Gemini 3.1 Pro Preview vs. Claude Opus 4.6: qual escolher? Essa é a decisão inevitável para desenvolvedores de IA no início de 2026. Este artigo faz uma comparação completa em 10 dimensões fundamentais, citando dados oficiais de benchmark e avaliações de terceiros para te ajudar a decidir com base em dados.
Valor central: Ao terminar de ler, você saberá exatamente qual modelo escolher para diferentes cenários e como validá-los rapidamente em seus projetos reais.

Visão Geral dos Benchmarks: Gemini 3.1 Pro vs. Claude Opus 4.6
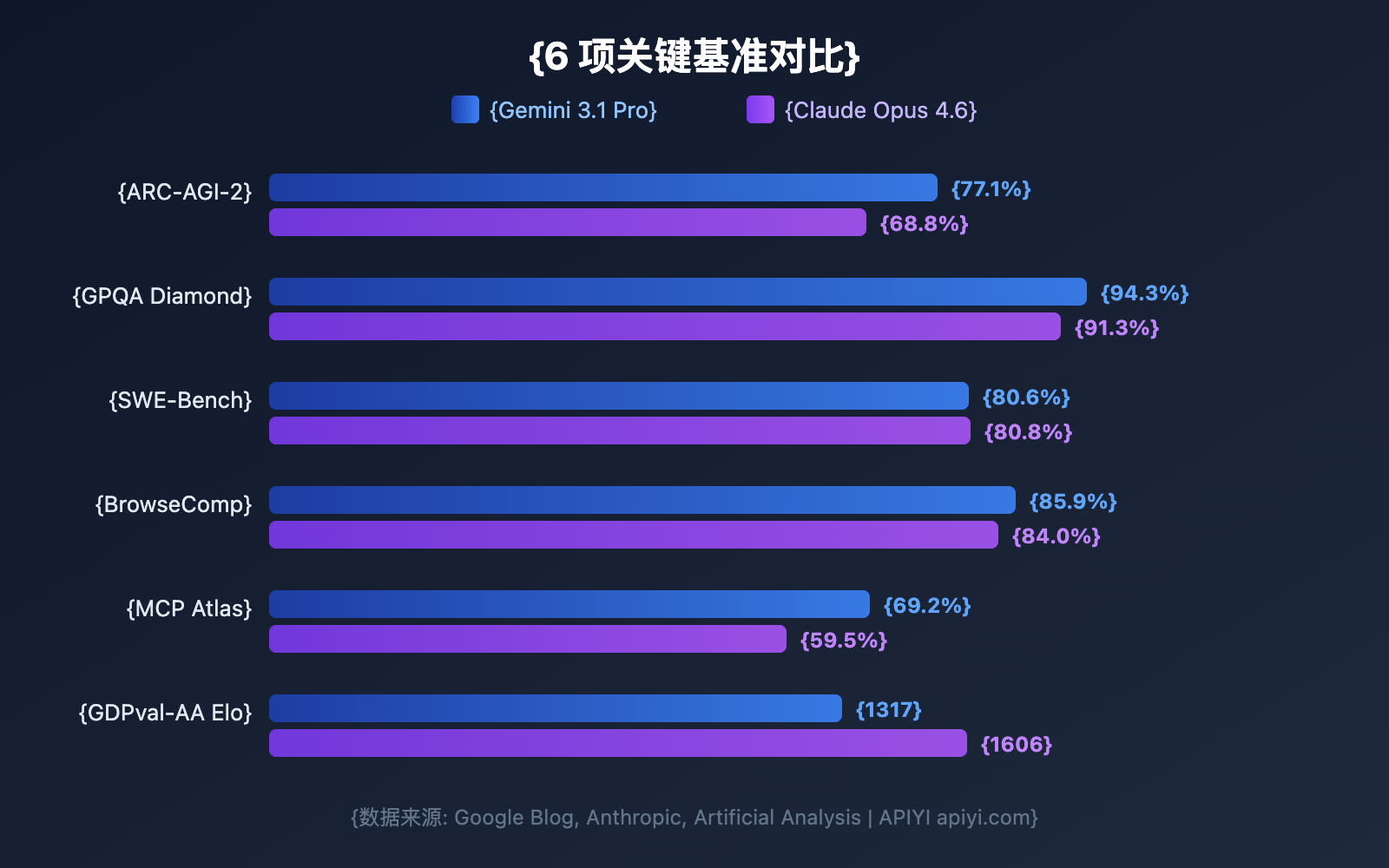
Antes de mergulharmos em cada dimensão, vamos conferir uma comparação geral dos benchmarks. O Google afirma que o Gemini 3.1 Pro lidera em 13 de 16 benchmarks, mas o Claude Opus 4.6 vence em vários cenários práticos.
