سعر Gemini 3.1 Pro Preview و Gemini 3.0 Pro Preview متطابق تماماً — المدخلات 2.00 دولار، المخرجات 12.00 دولار / مليون توكن. السؤال هنا هو: ما الذي يميز 3.1 عن 3.0 حقاً؟ وهل يستحق الانتقال إليه؟
الإجابة هي: يستحق وبشدة، ولا يوجد أي سبب يمنعك من الانتقال.
في هذا المقال، سنقارن بين الإصدارين نقطة بنقطة باستخدام بيانات معيارية حقيقية. إليك "حرق" للنتيجة — قفزت نتيجة الاستدلال في ARC-AGI-2 لنموذج 3.1 Pro من 31.1% إلى 77.1%، أي بزيادة قدرها 2.5 ضعفاً؛ وتحسن الأداء في SWE-Bench للبرمجة من 76.8% إلى 80.6%؛ وفي BrowseComp للبحث من 59.2% إلى 85.9%. هذا ليس مجرد تحسين طفيف، بل هو ترقية جيل كامل.
القيمة الجوهرية: بعد قراءة هذا المقال، ستعرف بوضوح كل تحسين محدد في 3.1 Pro مقارنة بـ 3.0 Pro، وكيفية الاختيار بينهما في السيناريوهات المختلفة.

جدول مقارنة شامل للمواصفات بين Gemini 3.1 Pro و 3.0 Pro
لنلقِ نظرة أولاً على الاختلافات في المواصفات التقنية الأساسية:
| بعد المقارنة | Gemini 3.0 Pro Preview | Gemini 3.1 Pro Preview | التغيير |
|---|---|---|---|
| معرف النموذج (ID) | gemini-3-pro-preview |
gemini-3.1-pro-preview |
إصدار جديد |
| تاريخ الإصدار | 18 نوفمبر 2025 | 19 فبراير 2026 | +3 أشهر |
| سعر المدخلات (≤200K) | $2.00 / مليون توكن | $2.00 / مليون توكن | لم يتغير |
| سعر المخرجات (≤200K) | $12.00 / مليون توكن | $12.00 / مليون توكن | لم يتغير |
| سعر المدخلات (>200K) | $4.00 / مليون توكن | $4.00 / مليون توكن | لم يتغير |
| سعر المخرجات (>200K) | $18.00 / مليون توكن | $18.00 / مليون توكن | لم يتغير |
| نافذة السياق | 1 مليون توكن | 1 مليون توكن | لم يتغير |
| أقصى مخرجات | — | 65K توكن | زيادة واضحة |
| الحد الأقصى لرفع الملفات | 20 ميجابايت | 100 ميجابايت | 5 أضعاف |
| دعم روابط YouTube | ❌ | ✅ | ميزة جديدة |
| مستويات التفكير | مستويان (منخفض/عالي) | 3 مستويات (منخفض/متوسط/عالي) | إضافة المستوى المتوسط |
| نقطة نهاية customtools | ❌ | ✅ | ميزة جديدة |
| تاريخ انتهاء المعرفة | يناير 2025 | يناير 2025 | لم يتغير |
السعر، ونافذة السياق، وتاريخ انتهاء المعرفة لم تتغير تماماً. كل التغييرات هي تحسينات محضة في القدرات.
🎯 الاستنتاج الأساسي: السعر لم يزد فلساً واحداً، والميزات زادت ولم تنقص. من حيث المواصفات، يعتبر 3.1 Pro بديلاً متفوقاً تماماً لـ 3.0 Pro. عبر منصة APIYI (apiyi.com)، يمكنك الترقية ببساطة عن طريق تغيير معامل
modelمنgemini-3-pro-previewإلىgemini-3.1-pro-preview.
الاختلاف 1: قدرات الاستنتاج — من "ممتاز" إلى "رائد"
هذا هو أكبر تحسين في الانتقال من 3.0 إلى 3.1، وهو أيضاً نقطة الترقية التي ركزت عليها جوجل رسمياً.
