Gemini 3.1 Pro Preview vs Claude Opus 4.6 : lequel choisir ? C'est le dilemme incontournable des développeurs IA en ce début d'année 2026. Cet article propose une comparaison complète sous 10 dimensions clés, en s'appuyant sur les données de référence officielles et des évaluations tierces pour vous aider à faire un choix éclairé grâce aux données.
Valeur ajoutée : après avoir lu cet article, vous saurez précisément quel modèle choisir selon vos besoins et comment les tester rapidement dans vos projets réels.

Aperçu des benchmarks : Gemini 3.1 Pro vs Claude Opus 4.6
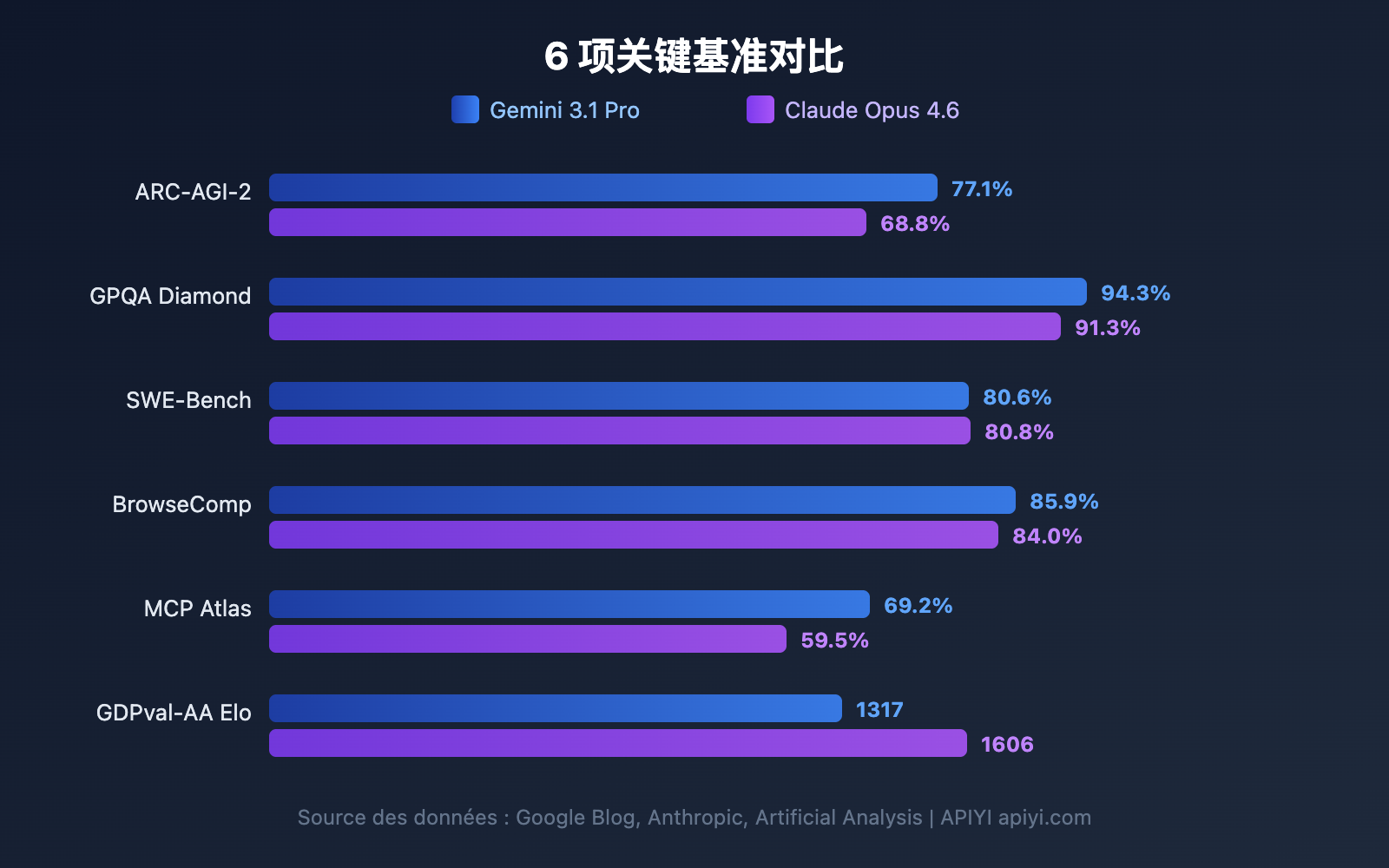
Avant d'analyser chaque dimension en détail, voici un comparatif global des benchmarks. Google affirme que Gemini 3.1 Pro est en tête sur 13 des 16 benchmarks, mais Claude Opus 4.6 l'emporte dans plusieurs scénarios réels.
