Nota do autor: Uma análise profunda das capacidades de codificação, desempenho de agentes e métodos de acesso à API das versões MiniMax-M2.5 e M2.5-Lightning. Com 80,2% no SWE-Bench, ele se aproxima dos 80,8% do Opus, custando apenas 1/60 do preço.
A MiniMax lançou em 12 de fevereiro de 2026 as versões de modelo MiniMax-M2.5 e M2.5-Lightning. Este é o primeiro modelo entre os modelos disponíveis que supera o Claude Sonnet em capacidade de codificação, atingindo 80,2% no SWE-Bench Verified, apenas 0,6 pontos percentuais abaixo do Claude Opus (80,8%). Atualmente, ambos os modelos já estão disponíveis na plataforma APIYI. Sinta-se à vontade para começar a usá-los; em termos de preço, ao participar das campanhas de recarga, é possível obter um valor 20% menor que no site oficial.
Valor Central: Através dos dados de testes reais e exemplos de código deste artigo, você entenderá as principais diferenças entre as duas versões do MiniMax-M2.5, escolherá a que melhor se adapta ao seu cenário e aprenderá como fazer a integração rápida via API.

Visão Geral das Capacidades do MiniMax-M2.5
| Indicador Principal | MiniMax-M2.5 Padrão | MiniMax-M2.5-Lightning | Descrição de Valor |
|---|---|---|---|
| SWE-Bench Verified | 80,2% | 80,2% (Mesma capacidade) | Próximo aos 80,8% do Opus |
| Velocidade de Saída | ~50 TPS | ~100 TPS | Lightning é 2x mais rápido |
| Preço de Saída | $0.15/$1.20 por milhão de Tokens | $0.30/$2.40 por milhão de Tokens | Versão padrão custa apenas 1/63 do Opus |
| Chamada de Ferramenta BFCL | 76,8% | 76,8% (Mesma capacidade) | Supera significativamente os 63,3% do Opus |
| Janela de Contexto | 205K tokens | 205K tokens | Suporta análise de grandes bases de código |
Detalhes da Capacidade de Codificação do MiniMax-M2.5