| معيار الاستنتاج | 3.0 Pro | 3.1 Pro | معدل التحسن | التوضيح |
|---|---|---|---|---|
| ARC-AGI-2 | 31.1% | 77.1% | +148% | استنتاج لأنماط منطقية جديدة كلياً |
| GPQA Diamond | — | 94.3% | — | استنتاج علمي بمستوى طلاب الدراسات العليا |
| MMMLU | — | 92.6% | — | فهم متعدد التخصصات والأنماط |
| LiveCodeBench Pro | — | Elo 2887 | — | مسابقات برمجة في الوقت الفعلي |
التحسن في ARC-AGI-2 هو الأكثر إثارة للدهشة: من 31.1% إلى 77.1%، هذا ليس مجرد مضاعفة، بل زيادة بمقدار 2.5 ضعف. يقيم هذا الاختبار قدرة النموذج على حل أنماط منطقية جديدة كلياً، أي أنواع المسائل التي لم يسبق للنموذج رؤيتها. وبتحقيقه درجة 77.1%، تفوق Gemini 3.1 Pro على Claude Opus 4.6 الذي حقق 68.8%، مما يرسخ مكانته الرائدة في بُعد الاستنتاج.
السبب التقني وراء ذلك: تصف جوجل رسمياً نموذج 3.1 Pro بأنه يتمتع بـ "عمق ودقة غير مسبوقين" (unprecedented depth and nuance)، بينما كان وصف 3.0 Pro هو "ذكاء متقدم" (advanced intelligence). هذا ليس مجرد تغيير في المصطلحات التسويقية، فبيانات ARC-AGI-2 تثبت أن عمق الاستنتاج قد حقق بالفعل قفزة نوعية.
الاختلاف 2: نظام مستويات التفكير – من مستويين إلى 3 مستويات
يعد هذا أحد أكثر التحسينات عملية في إصدار 3.1 Pro.
نظام التفكير في 3.0 Pro (مستويان)
| المستوى | السلوك |
|---|---|
| low | أدنى حد من الاستنتاج، استجابة سريعة |
| high | استنتاج عميق، تأخير أعلى |
نظام التفكير في 3.1 Pro (3 مستويات)
| المستوى | السلوك | العلاقة المقابلة |
|---|---|---|
| low | أدنى حد من الاستنتاج، استجابة سريعة | مشابه للمستوى low في 3.0 |
| medium (جديد) | استنتاج معتدل، توازن بين السرعة والجودة | ≈ المستوى high في 3.0 |
| high | وضع Deep Think Mini، أعمق استنتاج | يتفوق بمراحل على المستوى high في 3.0 |
معلومات أساسية: المستوى medium في 3.1 Pro ≈ المستوى high في 3.0 Pro. وهذا يعني:
- باستخدام المستوى medium في 3.1، يمكنك الحصول على جودة الاستنتاج الخاصة بأعلى مستوى في 3.0.
- المستوى high في 3.1 هو فئة جديدة تماماً – يشبه نسخة مصغرة من Gemini Deep Think.
- نفس جودة الاستنتاج (medium)، ولكن بتأخير أقل مما كان عليه في المستوى high في 3.0.
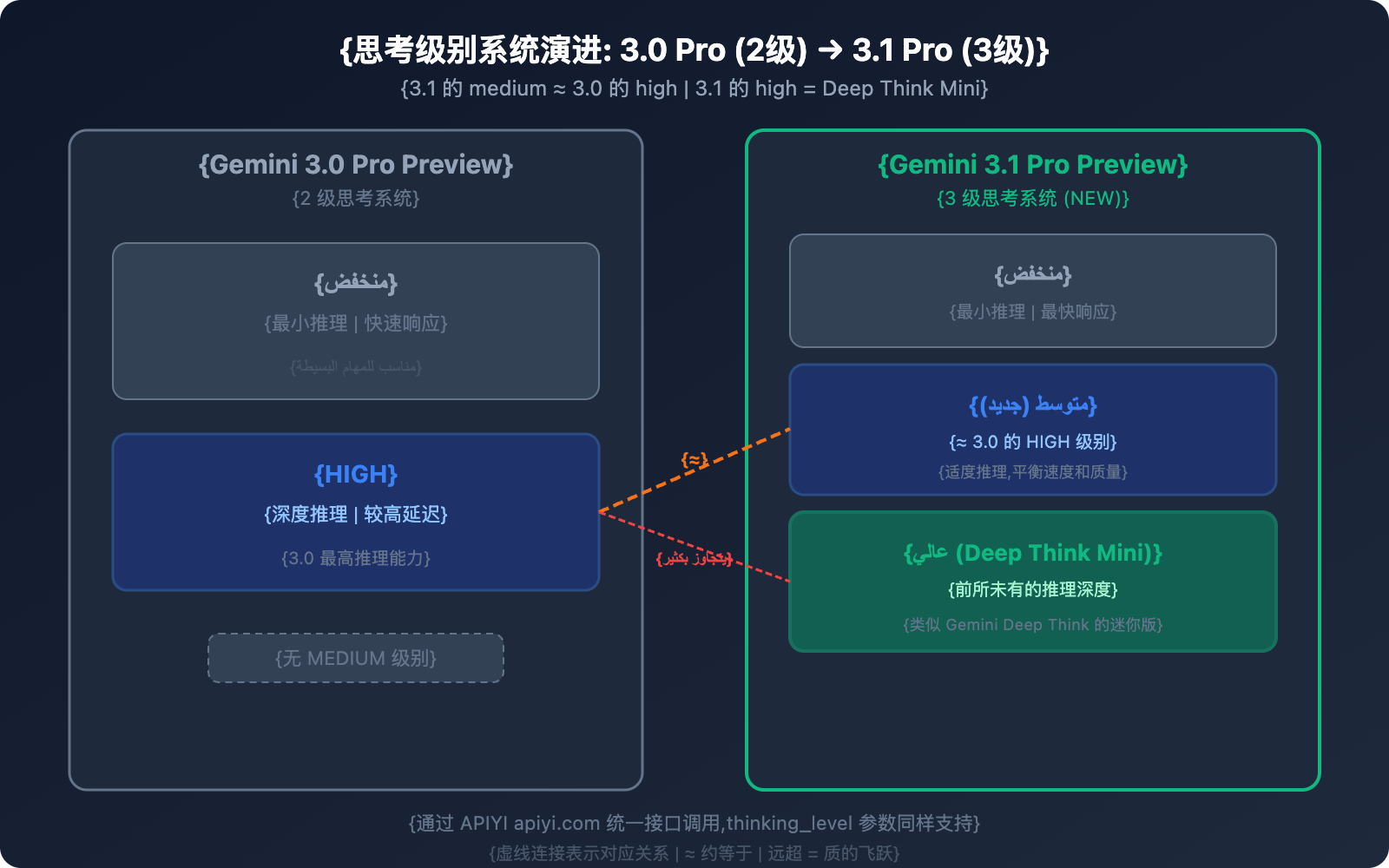
💡 نصيحة عملية: إذا كنت تستخدم سابقاً وضع high في 3.0 Pro، فننصحك بالبدء بوضع medium عند الانتقال إلى 3.1 Pro؛ حيث أن جودة الاستنتاج متساوية، لكن التأخير أقل. لا تنتقل إلى وضع high (Deep Think Mini) إلا عند مواجهة مهام استنتاج معقدة حقاً، فبهذه الطريقة يمكنك الحصول على تجربة شاملة أفضل دون زيادة في التكاليف. تدعم منصة APIYI (apiyi.com) تمرير معامل
thinking_level.
الاختلاف الثالث: قدرات البرمجة — الانضمام إلى الفئة الأولى
| معيار البرمجة | 3.0 Pro | 3.1 Pro | التحسن | مقارنة بالصناعة |
|---|---|---|---|---|
| SWE-Bench Verified | 76.8% | 80.6% | +3.8% | Claude Opus 4.6: 80.9% |
| Terminal-Bench 2.0 | 56.9% | 68.5% | +11.6% | برمجة محطة الطرفية (Agent) |
| LiveCodeBench Pro | — | Elo 2887 | — | مسابقات البرمجة في الوقت الفعلي |
قد يبدو التحسن في معيار SWE-Bench Verified طفيفاً من الناحية الظاهرية، حيث بلغ 3.8 نقطة مئوية فقط (من 76.8% إلى 80.6%)، ولكن في هذا النطاق من الدرجات، فإن كل زيادة بنسبة 1% تُعد إنجازاً صعباً للغاية. هذه النتيجة (80.6%) جعلت الفجوة بين Gemini 3.1 Pro و Claude Opus 4.6 (80.9%) تتقلص إلى 0.3% فقط، مما يعني انتقاله من "رائد الفئة الثانية" إلى "منافس شرس في الفئة الأولى".
أما التحسن في Terminal-Bench 2.0 فكان أكثر وضوحاً: من 56.9% إلى 68.5%، بزيادة قدرها 20.4%. يقيم هذا المعيار تحديداً قدرة الوكيل (Agent) على تنفيذ مهام البرمجة داخل بيئة محطة الطرفية (Terminal)، وزيادة قدرها 11.6 نقطة مئوية تعني تعزيزاً كبيراً في موثوقية 3.1 Pro في سيناريوهات البرمجة المؤتمتة.
