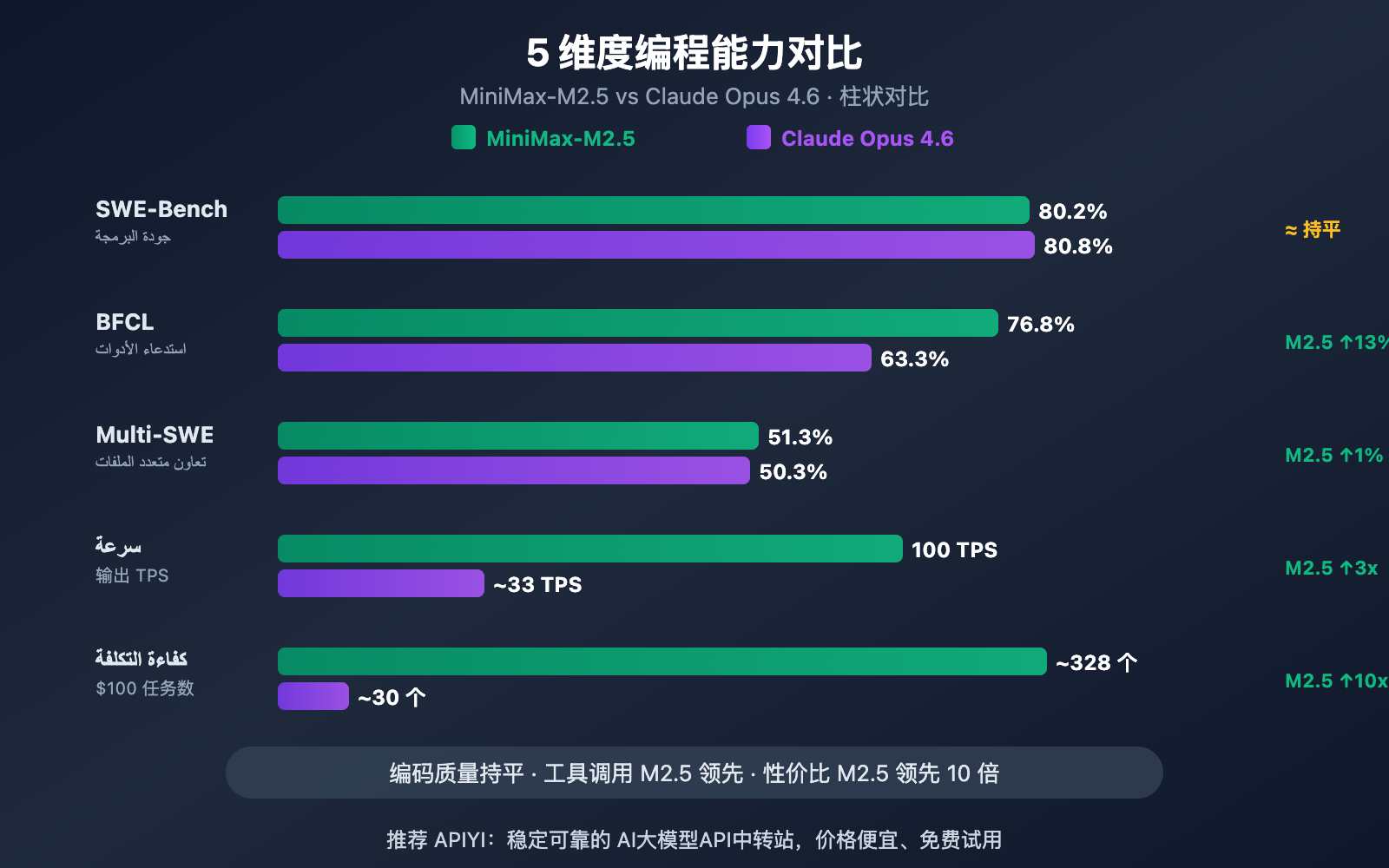
作者注:从 SWE-Bench、Multi-SWE-Bench、BFCL 工具调用、编码速度和价格 5 个维度深度对比 MiniMax-M2.5 和 Claude Opus 4.6 的编程能力差异
选择 AI 编程助手一直是开发者关注的核心问题。本文从 5 个关键维度对比 MiniMax-M2.5 和 Claude Opus 4.6 的编程能力,帮助你在性能和成本之间做出最优选择。
核心价值: 看完本文,你将清楚了解这两个模型在真实编码场景中的能力边界,明确在什么场景下选择谁更划算。

MiniMax-M2.5 与 Claude Opus 4.6 编程能力核心差异
| 对比维度 | MiniMax-M2.5 | Claude Opus 4.6 | 差距分析 |
|---|---|---|---|
| SWE-Bench Verified | 80.2% | 80.8% | Opus 仅领先 0.6% |
| Multi-SWE-Bench | 51.3% | 50.3% | M2.5 反超 1.0% |
| BFCL 工具调用 | 76.8% | 63.3% | M2.5 领先 13.5% |
| 输出速度 | 50-100 TPS | ~33 TPS | M2.5 最高快 3 倍 |
| 输出价格 | $1.20/M tokens | $25/M tokens | M2.5 便宜约 20 倍 |
MiniMax-M2.5 对比 Opus 4.6 编码基准解读
从 SWE-Bench Verified 这个最受行业认可的编码基准来看,两者差距极小——MiniMax-M2.5 的 80.2% 仅落后 Claude Opus 4.6 的 80.8% 共 0.6 个百分点。SWE-Bench Verified 测试的是模型在真实 GitHub Pull Request 中修复 Bug 和实现功能的能力,这是最接近真实开发场景的评测。
更值得关注的是 Multi-SWE-Bench 这个多文件复杂项目基准:MiniMax-M2.5 以 51.3% 的得分反超 Opus 4.6 的 50.3%。这意味着在处理需要跨多个文件协调修改的复杂工程任务时,M2.5 表现更稳定。
MiniMax 官方数据显示,M2.5 在公司内部已有 80% 的新提交代码由 M2.5 生成,30% 的日常任务由 M2.5 完成,这从实际应用层面验证了其编码能力。
MiniMax-M2.5 与 Opus 4.6 在工具调用上的差距
两个模型在编程领域最大的能力分野出现在工具调用上。BFCL Multi-Turn 基准测试中,MiniMax-M2.5 得分 76.8%,而 Claude Opus 4.6 为 63.3%,差距高达 13.5 个百分点。