| Benchmark | Gemini 3.1 Pro | Claude Opus 4.6 | Vencedor | Diferença |
|---|---|---|---|---|
| ARC-AGI-2 (Raciocínio Abstrato) | 77.1% | 68.8% | Gemini | +8.3pp |
| GPQA Diamond (Ciência nível PhD) | 94.3% | 91.3% | Gemini | +3.0pp |
| SWE-Bench Verified (Engenharia de Software) | 80.6% | 80.8% | Claude | +0.2pp |
| Terminal-Bench 2.0 (Codificação em Terminal) | 68.5% | 65.4% | Gemini | +3.1pp |
| BrowseComp (Busca por Agente) | 85.9% | 84.0% | Gemini | +1.9pp |
| MCP Atlas (Agente Multietapa) | 69.2% | 59.5% | Gemini | +9.7pp |
| HLE Sem Ferramentas (Exame Definitivo) | 44.4% | 40.0% | Gemini | +4.4pp |
| HLE Com Ferramentas (Exame Definitivo) | 51.4% | 53.1% | Claude | +1.7pp |
| SciCode (Codificação Científica) | 59% | 52% | Gemini | +7pp |
| MMMLU (QA Multilíngue) | 92.6% | 91.1% | Gemini | +1.5pp |
| tau2-bench Retail (Chamada de Ferramentas) | 90.8% | 91.9% | Claude | +1.1pp |
| GDPval-AA Elo (Tarefas de Especialista) | 1317 | 1606 | Claude | +289 |
📊 Nota sobre os dados: As informações acima vêm do blog oficial do Google, anúncios da Anthropic e avaliações de terceiros da Artificial Analysis. Através da APIYI (apiyi.com), você pode testar ambos os modelos simultaneamente em cenários reais.
Comparação 1: Gemini 3.1 Pro vs Claude Opus 4.6 – Capacidade de Raciocínio
A capacidade de raciocínio é a competência central de um Modelo de Linguagem Grande. As arquiteturas de raciocínio dos dois modelos apresentam diferenças significativas.
Raciocínio Abstrato: Gemini 3.1 Pro lidera com folga
O ARC-AGI-2 é atualmente o benchmark de raciocínio abstrato mais respeitado. O Gemini 3.1 Pro obteve uma pontuação de 77,1%, superando os 68,8% do Claude Opus 4.6 em 8,3 pontos percentuais. Isso significa que o Gemini é superior em tarefas que exigem a indução de regras a partir de poucos exemplos.
Raciocínio Científico de nível PhD: Gemini tem vantagem clara
O GPQA Diamond testa questões científicas de nível de doutorado. O Gemini 3.1 Pro marcou 94,3%, enquanto o Claude Opus 4.6 atingiu 91,3%. Uma diferença de 3 pontos percentuais nesse nível de dificuldade é extremamente significativa.