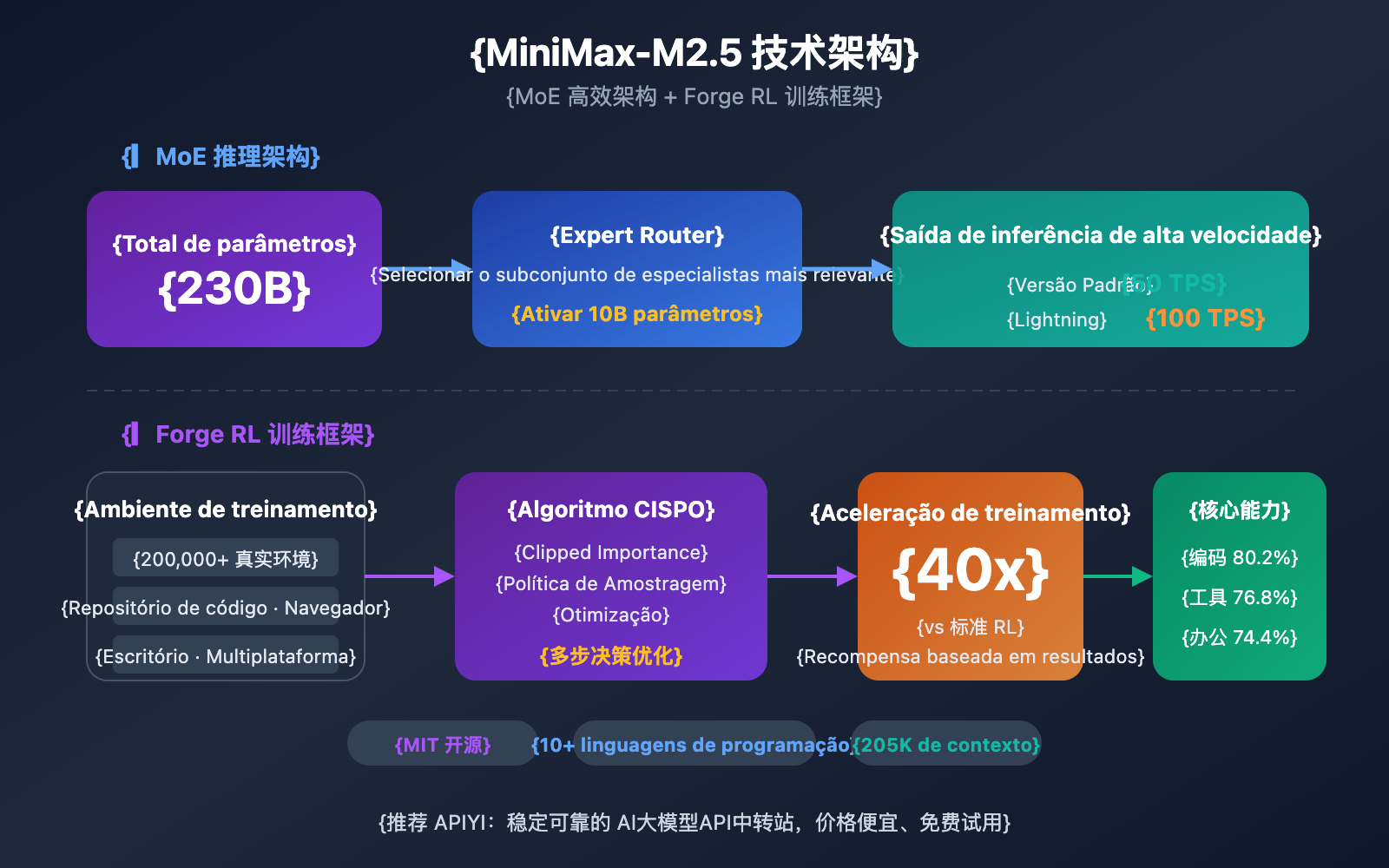
O MiniMax-M2.5 utiliza uma arquitetura MoE (Mixture of Experts), com um total de 230B de parâmetros, mas ativa apenas 10B para a inferência. Esse design permite que o modelo mantenha uma capacidade de codificação de ponta, enquanto reduz drasticamente os custos de inferência.
Em tarefas de codificação, o M2.5 demonstra uma "Spec-writing tendency" (tendência de escrita de especificações) única — antes de começar a escrever o código, ele realiza a decomposição da arquitetura e o planejamento do design do projeto. Esse padrão de comportamento o torna excepcionalmente bom ao lidar com projetos complexos de múltiplos arquivos, com uma pontuação de 51,3% no Multi-SWE-Bench, superando até os 50,3% do Claude Opus.
O modelo suporta desenvolvimento full-stack em mais de 10 linguagens de programação, abrangendo linguagens populares como Python, Go, C/C++, TypeScript, Rust, Java, JavaScript, Kotlin, PHP, entre outras, além de suportar projetos multiplataforma como Web, Android, iOS e Windows.
Capacidades de Agente e Chamada de Ferramentas do MiniMax-M2.5
O M2.5 obteve uma pontuação de 76,8% no benchmark BFCL Multi-Turn, superando amplamente os 63,3% do Claude Opus e os 61,0% do Gemini 1.5 Pro. Isso significa que, em cenários de agentes que exigem diálogos de múltiplos turnos e colaboração entre várias ferramentas, o M2.5 é atualmente a escolha mais forte.
Comparado à geração anterior M2.1, o M2.5 reduziu as rodadas de chamadas de ferramentas para completar tarefas de agentes em cerca de 20%, e a velocidade de avaliação no SWE-Bench Verified aumentou 37%. Uma capacidade de decomposição de tarefas mais eficiente reduz diretamente o consumo de tokens e os custos de chamada.