| Benchmark | Gemini 3.1 Pro | Claude Opus 4.6 | Vainqueur | Écart |
|---|---|---|---|---|
| ARC-AGI-2 (Raisonnement abstrait) | 77,1 % | 68,8 % | Gemini | +8,3 pp |
| GPQA Diamond (Sciences niveau PhD) | 94,3 % | 91,3 % | Gemini | +3,0 pp |
| SWE-Bench Verified (Génie logiciel) | 80,6 % | 80,8 % | Claude | +0,2 pp |
| Terminal-Bench 2.0 (Codage en terminal) | 68,5 % | 65,4 % | Gemini | +3,1 pp |
| BrowseComp (Recherche par Agent) | 85,9 % | 84,0 % | Gemini | +1,9 pp |
| MCP Atlas (Agent multi-étapes) | 69,2 % | 59,5 % | Gemini | +9,7 pp |
| HLE sans outils (L'examen ultime) | 44,4 % | 40,0 % | Gemini | +4,4 pp |
| HLE avec outils (L'examen ultime) | 51,4 % | 53,1 % | Claude | +1,7 pp |
| SciCode (Codage scientifique) | 59 % | 52 % | Gemini | +7 pp |
| MMMLU (QA multilingue) | 92,6 % | 91,1 % | Gemini | +1,5 pp |
| tau2-bench Retail (Appel d'outils) | 90,8 % | 91,9 % | Claude | +1,1 pp |
| GDPval-AA Elo (Tâches d'experts) | 1317 | 1606 | Claude | +289 |
📊 Note sur les données : Ces chiffres proviennent des blogs officiels de Google, d'Anthropic et des évaluations tierces d'Artificial Analysis. Via APIYI (apiyi.com), vous pouvez appeler les deux modèles simultanément pour valider vos propres cas d'usage.
Comparaison 1 : Capacités de raisonnement entre Gemini 3.1 Pro et Claude Opus 4.6
La capacité de raisonnement est la compétence clé des grands modèles de langage. Les architectures de raisonnement de ces deux modèles présentent des différences significatives.
Raisonnement abstrait : Gemini 3.1 Pro nettement en tête
ARC-AGI-2 est actuellement le benchmark de raisonnement abstrait le plus reconnu. Gemini 3.1 Pro y obtient un score de 77,1 %, soit 8,3 points de plus que les 68,8 % de Claude Opus 4.6. Cela signifie que Gemini est plus performant pour les tâches nécessitant d'induire des règles à partir de quelques exemples seulement.
Raisonnement scientifique de niveau doctorat : l'avantage marqué de Gemini
Le test GPQA Diamond évalue des questions scientifiques de niveau doctorat (PhD). Gemini 3.1 Pro affiche un score de 94,3 %, contre 91,3 % pour Claude Opus 4.6. Un écart de 3 points à ce niveau de difficulté est très significatif.
Raisonnement assisté par outils : Claude reprend l'avantage
Sur le HLE (Humanity's Last Exam), Gemini mène sans outils (44,4 % contre 40,0 %), mais une fois les outils introduits, Claude repasse devant (53,1 % contre 51,4 %). Cela indique que Claude Opus 4.6 est plus efficace pour utiliser des outils externes afin d'étayer son raisonnement.
| Dimension de raisonnement | Gemini 3.1 Pro | Claude Opus 4.6 | Idéal pour |
|---|---|---|---|
| Raisonnement abstrait | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Reconnaissance de formes, induction de règles |
| Raisonnement scientifique | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Recherche académique, aide à la rédaction |
| Raisonnement par outils | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Workflows complexes, orchestration d'outils |
| Raisonnement mathématique | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Spécialité de Deep Think Mini |
Comparaison 2 : Capacités de codage entre Gemini 3.1 Pro et Claude Opus 4.6
Le codage est la dimension qui intéresse le plus les développeurs. Les performances des deux modèles sont très proches, mais avec des points forts différents.
SWE-Bench : Presque à égalité
SWE-Bench Verified est un benchmark basé sur la résolution de problèmes réels sur GitHub :
- Claude Opus 4.6 : 80,8 % (légère avance)
- Gemini 3.1 Pro : 80,6 %
Avec seulement 0,2 point d'écart, on peut considérer que les deux modèles ont des capacités équivalentes sur des tâches d'ingénierie logicielle réelles.
