Gemini 3.1 Pro Preview vs Claude Opus 4.6, mana yang harus Anda pilih? Ini adalah pilihan yang tidak bisa dihindari oleh para developer AI di awal tahun 2026. Artikel ini akan melakukan perbandingan komprehensif dari 10 dimensi utama, mengutip data benchmark resmi dan evaluasi pihak ketiga untuk membantu Anda membuat pilihan yang tepat berdasarkan data.
Nilai Inti: Setelah membaca artikel ini, Anda akan tahu persis model mana yang harus dipilih untuk berbagai skenario, serta cara memverifikasinya dengan cepat dalam proyek nyata.

Ikhtisar Data Benchmark Gemini 3.1 Pro vs Claude Opus 4.6
Sebelum mendalami setiap dimensi, mari kita lihat perbandingan benchmark globalnya. Google secara resmi mengklaim bahwa Gemini 3.1 Pro unggul dalam 13 dari 16 benchmark, namun Claude Opus 4.6 menang dalam beberapa skenario penggunaan nyata.
| Uji Benchmark | Gemini 3.1 Pro | Claude Opus 4.6 | Pemenang | Selisih |
|---|---|---|---|---|
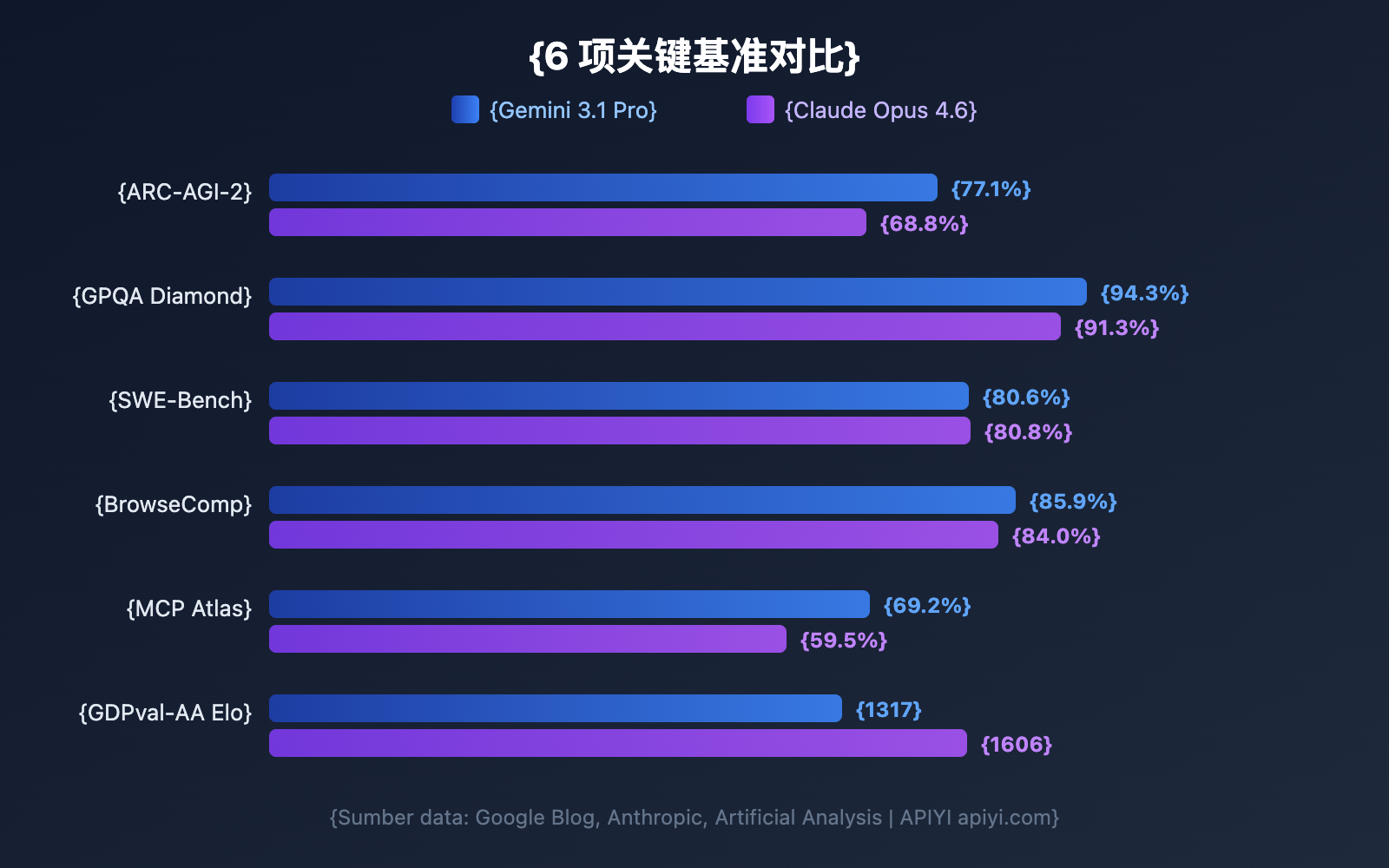
| ARC-AGI-2 (Penalaran Abstrak) | 77.1% | 68.8% | Gemini | +8.3pp |
| GPQA Diamond (Sains PhD) | 94.3% | 91.3% | Gemini | +3.0pp |
| SWE-Bench Verified (Rekayasa Perangkat Lunak) | 80.6% | 80.8% | Claude | +0.2pp |
| Terminal-Bench 2.0 (Coding Terminal) | 68.5% | 65.4% | Gemini | +3.1pp |
| BrowseComp (Pencarian Agent) | 85.9% | 84.0% | Gemini | +1.9pp |
| MCP Atlas (Agent Multi-langkah) | 69.2% | 59.5% | Gemini | +9.7pp |
| HLE Tanpa Tool (Ujian Akhir) | 44.4% | 40.0% | Gemini | +4.4pp |
| HLE Dengan Tool (Ujian Akhir) | 51.4% | 53.1% | Claude | +1.7pp |
| SciCode (Coding Riset Ilmiah) | 59% | 52% | Gemini | +7pp |
| MMMLU (QA Multibahasa) | 92.6% | 91.1% | Gemini | +1.5pp |
| tau2-bench Retail (Pemanggilan Tool) | 90.8% | 91.9% | Claude | +1.1pp |
| GDPval-AA Elo (Tugas Pakar) | 1317 | 1606 | Claude | +289 |
📊 Keterangan Data: Data di atas bersumber dari blog resmi Google, pengumuman resmi Anthropic, dan evaluasi pihak ketiga dari Artificial Analysis. Melalui APIYI apiyi.com, Anda dapat memanggil kedua model secara bersamaan untuk verifikasi skenario nyata.
Perbandingan 1: Gemini 3.1 Pro vs Claude Opus 4.6 – Kemampuan Penalaran
