¿Gemini 3.1 Pro Preview o Claude Opus 4.6? ¿Cuál elegir? Esta es la decisión inevitable para los desarrolladores de IA a principios de 2026. Este artículo realiza una comparativa exhaustiva desde 10 dimensiones clave, citando datos oficiales de referencia y evaluaciones de terceros para ayudarte a decidir con datos en la mano.
Valor central: Al terminar de leer, sabrás exactamente qué modelo elegir para cada escenario y cómo validarlo rápidamente en tus proyectos reales.

Resumen de datos de referencia: Gemini 3.1 Pro vs Claude Opus 4.6
Antes de profundizar en cada dimensión, veamos la comparativa global de referencias. Google afirma que Gemini 3.1 Pro lidera en 13 de 16 métricas, pero Claude Opus 4.6 destaca en varios escenarios prácticos.
| Benchmark | Gemini 3.1 Pro | Claude Opus 4.6 | Ganador | Diferencia |
|---|---|---|---|---|
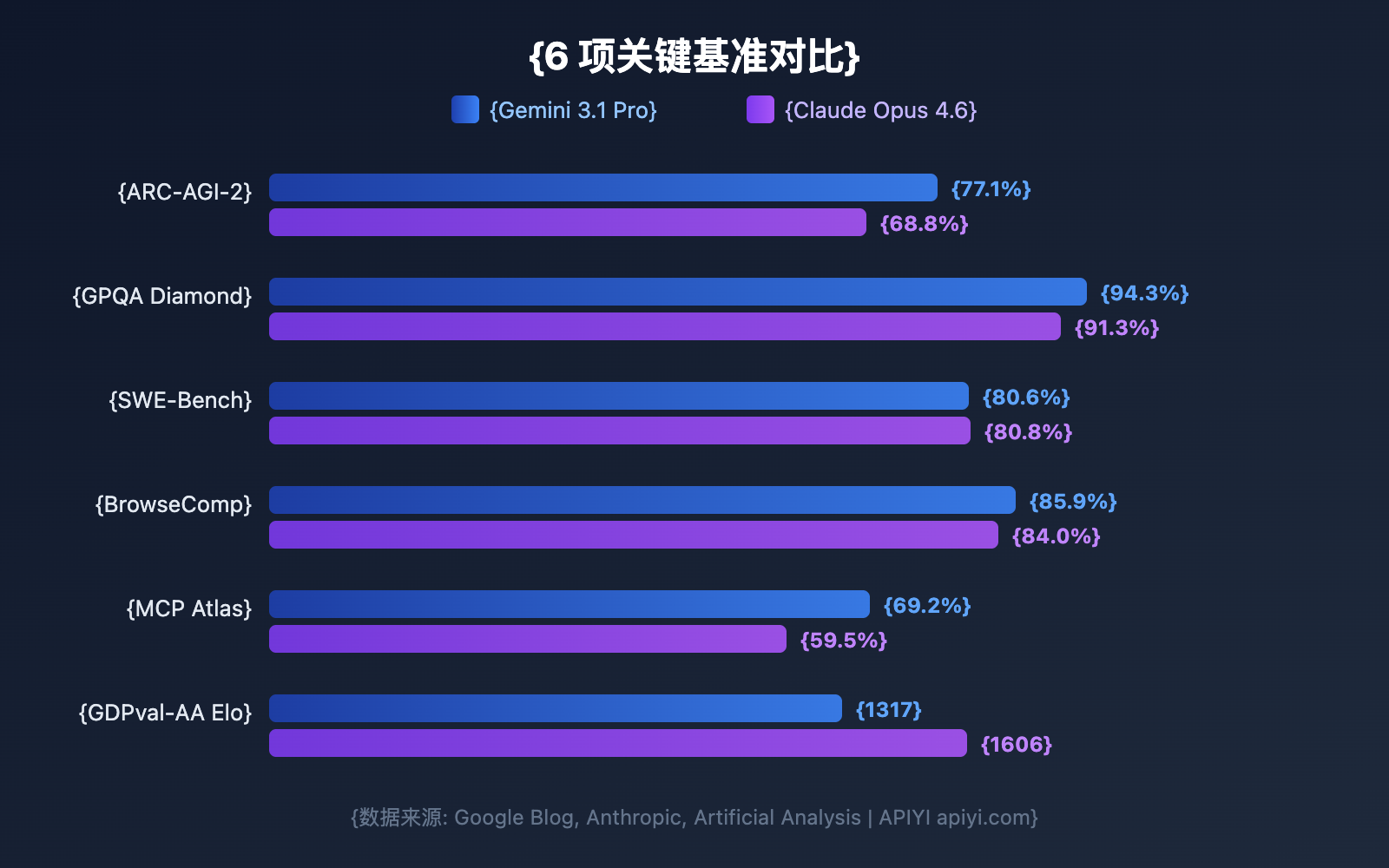
| ARC-AGI-2 (Razonamiento abstracto) | 77.1% | 68.8% | Gemini | +8.3pp |
| GPQA Diamond (Ciencias nivel PhD) | 94.3% | 91.3% | Gemini | +3.0pp |
| SWE-Bench Verified (Ingeniería de software) | 80.6% | 80.8% | Claude | +0.2pp |
| Terminal-Bench 2.0 (Codificación en terminal) | 68.5% | 65.4% | Gemini | +3.1pp |
| BrowseComp (Búsqueda con Agentes) | 85.9% | 84.0% | Gemini | +1.9pp |
| MCP Atlas (Agentes de múltiples pasos) | 69.2% | 59.5% | Gemini | +9.7pp |
| HLE sin herramientas (Examen definitivo) | 44.4% | 40.0% | Gemini | +4.4pp |
| HLE con herramientas (Examen definitivo) | 51.4% | 53.1% | Claude | +1.7pp |