الاختلاف الرابع: قدرات الوكيل (Agent) والبحث — قفزة نوعية
| معيار الوكيل (Agent) | 3.0 Pro | 3.1 Pro | معدل التحسن |
|---|---|---|---|
| BrowseComp | 59.2% | 85.9% | +45.1% |
| MCP Atlas | 54.1% | 69.2% | +27.9% |
هذان المعياران هما الأكثر تحسناً في الانتقال من الإصدار 3.0 إلى 3.1:
BrowseComp يقيم قدرة الوكيل على البحث في الويب؛ حيث قفزت النتيجة من 59.2% إلى 85.9%، بزيادة قدرها 26.7 نقطة مئوية. هذا له أهمية كبيرة في بناء وكلاء المساعدة البحثية، وتحليل المنافسين، واسترجاع المعلومات في الوقت الفعلي.
MCP Atlas يقيس القدرة على إدارة سير العمل متعدد الخطوات باستخدام بروتوكول سياق النموذج (Model Context Protocol)؛ حيث ارتفعت النتيجة من 54.1% إلى 69.2%. يُعد MCP معياراً لبروتوكولات الوكلاء تدعمه جوجل، وهذا التحسن يشير إلى أن قدرة 3.1 Pro على التنسيق والتنفيذ في مهام الوكلاء المعقدة قد تعززت بشكل ملحوظ.
نقطة نهاية مخصصة لـ customtools: أضاف إصدار 3.1 Pro أيضاً نقطة نهاية مخصصة باسم gemini-3.1-pro-preview-customtools لتحسين السيناريوهات التي تدمج بين أوامر bash واستدعاء الوظائف المخصصة. تم ضبط هذه النقطة خصيصاً لتعطي أولوية الاستدعاء للأدوات الشائعة لدى المطورين مثل view_file و search_code وغيرها، مما يجعلها أكثر استقراراً وموثوقية في سيناريوهات الوكلاء مثل الصيانة المؤتمتة ومساعدي البرمجة بالذكاء الاصطناعي مقارنة بنقاط النهاية العامة.
🎯 تنبيه لمطوري الوكلاء (Agents): إذا كنت تبني أدوات مثل بوتات مراجعة الكود أو وكلاء النشر المؤتمت، فنحن نوصي بشدة باستخدام نقطة النهاية customtools. يمكنك استدعاء هذه النقطة مباشرة عبر APIYI (apiyi.com)، فقط قم بتعبئة المعلمة model بالقيمة
gemini-3.1-pro-preview-customtools.
الفارق 5: قدرات المخرجات وميزات واجهة برمجة التطبيقات (API)
| الميزة | 3.0 Pro | 3.1 Pro | التغيير |
|---|---|---|---|
| الحد الأقصى لرموز المخرجات (tokens) | غير محدد | 65,000 | محدد بوضوح بـ 65K |
| الحد الأقصى لرفع الملفات | 20MB | 100MB | زيادة بمقدار 5 أضعاف |
| رابط YouTube | ❌ غير مدعوم | ✅ إدخال مباشر | ميزة جديدة |
| نقطة نهاية customtools | ❌ | ✅ | ميزة جديدة |
| كفاءة المخرجات | المرجع الأساسي | +15% | نتائج أفضل برموز (tokens) أقل |
حد مخرجات 65K: يمكنك الآن إنشاء مستندات طويلة كاملة، أو كتل برمجية ضخمة، أو تقارير تحليلية مفصلة دفعة واحدة، دون الحاجة إلى تقسيم الطلبات وربطها يدوياً.
رفع ملفات بحجم 100MB: التوسع من 20 ميجابايت إلى 100 ميجابايت يعني أنه يمكنك رفع مستودعات أكواد برمجية أكبر، أو مجموعات مستندات PDF ضخمة، أو ملفات وسائط لتحليلها مباشرة.
إدخال رابط YouTube مباشرة: يمكنك تمرير رابط يوتيوب مباشرة في الموجه (prompt)، وسيقوم النموذج تلقائياً بتحليل ومعالجة محتوى الفيديو — دون الحاجة إلى تحميله، تحويل صيغته، ثم إعادة رفعه.
