ملاحظة المؤلف: مقارنة متعمقة بين Claude Opus 4.6 و Grok 4.20 Beta عبر 7 أبعاد تشمل بنية الوكلاء المتعددين، قدرات البرمجة، أداء الاستنتاج، وتسعير واجهة برمجة التطبيقات (API)، لمساعدة المطورين على اختيار نموذج الذكاء الاصطناعي الأنسب حسب سيناريوهات الاستخدام المختلفة.
في فبراير 2026، شهد قطاع الذكاء الاصطناعي مواجهة مباشرة ومثيرة بين نموذجين من العيار الثقيل؛ حيث أطلقت شركة Anthropic نموذج Claude Opus 4.6 في 5 فبراير، وتبعته شركة xAI سريعاً بإطلاق Grok 4.20 (Beta) في منتصف الشهر نفسه. ورغم أن كلاهما يروج لـ "التعاون بين الوكلاء المتعددين" كنقطة بيع أساسية، إلا أن الفلسفة المعمارية لكل منهما تختلف تماماً عن الآخر.
القيمة الجوهرية: بعد قراءة هذا المقال، ستتضح لك الفروقات المحددة بين Claude Opus 4.6 و Grok 4.20 Beta في مجالات البرمجة، الاستنتاج، البيانات المباشرة، وتوفر واجهة برمجة التطبيقات (API)، مما يساعدك على اتخاذ القرار الصحيح بناءً على احتياجاتك.

نظرة عامة على الفروقات الجوهرية بين Claude Opus 4.6 و Grok 4.20 Beta
| بُعد المقارنة | Claude Opus 4.6 | Grok 4.20 Beta |
|---|---|---|
| المطور | Anthropic | xAI (إيلون ماسك) |
| تاريخ الإصدار | 5 فبراير 2026 (النسخة الرسمية) | منتصف فبراير 2026 (نسخة بيتا) |
| بنية الوكلاء المتعددين | فرق الوكلاء (القائد + أعضاء الفريق) | 4 وكلاء (Grok/Harper/Benjamin/Lucas) |
| نافذة السياق | 200 ألف قياسي / 1 مليون بيتا | من 256 ألف إلى 2 مليون توكن |
| الحد الأقصى للمخرجات | 128 ألف توكن | لم يُعلن عنه بعد |
| تسعير الـ API | 5$ / 25$ لكل مليون توكن | لم يُعلن بعد (مرجع 4.1: 0.20$ / 0.50$) |
| توفر الـ API | ✅ متاح بالكامل | ❌ غير متاح بعد |
| مصادر البيانات الحصرية | لا يوجد | بيانات التغريدات المباشرة من X Firehose |
الاختلاف في التوجه بين Claude Opus 4.6 و Grok 4.20 Beta
على الرغم من أن كلا النموذجين يركزان على "التعاون بين الوكلاء المتعددين"، إلا أن هناك اختلافاً جوهرياً في الفئات المستهدفة والمشكلات التي يعالجانها:
Claude Opus 4.6: ميزة "فرق الوكلاء" (Agent Teams) هي أداة إنتاجية موجهة للمطورين. فهي تسمح لعدة نسخ من Claude بالعمل بالتوازي في سياقات مستقلة للبرمجة، حيث يقوم "الوكيل القائد" (Lead Agent) بالتنسيق، بينما يمكن لكل "عضو فريق" (Teammate) قراءة وكتابة الملفات وتشغيل الاختبارات بشكل مستقل. هذه ميزة ناضجة وجاهزة للاستخدام الفعلي في المشاريع البرمجية.
Grok 4.20 Beta: نظام "الوكلاء الأربعة" (4 Agents) هو تعزيز للاستنتاج موجه لحل المشكلات العامة. حيث يعمل أربعة وكلاء بأدوار تخصصية مختلفة (البحث، المنطق، الإبداع، التنسيق) على التفكير بالتوازي داخلياً والتحقق من صحة إجابات بعضهم البعض للوصول إلى أدق نتيجة ممكنة. حالياً، هذه الميزة متاحة فقط لمستخدمي SuperGrok عبر واجهة الدردشة.