Kemampuan penalaran adalah daya saing inti dari Model Bahasa Besar. Arsitektur penalaran kedua model ini memiliki perbedaan yang signifikan.
Penalaran Abstrak: Gemini 3.1 Pro Unggul Jelas
ARC-AGI-2 adalah benchmark penalaran abstrak paling otoritatif saat ini. Gemini 3.1 Pro memperoleh skor 77,1%, lebih tinggi 8,3 poin persentase dibandingkan Claude Opus 4.6 yang meraih 68,8%. Ini berarti Gemini lebih kuat dalam tugas-tugas yang membutuhkan induksi aturan dari sedikit contoh.
Penalaran Ilmiah Tingkat PhD: Keunggulan Gemini Menonjol
GPQA Diamond menguji pertanyaan ilmiah tingkat PhD. Gemini 3.1 Pro mendapatkan skor 94,3%, sementara Claude Opus 4.6 mendapatkan 91,3%. Selisih 3 poin persentase pada tingkat kesulitan ini sangatlah signifikan.
Penalaran dengan Dukungan Alat: Claude Berhasil Menyusul
Pada HLE (Humanity's Last Exam), Gemini unggul dalam kondisi tanpa alat (44,4% vs 40,0%), namun setelah alat bantu diperkenalkan, Claude berhasil menyusul (53,1% vs 51,4%). Ini menunjukkan bahwa Claude Opus 4.6 lebih mahir dalam memanfaatkan alat eksternal untuk membantu penalaran.
| Sub-dimensi Penalaran | Gemini 3.1 Pro | Claude Opus 4.6 | Cocok untuk siapa |
|---|---|---|---|
| Penalaran Abstrak | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Pengenalan pola, induksi aturan |
| Penalaran Ilmiah | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Penelitian akademik, bantuan penulisan karya ilmiah |
| Penalaran Alat | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Alur kerja kompleks, kolaborasi multi-alat |
| Penalaran Matematika | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Keahlian Deep Think Mini |
Perbandingan 2: Gemini 3.1 Pro vs Claude Opus 4.6 – Kemampuan Coding
Kemampuan coding adalah dimensi yang paling diperhatikan oleh para pengembang. Performa kedua model ini sangat mendekati, namun masing-masing memiliki fokus yang berbeda.
SWE-Bench: Hampir Seimbang
SWE-Bench Verified adalah benchmark perbaikan masalah GitHub yang nyata:
- Claude Opus 4.6: 80,8% (unggul tipis)
- Gemini 3.1 Pro: 80,6%
Dengan selisih hanya 0,2 poin persentase, keduanya dapat dianggap memiliki kemampuan yang setara dalam tugas rekayasa perangkat lunak yang nyata.
