Anmerkung des Autors: Tiefgehende Analyse der Coding-Fähigkeiten, Agent-Performance und API-Anbindung der beiden Versionen MiniMax-M2.5 und M2.5-Lightning. Mit einem SWE-Bench-Score von 80,2 % rückt das Modell extrem nah an Opus 4,6 heran – und das bei nur 1/60 der Kosten.
MiniMax hat am 12. Februar 2026 die beiden Modellversionen MiniMax-M2.5 und M2.5-Lightning veröffentlicht. Dies ist das erste Open-Source-Modell, das Claude Sonnet in puncto Coding-Fähigkeiten übertrifft: Bei SWE-Bench Verified erreicht es 80,2 % und liegt damit nur 0,6 Prozentpunkte hinter Claude Opus 4,6. Beide Modelle sind ab sofort auf der APIYI-Plattform verfügbar. Durch die Teilnahme an Auflade-Aktionen lässt sich ein Preisvorteil von 20 % gegenüber den offiziellen Preisen erzielen.
Kernvorteile: Durch die Praxisdaten und Code-Beispiele in diesem Artikel erfahren Sie die wesentlichen Unterschiede zwischen den beiden MiniMax-M2.5-Versionen, welches Modell für Ihr Szenario am besten geeignet ist und wie Sie die API-Anbindung schnell umsetzen.

MiniMax-M2.5 Kernfähigkeiten im Überblick
| Kernmetrik | MiniMax-M2.5 Standard | MiniMax-M2.5-Lightning | Bedeutung |
|---|---|---|---|
| SWE-Bench Verified | 80,2 % | 80,2 % (Gleiche Leistung) | Nahe an Opus 4,6 (80,8 %) |
| Ausgabegeschwindigkeit | ~50 TPS | ~100 TPS | Lightning ist 2x schneller |
| Preis (Ausgabe) | $0,15/$1,20 pro Mio. Token | $0,30/$2,40 pro Mio. Token | Standard-Version kostet nur 1/63 von Opus |
| BFCL Tool-Calling | 76,8 % | 76,8 % (Gleiche Leistung) | Deutlich vor Opus (63,3 %) |
