يواجه العديد من المصممين عند التعامل مع GPT-Image-2 لأول مرة تساؤلاً جوهرياً: عندما أرفع صورة وأطلب من الذكاء الاصطناعي "تغيير لون ملابس الشخصية إلى الأزرق"، هل يقوم الذكاء الاصطناعي بتعديل البكسلات بدقة كما يفعل Photoshop، أم أنه يعيد رسم الصورة بالكامل في الخلفية؟ إجابة هذا السؤال تؤثر بشكل مباشر على كيفية استخدامنا لأدوات تحرير الصور بالذكاء الاصطناعي، وكيفية فهمنا لمدى قابلية التنبؤ بالنتائج.
في الواقع، هذه تفاصيل تقنية يساء فهمها بشكل كبير. سنقوم في هذا المقال بالانطلاق من مبادئ تحرير الصور بالذكاء الاصطناعي، لنحلل بعمق آليات عمل نماذج الصور ذاتية الانحدار (Autoregressive) من الجيل الجديد مثل GPT-Image-2 وNano Banana، للإجابة على سؤال "هل هو تعديل جزئي أم إعادة رسم؟" وكيف تحافظ هذه النماذج على اتساق بصري مذهل رغم أنها تعيد رسم الصورة بالكامل.
| السؤال الجوهري | الإجابة البديهية | الإجابة الحقيقية |
|---|---|---|
| طريقة التحرير | تغطية جزئية بأسلوب PS | إعادة رسم كامل للصورة عبر الرموز (Tokens) |
| مصدر الاتساق | الاحتفاظ بالبكسلات غير المعدلة | تثبيت ميزات الصورة الأصلية عبر آلية الانتباه الذاتي |
| البنية السائدة | إزالة الضجيج بالانتشار | نموذج Transformer ذاتي الانحدار |
| التحرير متعدد الجولات | تراكم التشويه بسهولة | GPT-Image-2 لا يعاني من انحراف ملحوظ |
بعد فهم هذه المبادئ، ستكتشف أن كتابة الموجه (Prompt)، واستخدام القناع (Mask)، واستراتيجيات تمرير الصور المرجعية أصبحت لها أسس نظرية جديدة. ننصح القراء بتجربة واجهة GPT-Image-2 على منصة APIYI (apiyi.com) أثناء القراءة، لربط المبادئ بالنتائج العملية.
مبدأ تحرير الصور بالذكاء الاصطناعي: ليس تعديلاً جزئياً بأسلوب PS، بل إعادة رسم ذكية
يعتقد العديد من المستخدمين، بناءً على تجربة التفاعل مع ChatGPT، أن تحرير الصور بالذكاء الاصطناعي يشبه "التعديل الجزئي" في Photoshop: حيث يحدد النظام المنطقة التي تريد تعديلها، ويغطي بضعة بكسلات في الصورة الأصلية، ويترك الباقي كما هو. هذا النموذج الذهني بديهي، لكنه خاطئ تماماً.
جميع نماذج تحرير الصور بالذكاء الاصطناعي السائدة تعتمد جوهرياً على منطق "إعادة الرسم". سواء كان ذلك GPT-Image-2، أو Nano Banana، أو سلسلة Stable Diffusion، فجميعها تحتاج إلى تشفير الصورة الأصلية أولاً إلى تمثيل داخلي (رموز أو تمثيل كامن)، ثم يقوم النموذج "بتخيل" التمثيل الداخلي الكامل للصورة الجديدة، وأخيراً فك التشفير للعودة إلى البكسلات. لا توجد أي خطوة تتضمن "الرسم فوق الصورة الأصلية".
وهذا هو السبب في أنك أحياناً تطلب من الذكاء الاصطناعي تغيير لون عين واحدة فقط، لتجد أن خصلات الشعر وتفاصيل الخلفية قد تغيرت بشكل طفيف. النموذج لا يتكاسل، بل هو بالفعل "يعيد رسم" الصورة بأكملها، لكنه يرسم معظم المناطق بشكل قريب جداً من الصورة الأصلية.
إذن السؤال هو: بما أنها عملية إعادة رسم، لماذا تبدو الصور التي تم تحريرها بواسطة GPT-Image-2 متسقة للغاية مع الصورة الأصلية، وتسمح حتى بجولات تحرير متعددة دون "الانحراف"؟ الإجابة تكمن في بنيتها. إذا كنت ترغب في التحقق من هذا السلوك بنفسك، يمكنك استدعاء واجهة /v1/images/edits الخاصة بـ GPT-Image-2 على موقع APIYI (apiyi.com)، وتجربة تحرير نفس الصورة بشكل متكرر باستخدام نفس الموجه، ومراقبة التغيرات في التفاصيل.