🎯 نصيحة للاختيار: إذا كنت مطوراً وتحتاج إلى ذكاء اصطناعي يساعدك في كتابة الكود، تصحيح الأخطاء، والتعامل مع المشاريع الضخمة، فإن Claude Opus 4.6 هو الخيار الأكثر نضجاً حالياً، ويمكنك استدعاؤه مباشرة عبر APIYI (apiyi.com). أما إذا كان اهتمامك ينصب على الاستنتاج المعقد، تحليل المعلومات اللحظية، والتفكير من زوايا متعددة، فإن Grok 4.20 Beta يستحق المتابعة والاهتمام.
مقارنة بين بنية الوكلاء المتعددين في Claude Opus 4.6 و Grok 4.20 Beta
تعد بنية الوكلاء المتعددين (Multi-agent architecture) في هذين النموذجين هي الفرق الجوهري الذي يستحق التحليل المتعمق.
بنية فرق الوكلاء (Agent Teams) في Claude Opus 4.6
تعتمد ميزة "فرق الوكلاء" في Claude Opus 4.6 نمط البرمجة المتوازية الصريحة:
| المكون | وصف الوظيفة | المميزات |
|---|---|---|
| الوكيل القائد (Lead Agent) | المنسق الرئيسي | توزيع المهام، تجميع النتائج، الإشراف العام |
| زملاء الفريق (Teammates) | وكلاء عمل مستقلون | يمتلك كل منهم نافذة سياق كاملة خاصة به |
| قائمة المهام | حالة تعاون مشتركة | تتبع التبعيات، وفتح المهام المقفلة تلقائياً |
| نظام الرسائل | التواصل بين الوكلاء | يمكن للزملاء تبادل الرسائل مباشرة فيما بينهم |
الخصائص التقنية الرئيسية لفرق الوكلاء:
- سياق مستقل: يمتلك كل زميل في الفريق نافذة سياق كاملة ومستقلة، مما يمنع التداخل أو التشويش بين المهام.
- توازي على مستوى الملفات: يمكن لزملاء مختلفين العمل على ملفات مختلفة في آن واحد، مما يحقق تطويراً متوازياً حقيقياً.
- تنسيق فوري: من خلال قائمة المهام المشتركة ونظام الرسائل، يمكن للوكيل القائد تعديل توزيع المهام ديناميكياً.
- القدرة على التوسع: أظهرت الاختبارات الفعلية قدرة النظام على دعم 16 وكيلاً يعملون بالتوازي لبناء مترجم لغة Rust C.
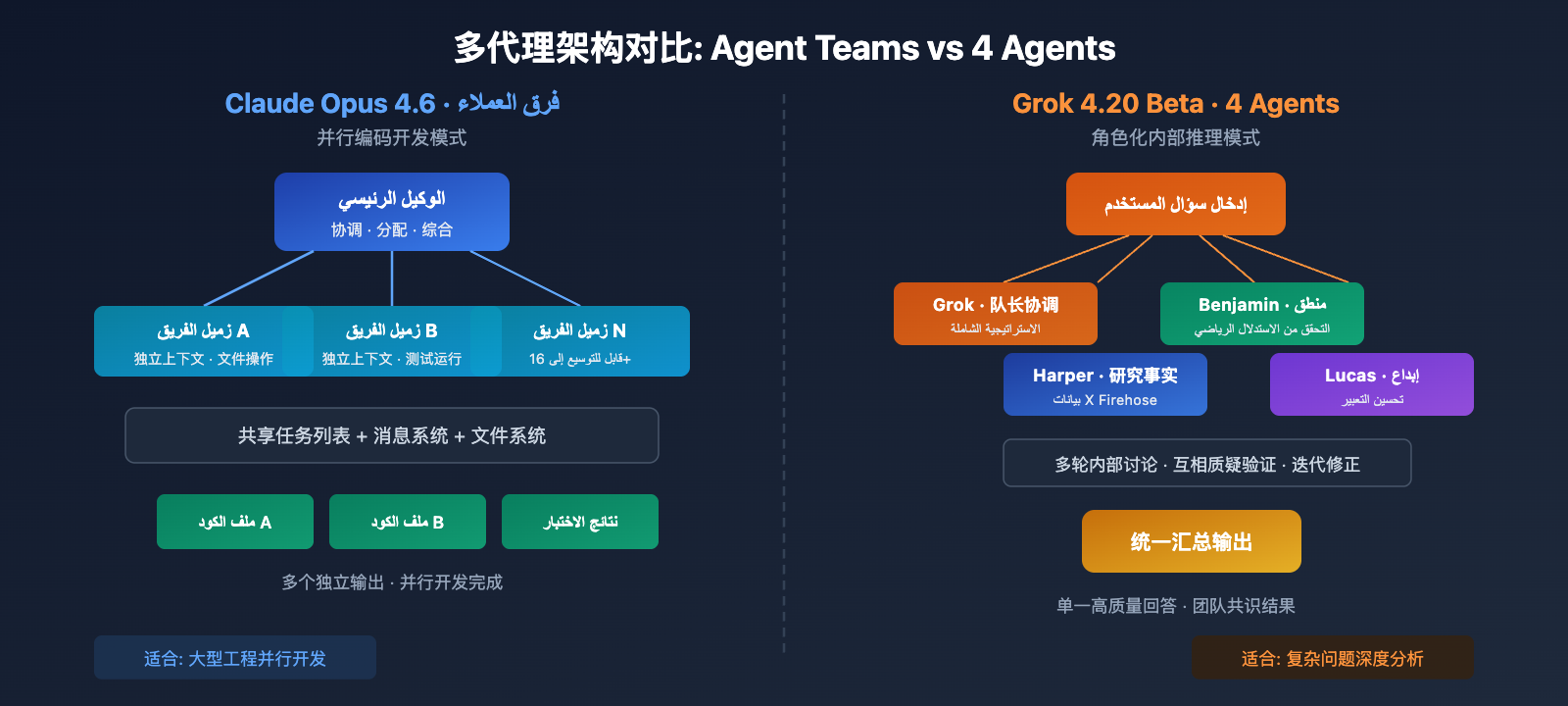
بنية الوكلاء الأربعة (4 Agents) في Grok 4.20 Beta
