Gemini 3.1 Pro Preview vs. Claude Opus 4.6 – für wen soll man sich entscheiden? Das ist die zentrale Frage, um die KI-Entwickler Anfang 2026 nicht herumkommen. Dieser Artikel bietet einen umfassenden Vergleich anhand von 10 Kerndimensionen, gestützt auf offizielle Benchmark-Daten und Drittanbieter-Tests, um Ihnen eine fundierte Entscheidungshilfe zu bieten.
Kernwert: Nach der Lektüre dieses Artikels werden Sie genau wissen, welches Modell Sie für verschiedene Szenarien wählen sollten und wie Sie dies in Ihren Projekten schnell validieren können.

Gemini 3.1 Pro vs. Claude Opus 4.6: Überblick über die Benchmark-Daten
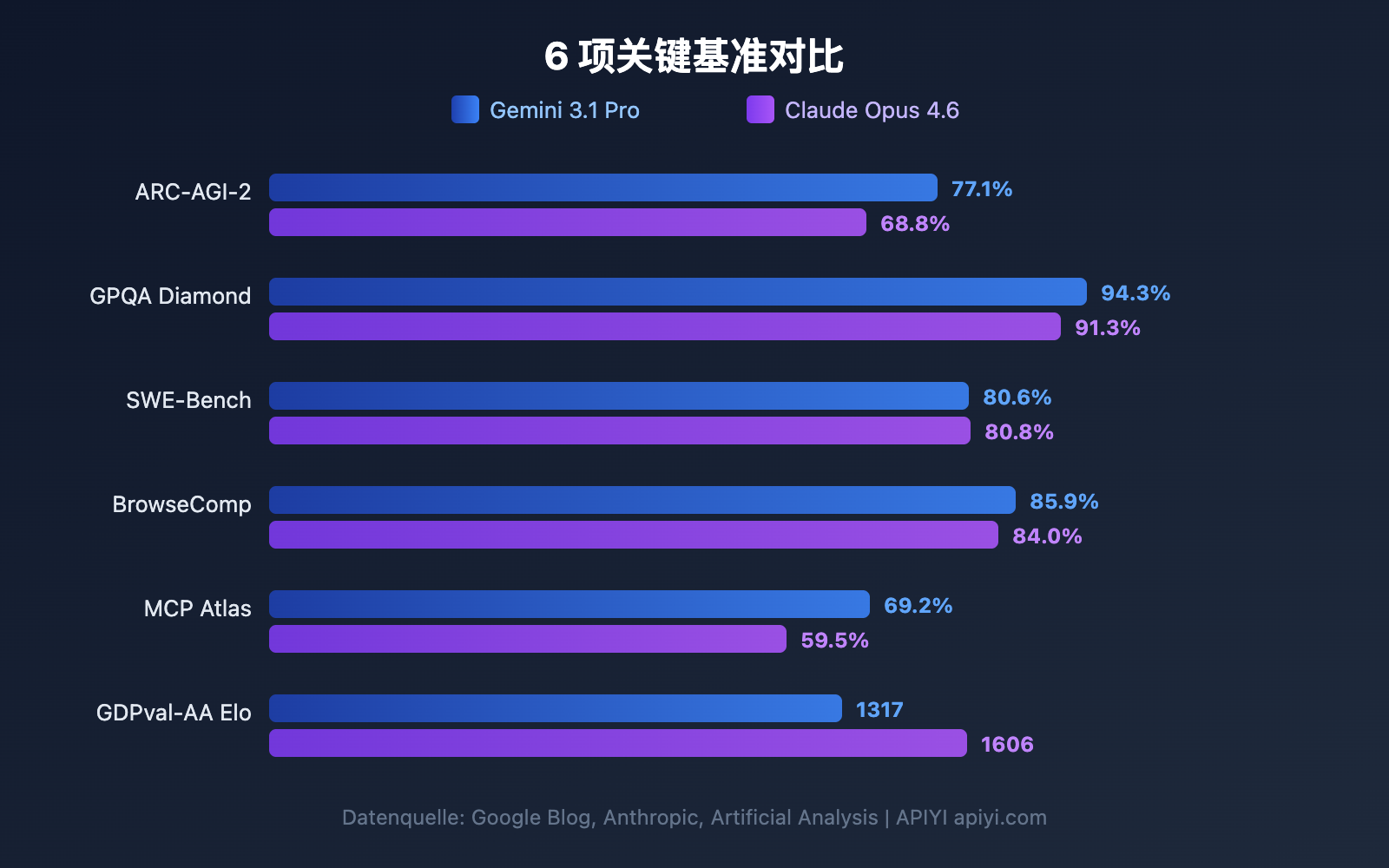
Bevor wir in die einzelnen Dimensionen eintauchen, werfen wir einen Blick auf den globalen Benchmark-Vergleich. Google behauptet, dass Gemini 3.1 Pro in 13 von 16 Benchmarks führt, während Claude Opus 4.6 in mehreren Praxisszenarien punktet.