Raciocínio com Ferramentas: Claude vira o jogo
No HLE (Humanity's Last Exam), o Gemini lidera em condições sem ferramentas (44,4% vs 40,0%), mas o Claude assume a liderança quando ferramentas são introduzidas (53,1% vs 51,4%). Isso indica que o Claude Opus 4.6 é mais eficiente ao utilizar ferramentas externas para auxiliar no raciocínio.
| Dimensão de Raciocínio | Gemini 3.1 Pro | Claude Opus 4.6 | Indicado para |
|---|---|---|---|
| Raciocínio Abstrato | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Reconhecimento de padrões, indução de regras |
| Raciocínio Científico | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Pesquisa acadêmica, auxílio em artigos |
| Raciocínio com Ferramentas | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Workflows complexos, colaboração multi-ferramentas |
| Raciocínio Matemático | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Especialidade do Deep Think Mini |
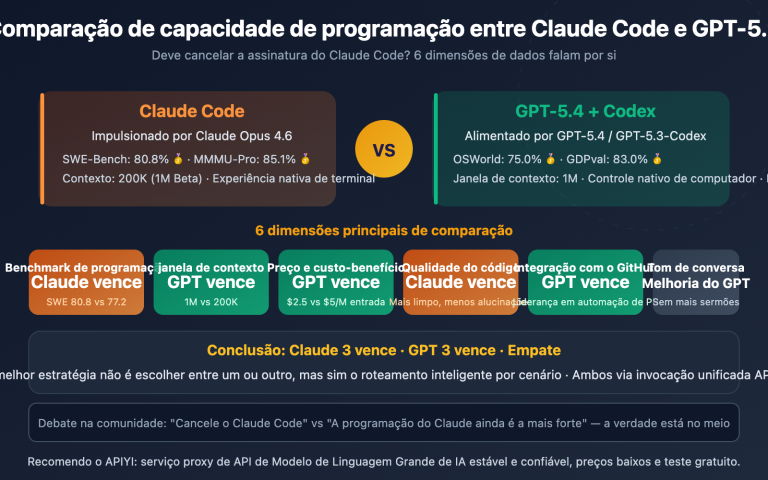
Comparação 2: Gemini 3.1 Pro vs Claude Opus 4.6 – Capacidade de Programação
A capacidade de codificação é a dimensão que mais interessa aos desenvolvedores. O desempenho de ambos os modelos é muito próximo, mas cada um tem seus pontos fortes.
SWE-Bench: Praticamente empatados
O SWE-Bench Verified é um benchmark baseado na correção de problemas reais do GitHub:
- Claude Opus 4.6: 80,8% (liderança mínima)
- Gemini 3.1 Pro: 80,6%
Com uma diferença de apenas 0,2 pontos percentuais, podemos considerar que ambos possuem capacidades equivalentes em tarefas reais de engenharia de software.
Terminal-Bench: Gemini leva a melhor
O Terminal-Bench 2.0 testa a capacidade de codificação de agentes em ambientes de terminal:
- Gemini 3.1 Pro: 68,5%
- Claude Opus 4.6: 65,4%
A diferença de 3,1 pontos percentuais mostra que o Gemini tem uma execução mais robusta em cenários de agentes de terminal.
Programação Competitiva: Gemini na frente
Dados do LiveCodeBench Pro mostram que o Gemini 3.1 Pro atingiu 2887 Elo, apresentando um desempenho excepcional em programação competitiva. Os dados correspondentes para o Claude Opus 4.6 ainda não foram totalmente divulgados, mas, a julgar pelo desempenho em competições como a USACO, o Claude também está no nível de elite.
# Testando a capacidade de codificação de ambos os modelos via APIYI
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interface unificada APIYI
)
# Testando a mesma tarefa de codificação separadamente
coding_prompt = "Implemente um LRU Cache que suporte operações get e put, com complexidade de tempo O(1)"
for model in ["gemini-3.1-pro-preview", "claude-opus-4-6"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": coding_prompt}]
)
print(f"\n{'='*50}")
print(f"Modelo: {model}")
print(f"Uso de Tokens: {resp.usage.total_tokens}")
print(f"Resposta:\n{resp.choices[0].message.content[:500]}")
Comparação 3: Capacidades de Agent do Gemini 3.1 Pro vs Claude Opus 4.6
Agents e fluxos de trabalho autônomos são os cenários centrais de 2026. Esta é uma das áreas onde as diferenças entre os dois modelos são mais marcantes.
Busca por Agent: Empate técnico
O BrowseComp testa a capacidade do modelo de realizar buscas na web e extração de informações de forma autônoma:
- Gemini 3.1 Pro: 85,9%
- Claude Opus 4.6: 84,0%
A diferença é de apenas 1,9 ponto percentual, ambos estão em um nível de elite.
