OpenClaw 接入哪个大模型性价比最高?这是我们客户问得最多的问题之一。本文将从 价格、性能、Agent 工具调用能力三个维度,对比 DeepSeek V3.2、MiniMax M2.5、GLM-5 三款高性价比模型,帮你找到 OpenClaw 的最佳搭档。
核心价值: 这三款模型的共同特点是便宜且好用——价格只有 GPT-5 / Claude Opus 的十分之一到二十分之一,但在编码、工具调用等 Agent 场景中表现出色。读完本文,你将清楚在不同场景下该选择哪个模型。

三款高性价比模型核心参数对比
先看最关键的数据——价格和性能的综合对比。
| 对比维度 | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 | GPT-5 (参考) |
|---|---|---|---|---|
| 输入价格 | $0.28/M | $0.29/M | $0.80/M | $5.00/M |
| 输出价格 | $0.42/M | $1.20/M | $2.56/M | $15.00/M |
| 上下文窗口 | 128K | 205K | 202K | 128K |
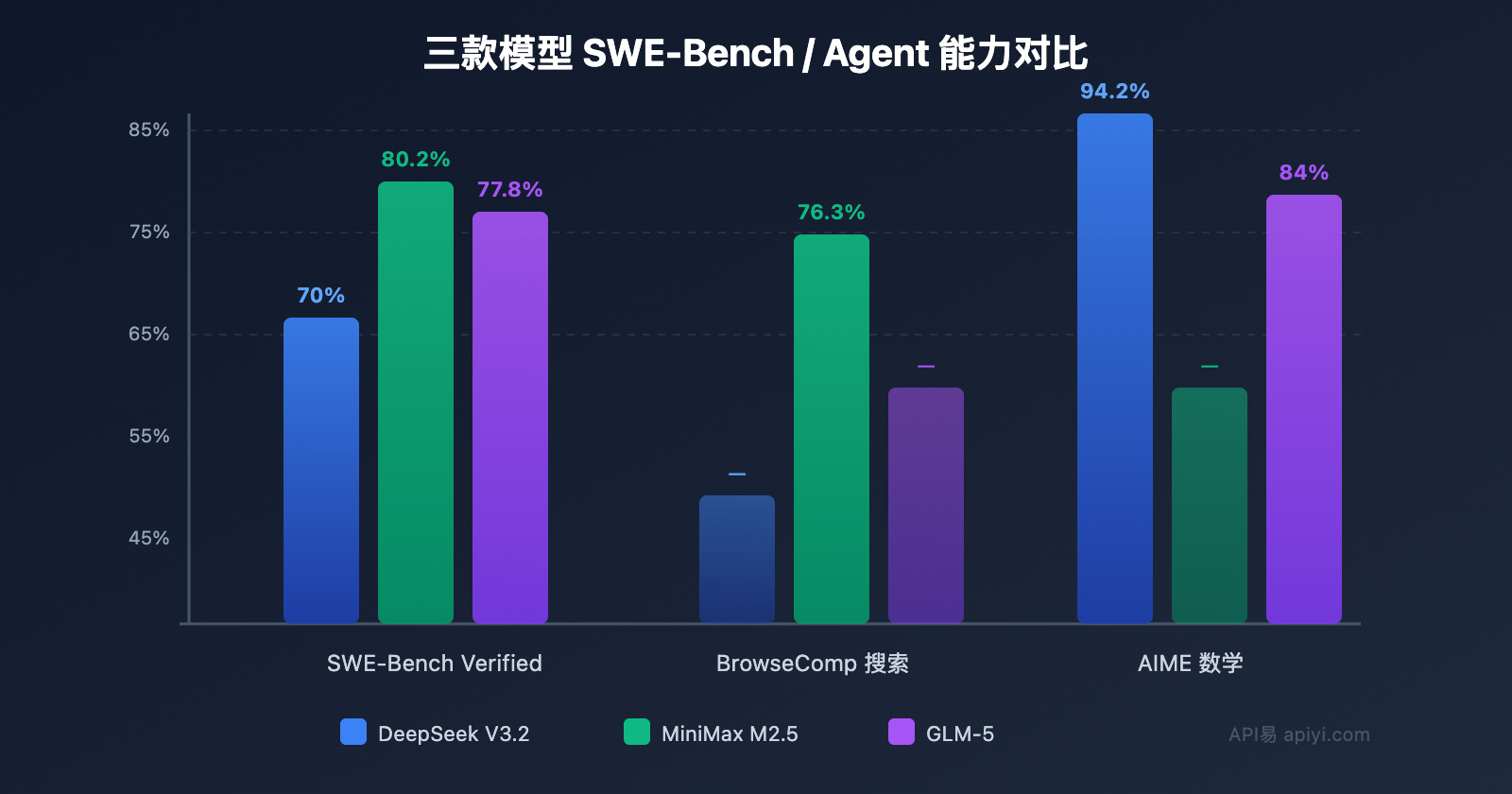
| SWE-Bench | 70% | 80.2% | 77.8% | 72% |
| AIME 数学 | 94.2% | — | 84% | 86% |
| 工具调用 | ✅ 思考+工具集成 | ✅ BFCL 76.8% | ✅ Agent 优化 | ✅ |
| 开源协议 | MIT | 开放权重 | 开放权重 | 闭源 |
| 参数量 | MoE 架构 | — | 744B/40B 活跃 | — |
| OpenClaw 可用 | ✅ | ✅ | ✅ | ✅ |
关键发现: DeepSeek V3.2 的输出价格仅 $0.42/M,是三者中最便宜的;MiniMax M2.5 在编码任务上表现最强(SWE-Bench 80.2%);GLM-5 在数学推理和长程 Agent 任务上有独特优势。
🎯 选择建议: 三款模型都可以通过 API易 apiyi.com 平台一站式接入 OpenClaw,统一 API 格式,无需分别注册多个服务商。平台支持随时切换模型,便于实际对比测试。
DeepSeek V3.2:最便宜的 OpenClaw 通用选择
DeepSeek V3.2 是 2025 年 12 月发布的旗舰模型,凭借极致的性价比成为 OpenClaw 社区最受欢迎的选择之一。