Terminal-Bench: Gemini Lebih Unggul
Terminal-Bench 2.0 menguji kemampuan coding Agent dalam lingkungan terminal:
- Gemini 3.1 Pro: 68,5%
- Claude Opus 4.6: 65,4%
Selisih 3,1 poin persentase menunjukkan bahwa Gemini memiliki eksekusi yang lebih kuat dalam skenario Agent terminal.
Pemrograman Kompetitif: Gemini Memimpin
Data LiveCodeBench Pro menunjukkan Gemini 3.1 Pro mencapai 2887 Elo, menunjukkan performa luar biasa dalam pemrograman kompetitif. Data koresponden untuk Claude Opus 4.6 belum dipublikasikan secara resmi, namun dari performa kompetisi seperti USACO, Claude juga berada di level papan atas.
# Menguji kemampuan coding kedua model secara bersamaan melalui APIYI
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Antarmuka terpadu APIYI
)
# Menguji tugas coding yang sama secara terpisah
coding_prompt = "Implementasikan LRU Cache, dukung operasi get dan put, kompleksitas waktu O(1)"
for model in ["gemini-3.1-pro-preview", "claude-opus-4-6"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": coding_prompt}]
)
print(f"\n{'='*50}")
print(f"Model: {model}")
print(f"Penggunaan Token: {resp.usage.total_tokens}")
print(f"Jawaban:\n{resp.choices[0].message.content[:500]}")
Perbandingan 3: Kemampuan Agent Gemini 3.1 Pro vs Claude Opus 4.6
Agent dan alur kerja otonom (autonomous workflow) adalah skenario inti di tahun 2026. Ini adalah salah satu bidang di mana perbedaan antara kedua model ini paling terlihat.
Pencarian Agent: Keduanya Bersaing Ketat
BrowseComp menguji kemampuan model dalam pencarian web otonom dan ekstraksi informasi:
- Gemini 3.1 Pro: 85.9%
- Claude Opus 4.6: 84.0%
Selisihnya hanya 1,9 poin persentase, keduanya berada di level teratas.
Agent Multi-langkah: Gemini Unggul Jauh
MCP Atlas menguji alur kerja multi-langkah yang kompleks, di mana Gemini 3.1 Pro mencetak skor 69,2%, hampir 10 poin persentase lebih tinggi dari Claude Opus 4.6 yang mencetak 59,5%. Ini adalah salah satu benchmark dengan perbedaan terbesar antara kedua model tersebut.
Operasi Komputer: Keunggulan Eksklusif Claude
Benchmark OSWorld menguji kemampuan model dalam mengoperasikan GUI (antarmuka grafis) yang sebenarnya. Claude Opus 4.6 mencetak skor 72,7%. Gemini belum merilis hasil untuk kategori ini. Ini berarti jika Anda membutuhkan AI untuk mengoperasikan aplikasi desktop secara otomatis, Claude adalah satu-satunya pilihan saat ini.
Tugas Tingkat Pakar: Claude Memimpin Jelas
GDPval-AA menguji tugas tingkat pakar dalam lingkungan kantor nyata (analisis data, penulisan laporan, dll.). Skor Elo Claude Opus 4.6 adalah 1606, jauh melampaui Gemini yang berada di angka 1317. Ini menunjukkan bahwa dalam pekerjaan berbasis pengetahuan yang membutuhkan pemahaman mendalam dan eksekusi yang halus, Claude lebih andal.
| Sub-dimensi Agent | Gemini 3.1 Pro | Claude Opus 4.6 | Selisih |
|---|---|---|---|
| BrowseComp (Pencarian) | 85.9% | 84.0% | +1.9pp |
| MCP Atlas (Multi-langkah) | 69.2% | 59.5% | +9.7pp |
| APEX-Agents (Siklus Panjang) | 33.5% | 29.8% | +3.7pp |
| OSWorld (Operasi Komputer) | — | 72.7% | Eksklusif Claude |
| GDPval-AA (Tugas Pakar) | 1317 Elo | 1606 Elo | +289 |
Perbandingan 4: Arsitektur Sistem Berpikir Gemini 3.1 Pro vs Claude Opus 4.6
Kedua model memiliki mekanisme "berpikir mendalam", namun dengan filosofi desain yang berbeda.
Gemini 3.1 Pro: Sistem Berpikir Tiga Tingkat
| Level | Nama | Karakteristik | Skenario Penggunaan |
|---|---|---|---|
| Low | Respons Cepat | Hampir tanpa delay | Tanya jawab sederhana, terjemahan |
| Medium | Penalaran Seimbang | Delay menengah (baru) | Coding harian, analisis |
| High | Deep Think Mini | Penalaran mendalam, 8 menit selesaikan soal IMO | Matematika, debugging kompleks |
Mode High pada Gemini 3.1 Pro sebenarnya adalah versi mini dari Deep Think (model penalaran khusus Google), yang setara dengan menanamkan mesin penalaran khusus di dalam satu model.