الفرق الجوهري بين التعديل الجزئي في PS وإعادة الرسم بالذكاء الاصطناعي
| وجه المقارنة | التعديل الجزئي في Photoshop | إعادة الرسم الذكية في GPT-Image-2 |
|---|---|---|
| وحدة التشغيل | البكسل | رموز بصرية (كتل 8×8 أو 16×16 بكسل) |
| المناطق غير المعدلة | تظل ثابتة فيزيائياً | تخضع للتشفير وفك التشفير، مع إعادة بناء طفيفة نظرياً |
| ضمان الاتساق | 100% (نسخ مباشر للبكسلات الأصلية) | مضمون عبر آلية الانتباه في النموذج |
| فهم الدلالات | لا يوجد، يعتمد على قيم البكسل فقط | يفهم دلالات "الملابس"، "الخلفية"، "الإضاءة" |
| الانتقال عند الحدود | يتطلب تنعيماً يدوياً | انتقال طبيعي تلقائي بناءً على الدلالات |
يعتمد Photoshop على "التعديل الميكانيكي" القائم على البكسل، بينما يعتمد الذكاء الاصطناعي على "الفهم ثم الرسم" القائم على الدلالات. ولهذا السبب يستطيع الذكاء الاصطناعي إنجاز تحرير شامل مثل "تحويل النهار إلى غسق" وهو أمر لا يمكن لـ Photoshop القيام به أبداً؛ فهو يعدل التمثيل الدلالي للصورة، وليس قيم RGB للبكسلات.
مبدأ عمل تحرير gpt-image-2: كيف "يفهم" محول التنبؤ الذاتي (Transformer) الصورة الأصلية؟
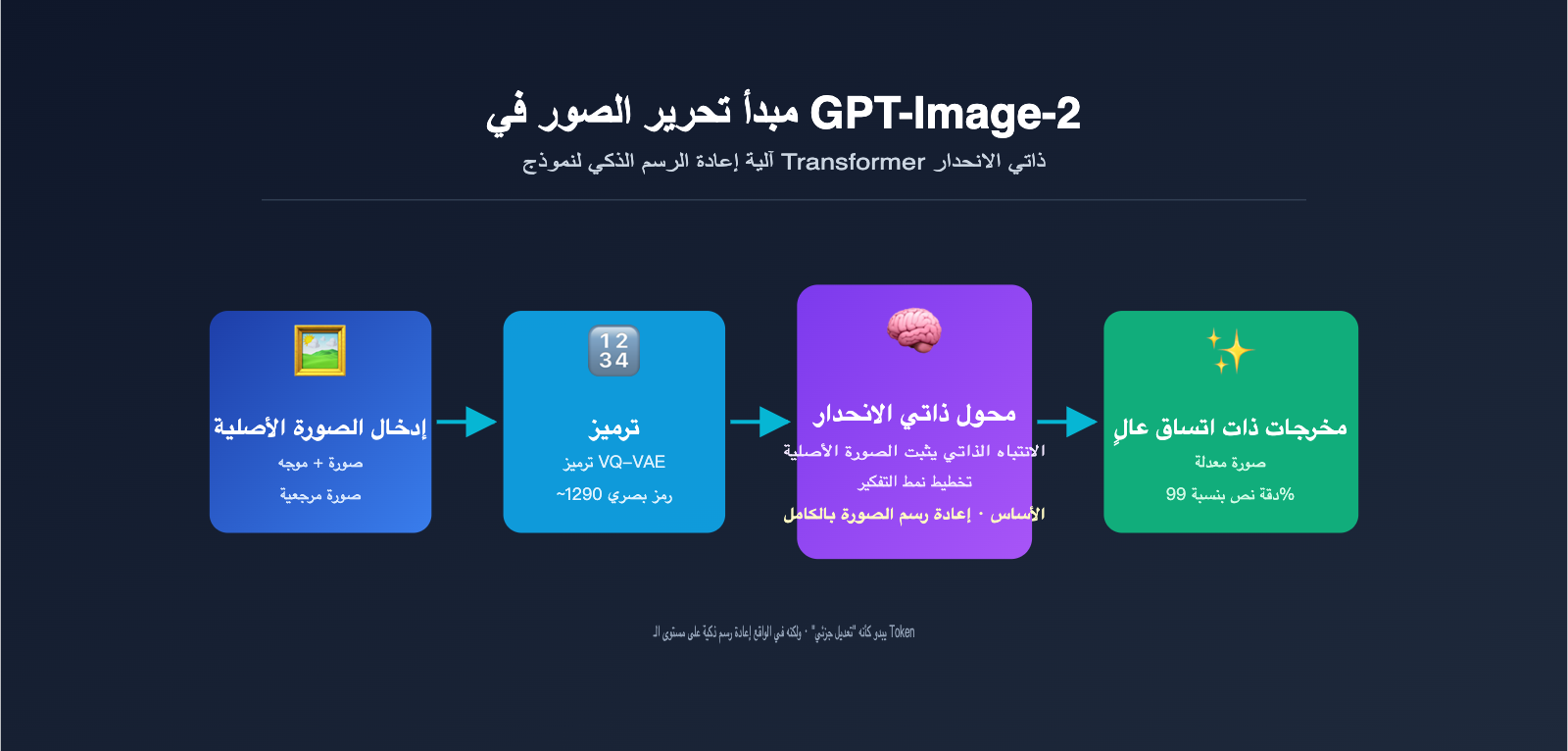
لفهم مبدأ عمل تحرير gpt-image-2 بشكل حقيقي، لا بد من التطرق إلى خيار معماري حاسم اتخذته OpenAI عند إطلاق هذا النموذج في 21 أبريل 2026: وهو التخلي عن نماذج الانتشار (Diffusion Models) المستخدمة في سلسلة DALL-E، والتحول إلى استخدام "محول التنبؤ الذاتي" (Autoregressive Transformer). هذا القرار مستوحى مباشرة من البنية متعددة الوسائط لنموذج GPT-4o.