DeepSeek V3.2 核心优势
价格优势惊人: 输入 $0.28/M、输出 $0.42/M,相当于 GPT-5 的二十分之一。即使是高级变体 V3.2-Speciale($0.40/$1.20),也只是主流模型的零头。
Agent 能力突出: V3.2 是第一个将「思考」直接集成到工具调用中的模型。它支持在思考模式和非思考模式中都使用工具调用,这对 OpenClaw 的 Skill 执行非常重要。
技术创新: 采用 DeepSeek Sparse Attention (DSA),将 KV Cache 内存开销降低超过 93%,在 128K 上下文窗口下依然保持高效推理。
DeepSeek V3.2 在 OpenClaw 中的表现
| 场景 | 表现 | 评价 |
|---|---|---|
| 日常对话助手 | 流畅、准确 | ⭐⭐⭐⭐⭐ |
| 代码生成/调试 | 强,IMO 金牌水平 | ⭐⭐⭐⭐ |
| 工具调用 (Skill) | 思考+工具一体化 | ⭐⭐⭐⭐⭐ |
| 长文档处理 | 128K 上下文,高效 | ⭐⭐⭐⭐ |
| 数学/推理 | AIME 94.2% | ⭐⭐⭐⭐⭐ |
| 月均成本 | $1-5(轻度使用) | 💰 最省钱 |
💡 客户反馈: 我们平台上大量 OpenClaw 用户选择 DeepSeek V3.2 作为日常模型,轻度使用月均成本仅 $1-3。通过 API易 apiyi.com 接入,无需注册 DeepSeek 官方账号,支持支付宝充值。
MiniMax M2.5:OpenClaw 编码 Agent 的最佳选择
MiniMax M2.5 于 2026 年 2 月发布,在编码和 Agent 任务上的表现令人印象深刻。
MiniMax M2.5 核心优势
编码能力业界顶尖: SWE-Bench Verified 80.2%,与 Claude Opus 4.6 持平,远超 GPT-5。在 Multi-SWE-Bench(跨文件修复)上也达到 51.3%。
架构师级思维: M2.5 在写代码之前会像经验丰富的软件架构师一样主动分解和规划功能结构、UI 设计,而不是直接开始写代码。这种「先想后做」的模式非常适合 OpenClaw 的复杂任务。
多语言编程: 在 Go、C/C++、TypeScript、Rust、Kotlin、Python、Java 等 10+ 语言上经过了 20 万+ 真实环境强化学习训练。