Claude Opus 4.6: Sistem Berpikir Adaptif
| Level | Nama | Karakteristik | Skenario Penggunaan |
|---|---|---|---|
| Low | Mode Cepat | Biaya penalaran minimal | Tugas sederhana |
| Medium | Mode Seimbang | Penalaran moderat | Pengembangan rutin |
| High | Mode Mendalam (Default) | Menentukan kedalaman penalaran secara otomatis | Sebagian besar tugas |
| Max | Penalaran Maksimal | Penalaran penuh | Masalah yang sangat sulit |
Keunggulan Claude adalah berpikir adaptif — model akan secara otomatis memutuskan berapa banyak sumber daya penalaran yang akan digunakan berdasarkan kompleksitas pertanyaan, sehingga pengembang tidak perlu memilih secara manual. Mode High default-nya sudah sangat cerdas.
🎯 Perbandingan Praktis: Gemini memberi Anda kontrol manual yang lebih halus (3 level), cocok untuk skenario yang membutuhkan kontrol biaya dan latensi yang presisi; Claude memberi Anda adaptasi otomatis yang lebih cerdas (4 level + adaptif), cocok untuk lingkungan produksi "set and forget". Kedua model ini dapat langsung dipanggil dan dibandingkan di APIYI apiyi.com.
Perbandingan 5: Harga dan Biaya Gemini 3.1 Pro vs Claude Opus 4.6
Biaya adalah pertimbangan krusial dalam lingkungan produksi. Perbedaan harga antara kedua model ini cukup signifikan.
| Dimensi Harga | Gemini 3.1 Pro | Claude Opus 4.6 | Efisiensi Biaya Gemini |
|---|---|---|---|
| Input (Standar) | $2.00 / 1M tokens | $5.00 / 1M tokens | 2,5x lebih murah |
| Output (Standar) | $12.00 / 1M tokens | $25.00 / 1M tokens | 2,1x lebih murah |
| Input (Konteks Panjang >200K) | $4.00 / 1M tokens | $10.00 / 1M tokens | 2,5x lebih murah |
| Output (Konteks Panjang >200K) | $18.00 / 1M tokens | $37.50 / 1M tokens | 2,1x lebih murah |
Estimasi Biaya Skenario Nyata
Dihitung berdasarkan pemrosesan 1 juta token input + 200 ribu token output per hari:
| Skenario | Gemini 3.1 Pro | Claude Opus 4.6 | Penghematan Bulanan |
|---|---|---|---|
| Panggilan Harian | $4.40/hari | $10.00/hari | $168/bulan |
| Penggunaan Berat (3x) | $13.20/hari | $30.00/hari | $504/bulan |
Gemini 3.1 Pro memiliki harga sekitar setengah dari Claude Opus 4.6 di semua dimensi harga. Untuk proyek yang sensitif terhadap biaya, ini adalah keunggulan yang sangat signifikan.
💰 Saran Optimasi Biaya: Melalui platform APIYI (apiyi.com), Anda dapat memanggil kedua model ini dengan penagihan yang fleksibel dan manajemen terpadu. Disarankan untuk melakukan pengujian batch kecil terlebih dahulu untuk memastikan hasilnya sebelum menentukan model utama.
Perbandingan 6: Jendela Konteks dan Output Gemini 3.1 Pro vs Claude Opus 4.6
| Spesifikasi | Gemini 3.1 Pro | Claude Opus 4.6 | Pihak yang Unggul |
|---|---|---|---|
| Jendela Konteks | 1.000.000 tokens | 200.000 tokens (1M beta) | Gemini |
| Output Maksimum | 64.000 tokens | 128.000 tokens | Claude |
| Ukuran File Unggahan | 100MB | — | Gemini |
Jendela Konteks: Gemini Unggul 5 Kali Lipat
Gemini 3.1 Pro secara standar mendukung jendela konteks 1 juta token, sementara Claude Opus 4.6 standarnya adalah 200 ribu (1 juta masih dalam versi beta). Untuk skenario yang memerlukan analisis repositori kode besar, dokumen panjang, atau video, keunggulan Gemini sangat terlihat jelas.
Output Maksimum: Claude Unggul Dua Kali Lipat
Claude Opus 4.6 mendukung output hingga 128K token, dua kali lipat dari Gemini. Hal ini sangat krusial untuk pembuatan artikel panjang, pembuatan kode yang mendetail, dan rantai penalaran yang mendalam—ruang output yang lebih panjang berarti model dapat "berpikir" dengan lebih leluasa.