Terminal-Bench : Gemini l'emporte
Terminal-Bench 2.0 teste les capacités d'un agent de codage dans un environnement de terminal :
- Gemini 3.1 Pro : 68,5 %
- Claude Opus 4.6 : 65,4 %
Cet écart de 3,1 points montre que Gemini est plus efficace dans les scénarios d'exécution via un agent de terminal.
Programmation compétitive : Gemini en tête
Les données de LiveCodeBench Pro montrent que Gemini 3.1 Pro atteint un score Elo de 2887, excellant ainsi en programmation compétitive. Les données correspondantes pour Claude Opus 4.6 n'ont pas encore été publiées, mais au vu de ses performances dans des compétitions comme l'USACO, Claude se situe également au plus haut niveau.
# 通过 APIYI 同时测试两个模型的编码能力
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 统一接口
)
# 同一编码任务分别测试
coding_prompt = "实现一个 LRU Cache,支持 get 和 put 操作,时间复杂度 O(1)"
for model in ["gemini-3.1-pro-preview", "claude-opus-4-6"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": coding_prompt}]
)
print(f"\n{'='*50}")
print(f"模型: {model}")
print(f"Token 用量: {resp.usage.total_tokens}")
print(f"回答:\n{resp.choices[0].message.content[:500]}")
Comparaison 3 : Capacités d'Agent de Gemini 3.1 Pro vs Claude Opus 4.6
Les agents et les flux de travail (workflows) autonomes sont au cœur des scénarios d'utilisation pour 2026. C'est l'un des domaines où les différences entre les deux modèles sont les plus marquées.
Recherche par Agent : un duel au sommet
Le test BrowseComp évalue la capacité des modèles à effectuer des recherches web autonomes et à extraire des informations :
- Gemini 3.1 Pro : 85,9 %
- Claude Opus 4.6 : 84,0 %
L'écart n'est que de 1,9 point de pourcentage, les deux modèles affichant un niveau d'excellence.
Agents multi-étapes : Gemini prend une avance considérable
Le benchmark MCP Atlas teste les flux de travail complexes à plusieurs étapes. Gemini 3.1 Pro obtient un score de 69,2 %, soit près de 10 points de plus que les 59,5 % de Claude Opus 4.6. C'est l'un des critères où la différence entre les deux modèles est la plus flagrante.
Utilisation de l'ordinateur : l'avantage exclusif de Claude
Le benchmark OSWorld teste la capacité d'un modèle à manipuler une véritable interface graphique (GUI). Claude Opus 4.6 obtient un score de 72,7 %. Gemini n'a pas encore publié de résultats pour cette catégorie. Cela signifie que si vous avez besoin qu'une IA manipule automatiquement des applications de bureau, Claude est actuellement votre seule option.
Tâches de niveau expert : Claude mène nettement
GDPval-AA teste des tâches de niveau expert dans un environnement de bureau réel (analyse de données, rédaction de rapports, etc.). Claude Opus 4.6 obtient un score Elo de 1606, dépassant de loin les 1317 de Gemini. Cela montre que pour le travail intellectuel nécessitant une compréhension profonde et une exécution méticuleuse, Claude est plus fiable.
| Sous-dimensions de l'Agent | Gemini 3.1 Pro | Claude Opus 4.6 | Écart |
|---|---|---|---|
| BrowseComp (Recherche) | 85,9 % | 84,0 % | +1,9 pp |
| MCP Atlas (Multi-étapes) | 69,2 % | 59,5 % | +9,7 pp |
| APEX-Agents (Cycle long) | 33,5 % | 29,8 % | +3,7 pp |
| OSWorld (Utilisation ordi) | — | 72,7 % | Exclusivité Claude |
| GDPval-AA (Tâches expert) | 1317 Elo | 1606 Elo | +289 |
Comparaison 4 : Architecture du système de réflexion de Gemini 3.1 Pro vs Claude Opus 4.6
Les deux modèles disposent d'un mécanisme de « réflexion profonde », mais leurs philosophies de conception diffèrent.
Gemini 3.1 Pro : un système de réflexion à trois niveaux
| Niveau | Nom | Caractéristiques | Cas d'utilisation |
|---|---|---|---|
| Low | Réponse rapide | Presque sans latence | Questions-réponses simples, traduction |
| Medium | Raisonnement équilibré | Latence modérée (nouveau) | Codage quotidien, analyse |
| High | Deep Think Mini | Raisonnement profond, résout des problèmes de l'OMI en 8 min | Mathématiques, débogage complexe |
Le mode High de Gemini 3.1 Pro est en réalité une version mini de Deep Think (le modèle de raisonnement dédié de Google), ce qui revient à intégrer un moteur de raisonnement spécialisé au sein du modèle.