| Benchmark | Gemini 3.1 Pro | Claude Opus 4.6 | Sieger | Differenz |
|---|---|---|---|---|
| ARC-AGI-2 (Abstraktes Denken) | 77,1 % | 68,8 % | Gemini | +8,3 pp |
| GPQA Diamond (PhD-Wissenschaft) | 94,3 % | 91,3 % | Gemini | +3,0 pp |
| SWE-Bench Verified (Software-Engineering) | 80,6 % | 80,8 % | Claude | +0,2 pp |
| Terminal-Bench 2.0 (Terminal-Coding) | 68,5 % | 65,4 % | Gemini | +3,1 pp |
| BrowseComp (Agent-Suche) | 85,9 % | 84,0 % | Gemini | +1,9 pp |
| MCP Atlas (Mehrstufige Agenten) | 69,2 % | 59,5 % | Gemini | +9,7 pp |
| HLE ohne Tools (Ultimative Prüfung) | 44,4 % | 40,0 % | Gemini | +4,4 pp |
| HLE mit Tools (Ultimative Prüfung) | 51,4 % | 53,1 % | Claude | +1,7 pp |
| SciCode (Wissenschaftliches Coding) | 59 % | 52 % | Gemini | +7 pp |
| MMMLU (Mehrsprachige QA) | 92,6 % | 91,1 % | Gemini | +1,5 pp |
| tau2-bench Retail (Tool-Aufrufe) | 90,8 % | 91,9 % | Claude | +1,1 pp |
| GDPval-AA Elo (Expertenaufgaben) | 1317 | 1606 | Claude | +289 |
📊 Datenhinweis: Die oben genannten Daten stammen aus den offiziellen Google-Blogs, Anthropic-Ankündigungen und Drittanbieter-Tests von Artificial Analysis. Über APIYI (apiyi.com) können Sie beide Modelle gleichzeitig aufrufen, um sie in realen Szenarien zu testen.
Vergleich 1: Gemini 3.1 Pro vs. Claude Opus 4.6 – Schlussfolgerungsfähigkeiten
Die Reasoning-Fähigkeit (Schlussfolgerung) ist die Kernkompetenz eines Großen Sprachmodells. Die Reasoning-Architekturen der beiden Modelle unterscheiden sich erheblich.
Abstraktes Denken: Gemini 3.1 Pro liegt deutlich vorn
ARC-AGI-2 ist derzeit der maßgebliche Benchmark für abstraktes Denken. Gemini 3.1 Pro erzielt hier 77,1 %, was 8,3 Prozentpunkte über den 68,8 % von Claude Opus 4.6 liegt. Das bedeutet, dass Gemini bei Aufgaben, die das Ableiten von Regeln aus nur wenigen Beispielen erfordern, deutlich stärker ist.
Wissenschaftliches Denken auf PhD-Niveau: Gemini mit klarem Vorteil
Der GPQA Diamond Test prüft wissenschaftliche Fragestellungen auf PhD-Niveau. Hier erreicht Gemini 3.1 Pro 94,3 %, während Claude Opus 4.6 auf 91,3 % kommt. Ein Unterschied von 3 Prozentpunkten ist auf diesem extremen Schwierigkeitsgrad sehr signifikant.
Werkzeuggestütztes Reasoning: Claude überholt
Beim HLE (Humanity's Last Exam) liegt Gemini ohne Werkzeuge vorne (44,4 % vs. 40,0 %). Sobald jedoch externe Werkzeuge zugeschaltet werden, übernimmt Claude die Führung (53,1 % vs. 51,4 %). Dies zeigt, dass Claude Opus 4.6 geschickter darin ist, externe Tools zur Unterstützung komplexer Argumentationsketten zu nutzen.
| Reasoning-Dimension | Gemini 3.1 Pro | Claude Opus 4.6 | Ideal für |
|---|---|---|---|
| Abstraktes Denken | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Mustererkennung, Regelinduktion |
| Wissenschaftliches Denken | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Akademische Forschung, Unterstützung bei Publikationen |
| Werkzeuggestütztes Reasoning | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Komplexe Workflows, Multi-Tool-Kollaboration |
| Mathematisches Denken | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Spezialgebiet von Deep Think Mini |
Vergleich 2: Gemini 3.1 Pro vs. Claude Opus 4.6 – Coding-Fähigkeiten
Die Programmierfähigkeit ist die Dimension, die für Entwickler am wichtigsten ist. Die Leistung beider Modelle liegt hier sehr nah beieinander, setzt jedoch unterschiedliche Schwerpunkte.
