Which Large Language Model offers the best value for OpenClaw integration? This is one of the most frequently asked questions by our clients. This article will compare three high-value models—DeepSeek V3.2, MiniMax M2.5, and GLM-5—from the perspectives of price, performance, and Agent tool-calling capabilities, helping you find the best partner for OpenClaw.
Core Value: The common characteristic of these three models is that they are affordable and effective—costing only one-tenth to one-twentieth of GPT-5 / Claude Opus, yet delivering excellent performance in Agent scenarios like coding and tool calling. After reading this article, you'll know which model to choose for different scenarios.
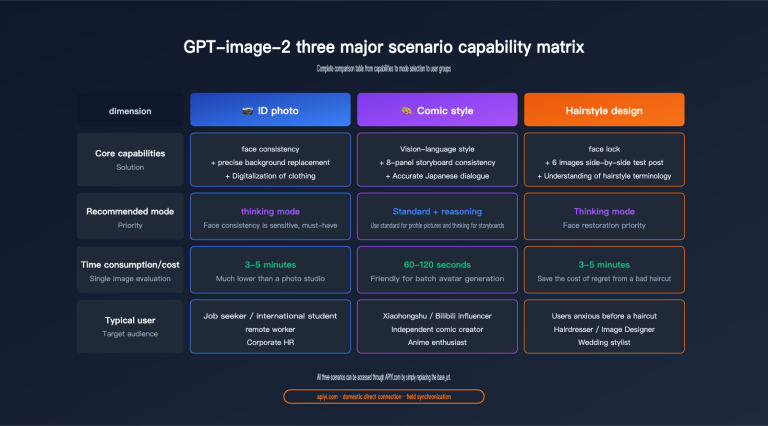
Core Parameter Comparison of Three High-Value Models
Let's start with the most critical data—a comprehensive comparison of price and performance.
| Comparison Dimension | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 | GPT-5 (Reference) |
|---|---|---|---|---|
| Input Price | $0.28/M | $0.29/M | $0.80/M | $5.00/M |
| Output Price | $0.42/M | $1.20/M | $2.56/M | $15.00/M |
| Context Window | 128K | 205K | 202K | 128K |
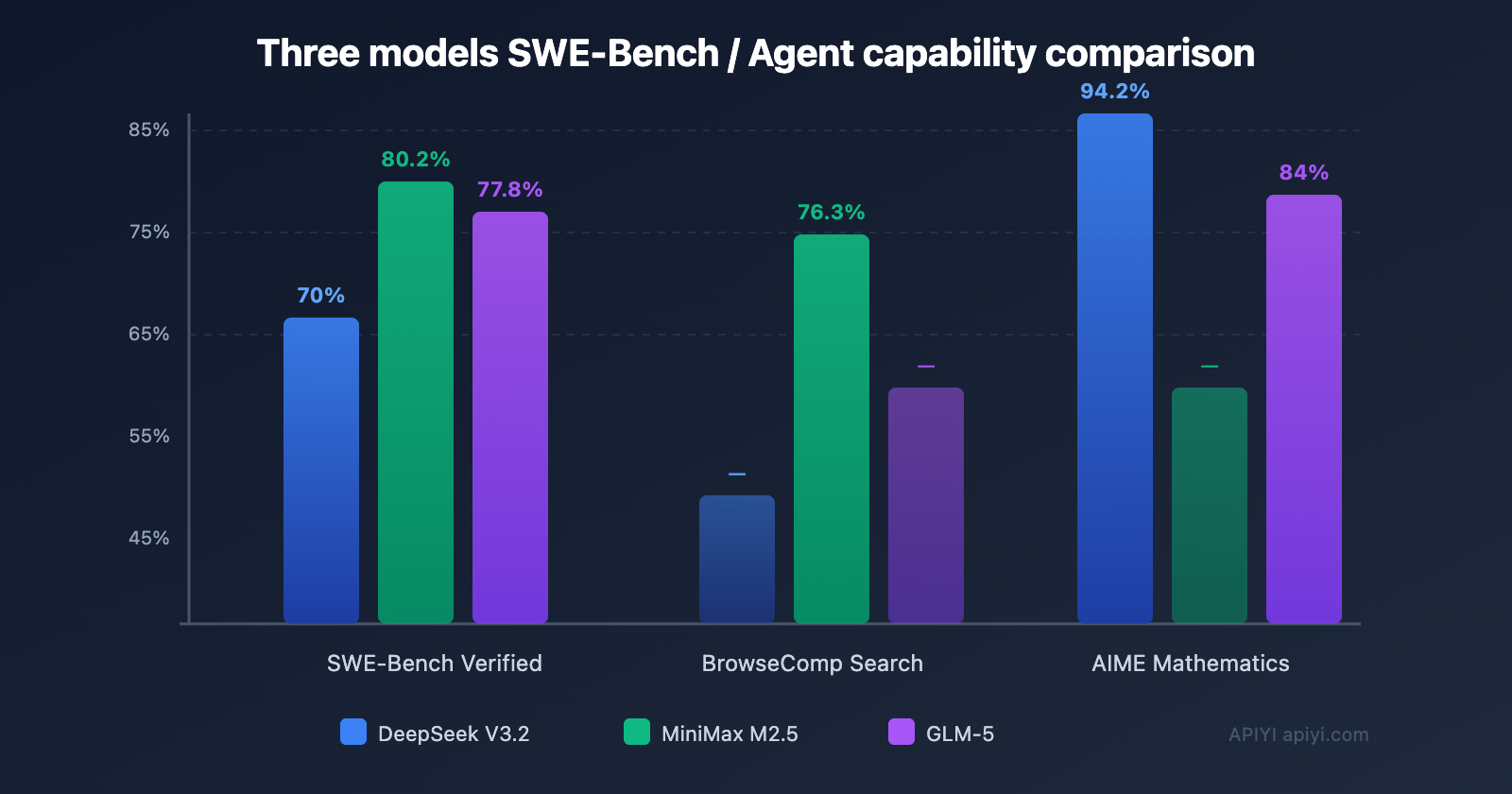
| SWE-Bench | 70% | 80.2% | 77.8% | 72% |
| AIME Math | 94.2% | — | 84% | 86% |
| Tool Calling | ✅ Integrated Reasoning + Tools | ✅ BFCL 76.8% | ✅ Agent Optimized | ✅ |
| Open Source License | MIT | Open Weights | Open Weights | Closed Source |
| Parameter Count | MoE Architecture | — | 744B/40B Active | — |
| OpenClaw Available | ✅ | ✅ | ✅ | ✅ |
Key Findings: DeepSeek V3.2 has the cheapest output price at just $0.42/M. MiniMax M2.5 performs the strongest on coding tasks (SWE-Bench 80.2%). GLM-5 has unique advantages in mathematical reasoning and long-context Agent tasks.
