Gemini 3.1 Pro Preview vs. Claude Opus 4.6: which one should you choose? This is the dilemma every AI developer faces in early 2026. We're diving into a comprehensive comparison across 10 core dimensions, using official benchmarks and third-party reviews to help you make a data-driven decision.
Core Value: By the end of this post, you'll know exactly which model fits your specific use case and how to quickly validate them in your real-world projects.

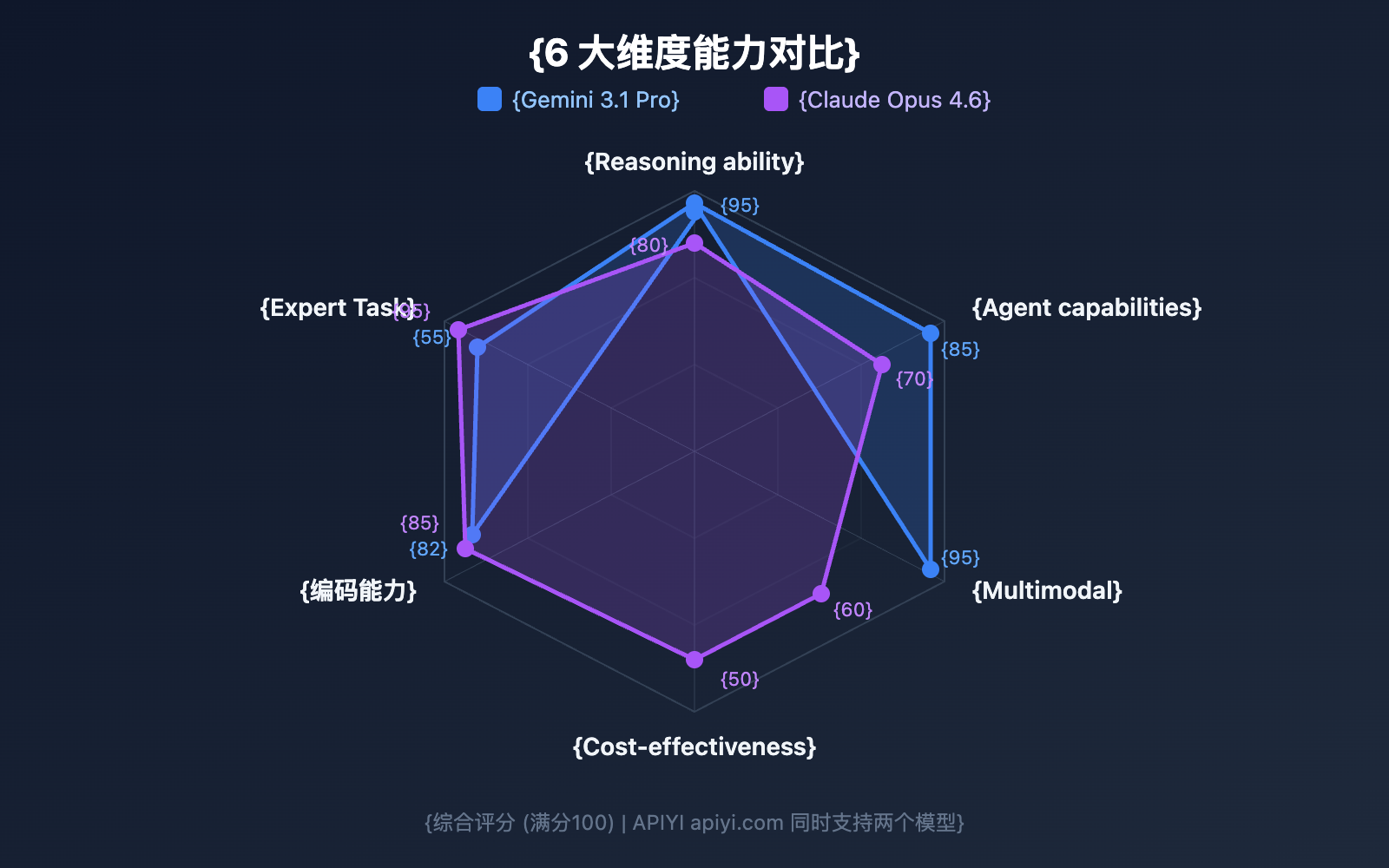
Gemini 3.1 Pro vs. Claude Opus 4.6 Benchmark Overview
Before we dive into the specifics, let's look at the big picture. Google claims Gemini 3.1 Pro leads in 13 out of 16 benchmarks, but Claude Opus 4.6 still takes the crown in several critical real-world scenarios.
