作者注:深度解析 MiniMax-M2.5 和 M2.5-Lightning 两个版本的编码能力、智能体表现和 API 接入方法,SWE-Bench 80.2% 接近 Opus 4.6,价格仅为 1/60
MiniMax 在 2026 年 2 月 12 日发布了 MiniMax-M2.5 和 M2.5-Lightning 两个模型版本。这是目前开源模型中首个在编码能力上超越 Claude Sonnet 的模型,SWE-Bench Verified 达到 80.2%,仅比 Claude Opus 4.6 低 0.6 个百分点。目前该两个模型已上线 APIYI 平台,欢迎接入使用,价格方面通过参与充值活动,可做到官网 8 折。
核心价值: 通过本文的实测数据和代码示例,你将了解 MiniMax-M2.5 两个版本的核心差异,选择最适合你场景的版本,并快速完成 API 接入。

MiniMax-M2.5 核心能力概览
| 核心指标 | MiniMax-M2.5 标准版 | MiniMax-M2.5-Lightning | 价值说明 |
|---|---|---|---|
| SWE-Bench Verified | 80.2% | 80.2%(能力相同) | 接近 Opus 4.6 的 80.8% |
| 输出速度 | ~50 TPS | ~100 TPS | Lightning 快 2 倍 |
| 输出价格 | $0.15/$1.20 每百万 Token | $0.30/$2.40 每百万 Token | 标准版仅为 Opus 的 1/63 |
| BFCL 工具调用 | 76.8% | 76.8%(能力相同) | 大幅领先 Opus 的 63.3% |
| 上下文窗口 | 205K tokens | 205K tokens | 支持大型代码库分析 |
MiniMax-M2.5 编码能力详解
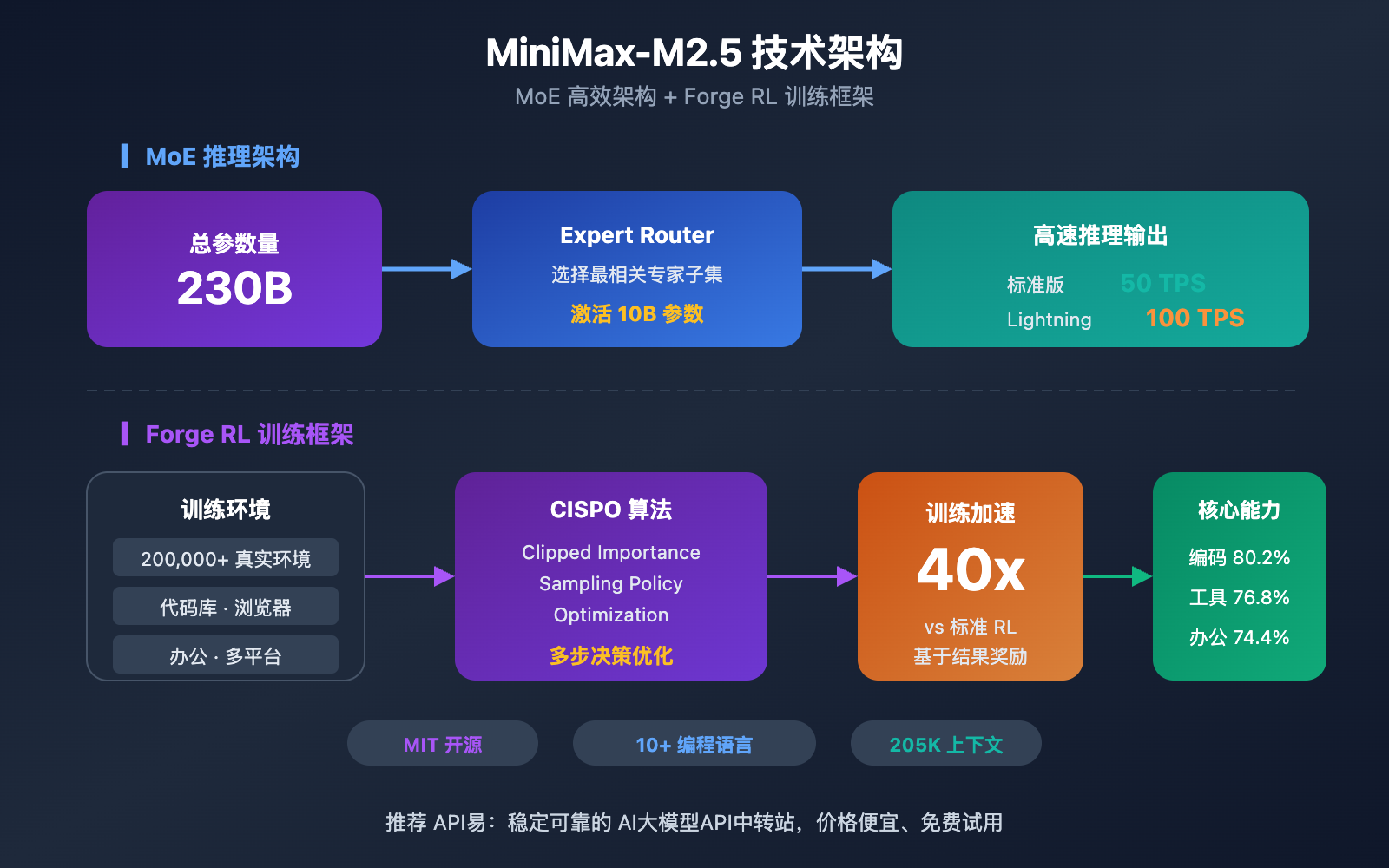
MiniMax-M2.5 采用 MoE(Mixture of Experts)架构,总参数量 230B,但仅激活 10B 参数进行推理。这种设计使得模型在保持前沿编码能力的同时,大幅降低了推理成本。
在编码任务中,M2.5 展现出一种独特的 "Spec-writing tendency"——在动手写代码之前,先对项目进行架构分解和设计规划。这种行为模式使它在处理复杂多文件项目时表现尤为出色,Multi-SWE-Bench 得分 51.3% 甚至领先 Claude Opus 4.6 的 50.3%。
模型支持 10+ 编程语言的全栈开发,覆盖 Python、Go、C/C++、TypeScript、Rust、Java、JavaScript、Kotlin、PHP 等主流语言,同时支持 Web、Android、iOS、Windows 等多平台项目。
MiniMax-M2.5 智能体与工具调用能力
