Quel grand modèle de langage offre le meilleur rapport qualité-prix pour OpenClaw ? C'est l'une des questions que nos clients posent le plus. Cet article comparera trois modèles à excellent rapport qualité-prix — DeepSeek V3.2, MiniMax M2.5 et GLM-5 — sous trois angles : prix, performance et capacité d'appel d'outils pour les agents, afin de vous aider à trouver le partenaire idéal pour OpenClaw.
Valeur clé : Le point commun de ces trois modèles est qu'ils sont économiques et performants — leur prix n'est qu'un dixième à un vingtième de celui de GPT-5 / Claude Opus, mais ils excellent dans des scénarios d'agent comme le codage et l'appel d'outils. Après avoir lu cet article, vous saurez quel modèle choisir selon vos besoins.

Comparaison des paramètres clés de trois modèles à excellent rapport qualité-prix
Commençons par les données les plus cruciales – la comparaison globale entre prix et performances.
| Critère de comparaison | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 | GPT-5 (référence) |
|---|---|---|---|---|
| Prix d'entrée | 0,28 $/M | 0,29 $/M | 0,80 $/M | 5,00 $/M |
| Prix de sortie | 0,42 $/M | 1,20 $/M | 2,56 $/M | 15,00 $/M |
| Fenêtre de contexte | 128K | 205K | 202K | 128K |
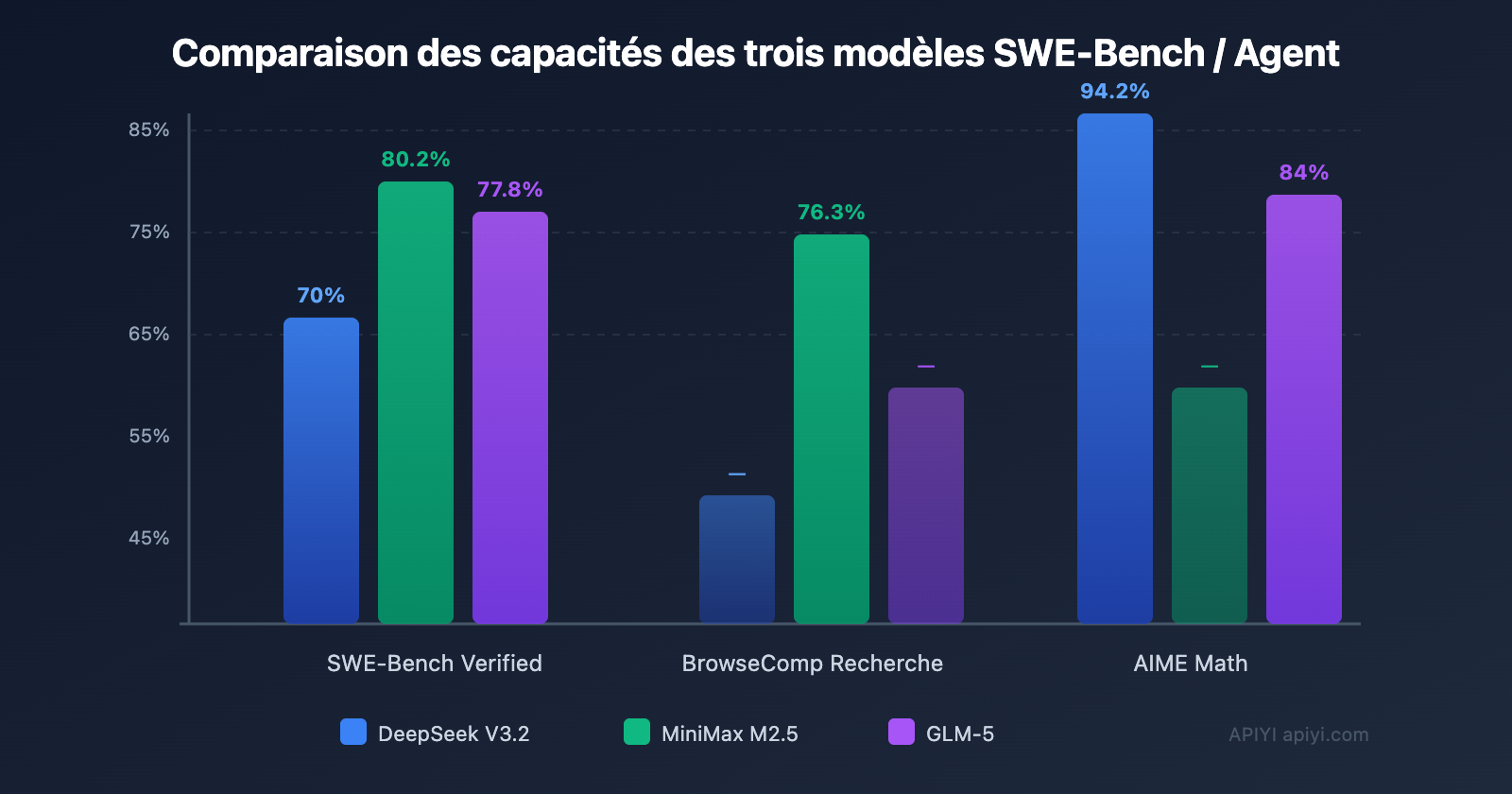
| SWE-Bench | 70% | 80,2% | 77,8% | 72% |
| AIME (Maths) | 94,2% | — | 84% | 86% |
| Appel d'outils | ✅ Intégration réflexion + outils | ✅ BFCL 76,8% | ✅ Optimisé pour Agent | ✅ |
| Licence open source | MIT | Poids ouverts | Poids ouverts | Propriétaire |
| Nombre de paramètres | Architecture MoE | — | 744B/40B actifs | — |
| OpenClaw disponible | ✅ | ✅ | ✅ | ✅ |
Conclusion clé : Le prix de sortie de DeepSeek V3.2 (0,42 $/M) est le plus bas des trois ; MiniMax M2.5 excelle dans les tâches de codage (SWE-Bench 80,2%) ; GLM-5 présente des avantages uniques en raisonnement mathématique et pour les tâches d'Agent à long terme.
🎯 Conseil de choix : Les trois modèles sont accessibles via la plateforme APIYI (apiyi.com) pour une intégration OpenClaw unifiée, avec un format d'API cohérent, sans avoir besoin de s'inscrire auprès de multiples fournisseurs. La plateforme permet de basculer facilement entre modèles pour des tests comparatifs pratiques.
