Gemini 3.1 Pro Preview vs Claude Opus 4.6 該選誰? 這是 2026 年初 AI 開發者繞不開的抉擇。本文從 10 個核心維度 進行全面對比,引用官方基準數據和第三方評測,幫你用數據做出明確選擇。
核心價值: 看完本文,你將清楚知道在不同場景下應該選擇哪個模型,以及如何在實際項目中快速驗證。

Gemini 3.1 Pro vs Claude Opus 4.6 基準數據總覽
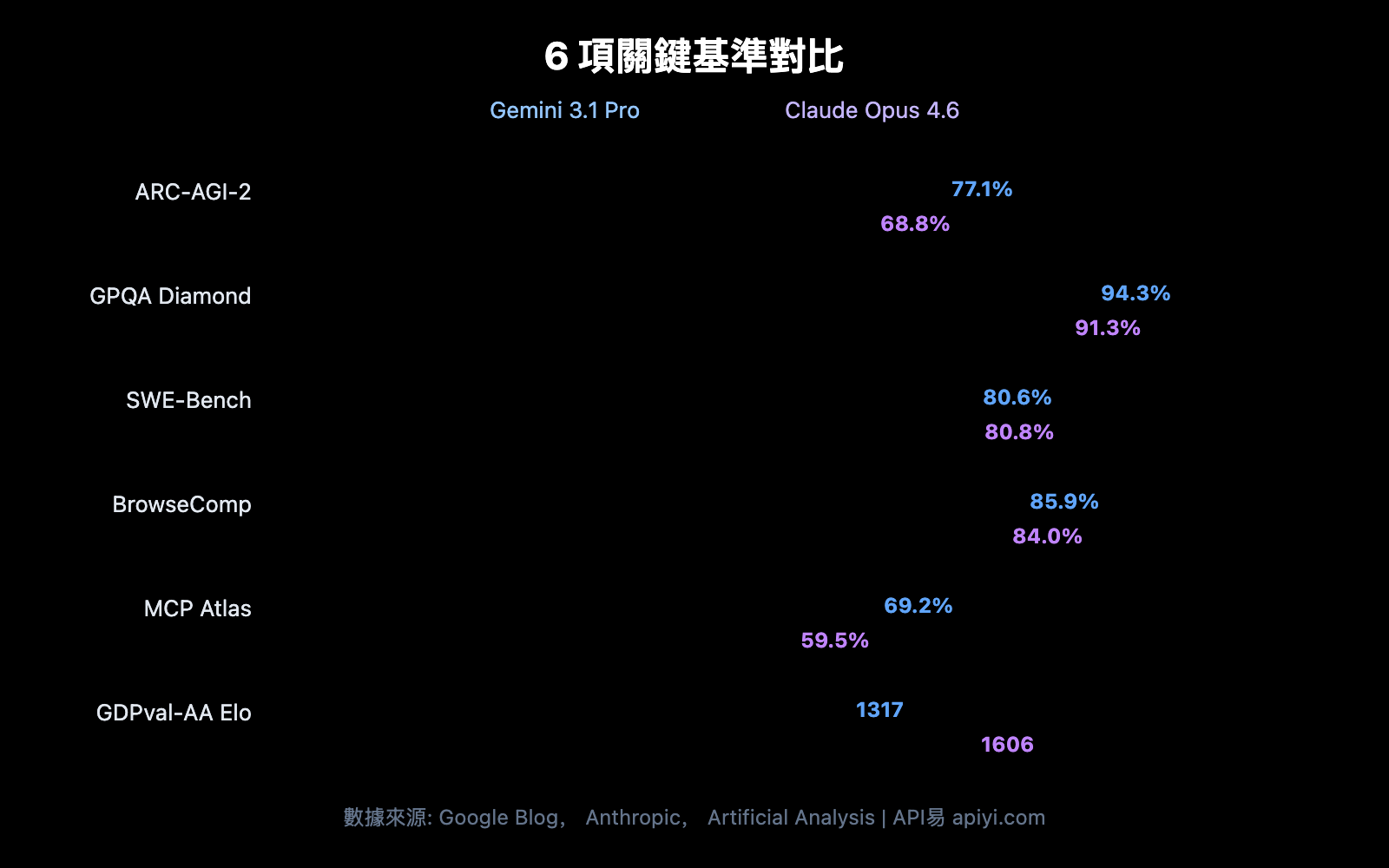
在深入各維度之前,先看全局基準對比。谷歌官方宣稱 Gemini 3.1 Pro 在 16 項基準中的 13 項領先,但 Claude Opus 4.6 在多個實戰場景中勝出。
| 基準測試 | Gemini 3.1 Pro | Claude Opus 4.6 | 勝出 | 差距 |
|---|---|---|---|---|
| ARC-AGI-2 (抽象推理) | 77.1% | 68.8% | Gemini | +8.3pp |
| GPQA Diamond (PhD科學) | 94.3% | 91.3% | Gemini | +3.0pp |
| SWE-Bench Verified (軟件工程) | 80.6% | 80.8% | Claude | +0.2pp |
| Terminal-Bench 2.0 (終端編碼) | 68.5% | 65.4% | Gemini | +3.1pp |
| BrowseComp (Agent 搜索) | 85.9% | 84.0% | Gemini | +1.9pp |
| MCP Atlas (多步驟 Agent) | 69.2% | 59.5% | Gemini | +9.7pp |
| HLE 無工具 (終極考試) | 44.4% | 40.0% | Gemini | +4.4pp |
| HLE 有工具 (終極考試) | 51.4% | 53.1% | Claude | +1.7pp |
| SciCode (科研編碼) | 59% | 52% | Gemini | +7pp |
| MMMLU (多語言QA) | 92.6% | 91.1% | Gemini | +1.5pp |
| tau2-bench Retail (工具調用) | 90.8% | 91.9% | Claude | +1.1pp |
| GDPval-AA Elo (專家任務) | 1317 | 1606 | Claude | +289 |
📊 數據說明: 以上數據來源於谷歌官方博客、Anthropic 官方公告及 Artificial Analysis 第三方評測。通過 API易 apiyi.com 可以同時調用兩個模型進行實際場景驗證。
對比 1: Gemini 3.1 Pro vs Claude Opus 4.6 推理能力
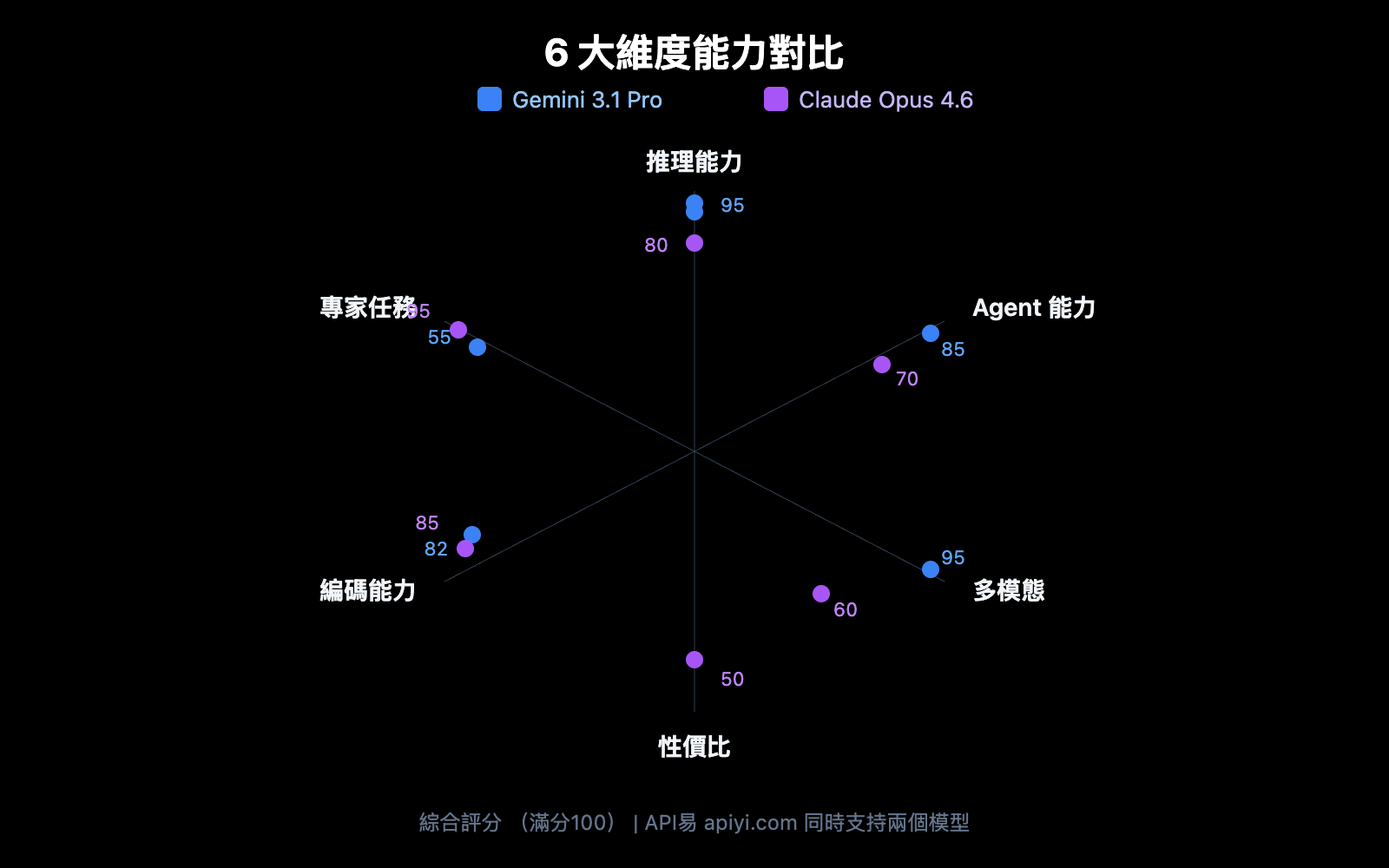
推理能力是大模型的核心競爭力。兩個模型的推理架構差異顯著。
抽象推理: Gemini 3.1 Pro 領先明顯
ARC-AGI-2 是目前最權威的抽象推理基準,Gemini 3.1 Pro 得分 77.1%,比 Claude Opus 4.6 的 68.8% 高出 8.3 個百分點。這意味着在需要從少量示例中歸納規則的任務中,Gemini 更強。
PhD 級科學推理: Gemini 優勢突出