Agent de múltiplas etapas: Gemini lidera com folga
O MCP Atlas testa fluxos de trabalho complexos de várias etapas. O Gemini 3.1 Pro marcou 69,2%, quase 10 pontos percentuais a mais que os 59,5% do Claude Opus 4.6. Este é um dos benchmarks onde a disparidade entre os dois modelos é mais evidente.
Operação de computador: Vantagem exclusiva do Claude
O benchmark OSWorld testa a capacidade do modelo de operar uma interface gráfica (GUI) real. O Claude Opus 4.6 atingiu 72,7%. O Gemini ainda não divulgou resultados para esta categoria. Isso significa que, se você precisa que a IA opere aplicativos de desktop automaticamente, o Claude é a única escolha no momento.
Tarefas de nível especialista: Claude lidera claramente
O GDPval-AA testa tarefas de nível especialista em ambientes de escritório reais (análise de dados, redação de relatórios, etc.). O Claude Opus 4.6 obteve uma pontuação Elo de 1606, superando de longe os 1317 do Gemini. Isso indica que, em trabalhos intelectuais que exigem compreensão profunda e execução refinada, o Claude é mais confiável.
| Subdimensão de Agent | Gemini 3.1 Pro | Claude Opus 4.6 | Diferença |
|---|---|---|---|
| BrowseComp (Busca) | 85,9% | 84,0% | +1,9 p.p. |
| MCP Atlas (Múltiplas etapas) | 69,2% | 59,5% | +9,7 p.p. |
| APEX-Agents (Ciclo longo) | 33,5% | 29,8% | +3,7 p.p. |
| OSWorld (Operação de PC) | — | 72,7% | Exclusivo Claude |
| GDPval-AA (Tarefas especialistas) | 1317 Elo | 1606 Elo | +289 |
Comparação 4: Arquitetura do sistema de pensamento do Gemini 3.1 Pro vs Claude Opus 4.6
Ambos os modelos possuem mecanismos de "pensamento profundo", mas com filosofias de design diferentes.
Gemini 3.1 Pro: Sistema de pensamento em três níveis
| Nível | Nome | Características | Cenários de Uso |
|---|---|---|---|
| Low | Resposta rápida | Quase sem latência | Perguntas simples, tradução |
| Medium | Raciocínio equilibrado | Latência média (novo) | Codificação diária, análise |
| High | Deep Think Mini | Raciocínio profundo, resolve problemas da IMO em 8 min | Matemática, depuração complexa |
O modo High do Gemini 3.1 Pro é, na verdade, uma versão "mini" do Deep Think (modelo de raciocínio dedicado do Google), o que equivale a ter um motor de raciocínio especializado embutido no modelo.
Claude Opus 4.6: Sistema de pensamento adaptativo
| Nível | Nome | Características | Cenários de Uso |
|---|---|---|---|
| Low | Modo rápido | Custo mínimo de raciocínio | Tarefas simples |
| Medium | Modo equilibrado | Raciocínio moderado | Desenvolvimento rotineiro |
| High | Modo profundo (padrão) | Julga automaticamente a profundidade do raciocínio | Maioria das tarefas |
| Max | Raciocínio máximo | Raciocínio total | Problemas extremamente difíceis |
O diferencial do Claude é o pensamento adaptativo — o modelo decide automaticamente quanto recurso de raciocínio investir com base na complexidade da pergunta, sem que o desenvolvedor precise escolher manualmente. O modo High padrão já é extremamente inteligente.
🎯 Comparação prática: O Gemini te dá um controle manual mais refinado (3 níveis), ideal para cenários que exigem controle preciso de custo e latência; o Claude oferece uma adaptação automática mais inteligente (4 níveis + adaptativo), ideal para ambientes de produção no estilo "configurar e esquecer". Ambos os modelos podem ser acessados e comparados diretamente no APIYI apiyi.com.