MiniMax-M2.5: Comparação entre as versões Standard e Lightning
A escolha de qual versão do MiniMax-M2.5 usar depende do seu cenário específico. As capacidades de ambos os modelos são idênticas; a diferença principal reside na velocidade de inferência e no preço.
| Dimensão de Comparação | M2.5 Standard | M2.5-Lightning | Sugestão de Escolha |
|---|---|---|---|
| ID do Modelo na API | MiniMax-M2.5 |
MiniMax-M2.5-highspeed |
— |
| Velocidade de Inferência | ~50 TPS | ~100 TPS | Escolha Lightning para respostas em tempo real |
| Preço de Entrada (Input) | $0.15/M tokens | $0.30/M tokens | Escolha Standard para tarefas em lote |
| Preço de Saída (Output) | $1.20/M tokens | $2.40/M tokens | Standard é 50% mais barato |
| Custo de Operação Contínua | ~$0.30/hora | ~$1.00/hora | Escolha Standard para tarefas de background |
| Capacidade de Codificação | Exatamente igual | Exatamente igual | Sem diferença entre os dois |
| Chamada de Ferramentas | Exatamente igual | Exatamente igual | Sem diferença entre os dois |
Guia de Cenários para Escolha da Versão MiniMax-M2.5
Quando escolher a versão Lightning (Alta Velocidade):
- Integração com assistentes de codificação em IDEs, que exigem baixa latência para completamento de código e sugestões de refatoração em tempo real.
- Diálogos com agentes inteligentes interativos, onde o usuário espera uma resposta rápida do suporte técnico ou atendimento ao cliente.
- Aplicações de busca aprimorada em tempo real, que necessitam de feedback rápido na navegação web e recuperação de informações.
Quando escolher a versão Standard:
- Revisão de código em lote e correções automáticas em segundo plano, onde a interação em tempo real não é necessária.
- Orquestração de tarefas complexas de agentes em larga escala e fluxos de trabalho assíncronos de longa duração.
- Aplicações de alto rendimento com orçamento sensível, onde se busca o menor custo por unidade.
🎯 Dica de Especialista: Se você não tem certeza de qual versão escolher, recomendamos testar ambas simultaneamente na plataforma APIYI (apiyi.com). Como as versões Standard e Lightning operam sob a mesma interface, basta alterar o parâmetro
modelpara comparar rapidamente a latência e os resultados.
MiniMax-M2.5 vs. Concorrentes: Capacidade de Codificação

| Modelo | SWE-Bench Verified | BFCL Multi-Turn | Preço de Saída/M | Tarefas por $100 |
|---|---|---|---|---|
| MiniMax-M2.5 | 80.2% | 76.8% | $1.20 | ~328 |
| MiniMax-M2.5-Lightning | 80.2% | 76.8% | $2.40 | ~164 |
| Claude Opus 4.6 | 80.8% | 63.3% | ~$75 | ~30 |
| GPT-5.2 | 80.0% | — | ~$60 | ~30 |
| Gemini 3 Pro | 78.0% | 61.0% | ~$20 | ~90 |
Olhando para os dados, o MiniMax-M2.5 atingiu um nível de excelência em codificação. A pontuação de 80.2% no SWE-Bench Verified é apenas 0.6% inferior ao Opus 4.6, mas a diferença de preço é de mais de 60 vezes. Na capacidade de chamada de ferramentas (Tool Calling), o BFCL de 76.8% do M2.5 lidera com folga sobre todos os concorrentes.
Para equipes que precisam implantar agentes de codificação em larga escala, a vantagem de custo do M2.5 significa que o mesmo orçamento de $100 pode completar cerca de 328 tarefas, enquanto o Opus 4.6 completaria apenas cerca de 30.
Nota sobre a comparação: Os dados de benchmark acima são baseados em informações oficiais dos modelos e da agência de avaliação de terceiros Artificial Analysis. O desempenho real pode variar conforme o cenário da tarefa; recomendamos realizar testes em cenários reais através do APIYI (apiyi.com).