GPQA Diamond 測試 PhD 級別的科學問題,Gemini 3.1 Pro 得分 94.3%,Claude Opus 4.6 得分 91.3%。3 個百分點的差距在這個難度級別上非常顯著。
工具增強推理: Claude 反超
HLE (Humanity's Last Exam) 在無工具條件下 Gemini 領先 (44.4% vs 40.0%),但引入工具後 Claude 反超 (53.1% vs 51.4%)。這表明 Claude Opus 4.6 在利用外部工具輔助推理方面更出色。
| 推理子維度 | Gemini 3.1 Pro | Claude Opus 4.6 | 適合誰 |
|---|---|---|---|
| 抽象推理 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 模式識別、規則歸納 |
| 科學推理 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 學術研究、論文輔助 |
| 工具推理 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 複雜工作流、多工具協同 |
| 數學推理 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Deep Think Mini 專長 |
對比 2: Gemini 3.1 Pro vs Claude Opus 4.6 編碼能力
編碼能力是開發者最關心的維度。兩個模型的表現非常接近,但各有側重。
SWE-Bench: 幾乎持平
SWE-Bench Verified 是真實 GitHub 問題修復基準:
- Claude Opus 4.6: 80.8% (微弱領先)
- Gemini 3.1 Pro: 80.6%
僅 0.2 個百分點的差距,基本可以認爲兩者在真實軟件工程任務上能力相當。
Terminal-Bench: Gemini 佔優
Terminal-Bench 2.0 測試終端環境下的 Agent 編碼能力:
- Gemini 3.1 Pro: 68.5%
- Claude Opus 4.6: 65.4%
3.1 個百分點的差距說明 Gemini 在終端 Agent 場景下執行力更強。
競賽編程: Gemini 領先
LiveCodeBench Pro 數據顯示 Gemini 3.1 Pro 達到 2887 Elo,在競賽編程上表現出色。Claude Opus 4.6 的對應數據暫未公開,但從 USACO 等競賽表現來看,Claude 也是頂級水平。
# 通過 API易 同時測試兩個模型的編碼能力
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易 統一接口
)
# 同一編碼任務分別測試
coding_prompt = "實現一個 LRU Cache,支持 get 和 put 操作,時間複雜度 O(1)"
for model in ["gemini-3.1-pro-preview", "claude-opus-4-6"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": coding_prompt}]
)
print(f"\n{'='*50}")
print(f"模型: {model}")