| Kontextfenster | 205K Token | 205K Token | Unterstützt Analyse großer Codebasen |
MiniMax-M2.5 Coding-Fähigkeiten im Detail
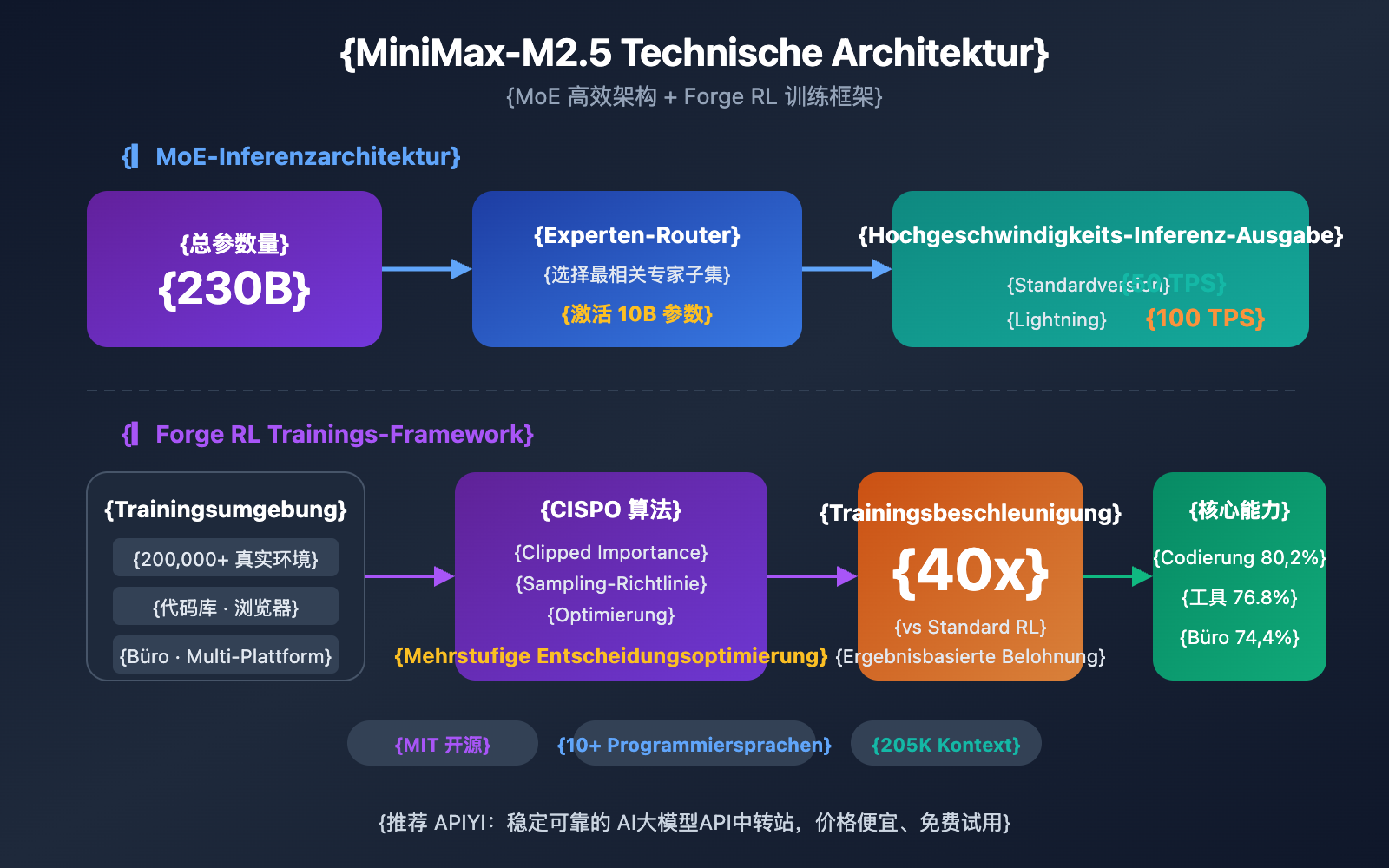
MiniMax-M2.5 basiert auf einer MoE-Architektur (Mixture of Experts) mit insgesamt 230 Mrd. Parametern, wobei für die Inferenz lediglich 10 Mrd. Parameter aktiviert werden. Dieses Design ermöglicht es dem Modell, Spitzenleistungen im Coding zu erbringen und gleichzeitig die Inferenzkosten massiv zu senken.
Bei Coding-Aufgaben zeigt M2.5 eine markante "Spec-writing tendency": Bevor es mit dem eigentlichen Programmieren beginnt, zerlegt es das Projekt in seine Architektur und erstellt einen Designplan. Dieses Verhaltensmuster führt dazu, dass es bei komplexen Projekten mit mehreren Dateien besonders glänzt – im Multi-SWE-Bench liegt es mit 51,3 % sogar vor Claude Opus 4,6 (50,3 %).
Das Modell unterstützt Full-Stack-Entwicklung in über 10 Programmiersprachen, darunter Python, Go, C/C++, TypeScript, Rust, Java, JavaScript, Kotlin, PHP und weitere. Zudem werden plattformübergreifende Projekte für Web, Android, iOS und Windows unterstützt.
MiniMax-M2.5 Agenten- und Tool-Calling-Fähigkeiten
Im BFCL Multi-Turn Benchmark erreicht M2.5 einen Score von 76,8 % und lässt damit Claude Opus 4,6 (63,3 %) sowie Gemini 3 Pro (61,0 %) weit hinter sich. Das bedeutet: In Agenten-Szenarien, die Multi-Turn-Dialoge und die Koordination mehrerer Tools erfordern, ist M2.5 derzeit die stärkste Wahl.