Acesso Rápido à API do MiniMax-M2.5
Exemplo Minimalista
Aqui está a forma mais simples de acessar o MiniMax-M2.5 através da plataforma APIYI, com apenas 10 linhas de código:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="MiniMax-M2.5", # Alterne para MiniMax-M2.5-Lightning para usar a versão de alta velocidade
messages=[{"role": "user", "content": "用 Python 实现一个 LRU 缓存"}]
)
print(response.choices[0].message.content)
Ver código de implementação completo (incluindo saída em streaming e chamadas de ferramentas)
from openai import OpenAI
from typing import Optional
def call_minimax_m25(
prompt: str,
model: str = "MiniMax-M2.5",
system_prompt: Optional[str] = None,
max_tokens: int = 4096,
stream: bool = False
) -> str:
"""
调用 MiniMax-M2.5 API
Args:
prompt: 用户输入
model: MiniMax-M2.5 或 MiniMax-M2.5-Lightning
system_prompt: 系统提示词
max_tokens: 最大输出 token 数
stream: 是否启用流式输出
Returns:
模型响应内容
"""
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=max_tokens,
stream=stream
)
if stream:
result = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
result += content
print(content, end="", flush=True)
print()
return result
else:
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 使用示例:编码任务
result = call_minimax_m25(
prompt="重构以下代码,提升性能并添加错误处理",
model="MiniMax-M2.5-Lightning",
system_prompt="你是一个资深全栈工程师,擅长代码重构和性能优化",
stream=True
)
Dica: Obtenha créditos de teste gratuitos através da APIYI (apiyi.com) para validar rapidamente o desempenho de codificação do MiniMax-M2.5 em seus projetos reais. A plataforma suporta a interface compatível com OpenAI; basta alterar os parâmetros
base_urlemodelno seu código atual para fazer a troca.
Análise da Arquitetura Técnica do MiniMax-M2.5
A competitividade central do MiniMax-M2.5 vem de duas inovações técnicas: a arquitetura eficiente MoE e o framework de treinamento Forge RL.
Vantagens da Arquitetura MoE do MiniMax-M2.5
| Parâmetro de Arquitetura | MiniMax-M2.5 | Modelo Denso Tradicional | Descrição da Vantagem |
|---|---|---|---|
| Total de Parâmetros | 230B | Geralmente 70B-200B | Maior capacidade de conhecimento |
| Parâmetros Ativados | 10B | Igual ao total de parâmetros | Custo de inferência extremamente baixo |
| Eficiência de Inferência | 50-100 TPS | 10-30 TPS | Velocidade 3 a 10 vezes maior |
| Custo Unitário | $1.20/M saída | $20-$75/M saída | Redução de custo de 20 a 60 vezes |
A ideia central da arquitetura MoE é a "divisão de tarefas entre especialistas" — o modelo contém vários grupos de redes especialistas, e cada inferência ativa apenas o subconjunto de especialistas mais relevante para a tarefa atual. O M2.5 alcança resultados próximos aos de um modelo denso de 230B com apenas 10B de parâmetros ativados, tornando-o uma das opções de menor tamanho e custo entre os modelos Tier 1 atuais.
Framework de Treinamento Forge RL do MiniMax-M2.5
Outra tecnologia chave do M2.5 é o framework de aprendizado por reforço Forge:
- Escala do ambiente de treinamento: Mais de 200 mil ambientes de treinamento do mundo real, abrangendo repositórios de código, navegadores web e aplicativos de escritório.
- Algoritmo de treinamento: CISPO (Clipped Importance Sampling Policy Optimization), projetado especificamente para tarefas de decisão em várias etapas.
- Eficiência de treinamento: Aceleração de treinamento de 40 vezes em comparação com métodos RL padrão.
- Mecanismo de recompensa: Sistema de recompensa baseado em resultados, em vez do tradicional feedback de preferência humana (RLHF).
Essa abordagem de treinamento torna o M2.5 mais robusto em tarefas reais de codificação e agentes (agents), sendo capaz de realizar decomposição de tarefas, seleção de ferramentas e execução de múltiplas etapas de forma eficiente.
🎯 Dica Prática: O MiniMax-M2.5 já está disponível na plataforma APIYI (apiyi.com). Recomendamos que os desenvolvedores usem os créditos gratuitos primeiro para testar cenários de codificação e agentes, escolhendo entre a versão padrão ou a Lightning com base na latência e nos resultados reais.
Perguntas Frequentes
Q1: Existe diferença de capacidade entre as versões MiniMax-M2.5 Standard e Lightning?
