Note de l'auteur : Analyse approfondie des capacités de codage, des performances des agents et des méthodes d'accès API pour les versions MiniMax-M2.5 et M2.5-Lightning. Avec un score de 80,2 % au SWE-Bench, il talonne les 80,8 % d'Opus pour seulement 1/60 du prix.
MiniMax a lancé, le 12 février 2026, deux versions de son modèle : MiniMax-M2.5 et M2.5-Lightning. C'est actuellement le tout premier modèle open-source à surpasser Claude Sonnet en codage, atteignant 80,2 % au SWE-Bench Verified, soit seulement 0,6 point de moins que Claude Opus 4.6. Ces deux modèles sont déjà disponibles sur la plateforme APIYI. D'ailleurs, en profitant des offres de recharge, vous pouvez obtenir un tarif 20 % moins cher que sur le site officiel.
Valeur ajoutée : Grâce aux données de tests réels et aux exemples de code de cet article, vous découvrirez les différences majeures entre les deux versions de MiniMax-M2.5, choisirez celle qui correspond le mieux à vos besoins et maîtriserez rapidement l'accès à l'API.

Aperçu des capacités clés de MiniMax-M2.5
| Indicateurs clés | MiniMax-M2.5 Standard | MiniMax-M2.5-Lightning | Description de la valeur |
|---|---|---|---|
| SWE-Bench Verified | 80,2 % | 80,2 % (Capacités identiques) | Proche des 80,8 % d'Opus 4.6 |
| Vitesse de sortie | ~50 TPS | ~100 TPS | Lightning est 2x plus rapide |
| Prix de sortie | 0,15 $ / 1,20 $ par million de tokens | 0,30 $ / 2,40 $ par million de tokens | La version Standard ne coûte que 1/63 d'Opus |
| Appel d'outils BFCL | 76,8 % | 76,8 % (Capacités identiques) | Nettement supérieur aux 63,3 % d'Opus |
| Fenêtre de contexte | 205K tokens | 205K tokens | Supporte l'analyse de larges bases de code |
Détails des capacités de codage de MiniMax-M2.5
