Author's Note: A deep dive into the coding capabilities, agent performance, and API integration for MiniMax-M2.5 and M2.5-Lightning. With an SWE-Bench score of 80.2%, it rivals Opus 4.6 at just 1/60th of the cost.
On February 12, 2026, MiniMax released two model versions: MiniMax-M2.5 and M2.5-Lightning. This marks the first open-source model to surpass Claude Sonnet in coding ability, hitting 80.2% on SWE-Bench Verified—just 0.6 percentage points behind Claude Opus 4.6. Both models are now live on the APIYI platform. You can start using them today, and by participating in top-up promotions, you can get them for 20% off the official price.
Core Value: Through real-world data and code examples, you'll learn the key differences between the two MiniMax-M2.5 versions, choose the one that fits your needs, and get up and running with the API in no time.

MiniMax-M2.5 Core Capabilities Overview
| Key Metrics | MiniMax-M2.5 Standard | MiniMax-M2.5-Lightning | Value Proposition |
|---|---|---|---|
| SWE-Bench Verified | 80.2% | 80.2% (Same capability) | Rivals Opus 4.6's 80.8% |
| Output Speed | ~50 TPS | ~100 TPS | Lightning is 2x faster |
| Output Price | $0.15/$1.20 per million tokens | $0.30/$2.40 per million tokens | Standard is only 1/63rd of Opus |
| BFCL Tool Calling | 76.8% | 76.8% (Same capability) | Significantly ahead of Opus's 63.3% |
| Context Window | 205K tokens | 205K tokens | Supports large codebase analysis |
MiniMax-M2.5 Coding Capabilities in Detail
MiniMax-M2.5 utilizes a Mixture of Experts (MoE) architecture with a total of 230B parameters, but it only activates 10B parameters during inference. This design allows the model to maintain cutting-edge coding performance while drastically reducing inference costs.
In coding tasks, M2.5 exhibits a unique "Spec-writing tendency"—it tends to break down the project architecture and plan the design before actually writing any code. This behavioral pattern makes it particularly effective at handling complex, multi-file projects, as evidenced by its Multi-SWE-Bench score of 51.3%, which even edges out Claude Opus 4.6's 50.3%.
The model supports full-stack development across 10+ programming languages, including Python, Go, C/C++, TypeScript, Rust, Java, JavaScript, Kotlin, PHP, and more. It's also versatile enough to handle projects for Web, Android, iOS, and Windows platforms.
MiniMax-M2.5 Agent and Tool-Calling Capabilities
M2.5 scored 76.8% on the BFCL Multi-Turn benchmark, significantly outperforming Claude Opus 4.6 (63.3%) and Gemini 3 Pro (61.0%). This makes M2.5 the strongest choice currently available for Agent scenarios that require multi-turn dialogues and multi-tool collaboration.
Compared to the previous generation M2.1, M2.5 reduces the number of tool-calling rounds needed to complete Agent tasks by about 20%, and its SWE-Bench Verified evaluation speed has increased by 37%. More efficient task decomposition directly translates to lower token consumption and reduced calling costs.
MiniMax-M2.5 Standard vs. Lightning Comparison
Choosing which version of MiniMax-M2.5 to use depends entirely on your specific use case. Both versions offer identical model capabilities; the core differences lie in inference speed and pricing.
| Dimension | M2.5 Standard | M2.5-Lightning | Recommendation |
|---|---|---|---|
| API Model ID | MiniMax-M2.5 |
MiniMax-M2.5-highspeed |
— |
| Inference Speed | ~50 TPS | ~100 TPS | Choose Lightning for real-time response |
| Input Price | $0.15/M tokens | $0.30/M tokens | Choose Standard for batch tasks |
| Output Price | $1.20/M tokens | $2.40/M tokens | Standard is half the price |
| Running Cost | ~$0.30/hour | ~$1.00/hour | Choose Standard for background tasks |
| Coding Ability | Identical | Identical | No difference |
| Tool Calling | Identical | Identical | No difference |
MiniMax-M2.5 Version Selection Scenario Guide
When to choose the Lightning (High-Speed) version:
- IDE coding assistant integrations that need low-latency, real-time code completion and refactoring suggestions.
- Interactive agent chats where users expect fast responses for customer service or tech support.
- Real-time search-augmented apps requiring quick feedback for web browsing and info retrieval.