| SciCode (Codificación científica) | 59% | 52% | Gemini | +7pp |
| MMMLU (QA Multilingüe) | 92.6% | 91.1% | Gemini | +1.5pp |
| tau2-bench Retail (Llamada a herramientas) | 90.8% | 91.9% | Claude | +1.1pp |
| GDPval-AA Elo (Tareas de expertos) | 1317 | 1606 | Claude | +289 |
📊 Nota sobre los datos: Los datos anteriores provienen de los blogs oficiales de Google, los anuncios oficiales de Anthropic y las evaluaciones de terceros de Artificial Analysis. Puedes llamar a ambos modelos simultáneamente para validarlos en escenarios reales a través de APIYI (apiyi.com).
Comparativa 1: Gemini 3.1 Pro vs. Claude Opus 4.6 – Capacidad de razonamiento
La capacidad de razonamiento es la ventaja competitiva central de cualquier Modelo de Lenguaje Grande. Las arquitecturas de razonamiento de ambos modelos presentan diferencias significativas.
Razonamiento abstracto: Gemini 3.1 Pro lleva una ventaja clara
ARC-AGI-2 es actualmente el benchmark de razonamiento abstracto más prestigioso. Gemini 3.1 Pro obtuvo una puntuación del 77.1%, superando por 8.3 puntos porcentuales al 68.8% de Claude Opus 4.6. Esto significa que Gemini es más fuerte en tareas que requieren inducir reglas a partir de unos pocos ejemplos.
Razonamiento científico de nivel PhD: La ventaja de Gemini es notable
El test GPQA Diamond evalúa preguntas científicas de nivel de doctorado (PhD). Gemini 3.1 Pro alcanzó un 94.3%, mientras que Claude Opus 4.6 se quedó en un 91.3%. Una diferencia de 3 puntos porcentuales en este nivel de dificultad es sumamente significativa.
