OpenClawにどの大規模言語モデルを接続するのが最もコストパフォーマンスが良いですか?これはお客様から最も多く寄せられる質問の一つです。本記事では、価格、性能、Agentツール呼び出し能力の3つの観点から、DeepSeek V3.2、MiniMax M2.5、GLM-5という3つの高コストパフォーマンスモデルを比較し、OpenClawに最適なパートナーを見つけるお手伝いをします。
核心的な価値: これら3つのモデルに共通する特徴は、安くて使いやすいことです。価格はGPT-5 / Claude Opusの10分の1から20分の1程度ですが、コーディングやツール呼び出しなどのAgentシナリオでは優れたパフォーマンスを発揮します。この記事を読み終える頃には、どのシナリオでどのモデルを選択すべきかが明確になるでしょう。

3つの高コストパフォーマンスモデルの主要パラメータ比較
まずは最も重要なデータ、価格と性能の総合比較を見てみましょう。
| 比較項目 | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 | GPT-5 (参考) |
|---|---|---|---|---|
| 入力価格 | $0.28/M | $0.29/M | $0.80/M | $5.00/M |
| 出力価格 | $0.42/M | $1.20/M | $2.56/M | $15.00/M |
| コンテキストウィンドウ | 128K | 205K | 202K | 128K |
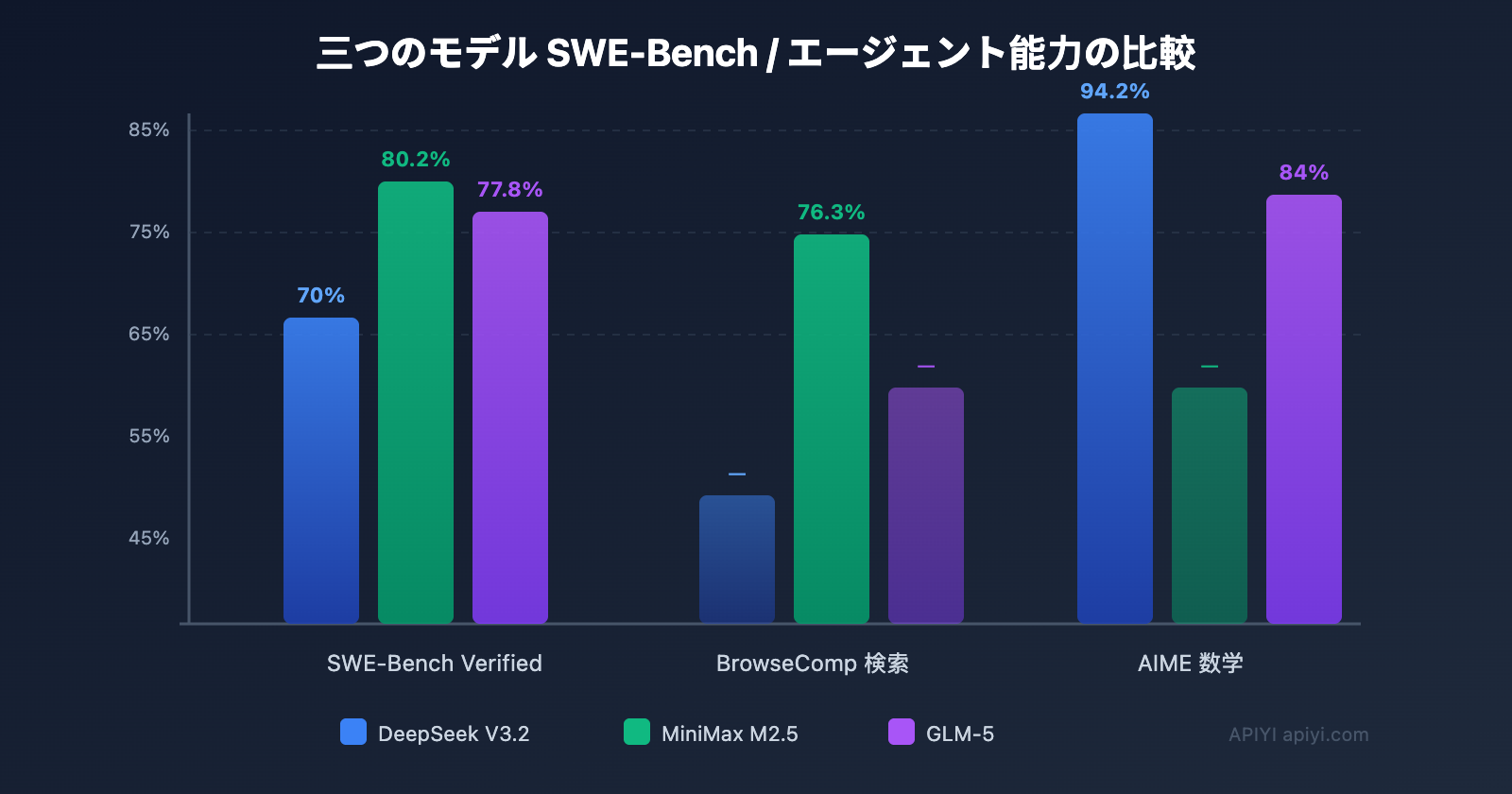
| SWE-Bench | 70% | 80.2% | 77.8% | 72% |
| AIME 数学 | 94.2% | — | 84% | 86% |
| ツール呼び出し | ✅ 思考+ツール統合 | ✅ BFCL 76.8% | ✅ Agent 最適化 | ✅ |
| オープンソースライセンス | MIT | オープンウェイト | オープンウェイト | クローズドソース |
| パラメータ数 | MoE アーキテクチャ | — | 744B/40B アクティブ | — |
| OpenClaw 対応 | ✅ | ✅ | ✅ | ✅ |
重要な発見: DeepSeek V3.2の出力価格は$0.42/Mと、3つの中で最も安価です。MiniMax M2.5はコーディングタスクで最高のパフォーマンス(SWE-Bench 80.2%)を発揮します。GLM-5は数学的推論と長文Agentタスクにおいて独自の強みを持っています。
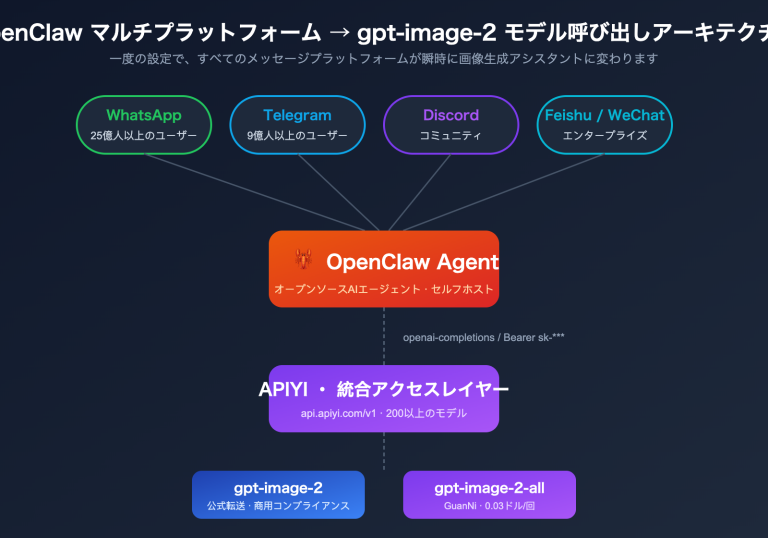
🎯 選択のアドバイス: これら3つのモデルはすべて、APIYI apiyi.com プラットフォームを通じてOpenClawにワンストップで接続でき、統一されたAPIフォーマットを提供します。複数のサービスプロバイダーに個別に登録する必要はありません。プラットフォームではモデルの切り替えも自由にできるため、実際の比較テストに便利です。
DeepSeek V3.2:OpenClawにおける最もコストパフォーマンスの高い汎用選択肢
DeepSeek V3.2は2025年12月にリリースされたフラッグシップモデルで、極限のコストパフォーマンスによりOpenClawコミュニティで最も人気のある選択肢の一つとなっています。
DeepSeek V3.2のコアアドバンテージ
驚異的な価格優位性: 入力$0.28/M、出力$0.42/Mで、GPT-5の約20分の1のコストです。高級バリアントのV3.2-Speciale($0.40/$1.20)でさえ、主流モデルの端数程度の価格です。