When to choose the Standard version:
- Backend batch code reviews and auto-fixes where real-time interaction isn't necessary.
- Large-scale agent task orchestration and long-running asynchronous workflows.
- Budget-sensitive, high-throughput applications aiming for the lowest unit cost.
🎯 Pro Tip: If you're not sure which one to pick, we recommend testing both on the APIYI (apiyi.com) platform. You can switch between the Standard and Lightning versions under the same interface just by changing the
modelparameter to compare latency and performance quickly.
MiniMax-M2.5 vs. Competitors: Coding Ability Comparison

| Model | SWE-Bench Verified | BFCL Multi-Turn | Output Price/M | Tasks per $100 |
|---|---|---|---|---|
| MiniMax-M2.5 | 80.2% | 76.8% | $1.20 | ~328 |
| MiniMax-M2.5-Lightning | 80.2% | 76.8% | $2.40 | ~164 |
| Claude Opus 4.6 | 80.8% | 63.3% | ~$75 | ~30 |
| GPT-5.2 | 80.0% | — | ~$60 | ~30 |
| Gemini 3 Pro | 78.0% | 61.0% | ~$20 | ~90 |
Based on the data, MiniMax-M2.5 has reached frontier levels in coding capability. Its SWE-Bench Verified score of 80.2% is only 0.6% lower than Opus 4.6, yet the price difference is over 60x. In terms of tool calling, M2.5's BFCL score of 76.8% significantly leads all competitors.
For teams needing to deploy coding agents at scale, M2.5's cost advantage means a $100 budget can complete about 328 tasks, compared to only about 30 with Opus 4.6.
Comparison Note: The benchmark data above comes from official model releases and the third-party evaluation agency Artificial Analysis. Actual performance may vary depending on specific tasks; we recommend verifying with real-world scenarios via APIYI (apiyi.com).
MiniMax-M2.5 API Quick Integration
Minimalist Example
Here's the simplest way to integrate MiniMax-M2.5 via the APIYI platform—you can get it running in just 10 lines of code:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="MiniMax-M2.5", # Switch to MiniMax-M2.5-Lightning for the high-speed version
messages=[{"role": "user", "content": "用 Python 实现一个 LRU 缓存"}]
)
print(response.choices[0].message.content)
View full implementation code (including streaming output and tool calls)
from openai import OpenAI
from typing import Optional
def call_minimax_m25(
prompt: str,
model: str = "MiniMax-M2.5",
system_prompt: Optional[str] = None,
max_tokens: int = 4096,
stream: bool = False
) -> str:
"""
调用 MiniMax-M2.5 API
Args:
prompt: 用户输入
model: MiniMax-M2.5 或 MiniMax-M2.5-Lightning
system_prompt: 系统提示词
max_tokens: 最大输出 token 数
stream: 是否启用流式输出
Returns:
模型响应内容
"""
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=max_tokens,
stream=stream
)
if stream:
result = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
result += content
print(content, end="", flush=True)
print()
return result
else:
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 使用示例:编码任务
result = call_minimax_m25(
prompt="重构以下代码,提升性能并添加错误处理",
model="MiniMax-M2.5-Lightning",
system_prompt="你是一个资深全栈工程师,擅长代码重构和性能优化",
stream=True
)
Pro Tip: Get free test credits via APIYI (apiyi.com) to quickly verify MiniMax-M2.5's coding performance in your actual projects. The platform supports OpenAI-compatible interfaces, so you can switch existing code just by modifying the
base_urlandmodelparameters.
