저자 주: MiniMax-M2.5와 M2.5-Lightning 두 버전의 코딩 능력, 에이전트 성능 및 API 접속 방법을 심층 분석합니다. SWE-Bench 80.2%로 Opus 4.6에 근접하는 성능을 보여주면서도 가격은 1/60 수준에 불과합니다.
MiniMax가 2026년 2월 12일, MiniMax-M2.5와 M2.5-Lightning 두 가지 모델 버전을 출시했습니다. 이는 현재 오픈소스 모델 중 코딩 능력에서 Claude Sonnet을 능가한 최초의 모델로, SWE-Bench Verified에서 80.2%를 기록하며 Claude Opus 4.6보다 단 0.6% 포인트 낮은 성적을 거두었습니다. 현재 이 두 모델은 APIYI 플랫폼에 출시되었으니 바로 접속해 사용해 보세요. 충전 이벤트에 참여하면 공식 홈페이지 대비 20% 저렴한 가격으로 이용하실 수 있습니다.
핵심 가치: 본문의 실측 데이터와 코드 예시를 통해 MiniMax-M2.5 두 버전의 핵심 차이점을 파악하고, 여러분의 상황에 가장 적합한 버전을 선택하여 빠르게 API를 연동하는 방법을 알아보세요.

MiniMax-M2.5 핵심 능력 개요
| 핵심 지표 | MiniMax-M2.5 표준판 | MiniMax-M2.5-Lightning | 가치 설명 |
|---|---|---|---|
| SWE-Bench Verified | 80.2% | 80.2% (능력 동일) | Opus 4.6의 80.8%에 근접 |
| 출력 속도 | ~50 TPS | ~100 TPS | Lightning이 2배 빠름 |
| 출력 가격 | $0.15/$1.20 (1M Token당) | $0.30/$2.40 (1M Token당) | 표준판은 Opus의 1/63 수준 |
| BFCL 도구 호출 | 76.8% | 76.8% (능력 동일) | Opus의 63.3%를 크게 상회 |
| 컨텍스트 윈도우 | 205K tokens | 205K tokens | 대규모 코드베이스 분석 지원 |
MiniMax-M2.5 코딩 능력 상세 분석
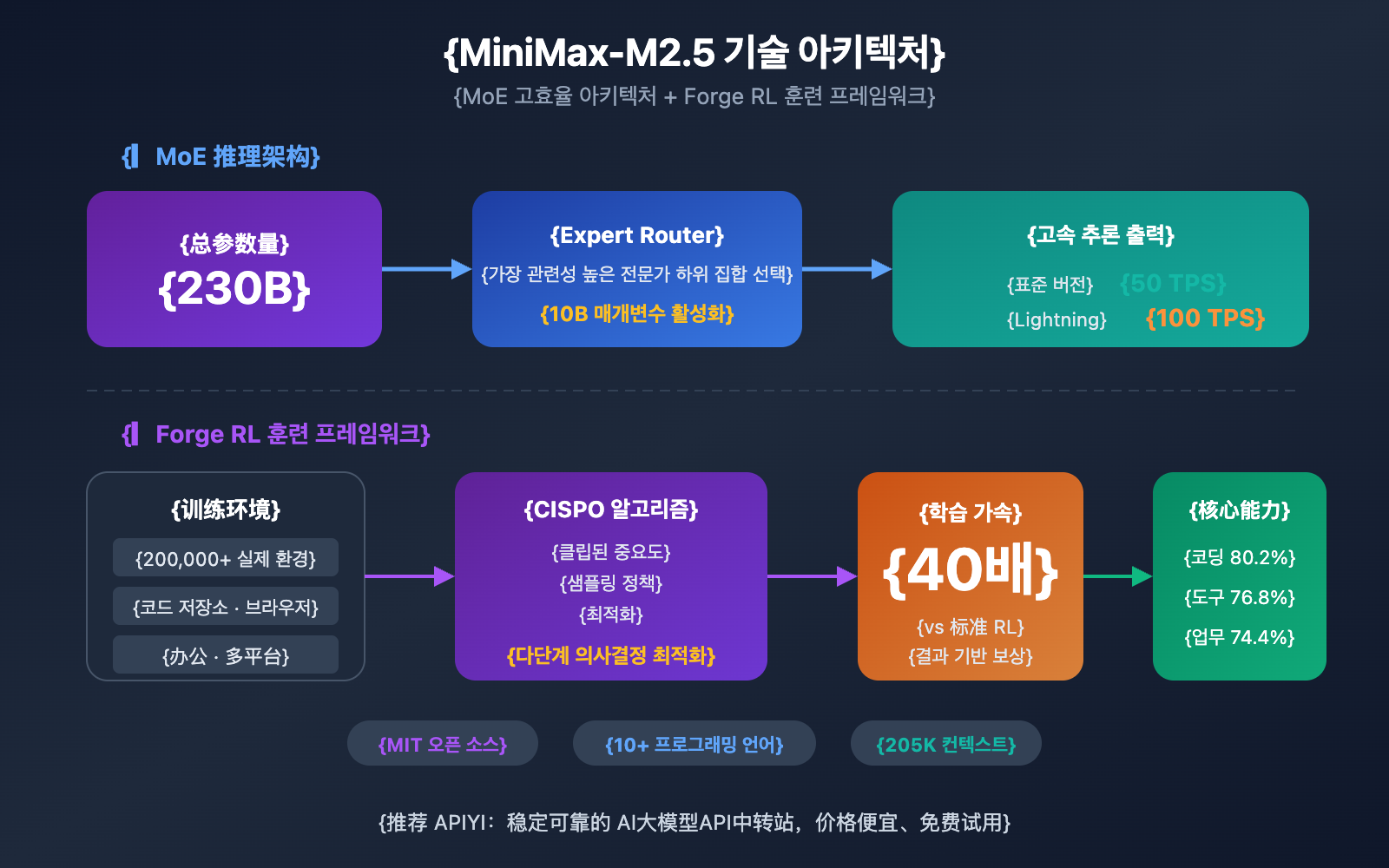