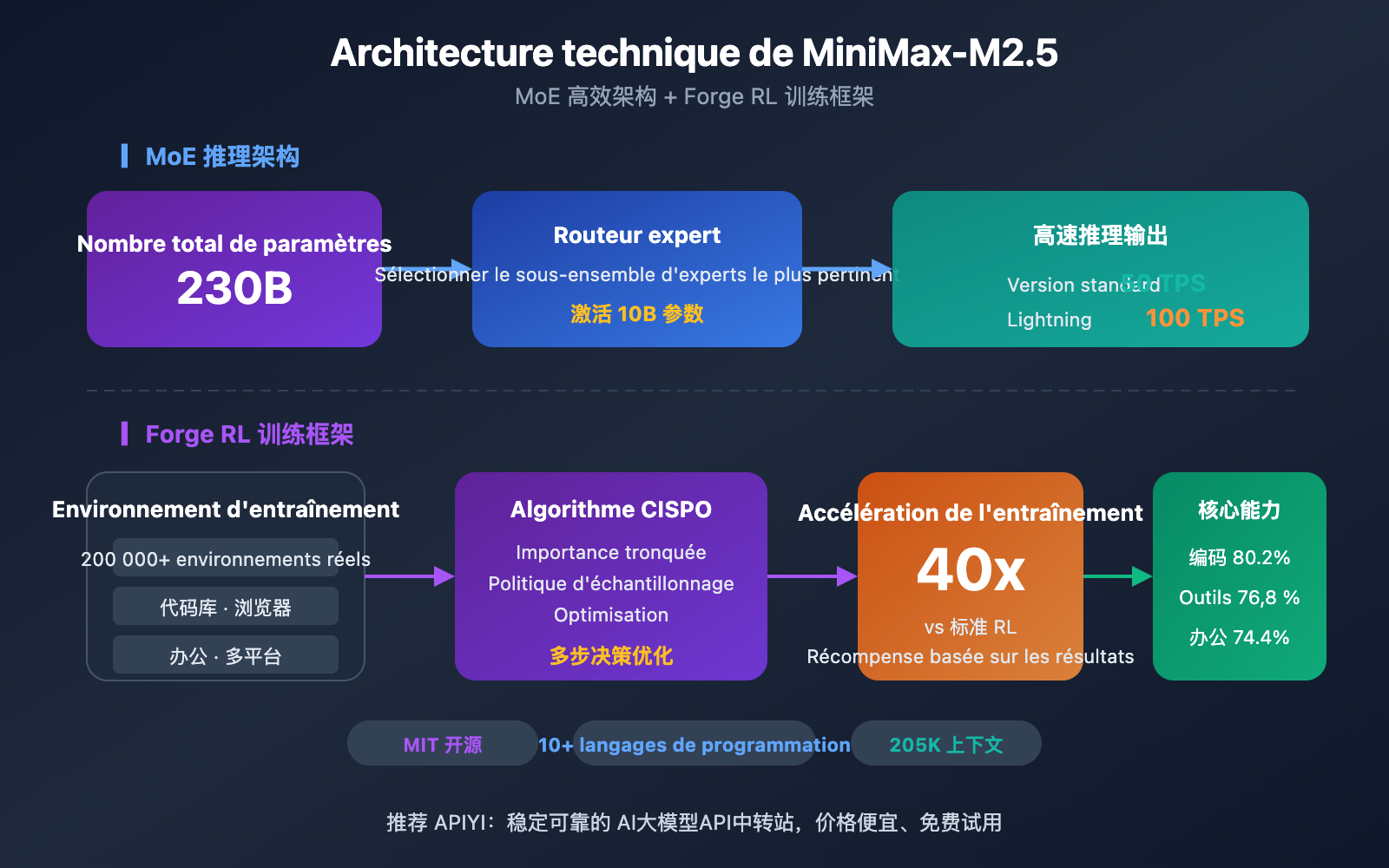
MiniMax-M2.5 repose sur une architecture MoE (Mixture of Experts) avec un total de 230B de paramètres, dont seulement 10B sont activés lors de l'inférence. Cette conception permet au modèle de maintenir des capacités de codage de pointe tout en réduisant considérablement les coûts d'inférence.
Pour les tâches de programmation, le M2.5 affiche une « tendance à la rédaction de spécifications » (Spec-writing tendency) unique : avant de se lancer dans le code, il décompose l'architecture et planifie la conception du projet. Ce mode de fonctionnement le rend particulièrement performant sur des projets complexes multi-fichiers, avec un score Multi-SWE-Bench de 51,3 %, dépassant même les 50,3 % de Claude Opus 4.6.
Le modèle supporte le développement full-stack dans plus de 10 langages, incluant Python, Go, C/C++, TypeScript, Rust, Java, JavaScript, Kotlin, PHP, etc., tout en étant compatible avec des projets multi-plateformes (Web, Android, iOS, Windows).
Capacités d'agent et d'appel d'outils de MiniMax-M2.5
Le M2.5 a obtenu un score de 76,8 % au benchmark BFCL Multi-Turn, devançant largement Claude Opus 4.6 (63,3 %) et Gemini 3 Pro (61,0 %). Cela signifie que pour des scénarios d'agents nécessitant des dialogues multi-tours et une collaboration entre plusieurs outils, le M2.5 est actuellement le choix le plus performant.
Par rapport à la génération précédente M2.1, le M2.5 réduit d'environ 20 % le nombre de tours d'appels d'outils pour accomplir une tâche, et sa vitesse d'évaluation SWE-Bench Verified a augmenté de 37 %. Cette capacité de décomposition des tâches plus efficace réduit directement la consommation de tokens et les coûts d'appel.
