¿Cuál es el modelo de lenguaje grande más rentable para integrar con OpenClaw? Esta es una de las preguntas más frecuentes de nuestros clientes. Este artículo comparará tres modelos de gran relación calidad-precio—DeepSeek V3.2, MiniMax M2.5 y GLM-5—desde tres dimensiones: precio, rendimiento y capacidad de invocación de herramientas de agente, para ayudarte a encontrar el mejor compañero para OpenClaw.
Valor central: La característica común de estos tres modelos es que son económicos y eficaces—su precio es solo una décima o vigésima parte del de GPT-5 / Claude Opus, pero ofrecen un rendimiento sobresaliente en escenarios de agente como codificación e invocación de herramientas. Al terminar este artículo, tendrás claro qué modelo elegir en diferentes situaciones.

Comparación de parámetros clave de los tres modelos de alta relación calidad-precio
Primero, veamos los datos más cruciales: la comparación integral de precio y rendimiento.
| Dimensión de comparación | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 | GPT-5 (Referencia) |
|---|---|---|---|---|
| Precio de entrada | $0.28/M | $0.29/M | $0.80/M | $5.00/M |
| Precio de salida | $0.42/M | $1.20/M | $2.56/M | $15.00/M |
| Ventana de contexto | 128K | 205K | 202K | 128K |
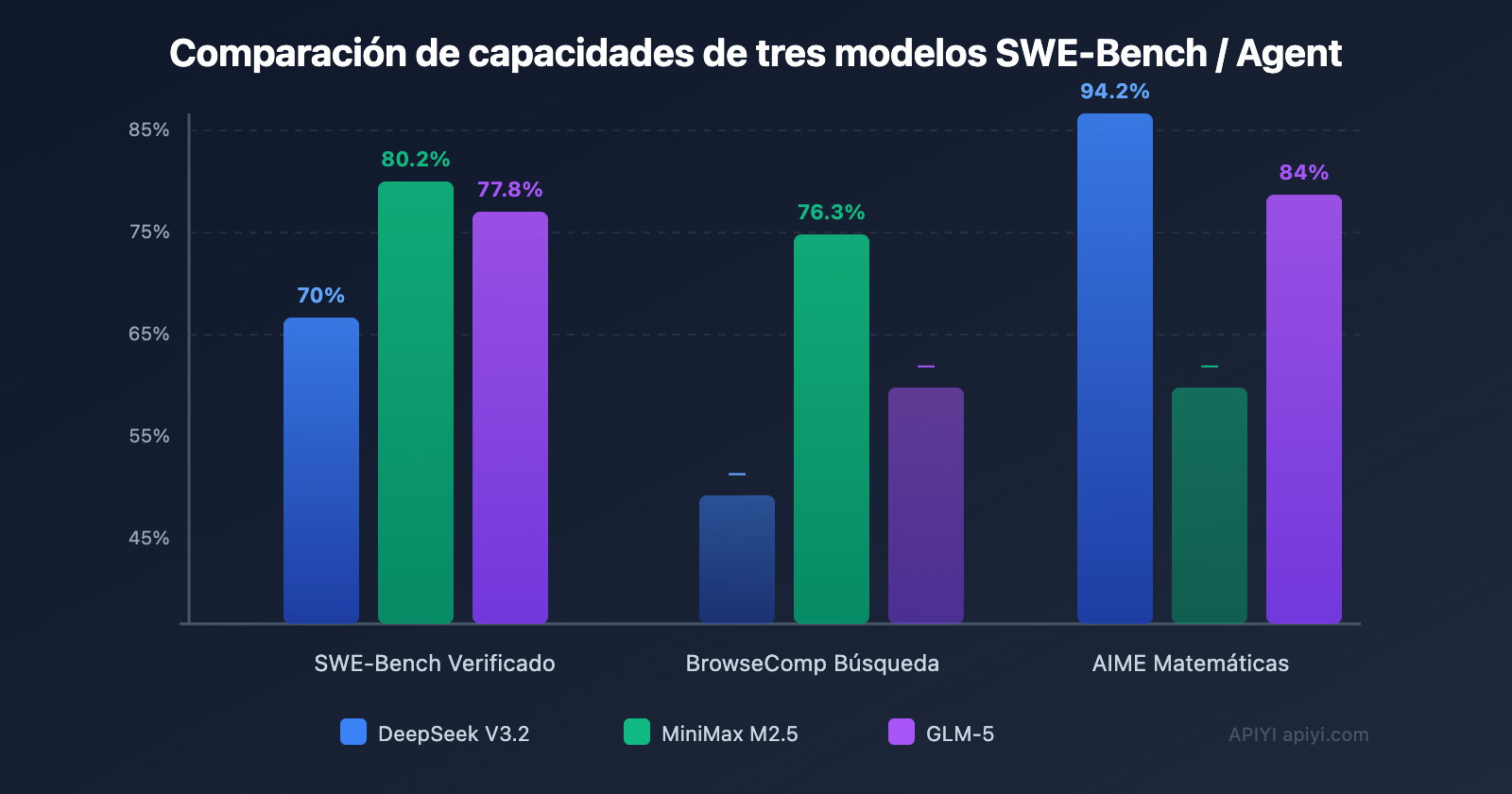
| SWE-Bench | 70% | 80.2% | 77.8% | 72% |
| AIME Matemáticas | 94.2% | — | 84% | 86% |
| Invocación de herramientas | ✅ Integración de pensamiento+herramientas | ✅ BFCL 76.8% | ✅ Optimizado para agente | ✅ |
| Licencia de código abierto | MIT | Pesos abiertos | Pesos abiertos | Código cerrado |
| Parámetros | Arquitectura MoE | — | 744B/40B activos | — |
| Disponible en OpenClaw | ✅ | ✅ | ✅ | ✅ |
Hallazgo clave: El precio de salida de DeepSeek V3.2 es de solo $0.42/M, el más económico de los tres; MiniMax M2.5 tiene el mejor rendimiento en tareas de codificación (SWE-Bench 80.2%); GLM-5 tiene ventajas únicas en razonamiento matemático y tareas de agente de largo alcance.