Claude Opus 4.6 : un système de réflexion adaptatif
| Niveau | Nom | Caractéristiques | Cas d'utilisation |
|---|---|---|---|
| Low | Mode rapide | Coût de raisonnement minimal | Tâches simples |
| Medium | Mode équilibré | Raisonnement modéré | Développement classique |
| High | Mode profond (par défaut) | Détermine automatiquement la profondeur de raisonnement | La plupart des tâches |
| Max | Raisonnement maximal | Raisonnement à pleine puissance | Problèmes extrêmement difficiles |
La particularité de Claude est sa réflexion adaptative : le modèle décide automatiquement de la quantité de ressources de raisonnement à allouer en fonction de la complexité du problème. Le développeur n'a pas besoin de choisir manuellement. Le mode High par défaut est déjà extrêmement intelligent.
🎯 Comparaison pratique : Gemini vous offre un contrôle manuel plus fin (3 niveaux), idéal pour les scénarios nécessitant une maîtrise précise des coûts et de la latence. Claude vous propose une adaptation automatique plus intelligente (4 niveaux + adaptatif), parfaite pour les environnements de production où l'on préfère « configurer et oublier ». Vous pouvez tester et comparer ces deux modèles directement sur APIYI apiyi.com.
Comparaison 5 : Gemini 3.1 Pro vs Claude Opus 4.6 – Tarification et coûts
Le coût est un facteur déterminant pour les environnements de production. La différence de prix entre ces deux modèles est d'ailleurs assez marquée.
| Dimension de prix | Gemini 3.1 Pro | Claude Opus 4.6 | Rapport qualité-prix Gemini |
|---|---|---|---|
| Entrée (Standard) | 2,00 $ / 1M tokens | 5,00 $ / 1M tokens | 2,5x moins cher |
| Sortie (Standard) | 12,00 $ / 1M tokens | 25,00 $ / 1M tokens | 2,1x moins cher |
| Entrée (Contexte long >200K) | 4,00 $ / 1M tokens | 10,00 $ / 1M tokens | 2,5x moins cher |
| Sortie (Contexte long >200K) | 18,00 $ / 1M tokens | 37,50 $ / 1M tokens | 2,1x moins cher |
Estimation des coûts en conditions réelles
En se basant sur un traitement quotidien de 1 million de tokens en entrée et 200 000 tokens en sortie :
| Scénario | Gemini 3.1 Pro | Claude Opus 4.6 | Économie mensuelle |
|---|---|---|---|
| Utilisation quotidienne | 4,40 $/jour | 10,00 $/jour | 168 $/mois |
| Utilisation intensive (x3) | 13,20 $/jour | 30,00 $/jour | 504 $/mois |
Gemini 3.1 Pro coûte environ moitié moins cher que Claude Opus 4.6 sur tous les plans. Pour les projets sensibles au budget, c'est un avantage de taille.
💰 Conseil d'optimisation des coûts : En passant par la plateforme APIYI (apiyi.com) pour appeler ces deux modèles, vous bénéficiez d'une facturation flexible et d'une gestion centralisée. Je vous recommande de tester d'abord sur de petits volumes pour valider les résultats avant de choisir votre modèle principal.
Comparaison 6 : Gemini 3.1 Pro vs Claude Opus 4.6 – Fenêtre de contexte et sortie
| Spécifications | Gemini 3.1 Pro | Claude Opus 4.6 | Avantage |
|---|---|---|---|
| Fenêtre de contexte | 1 000 000 tokens | 200 000 tokens (1M en bêta) | Gemini |
| Sortie maximale | 64 000 tokens | 128 000 tokens | Claude |
| Taille de fichier max. | 100 Mo | — | Gemini |
Fenêtre de contexte : Gemini en tête avec un facteur 5
Gemini 3.1 Pro supporte nativement une fenêtre de 1 million de tokens, alors que Claude Opus 4.6 est à 200 000 (le million est encore en bêta). Pour analyser de gros dépôts de code, de longs documents ou des vidéos, l'avantage de Gemini est flagrant.
Sortie maximale : Claude prend le large (x2)
Claude Opus 4.6 permet une sortie allant jusqu'à 128K tokens, soit le double de Gemini. C'est crucial pour la génération de textes longs, de code détaillé ou de chaînes de raisonnement complexes — une plus grande capacité de sortie permet au modèle de « réfléchir » plus en profondeur.