Im Vergleich zur Vorgängergeneration M2.1 benötigt M2.5 etwa 20 % weniger Tool-Aufrufe, um Agenten-Aufgaben zu lösen, während die Geschwindigkeit bei der SWE-Bench-Verified-Evaluierung um 37 % gestiegen ist. Die effizientere Aufgabenzerlegung reduziert direkt den Token-Verbrauch und damit die Betriebskosten.
MiniMax-M2.5 Standard vs. Lightning Version
Welche Version von MiniMax-M2.5 Sie wählen sollten, hängt von Ihrem spezifischen Einsatzszenario ab. Die Modellfähigkeiten beider Versionen sind identisch; die Hauptunterschiede liegen in der Inferenzgeschwindigkeit und der Preisgestaltung.
| Vergleichsdimension | M2.5 Standard | M2.5-Lightning | Empfehlung |
|---|---|---|---|
| API-Modell-ID | MiniMax-M2.5 |
MiniMax-M2.5-highspeed |
— |
| Inferenzgeschwindigkeit | ~50 TPS | ~100 TPS | Lightning für Echtzeit-Antworten |
| Eingabepreis | 0,15 $ / Mio. Tokens | 0,30 $ / Mio. Tokens | Standard für Batch-Aufgaben |
| Ausgabepreis | 1,20 $ / Mio. Tokens | 2,40 $ / Mio. Tokens | Standard ist 50 % günstiger |
| Laufende Kosten | ~0,30 $ / Stunde | ~1,00 $ / Stunde | Standard für Hintergrund-Tasks |
| Coding-Fähigkeiten | Identisch | Identisch | Kein Unterschied |
| Tool-Calling | Identisch | Identisch | Kein Unterschied |
Leitfaden zur Versionsauswahl für MiniMax-M2.5
Szenarien für die Lightning-Hochgeschwindigkeitsversion:
- Integration von IDE-Coding-Assistenten, die eine geringe Latenz für Echtzeit-Codevervollständigung und Refactoring-Vorschläge benötigen.
- Interaktive Agenten-Dialoge, bei denen Nutzer schnelle Antworten vom Kundenservice oder technischen Support erwarten.
- Echtzeit-Anwendungen zur Sucherweiterung, die schnelles Feedback bei der Web-Suche und Informationsabfrage erfordern.
Szenarien für die Standardversion:
- Batch-Code-Reviews und automatische Fehlerbehebungen im Hintergrund, die keine Echtzeit-Interaktion erfordern.
- Großflächige Orchestrierung von Agenten-Aufgaben und asynchrone Workflows mit langer Laufzeit.
- Budgetsensitive Anwendungen mit hohem Durchsatz, bei denen die niedrigsten Kosten pro Einheit im Vordergrund stehen.
🎯 Empfehlung: Wenn Sie unsicher sind, welche Version die richtige ist, empfehlen wir, beide Versionen parallel auf der Plattform APIYI (apiyi.com) zu testen. Da beide über dieselbe Schnittstelle laufen, müssen Sie lediglich den
model-Parameter anpassen, um Latenz und Ergebnisse direkt zu vergleichen.