print(f"Token 用量: {resp.usage.total_tokens}")
print(f"回答:\n{resp.choices[0].message.content[:500]}")
對比 3: Gemini 3.1 Pro vs Claude Opus 4.6 Agent 能力
Agent 和自主工作流是 2026 年的核心場景。這是兩個模型差異最大的領域之一。
Agent 搜索: 兩強接近
BrowseComp 測試模型的自主網頁搜索和信息提取能力:
- Gemini 3.1 Pro: 85.9%
- Claude Opus 4.6: 84.0%
差距僅 1.9 個百分點,兩者都是頂級水平。
多步驟 Agent: Gemini 大幅領先
MCP Atlas 測試複雜多步驟工作流,Gemini 3.1 Pro 得分 69.2%,比 Claude Opus 4.6 的 59.5% 高出近 10 個百分點。這是兩個模型差異最大的基準之一。
計算機操作: Claude 獨佔優勢
OSWorld 基準測試模型操作真實 GUI 的能力,Claude Opus 4.6 得分 72.7%。Gemini 暫未公佈該項成績。這意味着如果你需要 AI 自動操作桌面應用,Claude 是當前唯一選擇。
專家級任務: Claude 明顯領先
GDPval-AA 測試真實辦公環境中的專家級任務 (數據分析、報告撰寫等),Claude Opus 4.6 的 Elo 評分 1606,遠超 Gemini 的 1317。這說明在需要深度理解和精細執行的知識工作中,Claude 更可靠。
| Agent 子維度 | Gemini 3.1 Pro | Claude Opus 4.6 | 差距 |
|---|---|---|---|
| BrowseComp (搜索) | 85.9% | 84.0% | +1.9pp |
| MCP Atlas (多步驟) | 69.2% | 59.5% | +9.7pp |
| APEX-Agents (長週期) | 33.5% | 29.8% | +3.7pp |
| OSWorld (計算機操作) | — | 72.7% | Claude 獨佔 |
| GDPval-AA (專家任務) | 1317 Elo | 1606 Elo | +289 |
對比 4: Gemini 3.1 Pro vs Claude Opus 4.6 思考系統架構
兩個模型都有「深度思考」機制,但設計理念不同。
Gemini 3.1 Pro: 三級思考系統
| 級別 | 名稱 | 特點 | 適用場景 |
|---|---|---|---|
| Low | 快速響應 | 幾乎無延遲 | 簡單問答、翻譯 |
| Medium | 平衡推理 | 中等延遲 (新增) | 日常編碼、分析 |
| High | Deep Think Mini | 深度推理,8 分鐘解 IMO 題 | 數學、複雜調試 |
Gemini 3.1 Pro 的 High 模式實際上是 Deep Think (谷歌專用推理模型) 的迷你版,相當於在一個模型內嵌入了專用推理引擎。
Claude Opus 4.6: 自適應思考系統
| 級別 | 名稱 | 特點 | 適用場景 |
|---|---|---|---|
| Low | 快速模式 | 最小推理開銷 | 簡單任務 |
| Medium | 平衡模式 | 適度推理 | 常規開發 |
| High | 深度模式 (默認) | 自動判斷推理深度 | 大多數任務 |