SWE-Bench: Nahezu gleichauf
SWE-Bench Verified ist ein Benchmark für die Behebung realer GitHub-Issues:
- Claude Opus 4.6: 80,8 % (hauchdünner Vorsprung)
- Gemini 3.1 Pro: 80,6 %
Mit einem Unterschied von nur 0,2 Prozentpunkten kann man davon ausgehen, dass beide Modelle bei realen Software-Engineering-Aufgaben praktisch gleichwertig sind.
Terminal-Bench: Gemini im Vorteil
Terminal-Bench 2.0 testet die Fähigkeiten von KI-Agenten in einer Terminal-Umgebung:
- Gemini 3.1 Pro: 68,5 %
- Claude Opus 4.6: 65,4 %
Der Vorsprung von 3,1 Prozentpunkten deutet darauf hin, dass Gemini in Szenarien mit Terminal-Agenten eine präzisere Ausführung bietet.
Wettbewerbsprogrammierung: Gemini führt
Daten von LiveCodeBench Pro zeigen, dass Gemini 3.1 Pro ein Elo-Rating von 2887 erreicht und damit bei Programmierwettbewerben exzellent abschneidet. Die entsprechenden Daten für Claude Opus 4.6 sind noch nicht vollständig öffentlich, aber basierend auf Wettbewerben wie USACO spielt auch Claude auf absolutem Top-Niveau.
# Testen der Coding-Fähigkeiten beider Modelle gleichzeitig via APIYI
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Einheitliche Schnittstelle von APIYI
)
# Dieselbe Coding-Aufgabe für beide Modelle
coding_prompt = "Implementiere einen LRU-Cache, der get- und put-Operationen unterstützt, Zeitkomplexität O(1)"
for model in ["gemini-3.1-pro-preview", "claude-opus-4-6"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": coding_prompt}]
)
print(f"\n{'='*50}")
print(f"Modell: {model}")
print(f"Token-Verbrauch: {resp.usage.total_tokens}")
print(f"Antwort:\n{resp.choices[0].message.content[:500]}")
Vergleich 3: Gemini 3.1 Pro vs. Claude Opus 4.6 Agent-Fähigkeiten
Agenten und autonome Workflows sind die Kernszenarien des Jahres 2026. Dies ist einer der Bereiche, in denen die Unterschiede zwischen den beiden Modellen am deutlichsten sind.
Agent-Suche: Ein enges Rennen
BrowseComp testet die autonomen Web-Such- und Informationsextraktionsfähigkeiten der Modelle:
- Gemini 3.1 Pro: 85,9 %
- Claude Opus 4.6: 84,0 %
Der Unterschied beträgt lediglich 1,9 Prozentpunkte – beide bewegen sich auf absolutem Top-Niveau.
Mehrstufige Agenten: Gemini liegt deutlich vorn
MCP Atlas testet komplexe, mehrstufige Workflows. Hier erzielt Gemini 3.1 Pro eine Punktzahl von 69,2 %, was fast 10 Prozentpunkte über den 59,5 % von Claude Opus 4.6 liegt. Dies ist einer der Benchmarks mit der größten Diskrepanz zwischen den beiden Modellen.
Computer-Bedienung: Claude mit exklusivem Vorteil
Der OSWorld-Benchmark testet die Fähigkeit eines Modells, echte grafische Benutzeroberflächen (GUIs) zu bedienen. Claude Opus 4.6 erreicht hier einen Wert von 72,7 %. Gemini hat für diesen Bereich noch keine Ergebnisse veröffentlicht. Das bedeutet: Wenn Sie eine KI benötigen, die Desktop-Anwendungen automatisch bedient, ist Claude derzeit die einzige Wahl.