MiniMax-M2.5 vs. Wettbewerber: Vergleich der Coding-Fähigkeiten
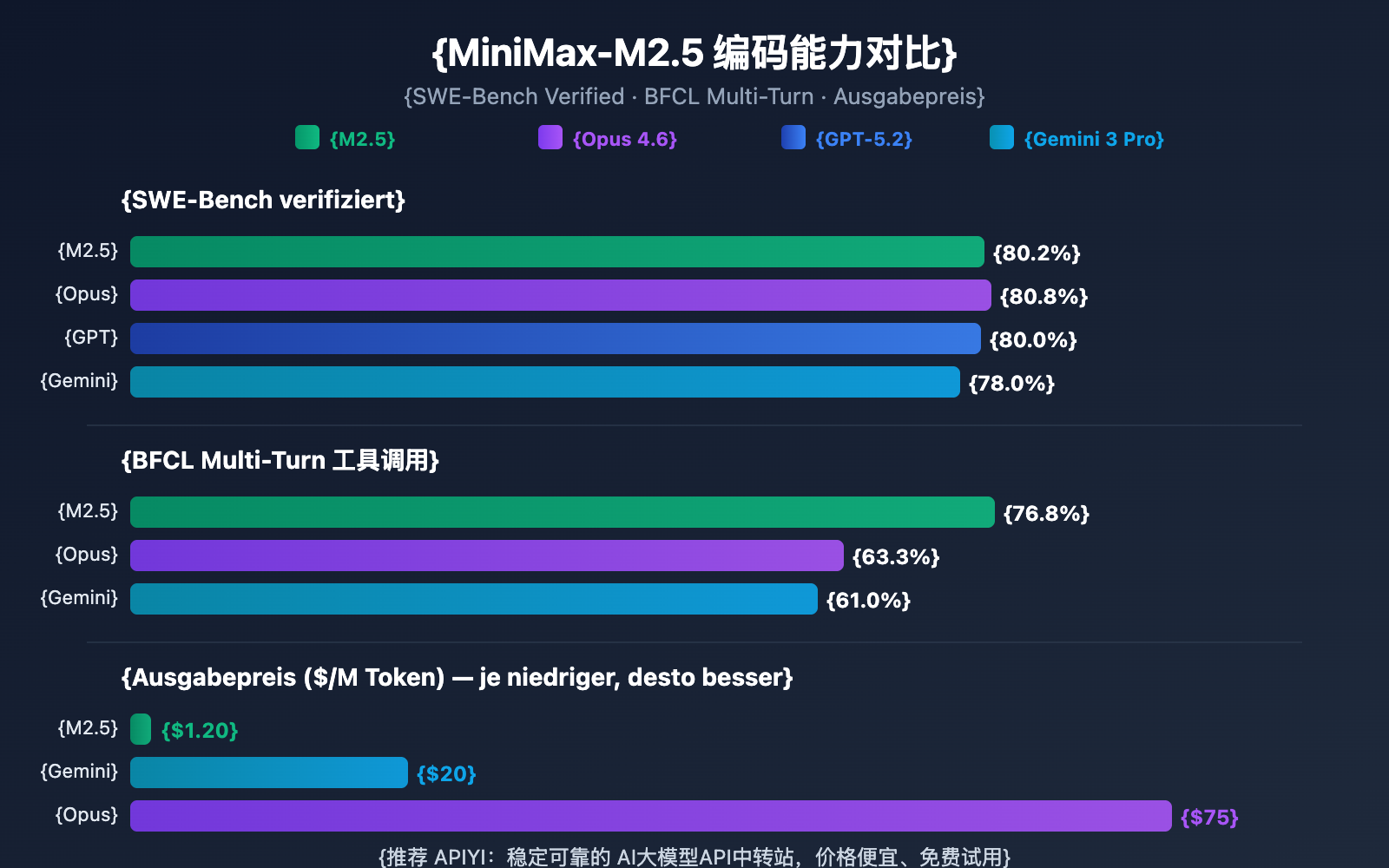
| Modell | SWE-Bench Verified | BFCL Multi-Turn | Ausgabepreis / Mio. | Aufgaben pro 100 $ |
|---|---|---|---|---|
| MiniMax-M2.5 | 80,2 % | 76,8 % | 1,20 $ | ~328 |
| MiniMax-M2.5-Lightning | 80,2 % | 76,8 % | 2,40 $ | ~164 |
| Claude Opus 4.6 | 80,8 % | 63,3 % | ~75 $ | ~30 |
| GPT-5.2 | 80,0 % | — | ~60 $ | ~30 |
| Gemini 3 Pro | 78,0 % | 61,0 % | ~20 $ | ~90 |
Den Daten zufolge hat MiniMax-M2.5 bei den Coding-Fähigkeiten bereits das State-of-the-Art-Niveau erreicht. Mit einem Score von 80,2 % im SWE-Bench Verified liegt MiniMax-M2.5 nur 0,6 % hinter Opus 4.6, während der Preisunterschied mehr als das 60-Fache beträgt. Bei den Tool-Calling-Fähigkeiten liegt M2.5 mit 76,8 % im BFCL-Benchmark sogar deutlich vor allen Wettbewerbern.