Comparação 5: Gemini 3.1 Pro vs. Claude Opus 4.6 – Preços e Custos
O custo é um fator determinante em ambientes de produção. A diferença de preço entre os dois modelos é significativa.
| Dimensão de Preço | Gemini 3.1 Pro | Claude Opus 4.6 | Custo-benefício do Gemini |
|---|---|---|---|
| Entrada (Padrão) | $2.00 / 1M tokens | $5.00 / 1M tokens | 2.5x mais barato |
| Saída (Padrão) | $12.00 / 1M tokens | $25.00 / 1M tokens | 2.1x mais barato |
| Entrada (Contexto Longo >200K) | $4.00 / 1M tokens | $10.00 / 1M tokens | 2.5x mais barato |
| Saída (Contexto Longo >200K) | $18.00 / 1M tokens | $37.50 / 1M tokens | 2.1x mais barato |
Estimativa de custos em cenários reais
Calculado com base no processamento diário de 1 milhão de tokens de entrada + 200 mil tokens de saída:
| Cenário | Gemini 3.1 Pro | Claude Opus 4.6 | Economia Mensal |
|---|---|---|---|
| Chamadas diárias | $4.40/dia | $10.00/dia | $168/mês |
| Uso intenso (3x) | $13.20/dia | $30.00/dia | $504/mês |
O Gemini 3.1 Pro custa cerca de metade do Claude Opus 4.6 em todas as dimensões de preço. Para projetos sensíveis a custos, essa é uma vantagem muito expressiva.
💰 Dica de otimização de custos: Ao utilizar esses dois modelos através da plataforma APIYI (apiyi.com), você aproveita o faturamento flexível e a gestão unificada. Recomendamos testar primeiro com pequenos volumes para validar os resultados antes de definir seu modelo principal.
Comparação 6: Gemini 3.1 Pro vs. Claude Opus 4.6 – Janela de Contexto e Saída
| Especificação | Gemini 3.1 Pro | Claude Opus 4.6 | Vantagem |
|---|---|---|---|
| Janela de Contexto | 1.000.000 tokens | 200.000 tokens (1M em beta) | Gemini |
| Saída Máxima | 64.000 tokens | 128.000 tokens | Claude |
| Tamanho de Upload | 100MB | — | Gemini |
Janela de Contexto: Gemini lidera com 5x mais capacidade
O Gemini 3.1 Pro oferece suporte padrão para 1 milhão de tokens de contexto, enquanto o Claude Opus 4.6 oferece 200 mil (com 1M ainda em fase beta). Para cenários que exigem a análise de grandes repositórios de código, documentos extensos ou vídeos, a vantagem do Gemini é nítida.
Saída Máxima: Claude lidera com o dobro da capacidade
O Claude Opus 4.6 suporta uma saída de até 128K tokens, o dobro do Gemini. Isso é crucial para a geração de textos longos, códigos detalhados e cadeias de raciocínio profundo — um espaço de saída maior permite que o modelo "pense" com muito mais profundidade e clareza.
Comparação 7: Gemini 3.1 Pro vs Claude Opus 4.6 – Capacidades Multimodais
As capacidades multimodais são, tradicionalmente, o ponto forte da linha Gemini.
| Modalidade | Gemini 3.1 Pro | Claude Opus 4.6 |
|---|---|---|
| Entrada de Texto | ✅ | ✅ |
| Entrada de Imagem | ✅ (Nativo) | ✅ |
| Entrada de Vídeo | ✅ (Nativo) | ❌ |
| Entrada de Áudio | ✅ (Nativo) | ❌ |
| Processamento de PDF | ✅ | ✅ |
| URL do YouTube | ✅ | ❌ |
| Geração de SVG | ✅ (Nativo) | ✅ |
O Gemini 3.1 Pro é um verdadeiro modelo de modalidade total, suportando nativamente a compreensão unificada de texto, imagem, áudio e vídeo desde a sua arquitetura de treinamento. Já o multimodal do Claude Opus 4.6 limita-se a texto e imagens.
Se a sua aplicação envolve análise de vídeo, transcrição de áudio ou compreensão de conteúdo multimídia, o Gemini 3.1 Pro é a única escolha viável no momento.