Aufgaben auf Expertenniveau: Claude führt deutlich
GDPval-AA testet Aufgaben auf Expertenniveau in realen Büroumgebungen (Datenanalyse, Berichterstellung usw.). Claude Opus 4.6 erreicht ein Elo-Rating von 1606 und übertrifft damit Gemini (1317) bei Weitem. Dies zeigt, dass Claude bei Wissensarbeit, die tiefes Verständnis und präzise Ausführung erfordert, zuverlässiger ist.
| Agent-Unterdimensionen | Gemini 3.1 Pro | Claude Opus 4.6 | Unterschied |
|---|---|---|---|
| BrowseComp (Suche) | 85,9 % | 84,0 % | +1,9 PP |
| MCP Atlas (Mehrstufig) | 69,2 % | 59,5 % | +9,7 PP |
| APEX-Agents (Lange Zyklen) | 33,5 % | 29,8 % | +3,7 PP |
| OSWorld (Computer-Bedienung) | — | 72,7 % | Claude exklusiv |
| GDPval-AA (Expertenaufgaben) | 1317 Elo | 1606 Elo | +289 |
Vergleich 4: Gemini 3.1 Pro vs. Claude Opus 4.6 Architektur der Denksysteme
Beide Modelle verfügen über „Deep Thinking“-Mechanismen, verfolgen jedoch unterschiedliche Designphilosophien.
Gemini 3.1 Pro: Dreistufiges Denksystem
| Ebene | Name | Merkmale | Anwendungsszenarien |
|---|---|---|---|
| Low | Schnelle Antwort | Nahezu keine Verzögerung | Einfache Fragen, Übersetzungen |
| Medium | Ausgewogene Inferenz | Mittlere Verzögerung (neu) | Alltägliches Coding, Analysen |
| High | Deep Think Mini | Tiefe Inferenz, löst IMO-Aufgaben in 8 Min. | Mathematik, komplexes Debugging |
Der High-Modus von Gemini 3.1 Pro ist im Grunde eine Mini-Version von Deep Think (Googles spezialisiertem Inferenzmodell). Es ist so, als wäre eine dedizierte Inferenz-Engine direkt in das Modell eingebettet.
Claude Opus 4.6: Adaptives Denksystem
| Ebene | Name | Merkmale | Anwendungsszenarien |
|---|---|---|---|
| Low | Schnellmodus | Minimaler Inferenzaufwand | Einfache Aufgaben |
| Medium | Ausgewogener Modus | Moderate Inferenz | Reguläre Entwicklung |
| High | Tiefenmodus (Standard) | Automatische Bestimmung der Inferenztiefe | Die meisten Aufgaben |
| Max | Maximale Inferenz | Volle Inferenzleistung | Extrem schwierige Probleme |
Das Besondere an Claude ist das adaptive Denken — das Modell entscheidet basierend auf der Komplexität der Frage automatisch, wie viele Inferenzressourcen investiert werden. Entwickler müssen dies nicht manuell auswählen. Der Standard-High-Modus ist bereits extrem intelligent.
🎯 Praktischer Vergleich: Gemini bietet Ihnen eine feinere manuelle Steuerung (3 Stufen), ideal für Szenarien, in denen Kosten und Latenz präzise kontrolliert werden müssen. Claude bietet eine intelligentere automatische Anpassung (4 Stufen + adaptiv), ideal für „Set-and-forget“-Produktionsumgebungen. Beide Modelle können direkt über APIYI apiyi.com aufgerufen und verglichen werden.
Vergleich 5: Gemini 3.1 Pro vs. Claude Opus 4.6 – Preise und Kosten
Die Kosten sind ein entscheidender Faktor in Produktionsumgebungen. Die Preisunterschiede zwischen den beiden Modellen sind signifikant.
| Preisdimension | Gemini 3.1 Pro | Claude Opus 4.6 | Gemini Preis-Leistung |
|---|---|---|---|
| Eingabe (Standard) | $2.00 / 1M Tokens | $5.00 / 1M Tokens | 2.5x günstiger |
| Ausgabe (Standard) | $12.00 / 1M Tokens | $25.00 / 1M Tokens | 2.1x günstiger |
| Eingabe (Langer Kontext >200K) | $4.00 / 1M Tokens | $10.00 / 1M Tokens | 2.5x günstiger |
| Ausgabe (Langer Kontext >200K) | $18.00 / 1M Tokens | $37.50 / 1M Tokens | 2.1x günstiger |
Kostenschätzung für Praxisszenarien
Berechnet auf Basis von 1 Million Eingabe-Tokens + 200.000 Ausgabe-Tokens pro Tag:
| Szenario | Gemini 3.1 Pro | Claude Opus 4.6 | Monatliche Ersparnis |
|---|---|---|---|
| Tägliche Aufrufe | $4.40/Tag | $10.00/Tag | $168/Monat |
| Intensive Nutzung (3x) | $13.20/Tag | $30.00/Tag | $504/Monat |
Gemini 3.1 Pro kostet in allen Preisdimensionen etwa die Hälfte von Claude Opus 4.6. Für kostensensible Projekte ist dies ein sehr signifikanter Vorteil.