这项差距在智能体编程场景中影响巨大——当模型需要读取文件、执行命令、调用 API、解析输出并循环迭代时,工具调用能力直接决定了任务完成的效率和准确性。M2.5 完成同类任务的工具调用轮次比前代 M2.1 减少了 20%,每次调用都更精准。
不过,Claude Opus 4.6 在 MCP Atlas(大规模工具协调)中达到 62.7% 的行业领先水平,在需要同时协调大量工具的超复杂场景下仍有优势。
مقارنة MiniMax-M2.5 مقابل Opus 4.6 في سرعة وكفاءة البرمجة
لا تقتصر البرمجة على الدقة فحسب، بل تعد السرعة والكفاءة أمرين حيويين أيضاً. خاصة في سيناريوهات برمجة الوكلاء الذكيين (Agents)، حيث يحتاج النموذج إلى عدة جولات من التكرار لإكمال المهام، وتؤثر السرعة بشكل مباشر على تجربة التطوير والتكلفة الإجمالية.
| مؤشر الكفاءة | MiniMax-M2.5 | Claude Opus 4.6 | الطرف المتفوق |
|---|---|---|---|
| سرعة الإخراج (الإصدار القياسي) | ~50 TPS | ~33 TPS | M2.5 أسرع بـ 1.5 مرة |
| سرعة الإخراج (Lightning) | ~100 TPS | ~33 TPS | M2.5 أسرع بـ 3 مرات |
| الوقت المستغرق لمهمة SWE-Bench | 22.8 دقيقة | 22.9 دقيقة | متساويان تقريباً |
| التكلفة لمهمة SWE-Bench | ~$0.15 | ~$3.00 | M2.5 أرخص بـ 20 مرة |
| متوسط استهلاك التوكنز/المهمة | 3.52M tokens | أعلى | M2.5 أكثر توفيراً للتوكنز |
| تحسين جولات استدعاء الأدوات | أقل بنسبة 20% من M2.1 | — | M2.5 أكثر كفاءة |
تحليل ميزة سرعة البرمجة في MiniMax-M2.5
بلغ متوسط الوقت المستغرق للمهمة الواحدة في تقييم SWE-Bench Verified لنموذج MiniMax-M2.5 حوالي 22.8 دقيقة، وهو ما يتماشى تماماً مع 22.9 دقيقة لنموذج Claude Opus 4.6. لكن هيكل التكلفة وراء ذلك مختلف تماماً.