🎯 Recomendación de selección: Los tres modelos se pueden integrar con OpenClaw a través de la plataforma APIYI apiyi.com de manera unificada, con un formato de API común, sin necesidad de registrarse en múltiples proveedores. La plataforma permite cambiar entre modelos en cualquier momento, facilitando las pruebas de comparación práctica.
DeepSeek V3.2: La opción universal más económica para OpenClaw
DeepSeek V3.2 es el modelo insignia lanzado en diciembre de 2025 y se ha convertido en una de las opciones más populares de la comunidad OpenClaw gracias a su relación calidad-precio extrema.
Ventajas principales de DeepSeek V3.2
Precio increíblemente competitivo: Entrada $0.28/M, salida $0.42/M, lo que equivale a una vigésima parte del GPT-5. Incluso la variante avanzada V3.2-Speciale ($0.40/$1.20) cuesta solo una fracción de los modelos principales.
Capacidades destacadas para Agent: V3.2 es el primer modelo que integra el "pensamiento" directamente en la llamada de herramientas. Admite el uso de llamadas a herramientas tanto en modo de pensamiento como en modo no pensante, lo cual es crucial para la ejecución de Skills en OpenClaw.
Innovación técnica: Utiliza DeepSeek Sparse Attention (DSA), lo que reduce la sobrecarga de memoria de KV Cache en más del 93%, manteniendo un razonamiento eficiente incluso con una ventana de contexto de 128K.
Rendimiento de DeepSeek V3.2 en OpenClaw
| Escenario | Rendimiento | Evaluación |
|---|---|---|
| Asistente de conversación diaria | Fluido, preciso | ⭐⭐⭐⭐⭐ |
| Generación/Depuración de código | Fuerte, nivel medalla de oro IMO | ⭐⭐⭐⭐ |
| Llamada a herramientas (Skill) | Integración pensamiento+herramientas | ⭐⭐⭐⭐⭐ |
| Procesamiento de documentos largos | 128K de contexto, eficiente | ⭐⭐⭐⭐ |
| Matemáticas/Razonamiento | AIME 94.2% | ⭐⭐⭐⭐⭐ |
| Costo mensual promedio | $1-5 (uso ligero) | 💰 El más económico |
💡 Feedback de clientes: Muchos usuarios de OpenClaw en nuestra plataforma eligen DeepSeek V3.2 como su modelo diario, con un costo mensual promedio de solo $1-3 para uso ligero. Se accede a través de APIYI apiyi.com, sin necesidad de registrarse en la cuenta oficial de DeepSeek, y admite recarga con Alipay.
