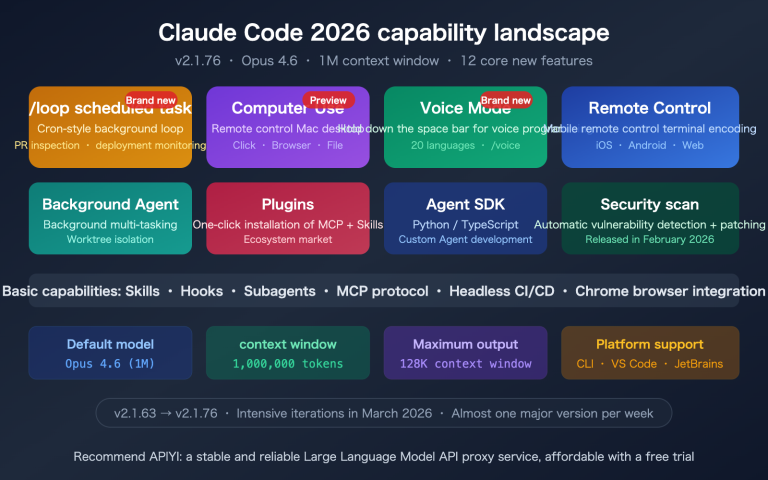
Author's Note: A deep dive into the coding capabilities of MiniMax-M2.5 vs. Claude Opus 4.6 across five dimensions: SWE-Bench, Multi-SWE-Bench, BFCL tool calling, coding speed, and pricing.
Choosing an AI coding assistant is always a top priority for developers. In this post, we'll compare the coding prowess of MiniMax-M2.5 and Claude Opus 4.6 across five key dimensions to help you find the perfect balance between performance and cost.
Core Value: By the end of this article, you'll have a clear understanding of the performance boundaries for both models in real-world coding scenarios, making it obvious which one offers the best bang for your buck in different situations.

Key Differences in Coding Capabilities: MiniMax-M2.5 vs. Claude Opus 4.6
| Dimension | MiniMax-M2.5 | Claude Opus 4.6 | Gap Analysis |
|---|---|---|---|
| SWE-Bench Verified | 80.2% | 80.8% | Opus leads by only 0.6% |
| Multi-SWE-Bench | 51.3% | 50.3% | M2.5 overtakes by 1.0% |
| BFCL Tool Calling | 76.8% | 63.3% | M2.5 leads by 13.5% |
| Output Speed | 50-100 TPS | ~33 TPS | M2.5 is up to 3x faster |
| Output Price | $1.20/M tokens | $25/M tokens | M2.5 is about 20x cheaper |
Decoding the Benchmarks: MiniMax-M2.5 vs. Opus 4.6
Looking at SWE-Bench Verified—the industry's gold standard for coding benchmarks—the gap is incredibly narrow. MiniMax-M2.5's 80.2% score trails Claude Opus 4.6's 80.8% by a mere 0.6 percentage points. SWE-Bench Verified tests a model's ability to fix bugs and implement features in real GitHub Pull Requests, making it the closest thing we have to a real-world dev environment.
What's even more interesting is the Multi-SWE-Bench, which focuses on complex, multi-file projects. Here, MiniMax-M2.5 actually overtakes Opus 4.6 with a score of 51.3% compared to 50.3%. This suggests that M2.5 is more stable when handling complex engineering tasks that require coordinating changes across multiple files.
Official data from MiniMax shows that 80% of new code submissions within their own company are now generated by M2.5, with the model handling 30% of daily tasks. That's a solid real-world validation of its coding chops.
The Tool Calling Gap: MiniMax-M2.5 vs. Opus 4.6
The biggest divide between these two models in the coding space lies in tool calling. In the BFCL Multi-Turn benchmark, MiniMax-M2.5 scored 76.8%, while Claude Opus 4.6 lagged behind at 63.3%—a massive 13.5% difference.
This gap has a huge impact on AI agent programming scenarios. When a model needs to read files, execute commands, call APIs, parse output, and iterate through loops, its tool-calling ability directly dictates efficiency and accuracy. M2.5 requires 20% fewer tool-calling rounds than its predecessor, M2.1, making every call more precise.