M2.5 在 BFCL Multi-Turn 基准测试中得分 76.8%,大幅领先 Claude Opus 4.6 的 63.3% 和 Gemini 3 Pro 的 61.0%。这意味着在需要多轮对话、多工具协作的智能体场景中,M2.5 是目前最强的选择。
相比前代 M2.1,M2.5 完成智能体任务的工具调用轮次减少了约 20%,SWE-Bench Verified 评估速度提升了 37%。更高效的任务分解能力直接降低了 Token 消耗和调用成本。
MiniMax-M2.5 标准版与 Lightning 版本对比
选择 MiniMax-M2.5 的哪个版本,取决于你的具体使用场景。两个版本的模型能力完全一致,核心差异在于推理速度和定价。
| 对比维度 | M2.5 标准版 | M2.5-Lightning | 选择建议 |
|---|---|---|---|
| API 模型 ID | MiniMax-M2.5 |
MiniMax-M2.5-highspeed |
— |
| 推理速度 | ~50 TPS | ~100 TPS | 需要实时响应选 Lightning |
| 输入价格 | $0.15/M tokens | $0.30/M tokens | 批量任务选标准版 |
| 输出价格 | $1.20/M tokens | $2.40/M tokens | 标准版便宜一半 |
| 持续运行成本 | ~$0.30/小时 | ~$1.00/小时 | 后台任务选标准版 |
| 编码能力 | 完全相同 | 完全相同 | 两者无差异 |
| 工具调用 | 完全相同 | 完全相同 | 两者无差异 |
MiniMax-M2.5 版本选择场景指南
选择 Lightning 高速版的场景:
- IDE 编码助手集成,需要低延迟的实时代码补全和重构建议
- 交互式智能体对话,用户期望快速响应的客服或技术支持
- 实时搜索增强应用,需要快速反馈的网页浏览和信息检索
选择标准版的场景:
- 后台批量代码审查和自动修复,不需要实时交互
- 大规模智能体任务编排,长时间运行的异步工作流
- 预算敏感的高吞吐量应用,追求最低单位成本
🎯 选择建议:如果你不确定选哪个版本,建议先在 API易 apiyi.com 平台上同时测试两个版本。标准版和 Lightning 版本在同一接口下切换,只需修改 model 参数即可快速对比延迟和效果。
MiniMax-M2.5 与竞品编码能力对比
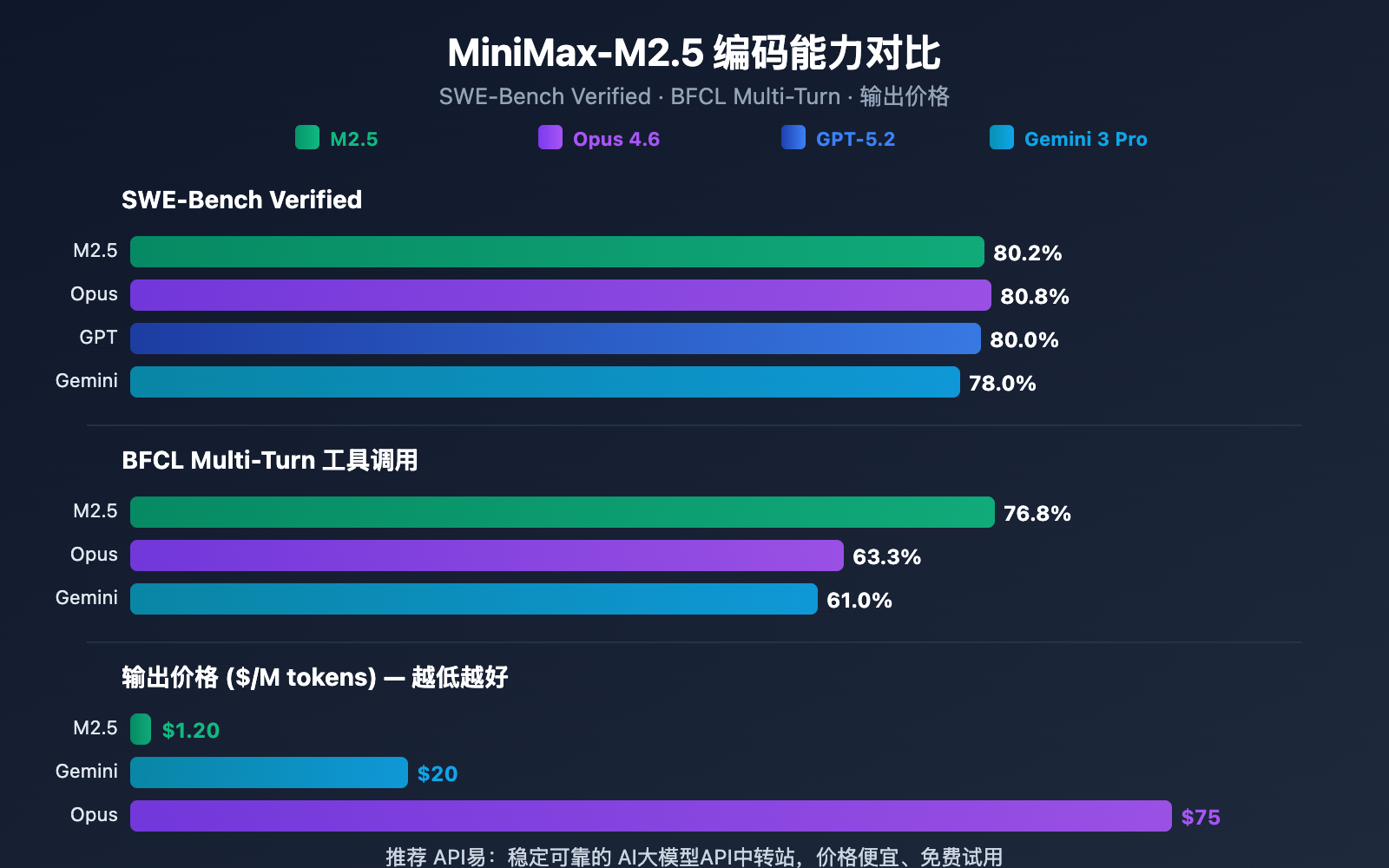
| 模型 | SWE-Bench Verified | BFCL Multi-Turn | 输出价格/M | 每 $100 可完成任务数 |
|---|---|---|---|---|
| MiniMax-M2.5 | 80.2% | 76.8% | $1.20 | ~328 |
| MiniMax-M2.5-Lightning | 80.2% | 76.8% | $2.40 | ~164 |
| Claude Opus 4.6 | 80.8% | 63.3% | ~$75 | ~30 |