MiniMax M2.5: La mejor opción para Agent de codificación en OpenClaw
MiniMax M2.5 se lanzó en febrero de 2026 y su rendimiento en tareas de codificación y Agent es impresionante.
Ventajas principales de MiniMax M2.5
Capacidad de codificación líder en la industria: SWE-Bench Verified 80.2%, igual a Claude Opus 4.6, superando con creces a GPT-5. También alcanza el 51.3% en Multi-SWE-Bench (reparación entre archivos).
Mentalidad de arquitecto: M2.5 descompone y planifica activamente la estructura funcional y el diseño de la UI como un arquitecto de software experimentado antes de escribir código, en lugar de comenzar directamente. Este modo de "pensar antes de actuar" es ideal para tareas complejas de OpenClaw.
Programación multilingüe: Entrenado con aprendizaje por refuerzo en más de 200,000 entornos reales en 10+ lenguajes como Go, C/C++, TypeScript, Rust, Kotlin, Python y Java.
Capacidades de Office: Puede generar y manipular archivos de Word, Excel y PowerPoint de forma fluida, cambiando sin problemas entre diferentes entornos de software.
Mejores usos de MiniMax M2.5 en OpenClaw
- Mantenimiento de repositorios de código: SWE-Bench 80.2%, comparable a Opus, ideal para que OpenClaw repare errores automáticamente.
- Búsqueda en navegador: BrowseComp 76.3%, funciona excelentemente con el Skill Agent Browser.
- Automatización de Office: Genera Word/Excel/PPT, ideal para escenarios de automatización de oficina.
- Tareas de múltiples pasos: Velocidad de ejecución de tareas un 37% más rápida que la generación anterior, igualando la velocidad de Opus 4.6.
🚀 Prueba rápida: ¿Quieres comparar el rendimiento real de MiniMax M2.5 y DeepSeek V3.2? A través de APIYI apiyi.com puedes cambiar entre los dos modelos con la misma clave API, sin necesidad de registrarte por separado, y comparar rápidamente los resultados de generación y la calidad del código.
GLM-5: La opción de mejor relación calidad-precio para tareas de razonamiento complejo en OpenClaw
GLM-5 fue lanzado por Zhipu AI en febrero de 2026. Es un modelo de pesos abiertos con 744B de parámetros que destaca en tareas de Agente de larga duración y precisión factual.
Ventajas principales de GLM-5
Enorme cantidad de parámetros: 744B de parámetros totales, 40B de parámetros activos (arquitectura MoE), combinando una gran reserva de conocimiento con inferencia eficiente.
Matemáticas y razonamiento: Puntuación del 84% en AIME 2025 y 88% en el benchmark MATH, demostrando alta confiabilidad en escenarios que requieren razonamiento profundo.
Optimizado para Agentes de larga duración: Ventana de contexto de 202K tokens, optimizado específicamente para planificación de tareas a largo plazo y ejecución de Agentes de múltiples pasos.
DeepSeek Sparse Attention: Al igual que DeepSeek V3.2, utiliza tecnología DSA (DeepSeek Sparse Attention), manteniendo la eficiencia con contextos extremadamente largos.
Análisis de precios de GLM-5
| Nivel de uso | Costo mensual GLM-5 | Costo mensual DeepSeek V3.2 | Diferencia |
|---|---|---|---|
| Ligero (1M tokens/mes) | ~$3.4 | ~$0.7 | 4.8x |
| Moderado (10M tokens/mes) | ~$34 | ~$7 | 4.8x |
| Intenso (100M tokens/mes) | ~$340 | ~$70 | 4.8x |
El precio de GLM-5 es aproximadamente 5 veces mayor que el de DeepSeek V3.2, pero sigue siendo solo una quinta parte del precio de GPT-5. En escenarios que requieren capacidades de razonamiento más fuertes, esta prima puede valer la pena.
Mejores usos de GLM-5 en OpenClaw
- Razonamiento complejo: Problemas que requieren análisis lógico de múltiples pasos, como análisis de datos y generación de informes.