| Max | 最大推理 | 全力推理 | 極難問題 |
Claude 的特色是自適應思考 — 模型會根據問題複雜度自動決定投入多少推理資源,開發者無需手動選擇。默認 High 模式已經非常智能。
🎯 實用對比: Gemini 給你更精細的手動控制 (3 級),適合需要精確控制成本和延遲的場景; Claude 給你更智能的自動適配 (4 級 + 自適應),適合「設好就不管」的生產環境。兩個模型都可以在 API易 apiyi.com 上直接調用和對比。
對比 5: Gemini 3.1 Pro vs Claude Opus 4.6 定價和成本
成本是生產環境中的關鍵考量。兩個模型的價格差異顯著。
| 價格維度 | Gemini 3.1 Pro | Claude Opus 4.6 | Gemini 性價比 |
|---|---|---|---|
| 輸入 (標準) | $2.00 / 1M tokens | $5.00 / 1M tokens | 2.5x 更便宜 |
| 輸出 (標準) | $12.00 / 1M tokens | $25.00 / 1M tokens | 2.1x 更便宜 |
| 輸入 (長上下文 >200K) | $4.00 / 1M tokens | $10.00 / 1M tokens | 2.5x 更便宜 |
| 輸出 (長上下文 >200K) | $18.00 / 1M tokens | $37.50 / 1M tokens | 2.1x 更便宜 |
實際場景成本估算
以每天處理 100 萬輸入 token + 20 萬輸出 token 計算:
| 場景 | Gemini 3.1 Pro | Claude Opus 4.6 | 月節省 |
|---|---|---|---|
| 日常調用 | $4.40/天 | $10.00/天 | $168/月 |
| 重度使用 (3x) | $13.20/天 | $30.00/天 | $504/月 |
Gemini 3.1 Pro 在所有價格維度上都是 Claude Opus 4.6 的一半左右。對於成本敏感的項目,這是一個非常顯著的優勢。
💰 成本優化建議: 通過 API易 apiyi.com 平臺調用這兩個模型,可以享受靈活計費和統一管理。建議先用小批量測試確認效果,再決定主力模型。
對比 6: Gemini 3.1 Pro vs Claude Opus 4.6 上下文窗口和輸出
| 規格 | Gemini 3.1 Pro | Claude Opus 4.6 | 優勢方 |
|---|---|---|---|
| 上下文窗口 | 1,000,000 tokens | 200,000 tokens (1M beta) | Gemini |
| 最大輸出 | 64,000 tokens | 128,000 tokens | Claude |
| 上傳文件大小 | 100MB | — | Gemini |
上下文窗口: Gemini 5 倍領先
Gemini 3.1 Pro 標準支持 100 萬 token 上下文,Claude Opus 4.6 標準是 20 萬 (1M 在 beta 中)。對於需要分析大型代碼倉庫、長文檔或視頻的場景,Gemini 的優勢非常明顯。
最大輸出: Claude 翻倍領先
Claude Opus 4.6 支持 128K token 輸出,是 Gemini 的 2 倍。這對於長文生成、詳細代碼生成和深度推理鏈條至關重要——更長的輸出空間意味着模型可以進行更充分的「思考」。