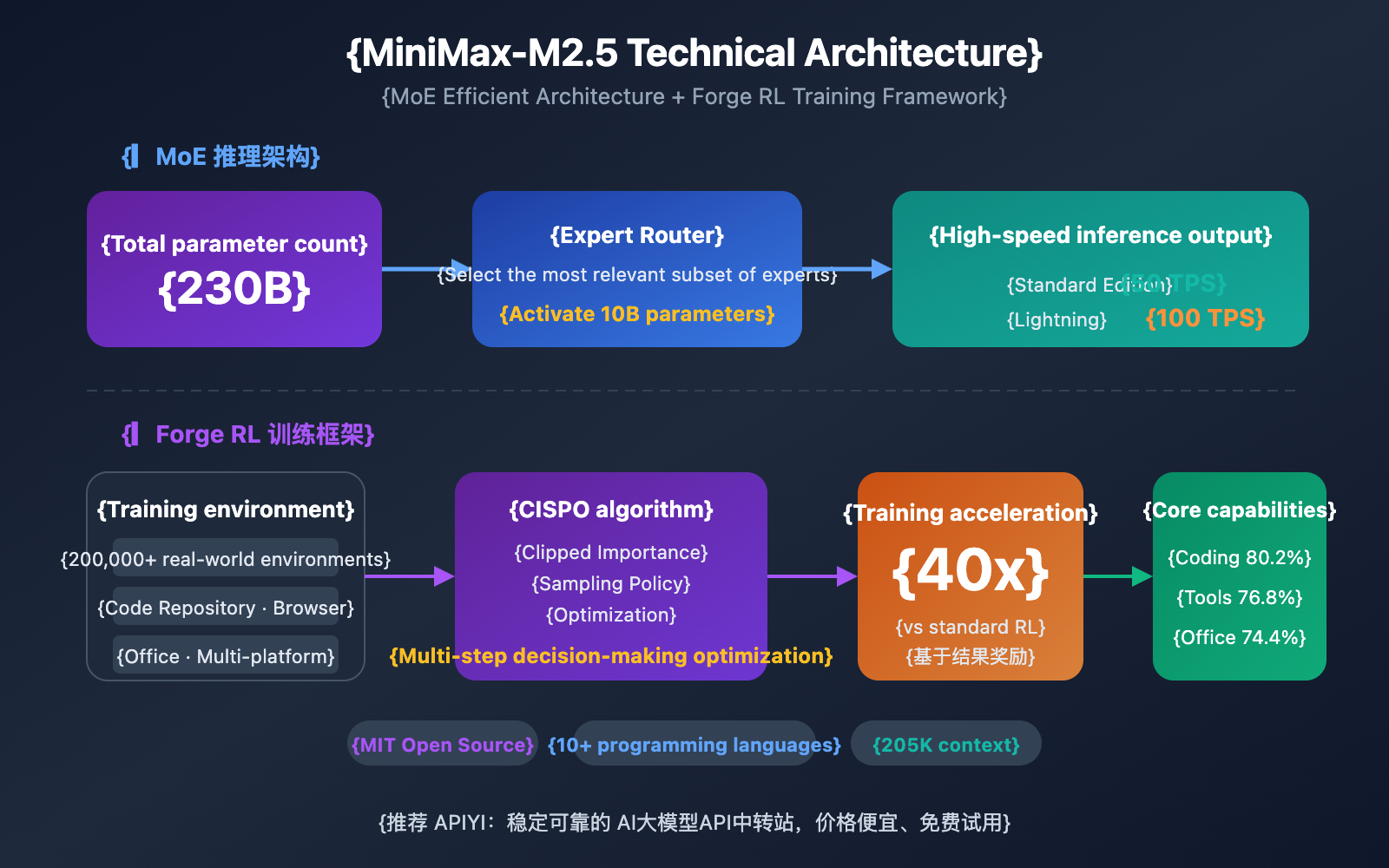
MiniMax-M2.5 Technical Architecture Analysis
The core competitiveness of MiniMax-M2.5 stems from two major technical innovations: the efficient MoE (Mixture of Experts) architecture and the Forge RL training framework.
MiniMax-M2.5 MoE Architecture Advantages
| Architectural Parameter | MiniMax-M2.5 | Traditional Dense Models | Advantage Description |
|---|---|---|---|
| Total Parameters | 230B | Usually 70B-200B | Larger knowledge capacity |
| Activated Parameters | 10B | Equal to total parameters | Extremely low inference cost |
| Inference Efficiency | 50-100 TPS | 10-30 TPS | 3-10x speed improvement |
| Unit Cost | $1.20/M output | $20-$75/M output | 20-60x cost reduction |
The core idea behind the MoE architecture is "division of labor among experts"—the model contains multiple sets of expert networks, and each inference only activates the subset of experts most relevant to the current task. With only 10B activated parameters, M2.5 achieves performance close to a 230B dense model, making it the smallest and most cost-effective choice among current Tier 1 models.
MiniMax-M2.5 Forge RL Training Framework
Another key technology in M2.5 is the Forge Reinforcement Learning (RL) framework:
- Training Environment Scale: Over 200,000 real-world training environments, covering codebases, web browsers, and office applications.