تحسين كفاءة المخرجات بنسبة 15%: وفقاً لتعليقات فعلية من مدير الذكاء الاصطناعي في JetBrains، فإن إصدار 3.1 Pro ينتج نتائج أكثر موثوقية باستخدام رموز (tokens) أقل. وهذا يعني استهلاكاً فعلياً أقل للرموز لنفس المهمة، مما يؤدي إلى تكلفة أفضل.
قيمة هذه الميزات لمختلف المستخدمين
| الميزة | القيمة للمطورين الأفراد | القيمة لفرق الشركات |
|---|---|---|
| مخرجات 65K | إنشاء ملفات برمجية كاملة مرة واحدة | إنشاء المستندات التقنية والتقارير بكميات كبيرة |
| رفع 100MB | رفع مشروع كامل لتحليله | تدقيق مستودعات الأكواد الضخمة |
| رابط YouTube | تحليل سريع لفيديوهات الشرح والدروس | تحليل عروض المنتجات المنافسة |
| customtools | تطوير مساعدي البرمجة بالذكاء الاصطناعي | وكلاء (Agents) الأتمتة والعمليات (DevOps) |
| كفاءة +15% | تقليل تكاليف الاستدعاء الشخصية | تحسين التكلفة بشكل ملحوظ في المشاريع الكبرى |
💰 تجربة التكلفة: في نفس المهمة، وجدنا أن استهلاك رموز المخرجات (output tokens) في 3.1 Pro أقل بنسبة 10-15% في المتوسط مقارنة بـ 3.0 Pro. بالنسبة لتطبيقات الشركات التي تستهلك ملايين الرموز يومياً، يمكن أن يوفر هذا الانتقال مئات الدولارات شهرياً. يمكنك مقارنة الاستهلاك بدقة من خلال ميزة إحصائيات الاستخدام في APIYI (apiyi.com).
الفارق 6: كفاءة المخرجات — نتائج أفضل برموز أقل
هذا تحسين قد يغفل عنه الكثيرون، لكن تأثيره الفعلي كبير جداً. وفقاً لـ Vladislav Tankov، مدير الذكاء الاصطناعي في JetBrains: حقق 3.1 Pro تحسناً في الجودة بنسبة 15% مقارنة بـ 3.0 Pro، مع استهلاك رموز مخرجات أقل.
ماذا يعني هذا؟
تكلفة استخدام فعلية أقل: على الرغم من أن سعر الرمز الواحد هو نفسه، إلا أن 3.1 Pro يستهلك رموزاً أقل لإنجاز نفس المهمة، مما يجعل الفاتورة النهائية أقل. لنفترض وجود تطبيق يستهلك مليون رمز مخرجات يومياً، فإن تحسين الكفاءة بنسبة 15% يعني توفير حوالي 1.80 دولار يومياً من رسوم المخرجات.
سرعة استجابة أكبر: رموز مخرجات أقل تعني وقتاً أقصر في التوليد. في التطبيقات اللحظية التي تهتم بـ "زمن التأخير" (latency)، يعد هذا التحسين ذا قيمة كبيرة.
جودة مخرجات أكثر إيجازاً ودقة: لا يعني 3.1 Pro أنه "يقول أقل" ببساطة، بل إنه "يقول ما هو أدق" — حيث يوصل نفس كمية المعلومات (أو أكثر) بتعبيرات أكثر إحكاماً، مما يقلل من الحشو والكلام الزائد.
الفرق 7: الأمان والموثوقية
| أبعاد الأمان | 3.0 Pro | 3.1 Pro | التغيير |
|---|---|---|---|
| أمان النصوص | المرجع | +0.10% | تحسن طفيف |
| الأمان متعدد اللغات | المرجع | +0.11% | تحسن طفيف |
| معدل الرفض الخاطئ | المرجع | الحفاظ على مستوى منخفض | دون تغيير |
| الاستقرار في المهام الطويلة | المرجع | تحسن | أكثر موثوقية |
رغم أن التحسينات في الأمان ليست كبيرة من حيث الأرقام، إلا أن التوجه صحيح؛ حيث تم تعزيز القدرات دون التضحية بالأمان. ويعد تحسين الاستقرار في المهام الطويلة أمراً بالغ الأهمية لتطبيقات الوكيل (Agent)، مما يعني أنه في تدفقات العمل متعددة الخطوات، يكون إصدار 3.1 Pro أقل عرضة لـ "الانحراف عن المسار" أو تقديم مخرجات غير موثوقة.