DeepSeek V3.2 : Le choix universel OpenClaw le plus économique
DeepSeek V3.2, modèle phare publié en décembre 2025, est devenu l'un des choix les plus populaires dans la communauté OpenClaw grâce à son rapport qualité-prix exceptionnel.
Avantages principaux de DeepSeek V3.2
Un avantage prix impressionnant : 0,28 $/M en entrée et 0,42 $/M en sortie, soit environ un vingtième du prix de GPT-5. Même sa variante avancée V3.2-Speciale (0,40 $/1,20 $) ne représente qu'une fraction du coût des modèles grand public.
Capacités Agent remarquables : V3.2 est le premier modèle à intégrer directement la « réflexion » dans l'appel d'outils. Il prend en charge l'utilisation d'outils à la fois en mode réflexion et en mode standard, ce qui est crucial pour l'exécution des Skills dans OpenClaw.
Innovation technique : Il utilise l'attention éparse DeepSeek (DSA), réduisant de plus de 93% la mémoire requise pour le KV Cache, permettant ainsi un raisonnement efficace même avec une fenêtre de contexte de 128K.
Performances de DeepSeek V3.2 avec OpenClaw
| Scénario | Performance | Évaluation |
|---|---|---|
| Assistant conversationnel quotidien | Fluide, précis | ⭐⭐⭐⭐⭐ |
| Génération/Débogage de code | Fort, niveau médaille d'or IMO | ⭐⭐⭐⭐ |
| Appel d'outils (Skill) | Intégration réflexion + outils | ⭐⭐⭐⭐⭐ |
| Traitement de documents longs | 128K de contexte, efficace | ⭐⭐⭐⭐ |
| Mathématiques/Raisonnement | AIME 94,2% | ⭐⭐⭐⭐⭐ |
| Coût mensuel moyen | 1-5 $ (utilisation légère) | 💰 Le plus économique |
💡 Retour client : Sur notre plateforme, de nombreux utilisateurs OpenClaw choisissent DeepSeek V3.2 comme modèle quotidien, avec un coût mensuel moyen de seulement 1-3 $ pour une utilisation légère. L'accès via APIYI (apiyi.com) ne nécessite pas de compte officiel DeepSeek et prend en charge le paiement par Alipay.
MiniMax M2.5 : Le meilleur choix pour l'agent de codage OpenClaw
MiniMax M2.5, publié en février 2026, offre des performances impressionnantes en matière de codage et de tâches d'agent.