Razonamiento potenciado por herramientas: Claude contraataca
En el HLE (Humanity's Last Exam), Gemini lidera en condiciones sin herramientas (44.4% vs. 40.0%), pero al introducir herramientas, Claude lo supera (53.1% vs. 51.4%). Esto indica que Claude Opus 4.6 es superior al utilizar herramientas externas para asistir en el razonamiento.
| Subdimensión de razonamiento | Gemini 3.1 Pro | Claude Opus 4.6 | Ideal para |
|---|---|---|---|
| Razonamiento abstracto | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Reconocimiento de patrones, inducción de reglas |
| Razonamiento científico | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Investigación académica, asistencia con artículos |
| Razonamiento con herramientas | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Flujos de trabajo complejos, colaboración entre herramientas |
| Razonamiento matemático | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Especialidad de Deep Think Mini |
Comparativa 2: Gemini 3.1 Pro vs. Claude Opus 4.6 – Capacidad de programación
La capacidad de programación es la dimensión que más interesa a los desarrolladores. El rendimiento de ambos modelos es muy cercano, aunque cada uno tiene sus propios enfoques.
SWE-Bench: Prácticamente un empate
SWE-Bench Verified es un benchmark basado en la resolución de problemas reales de GitHub:
- Claude Opus 4.6: 80.8% (ligera ventaja)
- Gemini 3.1 Pro: 80.6%
Con una diferencia de apenas 0.2 puntos porcentuales, se puede considerar que ambos tienen capacidades equivalentes en tareas de ingeniería de software real.
Terminal-Bench: Gemini toma la delantera
Terminal-Bench 2.0 evalúa la capacidad de los agentes de programación en entornos de terminal:
- Gemini 3.1 Pro: 68.5%
- Claude Opus 4.6: 65.4%
Esta diferencia de 3.1 puntos sugiere que Gemini tiene una mayor capacidad de ejecución en escenarios de agentes de terminal.
Programación competitiva: Gemini a la cabeza
Los datos de LiveCodeBench Pro muestran que Gemini 3.1 Pro alcanza los 2887 Elo, demostrando un rendimiento excelente en programación competitiva. Aunque los datos correspondientes para Claude Opus 4.6 no se han hecho públicos en su totalidad, su desempeño en competiciones como la USACO indica que Claude también se encuentra en el nivel superior.
# Prueba la capacidad de programación de ambos modelos simultáneamente a través de APIYI
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
# Prueba de la misma tarea de programación por separado
coding_prompt = "Implementa un LRU Cache que soporte operaciones get y put con complejidad temporal O(1)"
for model in ["gemini-3.1-pro-preview", "claude-opus-4-6"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": coding_prompt}]
)
print(f"\n{'='*50}")
print(f"Modelo: {model}")
print(f"Uso de tokens: {resp.usage.total_tokens}")
print(f"Respuesta:\n{resp.choices[0].message.content[:500]}")
Comparativa 3: Capacidades de Agente de Gemini 3.1 Pro vs. Claude Opus 4.6
Los agentes y los flujos de trabajo autónomos son el escenario central para 2026. Este es uno de los campos donde las diferencias entre ambos modelos son más marcadas.
Búsqueda de Agentes: Empate técnico
BrowseComp evalúa la capacidad de búsqueda web autónoma y la extracción de información de los modelos:
- Gemini 3.1 Pro: 85.9%
- Claude Opus 4.6: 84.0%
La diferencia es de solo 1.9 puntos porcentuales; ambos están en el nivel más alto de la industria.
Agentes de múltiples pasos: Gemini toma la delantera
MCP Atlas pone a prueba flujos de trabajo complejos de varios pasos. Gemini 3.1 Pro obtuvo un 69.2%, superando por casi 10 puntos el 59.5% de Claude Opus 4.6. Este es uno de los puntos de referencia donde la brecha entre ambos es más evidente.
Uso de la computadora: La ventaja exclusiva de Claude
El benchmark OSWorld evalúa la capacidad del modelo para operar una interfaz gráfica de usuario (GUI) real. Claude Opus 4.6 alcanzó una puntuación del 72.7%. Gemini aún no ha publicado resultados para esta categoría. Esto significa que, si necesitas que una IA automatice aplicaciones de escritorio, Claude es actualmente la única opción viable.