تعتمد ميزة الوكلاء الأربعة في Grok 4.20 Beta نمط الاستدلال الداخلي القائم على الأدوار:
- Grok (القائد): وضع الاستراتيجية العامة، وتجميع الإجابة النهائية.
- Harper (خبير البحث): البحث في الوقت الفعلي، والتحقق من البيانات، والوصول إلى بيانات X Firehose.
- Benjamin (خبير المنطق): الاستدلال الرياضي، والتحقق من البرمجة، والحسابات الدقيقة.
- Lucas (خبير الإبداع): التفكير المتشعب، وتحسين أسلوب التعبير، وتجربة المستخدم.
الاختلاف الجوهري في بنية الوكلاء الأربعة يكمن في آلية النقاش الداخلي والتقييم المتبادل متعدد الجولات. حيث يقوم الوكلاء بمساءلة استنتاجات بعضهم البعض وإجراء تصحيحات تكرارية، وهي آلية فعالة جداً في تقليل الهلوسة.
الفروق الجوهرية بين بنية الوكلاء في Claude Opus 4.6 و Grok 4.20 Beta
| البعد | فرق وكلاء Claude (Agent Teams) | وكلاء Grok الأربعة (4 Agents) |
|---|---|---|
| هدف التعاون | إنجاز مهام البرمجة بالتوازي | تحليل نفس المشكلة من زوايا متعددة |
| أدوار الوكلاء | متكافئة وظيفياً (كلهم نسخ من Claude) | أدوار متخصصة (بحث/منطق/إبداع/تنسيق) |
| طريقة العمل | سياق مستقل + نظام ملفات مشترك | تفكير داخلي متوازٍ + نقاشات متعددة الجولات |
| القابلية للتوسع | يمكن التوسع إلى أكثر من 16 وكيلاً | عدد ثابت من 4 وكلاء متخصصين |
| شكل المخرجات | مخرجات مستقلة لكل وكيل (أكواد/ملفات) | مخرجات مجمعة وموحدة (إجابة واحدة) |
| حالات الاستخدام | التطوير المتوازي للمشاريع الهندسية الكبيرة | التحليل العميق للمشكلات المعقدة |
| الرؤية للمستخدم | يمكن مراقبة تقدم عمل كل زميل في الفريق | تظهر فقط المخرجات النهائية المجمعة |
💡 رؤية تقنية: تشبه ميزة "فرق وكلاء Claude" وجود "عدة فرق تطوير في شركة واحدة تعمل على مشروع بالتوازي"، بينما تشبه ميزة "وكلاء Grok الأربعة" وجود "لجنة من الخبراء يجلسون حول طاولة لمناقشة نفس المعضلة". كلتا البنيتين تعالجان مشكلات مختلفة تماماً.