Avantages clés de MiniMax M2.5
Capacités de codage de premier plan : Score de 80,2 % sur SWE-Bench Verified, à égalité avec Claude Opus 4.6 et bien au-delà de GPT-5. Atteint également 51,3 % sur Multi-SWE-Bench (correction multi-fichiers).
Pensée d'architecte : Avant d'écrire du code, M2.5 décompose et planifie activement la structure fonctionnelle et la conception de l'interface utilisateur, comme un architecte logiciel expérimenté, plutôt que de se lancer directement. Ce mode « réfléchir avant d'agir » est parfait pour les tâches complexes d'OpenClaw.
Programmation multilingue : Formé par apprentissage par renforcement dans plus de 10 langages, dont Go, C/C++, TypeScript, Rust, Kotlin, Python, Java, avec plus de 200 000 entraînements en environnement réel.
Capacités bureautiques : Peut générer et manipuler de manière fluide des fichiers Word, Excel et PowerPoint, en passant de manière transparente d'un environnement logiciel à l'autre.
Meilleures utilisations de MiniMax M2.5 avec OpenClaw
- Maintenance de dépôts de code : SWE-Bench 80,2 %, comparable à Opus, idéal pour la correction automatique de bugs par OpenClaw.
- Recherche web : BrowseComp 76,3 %, excellent en combinaison avec la compétence Agent Browser Skill.
- Automatisation bureautique : Génération de Word/Excel/PPT, adapté aux scénarios d'automatisation de bureau.
- Tâches multi-étapes : Vitesse d'exécution des tâches 37 % plus rapide que la génération précédente, correspondant à la vitesse d'Opus 4.6.
🚀 Test rapide : Vous voulez comparer les performances réelles de MiniMax M2.5 et DeepSeek V3.2 ? Avec APIYI sur apiyi.com, vous pouvez basculer entre les deux modèles avec une seule clé API, sans inscription séparée, pour comparer rapidement la qualité des sorties et du code.
GLM-5 : Le choix rentable pour les tâches de raisonnement complexe d'OpenClaw
GLM-5, publié par Zhipu AI en février 2026, est un modèle à poids ouvert de 744B paramètres, qui excelle dans les tâches d'agent à long terme et la précision factuelle.
Avantages clés de GLM-5
Nombre de paramètres énorme : 744B paramètres totaux, 40B paramètres actifs (architecture MoE), offrant une plus grande base de connaissances tout en maintenant une inférence efficace.
Mathématiques et raisonnement : Score de 84 % sur AIME 2025, 88 % sur le benchmark MATH, très fiable dans les scénarios nécessitant un raisonnement approfondi.
Optimisation pour les agents à long terme : Fenêtre de contexte de 202K tokens, optimisée pour la planification de tâches longues et l'exécution multi-étapes par des agents.
DeepSeek Sparse Attention : Utilise la technologie DSA, comme DeepSeek V3.2, pour maintenir l'efficacité avec des contextes très longs.
Analyse tarifaire de GLM-5
| Niveau d'utilisation | Coût mensuel GLM-5 | Coût mensuel DeepSeek V3.2 | Différence |
|---|---|---|---|
| Léger (1M tokens/mois) | ~3,4 $ | ~0,7 $ | 4,8x |
| Modéré (10M tokens/mois) | ~34 $ | ~7 $ | 4,8x |
| Intensif (100M tokens/mois) | ~340 $ | ~70 $ | 4,8x |
Le prix de GLM-5 est environ 5 fois celui de DeepSeek V3.2, mais reste seulement un cinquième de celui de GPT-5. Dans les scénarios nécessitant une plus grande puissance de raisonnement, cette prime en vaut la peine.
Meilleures utilisations de GLM-5 avec OpenClaw
- Raisonnement complexe : Problèmes nécessitant une analyse logique en plusieurs étapes, comme l'analyse de données et la génération de rapports.
- Traitement de longs documents : Fenêtre de contexte de 202K tokens pour traiter des documents longs, résumés de thèses.
- Précision factuelle : Performances stables dans les scénarios nécessitant une haute précision factuelle.
- Tâches d'agent multi-étapes : Fiabilité supérieure à V3.2 pour la planification et l'exécution de tâches longues.
💡 Retour d'expérience : D'après les retours clients, GLM-5 offre des performances plus naturelles en chinois que les deux autres modèles, Zhipu AI ayant largement optimisé pour cette langue. Si votre OpenClaw traite principalement des tâches en chinois, GLM-5 mérite une attention particulière.