Comparaison 7 : Gemini 3.1 Pro vs Claude Opus 4.6 – Capacités multimodales
Les capacités multimodales sont historiquement le point fort de Gemini.
| Modalité | Gemini 3.1 Pro | Claude Opus 4.6 |
|---|---|---|
| Entrée de texte | ✅ | ✅ |
| Entrée d'image | ✅ (Natif) | ✅ |
| Entrée vidéo | ✅ (Natif) | ❌ |
| Entrée audio | ✅ (Natif) | ❌ |
| Traitement PDF | ✅ | ✅ |
| URL YouTube | ✅ | ❌ |
| Génération SVG | ✅ (Natif) | ✅ |
Gemini 3.1 Pro est un véritable modèle omnimodal. Dès son architecture d'entraînement, il supporte nativement une compréhension unifiée du texte, de l'image, de l'audio et de la vidéo. Les capacités multimodales de Claude Opus 4.6 se limitent au texte et à l'image.
Si votre application implique de l'analyse vidéo, de la transcription audio ou de la compréhension de contenu multimédia, Gemini 3.1 Pro est actuellement le seul choix possible.
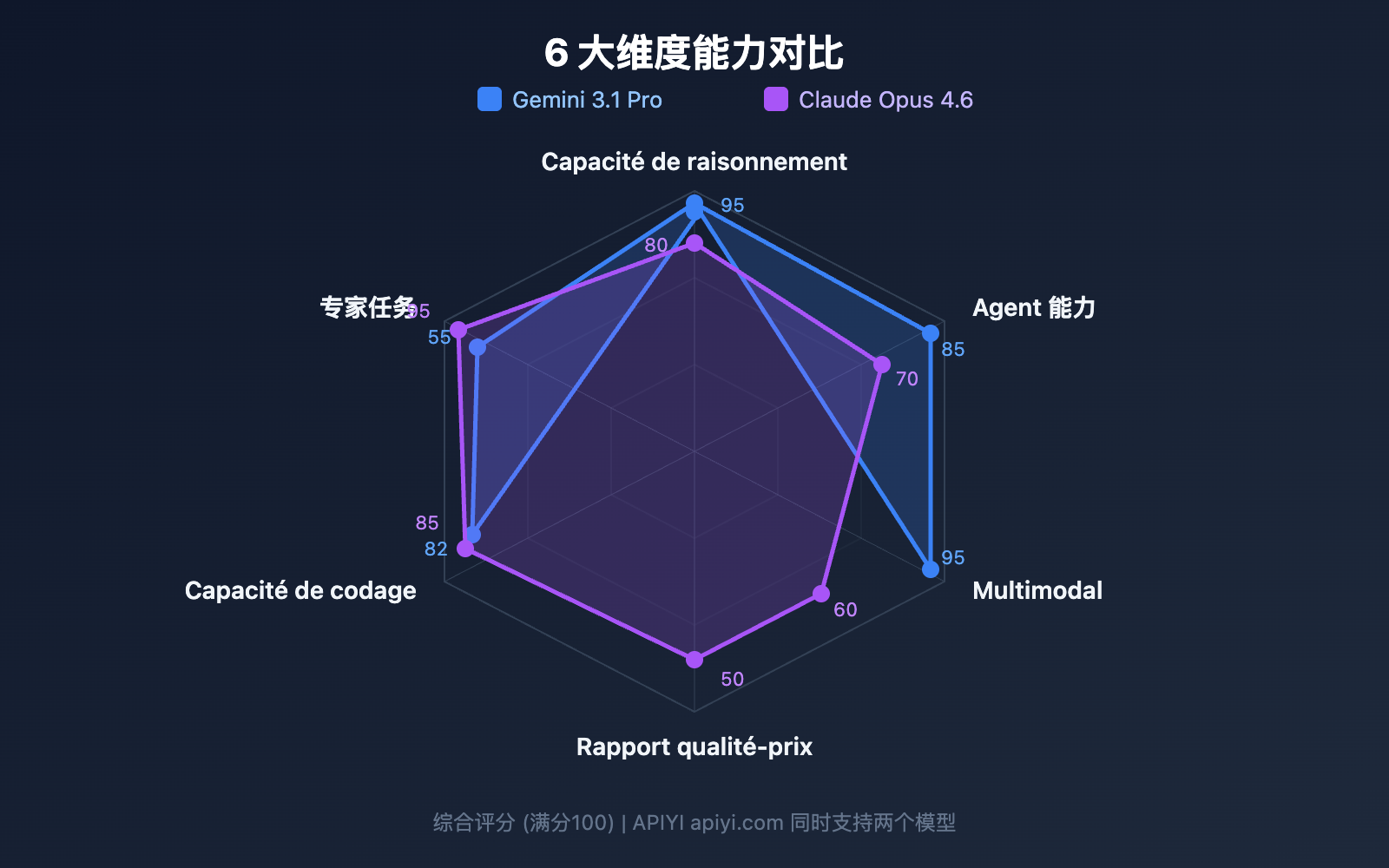
Comparaison 8 : Gemini 3.1 Pro vs Claude Opus 4.6 – Fonctionnalités exclusives
Exclusivités Gemini 3.1 Pro
| Fonctionnalité | Description | Valeur |
|---|---|---|
| Deep Think Mini | Moteur de raisonnement dédié intégré au mode High | Raisonnement mathématique / niveau compétition |
| Ancrage (Grounding) | 5000 recherches gratuites par mois | Enrichissement par informations en temps réel |
| Upload de fichiers 100 Mo | Téléchargement de fichiers volumineux en une seule fois | Analyse de bases de code massives / données |
| Analyse d'URL YouTube | Compréhension directe via l'URL de la vidéo | Analyse de contenu vidéo |
| Compréhension audio/vidéo native | Traitement multimodal de bout en bout | Applications IA multimédia |
Exclusivités Claude Opus 4.6
| Fonctionnalité | Description | Valeur |
|---|---|---|
| Computer Use (OSWorld 72,7%) | Manipulation automatique de l'interface GUI | RPA / Tests automatisés |
| Réflexion adaptative | Détermination automatique de la profondeur de raisonnement | Raisonnement intelligent sans configuration |
| Sortie 128K | Support de sorties ultra-longues | Génération de textes longs / raisonnement approfondi |
| API Batch (50% de réduction) | Traitement par lots asynchrone | Traitement de données à grande échelle |
| Mode Rapide | Vitesse accrue contre un tarif 6x plus élevé | Scénarios de production à faible latence |
Gemini 3.1 Pro vs Claude Opus 4.6 : Guide de sélection par scénario
Sur la base de la comparaison des 8 dimensions précédentes, voici des recommandations claires par scénario :