| Benchmark | Gemini 3.1 Pro | Claude Opus 4.6 | Winner | Gap |
|---|---|---|---|---|
| ARC-AGI-2 (Abstract Reasoning) | 77.1% | 68.8% | Gemini | +8.3pp |
| GPQA Diamond (PhD Science) | 94.3% | 91.3% | Gemini | +3.0pp |
| SWE-Bench Verified (Software Engineering) | 80.6% | 80.8% | Claude | +0.2pp |
| Terminal-Bench 2.0 (Terminal Coding) | 68.5% | 65.4% | Gemini | +3.1pp |
| BrowseComp (Agent Search) | 85.9% | 84.0% | Gemini | +1.9pp |
| MCP Atlas (Multi-step Agent) | 69.2% | 59.5% | Gemini | +9.7pp |
| HLE No Tools (Ultimate Exam) | 44.4% | 40.0% | Gemini | +4.4pp |
| HLE With Tools (Ultimate Exam) | 51.4% | 53.1% | Claude | +1.7pp |
| SciCode (Scientific Coding) | 59% | 52% | Gemini | +7pp |
| MMMLU (Multilingual QA) | 92.6% | 91.1% | Gemini | +1.5pp |
| tau2-bench Retail (Tool Calling) | 90.8% | 91.9% | Claude | +1.1pp |
| GDPval-AA Elo (Expert Tasks) | 1317 | 1606 | Claude | +289 |
📊 Data Note: The data above is sourced from Google's official blog, Anthropic's official announcements, and third-party evaluations by Artificial Analysis. You can use APIYI (apiyi.com) to call both models simultaneously for real-world validation.
Comparison 1: Gemini 3.1 Pro vs. Claude Opus 4.6 Reasoning Capabilities
Reasoning is the core competitive edge of any Large Language Model. The reasoning architectures of these two models differ significantly.
Abstract Reasoning: Gemini 3.1 Pro Takes a Clear Lead
ARC-AGI-2 is currently the most authoritative benchmark for abstract reasoning. Gemini 3.1 Pro scored 77.1%, outperforming Claude Opus 4.6's 68.8% by 8.3 percentage points. This means Gemini is stronger in tasks that require inducing rules from just a few examples.
PhD-Level Scientific Reasoning: Gemini's Advantage is Striking
The GPQA Diamond test evaluates PhD-level scientific questions. Gemini 3.1 Pro scored 94.3%, while Claude Opus 4.6 scored 91.3%. A 3-percentage-point gap at this level of difficulty is very significant.
Tool-Augmented Reasoning: Claude Pulls Ahead
In the HLE (Humanity's Last Exam) benchmark, Gemini leads under no-tool conditions (44.4% vs. 40.0%), but Claude pulls ahead once tools are introduced (53.1% vs. 51.4%). This suggests that Claude Opus 4.6 is more adept at utilizing external tools to assist in reasoning.
| Reasoning Sub-dimension | Gemini 3.1 Pro | Claude Opus 4.6 | Best For |
|---|---|---|---|
| Abstract Reasoning | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Pattern recognition, rule induction |
| Scientific Reasoning | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Academic research, paper assistance |
| Tool Reasoning | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Complex workflows, multi-tool coordination |
| Mathematical Reasoning | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Deep Think Mini specialty |
Comparison 2: Gemini 3.1 Pro vs. Claude Opus 4.6 Coding Capabilities
Coding capability is the dimension developers care about most. While both models perform very closely, they each have their own strengths.