Calcul des coûts réels d'utilisation des trois modèles
Le choix d'un modèle ne se limite pas à son prix unitaire, il faut aussi considérer les dépenses mensuelles réelles selon différents modes d'utilisation. Voici des estimations basées sur les données d'utilisation réelles de nos clients :
Scénarios d'utilisation typiques avec OpenClaw
| Type d'utilisateur | Messages quotidiens | Tokens mensuels moyens | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 |
|---|---|---|---|---|---|
| Utilisateur léger personnel | 20 messages | ~2M | 0,6 $ | 1,8 $ | 4,3 $ |
| Utilisateur intensif personnel | 100 messages | ~10M | 3 $ | 9 $ | 21 $ |
| Utilisation en équipe | 500 messages | ~50M | 15 $ | 45 $ | 105 $ |
| Utilisation intensive en entreprise | 2000 messages | ~200M | 60 $ | 180 $ | 420 $ |
Conclusion clé : DeepSeek V3.2 est l'option la plus économique à tous les niveaux d'utilisation. Pour un usage personnel léger, c'est moins de 1 $ par mois, et même pour une utilisation intensive en entreprise, cela ne représente que 60 $/mois.
Score global de rapport qualité-prix
Évaluation sur trois dimensions : prix, performances et capacités d'Agent :
| Modèle | Score prix | Score performances | Score Agent | Rapport qualité-prix global |
|---|---|---|---|---|
| DeepSeek V3.2 | 10/10 | 8/10 | 9/10 | 9,0 |
| MiniMax M2.5 | 8/10 | 9/10 | 9/10 | 8,7 |
| GLM-5 | 6/10 | 8,5/10 | 8/10 | 7,5 |
| GPT-5 (référence) | 2/10 | 9/10 | 8/10 | 6,3 |
Méthode de configuration pour connecter OpenClaw aux trois modèles
Les trois modèles peuvent être connectés à OpenClaw de manière unifiée via la plateforme APIYI, avec une configuration identique.

Exemple de configuration OpenClaw
Configurez APIYI comme Provider dans ~/.openclaw/openclaw.json :
{
"models": {
"providers": [{
"url": "https://api.apiyi.com/v1",
"token": "sk-votre_clé_API_APIYI",
"model": "deepseek-v3.2"
}]
}
}
Pour changer de modèle, modifiez simplement le champ model :
deepseek-v3.2— Choix général le moins cherminimax-m2.5— Premier choix pour le codage et les tâches d'Agentglm-5— Tâches de raisonnement complexe et mathématiques
Configuration multi-modèles mixte pour OpenClaw
Pour les utilisateurs avancés, il est possible de configurer plusieurs Providers dans OpenClaw et de basculer automatiquement selon le scénario :
{
"models": {
"defaultModel": "deepseek-v3.2",
"providers": [{
"url": "https://api.apiyi.com/v1",
"token": "sk-votre_clé_API_APIYI",
"models": [
"deepseek-v3.2",
"minimax-m2.5",
"glm-5"
]
}]
}
}
Utilisez la commande /model pour basculer :
/model deepseek-v3.2— Basculer vers DeepSeek (mode économique)/model minimax-m2.5— Basculer vers MiniMax (mode codage)/model glm-5— Basculer vers GLM-5 (mode raisonnement)
💰 Optimisation des coûts : Une astuce pratique consiste à configurer plusieurs modèles pour OpenClaw — utilisez DeepSeek V3.2 pour les conversations quotidiennes (le plus économique) et basculez vers MiniMax M2.5 pour les tâches de codage (meilleurs résultats). Avec APIYI (apiyi.com), une seule clé API suffit pour invoquer tous les modèles, sans avoir besoin de créer des comptes séparés auprès des trois fournisseurs de services.
Comparaison de la compatibilité API des trois modèles avec OpenClaw
| Fonctionnalité | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 |
|---|---|---|---|
| Format compatible OpenAI | ✅ | ✅ | ✅ |
| Sortie en streaming | ✅ | ✅ | ✅ |
| Function Calling | ✅ Réflexion + outils | ✅ BFCL 76,8 % | ✅ |
| Mode JSON | ✅ | ✅ | ✅ |
| Conversation multi-tours | ✅ | ✅ | ✅ |
| Invite système | ✅ | ✅ | ✅ |
| Accès API | ✅ Prêt à l'emploi | ✅ Prêt à l'emploi | ✅ Prêt à l'emploi |
Les trois modèles sont entièrement compatibles avec le format OpenAI, permettant à OpenClaw de basculer de manière transparente sans aucune adaptation.