Quand choisir Gemini 3.1 Pro
| Scénario | Avantage clé | Raison de la recommandation |
|---|---|---|
| Raisonnement abstrait / Mathématiques | ARC-AGI-2 +8,3pp | Deep Think Mini est extrêmement performant |
| Agents multi-étapes | MCP Atlas +9,7pp | Meilleure capacité d'exécution des flux de travail |
| Analyse Vidéo / Audio | Multimodalité native | Seul choix véritablement multimodal |
| Projets sensibles aux coûts | 2 à 2,5x moins cher | Qualité équivalente pour un coût moindre |
| Analyse de documents volumineux | 1M de contexte | Support standard pour des contextes ultra-larges |
| Recherche scientifique | GPQA +3,0pp | Meilleure capacité de raisonnement scientifique |
Quand choisir Claude Opus 4.6
| Scénario | Avantage clé | Raison de la recommandation |
|---|---|---|
| Ingénierie logicielle réelle | SWE-Bench 80,8% | Le plus précis pour corriger des bugs réels |
| Travail de connaissance expert | GDPval-AA +289 Elo | Le meilleur pour les rapports, analyses et décisions |
| Automatisation informatique | OSWorld 72,7% | Le seul à supporter les opérations GUI |
| Raisonnement assisté par outils | HLE+tools +1,7pp | Synergie multi-outils optimale |
| Besoins de sorties ultra-longues | 128K en sortie | Idéal pour les textes longs ou les chaînes de raisonnement profond |
| Production à faible latence | Mode rapide | Possibilité de payer pour plus de vitesse |
Utiliser les deux : L'architecture de routage intelligent
Dans de nombreux environnements de production, la solution optimale consiste à utiliser les deux modèles simultanément, en routant intelligemment les tâches selon leur type :
| Type de tâche | Router vers | Raison | Part estimée |
|---|---|---|---|
| Questions-réponses / Traduction | Gemini 3.1 Pro | Coût bas, qualité suffisante | 40% |
| Génération de code / Débogage | Claude Opus 4.6 | Légèrement supérieur sur SWE-Bench | 20% |
| Raisonnement / Math / Sciences | Gemini 3.1 Pro | Avance significative sur ARC-AGI-2 | 15% |
| Flux de travail d'agents | Gemini 3.1 Pro | MCP Atlas +9,7pp | 10% |
| Analyse / Rapports d'experts | Claude Opus 4.6 | Avance nette sur GDPval-AA | 10% |
| Traitement Vidéo / Audio | Gemini 3.1 Pro | Seul choix véritablement multimodal | 5% |
En routant selon ces proportions, le coût global peut être réduit d'environ 55% par rapport à une utilisation exclusive de Claude, tout en obtenant la meilleure qualité pour chaque scénario spécifique.