الفرق 8: التغيرات في وصف التوجه الرسمي
| البعد | وصف 3.0 Pro | وصف 3.1 Pro |
|---|---|---|
| التوجه الجوهري | advanced intelligence | unprecedented depth and nuance |
| خصائص الاستدلال | advanced reasoning | SOTA reasoning |
| خصائص البرمجة | agentic and vibe coding | powerful coding |
| الوسائط المتعددة | multimodal understanding | powerful multimodal understanding |
من "advanced" إلى "unprecedented"، ومن "agentic and vibe coding" إلى "powerful coding" — تعكس هذه التغييرات في الصياغة ترقية في التوجه. ركز إصدار 3.0 Pro على "التقدم" و"الابتكار" (vibe coding)، بينما يركز إصدار 3.1 Pro على "العمق" و"القوة".
الاختلاف 9: توصيات الاستخدام — متى تستخدم أياً منهما؟

نموذج كود الانتقال
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # واجهة APIYI الموحدة
)
# الانتقال من 3.0 Pro إلى 3.1 Pro يتطلب تغيير بارامتر واحد فقط
# الإصدار القديم: model="gemini-3-pro-preview"
# الإصدار الجديد: model="gemini-3.1-pro-preview"
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # المكان الوحيد الذي يحتاج لتعديل
messages=[{"role": "user", "content": "حلل اختناقات الأداء في هذا الكود"}]
)
عرض كود اختبار المقارنة A/B
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # واجهة APIYI الموحدة
)
test_prompt = "بفرض وجود المصفوفة [3,1,4,1,5,9,2,6]، استخدم فرز الدمج (Merge Sort) وحلل التعقيد الزمني"
# اختبار 3.0 Pro
start = time.time()
resp_30 = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_30 = time.time() - start
# اختبار 3.1 Pro
start = time.time()
resp_31 = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_31 = time.time() - start
print(f"3.0 Pro: {time_30:.2f}s, {resp_30.usage.total_tokens} tokens")
print(f"3.1 Pro: {time_31:.2f}s, {resp_31.usage.total_tokens} tokens")
print(f"\nإجابة 3.0:\n{resp_30.choices[0].message.content[:300]}...")
print(f"\nإجابة 3.1:\n{resp_31.choices[0].message.content[:300]}...")
ملاحظات الانتقال وأفضل الممارسات
الخطوة الأولى: اختبار السيناريوهات الأساسية
قارن بين مخرجات 3.0 و 3.1 في أكثر 3-5 موجهات (prompts) تستخدمها بشكل متكرر. ركز على جودة الاستدلال، ودقة الكود، وتنسيق المخرجات.
الخطوة الثانية: ضبط مستوى التفكير
إذا كنت تستخدم وضع high في 3.0 سابقاً، فنحن نقترح البدء بوضع medium عند الانتقال إلى 3.1 (جودة استدلال مماثلة ولكن بسرعة أكبر). استخدم وضع high (Deep Think Mini) فقط عندما تحتاج حقاً إلى استدلال عميق.
الخطوة الثالثة: استكشاف القدرات الجديدة
جرب الميزات الحصرية في 3.1 مثل رفع ملفات بحجم 100 ميجابايت، وتحليل روابط يوتيوب، والمخرجات الطويلة التي تصل إلى 65 ألف توكن، فقد تكتشف سيناريوهات تطبيقية جديدة.
الخطوة الرابعة: الانتقال الكامل
بعد التأكد من النتائج، قم بتغيير جميع الاستدعاءات من gemini-3-pro-preview إلى gemini-3.1-pro-preview. يُنصح بالاحتفاظ بـ 3.0 كخيار احتياطي (fallback) حتى يعمل 3.1 بشكل مستقر في بيئتك لمدة أسبوع على الأقل.
🚀 انتقال سريع: عبر منصة APIYI (apiyi.com)، لا يتطلب الانتقال من 3.0 إلى 3.1 سوى تغيير بارامتر واحد. نقترح إجراء اختبار A/B على بعض السيناريوهات الأساسية للتأكد من النتائج، ثم الانتقال الكامل.
الأسئلة الشائعة
س1: هل يتوافق إصدار 3.1 Pro تماماً مع 3.0 Pro؟ وهل أحتاج لتعديل الموجه (prompt) بعد التبديل؟
واجهة الـ API متوافقة تماماً، كل ما عليك فعله هو تغيير معامل النموذج (model parameter). ولكن بما أن طريقة الاستنتاج في 3.1 Pro قد تحسنت، فقد تختلف استجابة بعض الموجهات التي تم ضبطها بدقة على إصدار 3.1 — عادةً ما تكون النتائج أفضل، ولكن نوصي بإجراء اختبارات تراجعية (regression testing) في السيناريوهات الأساسية. يمكنك عبر منصة APIYI (apiyi.com) استدعاء النسختين في وقت واحد للمقارنة بينهما.