SWE-Bench: Almost a Dead Heat
SWE-Bench Verified is a benchmark for fixing real-world GitHub issues:
- Claude Opus 4.6: 80.8% (slight lead)
- Gemini 3.1 Pro: 80.6%
With only a 0.2 percentage point difference, the two can be considered essentially equal in real-world software engineering tasks.
Terminal-Bench: Gemini Holds the Edge
Terminal-Bench 2.0 tests the coding capabilities of agents in a terminal environment:
- Gemini 3.1 Pro: 68.5%
- Claude Opus 4.6: 65.4%
The 3.1 percentage point gap indicates that Gemini has stronger execution capabilities in terminal agent scenarios.
Competitive Programming: Gemini Leads
LiveCodeBench Pro data shows Gemini 3.1 Pro reaching 2887 Elo, performing exceptionally well in competitive programming. While corresponding data for Claude Opus 4.6 hasn't been fully released, Claude also maintains a top-tier level based on performances in competitions like USACO.
# 通过 APIYI 同时测试两个模型的编码能力
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 统一接口
)
# 同一编码任务分别测试
coding_prompt = "实现一个 LRU Cache,支持 get 和 put 操作,时间复杂度 O(1)"
for model in ["gemini-3.1-pro-preview", "claude-opus-4-6"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": coding_prompt}]
)
print(f"\n{'='*50}")
print(f"模型: {model}")
print(f"Token 用量: {resp.usage.total_tokens}")
print(f"回答:\n{resp.choices[0].message.content[:500]}")
Comparison 3: Gemini 3.1 Pro vs. Claude Opus 4.6 Agent Capabilities
Agents and autonomous workflows are the core scenarios for 2026. This is one of the areas where the two models differ the most.
Agent Search: A Close Race
BrowseComp tests a model's autonomous web search and information extraction capabilities:
- Gemini 3.1 Pro: 85.9%
- Claude Opus 4.6: 84.0%
With a gap of only 1.9 percentage points, both are performing at a top-tier level.
Multi-step Agents: Gemini Takes a Big Lead
MCP Atlas tests complex multi-step workflows. Gemini 3.1 Pro scored 69.2%, nearly 10 percentage points higher than Claude Opus 4.6's 59.5%. This is one of the benchmarks with the most significant difference between the two models.
Computer Use: Claude's Exclusive Advantage
The OSWorld benchmark tests a model's ability to operate a real GUI. Claude Opus 4.6 scored 72.7%. Gemini hasn't released a score for this yet. This means if you need an AI to automatically operate desktop applications, Claude is currently your only choice.
Expert-level Tasks: Claude Clearly Ahead
GDPval-AA tests expert-level tasks in real office environments (data analysis, report writing, etc.). Claude Opus 4.6 achieved an Elo rating of 1606, far surpassing Gemini's 1317. This shows that for knowledge work requiring deep understanding and precise execution, Claude is more reliable.
| Agent Dimension | Gemini 3.1 Pro | Claude Opus 4.6 | Gap |
|---|---|---|---|
| BrowseComp (Search) | 85.9% | 84.0% | +1.9pp |
| MCP Atlas (Multi-step) | 69.2% | 59.5% | +9.7pp |
| APEX-Agents (Long-cycle) | 33.5% | 29.8% | +3.7pp |
| OSWorld (Computer Use) | — | 72.7% | Claude Exclusive |
| GDPval-AA (Expert Tasks) | 1317 Elo | 1606 Elo | +289 |
Comparison 4: Gemini 3.1 Pro vs. Claude Opus 4.6 Thinking System Architecture
Both models feature "Deep Thinking" mechanisms, but their design philosophies are quite different.