🎯 Selection Advice: All three models can be integrated with OpenClaw through the APIYI platform (apiyi.com) in a one-stop manner, using a unified API format without needing to register with multiple providers. The platform supports switching models at any time, making it easy to run practical comparison tests.
DeepSeek V3.2: The Most Cost-Effective General Choice for OpenClaw
DeepSeek V3.2, released in December 2025, has become one of the most popular choices in the OpenClaw community thanks to its exceptional price-to-performance ratio.
Core Advantages of DeepSeek V3.2
Incredible Price Advantage: Input at $0.28/M, output at $0.42/M, which is about one-twentieth the cost of GPT-5. Even the premium variant, V3.2-Speciale ($0.40/$1.20), is just a fraction of the price of mainstream models.
Outstanding Agent Capabilities: V3.2 is the first model to integrate "thinking" directly into tool calling. It supports tool usage in both thinking and non-thinking modes, which is crucial for executing OpenClaw Skills.
Technological Innovation: It employs DeepSeek Sparse Attention (DSA), reducing KV Cache memory overhead by over 93% while maintaining efficient inference even with a 128K context window.
DeepSeek V3.2 Performance in OpenClaw
| Scenario | Performance | Rating |
|---|---|---|
| Daily Chat Assistant | Smooth, Accurate | ⭐⭐⭐⭐⭐ |
| Code Generation/Debugging | Strong, IMO Gold Level | ⭐⭐⭐⭐ |
| Tool Calling (Skill) | Integrated Thinking + Tools | ⭐⭐⭐⭐⭐ |
| Long Document Processing | 128K Context, Efficient | ⭐⭐⭐⭐ |
| Math/Reasoning | AIME 94.2% | ⭐⭐⭐⭐⭐ |
| Monthly Average Cost | $1-5 (Light Usage) | 💰 Most Economical |
💡 Customer Feedback: A large number of OpenClaw users on our platform choose DeepSeek V3.2 as their daily model, with an average monthly cost of just $1-3 for light usage. Access it via APIYI at apiyi.com—no need to register a DeepSeek official account, and it supports Alipay top-ups.