| GPT-5.2 | 80.0% | — | ~$60 | ~30 |
| Gemini 3 Pro | 78.0% | 61.0% | ~$20 | ~90 |
从数据来看,MiniMax-M2.5 在编码能力上已经达到前沿水平。SWE-Bench Verified 80.2% 的得分仅比 Opus 4.6 低 0.6%,但价格差距高达 60 倍以上。在工具调用能力上,M2.5 的 BFCL 76.8% 更是大幅领先所有竞品。
对于需要大规模部署编码智能体的团队,M2.5 的成本优势意味着同样 $100 的预算可以完成约 328 个任务,而使用 Opus 4.6 仅能完成约 30 个。
对比说明: 以上基准测试数据来源于各模型官方公布数据和第三方评测机构 Artificial Analysis。实际表现可能因具体任务场景有所不同,建议通过 API易 apiyi.com 进行实际场景测试验证。
MiniMax-M2.5 API 快速接入
极简示例
以下是通过 API易平台接入 MiniMax-M2.5 的最简方式,10 行代码即可运行:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="MiniMax-M2.5", # 切换为 MiniMax-M2.5-Lightning 可使用高速版
messages=[{"role": "user", "content": "用 Python 实现一个 LRU 缓存"}]
)
print(response.choices[0].message.content)
查看完整实现代码(含流式输出和工具调用)
from openai import OpenAI
from typing import Optional
def call_minimax_m25(
prompt: str,
model: str = "MiniMax-M2.5",
system_prompt: Optional[str] = None,
max_tokens: int = 4096,
stream: bool = False
) -> str:
"""
调用 MiniMax-M2.5 API
Args:
prompt: 用户输入
model: MiniMax-M2.5 或 MiniMax-M2.5-Lightning
system_prompt: 系统提示词
max_tokens: 最大输出 token 数
stream: 是否启用流式输出
Returns:
模型响应内容
"""
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=max_tokens,
stream=stream
)
if stream:
result = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
result += content
print(content, end="", flush=True)