That said, Claude Opus 4.6 still holds an industry-leading 62.7% in MCP Atlas (large-scale tool coordination). It still has the upper hand in ultra-complex scenarios that require managing a massive number of tools simultaneously.

MiniMax-M2.5 vs. Opus 4.6: Coding Speed and Efficiency
Coding isn't just about accuracy; speed and efficiency are just as critical. Especially in AI agent programming scenarios, where models need multiple iterations to complete a task, speed directly impacts the development experience and total cost.
| Efficiency Metric | MiniMax-M2.5 | Claude Opus 4.6 | Winner |
|---|---|---|---|
| Output Speed (Standard) | ~50 TPS | ~33 TPS | M2.5 is 1.5x faster |
| Output Speed (Lightning) | ~100 TPS | ~33 TPS | M2.5 is 3x faster |
| SWE-Bench Task Duration | 22.8 mins | 22.9 mins | Roughly equal |
| SWE-Bench Cost per Task | ~$0.15 | ~$3.00 | M2.5 is 20x cheaper |
| Avg. Token Usage/Task | 3.52M tokens | Higher | M2.5 is more token-efficient |
| Tool Call Optimization | 20% fewer than M2.1 | — | M2.5 is more efficient |
Analyzing MiniMax-M2.5's Coding Speed Advantage
In the SWE-Bench Verified evaluation, MiniMax-M2.5 averaged 22.8 minutes per task, almost identical to Claude Opus 4.6's 22.9 minutes. However, the cost structure behind these numbers is worlds apart.
Completing an SWE-Bench task with M2.5 costs about $0.15, while Opus 4.6 costs around $3.00. This means for the same coding quality, M2.5 costs only 1/20th as much as Opus. For teams running coding agents continuously, this gap translates into thousands or even tens of thousands of dollars in monthly savings.
MiniMax-M2.5's high efficiency stems from its MoE (Mixture of Experts) architecture—where only 10B parameters are activated out of a 230B total—and task decomposition optimizations from the Forge RL training framework. When coding, the model performs "Spec-writing" first (architectural design and task breakdown) and then executes efficiently, rather than relying on blind trial and error.
Unique Coding Strengths of Claude Opus 4.6
Even though it's not the leader in cost efficiency, Claude Opus 4.6 has some irreplaceable advantages:
- Terminal-Bench 2.0: 65.4%, leading the industry in complex coding tasks within terminal environments.
- OSWorld: 72.7%, with AI agent computer operation capabilities that far outpace competitors.
- MCP Atlas: 62.7%, ranking first in large-scale tool coordination.
- 1M Context Window: The Beta version supports a 1-million-token context, so you don't need to chunk data when handling massive codebases.
- Adaptive Thinking: Supports four levels of thinking intensity (low/medium/high/max), allowing you to adjust reasoning depth as needed.
For tasks requiring deep reasoning, ultra-long code context understanding, or extremely complex system-level operations, Opus 4.6 remains the most powerful choice currently available.
🎯 Recommendation: Both models have their strengths. We recommend testing them yourself on the APIYI (apiyi.com) platform. The platform supports both MiniMax-M2.5 and Claude Opus 4.6 with a unified interface—just switch the
modelparameter to quickly verify which works best for you.