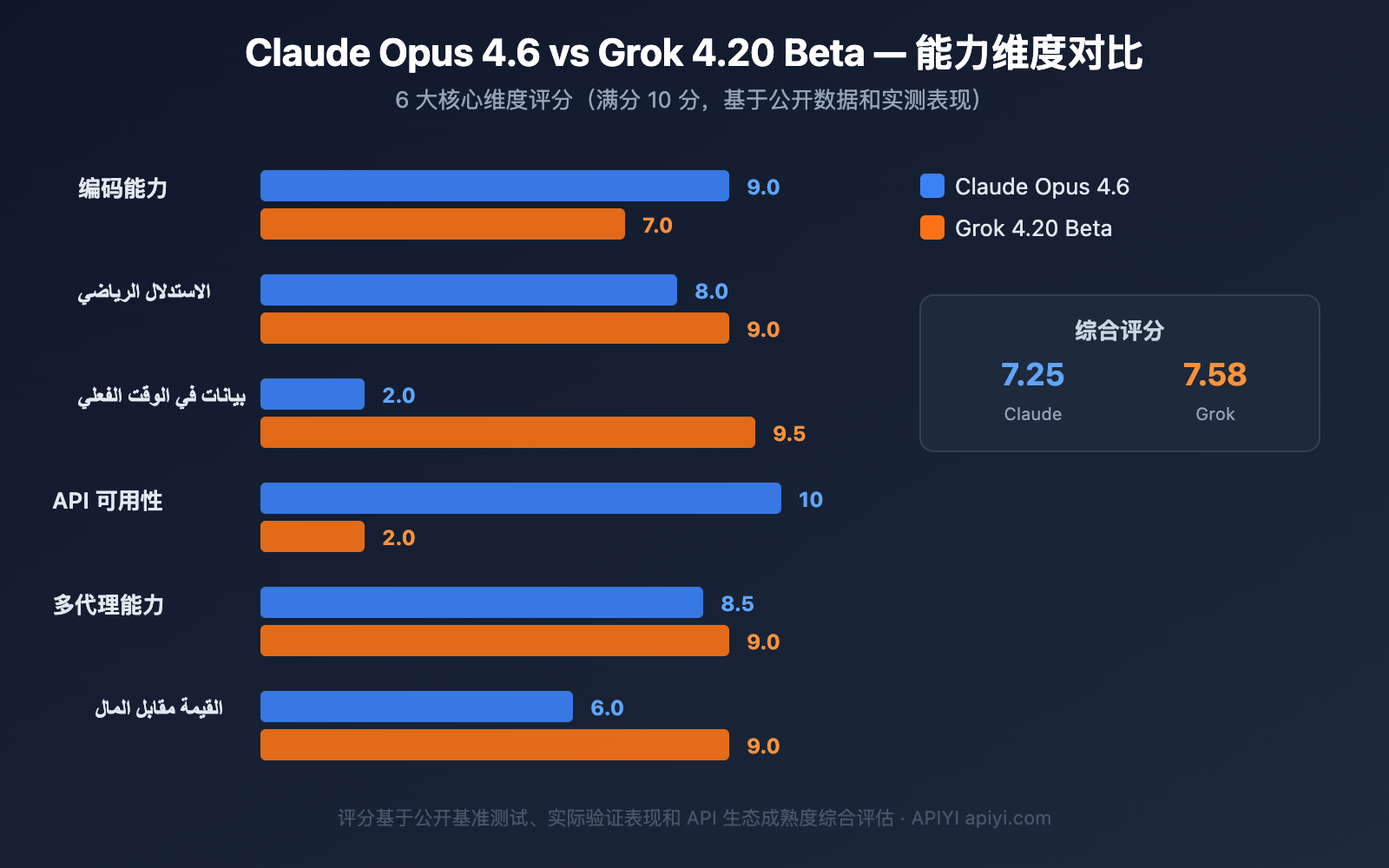
مقارنة الأداء المرجعي بين Claude Opus 4.6 وGrok 4.20 Beta
نتائج الاختبارات المرجعية المعلنة لنموذج Claude Opus 4.6
بصفته نموذجاً تم إطلاقه رسمياً، يمتلك Claude Opus 4.6 بيانات اختبارات مرجعية كاملة:
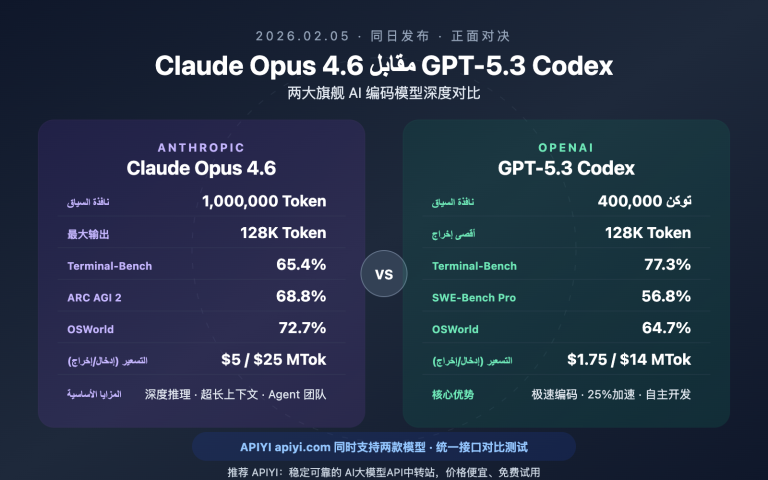
| الاختبار المرجعي | Claude Opus 4.6 | Claude Opus 4.5 | GPT-5.2 | الوصف |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 65.4% | 59.8% | — | تقييم البرمجة الوكيلية (Agentic Coding)، الأعلى في الصناعة |
| ARC AGI 2 | 68.8% | 37.6% | 54.2% | استدلال سهل للبشر وصعب على الذكاء الاصطناعي |
| GDPval-AA | +144 Elo | خط الأساس | مجموعة ضابطة | مهام العمل المعرفي ذات القيمة الاقتصادية |
| OSWorld | 72.7% | 66.3% | — | القدرة على استخدام الكمبيوتر |
| Humanity's Last Exam | رائد في الصناعة | — | — | استدلال معقد متعدد التخصصات |
يبرز أداء Claude Opus 4.6 بشكل خاص في مجال البرمجة – حيث حقق أعلى درجة في الصناعة في Terminal-Bench 2.0، ووُصف بأنه "مبرمج ذو ذوق رفيع" (tasteful coder)، وهو بارع بشكل خاص في:
- التنقل وفهم قواعد البيانات البرمجية الضخمة.