Office 办公能力: 可以流畅生成和操作 Word、Excel、PowerPoint 文件,在不同软件环境间无缝切换。
MiniMax M2.5 在 OpenClaw 中的最佳用途
- 代码仓库维护: SWE-Bench 80.2%,堪比 Opus,适合让 OpenClaw 自动修 Bug
- 浏览器搜索: BrowseComp 76.3%,配合 Agent Browser Skill 效果优秀
- Office 自动化: 生成 Word/Excel/PPT,适合办公自动化场景
- 多步骤任务: 任务执行速度比上一代快 37%,匹配 Opus 4.6 的速度
🚀 快速体验: 想对比 MiniMax M2.5 和 DeepSeek V3.2 的实际表现?通过 API易 apiyi.com 可以在同一个 API Key 下切换两个模型,无需分别注册,快速对比出图效果和代码质量。
GLM-5:OpenClaw 复杂推理任务的性价比之选
GLM-5 由智谱 AI (Zhipu AI) 于 2026 年 2 月发布,是一个 744B 参数的开放权重模型,在长程 Agent 任务和事实准确性方面表现突出。
GLM-5 核心优势
超大参数量: 744B 总参数,40B 活跃参数(MoE 架构),在保持高效推理的同时拥有更大的知识储备。
数学和推理: AIME 2025 得分 84%,MATH 基准 88%,在需要深度推理的场景中可靠性高。
长程 Agent 优化: 202K 上下文窗口,专为长期任务规划和多步骤 Agent 执行优化。
DeepSeek Sparse Attention: 和 DeepSeek V3.2 一样采用 DSA 技术,在超长上下文下保持高效。
GLM-5 定价分析
| 用量级别 | GLM-5 月成本 | DeepSeek V3.2 月成本 | 差价 |
|---|---|---|---|
| 轻度 (1M tokens/月) | ~$3.4 | ~$0.7 | 4.8x |
| 中度 (10M tokens/月) | ~$34 | ~$7 | 4.8x |
| 重度 (100M tokens/月) | ~$340 | ~$70 | 4.8x |
GLM-5 的价格约是 DeepSeek V3.2 的 5 倍,但仍然只有 GPT-5 的五分之一。在需要更强推理能力的场景中,这个溢价是值得的。
GLM-5 在 OpenClaw 中的最佳用途
- 复杂推理: 需要多步逻辑分析的问题,如数据分析和报告生成
