| GDPval-AA Elo (専門家タスク) | 1317 | 1606 | Claude | +289 |
📊 データ説明: 上記データはGoogle公式ブログ、Anthropic公式発表、およびArtificial Analysisによる第三者評価に基づいています。APIYI(apiyi.com)を通じて、両方のモデルを同時に呼び出し、実際のシナリオで検証することが可能です。
比較 1: Gemini 3.1 Pro vs Claude Opus 4.6 の推理能力
推理能力は大規模言語モデルの核心的な競争力です。これら2つのモデルは、推理アーキテクチャにおいて顕著な違いを見せています。
抽象推理: Gemini 3.1 Pro が大きくリード
ARC-AGI-2 は、現在最も権威のある抽象推理ベンチマークです。Gemini 3.1 Pro のスコアは 77.1% で、Claude Opus 4.6 の 68.8% よりも 8.3 ポイント上回っています。これは、少数の例から規則を帰納する必要があるタスクにおいて、Gemini がより強力であることを意味します。
PhD レベルの科学推理: Gemini の優位性が顕著
PhD レベルの科学的な問題をテストする GPQA Diamond において、Gemini 3.1 Pro は 94.3%、Claude Opus 4.6 は 91.3% を記録しました。この難易度レベルにおける 3 ポイントの差は非常に大きな意味を持ちます。
ツール活用推理: Claude が逆転
HLE (Humanity's Last Exam) では、ツールを使用しない条件では Gemini がリードしていましたが(44.4% vs 40.0%)、ツールを導入すると Claude が逆転しました(53.1% vs 51.4%)。これは、Claude Opus 4.6 が外部ツールを利用して推理を補助する能力に長けていることを示しています。
| 推理のサブカテゴリ | Gemini 3.1 Pro | Claude Opus 4.6 | おすすめの用途 |
|---|---|---|---|
| 抽象推理 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | パターン認識、規則の帰納 |
| 科学推理 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 学術研究、論文執筆補助 |
| ツール活用推理 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 複雑なワークフロー、複数ツールの連携 |
| 数学推理 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Deep Think Mini の得意分野 |
比較 2: Gemini 3.1 Pro vs Claude Opus 4.6 のコーディング能力
コーディング能力は、開発者が最も注目する次元です。両モデルのパフォーマンスは非常に拮抗していますが、それぞれに得意分野があります。
SWE-Bench: ほぼ互角
SWE-Bench Verified は、実際の GitHub の問題修正を評価するベンチマークです:
- Claude Opus 4.6: 80.8% (僅差でリード)
- Gemini 3.1 Pro: 80.6%
わずか 0.2 ポイントの差であり、実際のソフトウェアエンジニアリングタスクにおいて、両者の能力はほぼ同等であると言えます。
Terminal-Bench: Gemini が優勢
Terminal-Bench 2.0 は、ターミナル環境下でのエージェントのコーディング能力をテストします:
- Gemini 3.1 Pro: 68.5%
- Claude Opus 4.6: 65.4%
3.1 ポイントの差は、Gemini がターミナルエージェントのシナリオにおいて、より高い実行力を持っていることを示しています。
競技プログラミング: Gemini がリード
LiveCodeBench Pro のデータによると、Gemini 3.1 Pro は 2887 Elo に達し、競技プログラミングにおいて優れたパフォーマンスを発揮しています。Claude Opus 4.6 の対応するデータはまだ公開されていませんが、USACO などの競技実績から見て、Claude もトップレベルの水準にあります。