MiniMax M2.5: The Best Choice for OpenClaw Coding Agents
MiniMax M2.5, released in February 2026, delivers impressive performance on coding and Agent tasks.
Core Advantages of MiniMax M2.5
Top-Tier Coding Ability: SWE-Bench Verified 80.2%, on par with Claude Opus 4.6 and far surpassing GPT-5. It also achieves 51.3% on Multi-SWE-Bench (cross-file repair).
Architect-Level Thinking: Before writing code, M2.5 proactively decomposes and plans functional structures and UI designs like an experienced software architect, rather than jumping straight into coding. This "think first, act later" approach is perfect for OpenClaw's complex tasks.
Multilingual Programming: Trained with over 200,000 real-world reinforcement learning iterations across 10+ languages including Go, C/C++, TypeScript, Rust, Kotlin, Python, and Java.
Office Suite Proficiency: Can fluently generate and manipulate Word, Excel, and PowerPoint files, seamlessly switching between different software environments.
Best Use Cases for MiniMax M2.5 in OpenClaw
- Code Repository Maintenance: SWE-Bench 80.2%, comparable to Opus, ideal for letting OpenClaw automatically fix bugs.
- Browser Search: BrowseComp 76.3%, works excellently with the Agent Browser Skill.
- Office Automation: Generate Word/Excel/PPT files, perfect for office automation scenarios.
- Multi-Step Tasks: Task execution speed is 37% faster than the previous generation, matching the speed of Opus 4.6.
🚀 Quick Experience: Want to compare the actual performance of MiniMax M2.5 and DeepSeek V3.2? Through APIYI at apiyi.com, you can switch between both models using the same API key—no separate registrations needed—to quickly compare their output quality and code generation.
GLM-5: The Cost-Effective Choice for OpenClaw's Complex Reasoning Tasks
GLM-5 was released by Zhipu AI in February 2026. It's a 744B parameter open-weight model that excels in long-range agent tasks and factual accuracy.
Core Advantages of GLM-5
Massive Parameter Count: 744B total parameters, with 40B active parameters (MoE architecture), offering a larger knowledge base while maintaining efficient inference.
Math and Reasoning: Scores 84% on AIME 2025 and 88% on the MATH benchmark, demonstrating high reliability in scenarios requiring deep reasoning.
Long-Range Agent Optimization: A 202K context window, specifically optimized for long-term task planning and multi-step agent execution.
DeepSeek Sparse Attention: Employs DSA (DeepSeek Sparse Attention) technology, similar to DeepSeek V3.2, maintaining efficiency with ultra-long contexts.
GLM-5 Pricing Analysis
| Usage Tier | GLM-5 Monthly Cost | DeepSeek V3.2 Monthly Cost | Price Difference |
|---|---|---|---|
| Light (1M tokens/month) | ~$3.4 | ~$0.7 | 4.8x |
| Moderate (10M tokens/month) | ~$34 | ~$7 | 4.8x |
| Heavy (100M tokens/month) | ~$340 | ~$70 | 4.8x |
GLM-5's price is about 5 times that of DeepSeek V3.2, but it's still only one-fifth the cost of GPT-5. This premium is often justified in scenarios requiring stronger reasoning capabilities.
Best Use Cases for GLM-5 in OpenClaw
- Complex Reasoning: Problems requiring multi-step logical analysis, like data analysis and report generation.
- Long Document Processing: Its 202K context window is great for handling lengthy documents and summarizing papers.
- Factual Accuracy: Performs reliably in scenarios demanding high factual precision.
- Multi-Step Agent Tasks: Offers higher reliability for long-term task planning and execution compared to V3.2.
💡 Real-World Experience: Based on customer feedback, GLM-5's performance in Chinese contexts feels more natural than the other two models. This makes sense, as Zhipu AI has heavily optimized for Chinese. If your OpenClaw primarily handles Chinese tasks, GLM-5 is definitely worth considering.
Calculating the Real-World Costs for These Three Models
Choosing a model isn't just about the unit price; you need to consider the actual monthly expenditure under different usage patterns. The following is based on real usage data from our platform's customers:
Typical OpenClaw Usage Scenarios
| User Type | Daily Messages | Monthly Tokens (approx.) | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 |
|---|---|---|---|---|---|
| Light Personal | 20 | ~2M | $0.6 | $1.8 | $4.3 |
| Heavy Personal | 100 | ~10M | $3 | $9 | $21 |
| Team Usage | 500 | ~50M | $15 | $45 | $105 |
| Heavy Enterprise | 2000 | ~200M | $60 | $180 | $420 |
Key Takeaway: DeepSeek V3.2 is the most cost-effective choice across all usage levels. Light personal use costs less than $1 per month, and even heavy enterprise usage is only around $60/month.