Perbandingan 7: Gemini 3.1 Pro vs Claude Opus 4.6 Kemampuan Multimodal
Kemampuan multimodal adalah keunggulan tradisional dari Gemini.
| Modalitas | Gemini 3.1 Pro | Claude Opus 4.6 |
|---|---|---|
| Input Teks | ✅ | ✅ |
| Input Gambar | ✅ (Native) | ✅ |
| Input Video | ✅ (Native) | ❌ |
| Input Audio | ✅ (Native) | ❌ |
| Pemrosesan PDF | ✅ | ✅ |
| URL YouTube | ✅ | ❌ |
| Pembuatan SVG | ✅ (Native) | ✅ |
Gemini 3.1 Pro adalah Model Bahasa Besar full-multimodal yang sesungguhnya. Dari arsitektur pelatihannya, model ini sudah mendukung pemahaman terpadu untuk teks, gambar, audio, dan video secara native. Sementara itu, kemampuan multimodal Claude Opus 4.6 masih terbatas pada teks dan gambar saja.
Jika aplikasi yang Anda kembangkan melibatkan analisis video, transkripsi audio, atau pemahaman konten multimedia, Gemini 3.1 Pro adalah satu-satunya pilihan yang didukung saat ini.
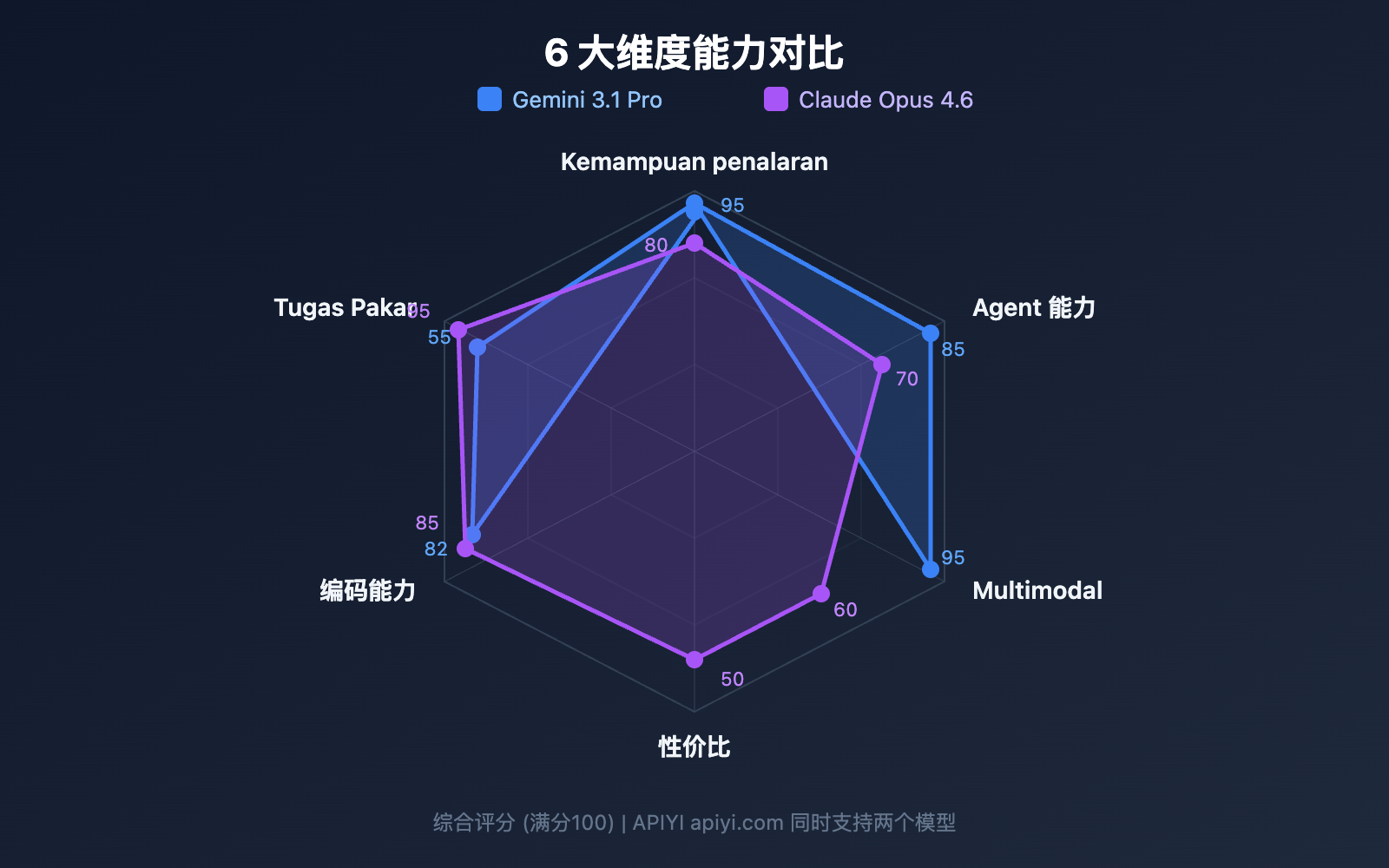
Perbandingan 8: Fitur Eksklusif Gemini 3.1 Pro vs Claude Opus 4.6
Eksklusif di Gemini 3.1 Pro
| Fitur | Deskripsi | Manfaat |
|---|---|---|
| Deep Think Mini | Mesin penalaran khusus yang tertanam dalam mode High | Penalaran tingkat kompetisi/matematika |
| Grounding (Pencarian) | 5.000 pencarian gratis setiap bulan | Peningkatan informasi secara real-time |
| Unggah File 100MB | Unggah file berukuran besar dalam satu kali proses | Analisis data/repositori kode skala besar |
| Analisis URL YouTube | Input URL video langsung untuk pemahaman konten | Analisis konten video yang efisien |
| Pemahaman Audio-Video Native | Pemrosesan multimodal end-to-end | Pengembangan aplikasi AI multimedia |
Eksklusif di Claude Opus 4.6
| Fitur | Deskripsi | Manfaat |
|---|---|---|
| Computer Use (OSWorld 72.7%) | Mengoperasikan antarmuka GUI secara otomatis | RPA/Pengujian otomatisasi |
| Adaptive Thinking | Menentukan kedalaman penalaran secara otomatis | Penalaran cerdas tanpa perlu konfigurasi |
| Output 128K | Dukungan untuk output teks yang sangat panjang | Pembuatan artikel panjang/penalaran mendalam |
| Batch API (Diskon 50%) | Pemrosesan batch secara asinkron | Pemrosesan data dalam skala masif |
| Fast Mode | Tarif 6x lebih tinggi untuk output yang lebih cepat | Skenario produksi dengan latensi rendah |
Panduan Pemilihan Skenario: Gemini 3.1 Pro vs Claude Opus 4.6