# 通过 APIYI 同时测试两个模型的编码能力
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 统一接口
)
# 同一编码任务分别测试
coding_prompt = "实现一个 LRU Cache,支持 get 和 put 操作,时间复杂度 O(1)"
for model in ["gemini-3.1-pro-preview", "claude-opus-4-6"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": coding_prompt}]
)
print(f"\n{'='*50}")
print(f"模型: {model}")
print(f"Token 用量: {resp.usage.total_tokens}")
print(f"回答:\n{resp.choices[0].message.content[:500]}")
比較 3:Gemini 3.1 Pro vs Claude Opus 4.6 のエージェント能力
エージェントと自律型ワークフローは、2026年における中核的な活用シーンです。これは、2つのモデルの間で最も大きな差が見られる領域の一つでもあります。
エージェント検索:両者譲らぬ実力
BrowseCompは、モデルの自律的なウェブ検索と情報抽出能力をテストします:
- Gemini 3.1 Pro: 85.9%
- Claude Opus 4.6: 84.0%
その差はわずか1.9ポイントで、どちらもトップレベルの水準にあります。
多段階エージェント:Gemini が大幅にリード
複雑な多段階ワークフローをテストする MCP Atlas では、Gemini 3.1 Pro が 69.2% を記録し、Claude Opus 4.6 の 59.5% を約10ポイント上回りました。これは、両モデルの差が最も顕著に表れたベンチマークの一つです。
コンピュータ操作:Claude 独自の強み
実際の GUI を操作する能力を測定する OSWorld ベンチマークにおいて、Claude Opus 4.6 は 72.7% というスコアを叩き出しました。Gemini は現時点でこの項目の成績を公表していません。つまり、AI にデスクトップアプリを自動操作させる必要がある場合、現時点では Claude が唯一の選択肢となります。
エキスパートレベルのタスク:Claude が明らかに優勢
実際のオフィス環境における専門的なタスク(データ分析、レポート作成など)をテストする GDPval-AA では、Claude Opus 4.6 の Elo レーティングは 1606 となり、Gemini の 1317 を大きく引き離しました。これは、深い理解と緻密な実行が求められる知識労働において、Claude の方がより信頼できることを示しています。
| エージェント評価指標 | Gemini 3.1 Pro | Claude Opus 4.6 | 差 |
|---|---|---|---|
| BrowseComp (検索) | 85.9% | 84.0% | +1.9pt |
| MCP Atlas (多段階) | 69.2% | 59.5% | +9.7pt |
| APEX-Agents (長期サイクル) | 33.5% | 29.8% | +3.7pt |
| OSWorld (コンピュータ操作) | — | 72.7% | Claude 独占 |
| GDPval-AA (専門タスク) | 1317 Elo | 1606 Elo | +289 |
比較 4:Gemini 3.1 Pro vs Claude Opus 4.6 の思考システム・アーキテクチャ
どちらのモデルも「思考(Reasoning)」メカニズムを備えていますが、その設計思想は異なります。
Gemini 3.1 Pro:3段階の思考システム
| レベル | 名称 | 特徴 | 活用シーン |
|---|---|---|---|
| Low | クイックレスポンス | 遅延がほぼゼロ | シンプルな質疑応答、翻訳 |
| Medium | バランス推論 | 中程度の遅延(新機能) | 日常的なコーディング、分析 |
| High | Deep Think Mini | 深い推論、8分でIMOの問題を解く | 数学、複雑なデバッグ |