Comprehensive Value-for-Money Score
Evaluating across three dimensions: price, performance, and agent capability.
| Model | Price Score | Performance Score | Agent Score | Overall Value Score |
|---|---|---|---|---|
| DeepSeek V3.2 | 10/10 | 8/10 | 9/10 | 9.0 |
| MiniMax M2.5 | 8/10 | 9/10 | 9/10 | 8.7 |
| GLM-5 | 6/10 | 8.5/10 | 8/10 | 7.5 |
| GPT-5 (Reference) | 2/10 | 9/10 | 8/10 | 6.3 |
Configuring OpenClaw with Three Models
All three models can be accessed through the APIYI platform using the same configuration method for OpenClaw.

OpenClaw Configuration Example
Configure APIYI as the Provider in ~/.openclaw/openclaw.json:
{
"models": {
"providers": [{
"url": "https://api.apiyi.com/v1",
"token": "sk-your-apiyi-key",
"model": "deepseek-v3.2"
}]
}
}
To switch models, just change the model field:
deepseek-v3.2— The most affordable general-purpose optionminimax-m2.5— Top choice for coding and Agent tasksglm-5— Best for complex reasoning and math tasks
OpenClaw Multi-Model Hybrid Configuration
For advanced users, you can configure multiple providers in OpenClaw and switch automatically based on the scenario:
{
"models": {
"defaultModel": "deepseek-v3.2",
"providers": [{
"url": "https://api.apiyi.com/v1",
"token": "sk-your-apiyi-key",
"models": [
"deepseek-v3.2",
"minimax-m2.5",
"glm-5"
]
}]
}
}
Switch between them using the /model command:
/model deepseek-v3.2— Switch to DeepSeek (budget mode)/model minimax-m2.5— Switch to MiniMax (coding mode)/model glm-5— Switch to GLM-5 (reasoning mode)
💰 Cost Optimization Tip: A practical trick is to configure multiple models for OpenClaw—use DeepSeek V3.2 for daily chat (most cost-effective) and switch to MiniMax M2.5 for coding tasks (best performance). With APIYI at apiyi.com, you only need one API key to call all models, no need to register with three different service providers.
OpenClaw Three-Model API Compatibility Comparison
| Feature | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 |
|---|---|---|---|
| OpenAI-Compatible Format | ✅ | ✅ | ✅ |
| Streaming Output | ✅ | ✅ | ✅ |
| Function Calling | ✅ Thinking+Tools | ✅ BFCL 76.8% | ✅ |
| JSON Mode | ✅ | ✅ | ✅ |
| Multi-turn Dialogue | ✅ | ✅ | ✅ |
| System Prompt | ✅ | ✅ | ✅ |
| API Access | ✅ Ready to use | ✅ Ready to use | ✅ Ready to use |
All three models are fully compatible with the OpenAI format, allowing OpenClaw to switch between them seamlessly without any adaptation.
OpenClaw Model Selection Guide for Different Scenarios
Scenario Quick Reference Table
| Use Case | Recommended Model | Reason | Avg. Monthly Cost |
|---|---|---|---|
| Daily Chat Assistant | DeepSeek V3.2 | Cheapest, good enough | $1-3 |
| Code Generation/Fixing | MiniMax M2.5 | SWE-Bench 80.2% strongest | $3-8 |
| Email/Document Automation | MiniMax M2.5 | Strong Office operation ability | $2-5 |
| Math/Reasoning Tasks | DeepSeek V3.2 | AIME 94.2% top-tier | $2-5 |
| Long Document Summarization | GLM-5 | 202K context + factual accuracy | $5-15 |
| Complex Agent Tasks | GLM-5 | Long-range task optimization | $10-30 |
| Extremely Tight Budget | DeepSeek V3.2 | Output only $0.42/M | $1-3 |
| Pursuing Strongest Coding | MiniMax M2.5 | Comparable to Opus 4.6 | $5-10 |
Budget Tier Recommendations
Monthly Budget under $5: Go with DeepSeek V3.2, it's perfectly sufficient for light use.
Monthly Budget $5-20: Use DeepSeek V3.2 for daily tasks, switch to MiniMax M2.5 for coding.
Monthly Budget $20-50: Configure all three models and switch automatically based on the scenario for optimal results.