print()
return result
else:
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 使用示例:编码任务
result = call_minimax_m25(
prompt="重构以下代码,提升性能并添加错误处理",
model="MiniMax-M2.5-Lightning",
system_prompt="你是一个资深全栈工程师,擅长代码重构和性能优化",
stream=True
)
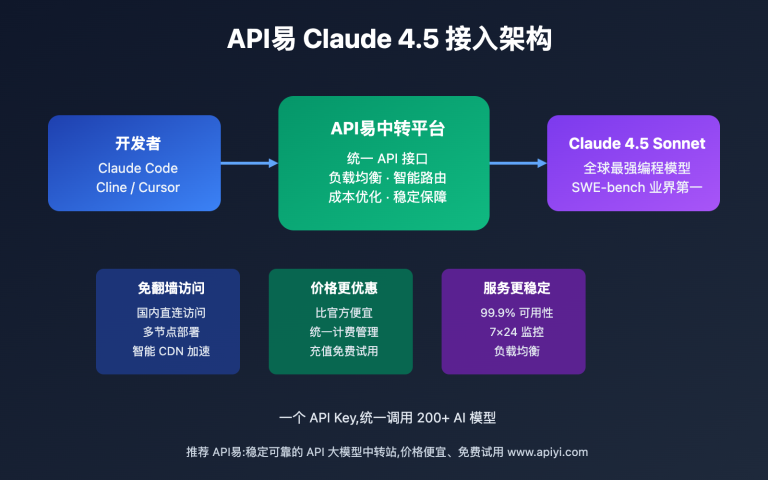
建议: 通过 API易 apiyi.com 获取免费测试额度,快速验证 MiniMax-M2.5 在你的实际项目中的编码效果。平台支持 OpenAI 兼容接口,现有代码只需修改 base_url 和 model 参数即可切换。
MiniMax-M2.5 技术架构解析
MiniMax-M2.5 的核心竞争力来源于两个技术创新:MoE 高效架构和 Forge RL 训练框架。
MiniMax-M2.5 MoE 架构优势
| 架构参数 | MiniMax-M2.5 | 传统密集模型 | 优势说明 |
|---|---|---|---|
| 总参数量 | 230B | 通常 70B-200B | 知识容量更大 |
| 激活参数量 | 10B | 等于总参数量 | 推理成本极低 |
| 推理效率 | 50-100 TPS | 10-30 TPS | 速度提升 3-10 倍 |
| 单位成本 | $1.20/M 输出 | $20-$75/M 输出 | 成本降低 20-60 倍 |
MoE 架构的核心思想是"专家分工"——模型包含多组专家网络,每次推理只激活与当前任务最相关的专家子集。M2.5 以仅 10B 的激活参数量实现了接近 230B 密集模型的效果,这使得它成为目前 Tier 1 模型中体积最小、成本最低的选择。
MiniMax-M2.5 Forge RL 训练框架
M2.5 的另一关键技术是 Forge 强化学习框架:
- 训练环境规模: 超过 20 万个真实世界训练环境,涵盖代码库、网页浏览器、办公应用
- 训练算法: CISPO(Clipped Importance Sampling Policy Optimization),专为多步决策任务设计
- 训练效率: 相比标准 RL 方法实现 40 倍训练加速
- 奖励机制: 基于结果的奖励系统,而非传统的人类偏好反馈(RLHF)
这种训练方式使得 M2.5 在真实编码和智能体任务中表现更加稳健,能够高效地进行任务分解、工具选择和多步执行。
🎯 实践建议:MiniMax-M2.5 已经在 API易 apiyi.com 平台上线。建议开发者先使用免费额度测试编码和智能体场景,根据实际延迟和效果需求选择标准版或 Lightning 版本。
常见问题
Q1: MiniMax-M2.5 标准版和 Lightning 版本能力有差异吗?