對比 7: Gemini 3.1 Pro vs Claude Opus 4.6 多模態能力
多模態能力是 Gemini 的傳統強項。
| 模態 | Gemini 3.1 Pro | Claude Opus 4.6 |
|---|---|---|
| 文本輸入 | ✅ | ✅ |
| 圖像輸入 | ✅ (原生) | ✅ |
| 視頻輸入 | ✅ (原生) | ❌ |
| 音頻輸入 | ✅ (原生) | ❌ |
| PDF 處理 | ✅ | ✅ |
| YouTube URL | ✅ | ❌ |
| SVG 生成 | ✅ (原生) | ✅ |
Gemini 3.1 Pro 是真正的全模態模型,從訓練架構上就原生支持文本、圖像、音頻、視頻的統一理解。Claude Opus 4.6 的多模態限於文本和圖像。
如果你的應用涉及視頻分析、音頻轉寫或多媒體內容理解,Gemini 3.1 Pro 是目前唯一支持的選擇。
對比 8: Gemini 3.1 Pro vs Claude Opus 4.6 獨有特性
Gemini 3.1 Pro 獨有
| 特性 | 說明 | 價值 |
|---|---|---|
| Deep Think Mini | High 模式內嵌專用推理引擎 | 數學/競賽級推理 |
| 搜索落地 (Grounding) | 每月 5000 次免費搜索 | 實時信息增強 |
| 100MB 文件上傳 | 單次上傳大型文件 | 大型代碼庫/數據分析 |
| YouTube URL 分析 | 直接輸入視頻 URL 進行理解 | 視頻內容分析 |
| 音視頻原生理解 | 端到端多模態處理 | 多媒體 AI 應用 |
Claude Opus 4.6 獨有
| 特性 | 說明 | 價值 |
|---|---|---|
| 計算機操作 (OSWorld 72.7%) | 自動操作 GUI 界面 | RPA/自動化測試 |
| 自適應思考 | 自動判斷推理深度 | 零配置智能推理 |
| 128K 輸出 | 超長輸出支持 | 長文生成/深度推理 |
| 批量 API (50% 折扣) | 異步批量處理 | 大規模數據處理 |
| 快速模式 | 6x 費率換取更快輸出 | 低延遲生產場景 |
Gemini 3.1 Pro vs Claude Opus 4.6 場景選擇指南
根據以上 8 個維度的對比,以下是明確的場景推薦:
選擇 Gemini 3.1 Pro 的場景
| 場景 | 關鍵優勢 | 推薦理由 |
|---|---|---|
| 抽象推理/數學 | ARC-AGI-2 +8.3pp | Deep Think Mini 極強 |
| 多步驟 Agent | MCP Atlas +9.7pp | 工作流執行力最強 |
| 視頻/音頻分析 | 原生多模態 | 唯一全模態選擇 |
| 成本敏感項目 | 價格便宜 2-2.5x | 同等質量更低成本 |
| 大型文檔分析 | 1M 上下文 | 超大上下文標準支持 |
| 科學研究 | GPQA +3.0pp | 科學推理能力最強 |
選擇 Claude Opus 4.6 的場景
| 場景 | 關鍵優勢 | 推薦理由 |
|---|---|---|
| 真實軟件工程 | SWE-Bench 80.8% | 修復實際 Bug 最準 |
| 專家級知識工作 | GDPval-AA +289 Elo | 報告/分析/決策最強 |