Tareas de nivel experto: Claude lidera claramente
GDPval-AA evalúa tareas de nivel experto en entornos de oficina reales (análisis de datos, redacción de informes, etc.). Claude Opus 4.6 obtuvo una calificación Elo de 1606, superando con creces los 1317 de Gemini. Esto demuestra que Claude es más confiable en trabajos de conocimiento que requieren una comprensión profunda y una ejecución meticulosa.
| Subdimensión de Agente | Gemini 3.1 Pro | Claude Opus 4.6 | Diferencia |
|---|---|---|---|
| BrowseComp (Búsqueda) | 85.9% | 84.0% | +1.9pp |
| MCP Atlas (Multipaso) | 69.2% | 59.5% | +9.7pp |
| APEX-Agents (Ciclo largo) | 33.5% | 29.8% | +3.7pp |
| OSWorld (Uso de PC) | — | 72.7% | Exclusivo de Claude |
| GDPval-AA (Tareas experto) | 1317 Elo | 1606 Elo | +289 |
Comparativa 4: Arquitectura del sistema de pensamiento de Gemini 3.1 Pro vs. Claude Opus 4.6
Ambos modelos cuentan con mecanismos de "pensamiento profundo", pero sus filosofías de diseño son distintas.
Gemini 3.1 Pro: Sistema de pensamiento de tres niveles
| Nivel | Nombre | Características | Casos de uso ideales |
|---|---|---|---|
| Low | Respuesta rápida | Latencia casi nula | Preguntas simples, traducción |
| Medium | Razonamiento equilibrado | Latencia media (Nuevo) | Programación diaria, análisis |
| High | Deep Think Mini | Razonamiento profundo, resuelve problemas de la IMO en 8 min | Matemáticas, depuración compleja |
El modo "High" de Gemini 3.1 Pro es, en realidad, una versión mini de Deep Think (el modelo de razonamiento dedicado de Google), lo que equivale a tener un motor de razonamiento especializado integrado dentro del modelo.
Claude Opus 4.6: Sistema de pensamiento adaptativo
| Nivel | Nombre | Características | Casos de uso ideales |
|---|---|---|---|
| Low | Modo rápido | Coste de razonamiento mínimo | Tareas sencillas |
| Medium | Modo equilibrado | Razonamiento moderado | Desarrollo convencional |
| High | Modo profundo (Predeterminado) | Determina automáticamente la profundidad | La mayoría de las tareas |
| Max | Razonamiento máximo | Potencia de razonamiento total | Problemas extremadamente difíciles |
Lo más destacado de Claude es su pensamiento adaptativo: el modelo decide automáticamente cuántos recursos de razonamiento invertir según la complejidad de la pregunta, sin que el desarrollador tenga que elegir manualmente. El modo "High" predeterminado ya es sumamente inteligente.
🎯 Comparativa práctica: Gemini te ofrece un control manual más fino (3 niveles), ideal para escenarios que requieren un control preciso de costes y latencia; Claude te ofrece una adaptación automática más inteligente (4 niveles + adaptativo), ideal para entornos de producción de tipo "configurar y olvidar". Ambos modelos se pueden invocar y comparar directamente en APIYI apiyi.com.
Comparativa 5: Gemini 3.1 Pro vs Claude Opus 4.6 – Precios y costos
El costo es un factor clave en entornos de producción. La diferencia de precio entre ambos modelos es significativa.
| Dimensión de precio | Gemini 3.1 Pro | Claude Opus 4.6 | Relación calidad-precio de Gemini |
|---|---|---|---|
| Entrada (estándar) | $2.00 / 1M tokens | $5.00 / 1M tokens | 2.5x más barato |
| Salida (estándar) | $12.00 / 1M tokens | $25.00 / 1M tokens | 2.1x más barato |
| Entrada (contexto largo >200K) | $4.00 / 1M tokens | $10.00 / 1M tokens | 2.5x más barato |
| Salida (contexto largo >200K) | $18.00 / 1M tokens | $37.50 / 1M tokens | 2.1x más barato |
Estimación de costos en escenarios reales
Calculado con un procesamiento diario de 1 millón de tokens de entrada + 200 mil tokens de salida:
| Escenario | Gemini 3.1 Pro | Claude Opus 4.6 | Ahorro mensual |
|---|---|---|---|
| Llamadas diarias | $4.40/día | $10.00/día | $168/mes |
| Uso intensivo (3x) | $13.20/día | $30.00/día | $504/mes |
Gemini 3.1 Pro cuesta aproximadamente la mitad que Claude Opus 4.6 en todas las dimensiones de precio. Para proyectos sensibles al costo, esta es una ventaja muy significativa.