يعتمد التوليد بالتنبؤ الذاتي في جوهره على نفس آلية كتابة النصوص في ChatGPT، وهي التنبؤ بالـ token التالي. الفرق يكمن في أن الـ "token" هنا ليس نصاً، بل token بصري. يقوم النموذج بالآتي:
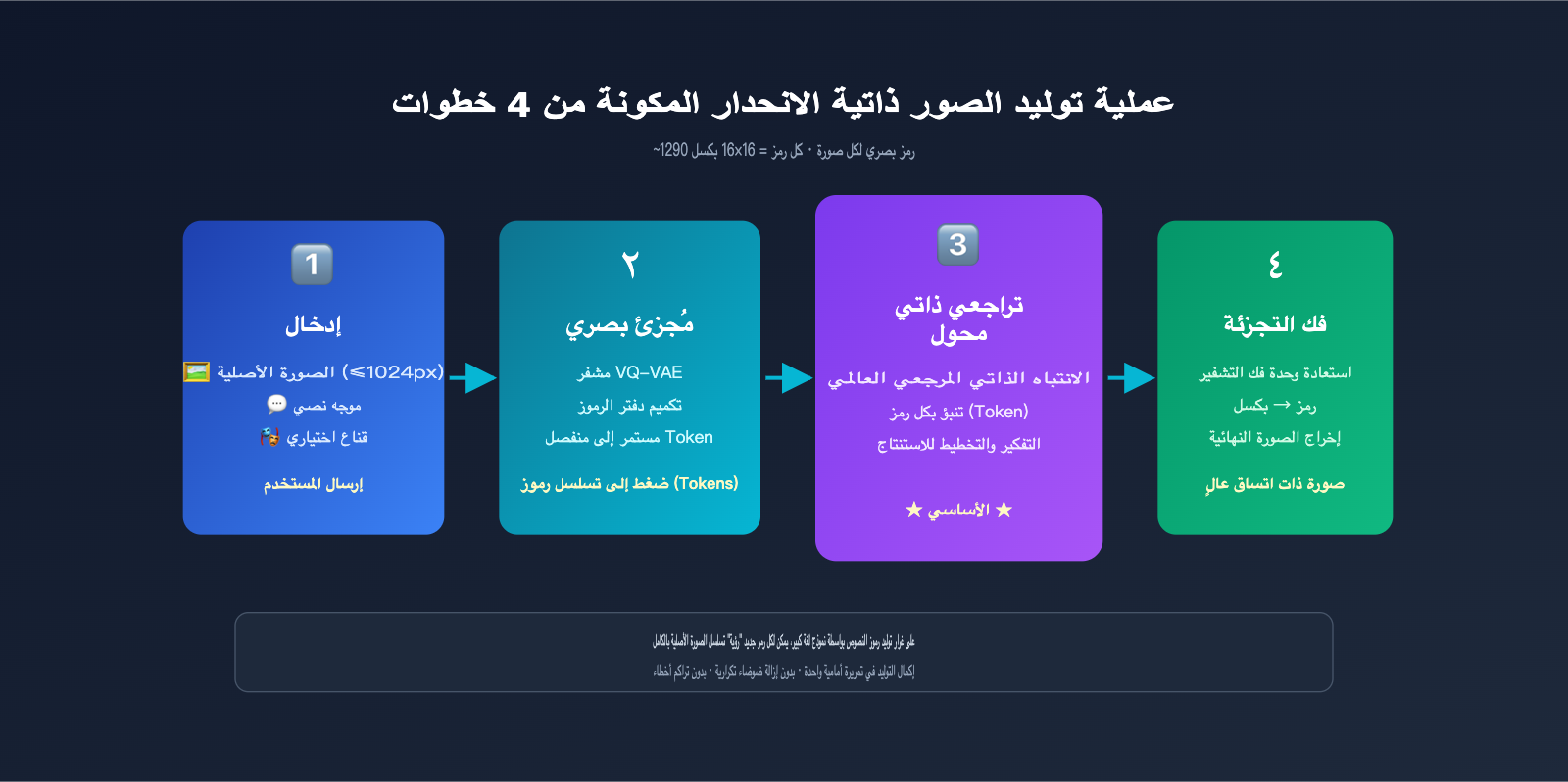
- تحويل الصورة إلى tokens: من خلال آلية تكميم مشابهة لـ VQ-VAE، يتم تقطيع الصورة إلى حوالي 1024-1290 token بصري، حيث يمثل كل token تقريباً كتلة بكسلات بحجم 8×8 أو 16×16.