| 計算機自動化 | OSWorld 72.7% | 唯一支持 GUI 操作 |
| 工具增強推理 | HLE+tools +1.7pp | 多工具協同最優 |
| 超長輸出需求 | 128K 輸出 | 長文/深度推理鏈 |
| 低延遲生產環境 | 快速模式 | 付費換速度 |
兩個都用: 智能路由架構
很多生產環境中,最優解是同時使用兩個模型,按任務類型智能路由:
| 任務類型 | 路由到 | 原因 | 預估佔比 |
|---|---|---|---|
| 常規問答/翻譯 | Gemini 3.1 Pro | 成本低,質量足夠 | 40% |
| 代碼生成/調試 | Claude Opus 4.6 | SWE-Bench 略優 | 20% |
| 推理/數學/科學 | Gemini 3.1 Pro | ARC-AGI-2 大幅領先 | 15% |
| Agent 工作流 | Gemini 3.1 Pro | MCP Atlas +9.7pp | 10% |
| 專家級分析/報告 | Claude Opus 4.6 | GDPval-AA 明顯領先 | 10% |
| 視頻/音頻處理 | Gemini 3.1 Pro | 唯一全模態選擇 | 5% |
按上述比例路由,整體成本相比全用 Claude 可節省約 55%,同時在各細分場景都獲得最優質量。
Gemini 3.1 Pro vs Claude Opus 4.6 成本優化策略
策略 1: 分級處理
簡單任務用 Gemini Low 模式 (最快最便宜),中等任務用 Gemini Medium,只有真正複雜的任務才用 Claude High 或 Gemini High (Deep Think Mini)。
策略 2: 批量與實時分離
實時請求用 Gemini 3.1 Pro (低延遲、低成本),離線批量處理可以用 Claude 的 Batch API (50% 折扣),綜合成本接近。
策略 3: 上下文緩存
Gemini 提供上下文緩存 (輸入 $0.20-$0.40/MTok),對於重複使用同一長文檔的場景,緩存後成本可降低 80% 以上。
🚀 快速驗證: 通過 API易 apiyi.com 平臺,你可以用同一個 API Key 同時調用 Gemini 3.1 Pro 和 Claude Opus 4.6。建議先用實際業務 prompt 做 A/B 測試,10 分鐘即可得出結論。
Gemini 3.1 Pro vs Claude Opus 4.6 快速上手
以下代碼演示如何通過 API易 統一接口同時調用兩個模型進行對比測試:
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易 統一接口
)
def compare_models(prompt, models=None):
"""對比兩個模型的輸出質量和速度"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-opus-4-6"]
results = {}
for model in models:
start = time.time()
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
elapsed = time.time() - start
results[model] = {
"time": f"{elapsed:.2f}s",
"tokens": resp.usage.total_tokens,