Recommandations de choix de modèle OpenClaw selon les scénarios
Tableau de référence rapide par scénario
| Scénario d'utilisation | Modèle recommandé | Raison | Coût mensuel moyen |
|---|---|---|---|
| Assistant conversationnel quotidien | DeepSeek V3.2 | Le moins cher, performances suffisantes | 1-3 $ |
| Génération/Correction de code | MiniMax M2.5 | Meilleur score SWE-Bench 80.2% | 3-8 $ |
| Automatisation emails/documents | MiniMax M2.5 | Excellentes capacités avec Office | 2-5 $ |
| Tâches mathématiques/raisonnement | DeepSeek V3.2 | Score AIME 94.2% de premier ordre | 2-5 $ |
| Résumé de longs documents | GLM-5 | Contexte 202K + précision factuelle | 5-15 $ |
| Tâches Agent complexes | GLM-5 | Optimisé pour les tâches longues | 10-30 $ |
| Budget extrêmement limité | DeepSeek V3.2 | Sortie à seulement 0,42 $/M | 1-3 $ |
| Recherche de la meilleure programmation | MiniMax M2.5 | Comparable à Opus 4.6 | 5-10 $ |
Recommandations par tranche de budget
Budget mensuel < 5 $ : Choisissez directement DeepSeek V3.2, parfaitement adapté pour une utilisation légère.
Budget mensuel 5-20 $ : Utilisez DeepSeek V3.2 au quotidien, basculez sur MiniMax M2.5 pour les tâches de codage.
Budget mensuel 20-50 $ : Configurez les trois modèles, basculez automatiquement selon le scénario pour des résultats optimaux.

🎯 Notre conseil : Si vous utilisez OpenClaw pour la première fois pour accéder à un grand modèle de langage, nous vous recommandons de commencer par DeepSeek V3.2. C'est le moins cher des trois et ses capacités couvrent 90% des scénarios quotidiens. Lorsque vous aurez besoin de plus de puissance pour le codage, basculez vers MiniMax M2.5. En passant par APIYI apiyi.com, le changement de modèle ne nécessite que la modification d'un seul champ.
Questions fréquentes
Q1 : L’écart entre ces trois modèles et Claude Opus / GPT-5 est-il important ?
Pour les tâches de codage, le score SWE-Bench de 80,2 % de MiniMax M2.5 est déjà au niveau de Claude Opus 4.6. En raisonnement mathématique, le score AIME de 94,2 % de DeepSeek V3.2 dépasse même celui de GPT-5. Globalement, ces trois modèles atteignent 85 à 95 % des capacités des modèles de pointe, mais à un coût dix à vingt fois inférieur. Pour la plupart des cas d'utilisation d'OpenClaw, le rapport qualité-prix est bien supérieur à l'utilisation directe d'Opus ou de GPT-5. Si vous souhaitez essayer plus de modèles, APIYI apiyi.com prend en charge l'invocation unifiée de dizaines de modèles, y compris Claude et GPT.
Q2 : Ces modèles sont-ils stables dans OpenClaw ? Y a-t-il souvent des erreurs ?
Les trois modèles ont été validés par la communauté pour l'appel d'outils (exécution de Skill) dans OpenClaw. DeepSeek V3.2, grâce à sa conception intégrée réflexion+outils, présente la meilleure stabilité pour l'appel de Skills. Le score BFCL (benchmark d'appel d'outils) de 76,8 % de MiniMax M2.5 est également de niveau supérieur. Nous recommandons de vous connecter via APIYI apiyi.com pour bénéficier d'un service API stable et d'une assistance technique.
Q3 : Puis-je configurer plusieurs modèles simultanément dans OpenClaw ?
Oui. Configurez plusieurs Provider dans le fichier openclaw.json, chacun pointant vers un modèle différent. Vous pouvez basculer pendant une conversation avec les commandes /model deepseek-v3.2 ou /model minimax-m2.5. Vous pouvez également laisser OpenClaw sélectionner automatiquement le modèle en fonction du type de tâche.
Q4 : Quelle est la différence entre DeepSeek V3.2-Speciale et la version standard ?