- دمج التسلسل: يتم دمج الـ tokens الخاصة بموجه المستخدم النصي مع الـ tokens البصرية للصورة الأصلية في تسلسل طويل، ثم إرسالها إلى محول (Transformer) موحد.
- التوليد token تلو الآخر: يتنبأ النموذج بكل token بصري للصورة الناتجة واحداً تلو الآخر من اليسار إلى اليمين (أو وفق ترتيب المسح النقطي)، بحيث يمكن لكل token جديد يتم توليده "رؤية" جميع المدخلات السابقة والمحتوى الذي تم إنتاجه بالفعل.
- فك التشفير إلى بكسلات: بعد اكتمال توليد جميع الـ tokens البصرية، يتم تحويلها عبر وحدة فك التشفير إلى صورة بكسلات نهائية.
الرؤية الأساسية هنا هي: عندما يقوم GPT-Image-2 بتوليد صورة جديدة، تكون جميع الـ tokens الخاصة بالصورة الأصلية ضمن "مجال رؤيته". هذا يطابق تماماً مبدأ عمل ChatGPT عند إجراء محادثة، حيث يمكنه رؤية جميع الرسائل السابقة. تتيح آلية الانتباه الذاتي (Self-Attention) لكل token جديد يتم توليده "الرجوع" إلى ميزات أي جزء من الصورة الأصلية.
كما قدمت OpenAI في GPT-Image-2 "نمط التفكير" (Thinking mode)، الذي يسمح للنموذج بإجراء استنتاج داخلي قبل البدء الفعلي في توليد الـ tokens البصرية؛ وذلك لترتيب الأفكار حول ما يريد المستخدم تغييره، وما هي الأجزاء التي يجب الاحتفاظ بها، وكيفية ترتيب التخطيط المكاني. هذا يعزز دقة تنفيذ أوامر التحرير المعقدة، ليصل إلى دقة نصية بنسبة 99% وتخطيط دقيق للأجسام المتعددة. إذا كنت بحاجة لاختبار هذه القدرات في بيئة الإنتاج، يمكنك الوصول إلى gpt-image-2 عبر خدمة APIYI (apiyi.com)، حيث توفر المنصة مواصفات واجهة متوافقة مع الرسمية وتتيح التبديل السهل بين نماذج متعددة.
مُرمز الصور (Visual Tokenizer): التوازن بين الضغط والحفاظ على المعلومات
يُعد مُرمز الصور (Visual Tokenizer) عنق الزجاجة الرئيسي لنظام توليد الصور بالتنبؤ الذاتي بأكمله. فهو يحتاج إلى الموازنة بين هدفين:
- نسبة ضغط عالية: كلما قل عدد الـ tokens، زادت سرعة معالجة المحول (Transformer) وانخفضت التكلفة.
- جودة إعادة بناء عالية: يجب أن تكون البكسلات الناتجة عن فك التشفير مطابقة قدر الإمكان للصورة الأصلية دون فقدان التفاصيل.
النهج السائد هو VQ-VAE (Vector Quantized Variational Autoencoder): حيث يتم استخدام مُشفر لضغط مناطق الصورة إلى متجه مستمر، ثم تعيينه إلى فهرس "كود" (Codebook) محدود هو الأقرب، وهذا الفهرس هو الـ token. عادة ما يتم ضغط الصور بدقة 1024×1024 إلى حوالي 1024 token، مما يعطي كثافة معلومات عالية جداً.
ونظراً لأن هذا الضغط بحد ذاته يؤدي إلى فقدان بعض البيانات، لا يمكن لأي أداة تحرير تعمل بالذكاء الاصطناعي "الحفاظ على قيم البكسلات بنسبة 100% في المناطق غير المعدلة". وهذا يقودنا إلى السؤال الرئيسي التالي: الاتساق.
بما أن GPT-Image-2 يقوم بإعادة رسم الصورة بالكامل، فكيف تتحقق اتساق الصور بالذكاء الاصطناعي؟ ولماذا لا تتغير ملامح وجهك أو لون بشرتك أو تسريحة شعرك لتصبح شخصاً آخر عند تعديل صورة شخصية؟ الإجابة تكمن في أربع طبقات:
الطبقة الأولى: التجريد العالي لرموز الرؤية (Visual Tokens). بعد تحويل وجه الإنسان إلى رموز (Tokenization)، تصبح سلسلة الرموز الناتجة مشفرة بالسمات الجوهرية لـ "هذا الشخص" — مثل شكل الوجه، ونسب الملامح، ودرجة لون البشرة. طالما تم الاحتفاظ بهذه "رموز الهوية" عند توليد الصورة الجديدة، فلن تتغير ملامح الشخص.
الطبقة الثانية: المرجع الشامل عبر آلية الانتباه الذاتي (Self-Attention). يقوم نموذج Transformer ذاتي الانحدار بحساب أوزان الانتباه لكل رمز جديد يتم توليده مقارنة بجميع الرموز المدخلة (بما في ذلك رموز الصورة الأصلية). إذا لم يحدد المستخدم تعديلاً لمنطقة معينة، يمنح النموذج وزناً أعلى لرموز تلك المنطقة في الصورة الأصلية، وهو ما يعني فعلياً "نسخ" الأصل.