Comparaison entre MiniMax-M2.5 Standard et la version Lightning
Le choix de la version de MiniMax-M2.5 dépend de votre cas d'utilisation spécifique. Les capacités des deux versions du modèle sont strictement identiques ; la différence fondamentale réside dans la vitesse d'inférence et la tarification.
| Dimension de comparaison | M2.5 Standard | M2.5-Lightning | Conseil de choix |
|---|---|---|---|
| ID du modèle API | MiniMax-M2.5 |
MiniMax-M2.5-highspeed |
— |
| Vitesse d'inférence | ~50 TPS | ~100 TPS | Choisissez Lightning pour une réponse en temps réel |
| Prix d'entrée | 0,15 $/M tokens | 0,30 $/M tokens | Choisissez Standard pour les tâches par lots |
| Prix de sortie | 1,20 $/M tokens | 2,40 $/M tokens | La version Standard est deux fois moins chère |
| Coût de fonctionnement continu | ~0,30 $/heure | ~1,00 $/heure | Choisissez Standard pour les tâches en arrière-plan |
| Capacité de codage | Identique | Identique | Aucune différence entre les deux |
| Appel d'outils | Identique | Identique | Aucune différence entre les deux |
Guide de sélection des scénarios pour MiniMax-M2.5
Quand choisir la version haute vitesse Lightning :
- Intégration d'assistants de codage IDE, nécessitant une complétion de code en temps réel et des suggestions de refactorisation à faible latence.
- Dialogues avec des agents intelligents interactifs, où l'utilisateur attend une réponse rapide du support client ou technique.
- Applications de recherche augmentée en temps réel, nécessitant un retour rapide pour la navigation web et l'extraction d'informations.
Quand choisir la version Standard :
- Revue de code et correction automatique en arrière-plan par lots, sans besoin d'interaction en temps réel.
- Orchestration de tâches d'agents à grande échelle, pour des flux de travail asynchrones de longue durée.