- مراجعة الكود واكتشاف الأخطاء (Bugs).
- تطوير الواجهات الأمامية من التصميم إلى التنفيذ الوظيفي.
- مهام البرمجة الوكيلية (Agentic Coding) المستمرة.
الأداء الفعلي المثبت لنموذج Grok 4.20 Beta
لا يمتلك Grok 4.20 Beta بيانات اختبارات مرجعية كاملة حتى الآن (لا يزال في المرحلة التجريبية Beta)، ولكن تم إثبات أدائه الفعلي في مجالات محددة:
- مسابقة تداول Alpha Arena: الذكاء الاصطناعي الوحيد الذي حقق أرباحاً بين جميع المشاركين (متوسط عائد 12.11%، وذروة بلغت 50%).
- الأبحاث الرياضية: ساعد عالم الرياضيات Paata Ivanisvili في تحقيق اكتشافات جديدة في مجال دوال بلمان (Bellman functions)، حيث استنتج الصيغة الدقيقة لـ U(p,q) في حوالي 5 دقائق.
- البرمجة الهندسية: أقر إيلون ماسك علناً بأنه "بدأ في الإجابة بشكل صحيح على الأسئلة الهندسية المفتوحة".
- معالجة البيانات في الوقت الفعلي: بالاعتماد على X Firehose، يحقق تحليلاً لمشاعر السوق في أجزاء من الثانية.
توفر واجهة برمجة التطبيقات (API) والتسعير: Claude Opus 4.6 مقابل Grok 4.20 Beta
بالنسبة للمطورين، يعد توفر واجهة برمجة التطبيقات (API) والتكلفة من العوامل الحاسمة عند اختيار النموذج.