没有差异。两个版本的模型能力完全一致,SWE-Bench、BFCL 等所有基准测试得分相同。唯一的区别是推理速度(标准版 50 TPS vs Lightning 100 TPS)和对应的定价。选择时只需考虑延迟需求和预算。
Q2: MiniMax-M2.5 适合替代 Claude Opus 4.6 吗?
在编码和智能体场景中可以考虑。M2.5 的 SWE-Bench 得分(80.2%)仅低于 Opus 4.6 0.6 个百分点,而工具调用能力(BFCL 76.8%)大幅领先。价格方面,M2.5 标准版仅为 Opus 的 1/63。建议通过 API易 apiyi.com 在实际项目中对比测试,根据你的具体场景判断。
Q3: 如何快速开始测试 MiniMax-M2.5?
推荐使用 API易平台快速接入:
- 访问 API易 apiyi.com 注册账号
- 获取 API Key 和免费测试额度
- 使用本文的代码示例,修改 model 参数为
MiniMax-M2.5或MiniMax-M2.5-Lightning - OpenAI 兼容接口,现有项目只需修改 base_url 即可
总结
MiniMax-M2.5 的核心要点:
- 编码能力前沿: SWE-Bench Verified 80.2%,Multi-SWE-Bench 51.3% 行业领先,是首个超越 Claude Sonnet 的开源模型
- 智能体能力第一: BFCL Multi-Turn 76.8% 大幅领先所有竞品,工具调用轮次比前代减少 20%
- 极致性价比: 标准版输出仅 $1.20/M tokens,是 Opus 4.6 的 1/63,同等预算可完成 10 倍以上任务
- 双版本灵活选择: 标准版适合批量和成本优先场景,Lightning 适合实时交互和低延迟场景
MiniMax-M2.5 已在 API易平台上线,支持 OpenAI 兼容接口调用。推荐通过 API易 apiyi.com 获取免费额度进行实测,只需修改 model 参数即可在两个版本间切换对比。
📚 参考资料
⚠️ 链接格式说明: 所有外链使用
资料名: domain.com格式,方便复制但不可点击跳转,避免 SEO 权重流失。
-
MiniMax M2.5 官方公告: 详细介绍 M2.5 的核心能力和技术细节
- 链接:
minimax.io/news/minimax-m25 - 说明: 官方发布文档,包含完整的基准测试数据和训练方法介绍
- 链接:
-
MiniMax API 文档: 官方 API 接入指南和模型规格
- 链接:
platform.minimax.io/docs/guides/text-generation - 说明: 包含模型 ID、上下文窗口、API 调用示例等技术规格
- 链接:
-
Artificial Analysis 评测: 独立第三方模型评测和性能分析
- 链接:
artificialanalysis.ai/models/minimax-m2-5 - 说明: 提供标准化的基准测试排名、速度实测和价格对比
- 链接:
-
MiniMax HuggingFace: 开源模型权重下载
- 链接:
huggingface.co/MiniMaxAI - 说明: MIT 协议开源,支持 vLLM/SGLang 私有化部署
- 链接:
作者: 技术团队
技术交流: 欢迎在评论区讨论 MiniMax-M2.5 的使用体验,更多 AI 模型 API 接入教程可访问 API易 apiyi.com 技术社区