- Training Algorithm: CISPO (Clipped Importance Sampling Policy Optimization), specifically designed for multi-step decision-making tasks.
- Training Efficiency: Achieves 40x training acceleration compared to standard RL methods.
- Reward Mechanism: An outcome-based reward system, rather than traditional Reinforcement Learning from Human Feedback (RLHF).
This training approach makes M2.5 more robust in real-world coding and Agent tasks, enabling efficient task decomposition, tool selection, and multi-step execution.
🎯 Practical Advice: MiniMax-M2.5 is now live on the APIYI (apiyi.com) platform. We recommend developers use the free credits to test coding and Agent scenarios first, then choose between the standard or Lightning version based on your actual latency and performance needs.
FAQ
Q1: Is there a difference in capability between MiniMax-M2.5 Standard and the Lightning version?
There's no difference. The model capabilities of both versions are identical, with the same scores across all benchmarks like SWE-Bench and BFCL. The only differences are the inference speed (Standard at 50 TPS vs. Lightning at 100 TPS) and their respective pricing. When choosing, you only need to consider your latency requirements and budget.
Q2: Is MiniMax-M2.5 a suitable replacement for Claude Opus 4.6?
It's definitely worth considering for coding and agent scenarios. M2.5's SWE-Bench score (80.2%) is only 0.6 percentage points behind Opus 4.6, while its tool-calling capability (BFCL 76.8%) is significantly ahead. Price-wise, the M2.5 Standard version is just 1/63 the cost of Opus. We recommend running side-by-side tests in your actual projects via APIYI (apiyi.com) to judge based on your specific use case.
Q3: How can I quickly start testing MiniMax-M2.5?
We recommend using the APIYI platform for a quick setup:
- Visit APIYI (apiyi.com) to register an account.
- Get your API Key and free testing credits.
- Use the code examples provided in this article and change the
modelparameter toMiniMax-M2.5orMiniMax-M2.5-Lightning. - Since it uses an OpenAI-compatible interface, you'll only need to modify the
base_urlin your existing projects.
Summary
Key takeaways for MiniMax-M2.5:
- Cutting-edge Coding Capabilities: With a SWE-Bench Verified score of 80.2% and an industry-leading Multi-SWE-Bench score of 51.3%, it's the first open-source model to surpass Claude Sonnet.
- Top-tier Agent Performance: Its BFCL Multi-Turn score of 76.8% significantly leads all competitors, with tool-calling rounds reduced by 20% compared to the previous generation.
- Extreme Cost-Efficiency: The Standard version's output is priced at just $1.20/M tokens—1/63 the cost of Opus 4.6. You can complete over 10x the tasks for the same budget.
- Flexible Dual-Version Choice: The Standard version is ideal for batch processing and cost-sensitive scenarios, while Lightning is perfect for real-time interaction and low-latency needs.
MiniMax-M2.5 is now live on the APIYI platform, supporting OpenAI-compatible interface calls. We recommend heading over to APIYI (apiyi.com) to grab some free credits and test it out—switching between the two versions is as simple as changing a single model parameter.
📚 References
⚠️ Link Format Note: All external links use the
Resource Name: domain.comformat. This makes them easy to copy while preventing SEO juice leakage (non-clickable).
-
MiniMax M2.5 Official Announcement: Detailed introduction to M2.5's core capabilities and technical details.
- Link:
minimax.io/news/minimax-m25 - Description: Official release document, including full benchmark data and training methodology.
- Link:
-
MiniMax API Documentation: Official API integration guide and model specifications.
- Link:
platform.minimax.io/docs/guides/text-generation - Description: Includes model IDs, context windows, API call examples, and other technical specs.
- Link:
-
Artificial Analysis Evaluation: Independent third-party model evaluation and performance analysis.
- Link:
artificialanalysis.ai/models/minimax-m2-5 - Description: Provides standardized benchmark rankings, real-world speed tests, and price comparisons.
- Link:
-
MiniMax HuggingFace: Open-source model weight downloads.
- Link:
huggingface.co/MiniMaxAI - Description: Open-sourced under the MIT license, supporting private deployment via vLLM/SGLang.
- Link:
Author: Technical Team
Tech Talk: Feel free to discuss your experience with MiniMax-M2.5 in the comments. For more AI model API integration tutorials, visit the APIYI (apiyi.com) tech community.