"answer": resp.choices[0].message.content[:300]
}
for model, data in results.items():
print(f"\n{'='*50}")
print(f"模型: {model}")
print(f"耗時: {data['time']} | Token: {data['tokens']}")
print(f"回答: {data['answer']}...")
# 測試推理能力
compare_models("請用鏈式推理解釋爲什麼 0.1 + 0.2 不等於 0.3")
查看帶思考級別控制的完整代碼
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def compare_with_thinking(prompt, thinking_config=None):
"""對比不同思考級別下的模型表現"""
configs = [
{"model": "gemini-3.1-pro-preview", "label": "Gemini Medium",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 8000}}},
{"model": "gemini-3.1-pro-preview", "label": "Gemini High (Deep Think Mini)",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 32000}}},
{"model": "claude-opus-4-6", "label": "Claude High (默認自適應)",
"extra": {}},
]
for cfg in configs:
start = time.time()
params = {
"model": cfg["model"],
"messages": [{"role": "user", "content": prompt}],
**cfg["extra"]
}
resp = client.chat.completions.create(**params)
elapsed = time.time() - start
print(f"\n[{cfg['label']}] {elapsed:.2f}s | {resp.usage.total_tokens} tokens")
print(f" → {resp.choices[0].message.content[:200]}...")
# 測試複雜推理
compare_with_thinking("證明: 對於所有正整數 n, n^3 - n 能被 6 整除")
常見問題
Q1: Gemini 3.1 Pro 和 Claude Opus 4.6 哪個更好?
沒有絕對的「更好」。Gemini 3.1 Pro 在抽象推理 (ARC-AGI-2 +8.3pp)、多步驟 Agent (MCP Atlas +9.7pp)、多模態和成本上領先; Claude Opus 4.6 在真實軟件工程 (SWE-Bench)、專家知識工作 (GDPval-AA +289 Elo)、計算機操作和工具推理上佔優。建議通過 API易 apiyi.com 在你的實際場景中做 A/B 測試。
Q2: 兩個模型的 API 接口兼容嗎? 能方便切換嗎?