Gemini 3.1 Pro の High モードは、実質的に Deep Think(Google 専用の推論モデル)のミニ版であり、一つのモデルの中に専用の推論エンジンが組み込まれているような形です。
Claude Opus 4.6:適応型思考システム
| レベル | 名称 | 特徴 | 活用シーン |
|---|---|---|---|
| Low | クイックモード | 最小限の推論コスト | シンプルなタスク |
| Medium | バランスモード | 適度な推論 | 標準的な開発 |
| High | ディープモード (デフォルト) | 推論の深さを自動判断 | ほとんどのタスク |
| Max | 最大推論 | 全力で推論を実行 | 極めて困難な問題 |
Claude の特徴は**適応型思考(Adaptive Thinking)**です。モデルが問題の複雑さに応じて投入する推論リソースを自動的に決定するため、開発者が手動で選択する必要はありません。デフォルトの High モードですでに非常にインテリジェントです。
🎯 実用的な比較: Gemini はよりきめ細かな手動制御(3段階)を提供し、コストとレイテンシを厳密にコントロールしたいシーンに適しています。一方、Claude はよりスマートな自動適応(4段階+適応型)を提供し、「設定したらあとはお任せ」という本番環境に適しています。どちらのモデルも APIYI (apiyi.com) で直接呼び出して比較することが可能です。
比較 5:Gemini 3.1 Pro vs Claude Opus 4.6 の料金とコスト
コストは本番環境における重要な検討事項です。これら2つのモデルの価格差は顕著です。
| 料金体系 | Gemini 3.1 Pro | Claude Opus 4.6 | Gemini のコスパ |
|---|---|---|---|
| 入力(標準) | $2.00 / 1M tokens | $5.00 / 1M tokens | 2.5倍安い |
| 出力(標準) | $12.00 / 1M tokens | $25.00 / 1M tokens | 2.1倍安い |
| 入力(長いコンテキスト >200K) | $4.00 / 1M tokens | $10.00 / 1M tokens | 2.5倍安い |
| 出力(長いコンテキスト >200K) | $18.00 / 1M tokens | $37.50 / 1M tokens | 2.1倍安い |
実利用シーンでのコスト見積もり
1日あたり100万入力トークン + 20万出力トークンを処理する場合の計算:
| シナリオ | Gemini 3.1 Pro | Claude Opus 4.6 | 月間の節約額 |
|---|---|---|---|
| 日常的な呼び出し | $4.40/日 | $10.00/日 | $168/月 |
| ヘビーユース (3倍) | $13.20/日 | $30.00/日 | $504/月 |
Gemini 3.1 Proは、すべての料金体系においてClaude Opus 4.6の約半額です。コストに敏感なプロジェクトにとって、これは非常に大きなメリットとなります。
💰 コスト最適化のアドバイス: APIYI(apiyi.com)プラットフォームを通じてこれらのモデルを呼び出すことで、柔軟な課金と一元管理が可能になります。まずは小規模なテストで効果を確認してから、メインのモデルを決定することをお勧めします。
比較 6:Gemini 3.1 Pro vs Claude Opus 4.6 のコンテキストウィンドウと出力
| 仕様 | Gemini 3.1 Pro | Claude Opus 4.6 | 優位性 |
|---|---|---|---|
| コンテキストウィンドウ | 1,000,000 tokens | 200,000 tokens (1M beta) | Gemini |
| 最大出力 | 64,000 tokens | 128,000 tokens | Claude |
| アップロードファイルサイズ | 100MB | — | Gemini |
コンテキストウィンドウ:Geminiが5倍リード
Gemini 3.1 Proは標準で100万トークンのコンテキストをサポートしていますが、Claude Opus 4.6の標準は20万トークンです(100万はベータ版)。大規模なコードリポジトリ、長いドキュメント、または動画を分析する必要があるシナリオでは、Geminiの優位性が際立ちます。