Für Teams, die Coding-Agenten in großem Maßstab einsetzen müssen, bedeutet der Kostenvorteil von M2.5, dass mit demselben Budget von 100 $ etwa 328 Aufgaben erledigt werden können, während mit Opus 4.6 lediglich etwa 30 Aufgaben möglich wären.
Hinweis zum Vergleich: Die oben genannten Benchmark-Daten stammen aus offiziellen Veröffentlichungen der jeweiligen Modellhersteller sowie von der unabhängigen Testorganisation Artificial Analysis. Die tatsächliche Leistung kann je nach spezifischem Einsatzszenario variieren. Wir empfehlen praktische Tests über APIYI (apiyi.com) durchzuführen.
MiniMax-M2.5 API Schnelleinstieg
Minimalbeispiel
Hier ist der einfachste Weg, MiniMax-M2.5 über die APIYI-Plattform einzubinden – in nur 10 Zeilen Code ist alles startklar:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="MiniMax-M2.5", # Wechseln Sie zu MiniMax-M2.5-Lightning für die Hochgeschwindigkeitsversion
messages=[{"role": "user", "content": "用 Python 实现一个 LRU 缓存"}]
)
print(response.choices[0].message.content)
Vollständigen Implementierungscode anzeigen (inkl. Streaming-Ausgabe und Tool-Calling)
from openai import OpenAI
from typing import Optional
def call_minimax_m25(
prompt: str,
model: str = "MiniMax-M2.5",
system_prompt: Optional[str] = None,
max_tokens: int = 4096,
stream: bool = False
) -> str:
"""
调用 MiniMax-M2.5 API
Args:
prompt: 用户输入
model: MiniMax-M2.5 或 MiniMax-M2.5-Lightning
system_prompt: 系统提示词
max_tokens: 最大输出 token 数
stream: 是否启用流式输出
Returns:
模型响应内容
"""
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=max_tokens,
stream=stream
)
if stream:
result = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
result += content
print(content, end="", flush=True)
print()
return result
else:
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 使用示例:编码任务
result = call_minimax_m25(
prompt="重构以下代码,提升性能并添加错误处理",
model="MiniMax-M2.5-Lightning",
system_prompt="你是一个资深全栈工程师,擅长代码重构和性能优化",
stream=True
)
Empfehlung: Holen Sie sich über APIYI (apiyi.com) kostenloses Testguthaben, um die Coding-Performance von MiniMax-M2.5 in Ihren realen Projekten schnell zu validieren. Die Plattform unterstützt OpenAI-kompatible Schnittstellen; bestehender Code kann durch einfaches Anpassen der Parameter
base_urlundmodelumgestellt werden.
Analyse der technischen Architektur von MiniMax-M2.5
Die Kernwettbewerbsfähigkeit von MiniMax-M2.5 basiert auf zwei technologischen Innovationen: der effizienten MoE-Architektur (Mixture of Experts) und dem Forge RL-Trainings-Framework.