تفاصيل تسعير واجهة برمجة تطبيقات Claude Opus 4.6
| البند | التسعير | الوصف |
|---|---|---|
| الإدخال القياسي | 5 دولار / مليون توكن | ضمن سياق 200 ألف |
| الإخراج القياسي | 25 دولار / مليون توكن | بحد أقصى 128 ألف توكن |
| إدخال السياق الطويل | 10 دولار / مليون توكن | تبديل تلقائي عند تجاوز 200 ألف |
| إخراج السياق الطويل | 37.50 دولار / مليون توكن | وضع بيتا 1 مليون |
| تخزين الموجهات مؤقتاً (Prompt Caching) | توفير يصل إلى 90% | تخزين الموجهات المتكررة |
| المعالجة بالدفعة (Batch) | توفير 50% | الطلبات غير المتزامنة بالدفعة |
| الوضع السريع (Fast) | 30 / 150 دولار لكل مليون توكن | سرعة أكبر بـ 2.5 مرة |
واجهة برمجة تطبيقات Claude Opus 4.6 متاحة بالفعل على جميع المنصات الرئيسية: claude.ai، وAnthropic API، وAzure، وAWS Bedrock، وغيرها.
حالة واجهة برمجة تطبيقات Grok 4.20 Beta
واجهة برمجة تطبيقات Grok 4.20 Beta ليست متاحة بعد. وبالرجوع إلى تسعير Grok 4.1:
- الإدخال: 0.20 دولار / مليون توكن
- الإخراج: 0.50 دولار / مليون توكن
إذا حافظ Grok 4.20 على استراتيجية تسعير مماثلة، فستكون تكلفة واجهة برمجة التطبيقات الخاصة به أقل بكثير من Claude Opus 4.6. ومع ذلك، وبالنظر إلى أن بنية "الوكلاء الأربعة" (4 Agents) تتطلب تشغيل أربعة وكلاء متوازيين، فقد يرتفع التسعير الفعلي قليلاً.
💰 نصيحة التكلفة: Claude Opus 4.6 متاح الآن عبر APIYI (apiyi.com)، حيث يمكن للمطورين الحصول مباشرة على مفتاح API للبدء في استخدامه. توفر المنصة نظام فوترة مرن ورصيد اختبار مجاني، وتدعم ميزات خفض التكلفة مثل Prompt Caching. وبمجرد فتح واجهة برمجة تطبيقات Grok 4.20، ستوفرها منصة APIYI في أسرع وقت ممكن.
توصيات سيناريوهات الاستخدام: Claude Opus 4.6 مقابل Grok 4.20 Beta
حالات اختيار Claude Opus 4.6
- التطوير البرمجي الاحترافي: يعد نظام "فرق الوكلاء" (Agent Teams) للبرمجة المتوازية أقوى حل حالي للمساعدة البرمجية بالذكاء الاصطناعي، وهو مثالي للمشاريع الكبيرة.
- هندسة الواجهات الأمامية (Frontend): يُصنف كـ "مبرمج ذو ذوق رفيع" (tasteful coder)، حيث تتصدر دقته في تحويل التصاميم إلى أكواد وظيفية هذا المجال.
- مراجعة الأكواد وتصحيح الأخطاء: أكثر موثوقية في التعامل مع قواعد البيانات البرمجية الضخمة، مع تحسن ملحوظ في قدرات اكتشاف الأخطاء (Bug detection).
- العمل المعرفي للمؤسسات: تفوق على GPT-5.2 في تقييم GDPval-AA (+144 Elo)، مما يجعله مناسباً لمجالات التمويل والقانون.
- الحاجة إلى واجهة برمجة تطبيقات جاهزة فوراً: متاح بالكامل ويدعم جميع المنصات السحابية الكبرى.
حالات اختيار Grok 4.20 Beta
- تحليل المعلومات في الوقت الفعلي: الوصول إلى بيانات X Firehose ميزة حصرية، مما يجعله مناسباً لمراقبة الرأي العام وتحليل السوق.
- استراتيجيات التداول المالي: هو نموذج الذكاء الاصطناعي الوحيد الذي حقق أرباحاً في مسابقة Alpha Arena، وهو المزيج الأفضل بين البيانات اللحظية والتحليل الكمي.
- البحث العلمي والرياضيات: أثبت قدرته على المساعدة في أبحاث الرياضيات المتقدمة، وهو مناسب للسيناريوهات الأكاديمية التي تتطلب استدلالاً صارماً.
- الحاجة إلى تحليل عميق متعدد الزوايا: آلية المناقشة الداخلية بين "الوكلاء الأربعة" مناسبة لاتخاذ القرارات المعقدة والتخطيط الاستراتيجي.
- السيناريوهات الحساسة للميزانية: بالرجوع لتسعير Grok 4.1، قد تكون تكلفة واجهة برمجة التطبيقات أقل بكثير من Claude Opus 4.6.