الطبقة الثالثة: التحيز الاستقرائي لبيانات التدريب. استخدمت OpenAI كميات هائلة من بيانات "الصورة الأصلية – الصورة المعدلة" لتدريب GPT-Image-2، حيث تعلم النموذج قاعدة ضمنية: حاول الحفاظ على المناطق الأخرى دون تغيير ما لم يطلب الموجه (Prompt) خلاف ذلك. هذا التحيز يترسخ في أوزان النموذج ويعمل تلقائياً أثناء الاستدلال.
الطبقة الرابعة: التخطيط الصريح عبر نمط التفكير (Thinking Mode). يقوم GPT-Image-2 بإجراء عملية تفكير داخلي لتحديد "المناطق التي تحتاج إلى تغيير وتلك التي يجب الاحتفاظ بها" قبل البدء في التوليد، مما يعني أنه يضع لنفسه قائمة حماية قبل التنفيذ.
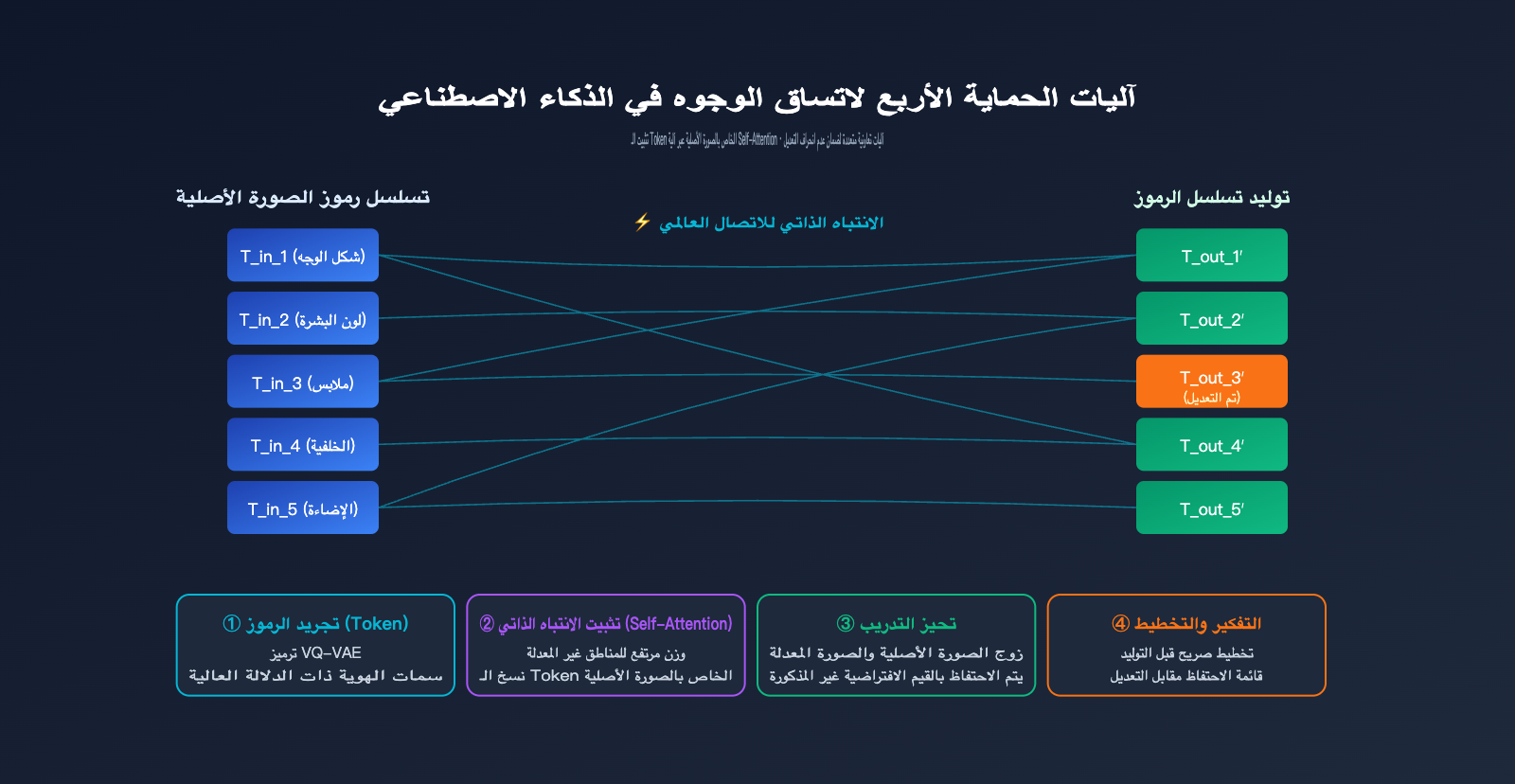
مقارنة طبقات الحماية لآلية الاتساق
| طبقة الآلية | نطاق التأثير | سيناريوهات الفشل |
|---|---|---|
| تجريد الرموز | سمات الهوية العالمية | المسافة البعيدة للوجه تؤدي لنقص الرموز |
| الانتباه الذاتي | تثبيت التفاصيل المحلية | تعارض الموجه مع دلالات الصورة الأصلية |
| تحيز التدريب | الاحتفاظ بالمناطق غير المذكورة افتراضياً | الموجه عدواني جداً |
| تخطيط التفكير | تعليمات التعديل المعقدة | تتطلب تجربة وتعديلاً متكرراً |
بعد فهم هذه الطبقات الأربع، ستتمكن من كتابة موجهات أكثر دقة لتجنب "الانحراف". على سبيل المثال، بدلاً من قول "أعد رسم ملابس هذا الشخص"، قل "حافظ على هوية الشخص كما هي، وقم فقط بتغيير لون الملابس من الأبيض إلى الأزرق". عند اختبار GPT-Image-2 على APIYI (apiyi.com)، وجدنا أن إضافة قيود صريحة مثل "حافظ على العناصر الأخرى دون تغيير" تجعل نمط التفكير يعمل بشكل أكثر فعالية.