تبلغ تكلفة إكمال مهمة واحدة في SWE-Bench باستخدام M2.5 حوالي 0.15 دولار، بينما تبلغ في Opus 4.6 حوالي 3.00 دولارات؛ وهذا يعني أنه بنفس جودة البرمجة، تبلغ تكلفة M2.5 فقط 1/20 من تكلفة Opus. بالنسبة للفرق التي تحتاج إلى تشغيل وكلاء البرمجة باستمرار، ستتضخم هذه الفجوة لتصل إلى توفير آلاف أو حتى عشرات الآلاف من الدولارات شهرياً.
تأتي الكفاءة العالية لـ MiniMax-M2.5 من بنية MoE (إجمالي 230 مليار معلمة مع تنشيط 10 مليارات فقط) وتحسين تفكيك المهام الذي يوفره إطار تدريب Forge RL. عند البرمجة، يقوم النموذج أولاً بـ "Spec-writing" (كتابة المواصفات) – أي تصميم المعمارية وتفكيك المهام، ثم التنفيذ بكفاءة بدلاً من التجربة والخطأ العشوائي.
المزايا الفريدة لقدرات البرمجة في Claude Opus 4.6
على الرغم من عدم تفوقه في كفاءة التكلفة، إلا أن Claude Opus 4.6 يتمتع بمزايا لا يمكن استبدالها:
- Terminal-Bench 2.0: حقق 65.4%، وهو أداء رائد في الصناعة لمهام البرمجة المعقدة في بيئات الطرفية (Terminal).
- OSWorld: حقق 72.7%، حيث تتفوق قدرات تشغيل الكمبيوتر بواسطة الوكيل الذكي بمراحل على المنافسين.
- MCP Atlas: حقق 62.7%، ليحتل المرتبة الأولى في الصناعة في القدرة على تنسيق الأدوات على نطاق واسع.
- نافذة سياق 1 مليون توكن: يدعم إصدار Beta سياقاً يصل إلى مليون توكن، مما يلغي الحاجة إلى تقسيم الكود عند التعامل مع قواعد الكود الضخمة جداً.
- التفكير التكيفي (Adaptive Thinking): يدعم 4 مستويات من قوة التفكير (منخفض/متوسط/عالي/أقصى)، مما يسمح بتعديل عمق الاستنتاج حسب الحاجة.
في المهام التي تتطلب استنتاجاً عميقاً، أو فهم سياق كود طويل جداً، أو مهام معقدة للغاية على مستوى النظام، لا يزال Opus 4.6 هو الخيار الأقوى حالياً.
🎯 نصيحة الاختيار: لكل نموذج نقاط قوته، وننصح بإجراء اختبارات عملية عبر منصة APIYI (apiyi.com). تدعم المنصة كلاً من MiniMax-M2.5 وClaude Opus 4.6 بواجهة برمجية موحدة، حيث يمكنك التحقق بسرعة بمجرد تغيير معلمة
model.