MiniMax-M2.5는 MoE(Mixture of Experts) 아키텍처를 채택하여 총 파라미터 수는 230B에 달하지만, 추론 시에는 10B의 파라미터만 활성화합니다. 이러한 설계를 통해 모델은 최첨단 코딩 능력을 유지하면서도 추론 비용을 획기적으로 낮췄습니다.
코딩 작업에서 M2.5는 독특한 '설계 우선 경향(Spec-writing tendency)'을 보입니다. 코드를 직접 작성하기 전에 프로젝트의 아키텍처를 분해하고 설계를 계획하는 과정을 거칩니다. 이러한 행동 패턴 덕분에 복잡한 다중 파일 프로젝트 처리 능력이 뛰어나며, Multi-SWE-Bench 점수 51.3%를 기록해 Claude Opus 4.6의 50.3%를 앞서기도 했습니다.
이 모델은 Python, Go, C/C++, TypeScript, Rust, Java, JavaScript, Kotlin, PHP 등 10개 이상의 주요 프로그래밍 언어를 지원하는 풀스택 개발 능력을 갖추고 있으며, Web, Android, iOS, Windows 등 다양한 플랫폼 프로젝트를 지원합니다.
MiniMax-M2.5 지능형 에이전트 및 도구 호출 능력
M2.5는 BFCL Multi-Turn 벤치마크에서 76.8%를 기록하며 Claude Opus 4.6(63.3%)과 Gemini 3 Pro(61.0%)를 크게 앞질렀습니다. 이는 여러 차례의 대화와 다양한 도구 협업이 필요한 지능형 에이전트 시나리오에서 M2.5가 현재 가장 강력한 선택지임을 의미합니다.
이전 세대인 M2.1과 비교했을 때, M2.5는 에이전트 작업을 완료하는 데 필요한 도구 호출 횟수가 약 20% 감소했으며, SWE-Bench Verified 평가 속도는 37% 향상되었습니다. 더욱 효율적인 작업 분해 능력은 토큰 소모량과 호출 비용을 직접적으로 절감해 줍니다.
MiniMax-M2.5 표준 버전과 Lightning 버전 비교
MiniMax-M2.5의 어떤 버전을 선택할지는 구체적인 사용 시나리오에 따라 달라집니다. 두 버전의 모델 성능은 완전히 동일하며, 핵심적인 차이점은 추론 속도와 가격 정책에 있습니다.