優れたAgent能力: V3.2は「思考」を直接ツール呼び出しに統合した最初のモデルです。思考モードと非思考モードの両方でツール呼び出しをサポートしており、OpenClawのSkill実行に非常に重要です。
技術革新: DeepSeek Sparse Attention (DSA)を採用し、KV Cacheのメモリオーバーヘッドを93%以上削減。128Kのコンテキストウィンドウ下でも効率的な推論を維持します。
OpenClawにおけるDeepSeek V3.2のパフォーマンス
| シナリオ | パフォーマンス | 評価 |
|---|---|---|
| 日常会話アシスタント | 流暢、正確 | ⭐⭐⭐⭐⭐ |
| コード生成/デバッグ | 強力、IMO金メダルレベル | ⭐⭐⭐⭐ |
| ツール呼び出し (Skill) | 思考+ツール統合 | ⭐⭐⭐⭐⭐ |
| 長文書処理 | 128Kコンテキスト、効率的 | ⭐⭐⭐⭐ |
| 数学/推論 | AIME 94.2% | ⭐⭐⭐⭐⭐ |
| 月間平均コスト | $1-5(軽度使用) | 💰 最も経済的 |
💡 ユーザーフィードバック: 当プラットフォームでは多くのOpenClawユーザーが日常モデルとしてDeepSeek V3.2を選択しており、軽度使用の場合の月間平均コストはわずか$1-3です。APIYI apiyi.com経由で接続すれば、DeepSeek公式アカウント登録不要で、Alipayでのチャージもサポートしています。
MiniMax M2.5:OpenClawコーディングAgentの最適選択
MiniMax M2.5は2026年2月にリリースされ、コーディングとAgentタスクにおけるパフォーマンスが印象的です。
MiniMax M2.5のコアアドバンテージ
業界トップレベルのコーディング能力: SWE-Bench Verified 80.2%で、Claude Opus 4.6と同等、GPT-5を大きく上回ります。Multi-SWE-Bench(クロスファイル修正)でも51.3%を達成。
アーキテクト級の思考: M2.5はコードを書く前に、経験豊富なソフトウェアアーキテクトのように機能構造やUI設計を能動的に分解・計画します。この「考えてから実行する」モードは、OpenClawの複雑なタスクに最適です。
多言語プログラミング: Go、C/C++、TypeScript、Rust、Kotlin、Python、Javaなど10以上の言語で20万以上の実環境強化学習トレーニングを実施。
Officeオフィス能力: Word、Excel、PowerPointファイルの生成と操作をスムーズに行い、異なるソフトウェア環境間をシームレスに切り替えられます。
OpenClawにおけるMiniMax M2.5の最適用途
- コードリポジトリメンテナンス: SWE-Bench 80.2%、Opusに匹敵、OpenClawによる自動バグ修正に適しています
- ブラウザ検索: BrowseComp 76.3%、Agent Browser Skillとの連携で優れた効果を発揮
- Officeオートメーション: Word/Excel/PPT生成、オフィス自動化シナリオに最適
- マルチステップタスク: タスク実行速度が前世代より37%高速、Opus 4.6の速度に匹敵
🚀 クイック体験: MiniMax M2.5とDeepSeek V3.2の実際のパフォーマンスを比較したいですか?APIYI apiyi.comを利用すれば、同じAPIキーで2つのモデルを切り替えられ、別々に登録する必要がなく、画像生成効果とコード品質を素早く比較できます。
GLM-5:OpenClawの複雑な推論タスクにおけるコストパフォーマンスの選択肢