MiniMax-M2.5 مقابل Opus 4.6: توصيات سيناريوهات البرمجة
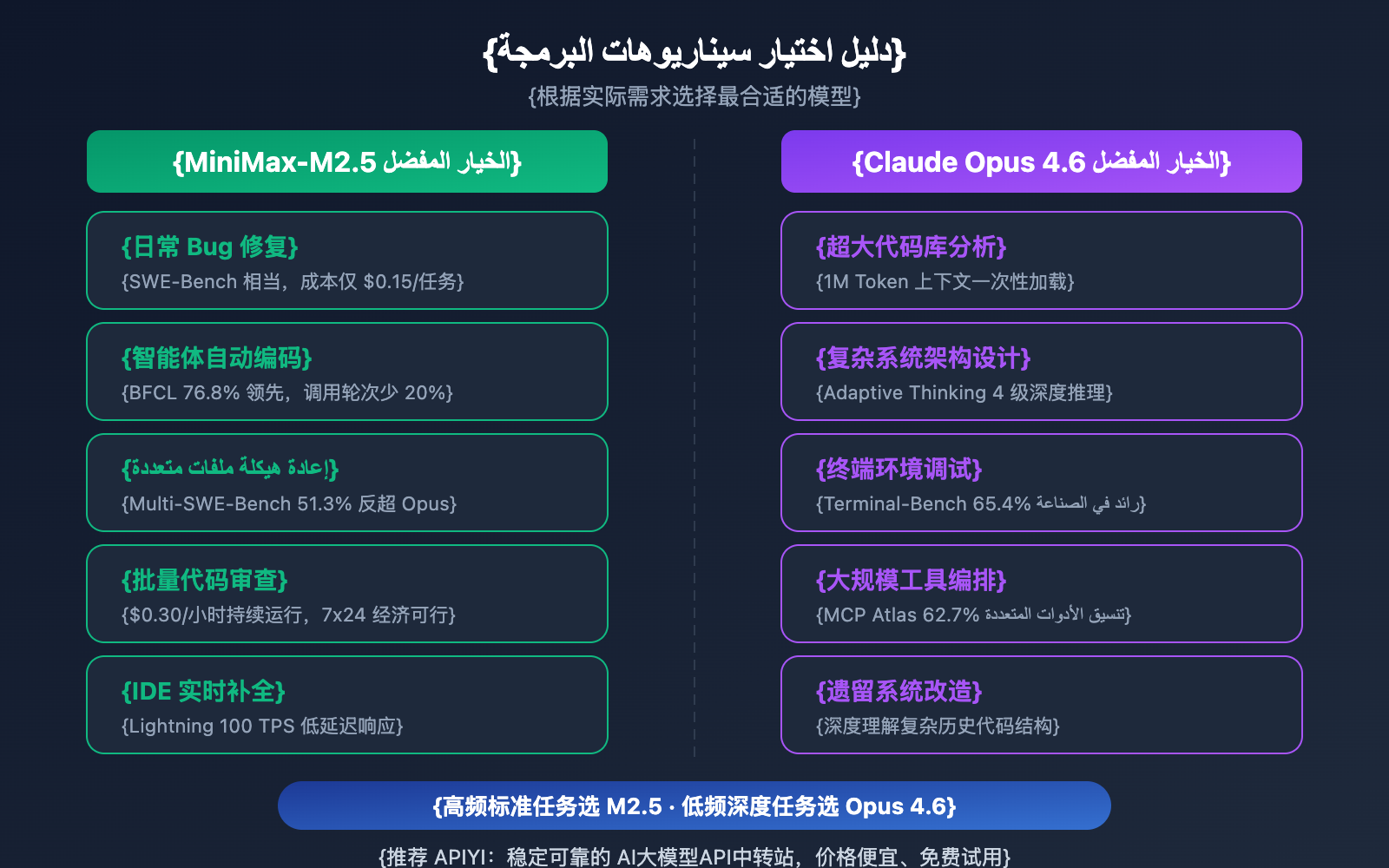
| سيناريو البرمجة | النموذج الموصى به | سبب التوصية |
|---|---|---|
| إصلاح الأخطاء اليومية | MiniMax-M2.5 | أداء SWE-Bench متقارب، وتكلفة أقل بـ 20 مرة |
| إعادة هيكلة ملفات متعددة | MiniMax-M2.5 | متفوق في Multi-SWE-Bench بنسبة 1% |
| البرمجة الآلية للوكلاء | MiniMax-M2.5 | متفوق في BFCL بنسبة 13.5%، وتكلفة 0.15$ للمهمة |
| مراجعة الكود الجماعية | MiniMax-M2.5 | إنتاجية عالية وتكلفة منخفضة، 0.30$/ساعة للإصدار القياسي |
| إكمال الكود الفوري في IDE | MiniMax-M2.5 Lightning | سرعة 100 TPS وزمن وصول منخفض |
| تحليل قواعد الكود الضخمة | Claude Opus 4.6 | نافذة سياق بحجم 1 مليون توكن |
| تصميم معمارية الأنظمة المعقدة | Claude Opus 4.6 | استنتاج عميق عبر التفكير التكيفي (Adaptive Thinking) |
| عمليات بيئة الطرفية المعقدة | Claude Opus 4.6 | متفوق في Terminal-Bench بنسبة 65.4% |
| تنسيق الأدوات واسع النطاق | Claude Opus 4.6 | متفوق في MCP Atlas بنسبة 62.7% |
أفضل سيناريوهات البرمجة لـ MiniMax-M2.5
تتركز مزايا MiniMax-M2.5 في مهام البرمجة "عالية التكرار، والمعيارية، والحساسة للتكلفة":
- الإصلاح التلقائي في CI/CD: تشغيل وكلاء مراقبة وإصلاح مستمرين في خطوط الأنابيب، حيث تجعل تكلفة 0.30$/ساعة التشغيل على مدار الساعة طوال أيام الأسبوع مجدياً اقتصادياً.