最大出力:Claudeが2倍リード
Claude Opus 4.6は128Kトークンの出力をサポートしており、これはGeminiの2倍です。これは長文生成、詳細なコード生成、そして深い推論チェーンにおいて極めて重要です。出力スペースが長いほど、モデルはより十分に「思考」を巡らせることができます。
比較 7: Gemini 3.1 Pro vs Claude Opus 4.6 マルチモーダル能力
マルチモーダル能力は、Geminiが伝統的に得意とする分野です。
| モダリティ | Gemini 3.1 Pro | Claude Opus 4.6 |
|---|---|---|
| テキスト入力 | ✅ | ✅ |
| 画像入力 | ✅ (ネイティブ) | ✅ |
| 動画入力 | ✅ (ネイティブ) | ❌ |
| 音声入力 | ✅ (ネイティブ) | ❌ |
| PDF 処理 | ✅ | ✅ |
| YouTube URL | ✅ | ❌ |
| SVG 生成 | ✅ (ネイティブ) | ✅ |
Gemini 3.1 Proは真のフルモーダルモデルであり、トレーニングアーキテクチャの段階からテキスト、画像、音声、動画の統合的な理解をネイティブにサポートしています。一方、Claude Opus 4.6のマルチモーダル機能は、テキストと画像に限定されています。
動画分析、音声の文字起こし、あるいはマルチメディアコンテンツの理解を伴うアプリケーションを構築する場合、Gemini 3.1 Proは現在、唯一無二の選択肢となります。
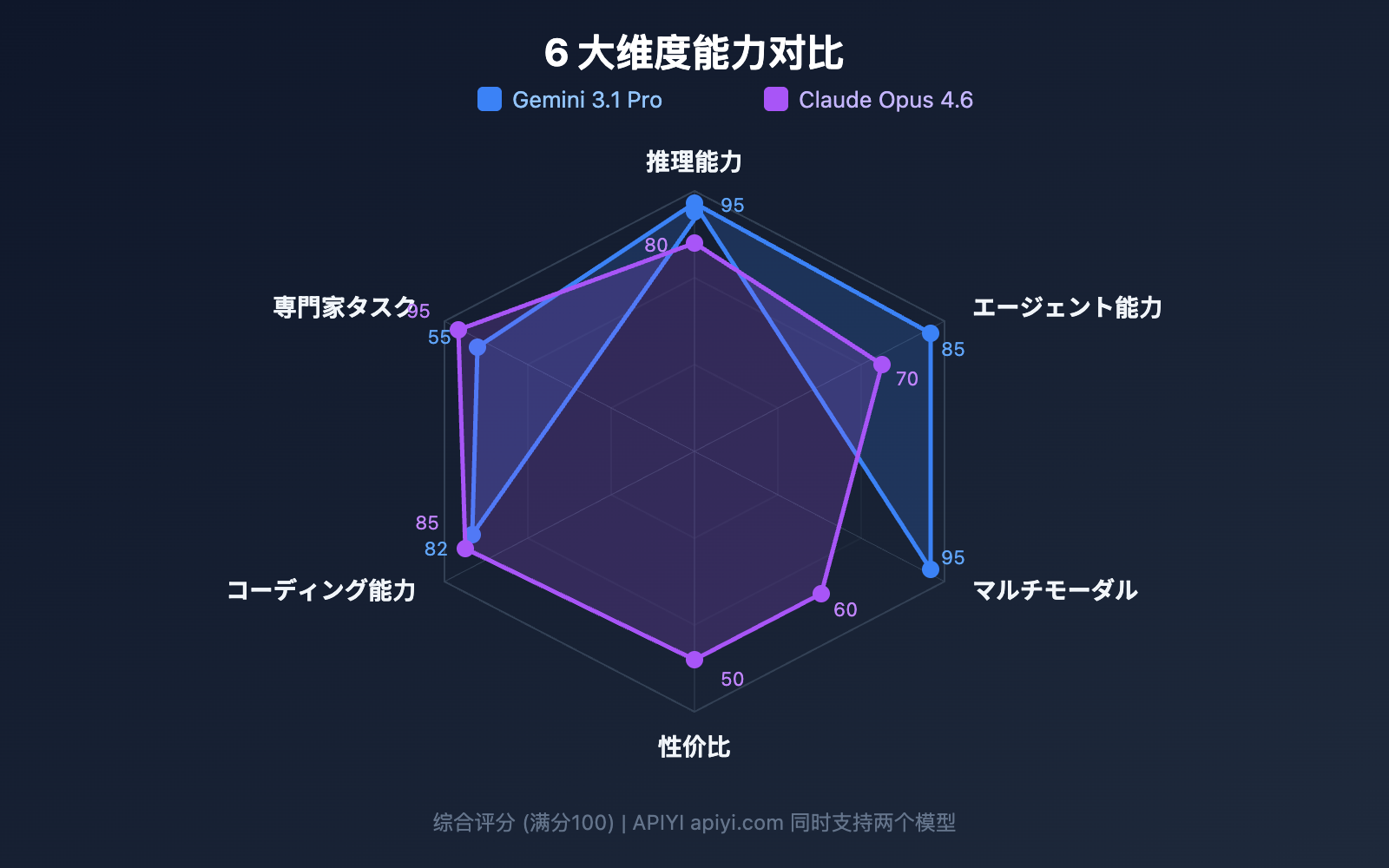
比較 8: Gemini 3.1 Pro vs Claude Opus 4.6 独自の機能
Gemini 3.1 Pro 独自の機能
| 機能 | 説明 | 価値 |
|---|---|---|
| Deep Think Mini | Highモードに組み込まれた専用推論エンジン | 数学・競技レベルの高度な推論 |
| グラウンディング (検索) | 月間 5,000 回の無料検索 | リアルタイム情報の強化 |
| 100MB ファイルアップロード | 1回あたりの大容量ファイルアップロード | 大規模なコードベース・データ分析 |
| YouTube URL 分析 | 動画URLを直接入力して内容を理解 | 動画コンテンツの効率的な分析 |
| 音動画ネイティブ理解 | エンドツーエンドのマルチモーダル処理 | 次世代のマルチメディアAIアプリ |
Claude Opus 4.6 独自の機能
| 機能 | 説明 | 価値 |
|---|---|---|
| コンピュータ操作 (OSWorld 72.7%) | GUI画面の自動操作 | RPA・自動テストの高度化 |
| 自適応思考 (Adaptive Thinking) | 推論の深さを自動的に判断 | 設定不要のインテリジェントな推論 |
| 128K 出力 | 超ロング出力のサポート | 長文生成・深い推論プロセス |
| バッチ API (50% 割引) | 非同期の一括処理 | 大規模データのコスト効率的な処理 |
| 高速モード | 6倍の料金でより高速な出力を実現 | 低遅延が求められる本番環境 |
Gemini 3.1 Pro vs Claude Opus 4.6 シーン別選択ガイド
以上の8つの観点からの比較に基づき、明確な推奨利用シーンを以下にまとめました。
Gemini 3.1 Pro を選択すべきシーン
| 利用シーン | 主な強み | 推奨理由 |
|---|---|---|
| 抽象的推論・数学 | ARC-AGI-2 +8.3pp | Deep Think Mini が非常に強力 |
| マルチステップ・エージェント | MCP Atlas +9.7pp | ワークフローの実行力が最強 |
| 動画・音声分析 | ネイティブ・マルチモーダル | 唯一の全モーダル対応の選択肢 |
| コスト重視のプロジェクト | 価格が2〜2.5倍安い | 同等の品質をより低コストで実現 |
| 大規模ドキュメント分析 | 1M コンテキスト | 超巨大コンテキストを標準サポート |
| 科学研究 | GPQA +3.0pp | 科学的推論能力が最も高い |
Claude Opus 4.6 を選択すべきシーン
| 利用シーン | 主な強み | 推奨理由 |