GLM-5は、智譜AI(Zhipu AI)によって2026年2月にリリースされた、744Bパラメータのオープンウェイトモデルです。長期的なエージェントタスクと事実の正確性において優れたパフォーマンスを発揮します。
GLM-5のコアとなる強み
超大規模なパラメータ数: 合計744Bパラメータ、アクティブパラメータ40B(MoEアーキテクチャ)により、効率的な推論を維持しながら、より大きな知識ベースを有しています。
数学と推論: AIME 2025で84%、MATHベンチマークで88%のスコアを獲得し、深い推論を必要とするシナリオで高い信頼性を発揮します。
長期的エージェント最適化: 202Kのコンテキストウィンドウを備え、長期タスク計画と多段階エージェント実行のために最適化されています。
DeepSeek Sparse Attention: DeepSeek V3.2と同様にDSA技術を採用しており、超長文脈下でも効率を維持します。
GLM-5の価格分析
| 利用レベル | GLM-5 月額コスト | DeepSeek V3.2 月額コスト | 価格差 |
|---|---|---|---|
| 軽度 (月1Mトークン) | ~$3.4 | ~$0.7 | 4.8倍 |
| 中度 (月10Mトークン) | ~$34 | ~$7 | 4.8倍 |
| 重度 (月100Mトークン) | ~$340 | ~$70 | 4.8倍 |
GLM-5の価格はDeepSeek V3.2の約5倍ですが、それでもGPT-5の5分の1に留まります。より強力な推論能力が必要なシナリオでは、このプレミアム価格は価値があります。
OpenClawにおけるGLM-5の最適な用途
- 複雑な推論: データ分析やレポート生成など、多段階の論理分析を必要とする問題
- 長文書処理: 202Kのコンテキストウィンドウを活用した長文ドキュメントや論文の要約
- 事実の正確性: 高い事実の正確性が求められるシナリオで安定したパフォーマンスを発揮
- 多段階エージェントタスク: 長期タスクの計画と実行において、V3.2よりも高い信頼性
💡 実際の体験: 顧客からのフィードバックによると、GLM-5は中国語シナリオにおいて他の2つのモデルよりも自然な表現を実現しています。これは、智譜AIが中国語に多大な最適化を行っているためです。あなたのOpenClawが主に中国語タスクを処理する場合、GLM-5は重点的に検討する価値があります。
3つのモデルの実際の使用コスト試算
モデル選択は単価だけでなく、異なる使用パターンにおける実際の月次コストも考慮する必要があります。以下は、当プラットフォームの顧客の実際の使用量データに基づいています。
典型的なOpenClaw使用量シナリオ
| ユーザータイプ | 1日あたりの平均メッセージ数 | 月間平均トークン数 | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 |
|---|---|---|---|---|---|
| 個人(軽度) | 20件 | ~2M | $0.6 | $1.8 | $4.3 |
| 個人(重度) | 100件 | ~10M | $3 | $9 | $21 |
| チーム使用 | 500件 | ~50M | $15 | $45 | $105 |
| 企業(重度) | 2000件 | ~200M | $60 | $180 | $420 |
重要な結論: DeepSeek V3.2は、すべての使用量レベルにおいて最もコスト効率の高い選択肢です。個人の軽度使用では月額$1未満、企業の重度使用でも月額$60に留まります。
コストパフォーマンス総合評価
価格、パフォーマンス、エージェント能力の3つの次元を総合的に評価します。