Comparação 8: Gemini 3.1 Pro vs Claude Opus 4.6 – Recursos Exclusivos
Exclusivos do Gemini 3.1 Pro
| Recurso | Descrição | Valor |
|---|---|---|
| Deep Think Mini | Mecanismo de raciocínio dedicado integrado no modo High | Raciocínio de nível matemático/olimpíada |
| Busca com Grounding | 5.000 buscas gratuitas por mês | Aprimoramento de informações em tempo real |
| Upload de arquivos de 100MB | Upload de arquivos grandes em uma única vez | Grandes bases de código/Análise de dados |
| Análise de URL do YouTube | Entrada direta de URL de vídeo para compreensão | Análise de conteúdo de vídeo |
| Compreensão Nativa de Áudio/Vídeo | Processamento multimodal de ponta a ponta | Aplicações de IA multimídia |
Exclusivos do Claude Opus 4.6
| Recurso | Descrição | Valor |
|---|---|---|
| Uso do Computador (OSWorld 72.7%) | Operação automática de interfaces GUI | RPA/Testes automatizados |
| Pensamento Adaptativo | Julgamento automático da profundidade do raciocínio | Raciocínio inteligente com configuração zero |
| Saída de 128K | Suporte para saídas extremamente longas | Geração de textos longos/Raciocínio profundo |
| API em Lote (50% de desconto) | Processamento em lote assíncrono | Processamento de dados em larga escala |
| Modo Rápido | Taxa 6x para obter saídas mais rápidas | Cenários de produção de baixa latência |
Gemini 3.1 Pro vs Claude Opus 4.6 场景选择指南
根据以上 8 个维度的对比,以下是明确的场景推荐:
选择 Gemini 3.1 Pro 的场景
| 场景 | 关键优势 | 推荐理由 |
|---|---|---|
| 抽象推理/数学 | ARC-AGI-2 +8.3pp | Deep Think Mini 极强 |
| 多步骤 Agent | MCP Atlas +9.7pp | 工作流执行力最强 |
| 视频/音频分析 | 原生多模态 | 唯一全模态选择 |
| 成本敏感项目 | 价格便宜 2-2.5x | 同等质量更低成本 |
| 大型文档分析 | 1M 上下文 | 超大上下文标准支持 |
| 科学研究 | GPQA +3.0pp | 科学推理能力最强 |
选择 Claude Opus 4.6 的场景
| 场景 | 关键优势 | 推荐理由 |
|---|---|---|
| 真实软件工程 | SWE-Bench 80.8% | 修复实际 Bug 最准 |
| 专家级知识工作 | GDPval-AA +289 Elo | 报告/分析/决策最强 |
| 计算机自动化 | OSWorld 72.7% | 唯一支持 GUI 操作 |
| 工具增强推理 | HLE+tools +1.7pp | 多工具协同最优 |
| 超长输出需求 | 128K 输出 | 长文/深度推理链 |
| 低延迟生产环境 | 快速模式 | 付费换速度 |
两个都用: 智能路由架构
很多生产环境中,最优解是同时使用两个模型,按任务类型智能路由:
| 任务类型 | 路由到 | 原因 | 预估占比 |
|---|---|---|---|
| 常规问答/翻译 | Gemini 3.1 Pro | 成本低,质量足够 | 40% |
| 代码生成/调试 | Claude Opus 4.6 | SWE-Bench 略优 | 20% |
| 推理/数学/科学 | Gemini 3.1 Pro | ARC-AGI-2 大幅领先 | 15% |
| Agent 工作流 | Gemini 3.1 Pro | MCP Atlas +9.7pp | 10% |
| 专家级分析/报告 | Claude Opus 4.6 | GDPval-AA 明显领先 | 10% |
| 视频/音频处理 | Gemini 3.1 Pro | 唯一全模态选择 | 5% |
按上述比例路由,整体成本相比全用 Claude 可节省约 55%,同时在各细分场景都获得最优质量。
Gemini 3.1 Pro vs Claude Opus 4.6 成本优化策略
策略 1: 分级处理
简单任务用 Gemini Low 模式 (最快最便宜),中等任务用 Gemini Medium,只有真正复杂的任务才用 Claude High 或 Gemini High (Deep Think Mini)。
策略 2: 批量与实时分离
实时请求用 Gemini 3.1 Pro (低延迟、低成本),离线批量处理可以用 Claude 的 Batch API (50% 折扣),综合成本接近。
策略 3: 上下文缓存
Gemini 提供上下文缓存 (输入 $0.20-$0.40/MTok),对于重复使用同一长文档的场景,缓存后成本可降低 80% 以上。
🚀 快速验证: 通过 APIYI apiyi.com 平台,你可以用同一个 API Key 同时调用 Gemini 3.1 Pro 和 Claude Opus 4.6。建议先用实际业务 prompt 做 A/B 测试,10 分钟即可得出结论。
Gemini 3.1 Pro vs Claude Opus 4.6 快速上手
以下代码演示如何通过 APIYI 统一接口同时调用两个模型进行对比测试:
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 统一接口
)
def compare_models(prompt, models=None):
"""对比两个模型的输出质量和速度"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-opus-4-6"]
results = {}
for model in models:
start = time.time()
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
elapsed = time.time() - start
results[model] = {
"time": f"{elapsed:.2f}s",
"tokens": resp.usage.total_tokens,
"answer": resp.choices[0].message.content[:300]
}
for model, data in results.items():
print(f"\n{'='*50}")
print(f"模型: {model}")
print(f"耗时: {data['time']} | Token: {data['tokens']}")
print(f"回答: {data['answer']}...")
# 测试推理能力
compare_models("请用链式推理解释为什么 0.1 + 0.2 不等于 0.3")
查看带思考级别控制的完整代码
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def compare_with_thinking(prompt, thinking_config=None):
"""对比不同思考级别下的模型表现"""
configs = [
{"model": "gemini-3.1-pro-preview", "label": "Gemini Medium",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 8000}}},
{"model": "gemini-3.1-pro-preview", "label": "Gemini High (Deep Think Mini)",
"extra": {"thinking": {"type": "enabled", "budget_tokens": 32000}}},
{"model": "claude-opus-4-6", "label": "Claude High (默认自适应)",
"extra": {}},
]
for cfg in configs:
start = time.time()
params = {
"model": cfg["model"],
"messages": [{"role": "user", "content": prompt}],
**cfg["extra"]
}
resp = client.chat.completions.create(**params)
elapsed = time.time() - start
print(f"\n[{cfg['label']}] {elapsed:.2f}s | {resp.usage.total_tokens} tokens")
print(f" → {resp.choices[0].message.content[:200]}...")
# 测试复杂推理
compare_with_thinking("证明: 对于所有正整数 n, n^3 - n 能被 6 整除")
Perguntas Frequentes
Q1: Qual é melhor: Gemini 3.1 Pro ou Claude Opus 4.6?
Não existe um "melhor" absoluto. O Gemini 3.1 Pro lidera em raciocínio abstrato (ARC-AGI-2 +8.3pp), Agentes de múltiplas etapas (MCP Atlas +9.7pp), multimodalidade e custo; já o Claude Opus 4.6 leva a melhor em engenharia de software real (SWE-Bench), trabalho de conhecimento especializado (GDPval-AA +289 Elo), operação de computador e raciocínio de ferramentas. Recomendamos realizar testes A/B no seu cenário real através da APIYI (apiyi.com).
Q2: As interfaces de API dos dois modelos são compatíveis? É fácil alternar entre eles?
Através da plataforma APIYI (apiyi.com), os dois modelos utilizam uma interface unificada compatível com OpenAI. Para alternar, basta modificar o parâmetro model (gemini-3.1-pro-preview → claude-opus-4-6), sem precisar alterar mais nada no código.
Q3: Qual devo escolher se meu orçamento for limitado?
Priorize o Gemini 3.1 Pro. O preço de entrada (input) é 40% do valor do Claude Opus 4.6 ($2 vs $5), e o preço de saída (output) é menos da metade ($12 vs $25). Na maioria dos benchmarks, o desempenho do Gemini é equivalente ou até superior, oferecendo um custo-benefício altíssimo. Use o Claude apenas em cenários onde ele é claramente superior, como no SWE-Bench ou em tarefas especialistas.