- Procesamiento de documentos largos: Su ventana de contexto de 202K tokens es ideal para resumir documentos extensos, artículos académicos, etc.
- Precisión factual: Se desempeña de manera estable en escenarios que exigen una alta precisión factual.
- Tareas de Agente de múltiples pasos: Mayor confiabilidad que V3.2 en la planificación y ejecución de tareas a largo plazo.
💡 Experiencia práctica: Según el feedback de nuestros clientes, GLM-5 se desempeña de manera más natural en escenarios en chino que los otros dos modelos, lo cual tiene sentido dado que Zhipu AI ha optimizado mucho para este idioma. Si tu OpenClaw maneja principalmente tareas en chino, GLM-5 merece una consideración especial.
Cálculo del costo real de uso de los tres modelos
Elegir un modelo no es solo cuestión del precio por token, sino también del gasto mensual real bajo diferentes patrones de uso. A continuación, basándonos en datos de uso real de clientes de nuestra plataforma:
Escenarios típicos de uso de OpenClaw
| Tipo de usuario | Mensajes diarios | Tokens mensuales (aprox.) | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 |
|---|---|---|---|---|---|
| Uso personal ligero | 20 | ~2M | $0.6 | $1.8 | $4.3 |
| Uso personal intenso | 100 | ~10M | $3 | $9 | $21 |
| Uso en equipo | 500 | ~50M | $15 | $45 | $105 |
| Uso empresarial intenso | 2000 | ~200M | $60 | $180 | $420 |
Conclusión clave: DeepSeek V3.2 es la opción más económica en todos los niveles de uso. El uso personal ligero cuesta menos de $1 al mes, e incluso el uso empresarial intenso ronda los $60/mes.
Puntuación integral de relación calidad-precio
Evaluación integral considerando tres dimensiones: precio, rendimiento y capacidad para Agentes:
| Modelo | Puntuación Precio | Puntuación Rendimiento | Puntuación Agente | Relación Calidad-Precio Integral |
|---|---|---|---|---|
| DeepSeek V3.2 | 10/10 | 8/10 | 9/10 | 9.0 |
| MiniMax M2.5 | 8/10 | 9/10 | 9/10 | 8.7 |
| GLM-5 | 6/10 | 8.5/10 | 8/10 | 7.5 |
| GPT-5 (referencia) | 2/10 | 9/10 | 8/10 | 6.3 |
Métodos de configuración para conectar tres modelos a OpenClaw