通過 API易 apiyi.com 平臺,兩個模型使用統一的 OpenAI 兼容接口。切換隻需修改 model 參數 (gemini-3.1-pro-preview → claude-opus-4-6),其他代碼完全不用改。
Q3: 預算有限應該選哪個?
優先選擇 Gemini 3.1 Pro。它的輸入價格是 Claude Opus 4.6 的 40% ($2 vs $5),輸出價格不到一半 ($12 vs $25)。在大多數基準上 Gemini 表現不輸甚至更強,性價比極高。只在 SWE-Bench、專家任務等 Claude 明顯佔優的場景用 Claude。
Q4: 能同時用兩個模型做智能路由嗎?
可以。推薦的架構是: 用 Gemini 3.1 Pro 處理 80% 的常規請求 (成本低、推理強),Claude Opus 4.6 處理 20% 的專家級任務和工具增強場景。通過 API易 apiyi.com 的統一接口,只需在代碼中判斷任務類型並切換 model 參數即可實現智能路由。
總結: Gemini 3.1 Pro vs Claude Opus 4.6 選擇決策
| # | 對比維度 | Gemini 3.1 Pro | Claude Opus 4.6 | 勝出 |
|---|---|---|---|---|
| 1 | 抽象推理 | ARC-AGI-2 77.1% | 68.8% | Gemini |
| 2 | 編碼能力 | SWE-Bench 80.6% | 80.8% | Claude (微弱) |
| 3 | Agent 工作流 | MCP Atlas 69.2% | 59.5% | Gemini |
| 4 | 專家任務 | GDPval 1317 | 1606 | Claude |
| 5 | 多模態 | 全模態 (文/圖/音/視頻) | 文/圖 | Gemini |
| 6 | 價格 | $2/$12 per MTok | $5/$25 per MTok | Gemini (2x便宜) |
| 7 | 上下文窗口 | 1M (標準) | 200K (1M beta) | Gemini |
| 8 | 最大輸出 | 64K tokens | 128K tokens | Claude |
| 9 | 思考系統 | 3級 + Deep Think Mini | 4級 + 自適應 | 各有千秋 |
| 10 | 計算機操作 | 暫不支持 | OSWorld 72.7% | Claude 獨佔 |
最終建議:
- 性價比優先 → Gemini 3.1 Pro (便宜 2 倍,推理更強)
- 軟件工程優先 → Claude Opus 4.6 (SWE-Bench、GDPval 領先)
- 多模態優先 → Gemini 3.1 Pro (全模態唯一選擇)
- 最佳實踐 → 兩個都用,智能路由
推薦通過 API易 apiyi.com 平臺同時接入兩個模型,用統一接口實現靈活調度和 A/B 測試。
參考資料
-
Google 官方博客: Gemini 3.1 Pro 發佈公告
- 鏈接:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - 說明: 官方基準數據和功能介紹
- 鏈接:
-
Anthropic 官方公告: Claude Opus 4.6 發佈詳情
- 鏈接:
anthropic.com/news/claude-opus-4-6 - 說明: Claude Opus 4.6 技術規格和基準數據
- 鏈接:
-
Artificial Analysis: 第三方對比評測
- 鏈接:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - 說明: 獨立基準對比和性能分析
- 鏈接:
-
Google DeepMind: 模型卡和安全評估
- 鏈接:
deepmind.google/models/model-cards/gemini-3-1-pro - 說明: 詳細技術參數和安全性數據
- 鏈接:
-
VentureBeat: Deep Think Mini 深度體驗
- 鏈接:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - 說明: 三級思考系統實際測評
- 鏈接:
📝 作者: APIYI Team | 技術交流請訪問 API易 apiyi.com
📅 更新時間: 2026 年 2 月 20 日
🏷️ 關鍵詞: Gemini 3.1 Pro vs Claude Opus 4.6, 模型對比, ARC-AGI-2, SWE-Bench, MCP Atlas, 多模態, API 調用