مصفوفة القرار: Claude Opus 4.6 مقابل Grok 4.20 Beta
| احتياجاتك | الخيار الموصى به | السبب |
|---|---|---|
| كتابة الأكواد وإدارة المشاريع | Claude Opus 4.6 | أعلى درجة في Agent Teams + Terminal-Bench |
| تحليل السوق في الوقت الفعلي | Grok 4.20 Beta | مصدر بيانات حصري من X Firehose |
| الاستدلال الرياضي والعلمي | Grok 4.20 Beta | تحقق بمستوى دالة Bellman |
| العمل المعرفي للمؤسسات | Claude Opus 4.6 | رائد في معيار GDPval-AA |
| الحاجة الفورية لواجهة API | Claude Opus 4.6 | متاح بالكامل، ومتوفر على APIYI |
| التحكم في تكاليف الـ API | Grok 4.20 Beta | التسعير المرجعي أقل بكثير |
| تطوير الواجهات الأمامية | Claude Opus 4.6 | تقييم "مبرمج ذو ذوق رفيع" |
| القرارات الاستراتيجية المعقدة | Grok 4.20 Beta | تحليل متعدد الزوايا عبر 4 وكلاء |
🚀 تجربة سريعة: هل تريد مقارنة الأداء الفعلي للنموذجين؟ نوصي بالحصول على مفتاح API لـ Claude Opus 4.6 عبر APIYI (apiyi.com) لتجربة قدرات البرمجة والاستدلال أولاً. وبمجرد إطلاق واجهة برمجة تطبيقات Grok 4.20، يمكنك التبديل والمقارنة بسرعة على نفس المنصة.
الأسئلة الشائعة
س1: أيهما أقوى: ميزة Agent Teams في Claude Opus 4.6 أم 4 Agents في Grok 4.20؟
التقنيتان ليستا من نفس النوع، لذا لا يمكن مقارنة "القوة" بينهما بشكل مباشر. ميزة Claude Agent Teams هي أداة برمجة متوازية، تسمح لعدة نسخ من الذكاء الاصطناعي بكتابة وحدات برمجية مختلفة في وقت واحد، وهي مثالية لسيناريوهات تطوير البرمجيات. أما Grok 4 Agents فهي آلية تعزيز الاستدلال، حيث يقوم أربعة وكلاء متخصصين بتحليل نفس المشكلة من زوايا مختلفة، وهي مناسبة لسيناريوهات اتخاذ القرار المعقدة. يعتمد الاختيار على سيناريو الاستخدام الخاص بك وليس على الأداء المطلق.
س2: هل يمكن استخدام واجهة برمجة التطبيقات (API) لاستدعاء هذين النموذجين الآن؟
واجهة برمجة التطبيقات (API) لنموذج Claude Opus 4.6 مفتوحة بالكامل، ويمكن الحصول على مفتاح API واستدعاؤه مباشرة عبر منصة APIYI (apiyi.com)، وهي تدعم واجهات متوافقة مع معايير OpenAI. أما API نموذج Grok 4.20 Beta فلم يفتح بعد، ويمكن استخدامه حالياً فقط عبر اشتراك SuperGrok (بـ 30 دولاراً شهرياً) من خلال واجهة الدردشة على grok.com. ستوفر منصة APIYI الوصول لنموذج Grok 4.20 فور فتح واجهة برمجة التطبيقات الخاصة به.
س3: هل هناك فجوة كبيرة في تكلفة الـ API بين هذين النموذجين؟
الفجوة كبيرة جداً. يبلغ السعر القياسي لـ Claude Opus 4.6 حوالي 5 دولارات للمليون توكن (إدخال) و25 دولاراً للمليون توكن (إخراج)، بينما السعر المرجعي لـ Grok 4.1 هو 0.20 دولار و0.50 دولار لكل مليون توكن، مما يعني أن تكلفة API Grok تبلغ حوالي 2% إلى 4% فقط من تكلفة Claude. ومع ذلك، يوفر Claude حلولاً لخفض التكاليف مثل "تخزين الموجهات مؤقتاً" (Prompt Caching) الذي يوفر حتى 90%، والمعالجة بالدفعات (Batch Processing) التي توفر 50%، مما يقلل التكلفة الفعلية بشكل كبير. كما يمكنك الحصول على طرق فوترة أكثر مرونة من خلال الاستدعاء عبر منصة APIYI (apiyi.com).