وضع القناع (Mask Mode): جعل إعادة الرسم "يتظاهر" بأنه تعديل جزئي
إذا أراد المستخدم تجربة "تعديل جزئي" أكثر تأكيداً، يوفر GPT-Image-2 معلمة mask لنقطة النهاية /v1/images/edits. يمكن للمستخدم إدخال صورة قناع ثنائية: المناطق البيضاء تسمح للذكاء الاصطناعي بالتوليد، بينما يجب الاحتفاظ بالمناطق السوداء كما هي في الصورة الأصلية.
لكن تجدر الإشارة إلى أن وضع القناع لا يغير جوهر إعادة الرسم. دوره هو إضافة قيد صارم عند توليد الرموز: يجب أن تكون الرموز المقابلة للمناطق السوداء مطابقة تماماً لرموز الصورة الأصلية. هذا نوع من "التوليد المقيد" ضمن إطار التوليد ذاتي الانحدار، وليس مجرد تغطية بكسلات كما في برنامج فوتوشوب.
لفهم مزايا نموذج GPT-Image-2 بشكل كامل، نحتاج إلى إجراء مقارنة منهجية بينه وبين الجيل السابق من نماذج الانتشار (مثل Stable Diffusion وDALL-E 3 وMidjourney). هناك فرق جوهري بين النظامين في مبدأ تحرير الصور بالذكاء الاصطناعي.
سير عمل نماذج الانتشار (Diffusion Models): يبدأ من صورة ضوضاء عشوائية (Noise)، ويمر بعشرات الخطوات من التكرار لإزالة الضوضاء، لتظهر الصورة النهائية تدريجيًا. عند التحرير، يقوم النموذج بضغط الصورة الأصلية إلى مساحة كامنة (Latent Space)، ثم يضيف جزءًا من الضوضاء إلى هذه المساحة، ويستخدم "الموجه" (Prompt) لتوجيه عملية إزالة الضوضاء، وأخيرًا يقوم بفك التشفير للعودة إلى البكسلات. في وضع التحرير الجزئي (Inpainting)، يتم إعادة ضبط المساحة الكامنة خارج القناع (Mask) لتطابق الصورة الأصلية في كل خطوة، مما يؤدي إلى "تثبيت" المناطق غير المعدلة.
سير عمل النماذج ذاتية الانحدار (Autoregressive Models): يختلف تمامًا؛ حيث يتم ترميز الصورة إلى رموز (Tokens)، ثم التنبؤ بالمخرجات رمزًا تلو الآخر تمامًا كما نكتب نصًا. لا توجد عملية تكرار لإزالة الضوضاء، ولا توجد ضوضاء في المساحة الكامنة، بل يتم التوليد في تمريرة واحدة.

تختلف هاتان الطريقتان بشكل كبير في سيناريوهات تحرير الصور، كما هو موضح في الجدول التالي:
| وجه المقارنة | نماذج الانتشار (SD/DALL-E 3) | النماذج ذاتية الانحدار (GPT-Image-2/Nano Banana) |
|---|---|---|
| طريقة التوليد | تكرار إزالة الضوضاء متعدد الخطوات | التنبؤ بسلسلة الرموز (Tokens) في خطوة واحدة |
| تنفيذ القناع (Mask) | إعادة ضبط المساحة الكامنة غير المقنعة في كل خطوة | قيود صارمة على مستوى الرموز |
| معالجة الحدود | سهولة ظهور تشوهات في دمج المساحة الكامنة | انتقال طبيعي (على المستوى الدلالي) |
| عرض النصوص | غالبًا ما يفشل | دقة تصل إلى 99% تقريبًا |
| التحرير متعدد الجولات | تراكم خسائر إعادة الترميز | لا يوجد انحراف تقريبًا |
| الأوامر المعقدة | صعوبة في التخطيط الدقيق | دعم تخطيط أكثر من 100 عنصر |
| السرعة | عادة 10-30 ثانية | أسرع من نماذج الانتشار بنحو 60% |
| عرض النصوص الطويلة | صعب | يدعم أي لغة أو نص |
تكمن المشكلة الأساسية في نماذج الانتشار في خسائر إعادة الترميز (Re-encoding loss) الناتجة عن VAE؛ فحتى لو تم تثبيت المناطق غير المقنعة نظريًا، فإن التحويل ذهابًا وإيابًا بين المساحة الكامنة والبكسلات يؤدي إلى فروق لونية طفيفة. بعد عدة عمليات تحرير، تتراكم هذه الخسائر لتصبح تشوهات مرئية. وقد تجاوز نموذج GPT-Image-2 هذه المشكلة باستخدام البنية ذاتية الانحدار، حيث تتم عملية فك تشفير الرموز مرة واحدة فقط.