MiniMax-M2.5 vs. Opus 4.6: Recommended Coding Scenarios
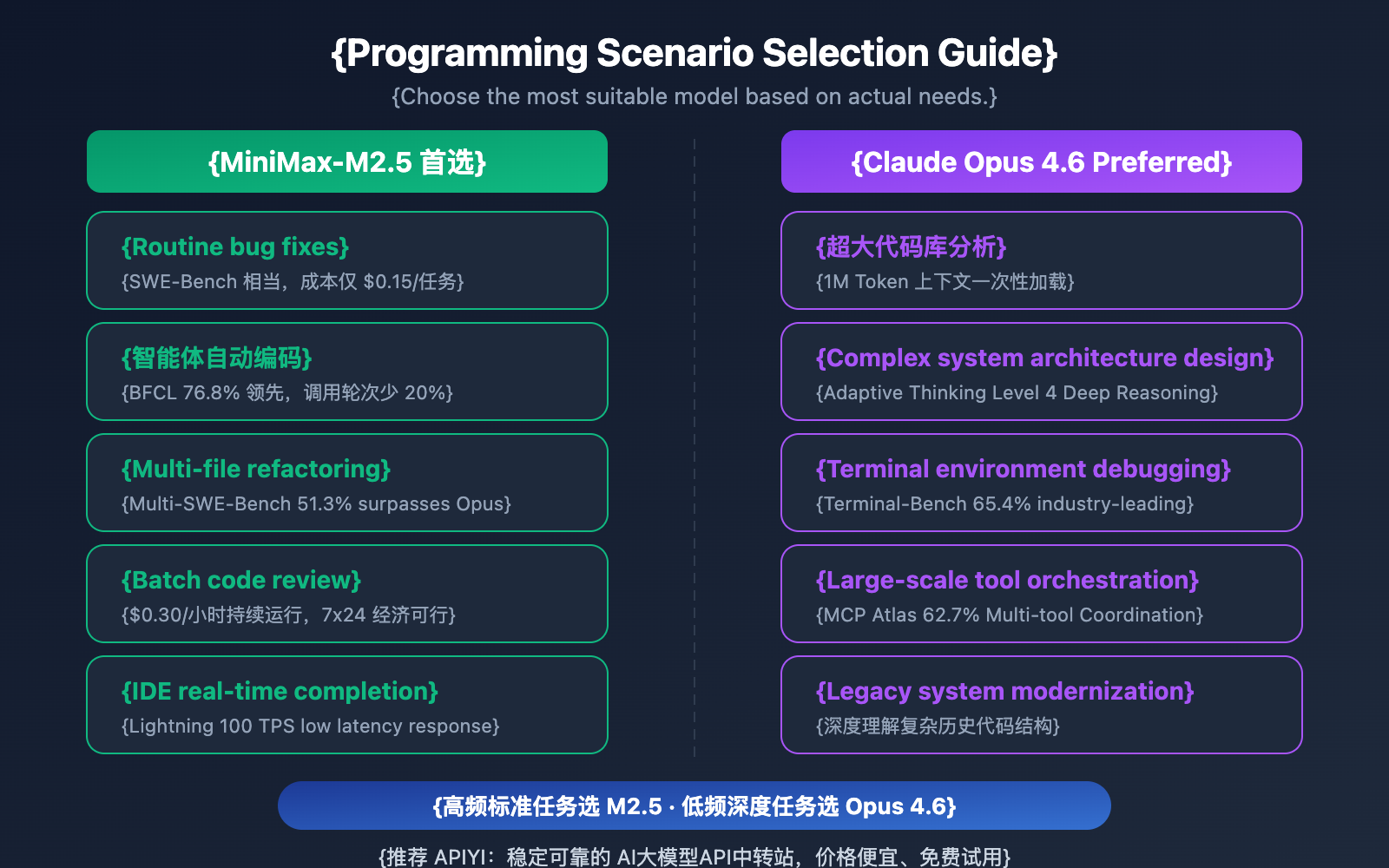
| Coding Scenario | Recommended Model | Reason |
|---|---|---|
| Daily Bug Fixing | MiniMax-M2.5 | Comparable SWE-Bench performance, 20x lower cost |
| Multi-file Refactoring | MiniMax-M2.5 | 1% lead in Multi-SWE-Bench |
| AI Agent Auto-coding | MiniMax-M2.5 | 13.5% lead in BFCL, only $0.15 per task |
| Batch Code Review | MiniMax-M2.5 | High throughput, low cost ($0.30/hr for Standard) |
| IDE Real-time Completion | MiniMax-M2.5 Lightning | Low latency with 100 TPS |
| Large Codebase Analysis | Claude Opus 4.6 | 1M Token context window |
| Complex Architecture Design | Claude Opus 4.6 | Deep reasoning via Adaptive Thinking |
| Complex Terminal Operations | Claude Opus 4.6 | Industry-leading 65.4% on Terminal-Bench |
| Large-scale Tool Orchestration | Claude Opus 4.6 | Industry-leading 62.7% on MCP Atlas |
Best Coding Scenarios for MiniMax-M2.5
MiniMax-M2.5 shines in "high-frequency, standardized, and cost-sensitive" programming tasks:
- CI/CD Auto-remediation: Running continuous agent pipelines for monitoring and fixing. A cost of $0.30/hour makes 24/7 operation economically viable.