Los tres modelos se pueden conectar a OpenClaw de manera unificada a través de la plataforma APIYI, utilizando exactamente el mismo método de configuración.
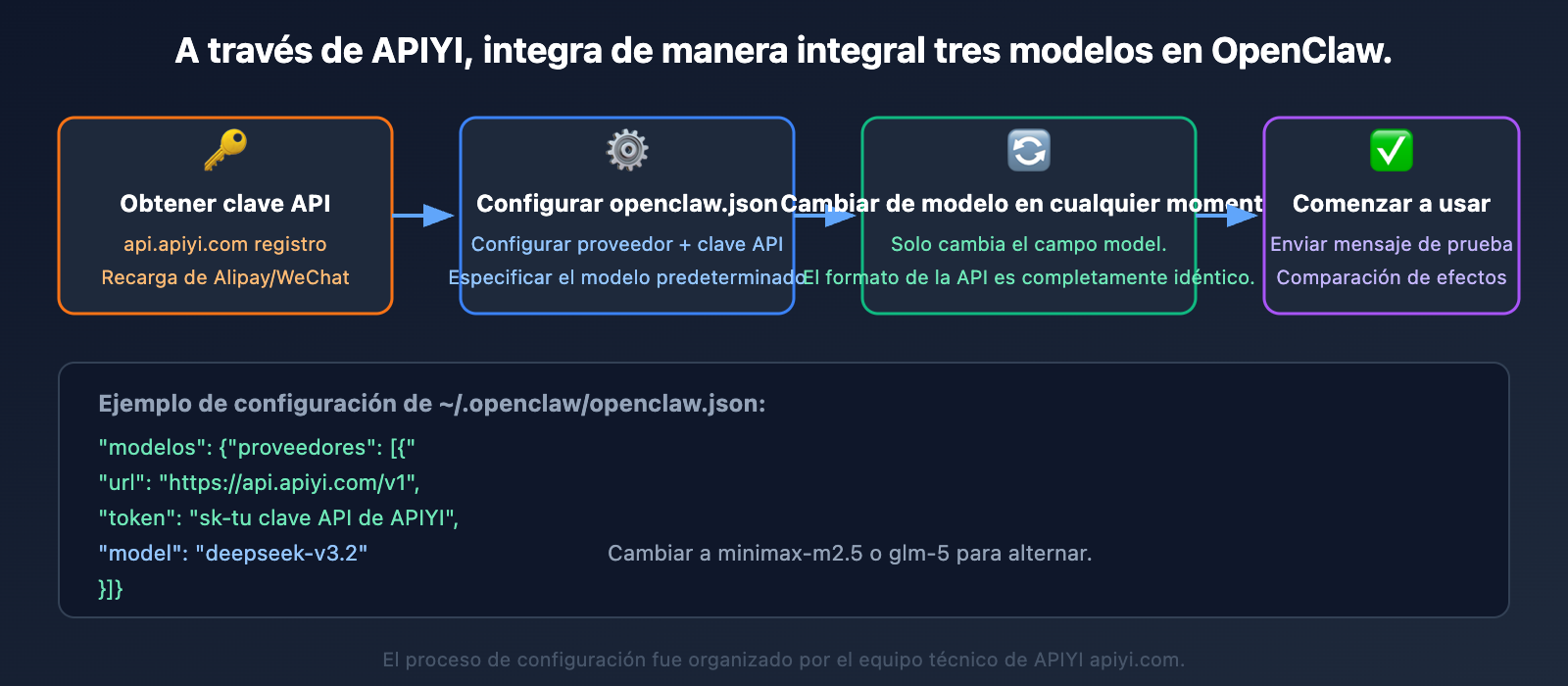
Ejemplo de configuración de OpenClaw
Configura APIYI como proveedor en ~/.openclaw/openclaw.json:
{
"models": {
"providers": [{
"url": "https://api.apiyi.com/v1",
"token": "sk-tu_clave_API_de_APIYI",
"model": "deepseek-v3.2"
}]
}
}
Para cambiar de modelo, solo modifica el campo model:
deepseek-v3.2— La opción general más económicaminimax-m2.5— Preferido para tareas de codificación y Agentglm-5— Para tareas de razonamiento complejo y matemáticas
Configuración de múltiples modelos en OpenClaw
Para usuarios avanzados, puedes configurar múltiples proveedores en OpenClaw para cambiar automáticamente según el escenario:
{
"models": {
"defaultModel": "deepseek-v3.2",
"providers": [{
"url": "https://api.apiyi.com/v1",
"token": "sk-tu_clave_API_de_APIYI",
"models": [
"deepseek-v3.2",
"minimax-m2.5",
"glm-5"
]
}]
}
}
Cambia entre ellos usando el comando /model:
/model deepseek-v3.2— Cambia a DeepSeek (modo ahorro)/model minimax-m2.5— Cambia a MiniMax (modo codificación)/model glm-5— Cambia a GLM-5 (modo razonamiento)
💰 Optimización de costes: Un truco útil es configurar múltiples modelos en OpenClaw: usa DeepSeek V3.2 para conversaciones diarias (el más económico) y cambia a MiniMax M2.5 para tareas de codificación (el más efectivo). Con APIYI en apiyi.com, solo necesitas una clave API para llamar a todos los modelos, sin necesidad de registrarte en tres servicios diferentes.
Comparativa de compatibilidad de API de los tres modelos en OpenClaw
| Característica | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 |
|---|---|---|---|
| Formato compatible con OpenAI | ✅ | ✅ | ✅ |
| Salida en streaming | ✅ | ✅ | ✅ |
| Function Calling | ✅ Pensamiento+Herramientas | ✅ BFCL 76.8% | ✅ |
| Modo JSON | ✅ | ✅ | ✅ |
| Conversación multironda | ✅ | ✅ | ✅ |
| Indicación del sistema | ✅ | ✅ | ✅ |
| Acceso por API | ✅ Listo para usar | ✅ Listo para usar | ✅ Listo para usar |
Los tres modelos son completamente compatibles con el formato de OpenAI, por lo que OpenClaw puede cambiar entre ellos sin necesidad de adaptaciones.