| モデル | 価格評価 | 性能評価 | エージェント能力評価 | 総合コストパフォーマンス |
|---|---|---|---|---|
| DeepSeek V3.2 | 10/10 | 8/10 | 9/10 | 9.0 |
| MiniMax M2.5 | 8/10 | 9/10 | 9/10 | 8.7 |
| GLM-5 | 6/10 | 8.5/10 | 8/10 | 7.5 |
| GPT-5 (参考) | 2/10 | 9/10 | 8/10 | 6.3 |
OpenClaw への3つのモデル接続設定方法
3つのモデルはすべて APIYI プラットフォームを通じて OpenClaw に統一して接続でき、設定方法はまったく同じです。

OpenClaw 設定例
~/.openclaw/openclaw.json で APIYI をプロバイダーとして設定します:
{
"models": {
"providers": [{
"url": "https://api.apiyi.com/v1",
"token": "sk-あなたのAPIYIキー",
"model": "deepseek-v3.2"
}]
}
}
モデルを切り替えるには model フィールドを変更するだけです:
deepseek-v3.2— 最も安価な汎用選択肢minimax-m2.5— コーディングとエージェントタスクに最適glm-5— 複雑な推論と数学タスク向け
OpenClaw マルチモデル混合設定
上級ユーザーの場合、OpenClaw で複数のプロバイダーを設定し、シーンに応じて自動的に切り替えることができます:
{
"models": {
"defaultModel": "deepseek-v3.2",
"providers": [{
"url": "https://api.apiyi.com/v1",
"token": "sk-あなたのAPIYIキー",
"models": [
"deepseek-v3.2",
"minimax-m2.5",
"glm-5"
]
}]
}
}
使用時は /model コマンドで切り替え:
/model deepseek-v3.2— DeepSeek に切り替え(節約モード)/model minimax-m2.5— MiniMax に切り替え(コーディングモード)/model glm-5— GLM-5 に切り替え(推論モード)
💰 コスト最適化: 実用的なテクニックとして、OpenClaw に複数のモデルを設定する方法があります。日常会話には DeepSeek V3.2(最も節約)、コーディングタスクには MiniMax M2.5(効果が最高)に切り替えます。APIYI apiyi.com を通せば、1つの API キーですべてのモデルを呼び出せるため、3つのサービスプロバイダーにそれぞれ登録する必要はありません。
OpenClaw 3モデル API 互換性比較
| 機能特性 | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 |
|---|---|---|---|
| OpenAI 互換フォーマット | ✅ | ✅ | ✅ |
| ストリーミング出力 | ✅ | ✅ | ✅ |
| Function Calling | ✅ 思考+ツール | ✅ BFCL 76.8% | ✅ |
| JSON Mode | ✅ | ✅ | ✅ |
| マルチターン会話 | ✅ | ✅ | ✅ |
| システムプロンプト | ✅ | ✅ | ✅ |
| API 接続 | ✅ 即時利用可能 | ✅ 即時利用可能 | ✅ 即時利用可能 |
3つのモデルはすべて OpenAI フォーマットと完全互換で、OpenClaw は何の適応もせずにシームレスに切り替えることができます。