|---|---|---|
| 実践的なソフトウェア開発 | SWE-Bench 80.8% | 実際のバグ修正において最も正確 |
| エキスパートレベルのナレッジワーク | GDPval-AA +289 Elo | レポート・分析・意思決定において最強 |
| コンピュータ自動化 | OSWorld 72.7% | 唯一 GUI 操作をサポート |
| ツール強化型推論 | HLE+tools +1.7pp | 複数ツールの連携が最適 |
| 超長文出力のニーズ | 128K 出力 | 長文や深い推論チェーンに対応 |
| 低遅延な本番環境 | 高速モード | コストをかけて速度を優先する場合 |
両方の併用:インテリジェント・ルーティング構成
多くの本番環境において、最適な解決策は2つのモデルを同時に使用し、タスクの種類に応じてインテリジェントにルーティングすることです。
| タスクタイプ | ルーティング先 | 理由 | 推定割合 |
|---|---|---|---|
| 一般的なQ&A・翻訳 | Gemini 3.1 Pro | 低コストで十分な品質 | 40% |
| コード生成・デバッグ | Claude Opus 4.6 | SWE-Bench でわずかに優位 | 20% |
| 推論・数学・科学 | Gemini 3.1 Pro | ARC-AGI-2 で大幅にリード | 15% |
| エージェント・ワークフロー | Gemini 3.1 Pro | MCP Atlas +9.7pp | 10% |
| エキスパートレベルの分析・レポート | Claude Opus 4.6 | GDPval-AA で明確にリード | 10% |
| 動画・音声処理 | Gemini 3.1 Pro | 唯一の全モーダル対応 | 5% |
上記の比率でルーティングを行うことで、すべて Claude を使用する場合と比較して、全体的なコストを約 55% 削減しつつ、各細分化されたシーンで最高の品質を得ることができます。
Gemini 3.1 Pro vs Claude Opus 4.6 コスト最適化戦略
戦略 1: 処理の階層化
単純なタスクには Gemini Low モード(最速・最安)を使用し、中程度のタスクには Gemini Medium、真に複雑なタスクにのみ Claude High または Gemini High (Deep Think Mini) を使用します。
戦略 2: バッチ処理とリアルタイム処理の分離
リアルタイムのレスポンスが必要なリクエストには Gemini 3.1 Pro(低遅延・低コスト)を使用し、オフラインのバッチ処理には Claude の Batch API(50% オフ)を利用することで、総合的なコストを抑えられます。
戦略 3: コンテキスト・キャッシュ
Gemini はコンテキスト・キャッシュを提供しています(入力 $0.20-$0.40/MTok)。同じ長いドキュメントを繰り返し使用するシーンでは、キャッシュを利用することでコストを 80% 以上削減できます。
🚀 クイック検証: APIYI (apiyi.com) プラットフォームを利用すれば、1つの API Key で Gemini 3.1 Pro と Claude Opus 4.6 を同時に呼び出すことができます。実際の業務プロンプトで A/B テストを行うことをお勧めします。10分ほどで結論が出るはずです。
Gemini 3.1 Pro vs Claude Opus 4.6 クイックスタート
以下のコードは、APIYI の統合インターフェースを使用して、2つのモデルを同時に呼び出し比較テストを行う方法を示しています。
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 統合インターフェース
)
def compare_models(prompt, models=None):
"""2つのモデルの出力品質と速度を比較する"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-opus-4-6"]
results = {}
for model in models:
start = time.time()
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
elapsed = time.time() - start
results[model] = {