- Applications à haut débit sensibles au budget, visant le coût unitaire le plus bas.
🎯 Conseil de choix : Si vous hésitez, nous vous suggérons de tester les deux versions simultanément sur la plateforme APIYI (apiyi.com). Comme les deux versions utilisent la même interface, il vous suffit de modifier le paramètre
modelpour comparer rapidement la latence et les résultats.
MiniMax-M2.5 vs Concurrents : Capacités de codage
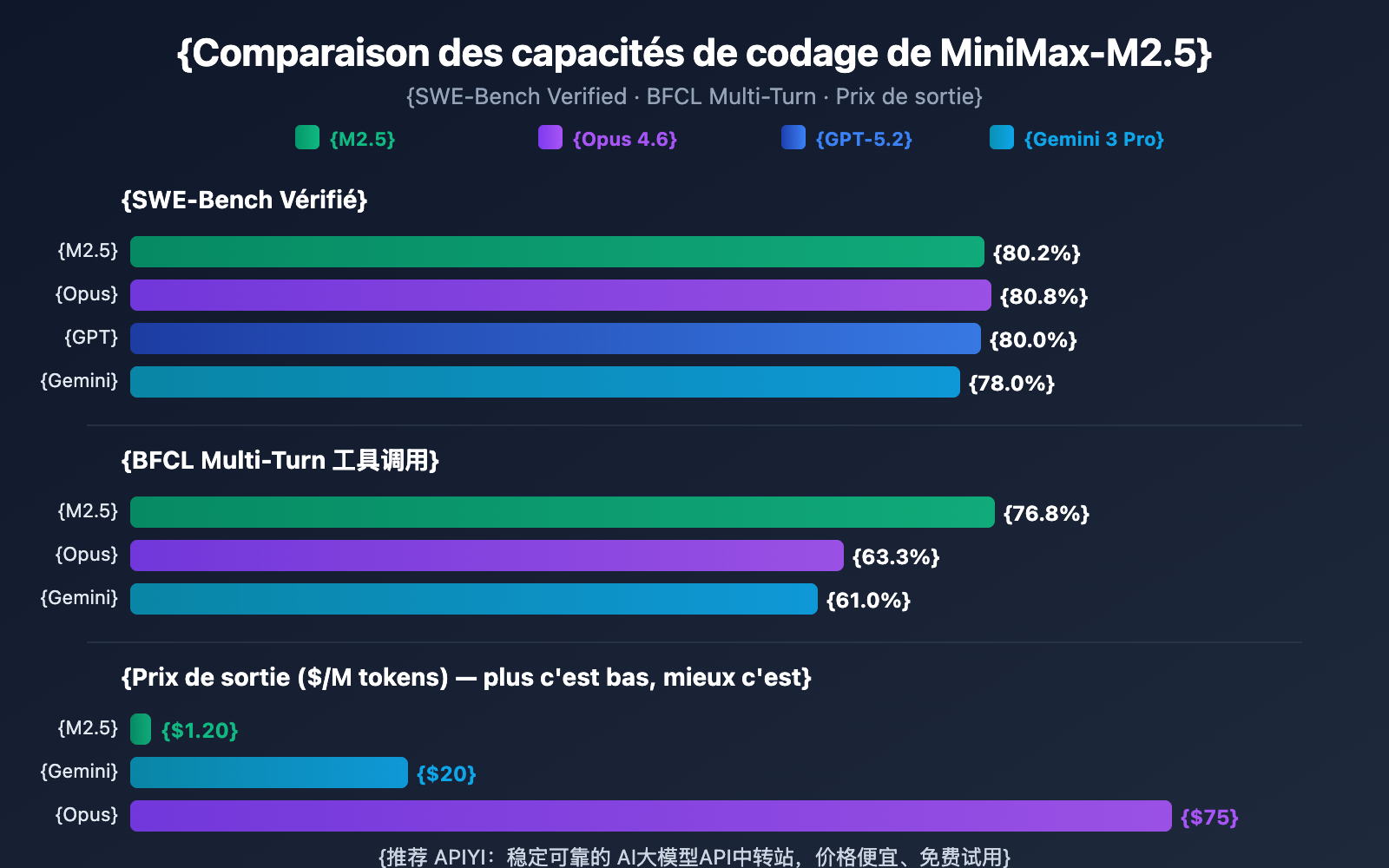
| Modèle | SWE-Bench Verified | BFCL Multi-Turn | Prix de sortie/M | Tâches réalisables pour 100 $ |
|---|---|---|---|---|
| MiniMax-M2.5 | 80,2 % | 76,8 % | 1,20 $ | ~328 |
| MiniMax-M2.5-Lightning | 80,2 % | 76,8 % | 2,40 $ | ~164 |
| Claude Opus 4.6 | 80,8 % | 63,3 % | ~75 $ | ~30 |
| GPT-5.2 | 80,0 % | — | ~60 $ | ~30 |
| Gemini 3 Pro | 78,0 % | 61,0 % | ~20 $ | ~90 |
D'après les données, MiniMax-M2.5 a atteint un niveau de pointe en termes de capacités de codage. Son score de 80,2 % sur SWE-Bench Verified n'est que de 0,6 % inférieur à celui d'Opus 4.6, mais avec une différence de prix de plus de 60 fois. En ce qui concerne l'appel d'outils, le score BFCL de 76,8 % de M2.5 surpasse largement tous ses concurrents.
Pour les équipes ayant besoin de déployer des agents de codage à grande échelle, l'avantage de coût de M2.5 signifie qu'avec un budget identique de 100 $, vous pouvez accomplir environ 328 tâches, contre seulement 30 environ avec Opus 4.6.
Note de comparaison : Les données de référence ci-dessus proviennent des chiffres officiels publiés par chaque modèle et de l'organisme d'évaluation tiers Artificial Analysis. Les performances réelles peuvent varier selon les scénarios de tâches spécifiques ; il est recommandé d'effectuer des tests en situation réelle via APIYI (apiyi.com).