س4: إذا كانت الميزانية محدودة، أيهما يجب أن أختار أولاً؟
إذا كان احتياجك الأساسي هو البرمجة والتطوير، فإن Claude Opus 4.6، رغم سعره الأعلى، يعوض فرق التكلفة بجودة الكود ورفع الكفاءة الذي توفره ميزة Agent Teams. أما إذا كان تركيزك على تحليل المعلومات والاستدلال، فيمكنك البدء باستخدام اشتراك SuperGrok (30 دولاراً شهرياً لدردشة غير محدودة) لتجربة Grok 4.20 Beta، ثم تقييم الانتقال إليه بعد إطلاق الـ API الخاص به. في النهاية، يمكن إدارة واستدعاء كلا النموذجين عبر منصة واحدة وهي APIYI (apiyi.com).
الخلاصة
الاستنتاجات الجوهرية للمقارنة بين Claude Opus 4.6 و Grok 4.20 Beta:
- اختلاف مسار بنية الوكلاء المتعددين: يعمل Claude Agent Teams كـ "فريق تطوير متوازي"، بينما يعمل Grok 4 Agents كـ "مجموعة نقاش خبراء" — كلاهما يكمل الآخر ولا يحل محله.
- اختر Claude للبرمجة و Grok للاستدلال: يتصدر Claude Opus 4.6 في اختبارات Terminal-Bench و ARC AGI 2، بينما يتمتع Grok 4.20 بمزايا حصرية في الأبحاث الرياضية والتحليل في الوقت الفعلي.
- فجوة واضحة في نضج الـ API: نموذج Claude Opus 4.6 متاح بالكامل للاستخدام، بينما لا يزال Grok 4.20 في المرحلة التجريبية (Beta) ولم تفتح واجهة برمجة التطبيقات الخاصة به بعد.
- اعتبارات التكلفة: السعر المرجعي لـ Grok API أقل بكثير من Claude، لكن ميزة Prompt Caching في Claude يمكن أن تقلص هذه الفجوة.
- البيانات اللحظية هي الميزة الحصرية لـ Grok: بيانات X Firehose لا يمكن تعويضها في سيناريوهات التداول المالي وتحليل الرأي العام.
بالنسبة لمعظم المطورين، نوصي بالبدء باستخدام Claude Opus 4.6 لتلبية احتياجات البرمجة والمهام اليومية، مع متابعة تقدم إطلاق API Grok 4.20 لاستخدامه كأداة تكميلية في سيناريوهات محددة (التحليل اللحظي، الاستدلال الرياضي).
نوصي بإدارة استدعاءات الـ API بشكل موحد عبر APIYI (apiyi.com)، حيث تدعم المنصة بالفعل Claude Opus 4.6، وستوفر الوصول لـ Grok 4.20 فور إطلاقه، مما يسهل التبديل السريع ومقارنة التكاليف تحت واجهة برمجية واحدة.
📚 المصادر والمراجع
-
الإعلان الرسمي من Anthropic – إطلاق Claude Opus 4.6: تفاصيل ميزات النموذج واختبارات الأداء (Benchmarks)
- الرابط:
anthropic.com/news/claude-opus-4-6 - الوصف: معلومات الإطلاق الرسمية والتفاصيل التقنية لنموذج Claude Opus 4.6
- الرابط:
-
وثائق تسعير Claude API: القواعد الكاملة لتسعير الـ API والفوترة
- الرابط:
platform.claude.com/docs/en/about-claude/pricing - الوصف: يتضمن معلومات مفصلة حول التسعير القياسي، ورسوم السياق الطويل، وميزة Prompt Caching، وغيرها
- الرابط:
-
سجل الإصدارات الرسمي من xAI: تحديثات إصدارات سلسلة Grok
- الرابط:
docs.x.ai/developers/release-notes - الوصف: سجل تحديثات النماذج وإصدارات الـ API الرسمية من xAI
- الرابط:
-
تسعير نماذج xAI: التسعير الرسمي لـ Grok API
- الرابط:
docs.x.ai/developers/models - الوصف: معلومات التسعير المفصلة لمختلف إصدارات Grok API
- الرابط:
الكاتب: فريق APIYI
التواصل التقني: نرحب بمشاركة تجاربكم في استخدام Claude Opus 4.6 وGrok 4.20 Beta في قسم التعليقات. لمزيد من مقارنات النماذج وحلول الربط البرمجي (API)، تفضلوا بزيارة مجتمع APIYI التقني عبر apiyi.com.