💰 Kosteneffizienz-Tipp: Über die Plattform APIYI (apiyi.com) können Sie beide Modelle mit flexibler Abrechnung und zentraler Verwaltung nutzen. Es wird empfohlen, die Ergebnisse zunächst mit kleinen Testmengen zu validieren, bevor Sie sich für ein Hauptmodell entscheiden.
Vergleich 6: Gemini 3.1 Pro vs. Claude Opus 4.6 – Kontextfenster und Ausgabe
| Spezifikationen | Gemini 3.1 Pro | Claude Opus 4.6 | Vorteil bei |
|---|---|---|---|
| Kontextfenster | 1.000.000 Tokens | 200.000 Tokens (1M Beta) | Gemini |
| Maximale Ausgabe | 64.000 Tokens | 128.000 Tokens | Claude |
| Dateigröße für Uploads | 100MB | — | Gemini |
Kontextfenster: Gemini führt mit dem 5-fachen Faktor
Gemini 3.1 Pro unterstützt standardmäßig ein Kontextfenster von 1 Million Tokens, während Claude Opus 4.6 standardmäßig bei 200.000 liegt (1 Million in der Beta-Phase). Für Szenarien, die die Analyse großer Code-Repositories, langer Dokumente oder Videos erfordern, ist der Vorteil von Gemini sehr deutlich.
Maximale Ausgabe: Claude führt mit der doppelten Kapazität
Claude Opus 4.6 unterstützt eine Ausgabe von 128K Tokens, was dem Doppelten von Gemini entspricht. Dies ist entscheidend für die Generierung langer Texte, detaillierten Code und tiefe Argumentationsketten – ein größerer Ausgabebereich bedeutet, dass das Modell gründlicher „nachdenken“ kann.
Vergleich 7: Multimodale Fähigkeiten von Gemini 3.1 Pro vs. Claude Opus 4.6
Multimodale Fähigkeiten sind traditionell eine Stärke von Gemini.
| Modalität | Gemini 3.1 Pro | Claude Opus 4.6 |
|---|---|---|
| Texteingabe | ✅ | ✅ |
| Bildeingabe | ✅ (nativ) | ✅ |
| Videoeingabe | ✅ (nativ) | ❌ |
| Audioeingabe | ✅ (nativ) | ❌ |
| PDF-Verarbeitung | ✅ | ✅ |
| YouTube-URL | ✅ | ❌ |
| SVG-Generierung | ✅ (nativ) | ✅ |
Gemini 3.1 Pro ist ein echtes omnimodales Modell, das von der Trainingsarchitektur her nativ ein einheitliches Verständnis von Text, Bild, Audio und Video unterstützt. Die Multimodalität von Claude Opus 4.6 beschränkt sich auf Text und Bild.
Wenn Ihre Anwendung Videoanalysen, Audiotranskriptionen oder das Verständnis von Multimedia-Inhalten umfasst, ist Gemini 3.1 Pro derzeit die einzige unterstützte Wahl.