💰 Sugerencia de optimización de costos: Al llamar a estos dos modelos a través de la plataforma APIYI (apiyi.com), puedes disfrutar de una facturación flexible y una gestión unificada. Se recomienda realizar pruebas en lotes pequeños para confirmar los resultados antes de decidir cuál será tu modelo principal.
Comparativa 6: Gemini 3.1 Pro vs Claude Opus 4.6 – Ventana de contexto y salida
| Especificaciones | Gemini 3.1 Pro | Claude Opus 4.6 | Ganador |
|---|---|---|---|
| Ventana de contexto | 1,000,000 tokens | 200,000 tokens (1M en beta) | Gemini |
| Salida máxima | 64,000 tokens | 128,000 tokens | Claude |
| Tamaño de archivo subido | 100MB | — | Gemini |
Ventana de contexto: Gemini lidera por 5 veces
Gemini 3.1 Pro admite de forma estándar 1 millón de tokens de contexto, mientras que Claude Opus 4.6 ofrece 200 mil (1M en fase beta). Para escenarios que requieren analizar grandes repositorios de código, documentos extensos o videos, la ventaja de Gemini es muy clara.
Salida máxima: Claude lidera por el doble
Claude Opus 4.6 admite una salida de 128K tokens, el doble que Gemini. Esto es crucial para la generación de textos largos, generación de código detallado y cadenas de razonamiento profundo; un mayor espacio de salida significa que el modelo puede "pensar" de manera más exhaustiva.
Comparativa 7: Capacidades multimodales de Gemini 3.1 Pro vs. Claude Opus 4.6
Las capacidades multimodales son, por tradición, el punto fuerte de Gemini.
| Modalidad | Gemini 3.1 Pro | Claude Opus 4.6 |
|---|---|---|
| Entrada de texto | ✅ | ✅ |
| Entrada de imagen | ✅ (Nativo) | ✅ |
| Entrada de vídeo | ✅ (Nativo) | ❌ |
| Entrada de audio | ✅ (Nativo) | ❌ |
| Procesamiento de PDF | ✅ | ✅ |
| URL de YouTube | ✅ | ❌ |
| Generación de SVG | ✅ (Nativo) | ✅ |
Gemini 3.1 Pro es un verdadero modelo multimodal nativo; su arquitectura de entrenamiento soporta de forma integrada la comprensión de texto, imagen, audio y vídeo. La multimodalidad de Claude Opus 4.6 se limita a texto e imágenes.
Si tu aplicación requiere análisis de vídeo, transcripción de audio o comprensión de contenido multimedia, Gemini 3.1 Pro es actualmente la única opción compatible.