- بوت مراجعة طلبات السحب (PR Review Bot): مراجعة طلبات السحب تلقائياً، حيث تضمن نسبة 76.8% في BFCL دقة التفاعل مع الأدوات في جولات متعددة.
- تطوير الويب والتطبيقات متعدد اللغات: يدعم أكثر من 10 لغات برمجة (Python، Go، Rust، TypeScript، Java وغيرها)، ويغطي منصات Web/Android/iOS/Windows.
- هجرة الكود الجماعية: الاستفادة من قدرة التعاون بين الملفات المتعددة بنسبة 51.3% في Multi-SWE-Bench للتعامل مع عمليات إعادة الهيكلة واسعة النطاق.
أفضل سيناريوهات البرمجة لـ Claude Opus 4.6
تتركز مزايا Claude Opus 4.6 في مهام البرمجة "منخفضة التكرار، وعالية التعقيد، والعميقة في الاستنتاج":
- المساعدة في قرارات المعمارية: استخدام التفكير التكيفي (وضع max) لإجراء تحليل عميق للحلول التقنية.
- تطوير الأنظمة القديمة (Legacy Systems): تحميل قاعدة كود ضخمة بالكامل مرة واحدة بفضل نافذة سياق 1 مليون توكن.
- تصحيح الأخطاء على مستوى النظام: استخدام Terminal-Bench بنسبة 65.4% لتحديد وحل المشكلات المعقدة في بيئة الطرفية.
- منصات تنسيق الأدوات المتعددة: استخدام MCP Atlas بنسبة 62.7% لتنسيق العمل المشترك بين IDE، Git، CI/CD، والمراقبة وغيرها من الأدوات.
ملاحظة المقارنة: التوصيات المذكورة أعلاه مبنية على بيانات الاختبارات المعيارية وردود فعل المطورين الفعليين. قد تختلف النتائج الفعلية باختلاف المشاريع، لذا ننصح بالتحقق من السيناريوهات الفعلية عبر APIYI (apiyi.com).
مقارنة شاملة لتكاليف البرمجة بين MiniMax-M2.5 و Opus 4.6
بالنسبة لفرق التطوير، تعد التكلفة طويلة الأجل لمساعدي البرمجة المعتمدين على الذكاء الاصطناعي عاملاً حاسماً في اتخاذ القرار.
| سيناريو التكلفة | MiniMax-M2.5 (الإصدار القياسي) | MiniMax-M2.5 Lightning | Claude Opus 4.6 |
|---|---|---|---|
| سعر الإدخال / مليون رمز (tokens) | $0.15 | $0.30 | $5.00 |
| سعر الإخراج / مليون رمز (tokens) | $1.20 | $2.40 | $25.00 |
| مهمة SWE-Bench واحدة | ~$0.15 | ~$0.30 | ~$3.00 |
| تشغيل مستمر لمدة ساعة واحدة | $0.30 | $1.00 | ~$30+ |
| تشغيل على مدار الساعة شهرياً | ~$216 | ~$720 | ~$21,600+ |
| عدد المهام المنجزة بميزانية 100 دولار | ~328 مهمة | ~164 مهمة | ~30 مهمة |
لنأخذ فريق تطوير متوسط الحجم كمثال: إذا كان الفريق يحتاج إلى معالجة 50 مهمة برمجية يومياً (إصلاح الأخطاء، مراجعة الكود، تنفيذ الميزات)، فإن التكلفة الشهرية باستخدام إصدار MiniMax-M2.5 القياسي ستبلغ حوالي 225 دولاراً، وإصدار Lightning حوالي 450 دولاراً، بينما سيتطلب Claude Opus 4.6 حوالي 4,500 دولار. جودة إنجاز المهام في النماذج الثلاثة متساوية تقريباً على مستوى SWE-Bench.