MiniMax-M2.5 API 快速接入
极简示例
以下是通过 APIYI平台接入 MiniMax-M2.5 的最简方式,10 行代码即可运行:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="MiniMax-M2.5", # 切换为 MiniMax-M2.5-Lightning 可使用高速版
messages=[{"role": "user", "content": "用 Python 实现一个 LRU 缓存"}]
)
print(response.choices[0].message.content)
查看完整实现代码(含流式输出和工具调用)
from openai import OpenAI
from typing import Optional
def call_minimax_m25(
prompt: str,
model: str = "MiniMax-M2.5",
system_prompt: Optional[str] = None,
max_tokens: int = 4096,
stream: bool = False
) -> str:
"""
调用 MiniMax-M2.5 API
Args:
prompt: 用户输入
model: MiniMax-M2.5 或 MiniMax-M2.5-Lightning
system_prompt: 系统提示词
max_tokens: 最大输出 token 数
stream: 是否启用流式输出
Returns:
模型响应内容
"""
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=max_tokens,
stream=stream
)
if stream:
result = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
result += content
print(content, end="", flush=True)
print()
return result
else:
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 使用示例:编码任务
result = call_minimax_m25(
prompt="重构以下代码,提升性能并添加错误处理",
model="MiniMax-M2.5-Lightning",
system_prompt="你是一个资深全栈工程师,擅长代码重构和性能优化",
stream=True
)
建议: 通过 APIYI apiyi.com 获取免费测试额度,快速验证 MiniMax-M2.5 在你的实际项目中的编码效果。平台支持 OpenAI 兼容接口,现有代码只需修改 base_url 和 model 参数即可切换。
MiniMax-M2.5 技术架构解析
MiniMax-M2.5 的核心竞争力来源于两个技术创新:MoE 高效架构和 Forge RL 训练框架。
MiniMax-M2.5 MoE 架构优势
| 架构参数 | MiniMax-M2.5 | 传统密集模型 | 优势说明 |
|---|---|---|---|
| 总参数量 | 230B | 通常 70B-200B | 知识容量更大 |
| 激活参数量 | 10B | 等于总参数量 | 推理成本极低 |
| 推理效率 | 50-100 TPS | 10-30 TPS | 速度提升 3-10 倍 |
| 单位成本 | $1.20/M 输出 | $20-$75/M 输出 | 成本降低 20-60 倍 |
MoE 架构的核心思想是"专家分工"——模型包含多组专家网络,每次推理只激活与当前任务最相关的专家子集。M2.5 以仅 10B 的激活参数量实现了接近 230B 密集模型的效果,这使得它成为目前 Tier 1 模型中体积最小、成本最低的选择。
MiniMax-M2.5 Forge RL 训练框架
M2.5 的另一关键技术是 Forge 强化学习框架:
- 训练环境规模: 超过 20 万个真实世界训练环境,涵盖代码库、网页浏览器、办公应用
- 训练算法: CISPO(Clipped Importance Sampling Policy Optimization),专为多步决策任务设计
- 训练效率: 相比标准 RL 方法实现 40 倍训练加速
- 奖励机制: 基于结果的奖励系统,而非传统的人类偏好反馈(RLHF)
这种训练方式使得 M2.5 在真实编码和智能体任务中表现更加稳健,能够高效地进行任务分解、工具选择和多步执行。
🎯 实践建议:MiniMax-M2.5 已经在 APIYI apiyi.com 平台上线。建议开发者先使用免费额度测试编码和智能体场景,根据实际延迟和效果需求选择标准版或 Lightning 版本。
Questions Fréquentes
Q1 : Existe-t-il une différence de capacités entre les versions MiniMax-M2.5 Standard et Lightning ?
Aucune. Les capacités des deux versions sont strictement identiques : elles obtiennent les mêmes scores sur tous les benchmarks comme SWE-Bench ou BFCL. La seule différence réside dans la vitesse d'inférence (50 TPS pour la version Standard contre 100 TPS pour la version Lightning) et la tarification correspondante. Votre choix dépendra uniquement de vos besoins en termes de latence et de votre budget.
Q2 : MiniMax-M2.5 est-il une alternative viable à Claude Opus 4.6 ?