"time": f"{elapsed:.2f}s",
"tokens": resp.usage.total_tokens,
"answer": resp.choices[0].message.content[:300]
}
for model, data in results.items():
print(f"\n{'='*50}")
print(f"モデル: {model}")
print(f"所要時間: {data['time']} | トークン数: {data['tokens']}")
print(f"回答: {data['answer']}...")
# 推論能力のテスト
compare_models("0.1 + 0.2 が 0.3 にならない理由を、思考の連鎖(Chain of Thought)を用いて説明してください")
思考レベル制御を含む完全なコードを表示
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def compare_with_thinking(prompt, thinking_config=None):
"""異なる思考レベルでのモデルのパフォーマンスを比較する"""
configs = [
{"model": "gemini-3.1-pro-preview", "label": "Gemini Medium",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 8000}}},
{"model": "gemini-3.1-pro-preview", "label": "Gemini High (Deep Think Mini)",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 32000}}},
{"model": "claude-opus-4-6", "label": "Claude High (デフォルト適応型)",
"extra": {}},
]
for cfg in configs:
start = time.time()
params = {
"model": cfg["model"],
"messages": [{"role": "user", "content": prompt}],
**cfg["extra"]
}
resp = client.chat.completions.create(**params)
elapsed = time.time() - start
print(f"\n[{cfg['label']}] {elapsed:.2f}s | {resp.usage.total_tokens} tokens")
print(f" → {resp.choices[0].message.content[:200]}...")
# 複雑な推論のテスト
compare_with_thinking("証明してください:すべての正の整数 n について、n^3 - n は 6 で割り切れる")
よくある質問
Q1: Gemini 3.1 Pro と Claude Opus 4.6 はどちらが優れていますか?
どちらかが絶対的に「優れている」ということはありません。Gemini 3.1 Pro は抽象的推論(ARC-AGI-2 +8.3pp)、マルチステップ・エージェント(MCP Atlas +9.7pp)、マルチモーダル機能、およびコスト面でリードしています。一方、Claude Opus 4.6 は実際のソフトウェアエンジニアリング(SWE-Bench)、専門知識を要するタスク(GDPval-AA +289 Elo)、コンピュータ操作、およびツール推論において優位に立っています。APIYI(apiyi.com)を通じて、実際の利用シーンで A/B テストを行うことをお勧めします。
Q2: 2つのモデルの API インターフェースに互換性はありますか? 簡単に切り替えられますか?
APIYI(apiyi.com)プラットフォームを利用することで、両モデルとも統一された OpenAI 互換インターフェースを使用できます。切り替えは model パラメータを変更するだけ(gemini-3.1-pro-preview → claude-opus-4-6)で、他のコードを修正する必要は一切ありません。
Q3: 予算が限られている場合はどちらを選ぶべきですか?