Comparativa 8: Características exclusivas de Gemini 3.1 Pro vs. Claude Opus 4.6
Exclusivo de Gemini 3.1 Pro
| Característica | Descripción | Valor |
|---|---|---|
| Deep Think Mini | Motor de razonamiento dedicado integrado en el modo High | Razonamiento de nivel matemático/competitivo |
| Grounding (Búsqueda) | 5000 búsquedas gratuitas al mes | Enriquecimiento con información en tiempo real |
| Carga de archivos de 100MB | Carga de archivos de gran tamaño en una sola sesión | Análisis de grandes bases de código o datos |
| Análisis de URL de YouTube | Comprensión directa mediante la URL del vídeo | Análisis de contenido de vídeo |
| Comprensión nativa de audio/vídeo | Procesamiento multimodal de extremo a extremo | Aplicaciones de IA multimedia |
Exclusivo de Claude Opus 4.6
| Característica | Descripción | Valor |
|---|---|---|
| Uso de computadora (OSWorld 72.7%) | Operación automática de interfaces GUI | RPA / Pruebas automatizadas |
| Pensamiento adaptativo | Determinación automática de la profundidad del razonamiento | Razonamiento inteligente sin configuración |
| Salida de 128K | Soporte para respuestas extremadamente largas | Generación de textos largos / Razonamiento profundo |
| API por lotes (50% de descuento) | Procesamiento por lotes asíncrono | Procesamiento de datos a gran escala |
| Modo rápido | Tarifa 6x a cambio de una respuesta más veloz | Escenarios de producción de baja latencia |
Guía de selección de escenarios: Gemini 3.1 Pro vs Claude Opus 4.6
Basado en la comparativa de las 8 dimensiones anteriores, aquí tienes las recomendaciones de escenarios específicos:
Escenarios para elegir Gemini 3.1 Pro
| Escenario | Ventaja clave | Razón de recomendación |
|---|---|---|
| Razonamiento abstracto / Matemáticas | ARC-AGI-2 +8.3pp | Deep Think Mini es extremadamente potente |
| Agentes de múltiples pasos | MCP Atlas +9.7pp | Mayor capacidad de ejecución de flujos de trabajo |
| Análisis de video/audio | Multimodal nativo | Única opción para todas las modalidades |
| Proyectos sensibles al costo | Precio entre 2 y 2.5 veces más económico | Menor costo para la misma calidad |
| Análisis de documentos extensos | 1M de contexto | Soporte estándar para contextos masivos |
| Investigación científica | GPQA +3.0pp | Mayor capacidad de razonamiento científico |
Escenarios para elegir Claude Opus 4.6
| Escenario | Ventaja clave | Razón de recomendación |
|---|---|---|
| Ingeniería de software real | SWE-Bench 80.8% | Más preciso reparando bugs reales |
| Trabajo de conocimiento nivel experto | GDPval-AA +289 Elo | El mejor para informes, análisis y toma de decisiones |
| Automatización de computadoras | OSWorld 72.7% | Único que soporta operaciones GUI |
| Razonamiento potenciado por herramientas | HLE+tools +1.7pp | Óptima colaboración entre múltiples herramientas |
| Necesidad de salidas ultra largas | 128K de salida | Textos largos / Cadenas de razonamiento profundo |
| Entornos de producción de baja latencia | Modo rápido | Pagar por velocidad |
Usa ambos: Arquitectura de enrutamiento inteligente
En muchos entornos de producción, la solución óptima es usar ambos modelos simultáneamente, enrutando de forma inteligente según el tipo de tarea:
| Tipo de tarea | Enrutar a | Razón | Proporción estimada |
|---|---|---|---|
| Preguntas y respuestas generales / Traducción | Gemini 3.1 Pro | Bajo costo, calidad suficiente | 40% |
| Generación de código / Depuración | Claude Opus 4.6 | Ligeramente superior en SWE-Bench | 20% |
| Razonamiento / Matemáticas / Ciencia | Gemini 3.1 Pro | Liderazgo significativo en ARC-AGI-2 | 15% |
| Flujos de trabajo de agentes | Gemini 3.1 Pro | MCP Atlas +9.7pp | 10% |
| Análisis / Informes de nivel experto | Claude Opus 4.6 | Liderazgo claro en GDPval-AA | 10% |
| Procesamiento de video/audio | Gemini 3.1 Pro | Única opción para todas las modalidades | 5% |
Enrutando según estas proporciones, el costo total puede reducirse aproximadamente un 55% en comparación con usar solo Claude, obteniendo la mejor calidad en cada escenario específico.
Estrategias de optimización de costos: Gemini 3.1 Pro vs Claude Opus 4.6
Estrategia 1: Procesamiento por niveles
Usa el modo Gemini Low (el más rápido y barato) para tareas simples, Gemini Medium para tareas intermedias, y reserva Claude High o Gemini High (Deep Think Mini) solo para tareas verdaderamente complejas.
Estrategia 2: Separación de lotes y tiempo real
Usa Gemini 3.1 Pro para peticiones en tiempo real (baja latencia, bajo costo) y la API de lotes (Batch API) de Claude para procesamiento offline (50% de descuento); el costo total será similar.