Gemini 3.1 Pro: Three-Level Thinking System
| Level | Name | Features | Use Case |
|---|---|---|---|
| Low | Fast Response | Near-zero latency | Simple Q&A, translation |
| Medium | Balanced Reasoning | Moderate latency (New) | Daily coding, analysis |
| High | Deep Think Mini | Deep reasoning, solves IMO problems in 8 mins | Math, complex debugging |
Gemini 3.1 Pro's High mode is actually a mini version of Deep Think (Google's dedicated reasoning model), essentially embedding a dedicated reasoning engine within the model.
Claude Opus 4.6: Adaptive Thinking System
| Level | Name | Features | Use Case |
|---|---|---|---|
| Low | Fast Mode | Minimal reasoning overhead | Simple tasks |
| Medium | Balanced Mode | Moderate reasoning | Routine development |
| High | Deep Mode (Default) | Automatically determines reasoning depth | Most tasks |
| Max | Maximum Reasoning | Full-throttle reasoning | Extremely difficult problems |
Claude's standout feature is Adaptive Thinking—the model automatically decides how many reasoning resources to allocate based on the problem's complexity, so developers don't have to choose manually. The default High mode is already incredibly smart.
🎯 Practical Comparison: Gemini gives you finer manual control (3 levels), perfect for scenarios where you need to strictly manage costs and latency; Claude offers smarter automatic adaptation (4 levels + adaptive), ideal for "set it and forget it" production environments. Both models can be directly called and compared on APIYI (apiyi.com).
Comparison 5: Gemini 3.1 Pro vs. Claude Opus 4.6 Pricing and Cost
Cost is a critical factor in production environments. There's a significant price gap between these two models.
| Pricing Dimension | Gemini 3.1 Pro | Claude Opus 4.6 | Gemini Value |
|---|---|---|---|
| Input (Standard) | $2.00 / 1M tokens | $5.00 / 1M tokens | 2.5x cheaper |
| Output (Standard) | $12.00 / 1M tokens | $25.00 / 1M tokens | 2.1x cheaper |
| Input (Long Context >200K) | $4.00 / 1M tokens | $10.00 / 1M tokens | 2.5x cheaper |
| Output (Long Context >200K) | $18.00 / 1M tokens | $37.50 / 1M tokens | 2.1x cheaper |
Real-world Cost Estimation
Based on a daily volume of 1 million input tokens + 200,000 output tokens:
| Scenario | Gemini 3.1 Pro | Claude Opus 4.6 | Monthly Savings |
|---|---|---|---|
| Daily Calls | $4.40/day | $10.00/day | $168/month |
| Heavy Usage (3x) | $13.20/day | $30.00/day | $504/month |
Gemini 3.1 Pro is roughly half the price of Claude Opus 4.6 across all pricing dimensions. For cost-sensitive projects, this is a massive advantage.
💰 Cost Optimization Tip: You can access both models through the APIYI (apiyi.com) platform to enjoy flexible billing and unified management. We recommend running small-batch tests to confirm performance before committing to your primary model.
Comparison 6: Gemini 3.1 Pro vs. Claude Opus 4.6 Context Window and Output
| Specification | Gemini 3.1 Pro | Claude Opus 4.6 | Advantage |
|---|---|---|---|
| Context Window | 1,000,000 tokens | 200,000 tokens (1M beta) | Gemini |
| Max Output | 64,000 tokens | 128,000 tokens | Claude |
| Upload File Size | 100MB | — | Gemini |
Context Window: Gemini Leads by 5x
Gemini 3.1 Pro supports a 1-million-token context window by default, while Claude Opus 4.6 standard is 200k (with 1M currently in beta). For scenarios that require analyzing massive codebases, long documents, or video files, Gemini's advantage is clear.
Max Output: Claude Leads with Double the Capacity
Claude Opus 4.6 supports up to 128K token output, which is twice that of Gemini. This is crucial for long-form content generation, detailed code generation, and deep reasoning chains—more output space means the model has more room to "think" things through thoroughly.