Vergleich 8: Exklusive Funktionen von Gemini 3.1 Pro vs. Claude Opus 4.6
Exklusiv für Gemini 3.1 Pro
| Funktion | Beschreibung | Mehrwert |
|---|---|---|
| Deep Think Mini | Dedizierte Reasoning-Engine im High-Modus | Reasoning auf Mathematik-/Wettbewerbsniveau |
| Grounding (Suche) | 5.000 kostenlose Suchanfragen pro Monat | Echtzeit-Informationsanreicherung |
| 100 MB Datei-Upload | Upload großer Dateien in einem Durchgang | Analyse großer Code-Repositories/Datenmengen |
| YouTube-URL-Analyse | Direkte Eingabe von Video-URLs zum Verständnis | Analyse von Videoinhalten |
| Natives Audio-/Video-Verständnis | Multimodale End-to-End-Verarbeitung | Multimedia-KI-Anwendungen |
Exklusiv für Claude Opus 4.6
| Funktion | Beschreibung | Mehrwert |
|---|---|---|
| Computer Use (OSWorld 72,7 %) | Automatische Bedienung von GUI-Oberflächen | RPA/Automatisierte Tests |
| Adaptives Denken | Automatische Bestimmung der Reasoning-Tiefe | Intelligentes Reasoning ohne Konfiguration |
| 128K Output | Unterstützung für extrem lange Ausgaben | Langtexterstellung/Tiefgehendes Reasoning |
| Batch-API (50 % Rabatt) | Asynchrone Stapelverarbeitung | Großflächige Datenverarbeitung |
| Fast Mode | 6-fache Rate für schnellere Ausgabe | Produktionsszenarien mit geringer Latenz |
Gemini 3.1 Pro vs. Claude Opus 4.6: Leitfaden zur Szenarioauswahl
Basierend auf dem Vergleich der oben genannten 8 Dimensionen finden Sie hier klare Empfehlungen für verschiedene Szenarien:
Wann Sie Gemini 3.1 Pro wählen sollten
| Szenario | Hauptvorteil | Empfehlungsgrund |
|---|---|---|
| Abstrakte Schlussfolgerung/Mathematik | ARC-AGI-2 +8,3 pp | Deep Think Mini ist extrem leistungsstark |
| Mehrstufige Agenten | MCP Atlas +9,7 pp | Stärkste Ausführungskraft im Workflow |
| Video-/Audioanalyse | Natives Multimodal | Die einzige Wahl für alle Modalitäten |
| Kostensensible Projekte | 2-2,5x günstiger | Geringere Kosten bei gleicher Qualität |
| Analyse großer Dokumente | 1M Kontext | Standardunterstützung für riesige Kontextfenster |
| Wissenschaftliche Forschung | GPQA +3,0 pp | Stärkste wissenschaftliche Schlussfolgerungsfähigkeit |
Wann Sie Claude Opus 4.6 wählen sollten
| Szenario | Hauptvorteil | Empfehlungsgrund |
|---|---|---|
| Reales Software-Engineering | SWE-Bench 80,8 % | Präziseste Behebung echter Bugs |
| Wissensarbeit auf Expertenniveau | GDPval-AA +289 Elo | Bestens geeignet für Berichte/Analysen/Entscheidungen |
| Computer-Automatisierung | OSWorld 72,7 % | Einzige Unterstützung für GUI-Operationen |
| Werkzeuggestützte Schlussfolgerung | HLE+tools +1,7 pp | Optimale Synergie zwischen mehreren Werkzeugen |
| Bedarf an extrem langen Ausgaben | 128K Output | Lange Texte / tiefe Schlussfolgerungsketten |
| Produktionsumgebungen mit geringer Latenz | Fast-Modus | Bezahlung für höhere Geschwindigkeit |
Beide nutzen: Intelligente Routing-Architektur
In vielen Produktionsumgebungen ist die optimale Lösung die gleichzeitige Nutzung beider Modelle, mit intelligentem Routing je nach Aufgabentyp:
| Aufgabentyp | Weiterleiten an | Grund | Geschätzter Anteil |
|---|---|---|---|
| Allgemeine Fragen & Antworten / Übersetzung | Gemini 3.1 Pro | Niedrige Kosten, ausreichende Qualität | 40 % |
| Code-Generierung / Debugging | Claude Opus 4.6 | In SWE-Bench leicht überlegen | 20 % |
| Schlussfolgerung / Mathematik / Wissenschaft | Gemini 3.1 Pro | ARC-AGI-2 deutlich führend | 15 % |
| Agenten-Workflows | Gemini 3.1 Pro | MCP Atlas +9,7 pp | 10 % |
| Expertenanalyse / Berichte | Claude Opus 4.6 | GDPval-AA deutlich führend | 10 % |
| Video-/Audioverarbeitung | Gemini 3.1 Pro | Einzige Wahl für alle Modalitäten | 5 % |
Durch Routing in diesem Verhältnis lassen sich die Gesamtkosten im Vergleich zur ausschließlichen Nutzung von Claude um ca. 55 % senken, während in jedem Teilbereich die optimale Qualität erzielt wird.
Strategien zur Kostenoptimierung für Gemini 3.1 Pro vs. Claude Opus 4.6
Strategie 1: Gestufte Verarbeitung
Nutzen Sie für einfache Aufgaben den Gemini Low-Modus (am schnellsten und günstigsten), für mittlere Aufgaben Gemini Medium und nur für wirklich komplexe Aufgaben Claude High oder Gemini High (Deep Think Mini).
Strategie 2: Trennung von Batch- und Echtzeitverarbeitung
Echtzeitanfragen erfolgen über Gemini 3.1 Pro (geringe Latenz, niedrige Kosten), während die Offline-Batch-Verarbeitung über die Batch-API von Claude erfolgen kann (50 % Rabatt), wodurch die kombinierten Kosten ähnlich ausfallen.