| 비교 항목 | M2.5 표준 버전 | M2.5-Lightning | 선택 제안 |
|---|---|---|---|
| API 모델 ID | MiniMax-M2.5 |
MiniMax-M2.5-highspeed |
— |
| 추론 속도 | ~50 TPS | ~100 TPS | 실시간 응답이 필요하면 Lightning 선택 |
| 입력 가격 | $0.15/M tokens | $0.30/M tokens | 배치 작업은 표준 버전 선택 |
| 출력 가격 | $1.20/M tokens | $2.40/M tokens | 표준 버전이 절반 가격으로 저렴함 |
| 지속 실행 비용 | ~$0.30/시간 | ~$1.00/시간 | 백그라운드 작업은 표준 버전 선택 |
| 코딩 능력 | 완전히 동일함 | 완전히 동일함 | 두 버전 간 차이 없음 |
| 도구 호출 | 완전히 동일함 | 완전히 동일함 | 두 버전 간 차이 없음 |
MiniMax-M2.5 버전 선택 시나리오 가이드
Lightning 고속 버전을 선택해야 하는 경우:
- 저지연 실시간 코드 완성 및 리팩토링 제안이 필요한 IDE 코딩 어시스턴트 통합
- 고객 서비스나 기술 지원처럼 사용자가 빠른 응답을 기대하는 대화형 에이전트
- 빠른 피드백이 필요한 웹 브라우징 및 정보 검색 기반의 실시간 검색 강화 애플리케이션
표준 버전을 선택해야 하는 경우:
- 실시간 상호작용이 필요 없는 백그라운드 배치 코드 리뷰 및 자동 수정
- 장시간 실행되는 비동기 워크플로우 기반의 대규모 에이전트 작업 편성
- 단위 비용 최소화를 추구하는 예산에 민감한 고처리량 애플리케이션
🎯 선택 팁: 어떤 버전을 선택할지 고민된다면, 먼저 APIYI apiyi.com 플랫폼에서 두 버전을 동시에 테스트해 보시는 것을 추천해요. 표준 버전과 Lightning 버전은 동일한 인터페이스 내에서 model 파라미터만 수정하면 되므로 지연 시간과 효과를 빠르게 비교해 볼 수 있습니다.
MiniMax-M2.5와 경쟁 모델 코딩 능력 비교

| 모델 | SWE-Bench Verified | BFCL Multi-Turn | 출력 가격/1M | $100당 완료 가능한 작업 수 |
|---|---|---|---|---|
| MiniMax-M2.5 | 80.2% | 76.8% | $1.20 | ~328 |
| MiniMax-M2.5-Lightning | 80.2% | 76.8% | $2.40 | ~164 |
| Claude Opus 4.6 | 80.8% | 63.3% | ~$75 | ~30 |
| GPT-5.2 | 80.0% | — | ~$60 | ~30 |
| Gemini 3 Pro | 78.0% | 61.0% | ~$20 | ~90 |
데이터를 살펴보면, MiniMax-M2.5는 코딩 능력 면에서 이미 최첨단 수준에 도달했음을 알 수 있습니다. SWE-Bench Verified에서 80.2%의 점수를 기록하며 Opus 4.6보다 단 0.6% 낮을 뿐이지만, 가격 차이는 무려 60배 이상입니다. 특히 도구 호출 능력(Tool Calling)에서는 M2.5의 BFCL 점수가 76.8%로 모든 경쟁 모델을 압도하고 있습니다.
코딩 에이전트를 대규모로 배포해야 하는 팀에게 M2.5의 비용 효율성은 엄청난 장점이에요. 동일한 $100의 예산으로 약 328개의 작업을 완료할 수 있는 반면, Opus 4.6을 사용하면 약 30개 정도만 완료할 수 있기 때문이죠.
비교 설명: 위 벤치마크 데이터는 각 모델의 공식 발표 자료와 제3자 평가 기관인 Artificial Analysis의 데이터를 기반으로 합니다. 실제 성능은 구체적인 작업 시나리오에 따라 다를 수 있으므로, APIYI apiyi.com을 통해 실제 환경에서 직접 테스트해 보시는 것을 권장합니다.