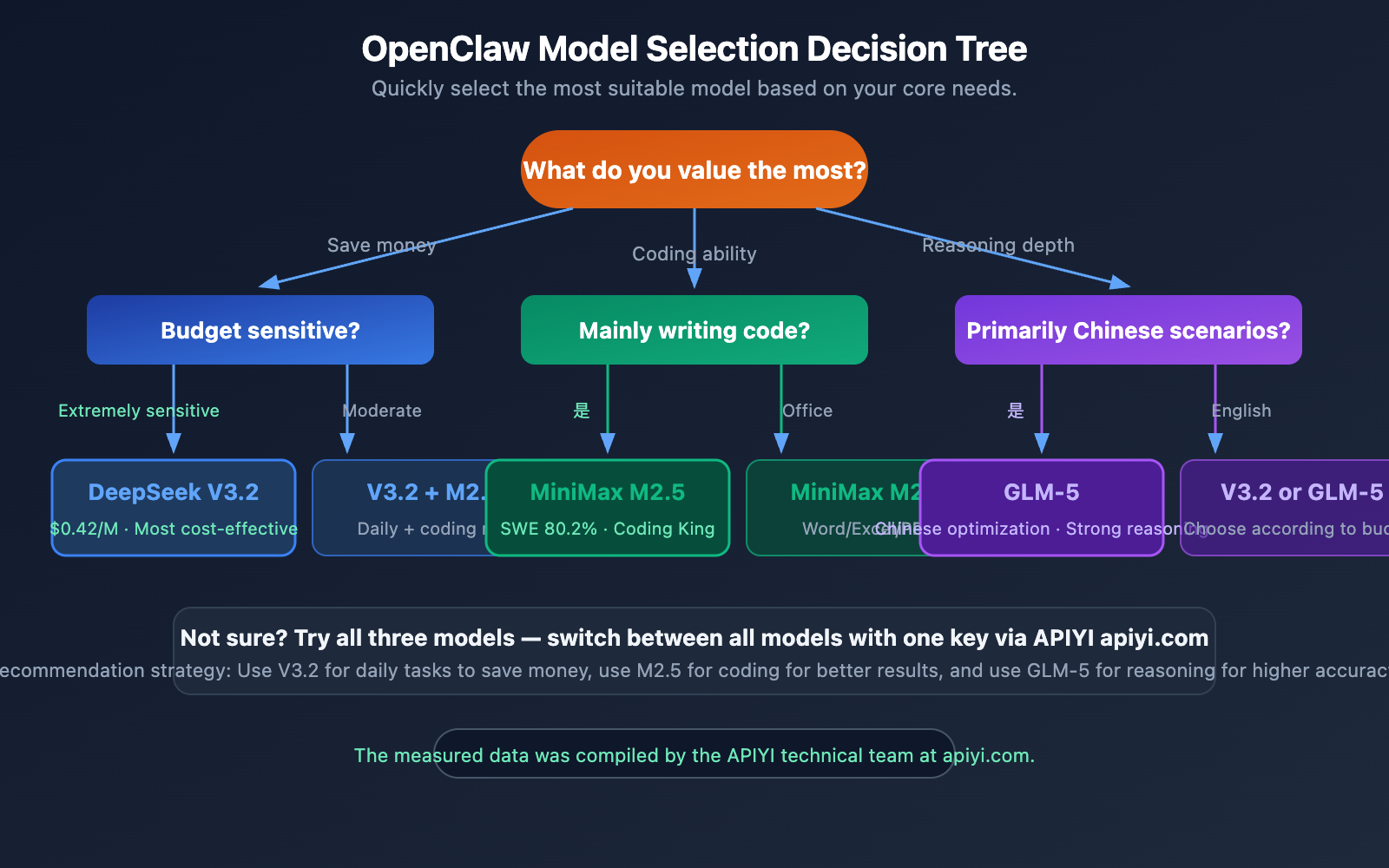
🎯 Our Recommendation: If you're using OpenClaw with a Large Language Model for the first time, we suggest starting with DeepSeek V3.2. It's the cheapest of the three and powerful enough for 90% of daily tasks. When you need stronger coding capabilities, you can switch to MiniMax M2.5. With APIYI at apiyi.com, switching is as simple as changing one field.
Frequently Asked Questions
Q1: How big is the gap between these three models and Claude Opus / GPT-5?