Estrategia 3: Caché de contexto
Gemini ofrece caché de contexto (entrada de $0.20 a $0.40/MTok). Para escenarios donde se reutiliza el mismo documento largo, el costo puede reducirse más del 80% tras el almacenamiento en caché.
🚀 Validación rápida: A través de la plataforma APIYI (apiyi.com), puedes llamar simultáneamente a Gemini 3.1 Pro y Claude Opus 4.6 con la misma API Key. Te sugerimos realizar una prueba A/B con indicaciones reales de tu negocio; obtendrás conclusiones en solo 10 minutos.
Guía rápida: Gemini 3.1 Pro vs Claude Opus 4.6
El siguiente código muestra cómo llamar a ambos modelos simultáneamente a través de la interfaz unificada de APIYI para realizar pruebas comparativas:
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 统一接口
)
def compare_models(prompt, models=None):
"""对比两个模型的输出质量和速度"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-opus-4-6"]
results = {}
for model in models:
start = time.time()
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
elapsed = time.time() - start
results[model] = {
"time": f"{elapsed:.2f}s",
"tokens": resp.usage.total_tokens,
"answer": resp.choices[0].message.content[:300]
}
for model, data in results.items():
print(f"\n{'='*50}")
print(f"模型: {model}")
print(f"耗时: {data['time']} | Token: {data['tokens']}")
print(f"回答: {data['answer']}...")
# 测试推理能力
compare_models("请用链式推理解释为什么 0.1 + 0.2 不等于 0.3")
Ver el código completo con control de nivel de pensamiento
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def compare_with_thinking(prompt, thinking_config=None):
"""对比不同思考级别下的模型表现"""
configs = [
{"model": "gemini-3.1-pro-preview", "label": "Gemini Medium",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 8000}}},
{"model": "gemini-3.1-pro-preview", "label": "Gemini High (Deep Think Mini)",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 32000}}},
{"model": "claude-opus-4-6", "label": "Claude High (默认自适应)",
"extra": {}},
]
for cfg in configs:
start = time.time()
params = {
"model": cfg["model"],
"messages": [{"role": "user", "content": prompt}],
**cfg["extra"]
}
resp = client.chat.completions.create(**params)
elapsed = time.time() - start
print(f"\n[{cfg['label']}] {elapsed:.2f}s | {resp.usage.total_tokens} tokens")
print(f" → {resp.choices[0].message.content[:200]}...")
# 测试复杂推理
compare_with_thinking("证明: 对于所有正整数 n, n^3 - n 能被 6 整除")
Preguntas frecuentes
Q1: ¿Cuál es mejor, Gemini 3.1 Pro o Claude Opus 4.6?
No hay un «mejor» absoluto. Gemini 3.1 Pro lidera en razonamiento abstracto (ARC-AGI-2 +8.3pp), Agentes de múltiples pasos (MCP Atlas +9.7pp), multimodalidad y costes; Claude Opus 4.6 destaca en ingeniería de software real (SWE-Bench), trabajo de conocimiento experto (GDPval-AA +289 Elo), operación de computadoras y razonamiento de herramientas. Te recomendamos realizar pruebas A/B en tus escenarios reales a través de APIYI apiyi.com.
Q2: ¿Son compatibles las interfaces API de ambos modelos? ¿Es fácil alternar entre ellos?
A través de la plataforma APIYI apiyi.com, ambos modelos utilizan una interfaz unificada compatible con OpenAI. Para cambiar, solo necesitas modificar el parámetro model (gemini-3.1-pro-preview → claude-opus-4-6), sin tener que tocar el resto del código.
Q3: ¿Cuál debería elegir si tengo un presupuesto limitado?
Prioriza Gemini 3.1 Pro. Su precio de entrada es el 40% del de Claude Opus 4.6 ($2 vs $5), y el precio de salida es menos de la mitad ($12 vs $25). En la mayoría de los benchmarks, el rendimiento de Gemini no se queda atrás e incluso es superior, por lo que su relación calidad-precio es altísima. Usa Claude solo en escenarios donde sea claramente superior, como SWE-Bench o tareas de expertos.