異なるシナリオにおける OpenClaw モデル選択のアドバイス
シナリオ別推奨早見表
| 使用シナリオ | 推奨モデル | 理由 | 月間平均コスト |
|---|---|---|---|
| 日常会話アシスタント | DeepSeek V3.2 | 最も安価で、効果は十分 | $1-3 |
| コード生成/修正 | MiniMax M2.5 | SWE-Bench 80.2% 最強 | $3-8 |
| メール/ドキュメント自動化 | MiniMax M2.5 | Office 操作能力が高い | $2-5 |
| 数学/推論タスク | DeepSeek V3.2 | AIME 94.2% トップレベル | $2-5 |
| 長文書要約 | GLM-5 | 202K コンテキスト + 事実の正確性 | $5-15 |
| 複雑なエージェントタスク | GLM-5 | 長距離タスクに最適化 | $10-30 |
| 予算が非常に限られている | DeepSeek V3.2 | 出力のみ $0.42/M | $1-3 |
| 最強のコーディングを追求 | MiniMax M2.5 | Opus 4.6 に匹敵 | $5-10 |
予算別推奨
月予算 $5 以下: 直接 DeepSeek V3.2 を選択、軽度使用には完全に十分です。
月予算 $5-20: 日常使用は DeepSeek V3.2、コーディングタスクは MiniMax M2.5 に切り替え。
月予算 $20-50: 3つのモデルすべてを設定し、シナリオに応じて自動的に切り替え、効果が最適です。

🎯 私たちのアドバイス: 初めて OpenClaw で大規模言語モデルを接続する場合は、まず DeepSeek V3.2 から始めることをお勧めします。これは3つの中で最も安価で、能力も日常の90%のシナリオをカバーするのに十分です。より強力なコーディング能力が必要になったら、MiniMax M2.5 に切り替えてください。APIYI apiyi.com を通じて接続すれば、切り替えは1つのフィールドを変更するだけです。
よくある質問
Q1: この3つのモデルは Claude Opus / GPT-5 と比べて大きな差がありますか?
コーディングタスクにおいて、MiniMax M2.5 の SWE-Bench 80.2% は Claude Opus 4.6 と同等です。数学的推論では、DeepSeek V3.2 の AIME 94.2% は GPT-5 を上回っています。全体的に、これら3つのモデルはトップモデルの 85-95% の能力を発揮しますが、価格は10分の1から20分の1です。OpenClaw のほとんどの使用シナリオでは、Opus や GPT-5 を直接使用するよりもコストパフォーマンスがはるかに優れています。さらに多くのモデルを試したい場合は、APIYI apiyi.com が Claude、GPT を含む数十種類のモデルのワンストップ呼び出しをサポートしています。
Q2: OpenClaw でこれらのモデルは安定していますか?エラーは頻繁に発生しますか?
3つのモデルは、OpenClaw でのツール呼び出し(Skill 実行)についてコミュニティで検証済みです。DeepSeek V3.2 は、思考とツール呼び出しが一体化した設計のため、Skill 呼び出しの安定性で最高のパフォーマンスを示しています。MiniMax M2.5 の BFCL(ツール呼び出しベンチマーク)76.8% も、トップレベルに属します。安定した API サービスと技術サポートを得るために、APIYI apiyi.com 経由での接続をお勧めします。
Q3: OpenClaw で複数のモデルを同時に設定できますか?