Berdasarkan perbandingan dari 8 dimensi di atas, berikut adalah rekomendasi skenario yang jelas:
Skenario untuk Memilih Gemini 3.1 Pro
| Skenario | Keunggulan Utama | Alasan Rekomendasi |
|---|---|---|
| Penalaran Abstrak/Matematika | ARC-AGI-2 +8.3pp | Deep Think Mini sangat kuat |
| Agent Multi-langkah | MCP Atlas +9.7pp | Eksekusi alur kerja terkuat |
| Analisis Video/Audio | Multimodal Native | Satu-satunya pilihan modalitas penuh |
| Proyek Sensitif Biaya | Harga 2-2.5x lebih murah | Biaya lebih rendah untuk kualitas yang setara |
| Analisis Dokumen Besar | Konteks 1M | Dukungan standar konteks super besar |
| Penelitian Ilmiah | GPQA +3.0pp | Kemampuan penalaran ilmiah terkuat |
Skenario untuk Memilih Claude Opus 4.6
| Skenario | Keunggulan Utama | Alasan Rekomendasi |
|---|---|---|
| Rekayasa Perangkat Lunak Nyata | SWE-Bench 80.8% | Paling akurat dalam memperbaiki bug nyata |
| Pekerjaan Pengetahuan Tingkat Ahli | GDPval-AA +289 Elo | Terkuat untuk laporan/analisis/pengambilan keputusan |
| Otomatisasi Komputer | OSWorld 72.7% | Satu-satunya yang mendukung operasi GUI |
| Penalaran dengan Peningkatan Alat | HLE+tools +1.7pp | Kolaborasi multi-alat yang optimal |
| Kebutuhan Output Sangat Panjang | Output 128K | Tulisan panjang/rantai penalaran mendalam |
| Lingkungan Produksi Latensi Rendah | Mode Cepat | Bayar lebih untuk kecepatan |
Gunakan Keduanya: Arsitektur Perutean Cerdas (Smart Routing)
Dalam banyak lingkungan produksi, solusi optimal adalah menggunakan kedua model secara bersamaan, dengan perutean cerdas berdasarkan jenis tugas:
| Jenis Tugas | Rute ke | Alasan | Estimasi Persentase |
|---|---|---|---|
| Tanya Jawab Umum/Terjemahan | Gemini 3.1 Pro | Biaya rendah, kualitas memadai | 40% |
| Pembuatan/Debugging Kode | Claude Opus 4.6 | SWE-Bench sedikit lebih unggul | 20% |
| Penalaran/Matematika/Sains | Gemini 3.1 Pro | ARC-AGI-2 unggul jauh | 15% |
| Alur Kerja Agent | Gemini 3.1 Pro | MCP Atlas +9.7pp | 10% |
| Analisis/Laporan Tingkat Ahli | Claude Opus 4.6 | GDPval-AA unggul nyata | 10% |
| Pemrosesan Video/Audio | Gemini 3.1 Pro | Satu-satunya pilihan modalitas penuh | 5% |
Dengan perutean sesuai proporsi di atas, total biaya dapat dihemat sekitar 55% dibandingkan jika hanya menggunakan Claude, sambil tetap mendapatkan kualitas optimal di setiap skenario spesifik.