Comparison 7: Gemini 3.1 Pro vs. Claude Opus 4.6 Multimodal Capabilities
Multimodal performance has always been a traditional forte for Gemini.
| Modality | Gemini 3.1 Pro | Claude Opus 4.6 |
|---|---|---|
| Text Input | ✅ | ✅ |
| Image Input | ✅ (Native) | ✅ |
| Video Input | ✅ (Native) | ❌ |
| Audio Input | ✅ (Native) | ❌ |
| PDF Processing | ✅ | ✅ |
| YouTube URL | ✅ | ❌ |
| SVG Generation | ✅ (Native) | ✅ |
Gemini 3.1 Pro is a true omni-modal model. Its training architecture natively supports a unified understanding of text, images, audio, and video from the ground up. In contrast, Claude Opus 4.6's multimodal capabilities are currently limited to text and images.
If your application involves video analysis, audio transcription, or complex multimedia content understanding, Gemini 3.1 Pro is currently the only viable choice.
Comparison 8: Gemini 3.1 Pro vs. Claude Opus 4.6 Unique Features
Exclusive to Gemini 3.1 Pro
| Feature | Description | Value |
|---|---|---|
| Deep Think Mini | Dedicated reasoning engine embedded in High mode | Math/Competition-level reasoning |
| Grounding | 5,000 free Google searches per month | Real-time information enhancement |
| 100MB File Uploads | Upload large files in a single go | Large codebase/data analysis |
| YouTube URL Analysis | Directly input video URLs for understanding | Video content analysis |
| Native Audio/Video Understanding | End-to-end multimodal processing | Multimedia AI applications |
Exclusive to Claude Opus 4.6
| Feature | Description | Value |
|---|---|---|
| Computer Use (OSWorld 72.7%) | Automatically operates GUI interfaces | RPA/Automated testing |
| Adaptive Thinking | Automatically determines reasoning depth | Zero-config intelligent reasoning |
| 128K Output | Support for ultra-long outputs | Long-form generation/Deep reasoning |
| Batch API (50% Discount) | Asynchronous batch processing | Large-scale data processing |
| Fast Mode | 6x rate for faster output delivery | Low-latency production scenarios |
Gemini 3.1 Pro vs Claude Opus 4.6: Scenario Selection Guide
Based on the 8-dimensional comparison above, here are clear recommendations for different scenarios:
When to Choose Gemini 3.1 Pro
| Scenario | Key Advantage | Why it's recommended |
|---|---|---|
| Abstract Reasoning/Math | ARC-AGI-2 +8.3pp | Deep Think Mini is incredibly strong |
| Multi-step Agents | MCP Atlas +9.7pp | Strongest workflow execution |
| Video/Audio Analysis | Native Multimodality | The only full-modality choice |
| Cost-Sensitive Projects | 2-2.5x Cheaper | Lower cost for equivalent quality |
| Large Document Analysis | 1M Context | Standard support for massive context |
| Scientific Research | GPQA +3.0pp | Strongest scientific reasoning capabilities |
When to Choose Claude Opus 4.6
| Scenario | Key Advantage | Why it's recommended |
|---|---|---|
| Real-world Software Engineering | SWE-Bench 80.8% | Most accurate at fixing real-world bugs |
| Expert-level Knowledge Work | GDPval-AA +289 Elo | Best for reports, analysis, and decision-making |
| Computer Automation | OSWorld 72.7% | Only model supporting GUI operations |
| Tool-Augmented Reasoning | HLE+tools +1.7pp | Optimal multi-tool coordination |
| Ultra-long Output Needs | 128K Output | Ideal for long-form content/deep reasoning chains |
| Low-latency Production | Fast Mode | Pay for speed when it matters |
Use Both: Smart Routing Architecture
In many production environments, the optimal solution is to use both models simultaneously, routing tasks intelligently based on their type:
| Task Type | Route To | Reason | Estimated Share |
|---|---|---|---|
| General Q&A / Translation | Gemini 3.1 Pro | Low cost, sufficient quality | 40% |
| Code Generation / Debugging | Claude Opus 4.6 | Slightly better SWE-Bench performance | 20% |
| Reasoning / Math / Science | Gemini 3.1 Pro | Significant lead in ARC-AGI-2 | 15% |
| Agent Workflows | Gemini 3.1 Pro | MCP Atlas +9.7pp | 10% |
| Expert Analysis / Reports | Claude Opus 4.6 | Clear lead in GDPval-AA | 10% |
| Video / Audio Processing | Gemini 3.1 Pro | The only full-modality choice | 5% |
By routing according to these proportions, you can save about 55% in overall costs compared to using Claude exclusively, while still getting the best quality for each specific scenario.