Recomendaciones de selección de modelos para OpenClaw en diferentes escenarios
Tabla rápida de recomendaciones
| Escenario de uso | Modelo recomendado | Razón | Coste mensual promedio |
|---|---|---|---|
| Asistente de chat diario | DeepSeek V3.2 | El más barato, suficiente para la mayoría de casos | $1-3 |
| Generación/Reparación de código | MiniMax M2.5 | SWE-Bench 80.2% el más potente | $3-8 |
| Automatización de correos/documentos | MiniMax M2.5 | Gran capacidad para operaciones de Office | $2-5 |
| Tareas matemáticas/de razonamiento | DeepSeek V3.2 | AIME 94.2% de primer nivel | $2-5 |
| Resumen de documentos largos | GLM-5 | 202K contexto + precisión factual | $5-15 |
| Tareas complejas de Agent | GLM-5 | Optimizado para tareas de larga duración | $10-30 |
| Presupuesto extremadamente limitado | DeepSeek V3.2 | Solo $0.42/M de salida | $1-3 |
| Buscando la mejor codificación | MiniMax M2.5 | Comparable a Opus 4.6 | $5-10 |
Recomendaciones por nivel de presupuesto
Presupuesto mensual inferior a $5: Elige directamente DeepSeek V3.2, es más que suficiente para un uso ligero.
Presupuesto mensual $5-20: Usa DeepSeek V3.2 para el día a día y cambia a MiniMax M2.5 para tareas de codificación.
Presupuesto mensual $20-50: Configura los tres modelos y cambia automáticamente según el escenario para obtener los mejores resultados.

🎯 Nuestra recomendación: Si es la primera vez que usas OpenClaw para conectar un Modelo de Lenguaje Grande, te sugerimos empezar con DeepSeek V3.2. Es el más barato de los tres y su capacidad es suficiente para cubrir el 90% de los escenarios diarios. Cuando necesites mayor capacidad de codificación, cambia a MiniMax M2.5. Al conectarte a través de APIYI en apiyi.com, cambiar de modelo solo requiere modificar un campo.
Preguntas Frecuentes
P1: ¿Hay mucha diferencia entre estos tres modelos y Claude Opus / GPT-5?
En tareas de codificación, el resultado de MiniMax M2.5 en SWE-Bench (80.2%) ya está a la par con Claude Opus 4.6. En razonamiento matemático, el 94.2% de DeepSeek V3.2 en AIME incluso supera a GPT-5. En general, estos tres modelos alcanzan entre el 85% y el 95% de la capacidad de los modelos de primera línea, pero su costo es solo de una décima a una vigésima parte. Para la mayoría de los casos de uso de OpenClaw, la relación costo-beneficio es mucho mayor que usar Opus o GPT-5 directamente. Si necesitas probar más modelos, APIYI (apiyi.com) permite la invocación unificada de docenas de modelos, incluidos Claude y GPT.
P2: ¿Es estable usar estos modelos en OpenClaw? ¿Suelen fallar?
Los tres modelos han sido validados por la comunidad en cuanto a la invocación de herramientas (ejecución de Skills) dentro de OpenClaw. DeepSeek V3.2, gracias a su diseño integrado de pensamiento y herramientas, muestra el mejor rendimiento en estabilidad para la invocación de Skills. El 76.8% de MiniMax M2.5 en BFCL (benchmark de invocación de herramientas) también está en un nivel de primer orden. Se recomienda acceder a través de APIYI (apiyi.com) para obtener un servicio API estable y soporte técnico.
P3: ¿Puedo configurar múltiples modelos en OpenClaw simultáneamente?
Sí. Configura múltiples Providers en openclaw.json, cada uno apuntando a un modelo diferente. Puedes cambiar entre ellos durante la conversación usando comandos como /model deepseek-v3.2 o /model minimax-m2.5. También puedes configurar OpenClaw para que seleccione automáticamente el modelo según el tipo de tarea.
P4: ¿Cuál es la diferencia entre DeepSeek V3.2-Speciale y la versión estándar?