MiniMax-M2.5 API 빠른 연동 가이드
초간단 예제
APIYI 플랫폼을 통해 MiniMax-M2.5를 연동하는 가장 간단한 방법입니다. 단 10줄의 코드로 바로 실행해 볼 수 있어요.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="MiniMax-M2.5", # 고속 버전이 필요하면 MiniMax-M2.5-Lightning으로 변경하세요
messages=[{"role": "user", "content": "用 Python 实现一个 LRU 缓存"}]
)
print(response.choices[0].message.content)
전체 구현 코드 보기 (스트리밍 출력 및 도구 호출 포함)
from openai import OpenAI
from typing import Optional
def call_minimax_m25(
prompt: str,
model: str = "MiniMax-M2.5",
system_prompt: Optional[str] = None,
max_tokens: int = 4096,
stream: bool = False
) -> str:
"""
调用 MiniMax-M2.5 API
Args:
prompt: 用户输入
model: MiniMax-M2.5 或 MiniMax-M2.5-Lightning
system_prompt: 系统提示词
max_tokens: 最大输出 token 数
stream: 是否启用流式输出
Returns:
模型响应内容
"""
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=max_tokens,
stream=stream
)
if stream:
result = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
result += content
print(content, end="", flush=True)
print()
return result
else:
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 使用示例:编码任务
result = call_minimax_m25(
prompt="重构以下代码,提升性能并添加错误处理",
model="MiniMax-M2.5-Lightning",
system_prompt="你是一个资深全栈工程师,擅长代码重构和性能优化",
stream=True
)
권장 사항: APIYI(apiyi.com)에서 무료 테스트 크레딧을 받아 실제 프로젝트에서 MiniMax-M2.5의 코딩 성능을 빠르게 검증해 보세요. 이 플랫폼은 OpenAI 호환 인터페이스를 지원하므로, 기존 코드에서 base_url과 model 파라미터만 수정하면 바로 전환할 수 있습니다.
MiniMax-M2.5 기술 아키텍처 분석
MiniMax-M2.5의 핵심 경쟁력은 MoE(Mixture of Experts) 효율적 아키텍처와 Forge RL 훈련 프레임워크라는 두 가지 기술 혁신에서 나옵니다.
MiniMax-M2.5 MoE 아키텍처의 장점
| 아키텍처 파라미터 | MiniMax-M2.5 | 기존 밀집(Dense) 모델 | 장점 설명 |
|---|---|---|---|
| 총 파라미터 수 | 230B | 보통 70B-200B | 지식 용량이 더 큼 |
| 활성화 파라미터 수 | 10B | 총 파라미터 수와 동일 | 추론 비용이 매우 낮음 |
| 추론 효율 | 50-100 TPS | 10-30 TPS | 속도 3-10배 향상 |
| 단위 비용 | $1.20/1M 출력 | $20-$75/1M 출력 | 비용 20-60배 절감 |
MoE 아키텍처의 핵심 아이디어는 '전문가 분업'입니다. 모델은 여러 전문가 네트워크 그룹을 포함하며, 추론할 때마다 현재 작업과 가장 관련이 있는 전문가 하위 집합만 활성화합니다. M2.5는 단 10B의 활성화 파라미터만으로 230B 밀집 모델에 가까운 성능을 구현했으며, 이는 현재 Tier 1 모델 중 가장 작고 비용 효율적인 선택지가 되게 합니다.
MiniMax-M2.5 Forge RL 훈련 프레임워크
M2.5의 또 다른 핵심 기술은 Forge 강화 학습 프레임워크입니다.
- 훈련 환경 규모: 코드 저장소, 웹 브라우저, 오피스 앱을 아우르는 20만 개 이상의 실제 환경 데이터 활용
- 훈련 알고리즘: 다단계 의사 결정 작업을 위해 특별히 설계된 CISPO(Clipped Importance Sampling Policy Optimization)
- 훈련 효율: 표준 RL 방식 대비 40배 빠른 훈련 가속화 실현
- 보상 메커니즘: 기존의 인간 선호도 피드백(RLHF) 대신 결과 기반 보상 시스템(Outcome-based Reward) 사용
이러한 훈련 방식 덕분에 M2.5는 실제 코딩 및 에이전트 작업에서 더욱 안정적인 성능을 보여주며, 효율적인 작업 분해, 도구 선택 및 다단계 실행이 가능합니다.
🎯 실전 팁: MiniMax-M2.5는 이미 APIYI(apiyi.com) 플랫폼에 출시되었습니다. 개발자분들은 먼저 무료 크레딧을 사용해 코딩 및 에이전트 시나리오를 테스트해 보시고, 실제 지연 시간과 성능 요구 사항에 따라 표준 버전 또는 Lightning 버전을 선택하는 것을 추천합니다.
자주 묻는 질문
Q1: MiniMax-M2.5 표준 버전과 Lightning 버전의 성능 차이가 있나요?
성능 차이는 없습니다. 두 버전의 모델 성능은 완전히 동일하며, SWE-Bench, BFCL 등 모든 벤치마크 테스트 점수가 같습니다. 유일한 차이점은 추론 속도(표준 버전 50 TPS vs Lightning 100 TPS)와 그에 따른 가격입니다. 선택 시 지연 시간(Latency) 요구 사항과 예산만 고려하시면 됩니다.