لكن النماذج ذاتية الانحدار لها ثمن أيضًا، حيث أن تكلفة التوليد أعلى، ويرجع ذلك أساسًا إلى العدد الكبير من الرموز والحاجة إلى تمرير كامل عبر Transformer لكل رمز. نوصي باستخدام GPT-Image-2 (الذي يمكن الوصول إليه عبر APIYI apiyi.com) للسيناريوهات التي تتطلب اتساقًا فائقًا وعرضًا دقيقًا للنصوص، بينما يمكن الاحتفاظ بسلسلة Stable Diffusion كخيار إضافي للسيناريوهات الحساسة للتكلفة وعالية التزامن.
تطبيق عملي لمبادئ تحرير الصور باستخدام GPT-Image-2: استدعاء API وتحسين الاتساق
بعد فهم مبادئ تحرير الصور في GPT-Image-2، دعنا نرى كيف يمكننا الاستفادة من هذه الآلية بشكل فعال. فيما يلي مثال بسيط وقابل للتشغيل، يوضح كيفية استدعاء واجهة تحرير GPT-Image-2 عبر نقاط النهاية المتوافقة مع APIYI:
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
with open("portrait.png", "rb") as image_file:
response = client.images.edit(
model="gpt-image-2",
image=image_file,
prompt="حافظ على هوية الشخص والخلفية كما هي، وقم فقط بتغيير لون القميص من الأبيض إلى الأزرق الداكن",
size="1024x1024",
quality="high"
)
print(response.data[0].url)
لاحظ كيفية كتابة الموجه (prompt): وضح صراحةً ما يجب الاحتفاظ به وما يجب تعديله، فهذا يحفز نمط التفكير (Thinking) في GPT-Image-2 للتخطيط للعملية كما تتوقع. إذا كنت ترغب في إجراء تحرير دقيق لمنطقة معينة، يمكنك إضافة معامل القناع (mask):
response = client.images.edit(
model="gpt-image-2",
image=open("portrait.png", "rb"),
mask=open("mask.png", "rb"),
prompt="تغيير القميص الأبيض إلى بدلة زرقاء داكنة",
size="1024x1024"
)
القناع (mask) هو ملف PNG بنفس الأبعاد، حيث تمثل المناطق البيضاء النطاق المسموح بتعديله، بينما تجبر المناطق السوداء النموذج على الاحتفاظ بـ token الصورة الأصلية.
5 نصائح عملية لتحسين الاتساق
بناءً على اختباراتنا الواقعية لـ اتساق صور الذكاء الاصطناعي، نلخص 5 نصائح:
- حدد بوضوح "ما يجب الاحتفاظ به" في الموجه: لا تكتفِ بقول "غيّر X"، بل قل "حافظ على Y كما هو، وغيّر X".
- استخدم دقة مناسبة للصورة المرجعية: توصي OpenAI بأن لا يتجاوز الضلع الأطول للصورة المرجعية 1024 بكسل؛ فالحجم الأكبر قد يشتت انتباه الـ token.
- استخدم صورة أساسية واحدة للجولات المتعددة: لا تجعل نتيجة التعديل السابق مدخلاً للجولة التالية، بل اعتمد دائماً على الصورة الأصلية لإجراء تعديلات بأبعاد مختلفة، ثم ادمج الموجهات في النهاية.
- قسّم التعليمات في المشاهد المعقدة: قسّم طلب "تغيير الشخص إلى نمط ياباني بخلفية غروب" إلى خطوتين، بحيث تتعامل كل خطوة مع متغير واحد فقط.
- اختر جودة high: الجودة المنخفضة تقلل من عدد الـ token، مما يضعف الاتساق بشكل مباشر.
الموازنة بين السعر والاتساق في GPT-Image-2
| تركيبة المعاملات | تكلفة الصورة الواحدة | سيناريو الاستخدام |
|---|---|---|
| 1024×1024 low | $0.006 | مسودات إبداعية / معاينة سريعة |
| 1024×1024 medium | $0.053 | صور وسائل التواصل الاجتماعي |
| 1024×1024 high | $0.211 | تحرير تجاري / تكرار مستمر |
| 4K high | $0.50+ | طباعة / عرض عالي الدقة |
التكلفة والاتساق مرتبطان طردياً؛ فنمط الجودة العالية يخصص المزيد من الـ token للنموذج، مما يسمح له بالحفاظ على المزيد من خصائص الصورة الأصلية. ننصح باستخدام نمط high في بيئات الإنتاج، ويمكنك تقليل التكلفة بنسبة 50% إضافية عبر استخدام Batch API في منصة APIYI (apiyi.com).