🎯 نصيحة بشأن التكلفة: بالنسبة لمعظم مهام البرمجة القياسية، تتفوق MiniMax-M2.5 بوضوح من حيث القيمة مقابل السعر. ننصح بإجراء اختبارات عملية عبر منصة APIYI (apiyi.com) قبل الاختيار، حيث تدعم المنصة التبديل المرن بين النماذج دون الحاجة لتغيير هيكلية الكود. كما يمكنك الاستفادة من أسعار أفضل عند المشاركة في عروض الشحن.
الوصول السريع للبرمجة: مقارنة بين MiniMax-M2.5 و Opus 4.6
يوضح الكود التالي كيفية التبديل السريع بين النموذجين للمقارنة عبر واجهة موحدة:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# اختبار MiniMax-M2.5
m25_response = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": "用 Go 实现一个并发安全的 LRU 缓存"}]
)
# اختبار Claude Opus 4.6 - فقط قم بتغيير معامل model
opus_response = client.chat.completions.create(
model="claude-opus-4-6-20250205",
messages=[{"role": "user", "content": "用 Go 实现一个并发安全的 LRU 缓存"}]
)
عرض كود اختبار المقارنة الكامل
from openai import OpenAI
import time
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model_name: str, prompt: str) -> dict:
"""
اختبار قدرة البرمجة لنموذج واحد
Args:
model_name: معرف النموذج
prompt: موجه مهمة البرمجة
Returns:
قاموس يحتوي على محتوى الاستجابة والوقت المستغرق
"""
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": "أنت مهندس برمجيات خبير"},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
elapsed = time.time() - start
return {
"model": model_name,
"content": response.choices[0].message.content,
"tokens": response.usage.completion_tokens,
"time": round(elapsed, 2)
}
# مهمة البرمجة
task = "أعد صياغة (Refactor) الدالة التالية لتدعم أمان التزامن، والتحكم في المهلة، والتراجع التدريجي (Graceful Degradation)"
# اختبار المقارنة
models = ["MiniMax-M2.5", "MiniMax-M2.5-Lightning", "claude-opus-4-6-20250205"]
for m in models:
result = benchmark_model(m, task)
print(f"[{result['model']}] {result['tokens']} tokens in {result['time']}s")
نصيحة: من خلال مفتاح API واحد من APIYI (apiyi.com)، يمكنك الوصول إلى كل من MiniMax-M2.5 و Claude Opus 4.6 في وقت واحد، لمقارنة الفرق في الأداء بينهما بسرعة في سيناريوهات البرمجة الفعلية الخاصة بك.
الأسئلة الشائعة
س1: هل يمكن لـ MiniMax-M2.5 استبدال Claude Opus 4.6 بالكامل في البرمجة؟
لا يمكن استبداله بالكامل، ولكن يمكنه ذلك في معظم السيناريوهات. الفجوة في SWE-Bench هي 0.6% فقط، بل ويتفوق M2.5 بنسبة 1% في Multi-SWE-Bench. لا يوجد فرق تقريبًا في المهام القياسية مثل إصلاح الأخطاء (Bug fixes)، ومراجعة الكود، وتنفيذ الوظائف. ومع ذلك، لا يزال Opus 4.6 يتفوق في تحليل قواعد البيانات البرمجية الضخمة (التي تتطلب سياق 1M) وتصحيح الأخطاء المعقدة على مستوى النظام (Terminal-Bench). نوصي بالاستخدام المختلط حسب السيناريو الفعلي.
س2: لماذا درجة BFCL لـ M2.5 أعلى بكثير من Opus 4.6، بينما درجات البرمجة متقاربة؟
يختبر BFCL القدرة على استدعاء الأدوات لعدة جولات (Function Calling)، بينما يختبر SWE-Bench قدرات البرمجة الشاملة (End-to-end). على الرغم من أن استدعاء الأدوات في جولة واحدة لدى Opus 4.6 ليس بدقة M2.5، إلا أن قدراته القوية في التفكير العميق تعوض نقص كفاءة استدعاء الأدوات، مما يحافظ في النهاية على جودة برمجة إجمالية متقاربة. ومع ذلك، في سيناريوهات البرمجة الآلية باستخدام الوكلاء (Agents)، تعني درجة BFCL العالية لـ M2.5 جولات استدعاء أقل وتكلفة إجمالية أدنى.
س3: كيف يمكنني مقارنة أداء البرمجة بين النموذجين بسرعة؟
نوصي بإجراء اختبار مقارنة عبر APIYI (apiyi.com):
- سجل حسابًا واحصل على مفتاح API.