- PR Review Bot: Automatically reviewing Pull Requests. Its 76.8% BFCL score ensures precise multi-turn tool interactions.
- Multi-language Full-stack Development: Supports 10+ programming languages (Python, Go, Rust, TypeScript, Java, etc.), covering Web, Android, iOS, and Windows.
- Batch Code Migration: Leverages its 51.3% Multi-SWE-Bench score to handle large-scale refactoring across multiple files.
Best Coding Scenarios for Claude Opus 4.6
Claude Opus 4.6 excels in "low-frequency, high-complexity, and deep-reasoning" programming tasks:
- Architectural Decision Support: Uses Adaptive Thinking (max mode) for in-depth technical solution analysis.
- Legacy System Modernization: Loads entire large codebases at once using the 1M Token context.
- System-level Debugging: Uses its 65.4% Terminal-Bench performance to locate and resolve complex issues within terminal environments.
- Multi-tool Orchestration Platforms: Coordinates IDEs, Git, CI/CD, monitoring, and other tools via MCP Atlas (62.7% score).
Note: These scenario recommendations are based on benchmark data and actual developer feedback. Real-world results may vary depending on your specific project. We recommend performing your own validation on the APIYI (apiyi.com) platform.
MiniMax-M2.5 vs. Opus 4.6: A Comprehensive Programming Cost Comparison
For development teams, the long-term cost of an AI coding assistant is a critical factor in the decision-making process.
| Cost Scenario | MiniMax-M2.5 Standard | MiniMax-M2.5 Lightning | Claude Opus 4.6 |
|---|---|---|---|
| Input Price / M tokens | $0.15 | $0.30 | $5.00 |
| Output Price / M tokens | $1.20 | $2.40 | $25.00 |
| Single SWE-Bench Task | ~$0.15 | ~$0.30 | ~$3.00 |
| Continuous Run (1 Hour) | $0.30 | $1.00 | ~$30+ |
| 24/7 Monthly Operation | ~$216 | ~$720 | ~$21,600+ |
| Tasks Completed with $100 Budget | ~328 tasks | ~164 tasks | ~30 tasks |
Let's take a medium-sized dev team as an example: if you're handling 50 coding tasks a day (bug fixes, code reviews, feature implementations), the monthly cost for MiniMax-M2.5 Standard is about $225, and the Lightning version is around $450. Meanwhile, Claude Opus 4.6 would set you back about $4,500. The quality of work across all three is nearly identical on the SWE-Bench scale.
🎯 Cost Advice: For most standard coding tasks, MiniMax-M2.5 offers a clear advantage in price-to-performance. We recommend testing it out on the APIYI (apiyi.com) platform. It lets you switch between models flexibly without changing your code architecture. Plus, you can get even better rates through their top-up promotions.
Quick Integration: MiniMax-M2.5 vs. Opus 4.6
Here's how you can quickly switch and compare both models using a unified interface:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Test MiniMax-M2.5
m25_response = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": "Implement a thread-safe LRU cache in Go"}]
)
# Test Claude Opus 4.6 - just swap the model parameter
opus_response = client.chat.completions.create(
model="claude-opus-4-6-20250205",
messages=[{"role": "user", "content": "Implement a thread-safe LRU cache in Go"}]
)
View Full Benchmark Code
from openai import OpenAI
import time
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model_name: str, prompt: str) -> dict:
"""
Test coding capabilities for a single model
Args:
model_name: Model ID
prompt: Coding task prompt
Returns:
Dictionary containing response content, tokens, and time elapsed
"""
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": "You are a senior software engineer"},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
elapsed = time.time() - start
return {
"model": model_name,
"content": response.choices[0].message.content,
"tokens": response.usage.completion_tokens,
"time": round(elapsed, 2)
}
# Coding task
task = "Refactor the following function to support thread safety, timeout control, and graceful degradation"
# Benchmark comparison
models = ["MiniMax-M2.5", "MiniMax-M2.5-Lightning", "claude-opus-4-6-20250205"]
for m in models:
result = benchmark_model(m, task)
print(f"[{result['model']}] {result['tokens']} tokens in {result['time']}s")
Pro Tip: With a single API Key from APIYI (apiyi.com), you can access both MiniMax-M2.5 and Claude Opus 4.6. This makes it easy to compare how they perform in your specific coding scenarios.