الأسئلة الشائعة حول مبادئ تحرير الصور والاتجاهات المستقبلية
س1: هل GPT-Image-2 يقوم بتعديل جزئي مثل فوتوشوب أم إعادة رسم؟
ج: هو يقوم بإعادة الرسم. تحتاج جميع نماذج الصور ذاتية الانحدار (Autoregressive) إلى ترميز الصورة الأصلية إلى token، ثم إنشاء تسلسل كامل من الـ token الناتجة، وأخيراً فك تشفيرها إلى صورة جديدة. حتى عند تفعيل القناع (mask)، فإنه يضيف قيوداً أثناء عملية إعادة الرسم، وليس مجرد تغطية بكسلات جزئية.
س2: بما أنه إعادة رسم، لماذا تبدو الصورة المعدلة متطابقة تقريباً؟
ج: يعتمد ذلك على آليات الاتساق الأربع: التجريد الميزي لـ token البصرية، المرجعية العالمية للصورة الأصلية عبر Self-Attention، التحيز الاستقرائي لبيانات التدريب، والتخطيط الصريح لنمط التفكير (Thinking). هذه الآليات تجعل الذكاء الاصطناعي "يختار طوعاً" الاحتفاظ بالمناطق غير المذكورة.
س3: هل يعتبر الـ inpainting في نماذج الانتشار (Diffusion) تعديلاً جزئياً حقيقياً؟
ج: لا. حتى في نماذج الانتشار، يجب تمرير المناطق غير المقنعة عبر VAE (ترميز وفك ترميز)، مما يؤدي إلى فقدان طفيف في البيانات. التعديلات المتعددة تؤدي إلى تراكم تشوهات مرئية، وهذا هو الدافع الأساسي لتحول GPT-Image-2 إلى البنية ذاتية الانحدار. يمكنك المقارنة بين النموذجين عبر APIYI (apiyi.com).
س4: لماذا لا يعاني GPT-Image-2 من الانجراف (Drift) في التعديلات المتعددة؟
ج: لأن البنية ذاتية الانحدار تشير إلى تسلسل الـ token الكامل للصورة الأصلية في كل عملية توليد، دون وجود أخطاء تراكمية ناتجة عن إزالة الضجيج التكراري. ومع التخطيط الصريح لنمط التفكير، فإن استقرار التعديلات المتعددة يتفوق بكثير على نماذج الانتشار.
س5: هل يجب أن أستخدم القناع (mask) أم التعديل بالموجّه فقط؟
ج: استخدم الموجه + تعليمات الاحتفاظ الواضحة أولاً، فهذا يستغل التخطيط التلقائي لنمط التفكير. استخدم القناع فقط عندما تكون حدود المنطقة المراد تعديلها واضحة ويجب أن تكون دقيقة للغاية (مثل أجزاء معينة من الوجه).
س6: كيف سيتطور تحرير الصور بالذكاء الاصطناعي مستقبلاً؟
ج: هناك ثلاثة اتجاهات: (1) تحسين كثافة معلومات الـ Tokenizer لتقليل التكلفة؛ (2) توحيد الوسائط المتعددة، حيث تتشارك النصوص والصور والفيديو في نفس المحول (Transformer)؛ (3) تعزيز قدرات التفكير (Thinking) لدعم سلاسل تعديل أطول. ننصح بمتابعة التحديثات على APIYI (apiyi.com) لتقييم مسارات الترقية فور توفرها.
الخلاصة: فهم المبادئ هو مفتاح استخدام الأدوات بفعالية
لقد قلبت نماذج الصور ذاتية الانحدار مثل GPT-Image-2 حدسنا حول "تحرير الصور بالذكاء الاصطناعي". فهي ليست تعديلاً جزئياً بأسلوب فوتوشوب، بل إعادة رسم ذكية تعتمد على توليد الصور ذاتي الانحدار. يأتي الاتساق من تعاون أربع آليات: التجريد الدلالي للـ token، التثبيت العالمي عبر Self-Attention، تحيز التدريب، ونمط التفكير.
من خلال فهم هذه المبادئ، ستتمكن من كتابة موجهات تحفز التخطيط الذكي، وتجنب فخاخ التعديلات المتعددة، وإيجاد التوازن بين التكلفة والجودة. ننصحك بإجراء اختبارات عملية عبر منصة APIYI (apiyi.com)، التي تدعم واجهات موحدة لنماذج متنوعة مثل GPT-Image-2 وNano Banana وStable Diffusion، لتسهيل التحقق من كل ما ورد في هذا المقال.
هذا المقال من إعداد فريق APIYI، استناداً إلى البيانات الرسمية من OpenAI وGoogle DeepMind والاختبارات الميدانية. للحصول على وثائق الربط البرمجي لاستخدام gpt-image-2 في بيئة الإنتاج، تفضل بزيارة موقعنا: apiyi.com.