Strategi Optimasi Biaya: Gemini 3.1 Pro vs Claude Opus 4.6
Strategi 1: Pemrosesan Bertingkat
Gunakan mode Gemini Low untuk tugas sederhana (paling cepat dan murah), Gemini Medium untuk tugas menengah, dan hanya gunakan Claude High atau Gemini High (Deep Think Mini) untuk tugas yang benar-benar kompleks.
Strategi 2: Pemisahan Batch dan Real-time
Gunakan Gemini 3.1 Pro untuk permintaan real-time (latensi rendah, biaya rendah), dan gunakan Batch API dari Claude untuk pemrosesan batch offline (diskon 50%), sehingga biaya keseluruhan menjadi seimbang.
Strategi 3: Context Caching
Gemini menyediakan context caching (input $0.20-$0.40/MTok). Untuk skenario penggunaan dokumen panjang yang sama secara berulang, biaya dapat dikurangi lebih dari 80% setelah menggunakan cache.
🚀 Validasi Cepat: Melalui platform APIYI apiyi.com, Anda dapat memanggil Gemini 3.1 Pro dan Claude Opus 4.6 secara bersamaan dengan satu API Key yang sama. Disarankan untuk melakukan pengujian A/B dengan petunjuk bisnis nyata terlebih dahulu; hasilnya bisa didapat dalam 10 menit.
Memulai Cepat: Gemini 3.1 Pro vs Claude Opus 4.6
Kode berikut menunjukkan cara memanggil kedua model secara bersamaan melalui antarmuka terpadu APIYI untuk pengujian perbandingan:
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Antarmuka terpadu APIYI
)
def compare_models(prompt, models=None):
"""Bandingkan kualitas output dan kecepatan kedua model"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-opus-4-6"]
results = {}
for model in models:
start = time.time()
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
elapsed = time.time() - start
results[model] = {
"time": f"{elapsed:.2f}s",
"tokens": resp.usage.total_tokens,
"answer": resp.choices[0].message.content[:300]
}
for model, data in results.items():
print(f"\n{'='*50}")
print(f"Model: {model}")
print(f"Waktu: {data['time']} | Token: {data['tokens']}")
print(f"Jawaban: {data['answer']}...")
# Uji kemampuan penalaran
compare_models("Tolong jelaskan menggunakan chain-of-thought mengapa 0.1 + 0.2 tidak sama dengan 0.3")
Lihat kode lengkap dengan kontrol tingkat pemikiran (thinking level)
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def compare_with_thinking(prompt, thinking_config=None):
"""Bandingkan performa model pada tingkat pemikiran yang berbeda"""
configs = [
{"model": "gemini-3.1-pro-preview", "label": "Gemini Medium",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 8000}}},
{"model": "gemini-3.1-pro-preview", "label": "Gemini High (Deep Think Mini)",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 32000}}},
{"model": "claude-opus-4-6", "label": "Claude High (Default adaptif)",
"extra": {}},
]
for cfg in configs:
start = time.time()
params = {
"model": cfg["model"],
"messages": [{"role": "user", "content": prompt}],
**cfg["extra"]
}
resp = client.chat.completions.create(**params)
elapsed = time.time() - start
print(f"\n[{cfg['label']}] {elapsed:.2f}s | {resp.usage.total_tokens} tokens")
print(f" → {resp.choices[0].message.content[:200]}...")
# Uji penalaran kompleks
compare_with_thinking("Buktikan: Untuk semua bilangan bulat positif n, n^3 - n habis dibagi 6")
Pertanyaan yang Sering Diajukan (FAQ)
Q1: Mana yang lebih baik, Gemini 3.1 Pro atau Claude Opus 4.6?
Tidak ada yang mutlak "lebih baik". Gemini 3.1 Pro unggul dalam penalaran abstrak (ARC-AGI-2 +8.3pp), Agent multi-langkah (MCP Atlas +9.7pp), kemampuan multimodal, dan biaya. Sementara itu, Claude Opus 4.6 lebih unggul dalam rekayasa perangkat lunak (SWE-Bench), pekerjaan pengetahuan tingkat pakar (GDPval-AA +289 Elo), operasi komputer, dan penalaran alat (tool reasoning). Disarankan untuk melakukan A/B testing pada skenario nyata Anda melalui APIYI apiyi.com.
Q2: Apakah antarmuka API kedua model ini kompatibel? Bisakah beralih dengan mudah?