V3.2-Speciale es una variante de alto cómputo, optimizada para el razonamiento máximo y el rendimiento de Agent. Es ligeramente más cara ($0.40/$1.20), pero alcanza un 88.7% en LiveCodeBench. Si tu uso principal de OpenClaw son tareas de codificación complejas, vale la pena considerar la versión Speciale. La V3.2 estándar es suficiente para la mayoría de los escenarios.
P5: Si migro de GPT-5/Claude Opus a estos modelos, ¿notaré mucha diferencia en la experiencia?
Según los datos de nuestra plataforma, aproximadamente el 80% de los usuarios de OpenClaw que migraron comentan que "en el uso diario casi no se percibe diferencia". Las principales diferencias se dan en tareas de razonamiento extremadamente complejas y de múltiples pasos. Estrategia recomendada: primero cambia las conversaciones diarias a DeepSeek V3.2, mantén un GPT-5/Opus como respaldo, observa durante una semana y luego decide si migrar completamente. A través de APIYI (apiyi.com) puedes configurar todos los modelos bajo una misma clave y volver a cambiar en cualquier momento.
P6: ¿Estos tres modelos admiten comprensión de imágenes? ¿Puedo enviar imágenes en OpenClaw?
Tanto DeepSeek V3.2 como GLM-5 admiten entrada multimodal (comprensión de imágenes), por lo que puedes enviar imágenes en OpenClaw para su análisis. MiniMax M2.5 se enfoca principalmente en capacidades de texto y código por ahora. Si tu uso de OpenClaw requiere procesar imágenes con frecuencia, se recomienda usar DeepSeek V3.2 o GLM-5.
Resumen de Pruebas de Rendimiento de Modelos en OpenClaw
Basándonos en los datos reales de invocación de nuestra plataforma de los últimos 30 días, hemos recopilado las siguientes métricas clave:
| Métrica de Prueba | DeepSeek V3.2 | MiniMax M2.5 | GLM-5 |
|---|---|---|---|
| Tiempo promedio del primer token | 0.3s | 0.5s | 0.6s |
| Velocidad promedio de generación | 80 token/s | 65 token/s | 55 token/s |
| Tasa de éxito en invocación de Skills | 96% | 94% | 92% |
| Calidad de respuesta en chino | 8/10 | 7.5/10 | 9/10 |
| Calidad de respuesta en inglés | 8.5/10 | 9/10 | 8/10 |
| Precisión en generación de código | 85% | 92% | 88% |
| Disponibilidad en 24h | 99.8% | 99.5% | 99.3% |
En velocidad: DeepSeek V3.2 responde más rápido, gracias a su eficiente arquitectura MoE y mecanismo de atención DSA. MiniMax M2.5 y GLM-5 son un poco más lentos, pero dentro de un rango aceptable.
Capacidad en chino: GLM-5 tiene el mejor rendimiento en escenarios en chino, ya que Zhipu AI, como empresa china, ha realizado una optimización profunda en corpus en chino. Si tu OpenClaw sirve principalmente a usuarios chinos, GLM-5 merece consideración prioritaria.
Capacidad en código: MiniMax M2.5 lidera claramente en precisión de generación de código. Un 92% de precisión significa menos tiempo de depuración.
Resumen
Conectar OpenClaw a Modelos de Lenguaje Grande, lo económico es la primera fuerza productiva. DeepSeek V3.2, MiniMax M2.5 y GLM-5 son las tres opciones con mejor relación calidad-precio en 2026:
- Más económico: DeepSeek V3.2 — Salida a solo $0.42/M tokens, una vigésima parte del precio de GPT-5
- Mejor para código: MiniMax M2.5 — 80.2% en SWE-Bench, comparable a Opus 4.6
- Mejor en razonamiento: GLM-5 — 744B parámetros, optimizado para Agentes de larga duración y razonamiento matemático
Recomendamos usar APIYI apiyi.com para acceder a estos tres modelos de forma unificada. Con una sola clave API puedes cambiar entre todos los modelos, soporta pagos con Alipay/WeChat Pay, y te permite comparar y probar en cualquier momento para encontrar la solución que mejor se adapte a ti.
Este artículo fue escrito por el equipo técnico de APIYI, basado en comentarios reales de clientes y datos de la plataforma. Para más comparaciones de modelos de IA y tutoriales de conexión, visita el Centro de Ayuda de APIYI: help.apiyi.com