Strategie 3: Kontext-Caching
Gemini bietet Kontext-Caching an (Input $0,20 – $0,40/MTok). In Szenarien, in denen dasselbe lange Dokument wiederholt verwendet wird, können die Kosten nach dem Caching um mehr als 80 % gesenkt werden.
🚀 Schnelltest: Über die Plattform APIYI (apiyi.com) können Sie mit demselben API-Key gleichzeitig Gemini 3.1 Pro und Claude Opus 4.6 aufrufen. Wir empfehlen, zunächst A/B-Tests mit Ihren tatsächlichen Business-Prompts durchzuführen; ein Ergebnis liegt meist in 10 Minuten vor.
Gemini 3.1 Pro vs. Claude Opus 4.6: Schnelleinstieg
Der folgende Code zeigt, wie Sie über die einheitliche Schnittstelle von APIYI beide Modelle gleichzeitig für einen Vergleichstest aufrufen können:
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Einheitliche APIYI-Schnittstelle
)
def compare_models(prompt, models=None):
"""Vergleicht die Ausgabequalität und Geschwindigkeit zweier Modelle"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-opus-4-6"]
results = {}
for model in models:
start = time.time()
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
elapsed = time.time() - start
results[model] = {
"time": f"{elapsed:.2f}s",
"tokens": resp.usage.total_tokens,
"answer": resp.choices[0].message.content[:300]
}
for model, data in results.items():
print(f"\n{'='*50}")
print(f"Modell: {model}")
print(f"Dauer: {data['time']} | Token: {data['tokens']}")
print(f"Antwort: {data['answer']}...")
# Test der Schlussfolgerungsfähigkeit
compare_models("Bitte erklären Sie mit Chain-of-Thought-Reasoning, warum 0.1 + 0.2 nicht gleich 0.3 ist.")
Vollständigen Code mit Steuerung der Denkebene anzeigen
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def compare_with_thinking(prompt, thinking_config=None):
"""Vergleicht die Modellleistung unter verschiedenen Denkebenen (Thinking Levels)"""
configs = [
{"model": "gemini-3.1-pro-preview", "label": "Gemini Medium",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 8000}}},
{"model": "gemini-3.1-pro-preview", "label": "Gemini High (Deep Think Mini)",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 32000}}},
{"model": "claude-opus-4-6", "label": "Claude High (Standard adaptiv)",
"extra": {}},
]
for cfg in configs:
start = time.time()
params = {
"model": cfg["model"],
"messages": [{"role": "user", "content": prompt}],
**cfg["extra"]
}
resp = client.chat.completions.create(**params)
elapsed = time.time() - start
print(f"\n[{cfg['label']}] {elapsed:.2f}s | {resp.usage.total_tokens} tokens")
print(f" → {resp.choices[0].message.content[:200]}...")
# Test komplexer Schlussfolgerungen
compare_with_thinking("Beweisen Sie: Für alle positiven Ganzzahlen n ist n^3 - n durch 6 teilbar.")
Häufig gestellte Fragen (FAQ)
F1: Gemini 3.1 Pro oder Claude Opus 4.6 – welches ist besser?
Es gibt kein absolutes „Besser“. Gemini 3.1 Pro führt beim abstrakten logischen Denken (ARC-AGI-2 +8,3pp), bei mehrstufigen Agenten (MCP Atlas +9,7pp), in der Multimodalität und bei den Kosten. Claude Opus 4.6 punktet dagegen beim realen Software-Engineering (SWE-Bench), bei Expertenwissen (GDPval-AA +289 Elo), bei der Computer-Bedienung (Computer Use) und beim Tool-Reasoning. Wir empfehlen, über APIYI (apiyi.com) A/B-Tests in Ihrem spezifischen Anwendungsszenario durchzuführen.
F2: Sind die API-Schnittstellen der beiden Modelle kompatibel? Kann man leicht wechseln?
Über die Plattform APIYI (apiyi.com) nutzen beide Modelle eine einheitliche, OpenAI-kompatible Schnittstelle. Ein Wechsel erfordert lediglich die Anpassung des model-Parameters (gemini-3.1-pro-preview → claude-opus-4-6), der restliche Code bleibt völlig unverändert.
F3: Welches Modell sollte ich bei begrenztem Budget wählen?