Melalui platform APIYI apiyi.com, kedua model menggunakan antarmuka seragam yang kompatibel dengan OpenAI. Untuk beralih, Anda hanya perlu mengubah parameter model (gemini-3.1-pro-preview → claude-opus-4-6), tanpa perlu mengubah kode lainnya sama sekali.
Q3: Mana yang harus dipilih jika anggaran terbatas?
Prioritaskan Gemini 3.1 Pro. Harga inputnya hanya 40% dari Claude Opus 4.6 ($2 vs $5), dan harga outputnya kurang dari setengahnya ($12 vs $25). Di sebagian besar benchmark, performa Gemini tidak kalah atau bahkan lebih kuat, sehingga rasio performa-harganya sangat tinggi. Gunakan Claude hanya pada skenario di mana Claude unggul jauh, seperti SWE-Bench atau tugas-tugas pakar tertentu.
Q4: Bisakah menggunakan kedua model secara bersamaan untuk smart routing?
Bisa. Arsitektur yang direkomendasikan adalah: gunakan Gemini 3.1 Pro untuk menangani 80% permintaan rutin (biaya rendah, penalaran kuat), dan Claude Opus 4.6 untuk 20% tugas tingkat pakar dan skenario dengan penguatan alat (tool-enhanced). Dengan antarmuka tunggal dari APIYI apiyi.com, Anda cukup menentukan jenis tugas dalam kode dan mengganti parameter model untuk menerapkan smart routing.
Ringkasan: Panduan Keputusan Gemini 3.1 Pro vs Claude Opus 4.6
| # | Dimensi Perbandingan | Gemini 3.1 Pro | Claude Opus 4.6 | Pemenang |
|---|---|---|---|---|
| 1 | Penalaran Abstrak | ARC-AGI-2 77.1% | 68.8% | Gemini |
| 2 | Kemampuan Coding | SWE-Bench 80.6% | 80.8% | Claude (Tipis) |
| 3 | Workflow Agent | MCP Atlas 69.2% | 59.5% | Gemini |
| 4 | Tugas Pakar | GDPval 1317 | 1606 | Claude |
| 5 | Multimodal | Full Multimodal (Teks/Gbr/Audio/Video) | Teks/Gbr | Gemini |
| 6 | Harga | $2/$12 per MTok | $5/$25 per MTok | Gemini (2x lebih murah) |
| 7 | Context Window | 1M (Standar) | 200K (1M beta) | Gemini |
| 8 | Output Maksimal | 64K tokens | 128K tokens | Claude |
| 9 | Sistem Berpikir | Level 3 + Deep Think Mini | Level 4 + Adaptif | Masing-masing punya kelebihan |
| 10 | Operasi Komputer | Belum didukung | OSWorld 72.7% | Eksklusif Claude |
Rekomendasi Akhir:
- Prioritas Rasio Performa-Harga → Gemini 3.1 Pro (2x lebih murah, penalaran lebih kuat)
- Prioritas Rekayasa Perangkat Lunak → Claude Opus 4.6 (Unggul di SWE-Bench & GDPval)
- Prioritas Multimodal → Gemini 3.1 Pro (Satu-satunya pilihan untuk full multimodal)
- Praktik Terbaik → Gunakan keduanya dengan smart routing
Disarankan untuk mengakses kedua model secara bersamaan melalui platform APIYI apiyi.com guna menerapkan penjadwalan yang fleksibel dan pengujian A/B melalui satu antarmuka yang seragam.
Referensi
-
Blog Resmi Google: Pengumuman Rilis Gemini 3.1 Pro
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - Deskripsi: Data benchmark resmi dan pengenalan fitur
- Link:
-
Pengumuman Resmi Anthropic: Detail Rilis Claude Opus 4.6
- Link:
anthropic.com/news/claude-opus-4-6 - Deskripsi: Spesifikasi teknis dan data benchmark Claude Opus 4.6
- Link:
-
Artificial Analysis: Evaluasi Perbandingan Pihak Ketiga
- Link:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - Deskripsi: Perbandingan benchmark independen dan analisis performa
- Link:
-
Google DeepMind: Model Card dan Evaluasi Keamanan
- Link:
deepmind.google/models/model-cards/gemini-3-1-pro - Deskripsi: Parameter teknis mendalam dan data keamanan
- Link:
-
VentureBeat: Pengalaman Mendalam Deep Think Mini
- Link:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - Deskripsi: Pengujian nyata sistem berpikir tiga tingkat
- Link:
📝 Penulis: Tim APIYI | Untuk diskusi teknis, silakan kunjungi APIYI apiyi.com
📅 Waktu Pembaruan: 20 Februari 2026
🏷️ Kata Kunci: Gemini 3.1 Pro vs Claude Opus 4.6, Perbandingan Model, ARC-AGI-2, SWE-Bench, MCP Atlas, Multimodal, Pemanggilan API