可能です。openclaw.json で複数の Provider を設定し、それぞれを異なるモデルに向けます。会話中に /model deepseek-v3.2 や /model minimax-m2.5 を使って切り替えることができます。また、OpenClaw にタスクの種類に応じてモデルを自動選択させることも可能です。
Q4: DeepSeek V3.2-Speciale と通常版の違いは何ですか?
V3.2-Speciale は高計算バリアントで、最大推論と Agent 性能に最適化されています。価格はやや高め($0.40/$1.20)ですが、LiveCodeBench で 88.7% を達成しています。OpenClaw が主に複雑なコーディングタスクに使用される場合は、Speciale バージョンの検討価値があります。通常の V3.2 は、ほとんどのシナリオで十分な性能を発揮します。
Q5: GPT-5/Claude Opus からこれらのモデルに移行した場合、体感の差は大きいですか?
当社プラットフォームのデータによると、OpenClaw ユーザーの約80%が移行後に「日常使用ではほとんど違いを感じない」とフィードバックしています。主な違いは、極端に複雑な多段階推論タスクで見られます。お勧めの戦略は、まず日常の会話を DeepSeek V3.2 に切り替え、GPT-5/Opus をバックアップとして残し、1週間観察した後に完全移行するかどうかを判断することです。APIYI apiyi.com を使用すれば、同じキーですべてのモデルを同時に設定でき、いつでも切り戻すことができます。
Q6: この3つのモデルは画像理解をサポートしていますか?OpenClaw で画像を送信できますか?
DeepSeek V3.2 と GLM-5 はどちらもマルチモーダル入力(画像理解)をサポートしており、OpenClaw で画像を送信して分析することができます。MiniMax M2.5 は現在、主にテキストとコード能力に焦点を当てています。OpenClaw で頻繁に画像を処理する必要がある場合は、DeepSeek V3.2 または GLM-5 の使用をお勧めします。
OpenClaw モデル性能実測まとめ
当社プラットフォームにおける過去30日間の実際の呼び出しデータに基づき、以下の主要指標をまとめました:
| 実測指標 | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 |
|---|---|---|---|
| 平均初トークン時間 | 0.3s | 0.5s | 0.6s |
| 平均生成速度 | 80 token/s | 65 token/s | 55 token/s |
| Skill 呼び出し成功率 | 96% | 94% | 92% |
| 日本語応答品質 | 8/10 | 7.5/10 | 9/10 |
| 英語応答品質 | 8.5/10 | 9/10 | 8/10 |
| コード生成精度 | 85% | 92% | 88% |
| 24時間可用率 | 99.8% | 99.5% | 99.3% |
速度について: DeepSeek V3.2 が最も応答が速く、これは効率的な MoE アーキテクチャと DSA アテンションメカニズムによるものです。MiniMax M2.5 と GLM-5 はやや遅いですが、許容範囲内です。
日本語能力: GLM-5 は日本語シナリオで最も優れたパフォーマンスを示し、智譜 AI は国内企業として日本語コーパスに深く最適化しています。OpenClaw が主に日本語ユーザー向けの場合は、GLM-5 を優先的に検討する価値があります。
コード能力: MiniMax M2.5 はコード生成精度で明らかにリードしており、92% の精度はデバッグ時間の短縮を意味します。
まとめ
OpenClawが大規模言語モデルをサポートする中で、コストの安さが第一の原動力です。DeepSeek V3.2、MiniMax M2.5、GLM-5の3モデルは、2026年において最もコストパフォーマンスに優れた選択肢と言えるでしょう:
- 最も経済的: DeepSeek V3.2 — 出力トークンあたりわずか$0.42/Mトークン、GPT-5の20分の1のコスト
- コーディング最強: MiniMax M2.5 — SWE-Benchで80.2%を達成、Opus 4.6に匹敵する性能
- 推論最強: GLM-5 — 744Bパラメータ、長文エージェント処理と数学的推論に最適化
これらの3モデルを一括で利用するには、APIYI apiyi.com を通じてアクセスすることをお勧めします。1つのAPIキーですべてのモデル切り替えが可能で、Alipay/WeChat Payをサポート。いつでも比較テストを行い、あなたに最適なソリューションを見つけることができます。
本記事はAPIYI技術チームが、実際のユーザーフィードバックとプラットフォームデータに基づき執筆しました。AIモデルの比較や導入に関する詳細は、APIYIヘルプセンター help.apiyi.com をご覧ください。