Stratégies d'optimisation des coûts pour Gemini 3.1 Pro vs Claude Opus 4.6
Stratégie 1 : Traitement par paliers
Utilisez le mode Gemini Low (le plus rapide et le moins cher) pour les tâches simples, Gemini Medium pour les tâches intermédiaires, et réservez Claude High ou Gemini High (Deep Think Mini) uniquement pour les tâches réellement complexes.
Stratégie 2 : Séparation du traitement par lots et du temps réel
Utilisez Gemini 3.1 Pro pour les requêtes en temps réel (faible latence, faible coût) et l'API Batch de Claude (50% de réduction) pour le traitement hors ligne par lots ; les coûts globaux deviennent alors comparables.
Stratégie 3 : Mise en cache du contexte
Gemini propose la mise en cache du contexte (entrée entre 0,20 $ et 0,40 $/MTok). Pour les scénarios utilisant de manière répétée le même document long, le coût peut être réduit de plus de 80% grâce au cache.
🚀 Validation rapide : Via la plateforme APIYI (apiyi.com), vous pouvez appeler simultanément Gemini 3.1 Pro et Claude Opus 4.6 avec la même clé API. Nous vous conseillons de faire un test A/B avec vos propres invites métiers ; 10 minutes suffisent pour tirer vos conclusions.
Prise en main rapide : Gemini 3.1 Pro vs Claude Opus 4.6
Le code suivant montre comment utiliser l'interface unifiée d'APIYI pour appeler les deux modèles simultanément à des fins de test comparatif :
import openai
import time
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
def compare_models(prompt, models=None):
"""Compare la qualité et la vitesse de sortie des deux modèles"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-opus-4-6"]
results = {}
for model in models:
start = time.time()
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
elapsed = time.time() - start
results[model] = {
"time": f"{elapsed:.2f}s",
"tokens": resp.usage.total_tokens,
"answer": resp.choices[0].message.content[:300]
}
for model, data in results.items():
print(f"\n{'='*50}")
print(f"Modèle : {model}")
print(f"Durée : {data['time']} | Tokens : {data['tokens']}")
print(f"Réponse : {data['answer']}...")
# Test des capacités de raisonnement
compare_models("Veuillez expliquer par un raisonnement en chaîne pourquoi 0.1 + 0.2 n'est pas égal à 0.3")
Voir le code complet avec contrôle du niveau de réflexion
import openai
import time
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1"
)
def compare_with_thinking(prompt, thinking_config=None):
"""Compare les performances des modèles selon différents niveaux de réflexion"""
configs = [
{"model": "gemini-3.1-pro-preview", "label": "Gemini Medium",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 8000}}},
{"model": "gemini-3.1-pro-preview", "label": "Gemini High (Deep Think Mini)",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 32000}}},
{"model": "claude-opus-4-6", "label": "Claude High (adaptatif par défaut)",
"extra": {}},
]
for cfg in configs:
start = time.time()
params = {
"model": cfg["model"],
"messages": [{"role": "user", "content": prompt}],
**cfg["extra"]
}
resp = client.chat.completions.create(**params)
elapsed = time.time() - start
print(f"\n[{cfg['label']}] {elapsed:.2f}s | {resp.usage.total_tokens} tokens")
print(f" → {resp.choices[0].message.content[:200]}...")
# Test de raisonnement complexe
compare_with_thinking("Prouvez que pour tout entier naturel n, n^3 - n est divisible par 6")
Questions Fréquentes
Q1 : Lequel est le meilleur entre Gemini 3.1 Pro et Claude Opus 4.6 ?
Il n'y a pas de « meilleur » absolu. Gemini 3.1 Pro mène sur le raisonnement abstrait (ARC-AGI-2 +8,3pp), les Agents multi-étapes (MCP Atlas +9,7pp), la multimodalité et le coût. Claude Opus 4.6 l'emporte sur l'ingénierie logicielle réelle (SWE-Bench), le travail de connaissance expert (GDPval-AA +289 Elo), l'utilisation de l'ordinateur et le raisonnement par outils. Nous vous conseillons d'effectuer des tests A/B dans vos propres scénarios via APIYI apiyi.com.
Q2 : Les interfaces API des deux modèles sont-elles compatibles ? Est-il facile de basculer de l’un à l’autre ?
Via la plateforme APIYI apiyi.com, les deux modèles utilisent une interface unifiée compatible avec OpenAI. Pour changer de modèle, il suffit de modifier le paramètre model (gemini-3.1-pro-preview → claude-opus-4-6), sans avoir à retoucher le reste de votre code.