Vorteile der MiniMax-M2.5 MoE-Architektur
| Architektur-Parameter | MiniMax-M2.5 | Herkömmliche Dense-Modelle | Vorteilserläuterung |
|---|---|---|---|
| Gesamtparameter | 230B | Meist 70B-200B | Größere Wissenskapazität |
| Aktive Parameter | 10B | Entspricht Gesamtparametern | Extrem niedrige Inferenzkosten |
| Inferenzeffizienz | 50-100 TPS | 10-30 TPS | 3- bis 10-fache Geschwindigkeitssteigerung |
| Stückkosten | $1.20/M Output | $20-$75/M Output | Kostenreduktion um das 20- bis 60-fache |
Die Grundidee der MoE-Architektur ist die "Arbeitsteilung unter Experten" – das Modell enthält mehrere Gruppen von Expertennetzwerken, wobei bei jeder Inferenz nur die Teilmenge der Experten aktiviert wird, die für die aktuelle Aufgabe am relevantesten ist. M2.5 erreicht mit nur 10B aktiven Parametern eine Leistung, die an 230B Dense-Modelle heranreicht. Dies macht es zur derzeit kompaktesten und kostengünstigsten Option unter den Tier-1-Modellen.
MiniMax-M2.5 Forge RL Trainings-Framework
Eine weitere Schlüsseltechnologie von M2.5 ist das Forge Reinforcement Learning Framework:
- Skalierung der Trainingsumgebung: Über 200.000 reale Trainingsumgebungen, die Code-Repositories, Webbrowser und Büroanwendungen abdecken.
- Trainingsalgorithmus: CISPO (Clipped Importance Sampling Policy Optimization), speziell für Aufgaben mit mehrstufiger Entscheidungsfindung entwickelt.
- Trainingseffizienz: Erreicht eine 40-fache Beschleunigung des Trainings im Vergleich zu Standard-RL-Methoden.
- Belohnungsmechanismus: Ein ergebnisbasiertes Belohnungssystem anstelle des traditionellen Feedbacks auf Basis menschlicher Präferenzen (RLHF).
Diese Trainingsmethode sorgt dafür, dass M2.5 bei realen Coding-Aufgaben und Agent-Szenarien robuster agiert und Aufgaben effizient zerlegen, Werkzeuge auswählen und mehrstufig ausführen kann.
🎯 Praxistipp: MiniMax-M2.5 ist bereits auf der APIYI-Plattform (apiyi.com) verfügbar. Wir empfehlen Entwicklern, zunächst das Gratis-Guthaben zu nutzen, um Coding- und Agent-Szenarien zu testen und je nach Latenzanforderungen und gewünschtem Ergebnis zwischen der Standard- oder der Lightning-Version zu wählen.
Häufig gestellte Fragen
Q1: Gibt es Leistungsunterschiede zwischen der MiniMax-M2.5 Standard- und der Lightning-Version?
Es gibt keine Unterschiede in den Fähigkeiten. Die Modellkapazitäten beider Versionen sind völlig identisch; alle Benchmark-Ergebnisse wie SWE-Bench und BFCL sind gleich. Der einzige Unterschied liegt in der Inferenzgeschwindigkeit (Standard-Version 50 TPS vs. Lightning 100 TPS) und der entsprechenden Preisgestaltung. Bei der Auswahl sollten Sie lediglich Ihre Anforderungen an die Latenz und Ihr Budget berücksichtigen.
Q2: Eignet sich MiniMax-M2.5 als Ersatz für Claude Opus 4.6?
In Coding- und Agent-Szenarien ist dies durchaus eine Überlegung wert. Der SWE-Bench-Score von M2.5 (80,2 %) liegt nur 0,6 Prozentpunkte hinter Opus 4.6, während die Tool-Calling-Fähigkeiten (BFCL 76,8 %) deutlich führen. Preislich gesehen kostet die Standard-Version von M2.5 nur etwa 1/63 von Opus. Wir empfehlen, Vergleichstests in realen Projekten über APIYI (apiyi.com) durchzuführen, um die Eignung für Ihr spezifisches Szenario zu beurteilen.
Q3: Wie kann ich schnell mit dem Testen von MiniMax-M2.5 beginnen?