Q2: MiniMax-M2.5가 Claude Opus 4.6을 대체하기에 적합할까요?
코딩 및 에이전트 시나리오에서 충분히 고려해 볼 만합니다. M2.5의 SWE-Bench 점수(80.2%)는 Opus 4.6보다 단 0.6% 포인트 낮을 뿐이며, 도구 호출 능력(BFCL 76.8%)은 크게 앞서 있습니다. 가격 면에서 M2.5 표준 버전은 Opus의 1/63에 불과합니다. APIYI(apiyi.com)를 통해 실제 프로젝트에서 비교 테스트를 진행해 보시고, 여러분의 구체적인 상황에 맞춰 판단하시길 권장합니다.
Q3: MiniMax-M2.5 테스트를 빠르게 시작하려면 어떻게 해야 하나요?
APIYI 플랫폼을 사용하여 빠르게 연동하는 것을 추천합니다:
- APIYI(apiyi.com)에 접속하여 계정 등록
- API Key와 무료 테스트 크레딧 받기
- 본문의 코드 예제를 사용하여
model파라미터를MiniMax-M2.5또는MiniMax-M2.5-Lightning으로 수정 - OpenAI 호환 인터페이스를 지원하므로, 기존 프로젝트에서
base_url만 수정하면 바로 사용 가능합니다.
요약
MiniMax-M2.5의 핵심 포인트는 다음과 같습니다:
- 최첨단 코딩 능력: SWE-Bench Verified 80.2%, Multi-SWE-Bench 51.3%로 업계 선두 수준이며, Claude Sonnet을 뛰어넘은 최초의 오픈소스 모델입니다.
- 에이전트 능력 1위: BFCL Multi-Turn 76.8%로 모든 경쟁 제품을 크게 앞서며, 도구 호출 횟수가 이전 세대보다 20% 감소했습니다.
- 압도적인 가성비: 표준 버전 출력 비용이 $1.20/M tokens로 Opus 4.6의 1/63 수준입니다. 동일한 예산으로 10배 이상의 작업을 수행할 수 있습니다.
- 유연한 두 가지 버전: 표준 버전은 대량 처리 및 비용 우선 시나리오에 적합하고, Lightning은 실시간 상호작용 및 저지연 시나리오에 적합합니다.
MiniMax-M2.5는 이미 APIYI 플랫폼에 출시되었으며, OpenAI 호환 인터페이스 호출을 지원합니다. APIYI(apiyi.com)에서 무료 크레딧을 받아 직접 테스트해 보시는 것을 추천드려요. model 파라미터만 수정하면 두 버전 사이를 간편하게 전환하며 비교해 볼 수 있습니다.
📚 참고 자료
⚠️ 링크 형식 안내: 모든 외부 링크는 SEO 가중치 손실을 방지하기 위해 복사는 쉽지만 클릭은 되지 않는
자료명: domain.com형식을 사용합니다.
-
MiniMax M2.5 공식 발표: M2.5의 핵심 역량과 기술적 세부 사항 상세 소개
- 링크:
minimax.io/news/minimax-m25 - 설명: 공식 배포 문서로, 전체 벤치마크 데이터와 학습 방법 소개를 포함하고 있습니다.
- 링크:
-
MiniMax API 문서: 공식 API 연동 가이드 및 모델 사양
- 링크:
platform.minimax.io/docs/guides/text-generation - 설명: 모델 ID, 컨텍스트 윈도우, API 호출 예시 등 기술 사양을 담고 있습니다.
- 링크:
-
Artificial Analysis 평가: 독립적인 제3자 모델 평가 및 성능 분석
- 링크:
artificialanalysis.ai/models/minimax-m2-5 - 설명: 표준화된 벤치마크 순위, 실제 속도 측정 및 가격 비교를 제공합니다.
- 링크:
-
MiniMax HuggingFace: 오픈 소스 모델 가중치 다운로드
- 링크:
huggingface.co/MiniMaxAI - 설명: MIT 라이선스로 공개되었으며, vLLM/SGLang을 통한 프라이빗 배포를 지원합니다.
- 링크:
작성자: 기술 팀
기술 교류: 댓글창에서 MiniMax-M2.5 사용 경험에 대해 자유롭게 이야기를 나눠주세요. 더 많은 AI 모델 API 연동 튜토리얼은 APIYI apiyi.com 기술 커뮤니티에서 확인하실 수 있습니다.