Q3 : Lequel choisir si mon budget est limité ?
Privilégiez Gemini 3.1 Pro. Son prix d'entrée (input) représente 40 % de celui de Claude Opus 4.6 (2 $ contre 5 $), et son prix de sortie (output) est moins de la moitié (12 $ contre 25 $). Sur la plupart des benchmarks, Gemini affiche des performances égales, voire supérieures, offrant ainsi un excellent rapport qualité-prix. Réservez Claude aux scénarios où il domine nettement, comme le SWE-Bench ou les tâches d'expertise pointue.
Q4 : Puis-je utiliser les deux modèles simultanément pour faire du routage intelligent ?
Oui, c'est tout à fait possible. L'architecture recommandée est la suivante : utilisez Gemini 3.1 Pro pour traiter 80 % des requêtes courantes (faible coût, raisonnement solide) et Claude Opus 4.6 pour les 20 % de tâches de niveau expert et les scénarios d'outils augmentés. Grâce à l'interface unifiée d'APIYI apiyi.com, il vous suffit de déterminer le type de tâche dans votre code et de basculer le paramètre model pour réaliser ce routage intelligent.
Résumé : Aide à la décision Gemini 3.1 Pro vs Claude Opus 4.6
| # | Dimension de comparaison | Gemini 3.1 Pro | Claude Opus 4.6 | Vainqueur |
|---|---|---|---|---|
| 1 | Raisonnement abstrait | ARC-AGI-2 77,1% | 68,8% | Gemini |
| 2 | Capacités de codage | SWE-Bench 80,6% | 80,8% | Claude (légère avance) |
| 3 | Workflow d'Agent | MCP Atlas 69,2% | 59,5% | Gemini |
| 4 | Tâches d'expertise | GDPval 1317 | 1606 | Claude |
| 5 | Multimodalité | Omnimodal (texte/image/audio/vidéo) | Texte/Image | Gemini |
| 6 | Prix | 2 $ / 12 $ par MTok | 5 $ / 25 $ par MTok | Gemini (2x moins cher) |
| 7 | Fenêtre de contexte | 1M (standard) | 200K (1M en bêta) | Gemini |
| 8 | Sortie maximale | 64K tokens | 128K tokens | Claude |
| 9 | Système de réflexion | Niveau 3 + Deep Think Mini | Niveau 4 + Adaptatif | Chacun ses atouts |
| 10 | Utilisation de l'ordinateur | Non supporté | OSWorld 72,7% | Exclusivité Claude |
Conseils finaux :
- Priorité au rapport qualité-prix → Gemini 3.1 Pro (2 fois moins cher, raisonnement plus puissant)
- Priorité à l'ingénierie logicielle → Claude Opus 4.6 (leader sur SWE-Bench et GDPval)
- Priorité à la multimodalité → Gemini 3.1 Pro (le seul choix véritablement omnimodal)
- Meilleure pratique → Utilisez les deux avec un routage intelligent.
Nous vous recommandons d'accéder aux deux modèles via la plateforme APIYI apiyi.com pour profiter d'une interface unifiée, d'une flexibilité de déploiement et de tests A/B simplifiés.
Références
-
Blog officiel de Google : Annonce du lancement de Gemini 3.1 Pro
- Lien :
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - Description : Données de référence (benchmarks) officielles et présentation des fonctionnalités.
- Lien :
-
Annonce officielle d'Anthropic : Détails du lancement de Claude Opus 4.6
- Lien :
anthropic.com/news/claude-opus-4-6 - Description : Spécifications techniques et données de référence de Claude Opus 4.6.
- Lien :
-
Artificial Analysis : Évaluation comparative tierce
- Lien :
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - Description : Comparaison indépendante des benchmarks et analyse des performances.
- Lien :
-
Google DeepMind : Fiches de modèle (Model Cards) et évaluations de sécurité
- Lien :
deepmind.google/models/model-cards/gemini-3-1-pro - Description : Paramètres techniques détaillés et données de sécurité.
- Lien :
-
VentureBeat : Test approfondi de Deep Think Mini
- Lien :
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - Description : Test en conditions réelles du système de réflexion à trois niveaux.
- Lien :
📝 Auteur : Équipe APIYI | Pour tout échange technique, visitez APIYI sur apiyi.com
📅 Date de mise à jour : 20 février 2026
🏷️ Mots-clés : Gemini 3.1 Pro vs Claude Opus 4.6, comparaison de modèles, ARC-AGI-2, SWE-Bench, MCP Atlas, multimodal, appels API