FAQ
Q1: Can MiniMax-M2.5 completely replace Claude Opus 4.6 for programming?
It's not a total replacement, but it works for most scenarios. The gap in SWE-Bench is only 0.6%, and M2.5 actually leads by 1% in Multi-SWE-Bench. For standard tasks like routine bug fixes, code reviews, and feature implementation, there's almost no difference between the two. However, for large-scale codebase analysis (requiring a 1M context window) or complex system-level debugging (Terminal-Bench), Opus 4.6 still holds an edge. We recommend a hybrid approach based on your specific needs.
Q2: Why is M2.5’s BFCL much higher than Opus 4.6, yet their coding scores are so close?
BFCL tests multi-turn tool calling (Function Calling) capabilities, while SWE-Bench tests end-to-end coding ability. Although Opus 4.6's single-turn tool calling isn't as precise as M2.5's, its powerful deep reasoning capabilities compensate for the lower tool-calling efficiency, resulting in similar overall coding quality. That said, in AI agent autonomous programming scenarios, M2.5's high BFCL score means fewer calling turns and significantly lower total costs.
Q3: How can I quickly compare the programming performance of these two models?
We recommend using APIYI (apiyi.com) for comparative testing:
- Sign up and get your API Key.
- Use the code examples from this article to call both models for the same coding task.
- Compare the generated code quality, response speed, and token consumption.
- With the unified OpenAI-compatible interface, switching models is as simple as changing the
modelparameter.
Summary
Here are the core conclusions when comparing MiniMax-M2.5's programming capabilities against Claude Opus 4.6:
- Coding quality is nearly on par: SWE-Bench 80.2% vs 80.8% (a tiny 0.6% gap); M2.5 actually takes the lead by 1% in Multi-SWE-Bench.
- M2.5 leads significantly in tool calling: BFCL 76.8% vs 63.3%, making M2.5 the go-to choice for AI agent programming scenarios.
- Massive cost difference: M2.5 costs about $0.15 per task compared to $3.00 for Opus. You can complete over 10x more tasks with the same budget.
- Opus 4.6 remains irreplaceable for deep tasks: It still holds the advantage in scenarios involving 1M context, Terminal-Bench, and MCP Atlas.
For most daily programming tasks, MiniMax-M2.5 offers coding quality close to Opus 4.6 but with far better cost-performance. We suggest verifying this in your own projects via APIYI (apiyi.com). The platform supports unified interface calls for both models, and you can take advantage of top-up promotions for extra savings.
📚 References
⚠️ Link Format Note: All external links use the
Resource Name: domain.comformat to make them easy to copy without clickable redirects, helping prevent SEO weight loss.
-
MiniMax M2.5 Official Announcement: Details on M2.5 core capabilities and coding benchmarks
- Link:
minimax.io/news/minimax-m25 - Description: Includes full data for SWE-Bench, Multi-SWE-Bench, BFCL, etc.
- Link:
-
Claude Opus 4.6 Official Release: Technical details of Opus 4.6 released by Anthropic
- Link:
anthropic.com/news/claude-opus-4-6 - Description: Explanations of Terminal-Bench, MCP Atlas, Adaptive Thinking, and more.
- Link:
-
OpenHands M2.5 Evaluation: Real-world coding evaluation of M2.5 by an independent developer platform
- Link:
openhands.dev/blog/minimax-m2-5-open-weights-models-catch-up-to-claude - Description: Practical analysis of the first open-weight model to surpass Claude Sonnet.
- Link:
-
VentureBeat Deep Comparison: Cost-performance analysis of M2.5 vs. Opus 4.6
- Link:
venturebeat.com/technology/minimaxs-new-open-m2-5-and-m2-5-lightning-near-state-of-the-art-while - Description: Analysis of cost-benefit differences from an enterprise perspective.
- Link:
-
Vellum Opus 4.6 Benchmark Analysis: Comprehensive breakdown of Claude Opus 4.6 benchmarks
- Link:
vellum.ai/blog/claude-opus-4-6-benchmarks - Description: Detailed analysis of core coding benchmarks like Terminal-Bench and SWE-Bench.
- Link:
Author: APIYI Team
Tech Talk: Feel free to share your model comparison results in the comments! For more AI programming model tutorials, visit the APIYI apiyi.com technical community.