Q4: ¿Puedo usar ambos modelos simultáneamente para hacer un enrutamiento inteligente?
Sí, puedes. La arquitectura recomendada es: usar Gemini 3.1 Pro para gestionar el 80% de las solicitudes rutinarias (bajo coste, razonamiento fuerte) y Claude Opus 4.6 para el 20% de las tareas de nivel experto y escenarios de herramientas mejoradas. Gracias a la interfaz unificada de APIYI apiyi.com, solo necesitas determinar el tipo de tarea en tu código y cambiar el parámetro model para implementar este enrutamiento inteligente.
Resumen: Decisión de elección entre Gemini 3.1 Pro vs Claude Opus 4.6
| # | Dimensión de comparativa | Gemini 3.1 Pro | Claude Opus 4.6 | Ganador |
|---|---|---|---|---|
| 1 | Razonamiento abstracto | ARC-AGI-2 77.1% | 68.8% | Gemini |
| 2 | Capacidad de programación | SWE-Bench 80.6% | 80.8% | Claude (ligero) |
| 3 | Flujo de trabajo de Agentes | MCP Atlas 69.2% | 59.5% | Gemini |
| 4 | Tareas de expertos | GDPval 1317 | 1606 | Claude |
| 5 | Multimodalidad | Multimodal completo (texto/imagen/audio/video) | Texto/Imagen | Gemini |
| 6 | Precio | $2/$12 por MTok | $5/$25 por MTok | Gemini (2x más barato) |
| 7 | Ventana de contexto | 1M (estándar) | 200K (1M beta) | Gemini |
| 8 | Salida máxima | 64K tokens | 128K tokens | Claude |
| 9 | Sistema de pensamiento | Nivel 3 + Deep Think Mini | Nivel 4 + Adaptativo | Cada uno tiene lo suyo |
| 10 | Operación de computadoras | No soportado aún | OSWorld 72.7% | Exclusivo de Claude |
Sugerencia final:
- Prioridad en relación calidad-precio → Gemini 3.1 Pro (2 veces más barato, razonamiento más fuerte)
- Prioridad en ingeniería de software → Claude Opus 4.6 (líder en SWE-Bench y GDPval)
- Prioridad en multimodalidad → Gemini 3.1 Pro (la única opción para todos los modos)
- Mejor práctica → Usar ambos con enrutamiento inteligente
Te recomendamos acceder a ambos modelos simultáneamente a través de la plataforma APIYI apiyi.com para lograr una gestión flexible y realizar pruebas A/B con una interfaz unificada.
Referencias
-
Blog oficial de Google: Anuncio de lanzamiento de Gemini 3.1 Pro
- Enlace:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - Descripción: Datos de referencia (benchmarks) oficiales e introducción de funciones.
- Enlace:
-
Anuncio oficial de Anthropic: Detalles del lanzamiento de Claude Opus 4.6
- Enlace:
anthropic.com/news/claude-opus-4-6 - Descripción: Especificaciones técnicas y datos de referencia de Claude Opus 4.6.
- Enlace:
-
Artificial Analysis: Evaluación comparativa de terceros
- Enlace:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - Descripción: Comparación de benchmarks independientes y análisis de rendimiento.
- Enlace:
-
Google DeepMind: Tarjetas de modelo (Model Cards) y evaluación de seguridad
- Enlace:
deepmind.google/models/model-cards/gemini-3-1-pro - Descripción: Parámetros técnicos detallados y datos de seguridad.
- Enlace:
-
VentureBeat: Experiencia en profundidad con Deep Think Mini
- Enlace:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - Descripción: Evaluación práctica del sistema de pensamiento de tres niveles.
- Enlace:
📝 Autor: APIYI Team | Para intercambio técnico, visita APIYI apiyi.com
📅 Fecha de actualización: 20 de febrero de 2026
🏷️ Palabras clave: Gemini 3.1 Pro vs Claude Opus 4.6, comparación de modelos, ARC-AGI-2, SWE-Bench, MCP Atlas, multimodal, llamadas a la API