س2: هل سيستمر دعم إصدار 3.0 Pro؟ ومتى سيتم إيقافه؟
باعتباره نموذجاً تجريبياً (Preview)، عادةً ما ترسل جوجل إشعاراً قبل أسبوعين على الأقل من إيقافه. حالياً لا يزال 3.0 Pro متاحاً، ولكن بالنظر إلى أن 3.1 Pro يتفوق عليه بشكل كامل في جميع الجوانب، فنحن ننصح بالانتقال إليه في أقرب وقت. الاستدعاء عبر APIYI (apiyi.com) لا يتأثر بتعديلات الإصدارات من جانب جوجل، حيث تقوم المنصة بمعالجة توجيه النماذج تلقائياً.
س3: هل استهلاك التوكنز (tokens) في وضع التفكير العالي (high) في 3.1 Pro كبير؟
وضع الـ high (المعروف بـ Deep Think Mini) يستهلك بالفعل المزيد من توكنز المخرجات، لأن النموذج يقوم بسلسلة استنتاج أعمق داخلياً. ننصح باستخدام وضع medium للمهام اليومية (وهو يعادل جودة high في إصدار 3.0)، واستخدام وضع high فقط في سيناريوهات مثل الاستنتاج الرياضي أو تصحيح الأكواد المعقدة. بهذه الطريقة، يمكنك الحفاظ على التكلفة أو حتى خفضها في معظم المهام.
س4: هل كلا الإصدارين متاحان على APIYI؟
نعم، كلاهما متاح. تدعم منصة APIYI (apiyi.com) كلاً من gemini-3-pro-preview و gemini-3.1-pro-preview باستخدام نفس مفتاح الـ API ورابط الـ base_url، مما يسهل إجراء اختبارات المقارنة (A/B testing) والتبديل المرن بينهما.
توصيات الترقية إلى Gemini 3.1 Pro لمختلف المستخدمين
تختلف الفوائد التي يجنيها المطورون عند الترقية من 3.0 إلى 3.1 باختلاف نوع الاستخدام، وإليك التوصيات المخصصة:
| فئة المستخدم | أهم ميزة مستفادة | أولوية الترقية | الإجراء المقترح |
|---|---|---|---|
| مطورو وكلاء الذكاء الاصطناعي (AI Agents) | تحسن الوكلاء/البحث بنسبة +45%، وMCP Atlas بنسبة +28% | ⭐⭐⭐⭐⭐ | التبديل فوراً، التحسن في النتائج هو الأوضح هنا |
| أدوات المساعدة في البرمجة | تحسن SWE-Bench بنسبة +5%، وTerminal-Bench بنسبة +20% | ⭐⭐⭐⭐ | نوصي بالتبديل، واستخدام وضع medium يكفي |
| محللو البيانات | تحسن استنتاج ARC-AGI-2 بنسبة +148%، ورفع ملفات حتى 100MB | ⭐⭐⭐⭐⭐ | أولوية قصوى للتبديل، قدرات تحليل الملفات الكبيرة تعززت بشكل هائل |
| صناع المحتوى | مخرجات طويلة تصل لـ 65 ألف توكن، وتحليل روابط YouTube | ⭐⭐⭐⭐ | نوصي بالتبديل، الميزات الجديدة عملية جداً |
| مستخدمو API للمهام الخفيفة | زيادة كفاءة المخرجات بنسبة +15% مع ثبات التكلفة | ⭐⭐⭐ | التبديل عند المناسبة، جودة أفضل بنفس السعر |
| التطبيقات الحساسة أمنياً | تحسن في الموثوقية والأمان، واستقرار في المهام الطويلة | ⭐⭐⭐⭐ | إجراء اختبارات تراجعية أولاً ثم التبديل |
💡 نصيحة عامة: بغض النظر عن فئة المستخدم، يمكنك عبر APIYI (apiyi.com) الاحتفاظ بكلا الإصدارين 3.0 و3.1 في نفس الوقت، واستخدام اختبارات A/B للتأكد من النتائج قبل التبديل الكامل. تكلفة انتقال صفرية، ومخاطر معدومة.