C'est une option très sérieuse pour le codage et les scénarios d'agents. Le score SWE-Bench de M2.5 (80,2 %) n'est qu'à 0,6 point de celui d'Opus 4.6, tandis que ses capacités d'appel d'outils (BFCL 76,8 %) sont largement supérieures. Côté prix, la version Standard de M2.5 ne coûte qu'un 1/63ème du prix d'Opus. Nous vous conseillons de faire un test comparatif sur vos projets réels via APIYI (apiyi.com) pour juger selon votre cas d'usage spécifique.
Q3 : Comment commencer rapidement à tester MiniMax-M2.5 ?
Le plus simple est d'utiliser la plateforme APIYI pour un accès rapide :
- Rendez-vous sur APIYI (apiyi.com) pour créer un compte.
- Récupérez votre clé API et vos crédits de test gratuits.
- Utilisez les exemples de code fournis dans cet article en modifiant le paramètre
modelparMiniMax-M2.5ouMiniMax-M2.5-Lightning. - L'interface est compatible avec OpenAI, il vous suffit donc de modifier le
base_urldans vos projets existants.
Conclusion
Voici ce qu'il faut retenir de MiniMax-M2.5 :
- Capacités de codage de pointe : Avec 80,2 % sur SWE-Bench Verified et 51,3 % sur Multi-SWE-Bench, il est en tête de l'industrie et devient le premier modèle open-source à surpasser Claude Sonnet.
- Leader pour les agents intelligents : Son score de 76,8 % sur BFCL Multi-Turn devance largement tous ses concurrents, avec une réduction de 20 % du nombre de tours nécessaires pour l'appel d'outils par rapport à la génération précédente.
- Rapport performance-prix imbattable : À seulement 1,20 $ / million de tokens en sortie pour la version Standard, il est 63 fois moins cher qu'Opus 4.6. À budget égal, vous pouvez accomplir 10 fois plus de tâches.
- Flexibilité avec deux versions : La version Standard est idéale pour les traitements par lots et l'optimisation des coûts, tandis que la version Lightning est parfaite pour les interactions en temps réel nécessitant une faible latence.
MiniMax-M2.5 est déjà disponible sur la plateforme APIYI avec une interface compatible OpenAI. Nous vous recommandons de profiter des crédits gratuits sur APIYI (apiyi.com) pour effectuer vos propres tests ; il vous suffit de changer un paramètre pour basculer entre les deux versions et comparer les résultats.
📚 Références
⚠️ Note sur le format des liens : Tous les liens externes utilisent le format
Nom de la ressource : domain.com. Ils sont faciles à copier mais ne sont pas cliquables afin d'éviter la perte de poids SEO.
-
Annonce officielle de MiniMax M2.5 : Présentation détaillée des capacités clés et des détails techniques de M2.5
- Lien :
minimax.io/news/minimax-m25 - Description : Document de publication officiel, incluant les données complètes de benchmark et une introduction aux méthodes d'entraînement.
- Lien :
-
Documentation de l'API MiniMax : Guide d'intégration officiel et spécifications du modèle
- Lien :
platform.minimax.io/docs/guides/text-generation - Description : Contient les ID de modèle, la fenêtre de contexte, des exemples d'appels API et d'autres spécifications techniques.
- Lien :
-
Évaluation d'Artificial Analysis : Évaluation et analyse de performance par un tiers indépendant
- Lien :
artificialanalysis.ai/models/minimax-m2-5 - Description : Fournit des classements de benchmarks standardisés, des tests de vitesse en conditions réelles et des comparaisons de prix.
- Lien :
-
MiniMax HuggingFace : Téléchargement des poids du modèle open-source
- Lien :
huggingface.co/MiniMaxAI - Description : Sous licence MIT, supporte le déploiement privé via vLLM/SGLang.
- Lien :
Auteur : Équipe Technique
Échanges techniques : N'hésitez pas à discuter de votre expérience avec MiniMax-M2.5 dans les commentaires. Pour plus de tutoriels sur l'intégration d'API de grands modèles de langage, visitez la communauté technique APIYI apiyi.com