Wir empfehlen den schnellen Zugriff über die APIYI-Plattform:
- Besuchen Sie APIYI (apiyi.com) und registrieren Sie ein Konto.
- Erhalten Sie Ihren API-Key und ein kostenloses Testguthaben.
- Verwenden Sie die Code-Beispiele aus diesem Artikel und ändern Sie den Parameter
modelaufMiniMax-M2.5oderMiniMax-M2.5-Lightning. - Dank der OpenAI-kompatiblen Schnittstelle müssen Sie in bestehenden Projekten lediglich die
base_urlanpassen.
Zusammenfassung
Die Kernpunkte von MiniMax-M2.5:
- Spitzenreiter bei der Coding-Leistung: Mit 80,2 % im SWE-Bench Verified und 51,3 % im Multi-SWE-Bench ist es branchenführend und das erste Open-Source-Modell, das Claude Sonnet übertrifft.
- Führend in Agent-Fähigkeiten: BFCL Multi-Turn erreicht 76,8 % und liegt damit weit vor allen Wettbewerbern; die Anzahl der Tool-Calling-Runden wurde im Vergleich zur Vorgängergeneration um 20 % reduziert.
- Maximale Kosteneffizienz: Mit nur 1,20 $/M Tokens für den Output in der Standard-Version kostet es nur 1/63 von Opus 4.6. Mit dem gleichen Budget können mehr als 10-mal so viele Aufgaben erledigt werden.
- Flexible Auswahl zwischen zwei Versionen: Die Standard-Version eignet sich für Batch-Verarbeitung und kostenoptimierte Szenarien, während Lightning ideal für Echtzeit-Interaktionen und Szenarien mit geringer Latenz ist.
MiniMax-M2.5 ist bereits auf der APIYI-Plattform verfügbar und unterstützt Aufrufe über OpenAI-kompatible Schnittstellen. Wir empfehlen, sich über APIYI (apiyi.com) ein kostenloses Guthaben für Praxistests zu sichern – Sie können einfach durch Ändern des Modellparameters zwischen den beiden Versionen wechseln und vergleichen.
📚 Referenzen
⚠️ Hinweis zum Linkformat: Alle externen Links verwenden das Format
Name: domain.com. Dies erleichtert das Kopieren, verhindert jedoch die direkte Verlinkung, um den SEO-Wert (Link Juice) zu erhalten.
-
Offizielle Ankündigung von MiniMax M2.5: Detaillierte Vorstellung der Kernfunktionen und technischen Details von M2.5
- Link:
minimax.io/news/minimax-m25 - Beschreibung: Offizielles Veröffentlichungsdokument mit vollständigen Benchmark-Daten und einer Einführung in die Trainingsmethoden.
- Link:
-
MiniMax API-Dokumentation: Offizieller Leitfaden zur API-Integration und Modellspezifikationen
- Link:
platform.minimax.io/docs/guides/text-generation - Beschreibung: Enthält technische Spezifikationen wie Modell-IDs, Kontextfenster und Beispiele für API-Aufrufe.
- Link:
-
Artificial Analysis Bewertung: Unabhängige Modellbewertung und Leistungsanalyse von Drittanbietern
- Link:
artificialanalysis.ai/models/minimax-m2-5 - Beschreibung: Bietet standardisierte Benchmark-Rankings, Geschwindigkeitsmessungen und Preisvergleiche.
- Link:
-
MiniMax HuggingFace: Download von Open-Source-Modellgewichten
- Link:
huggingface.co/MiniMaxAI - Beschreibung: Open Source unter der MIT-Lizenz, unterstützt die private Bereitstellung via vLLM/SGLang.
- Link:
Autor: Technik-Team
Technischer Austausch: Diskutieren Sie gerne Ihre Erfahrungen mit MiniMax-M2.5 im Kommentarbereich. Weitere Tutorials zur API-Integration von KI-Modellen finden Sie in der APIYI apiyi.com Technik-Community.