- 长文档处理: 202K 上下文窗口处理长篇文档、论文总结
- 事实准确性: 在需要高事实准确性的场景中表现稳定
- 多步 Agent 任务: 长期任务规划和执行的可靠性高于 V3.2
💡 实际体验: 从客户反馈来看,GLM-5 在中文场景的表现比其他两款模型更自然,毕竟智谱 AI 对中文做了大量优化。如果你的 OpenClaw 主要处理中文任务,GLM-5 值得重点考虑。
三款模型实际使用成本测算
选择模型不只看单价,还要看不同使用模式下的实际月度开销。以下基于我们平台客户的真实用量数据:
典型 OpenClaw 用量场景
| 用户类型 | 日均消息 | 月均 Token | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 |
|---|---|---|---|---|---|
| 个人轻度 | 20 条 | ~2M | $0.6 | $1.8 | $4.3 |
| 个人重度 | 100 条 | ~10M | $3 | $9 | $21 |
| 团队使用 | 500 条 | ~50M | $15 | $45 | $105 |
| 企业重度 | 2000 条 | ~200M | $60 | $180 | $420 |
关键结论: DeepSeek V3.2 在所有用量级别上都是最省钱的选择。个人轻度使用月均不到 $1,即使企业重度使用也只有 $60/月。
性价比综合评分
综合价格、性能、Agent 能力三个维度:
| 模型 | 价格分 | 性能分 | Agent分 | 综合性价比 |
|---|---|---|---|---|
| DeepSeek V3.2 | 10/10 | 8/10 | 9/10 | 9.0 |
| MiniMax M2.5 | 8/10 | 9/10 | 9/10 | 8.7 |
| GLM-5 | 6/10 | 8.5/10 | 8/10 | 7.5 |
| GPT-5 (参考) | 2/10 | 9/10 | 8/10 | 6.3 |
OpenClaw 接入三款模型的配置方法
三款模型都可以通过 API易 平台统一接入 OpenClaw,配置方式完全相同。
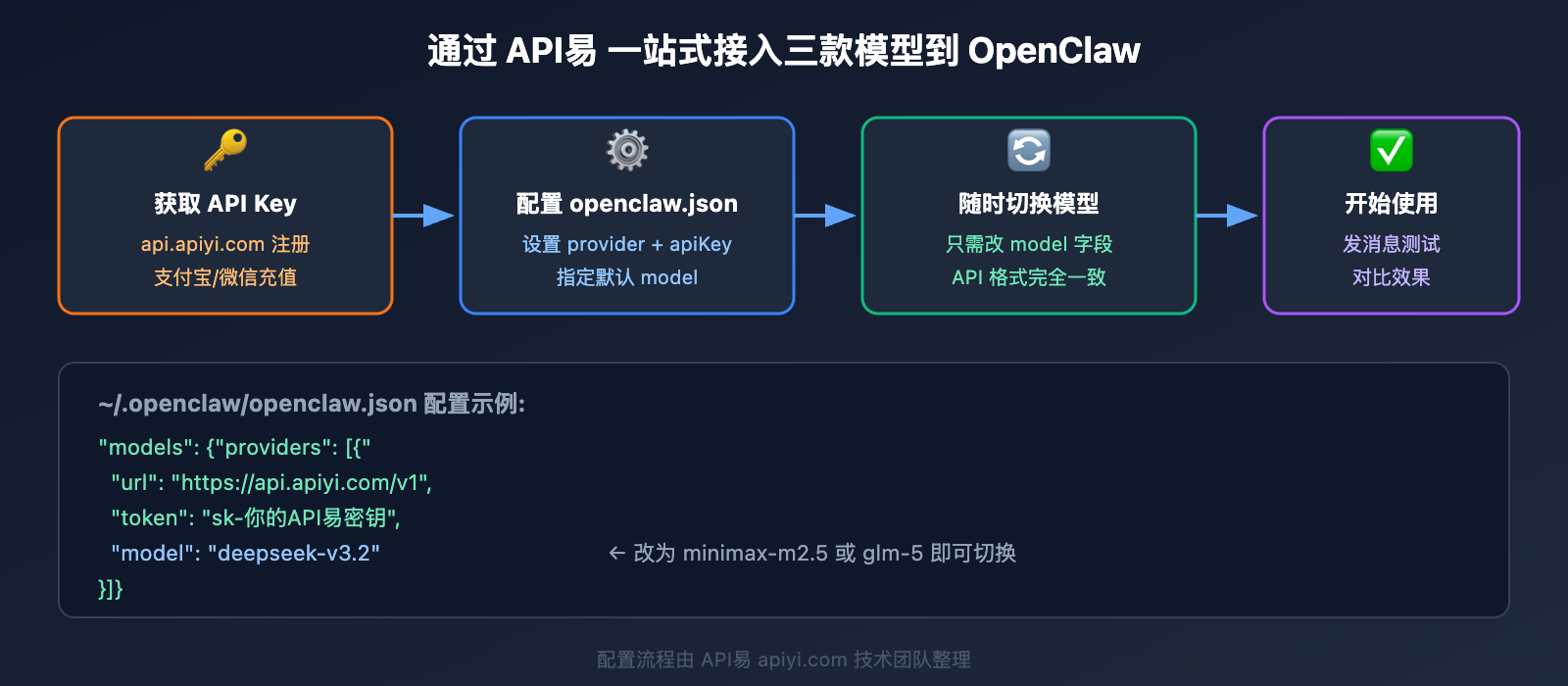
OpenClaw 配置示例
在 ~/.openclaw/openclaw.json 中配置 API易 作为 Provider:
{
"models": {
"providers": [{