Wählen Sie vorzugsweise Gemini 3.1 Pro. Der Preis für den Input liegt bei etwa 40 % von Claude Opus 4.6 (2 $ vs. 5 $), und der Output kostet weniger als die Hälfte (12 $ vs. 25 $). Da Gemini in den meisten Benchmarks ebenbürtig oder sogar stärker abschneidet, bietet es ein extrem hohes Preis-Leistungs-Verhältnis. Nutzen Sie Claude nur in Szenarien wie SWE-Bench oder Expertenaufgaben, in denen Claude einen deutlichen Vorsprung hat.
F4: Kann man beide Modelle gleichzeitig für intelligentes Routing nutzen?
Ja, das ist möglich. Eine empfohlene Architektur sieht so aus: Nutzen Sie Gemini 3.1 Pro für 80 % der Standardanfragen (kostengünstig, starkes Reasoning) und Claude Opus 4.6 für die restlichen 20 % der Expertenaufgaben und Szenarien mit Tool-Erweiterungen. Dank der einheitlichen Schnittstelle von APIYI (apiyi.com) müssen Sie im Code lediglich den Aufgabentyp prüfen und den model-Parameter entsprechend anpassen, um ein intelligentes Routing zu realisieren.
Zusammenfassung: Entscheidungsmatrix Gemini 3.1 Pro vs. Claude Opus 4.6
| # | Vergleichsdimension | Gemini 3.1 Pro | Claude Opus 4.6 | Gewinner |
|---|---|---|---|---|
| 1 | Abstraktes Denken | ARC-AGI-2 77,1 % | 68,8 % | Gemini |
| 2 | Coding-Fähigkeiten | SWE-Bench 80,6 % | 80,8 % | Claude (knapp) |
| 3 | Agent-Workflows | MCP Atlas 69,2 % | 59,5 % | Gemini |
| 4 | Expertenaufgaben | GDPval 1317 | 1606 | Claude |
| 5 | Multimodalität | Voll-modal (Text/Bild/Audio/Video) | Text/Bild | Gemini |
| 6 | Preis | 2 $ / 12 $ pro MTok | 5 $ / 25 $ pro MTok | Gemini (2x günstiger) |
| 7 | Kontextfenster | 1M (Standard) | 200K (1M Beta) | Gemini |
| 8 | Max. Output | 64K Tokens | 128K Tokens | Claude |
| 9 | Denksystem | Level 3 + Deep Think Mini | Level 4 + Adaptiv | Unentschieden |
| 10 | Computer-Bedienung | Derzeit nicht unterstützt | OSWorld 72,7 % | Exklusiv bei Claude |
Abschließende Empfehlung:
- Preis-Leistung im Fokus → Gemini 3.1 Pro (doppelt so günstig, stärkeres Reasoning)
- Software-Engineering im Fokus → Claude Opus 4.6 (führend bei SWE-Bench, GDPval)
- Multimodalität im Fokus → Gemini 3.1 Pro (einzige Wahl für alle Modalitäten)
- Best Practice → Beide nutzen, intelligentes Routing implementieren
Es wird empfohlen, beide Modelle gleichzeitig über die Plattform APIYI (apiyi.com) anzubinden, um durch die einheitliche Schnittstelle eine flexible Steuerung und A/B-Tests zu ermöglichen.
Referenzen
-
Offizieller Google-Blog: Ankündigung von Gemini 3.1 Pro
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - Beschreibung: Offizielle Benchmark-Daten und Funktionsübersicht
- Link:
-
Offizielle Anthropic-Ankündigung: Details zum Release von Claude Opus 4.6
- Link:
anthropic.com/news/claude-opus-4-6 - Beschreibung: Technische Spezifikationen und Benchmark-Daten von Claude Opus 4.6
- Link:
-
Artificial Analysis: Vergleichstest durch Drittanbieter
- Link:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - Beschreibung: Unabhängiger Benchmark-Vergleich und Performance-Analyse
- Link:
-
Google DeepMind: Model Cards und Sicherheitsbewertungen
- Link:
deepmind.google/models/model-cards/gemini-3-1-pro - Beschreibung: Detaillierte technische Parameter und Sicherheitsdaten
- Link:
-
VentureBeat: Deep Think Mini – Ein ausführlicher Erfahrungsbericht
- Link:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - Beschreibung: Praxistest des dreistufigen Denksystems
- Link:
📝 Autor: APIYI Team | Für technischen Austausch besuchen Sie APIYI apiyi.com
📅 Aktualisierungsdatum: 20. Februar 2026
🏷️ Schlagworte: Gemini 3.1 Pro vs. Claude Opus 4.6, Modellvergleich, ARC-AGI-2, SWE-Bench, MCP Atlas, Multimodalität, API-Aufruf