Q4: Posso usar os dois modelos simultaneamente para fazer um roteamento inteligente?
Sim. A arquitetura recomendada é: usar o Gemini 3.1 Pro para processar 80% das requisições rotineiras (baixo custo, raciocínio forte) e o Claude Opus 4.6 para os 20% de tarefas de nível especialista e cenários com uso intensivo de ferramentas. Com a interface unificada da APIYI (apiyi.com), basta identificar o tipo de tarefa no seu código e alternar o parâmetro model para implementar o roteamento inteligente.
Resumo: Decisão de Escolha Gemini 3.1 Pro vs Claude Opus 4.6
| # | Dimensão de Comparação | Gemini 3.1 Pro | Claude Opus 4.6 | Vencedor |
|---|---|---|---|---|
| 1 | Raciocínio Abstrato | ARC-AGI-2 77.1% | 68.8% | Gemini |
| 2 | Capacidade de Codificação | SWE-Bench 80.6% | 80.8% | Claude (leve vantagem) |
| 3 | Fluxo de Trabalho de Agentes | MCP Atlas 69.2% | 59.5% | Gemini |
| 4 | Tarefas Especializadas | GDPval 1317 | 1606 | Claude |
| 5 | Multimodalidade | Full multimodal (Texto/Img/Áudio/Vídeo) | Texto/Img | Gemini |
| 6 | Preço | $2/$12 por MTok | $5/$25 por MTok | Gemini (2x mais barato) |
| 7 | Janela de Contexto | 1M (Padrão) | 200K (1M beta) | Gemini |
| 8 | Saída Máxima | 64K tokens | 128K tokens | Claude |
| 9 | Sistema de Pensamento | Nível 3 + Deep Think Mini | Nível 4 + Adaptativo | Cada um com seus pontos fortes |
| 10 | Operação de Computador | Não suportado no momento | OSWorld 72.7% | Exclusivo Claude |
Sugestão Final:
- Foco em Custo-benefício → Gemini 3.1 Pro (2 vezes mais barato, raciocínio mais forte)
- Foco em Engenharia de Software → Claude Opus 4.6 (Liderança em SWE-Bench e GDPval)
- Foco em Multimodalidade → Gemini 3.1 Pro (Única escolha para áudio e vídeo nativos)
- Melhor Prática → Use ambos, com roteamento inteligente.
Recomendamos acessar ambos os modelos através da plataforma APIYI (apiyi.com), utilizando uma interface unificada para agilizar a implementação, testes A/B e a alternância flexível entre eles.
Referências
-
Blog oficial do Google: Anúncio de lançamento do Gemini 3.1 Pro
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - Descrição: Dados oficiais de benchmark e introdução de funcionalidades
- Link:
-
Comunicado oficial da Anthropic: Detalhes de lançamento do Claude Opus 4.6
- Link:
anthropic.com/news/claude-opus-4-6 - Descrição: Especificações técnicas e dados de benchmark do Claude Opus 4.6
- Link:
-
Artificial Analysis: Avaliação comparativa de terceiros
- Link:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-claude-opus-4-6-adaptive - Descrição: Comparação de benchmarks independentes e análise de desempenho
- Link:
-
Google DeepMind: Model Cards e avaliação de segurança
- Link:
deepmind.google/models/model-cards/gemini-3-1-pro - Descrição: Parâmetros técnicos detalhados e dados de segurança
- Link:
-
VentureBeat: Experiência aprofundada com o Deep Think Mini
- Link:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - Descrição: Avaliação prática do sistema de pensamento de três níveis
- Link:
📝 Autor: APIYI Team | Para troca de conhecimentos técnicos, visite APIYI apiyi.com
📅 Data de atualização: 20 de fevereiro de 2026
🏷️ Palavras-chave: Gemini 3.1 Pro vs Claude Opus 4.6, comparação de modelos, ARC-AGI-2, SWE-Bench, MCP Atlas, multimodal, chamadas de API