Gemini 3.1 Pro を優先的に選択することをお勧めします。入力価格は Claude Opus 4.6 の 40%($2 vs $5)、出力価格は半分以下($12 vs $25)です。ほとんどのベンチマークにおいて Gemini のパフォーマンスは引けを取らないか、むしろ上回っており、コストパフォーマンスが非常に高いです。SWE-Bench や専門的なタスクなど、Claude が明らかに優位なシナリオでのみ Claude を使用するのが賢明です。
Q4: 2つのモデルを同時に使ってインテリジェント・ルーティングを行うことは可能ですか?
はい、可能です。推奨されるアーキテクチャは、Gemini 3.1 Pro で一般的なリクエストの 80% を処理し(低コスト・高推論)、Claude Opus 4.6 でエキスパートレベルのタスクやツール拡張シナリオの 20% を処理する構成です。APIYI(apiyi.com)の統一インターフェースを使えば、コード内でタスクの種類を判断し、model パラメータを切り替えるだけでインテリジェント・ルーティングを実現できます。
まとめ: Gemini 3.1 Pro vs Claude Opus 4.6 選択の決め手
| # | 比較項目 | Gemini 3.1 Pro | Claude Opus 4.6 | 勝者 |
|---|---|---|---|---|
| 1 | 抽象的推論 | ARC-AGI-2 77.1% | 68.8% | Gemini |
| 2 | コーディング能力 | SWE-Bench 80.6% | 80.8% | Claude (僅差) |
| 3 | エージェント・ワークフロー | MCP Atlas 69.2% | 59.5% | Gemini |
| 4 | 専門的タスク | GDPval 1317 | 1606 | Claude |
| 5 | マルチモーダル | 全モーダル (文/図/音/動画) | 文/図 | Gemini |
| 6 | 価格 | $2/$12 (1M Tokあたり) | $5/$25 (1M Tokあたり) | Gemini (2倍安価) |
| 7 | コンテキストウィンドウ | 1M (標準) | 200K (1M beta) | Gemini |
| 8 | 最大出力 | 64K tokens | 128K tokens | Claude |
| 9 | 思考システム | レベル3 + Deep Think Mini | レベル4 + 適応型 | それぞれに強み |
| 10 | コンピュータ操作 | 未対応 | OSWorld 72.7% | Claude 独占 |
最終的なアドバイス:
- コスパ優先 → Gemini 3.1 Pro(2倍安く、推論も強力)
- ソフトウェアエンジニアリング優先 → Claude Opus 4.6(SWE-Bench、GDPval でリード)
- マルチモーダル優先 → Gemini 3.1 Pro(全モーダル対応の唯一の選択肢)
- ベストプラクティス → 両方を採用し、インテリジェント・ルーティングを活用
APIYI(apiyi.com)プラットフォームを通じて両方のモデルに同時にアクセスし、統一インターフェースによる柔軟なスケジューリングと A/B テストを実現することをお勧めします。
参考文献
-
Google 公式ブログ: Gemini 3.1 Pro リリースのお知らせ
- リンク:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - 説明: 公式ベンチマークデータと機能紹介
- リンク:
-
Anthropic 公式アナウンス: Claude Opus 4.6 リリース詳細
- リンク:
anthropic.com/news/claude-opus-4-6 - 説明: Claude Opus 4.6 の技術仕様とベンチマークデータ
- リンク:
-
Artificial Analysis: 第三者機関による比較レビュー
- リンク:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - 説明: 独立したベンチマーク比較とパフォーマンス分析
- リンク:
-
Google DeepMind: モデルカードと安全性評価
- リンク:
deepmind.google/models/model-cards/gemini-3-1-pro - 説明: 詳細な技術パラメータと安全性データ
- リンク:
-
VentureBeat: Deep Think Mini 詳細レビュー
- リンク:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - 説明: 3段階思考システムの実際の検証
- リンク:
📝 著者: APIYI チーム | 技術的な交流については APIYI(apiyi.com)をご覧ください
📅 更新日: 2026年2月20日
🏷️ キーワード: Gemini 3.1 Pro vs Claude Opus 4.6, モデル比較, ARC-AGI-2, SWE-Bench, MCP Atlas, マルチモーダル, API呼び出し