- استخدم أمثلة الكود في هذا المقال لاستدعاء النموذجين لنفس مهمة البرمجة.
- قارن جودة الكود الناتج، وسرعة الاستجابة، واستهلاك التوكنات (Tokens).
- واجهة موحدة متوافقة مع OpenAI، حيث يتطلب تغيير النموذج فقط تعديل معامل model.
الخلاصة
الاستنتاجات الرئيسية حول قدرات البرمجة لـ MiniMax-M2.5 مقارنة بـ Claude Opus 4.6:
- جودة البرمجة متساوية تقريبًا: 80.2% في SWE-Bench مقابل 80.8%، بفارق 0.6%؛ وتفوق M2.5 بنسبة 1% في Multi-SWE-Bench.
- تفوق كبير لـ M2.5 في استدعاء الأدوات: 76.8% في BFCL مقابل 63.3%، مما يجعله الخيار الأول لسيناريوهات البرمجة المعتمدة على الوكلاء.
- فجوة هائلة في التكلفة: 0.15 دولار للمهمة الواحدة في M2.5 مقابل 3.00 دولارات في Opus، مما يسمح بإنجاز مهام أكثر بـ 10 أضعاف بنفس الميزانية.
- لا يمكن الاستغناء عن Opus 4.6 في المهام العميقة: لا يزال يتمتع بمزايا في سياق 1M، وTerminal-Bench، وMCP Atlas، وغيرها من السيناريوهات.
بالنسبة لمعظم مهام البرمجة اليومية، يوفر MiniMax-M2.5 جودة برمجة قريبة من Opus 4.6 مع نسبة أداء إلى سعر أفضل بكثير من Opus. نوصي بالتحقق والمقارنة في مشاريعك الفعلية عبر APIYI (apiyi.com)، حيث تدعم المنصة واجهة استدعاء موحدة لكلا النموذجين، كما يمكنك المشاركة في أنشطة الشحن للحصول على خصومات.
📚 المراجع
⚠️ ملاحظة حول تنسيق الروابط: تُستخدم جميع الروابط الخارجية بتنسيق
اسم المرجع: domain.comلتسهيل نسخها ولكنها غير قابلة للنقر، وذلك لتجنب فقدان قوة الـ SEO.
-
الإعلان الرسمي عن MiniMax M2.5: تفاصيل القدرات الأساسية واختبارات قياس البرمجة لـ M2.5
- الرابط:
minimax.io/news/minimax-m25 - الوصف: يتضمن بيانات كاملة لـ SWE-Bench وMulti-SWE-Bench وBFCL وغيرها.
- الرابط:
-
الإطلاق الرسمي لـ Claude Opus 4.6: التفاصيل التقنية لـ Opus 4.6 الصادرة عن Anthropic
- الرابط:
anthropic.com/news/claude-opus-4-6 - الوصف: شرح لقدرات Terminal-Bench وMCP Atlas وAdaptive Thinking وغيرها.
- الرابط:
-
تقييم OpenHands لـ M2.5: تقييم برمجي فعلي لـ M2.5 من منصة مطورين مستقلة
- الرابط:
openhands.dev/blog/minimax-m2-5-open-weights-models-catch-up-to-claude - الوصف: تحليل عملي لأول نموذج مفتوح الأوزان يتفوق على Claude Sonnet.
- الرابط:
-
مقارنة متعمقة من VentureBeat: تحليل القيمة مقابل السعر لـ M2.5 وOpus 4.6
- الرابط:
venturebeat.com/technology/minimaxs-new-open-m2-5-and-m2-5-lightning-near-state-of-the-art-while - الوصف: تحليل فروق التكلفة والفعالية من منظور الشركات.
- الرابط:
-
تحليل معايير Vellum لـ Opus 4.6: تفسير شامل لاختبارات قياس Claude Opus 4.6
- الرابط:
vellum.ai/blog/claude-opus-4-6-benchmarks - الوصف: تحليل مفصل لمعايير البرمجة الأساسية مثل Terminal-Bench وSWE-Bench.
- الرابط:
المؤلف: فريق APIYI
التبادل التقني: نرحب بمشاركة نتائج اختبارات مقارنة النماذج الخاصة بك في قسم التعليقات. لمزيد من البرامج التعليمية حول دمج نماذج برمجة الذكاء الاصطناعي، يمكنك زيارة مجتمع APIYI التقني على apiyi.com.