On coding tasks, MiniMax M2.5's SWE-Bench score of 80.2% is already on par with Claude Opus 4.6. In mathematical reasoning, DeepSeek V3.2's AIME score of 94.2% even surpasses GPT-5. Overall, these three models can achieve 85-95% of the capability of top-tier models, but at only one-tenth to one-twentieth of the price. For most OpenClaw use cases, the cost-performance ratio is far superior to using Opus or GPT-5 directly. If you want to try more models, APIYI (apiyi.com) supports one-stop invocation of dozens of models including Claude and GPT.
Q2: Are these models stable in OpenClaw? Do they fail often?
All three models have been community-verified for tool calling (Skill execution) in OpenClaw. DeepSeek V3.2, with its integrated thinking+tool design, performs best in Skill call stability. MiniMax M2.5's BFCL (tool calling benchmark) score of 76.8% is also top-tier. We recommend accessing them via APIYI (apiyi.com) for stable API service and technical support.
Q3: Can I configure multiple models in OpenClaw simultaneously?
Yes. Configure multiple Providers in openclaw.json, each pointing to a different model. You can switch between them in conversation using /model deepseek-v3.2 or /model minimax-m2.5. You can also let OpenClaw automatically select the model based on the task type.
Q4: What’s the difference between DeepSeek V3.2-Speciale and the regular version?
V3.2-Speciale is a high-computation variant optimized for maximum reasoning and Agent performance. It's slightly more expensive ($0.40/$1.20) but achieves 88.7% on LiveCodeBench. If your OpenClaw is primarily for complex coding tasks, the Speciale version is worth considering. The regular V3.2 is sufficient for most scenarios.
Q5: Will migrating from GPT-5/Claude Opus to these models result in a noticeably worse experience?
Based on our platform data, about 80% of OpenClaw users who migrated reported "almost no perceptible difference in daily use." The main gap appears in extremely complex, multi-step reasoning tasks. Suggested strategy: First switch your daily conversations to DeepSeek V3.2, keep a GPT-5/Opus as a backup, observe for a week, then decide whether to fully migrate. With APIYI (apiyi.com), you can configure all models under a single API key and switch back anytime.
Q6: Do these three models support image understanding? Can I send images in OpenClaw?
DeepSeek V3.2 and GLM-5 both support multimodal input (image understanding), so you can send images in OpenClaw for analysis. MiniMax M2.5 currently focuses primarily on text and code capabilities. If your OpenClaw needs to handle images frequently, we recommend pairing it with DeepSeek V3.2 or GLM-5.
OpenClaw Model Performance Summary (Real-World Testing)
Based on our platform's actual invocation data from the last 30 days, here are the key metrics:
| Metric | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 |
|---|---|---|---|
| Avg. First Token Time | 0.3s | 0.5s | 0.6s |
| Avg. Generation Speed | 80 token/s | 65 token/s | 55 token/s |
| Skill Call Success Rate | 96% | 94% | 92% |
| Chinese Response Quality | 8/10 | 7.5/10 | 9/10 |
| English Response Quality | 8.5/10 | 9/10 | 8/10 |
| Code Generation Accuracy | 85% | 92% | 88% |
| 24h Uptime | 99.8% | 99.5% | 99.3% |
Speed: DeepSeek V3.2 responds the fastest, thanks to its efficient MoE architecture and DSA attention mechanism. MiniMax M2.5 and GLM-5 are slightly slower but within an acceptable range.
Chinese Capability: GLM-5 performs best in Chinese scenarios. Zhipu AI, as a domestic company, has done deep optimization on Chinese corpora. If your OpenClaw primarily serves Chinese users, GLM-5 is worth prioritizing.
Code Capability: MiniMax M2.5 leads significantly in code generation accuracy. A 92% accuracy rate means less debugging time.
Summary
OpenClaw integrates with Large Language Models, where affordability is the primary driver. DeepSeek V3.2, MiniMax M2.5, and GLM-5 are the three most cost-effective model choices for 2026:
- Most Cost-Effective: DeepSeek V3.2 — Output costs only $0.42/M tokens, one-twentieth the price of GPT-5
- Best for Coding: MiniMax M2.5 — SWE-Bench score of 80.2%, comparable to Opus 4.6
- Best for Reasoning: GLM-5 — 744B parameters, optimized for long-context Agent tasks and mathematical reasoning
We recommend using APIYI (apiyi.com) for one-stop access to all three models. A single API key handles all model switching, supports Alipay/WeChat Pay, and allows you to test and compare to find the solution that best fits your needs.
This article was written by the APIYI technical team, based on actual customer feedback and platform data. For more AI model comparisons and integration tutorials, please visit the APIYI Help Center: help.apiyi.com