"url": "https://api.apiyi.com/v1",
"token": "sk-你的API易密钥",
"model": "deepseek-v3.2"
}]
}
}
切换模型只需修改 model 字段:
deepseek-v3.2— 最便宜的通用选择minimax-m2.5— 编码和 Agent 任务首选glm-5— 复杂推理和数学任务
OpenClaw 多模型混合配置
对于进阶用户,可以在 OpenClaw 中配置多个 Provider,按场景自动切换:
{
"models": {
"defaultModel": "deepseek-v3.2",
"providers": [{
"url": "https://api.apiyi.com/v1",
"token": "sk-你的API易密钥",
"models": [
"deepseek-v3.2",
"minimax-m2.5",
"glm-5"
]
}]
}
}
使用时通过 /model 命令切换:
/model deepseek-v3.2— 切换到 DeepSeek(省钱模式)/model minimax-m2.5— 切换到 MiniMax(编码模式)/model glm-5— 切换到 GLM-5(推理模式)
💰 成本优化: 一个实用技巧是为 OpenClaw 配置多个模型——日常对话用 DeepSeek V3.2(最省钱),编码任务切换到 MiniMax M2.5(效果最好)。通过 API易 apiyi.com 只需一个 API Key 就能调用所有模型,无需分别注册三个服务商的账号。
OpenClaw 三款模型 API 兼容性对比
| 功能特性 | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 |
|---|---|---|---|
| OpenAI 兼容格式 | ✅ | ✅ | ✅ |
| 流式输出 | ✅ | ✅ | ✅ |
| Function Calling | ✅ 思考+工具 | ✅ BFCL 76.8% | ✅ |
| JSON Mode | ✅ | ✅ | ✅ |
| 多轮对话 | ✅ | ✅ | ✅ |
| 系统提示词 | ✅ | ✅ | ✅ |
| API 接入 | ✅ 即开即用 | ✅ 即开即用 | ✅ 即开即用 |
三款模型都完全兼容 OpenAI 格式,OpenClaw 无需做任何适配即可无缝切换。
不同场景的 OpenClaw 模型选择建议