Não há diferença. As capacidades do modelo em ambas as versões são idênticas, com as mesmas pontuações em todos os benchmarks, como SWE-Bench e BFCL. A única diferença é a velocidade de inferência (Standard 50 TPS vs Lightning 100 TPS) e o preço correspondente. Ao escolher, considere apenas a sua necessidade de latência e o seu orçamento.
Q2: O MiniMax-M2.5 é um bom substituto para o Claude Opus 4.6?
Pode ser considerado em cenários de codificação e agentes. A pontuação do M2.5 no SWE-Bench (80,2%) é apenas 0,6 pontos percentuais inferior à do Opus 4.6, enquanto a capacidade de chamada de ferramentas (BFCL 76,8%) lidera com folga. Em termos de preço, a versão Standard do M2.5 custa apenas 1/63 do Opus. Recomendamos realizar testes comparativos em projetos reais via APIYI (apiyi.com) para avaliar de acordo com seu cenário específico.
Q3: Como posso começar a testar o MiniMax-M2.5 rapidamente?
Recomendamos usar a plataforma APIYI para um acesso rápido:
- Acesse APIYI em apiyi.com e registre uma conta.
- Obtenha sua API Key e créditos de teste gratuitos.
- Use os exemplos de código deste artigo, alterando o parâmetro
modelparaMiniMax-M2.5ouMiniMax-M2.5-Lightning. - A interface é compatível com OpenAI; em projetos existentes, basta alterar a
base_url.
Resumo
Pontos principais do MiniMax-M2.5:
- Capacidade de codificação de ponta: SWE-Bench Verified 80,2%, Multi-SWE-Bench 51,3% (líder na indústria), sendo o primeiro modelo de código aberto a superar o Claude Sonnet.
- Líder em capacidades de Agentes: BFCL Multi-Turn 76,8%, superando significativamente todos os concorrentes; o número de turnos para chamadas de ferramentas foi reduzido em 20% em comparação com a geração anterior.
- Custo-benefício extremo: O custo de saída da versão Standard é de apenas $1,20/M tokens, o que representa 1/63 do Opus 4.6. Com o mesmo orçamento, é possível realizar mais de 10 vezes mais tarefas.
- Escolha flexível entre duas versões: A versão Standard é ideal para processamento em lote e cenários onde o custo é prioridade, enquanto a Lightning é voltada para interações em tempo real e baixa latência.
O MiniMax-M2.5 já está disponível na plataforma APIYI, com suporte para chamadas via interface compatível com OpenAI. Recomendamos utilizar a APIYI (apiyi.com) para obter créditos gratuitos e realizar seus testes, bastando alterar o parâmetro model para alternar e comparar as duas versões.
📚 Referências
⚠️ Nota sobre o formato dos links: Todos os links externos utilizam o formato
Nome do Recurso: domain.compara facilitar a cópia, mas não são clicáveis para evitar a perda de autoridade de SEO.
-
Anúncio Oficial do MiniMax M2.5: Detalhes sobre as capacidades principais e especificações técnicas do M2.5
- Link:
minimax.io/news/minimax-m25 - Descrição: Documentação oficial de lançamento, incluindo dados completos de benchmarks e introdução aos métodos de treinamento.
- Link:
-
Documentação da API MiniMax: Guia oficial de integração da API e especificações do modelo
- Link:
platform.minimax.io/docs/guides/text-generation - Descrição: Contém IDs do modelo, janela de contexto, exemplos de chamadas de API e outras especificações técnicas.
- Link:
-
Avaliação da Artificial Analysis: Avaliação independente de terceiros e análise de desempenho do modelo
- Link:
artificialanalysis.ai/models/minimax-m2-5 - Descrição: Fornece rankings de benchmarks padronizados, testes de velocidade real e comparação de preços.
- Link:
-
MiniMax no HuggingFace: Download de pesos de modelos de código aberto
- Link:
huggingface.co/MiniMaxAI - Descrição: Código aberto sob a licença MIT, suporta implantação privada via vLLM/SGLang.
- Link:
Autor: Equipe Técnica
Troca de Conhecimento: Sinta-se à vontade para discutir sua experiência com o MiniMax-M2.5 na seção de comentários. Para mais tutoriais de integração de APIs de Modelos de Linguagem Grande, visite a comunidade técnica APIYI em apiyi.com.