Gemini 3.1 Pro vs Claude Opus 4.6 Cost Optimization Strategies
Strategy 1: Tiered Processing
Use Gemini Low mode (fastest and cheapest) for simple tasks, Gemini Medium for medium tasks, and only use Claude High or Gemini High (Deep Think Mini) for truly complex tasks.
Strategy 2: Separate Batch and Real-time
Use Gemini 3.1 Pro for real-time requests (low latency, low cost). For offline batch processing, you can use Claude's Batch API (50% discount), making the combined costs comparable.
Strategy 3: Context Caching
Gemini offers context caching (Input $0.20-$0.40/MTok). For scenarios where the same long document is reused, caching can reduce costs by over 80%.
🚀 Quick Validation: Through the APIYI (apiyi.com) platform, you can call both Gemini 3.1 Pro and Claude Opus 4.6 using the same API Key. We recommend running an A/B test with your actual business prompts; you'll have your answer in about 10 minutes.
Gemini 3.1 Pro vs Claude Opus 4.6 Quick Start
The following code demonstrates how to use the APIYI unified interface to call both models simultaneously for comparison testing:
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI unified interface
)
def compare_models(prompt, models=None):
"""Compare the output quality and speed of two models"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-opus-4-6"]
results = {}
for model in models:
start = time.time()
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
elapsed = time.time() - start
results[model] = {
"time": f"{elapsed:.2f}s",
"tokens": resp.usage.total_tokens,
"answer": resp.choices[0].message.content[:300]
}
for model, data in results.items():
print(f"\n{'='*50}")
print(f"Model: {model}")
print(f"Time: {data['time']} | Tokens: {data['tokens']}")
print(f"Answer: {data['answer']}...")
# Test reasoning capabilities
compare_models("Please use chain-of-thought reasoning to explain why 0.1 + 0.2 does not equal 0.3")
View full code with thinking level control
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def compare_with_thinking(prompt, thinking_config=None):
"""Compare model performance under different thinking levels"""
configs = [
{"model": "gemini-3.1-pro-preview", "label": "Gemini Medium",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 8000}}},
{"model": "gemini-3.1-pro-preview", "label": "Gemini High (Deep Think Mini)",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 32000}}},
{"model": "claude-opus-4-6", "label": "Claude High (Default Adaptive)",
"extra": {}},
]
for cfg in configs:
start = time.time()
params = {
"model": cfg["model"],
"messages": [{"role": "user", "content": prompt}],
**cfg["extra"]
}
resp = client.chat.completions.create(**params)
elapsed = time.time() - start
print(f"\n[{cfg['label']}] {elapsed:.2f}s | {resp.usage.total_tokens} tokens")
print(f" → {resp.choices[0].message.content[:200]}...")
# Test complex reasoning
compare_with_thinking("Prove: For all positive integers n, n^3 - n is divisible by 6")
FAQ
Q1: Which is better, Gemini 3.1 Pro or Claude Opus 4.6?
There's no single "better" choice here. Gemini 3.1 Pro leads in abstract reasoning (ARC-AGI-2 +8.3pp), multi-step Agents (MCP Atlas +9.7pp), multimodality, and cost-efficiency. Claude Opus 4.6 excels in real-world software engineering (SWE-Bench), expert knowledge work (GDPval-AA +289 Elo), computer use, and tool reasoning. We recommend running A/B tests in your specific use cases via APIYI (apiyi.com).