مسار اتخاذ قرار التبديل إلى إصدار Gemini 3.1 Pro
اتبع الخطوات التالية لتقرر ما إذا كنت ستبدل الآن:
- هل يعتمد تطبيقك على دقة الاستنتاج؟ ← نعم ← انتقل فوراً (تحسن ARC-AGI-2 بنسبة 148%).
- هل يتضمن تطبيقك وكلاء (Agents) أو بحثاً؟ ← نعم ← نوصي بشدة بالتبديل (تحسن BrowseComp بنسبة 45%).
- هل الموجهات (prompts) الخاصة بك مخصصة بشكل كبير؟ ← نعم ← اختبر أولاً باستخدام وضع medium، وتأكد من تطابق المخرجات قبل التبديل.
- هل تقوم فقط بمهام بسيطة مثل سؤال وجواب أو ترجمة؟ ← نعم ← يمكنك التبديل في أي وقت، النتائج ستكون متساوية على الأقل مع كفاءة أعلى.
- غير متأكد؟ ← قم بتشغيل 5 موجهات أساسية في اختبار A/B على APIYI (apiyi.com)، وستحصل على النتيجة في 10 دقائق.
الملخص: استنتاج 9 فروقات جوهرية
| # | بُعد الاختلاف | من 3.0 Pro إلى 3.1 Pro | قيمة الانتقال |
|---|---|---|---|
| 1 | قدرات الاستنتاج | ARC-AGI-2: من 31.1% إلى 77.1% | عالية جداً |
| 2 | نظام التفكير | من المستوى 2 إلى المستوى 3 (يشمل Deep Think Mini) | عالية |
| 3 | قدرات البرمجة | SWE-Bench: من 76.8% إلى 80.6% | عالية |
| 4 | الوكلاء (Agent)/البحث | BrowseComp: من 59.2% إلى 85.9% | عالية جداً |
| 5 | ميزات المخرجات/API | 65 ألف توكن للمخرجات، رفع ملفات حتى 100 ميجابايت، دعم روابط YouTube | عالية |
| 6 | كفاءة المخرجات | نتائج أفضل باستخدام توكنز أقل (+15%) | عالية |
| 7 | الأمان والموثوقية | تحسن طفيف في الأمان، وزيادة استقرار المهام الطويلة | متوسطة |
| 8 | التوجه الرسمي | من متقدم (advanced) إلى عمق غير مسبوق (unprecedented depth) | إشارة قوية |
| 9 | سيناريوهات الاستخدام | يجب الانتقال في جميع الحالات تقريباً | واضحة |
ملخص في جملة واحدة: بنفس السعر، وتوافق تام مع API، وتفوق في كل المؤشرات — يُعد Gemini 3.1 Pro Preview ترقية مجانية لنسخة 3.0 Pro Preview، ولا يوجد أي سبب يمنعك من الانتقال إليه.
نوصي بإكمال عملية الانتقال بسرعة عبر APIYI (apiyi.com)، حيث لا يتطلب الأمر سوى تعديل معامل النموذج (model parameter) فقط.
المصادر والمراجع
-
مدونة جوجل الرسمية: إعلان إطلاق Gemini 3.1 Pro
- الرابط:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - الوصف: نتائج المعايير الرسمية وتقديم الميزات.
- الرابط:
-
بطاقة نموذج Google DeepMind: التفاصيل التقنية وتقييم الأمان لـ 3.1 Pro
- الرابط:
deepmind.google/models/model-cards/gemini-3-1-pro - الوصف: بيانات الأمان والمعايير التفصيلية.
- الرابط:
-
أول مراجعة من VentureBeat: تجربة متعمقة لميزات Deep Think Mini
- الرابط:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - الوصف: تقرير تجربة واقعية لنظام التفكير من المستوى الثالث.
- الرابط:
-
Artificial Analysis: بيانات المقارنة بين 3.1 Pro و 3.0 Pro
- الرابط:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-gemini-3-pro - الوصف: مقارنة معايير الطرف الثالث وتحليل الأداء.
- الرابط:
📝 الكاتب: فريق APIYI | للتواصل التقني يرجى زيارة APIYI (apiyi.com)
📅 تاريخ التحديث: 20 فبراير 2026
🏷️ الكلمات المفتاحية: Gemini 3.1 Pro vs 3.0 Pro, مقارنة النماذج, مضاعفة الاستنتاج, SWE-Bench, ARC-AGI-2, Deep Think Mini