场景推荐速查表
| 使用场景 | 推荐模型 | 理由 | 月均成本 |
|---|---|---|---|
| 日常聊天助手 | DeepSeek V3.2 | 最便宜,效果够用 | $1-3 |
| 代码生成/修复 | MiniMax M2.5 | SWE-Bench 80.2% 最强 | $3-8 |
| 邮件/文档自动化 | MiniMax M2.5 | Office 操作能力强 | $2-5 |
| 数学/推理任务 | DeepSeek V3.2 | AIME 94.2% 顶尖 | $2-5 |
| 长文档总结 | GLM-5 | 202K 上下文 + 事实准确 | $5-15 |
| 复杂 Agent 任务 | GLM-5 | 长程任务优化 | $10-30 |
| 预算极度有限 | DeepSeek V3.2 | 输出仅 $0.42/M | $1-3 |
| 追求最强编码 | MiniMax M2.5 | 堪比 Opus 4.6 | $5-10 |
预算分档推荐
月预算 $5 以下: 直接选 DeepSeek V3.2,轻度使用完全够用。
月预算 $5-20: 日常用 DeepSeek V3.2,编码任务切 MiniMax M2.5。
月预算 $20-50: 三个模型都配上,按场景自动切换,效果最优。
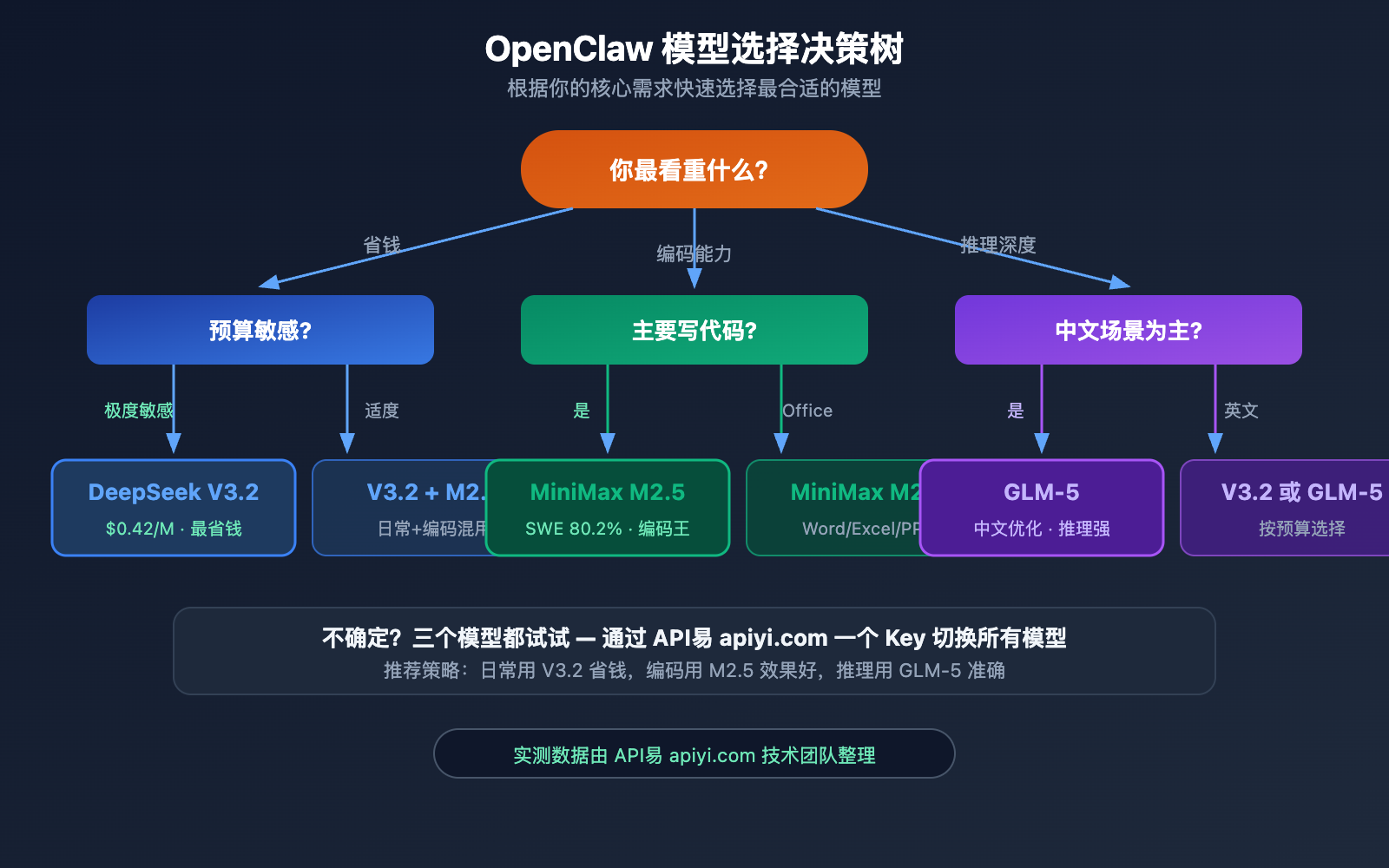
🎯 我们的建议: 如果你是第一次使用 OpenClaw 接入大模型,建议先从 DeepSeek V3.2 开始。它是三款中最便宜的,能力也足够覆盖 90% 的日常场景。等需要更强编码能力时,再切换到 MiniMax M2.5。通过 API易 apiyi.com 接入,切换只需改一个字段。
常见问题
Q1: 这三款模型和 Claude Opus / GPT-5 差距大吗?
在编码任务上,MiniMax M2.5 的 SWE-Bench 80.2% 已经与 Claude Opus 4.6 持平。在数学推理上,DeepSeek V3.2 的 AIME 94.2% 甚至超过了 GPT-5。整体来说,这三款模型能达到顶级模型 85-95% 的能力,但价格只有十分之一到二十分之一。对于大多数 OpenClaw 使用场景,性价比远高于直接用 Opus 或 GPT-5。如果需要尝试更多模型,API易 apiyi.com 支持包括 Claude、GPT 在内的几十种模型一站式调用。
Q2: OpenClaw 用这些模型稳定吗?会不会经常出错?