Q2: Are the API interfaces for these two models compatible? Is it easy to switch?
Yes. Through the APIYI (apiyi.com) platform, both models use a unified OpenAI-compatible interface. Switching is as simple as changing the model parameter (e.g., gemini-3.1-pro-preview → claude-opus-4-6); you won't need to change any other part of your code.
Q3: Which one should I choose if I’m on a tight budget?
Go with Gemini 3.1 Pro. Its input price is only 40% of Claude Opus 4.6 ($2 vs $5), and its output price is less than half ($12 vs $25). Since Gemini matches or even beats Claude on most benchmarks, it offers incredible value for the money. Save Claude for specific scenarios where it clearly dominates, like SWE-Bench or highly specialized expert tasks.
Q4: Can I use both models simultaneously for intelligent routing?
Absolutely. A recommended architecture is to use Gemini 3.1 Pro for 80% of routine requests (low cost, strong reasoning) and Claude Opus 4.6 for the remaining 20% of expert-level tasks and tool-augmented scenarios. With APIYI's unified interface, you can implement intelligent routing just by identifying the task type in your code and switching the model parameter accordingly.
Summary: Gemini 3.1 Pro vs. Claude Opus 4.6 Decision Matrix
| # | Dimension | Gemini 3.1 Pro | Claude Opus 4.6 | Winner |
|---|---|---|---|---|
| 1 | Abstract Reasoning | ARC-AGI-2 77.1% | 68.8% | Gemini |
| 2 | Coding Ability | SWE-Bench 80.6% | 80.8% | Claude (Slight edge) |
| 3 | Agent Workflow | MCP Atlas 69.2% | 59.5% | Gemini |
| 4 | Expert Tasks | GDPval 1317 | 1606 | Claude |
| 5 | Multimodality | Full (Text/Img/Audio/Video) | Text/Img | Gemini |
| 6 | Price | $2/$12 per MTok | $5/$25 per MTok | Gemini (2x cheaper) |
| 7 | Context Window | 1M (Standard) | 200K (1M beta) | Gemini |
| 8 | Max Output | 64K tokens | 128K tokens | Claude |
| 9 | Thinking System | Level 3 + Deep Think Mini | Level 4 + Adaptive | Tie (Different strengths) |
| 10 | Computer Use | Not yet supported | OSWorld 72.7% | Claude Exclusive |
Final Recommendations:
- Priority: Value for Money → Gemini 3.1 Pro (2x cheaper, stronger reasoning)
- Priority: Software Engineering → Claude Opus 4.6 (Leads in SWE-Bench and GDPval)
- Priority: Multimodality → Gemini 3.1 Pro (The only choice for full multimodal support)
- Best Practice → Use both with intelligent routing.
We recommend connecting to both models via the APIYI (apiyi.com) platform to enjoy flexible scheduling and easy A/B testing through a single unified interface.
References
-
Google Official Blog: Gemini 3.1 Pro Launch Announcement
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - Description: Official benchmark data and feature overview.
- Link:
-
Anthropic Official Announcement: Claude Opus 4.6 Release Details
- Link:
anthropic.com/news/claude-opus-4-6 - Description: Claude Opus 4.6 technical specifications and benchmark data.
- Link:
-
Artificial Analysis: Third-party Comparative Evaluation
- Link:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - Description: Independent benchmark comparisons and performance analysis.
- Link:
-
Google DeepMind: Model Card and Safety Assessment
- Link:
deepmind.google/models/model-cards/gemini-3-1-pro - Description: Detailed technical parameters and safety data.
- Link:
-
VentureBeat: Deep Think Mini In-depth Experience
- Link:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - Description: Real-world testing of the three-level reasoning system.
- Link:
📝 Author: APIYI Team | For technical discussions, visit APIYI at apiyi.com
📅 Updated: February 20, 2026
🏷️ Keywords: Gemini 3.1 Pro vs Claude Opus 4.6, Model Comparison, ARC-AGI-2, SWE-Bench, MCP Atlas, Multimodal, API Calls