V3.2-Speciale est une variante à haute puissance de calcul, optimisée pour le raisonnement maximal et les performances d'Agent. Son coût est légèrement plus élevé (0,40 $/1,20 $), mais il atteint 88,7 % sur LiveCodeBench. Si votre utilisation principale d'OpenClaw concerne des tâches de codage complexes, la version Speciale mérite d'être envisagée. La version standard V3.2 est déjà suffisante pour la plupart des scénarios.
Q5 : En migrant de GPT-5/Claude Opus vers ces modèles, la dégradation de l’expérience sera-t-elle importante ?
Selon les données de notre plateforme, environ 80 % des utilisateurs d'OpenClaw ayant migré rapportent « presque aucune différence perceptible dans l'usage quotidien ». Les différences principales apparaissent sur des tâches de raisonnement multi-étapes extrêmement complexes. Stratégie recommandée : basculez d'abord vos conversations quotidiennes vers DeepSeek V3.2, conservez un accès GPT-5/Opus en secours, observez pendant une semaine avant de décider d'une migration complète. Via APIYI apiyi.com, vous pouvez configurer tous ces modèles sous une même clé et revenir en arrière à tout moment.
Q6 : Ces trois modèles prennent-ils en charge la compréhension d’images ? Puis-je envoyer des images dans OpenClaw ?
DeepSeek V3.2 et GLM-5 prennent tous deux en charge l'entrée multimodale (compréhension d'images), vous pouvez donc envoyer des images dans OpenClaw pour analyse. MiniMax M2.5 se concentre actuellement principalement sur les capacités texte et code. Si votre utilisation d'OpenClaw nécessite de traiter fréquemment des images, nous vous recommandons de l'utiliser en combinaison avec DeepSeek V3.2 ou GLM-5.
Résumé des tests de performance des modèles OpenClaw
Basé sur les données d'appel réelles de notre plateforme sur les 30 derniers jours, voici les indicateurs clés :
| Indicateur mesuré | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 |
|---|---|---|---|
| Temps moyen du premier token | 0,3 s | 0,5 s | 0,6 s |
| Vitesse de génération moyenne | 80 token/s | 65 token/s | 55 token/s |
| Taux de réussite des appels Skill | 96 % | 94 % | 92 % |
| Qualité des réponses en chinois | 8/10 | 7,5/10 | 9/10 |
| Qualité des réponses en anglais | 8,5/10 | 9/10 | 8/10 |
| Précision de génération de code | 85 % | 92 % | 88 % |
| Disponibilité sur 24h | 99,8 % | 99,5 % | 99,3 % |
Concernant la vitesse : DeepSeek V3.2 répond le plus rapidement, grâce à son architecture MoE efficace et son mécanisme d'attention DSA. MiniMax M2.5 et GLM-5 sont légèrement plus lents mais restent dans des limites acceptables.
Capacités en chinois : GLM-5 excelle dans les scénarios en chinois, car Zhipu AI, en tant qu'entreprise chinoise, a effectué une optimisation approfondie sur les corpus en chinois. Si votre OpenClaw sert principalement des utilisateurs chinois, GLM-5 mérite d'être priorisé.
Capacités en code : MiniMax M2.5 est nettement en avance en termes de précision de génération de code, avec 92 % de précision, ce qui signifie moins de temps de débogage.
Résumé
L'intégration de grands modèles de langage avec OpenClaw, le prix est le premier facteur de productivité. DeepSeek V3.2, MiniMax M2.5 et GLM-5 sont les trois modèles offrant le meilleur rapport qualité-prix en 2026 :
- Le plus économique : DeepSeek V3.2 — Sortie à seulement 0,42 $/M de tokens, soit un vingtième du prix de GPT-5
- Le plus fort en codage : MiniMax M2.5 — SWE-Bench 80,2 %, comparable à Opus 4.6
- Le plus fort en raisonnement : GLM-5 — 744B paramètres, optimisé pour les agents à long terme et le raisonnement mathématique
Nous recommandons d'utiliser APIYI (apiyi.com) pour accéder à ces trois modèles en un seul point d'entrée. Une seule clé API gère toutes les transitions de modèle, avec support des paiements Alipay/WeChat Pay. Testez et comparez à tout moment pour trouver la solution qui vous convient le mieux.
Cet article a été rédigé par l'équipe technique d'APIYI, sur la base des retours clients réels et des données de la plateforme. Pour plus de comparaisons de modèles d'IA et de tutoriels d'intégration, visitez le centre d'aide d'APIYI : help.apiyi.com