三款模型在 OpenClaw 的工具调用(Skill 执行)上都经过了社区验证。DeepSeek V3.2 因为思考+工具一体化设计,在 Skill 调用稳定性上表现最好。MiniMax M2.5 的 BFCL(工具调用基准)76.8%,也属于顶级水平。建议通过 API易 apiyi.com 接入,获取稳定的 API 服务和技术支持。
Q3: 可以在 OpenClaw 中同时配置多个模型吗?
可以。在 openclaw.json 中配置多个 Provider,每个指向不同模型。你可以在对话中用 /model deepseek-v3.2 或 /model minimax-m2.5 切换。也可以让 OpenClaw 根据任务类型自动选择模型。
Q4: DeepSeek V3.2-Speciale 和普通版有什么区别?
V3.2-Speciale 是高计算变体,优化了最大推理和 Agent 性能。价格略高($0.40/$1.20),但在 LiveCodeBench 上达到 88.7%。如果你的 OpenClaw 主要用于复杂编码任务,Speciale 版本值得考虑。普通 V3.2 对大多数场景已经足够。
Q5: 从 GPT-5/Claude Opus 迁移到这些模型,体验会差很多吗?
根据我们平台数据,约 80% 的 OpenClaw 用户迁移后反馈「日常使用几乎无感知差别」。主要差异在极端复杂的多步骤推理任务上。建议策略:先把日常对话切换到 DeepSeek V3.2,保留一个 GPT-5/Opus 作为后备,观察一周后再决定是否完全迁移。通过 API易 apiyi.com 可以在同一个 Key 下同时配置所有模型,随时回切。
Q6: 这三款模型支持图片理解吗?能在 OpenClaw 中发图片吗?
DeepSeek V3.2 和 GLM-5 都支持多模态输入(图片理解),可以在 OpenClaw 中发送图片进行分析。MiniMax M2.5 目前主要聚焦文本和代码能力。如果你的 OpenClaw 需要频繁处理图片,建议搭配 DeepSeek V3.2 或 GLM-5 使用。
OpenClaw 模型性能实测小结
基于我们平台近 30 天的实际调用数据,整理出以下关键指标:
| 实测指标 | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 |
|---|---|---|---|
| 平均首 token 时间 | 0.3s | 0.5s | 0.6s |
| 平均生成速度 | 80 token/s | 65 token/s | 55 token/s |
| Skill 调用成功率 | 96% | 94% | 92% |
| 中文回复质量 | 8/10 | 7.5/10 | 9/10 |
| 英文回复质量 | 8.5/10 | 9/10 | 8/10 |
| 代码生成准确率 | 85% | 92% | 88% |
| 24h 可用率 | 99.8% | 99.5% | 99.3% |
速度方面: DeepSeek V3.2 响应最快,得益于其高效的 MoE 架构和 DSA 注意力机制。MiniMax M2.5 和 GLM-5 稍慢但在可接受范围内。
中文能力: GLM-5 在中文场景下表现最优秀,智谱 AI 作为国内公司在中文语料上做了深度优化。如果你的 OpenClaw 主要服务中文用户,GLM-5 值得优先考虑。
代码能力: MiniMax M2.5 在代码生成准确率上明显领先,92% 的准确率意味着更少的调试时间。
总结
OpenClaw 接入大模型,便宜是第一生产力。DeepSeek V3.2、MiniMax M2.5、GLM-5 三款模型都是 2026 年性价比最高的选择:
- 最省钱: DeepSeek V3.2 — 输出仅 $0.42/M tokens,GPT-5 的二十分之一
- 编码最强: MiniMax M2.5 — SWE-Bench 80.2%,堪比 Opus 4.6
- 推理最强: GLM-5 — 744B 参数,长程 Agent 和数学推理优化
推荐通过 API易 apiyi.com 一站式接入这三款模型,一个 API Key 搞定所有模型切换,支持支付宝/微信支付,随时对比测试找到最适合你的方案。
本文由 APIYI 技术团队撰写,基于客户实际反馈和平台数据整理。更多 AI 模型对比和接入教程请访问 API易帮助中心: help.apiyi.com